最近我在看论文时,发现很多都在用 Transformer 模型,我知道transformer很有名,但是我也只是听说过他的大名,不知道他具体是做什么怎么做的,因此我决定深入了解一下,并做个简单记录,方便以后参考。  Transformer 主要用于处理自然语言处理(NLP)任务。与之前的循环神经网络(RNN)和长短时记忆网络(LSTM)等模型不同,Transformer 最主要的模块是使用了注意力机制,而不需要顺序地处理数据,也就是说不依赖时间或序列顺序。transformer的核心功能是处理序列数据,就是处理输入的数据和输出的数据之间的关系,像我自己看的那篇论文,是推荐系统方向的,输入的数据是庞大的用户行为数据,经过整个模型处理,输出的数据就是精确的用户可能点击的数据,提高用户可能点击的概率。
Transformer 主要用于处理自然语言处理(NLP)任务。与之前的循环神经网络(RNN)和长短时记忆网络(LSTM)等模型不同,Transformer 最主要的模块是使用了注意力机制,而不需要顺序地处理数据,也就是说不依赖时间或序列顺序。transformer的核心功能是处理序列数据,就是处理输入的数据和输出的数据之间的关系,像我自己看的那篇论文,是推荐系统方向的,输入的数据是庞大的用户行为数据,经过整个模型处理,输出的数据就是精确的用户可能点击的数据,提高用户可能点击的概率。
Transformer 由以下几个部分组成:
- 自注意力机制: 这一机制让模型在处理每个词语时,能够参考序列中的其他所有词。比如在翻译时,句子中的某个词可能会依赖其他几个词,这种机制让模型可以全局地理解上下文,从而捕捉长距离依赖关系,比如在最近很火的gpt文本生成中,一句话中各个单词的远近可能对当前词有影响。
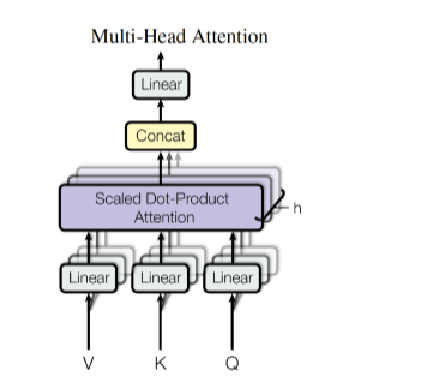
- 多头注意力: 这是对自注意力机制的并行化处理,让模型从不同角度(即多个“头”)来理解输入序列。每个“头”可以独立学习不同的信息关联,进一步提升模型的表达能力,使得它能够捕捉到句子中 不同的部分。
- 位置编码: 由于 Transformer 不是按顺序处理数据的,它通过位置编码引入词语的位置信息,确保模型能理解词与词之间的顺序关系。就像你阅读一句话时,不仅要知道每个词的含义,还要知道它们在句中的顺序,这样才能明白句子的意思。

Transformer的编码器与解码器
在 NLP 任务中,编码器负责将输入数据转化为一种计算机能够看懂的代码,而解码器则根据这个表示生成输出。Transformer 的编码器由 6 层相同的堆栈组成,每层包含两个子层:多头自注意力机制和一个前馈网络。主要是对输入的序列进行编码,提取出表示序列各个部分的向量。
解码器也有类似的结构,但它比编码器多了一个子层,这个额外的子层用来处理编码器的输出。另外,解码器中的自注意力机制经过调整,只允许每个位置关注之前已生成的内容,确保生成顺序合理,输出新的输出序列。
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
Attention(Q,K,V)=softmax(dkQKT)V

在深度学习领域,特别是注意力机制的应用中,点积计算、缩放、softmax变换以及加权求和是实现自注意力或注意力层的核心步骤。通过这些步骤,注意力机制能够有效地捕捉序列数据中的长距离依赖关系,大大增强了模型理解和生成复杂语言结构的能力,是现代自然语言处理模型如Transformer架构中的关键组件。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i … … V ) where head_i = Attention(QW_i^Q,KW_i^K,VW_i……V) whereheadi=Attention(QWiQ,KWiK,VWi……V)
论文接下来详细的介绍了transformer是如何工作的:
第一步:线性变换
对于输入的查询Q、键K和值V,我们使用不同的线性变换矩阵
W
i
Q
、
W
i
K
和
W
i
V
W_i^Q、W_i^K和W_i^V
WiQ、WiK和WiV
,将它们分别隐射到h个不同的子空间。每一个注意力投都有自己专用的一组权重矩阵。
Q
i
=
Q
W
i
Q
,
K
i
=
K
W
i
K
,
V
i
=
V
W
i
V
Q_i=QW_i^Q,K_i=KW_i^K,V_i=VW_i^V
Qi=QWiQ,Ki=KWiK,Vi=VWiV
第二步:独立计算每个注意力投的输出
对于每一个注意力i,计算缩放点积注意力:
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
i
,
K
i
,
V
i
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
i
head_i=Attention(Q_i,K_i,V_i) = softmax(\frac{Q K^{T}}{\sqrt{d_{k}}})V_i
headi=Attention(Qi,Ki,Vi)=softmax(dkQKT)Vi
第三部:连接所有注意力头的输出
将所有注意力头的输出
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
head_1,head_2,...,head_h
head1,head2,...,headh进行拼接(Concat),得到一个大矩阵:
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
)
Concat(head_1,head_2,...,head_h)
Concat(head1,head2,...,headh)
第四步:线性变换输出
对拼接后的结果进行一次线性变换,得到最终的多头注意力输出:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
除了注意力机制,Transformer 的每一层还包含一个前馈网络神经网络,通常由两次线性变换和中间的 ReLU 激活函数组成。
F
F
N
(
x
)
=
m
a
x
(
0
,
s
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0,sW_1+b1)W_2+b_2
FFN(x)=max(0,sW1+b1)W2+b2
多头注意力的计算是将查询、键和值分别线性变换到多个子空间中,然后独立计算每个子空间的注意力分布,最后将所有头的输出拼接起来,进行线性变换,得到最终的结果。这让模型可以并行地关注输入序列中的不同部分,提升了处理能力。
transformer广泛的应用于序列到序列的任务中,具有高效的并行计算能力和捕捉长距离依赖关系的能力。















![[Linux#65][TCP] 详解 延迟应答 | 捎带应答 | 流量控制 | 拥塞控制](https://img-blog.csdnimg.cn/img_convert/7269cc9f9d5459c184e53d77b238c074.png)