在AI这个超火的领域,打好基础真的超级重要,尤其是当你开始研究那些超大型的语言模型,也就是LLMs的时候。这个指南就是想帮新手们把那些听起来高大上的概念变得简单易懂,比如神经网络、自然语言处理(NLP)还有LLMs这些。我也会把之前文章的内容做个总结,有些细节我会直接放链接,点一下就能看。咱们会聊聊LLMs是怎么搭建和训练的,还有它们会遇到的一些问题,比如偏见和幻觉。
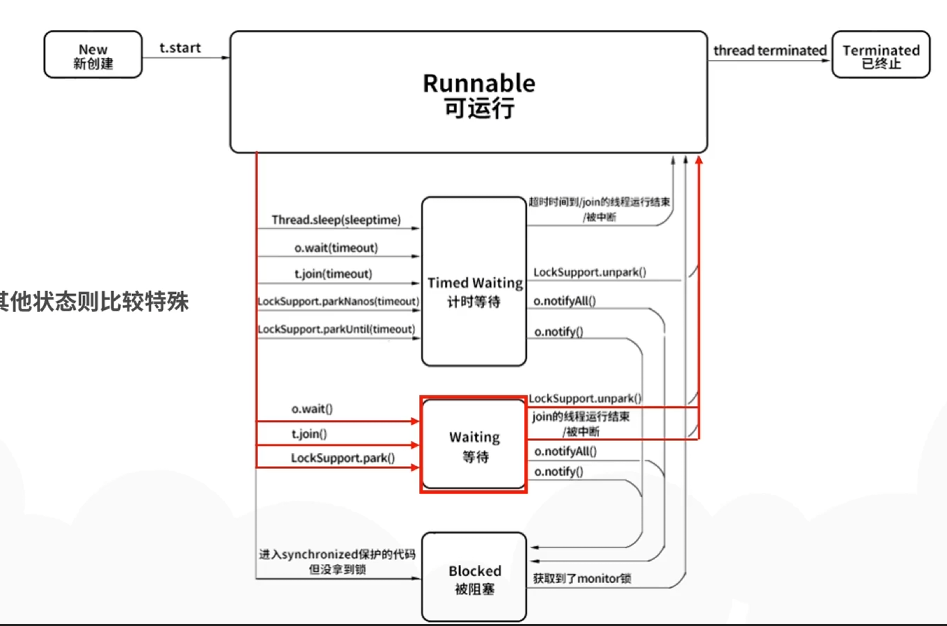
神经网络是啥?
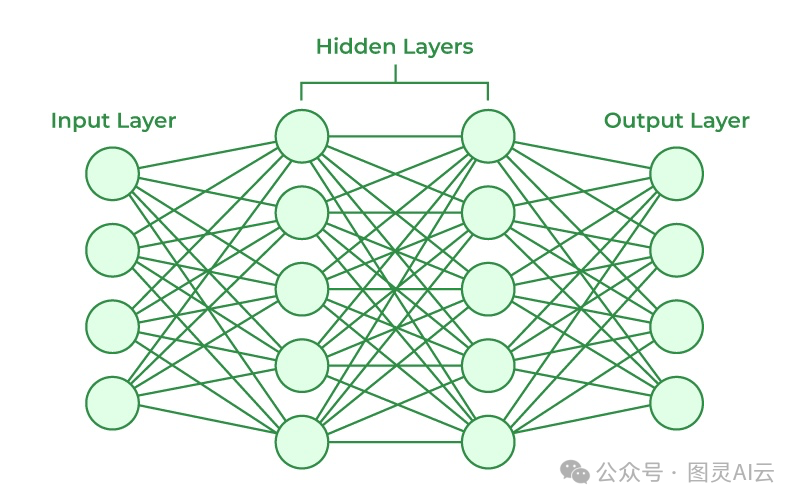
简单来说,神经网络就是一种模仿人脑的机器学习模型。它通过模拟神经元是怎么一起工作的,来识别模式、做决策。这可是所有AI模型,包括LLMs的核心。神经网络是由很多层组成的,每层都有它的任务:
-
输入层: 数据就是从这儿开始进入模型的。
-
隐藏层: 这里的计算让网络能学习到模式。
-
输出层: 最后的结果,比如预测或者决定,就是从这儿出来的。
比如,你可以训练一个神经网络来识别猫的图片。它通过层层的神经元处理图片,最后能从一堆形状各异的东西里认出猫来。可参见《分层神经网络(DNN)知多少?》
自然语言处理(NLP)又是啥?
NLP就是让计算机能理解我们人类的语言,不管是说话还是写字。这个领域就是为了让机器能听懂我们的话,然后做出回应。从聊天机器人到语音助手,背后都是NLP在帮忙。NLP要做的事儿包括:
-
分词: 把一长串的文本拆成小块,比如单词或者更小的词。
-
解析: 理解句子的结构是啥样的。
-
情感分析: 判断一段话是正面的、负面的还是中性的。
如果没有NLP,LLMs根本就搞不懂我们人类的语言到底有多复杂。
大型语言模型(LLMs)到底是啥?
LLMs就是那些特别高级的神经网络,专门用来理解和生成我们人类的语言。它们通过学习大量的文本数据,来掌握语言的模式、上下文和细节。LLMs能做的事情可多了,比如回答问题、写文章、翻译语言或者聊天。它们的目标就是创造出跟人类写的一样自然、复杂的文本。
LLMs的核心思想其实挺直接的:预测句子里的下一个单词。比如,你输入“The sun rises in the...”,它就应该能预测出“east”。虽然听起来简单,但这个小小的任务让模型发展出了超多厉害的能力,比如生成文本、推理甚至创造新的东西。
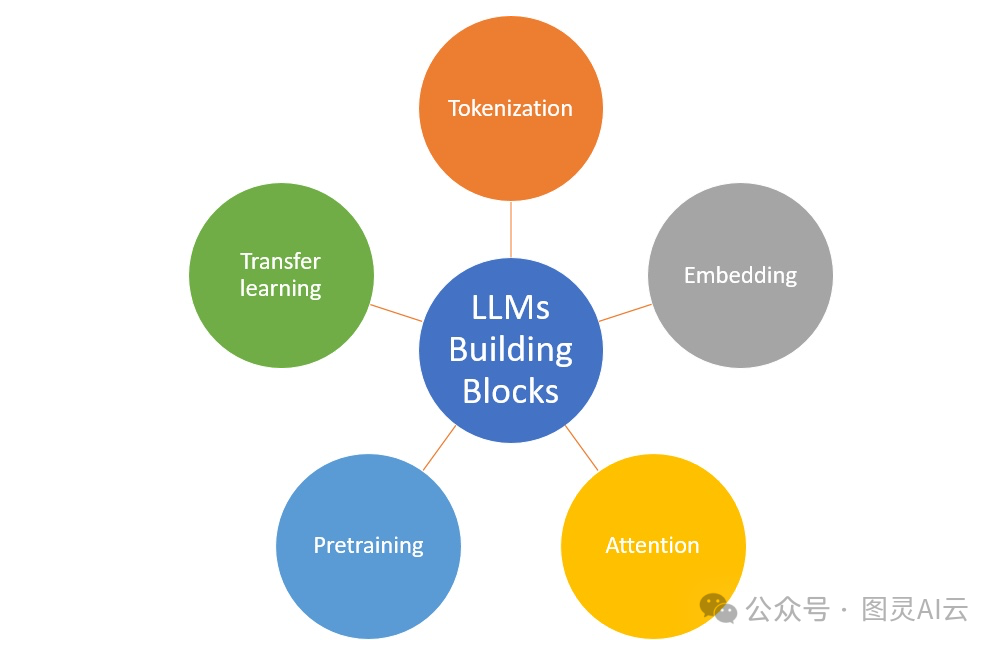
咱们再来聊聊LLMs的一些关键术语。
变换器
变换器,这可是个厉害的角色,它是一种神经网络架构,让模型处理起数据来更高效,特别是在处理自然语言处理(NLP)的时候。这个概念最早是在一篇叫《Attention Is All You Need》的论文里提出来的。以前的模型,比如循环神经网络(RNN),虽然也能处理数据序列,但处理长序列时会遇到麻烦,比如梯度消失问题,就是说,时间一长,模型就记不住前面的信息了。这是因为模型调整得太微小,影响不大。具体可参见:《Transformer架构的详解》及 《用PyTorch构建Transformer模型实战》
变换器用了个叫注意力的机制来解决这些问题,让模型能更专注地看句子或文档的重要部分,不管它们在哪儿。这个创新给像GPT-4、Claude和LLaMA这样的前沿模型打下了基础。
这个架构一开始是个编码器-解码器的结构。编码器负责处理输入的文本,挑出重要的信息,然后解码器再把这个信息变回我们能看懂的文本。这对做摘要之类的任务特别有用。编码器和解码器可以一起用,也可以单独用,这样就很灵活。有些模型只用编码器把文本变成向量,有些则只用解码器,这就是大型语言模型的基础。
语言建模
语言建模,就是教LLMs理解语言里单词出现的概率分布。这样,模型就能预测句子里的下一个单词,这对于生成连贯的文本来说超级重要。在很多应用里,比如文本摘要、翻译或者对话代理,能生成连贯、合适的文本都是关键。
分词
分词,这是用LLMs时的第一步。就是把句子拆成小块,叫标记。这些标记可以是单个字母,也可以是整个单词,具体看模型怎么分,这也会影响模型的效果。详见《什么是分词(Tokenization)》
比如,这句话:“The developer’s favorite machine.”
如果我们按空格分,就得到:
["The", "developer's", "favorite", "machine."]
这里的撇号和句号都还在单词上。但我们也可以根据空格和标点来分:
["The", "developer", "'", "s", "favorite", "machine", "."]
怎么分词,这得看模型。很多高级模型用的方法叫子词分词。就是把单词拆成更小、有意义的部分。比如“It's raining”可以拆成:
["It", "'", "s", "rain", "ing", "."]
这样,“raining”就被拆成了“rain”和“ing”,帮助模型更好地理解单词的结构。通过把单词拆成基本形式和后缀,模型就能更有效地学习单词的意思,而不需要记住每个单词的所有版本。
分词的时候,文本会被扫描,每个标记都会被分配一个在字典里的唯一ID。这样模型处理文本的时候就能快速查字典,让输入更容易理解和处理。
嵌入
分完词之后,下一步就是把这些标记转换成计算机能处理的东西,这就是通过嵌入来完成的。嵌入就是用数字来表示标记(单词或者单词的一部分),这样计算机就能懂了。这些数字帮助模型识别单词之间的关系和上下文。具体参见《LLM向量嵌入知多少》及《大话LLM之向量嵌入》
比如,我们有“happy”和“joyful”这两个词。模型给每个词分配一组数字(它的嵌入),来捕捉它们的意思。如果两个词意思相近,比如“happy”和“joyful”,它们的数字就会很接近,哪怕单词本身不一样。
一开始,模型会给每个标记随机分配数字。但随着模型的训练——通过阅读和学习大量文本——它会调整这些数字。目标就是让意思相近的标记有相近的数字集合,帮助模型理解它们之间的关系。
虽然听起来复杂,嵌入其实就是让模型高效存储和处理信息的数字列表。用这些数字(或向量)让模型更容易理解标记之间的关系。
咱们来看个简单的例子,比如有三个词:“cat”、“dog”和“car”。模型会给每个词分配一组数字,比如:
cat → [1.2, 0.5]
dog → [1.1, 0.6]
car → [4.0, 3.5]
这里,“cat”和“dog”的数字相近,因为它们都是动物,意思相关。而“car”的数字就很不一样,因为它是车,不是动物。
咱们继续聊聊LLMs的训练和微调。
训练和微调
LLMs就是通过读一大堆文本来学习怎么预测句子里的下一个单词。模型的目标就是根据它在文本里看到的各种模式,调整自己的内部设置,让自己预测得更准。一开始,LLMs都是在互联网上的一些通用数据集上训练,比如The Pile或者CommonCrawl,这些数据集里啥都有。如果需要专业知识,模型也可能在一些专注于特定领域的数据集上训练,比如Reddit帖子,这样就能学到一些特定的东西,比如编程。训练的时候还要防止过度或欠缺,可参见: 《谈谈LLM训练中的“过拟合”与“欠拟合”》
这个阶段叫做预训练,就是让模型先学学语言是啥样的。具体参见《深入LLM:指令预训练(Instruction Pretraining LLMs)》。在这个阶段,模型的内部权重(就是它的设置)会被调整,让它能根据训练数据更准确地预测下一个单词。
预训练完了之后,模型一般会进入第二阶段,也就是微调。在这个阶段,模型会在一些更小的、专注于特定任务或领域的数据集上训练,比如医学文本或者财务报告。这样,模型就能把自己在预训练中学到的东西用到特定任务上,比如翻译文本或者回答特定领域的问题。具体参见《一文读懂 LLM 如何进行微调?》。还有一些新的发现,比如:《LLM 直接偏好优化(DPO)的一些研究》、《LLM的指令微调新发现:不掩蔽指令》及《LoRA实现大模型LLM微调研究》等。
对于那些高级的模型,比如GPT-4,微调就需要更复杂的技术和更多的数据才能达到超棒的性能。
预测
训练或微调完了之后,模型就能通过预测句子里的下一个单词(或者更准确地说,下一个标记)来创建文本了。它会分析输入的内容,然后给每个可能的下一个标记打个分,看它出现的可能性有多大。得分最高的标记就会被选中,然后这个过程会一直重复。这样,模型就能生成任意长度的句子了。但别忘了,模型一次只能处理一定量的文本作为输入,这就是它的上下文大小。
上下文大小
上下文大小,或者说上下文窗口,是LLMs的一个关键概念。它指的是模型在一次请求中能处理的最大标记数量。这个决定了模型一次能处理多少信息,也影响着它的性能和输出的质量。详见:《一文了解:LLM 的上下文长度(context length)》
不同的模型有不同的上下文大小。比如,OpenAI的gpt-3.5-turbo-16k模型能处理多达16,000个标记。小一点的模型可能就只能处理1,000个标记,而更大的模型,比如GPT-4-0125-preview,能处理多达128,000个标记。这个限制决定了模型一次能生成多少文本。可参见:《您必须知道的:如何使用 tiktoken 估算 GPT 成本》
扩展法则
扩展法则解释了语言模型的性能是怎么受到不同因素影响的,比如参数的数量、训练数据集的大小、可用的计算能力以及模型的设计。这些法则在《Chinchilla》论文里讨论过,它们帮我们了解怎么最有效地利用资源来训练模型。它们还提供了优化性能的方法。根据扩展法则,以下几个元素决定了语言模型的性能:
-
参数数量(N): 参数就像是模型大脑里的小零件,帮助它学习。当模型读数据的时候,它会调整这些参数,让自己更好地理解模式。参数越多,模型就越聪明,能捕捉到数据中更复杂和详细的模式。详见:《如何进行参数高效微调LLM》
-
训练数据集大小(D): 训练数据集就是模型学习用的文本或数据集合。训练数据集越大,模型能学的就越多,能识别不同文本中的模式。
-
FLOPs(每秒浮点运算次数): 这个术语指的是训练模型需要的计算能力。它衡量模型在训练期间处理数据和执行计算的速度。FLOPs越多,意味着模型能处理更复杂的任务,但也需要更多的计算资源。具体参见《一文读懂:使用混合精度(Mixed-Precision)技术加速LLM》
LLMs中的突现能力
随着LLMs的规模和复杂性的增长,它们开始展现出一些突现能力,这些能力并没有明确地编程到它们中。比如,GPT-4可以总结长文本甚至执行基本的算术运算,而不需要专门为这些任务进行训练。这些能力的出现是因为模型在训练过程中对语言和数据了解得如此之多。
提示
给LLMs提提示,就像是给朋友发消息,告诉它你想要啥。提得越清楚,它回复得就越好。比如:
1. 用清晰明确的语言:
直接点,别绕弯子。
-
太含糊: 给我写点关于阿拉玛·伊克巴尔的东西。
-
够清楚: 来一篇500字的文章,好好介绍介绍次大陆的大诗人阿拉玛·伊克巴尔。
2. 多给点背景:
背景信息多了,模型才知道你真正想要的是什么。
-
没啥背景: 写个故事。
-
背景丰富: 写个短篇故事,讲一个小女孩在森林里迷路了,最后快乐地结束了冒险。
3. 多试几种说法:
换换风格,看看哪种最合适。
-
原话: 写篇博客,说说编程的好处。
-
变体1: 写篇1000字的博客,聊聊定期编程对心理和钱包的好处。
-
变体2: 整一篇吸引人的博客,数数编程的十大好处。
4. 检查一下:
分享之前,别忘了检查一下模型的回复,确保准确无误。
幻觉
幻觉就是模型生成的内容,虽然读起来挺像那么回事,但实际上是错的或者没啥意义。比如,模型可能会说“中国的首都是悉尼”,其实应该是北京。这是因为模型只顾着生成听起来合理的文本,而不管是不是真的。具体参见《白话:大型语言模型中的幻觉(Hallucinations)》
偏见
如果LLMs的训练数据反映了文化、性别或种族上的偏见,那模型的输出也会有偏见。比如,如果模型主要是在西方的英文资料上训练的,那它可能就会偏向西方的观点。虽然大家都在努力减少这些偏见,但它们仍然是这个领域里的一大挑战。可参见:《一文了解:大型语言模型(LLMs)中的偏见、毒性以及破解》