文字来源 | 夕小瑶科技说 AI寒武纪
大语言模型(LLM)已经接近人类水平,但视觉理解在世界范围似乎尚未突破,那么为何不能直接将LLM技术用于视觉?让AI看视频的难点在哪?如果语言是AGI必要的能力,为何猫狗、幼儿不会说话似乎也比目前的AI更能理解现实世界?
这些问题非常关键,近日,LeCun 又一次来到 Lex Fridman 的播客,展开了一场接近三个小时的访谈,谈到了这些问题,内容涉及LLM 的局限性、视觉理解与语言理解的区别、通向 AGI 的道路等等,非常精彩。我们精选了一些观点,与大家分享。以下内容受限于篇幅,有删减无修改:
完整视频观看链接:
https://www.youtube.com/watch?v=5t1vTLU7s40
模型没有视觉输入,仅靠语言不会达到AGI
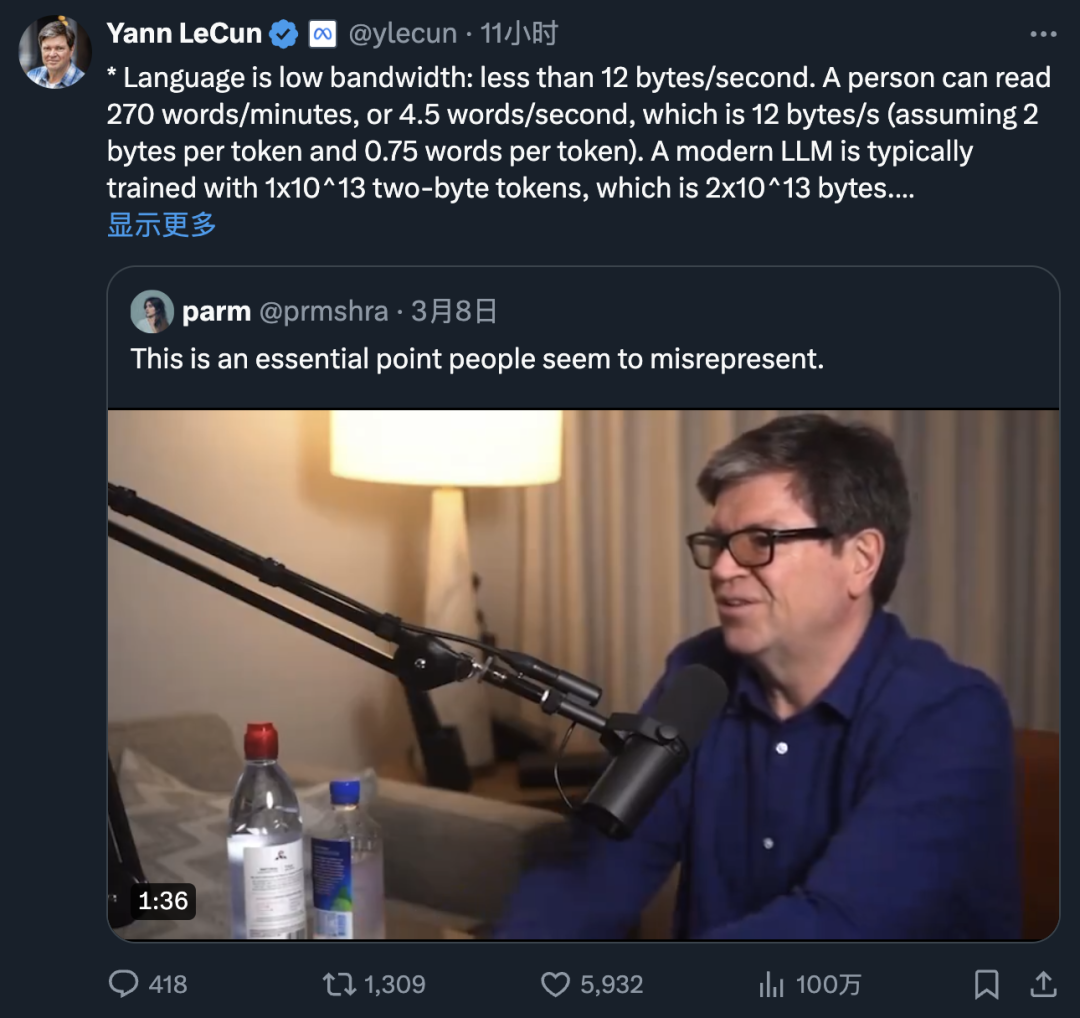
推特原文:https://twitter.com/ylecun/status/1766498677751787723
访谈视频播出后LeCun在推特与网友开展讨论,补充了视觉信息的重要性,要点摘录:
-
语言的信息带宽很低:每秒不到12字节。一个人每分钟可以阅读270个单词,即每秒4.5个单词,这相当于每秒12字节(假设每个Token占用2字节,每个Token对应0.75个单词)。一个现代的大语言模型(LLM)通常使用1x10^13个双字节Token进行训练,这相当于2x10^13字节。这将需要一个人花费大约10万年的时间来阅读(假设每天阅读12小时)
-
视觉的信息带宽要高得多:大约每秒20MB。每条视神经有100万根神经纤维,每根每秒传输大约10字节。一个4岁的孩子总共醒着的时间是16,000小时,这相当于1x10^15字节
-
文本是冗余的,视觉神经中的信号甚至更加冗余(尽管它们是视网膜中感光细胞输出的100倍压缩版本)。但数据中的冗余正是我们所需要的,以便自监督学习(SSL)能够捕捉数据的结构。冗余越多,对SSL越有利
-
大部分人类知识(以及几乎所有动物知识)都来自我们对物理世界的感官体验。语言只是锦上添花。
-
我们绝对没有任何办法在不使机器从高带宽感官输入(如视觉)中学习的情况下达到人类水平的AI。
十年经验谈:视频理解的难点
要点摘录:
Lex Fridman:能否建立一个对世界有深刻理解的模型?
Yann LeCun:能否通过预测来构建它,答案很可能是肯定的。但能通过预测单词来构建它(世界模型)吗?答案很可能是否定的,因为语言在弱带宽或低带宽方面非常贫乏,没有足够的信息。因此,建立世界模型意味着要观察世界,了解世界为什么会以这样的方式演变,然后世界模型的额外组成部分就是能够预测你可能采取的行动会导致世界如何演变。
因此,一个真正的模型是:这是我对 T 时世界状态的想法,这是我可能采取的行动。在 T+1 时间,预测的世界状态是什么?现在,世界的状态并不需要代表世界的一切,它只需要代表与这次行动规划相关的足够多的信息,但不一定是所有的细节。
如果你愿意,可以做视频大模型。在 FAIR,我和我们的一些同事尝试已有 10 年之久,但你无法用与 LLM 相同的技术,因为 LLM,正如我所说,你无法准确预测哪一个单词会跟随一连串单词,但你可以预测单词的分布。现在,如果你去看视频,你要做的就是预测视频中所有可能帧的分布,而我们并不知道如何正确地做到这一点。
我们不知道如何以有用的方式来表示高维连续空间上的分布。这就是主要问题所在,我们之所以能做到这一点,是因为这个世界比文字复杂得多,信息丰富得多。文本是离散的,而视频是高维的、连续的。这里面有很多细节。因此,如果我拍摄了这个房间的视频,视频中的摄像机在四处转动,我根本无法预测在我四处转动时房间里会出现的所有东西。系统也无法预测摄像机转动时房间里会出现什么。也许它能预测到这是一个房间,里面有一盏灯,有一面墙,诸如此类的东西。它无法预测墙壁上的画是什么样子,也无法预测沙发的纹理是什么样子。当然也无法预测地毯的质地。所以我无法预测所有这些细节。
因此,一种可能的处理方法,也是我们一直在研究的方法,就是建立一个拥有所谓潜在变量的模型。潜在变量被输入到神经网络中,它应该代表所有你还没有感知到的关于这个世界的信息,你需要增强系统的预测能力,才能很好地预测像素,包括地毯、沙发和墙上画作的细微纹理。
我们试过直接的神经网络,试过 GAN,试过 VAE,试过各种正则化自动编码器。我们还尝试用这些方法来学习图像或视频的良好表征,然后将其作为图像分类系统等的输入。基本上都失败了。
所有试图从损坏版本的图像或视频中预测缺失部分的系统,基本上都是这样的:获取图像或视频,将其损坏或以某种方式进行转换,然后尝试从损坏版本中重建完整的视频或图像,然后希望系统内部能够开发出良好的图像表征,以便用于物体识别、分割等任何用途。这种方法基本上是完全失败的,而它在文本方面却非常有效。这就是用于 LLM 的原理。
Lex Fridman:失败究竟出在哪里?是很难很好地呈现图像,比如将所有重要信息很好地嵌入图像?是图像与图像、图像与图像之间的一致性形成了视频?如果我们把你所有失败的方式做一个集锦,那会是什么样子?
Yann LeCun:首先,我必须告诉你什么是行不通的,因为还有其他东西是行得通的。所以,行不通的地方就是训练系统学习图像的表征,训练它从损坏的图像中重建出好的图像。
对此,我们有一整套技术,它们都是去噪自编码器的变体,我在 FAIR 的一些同事开发了一种叫做 MAE 的东西,即掩蔽自编码器。因此,它基本上就像 LLM 或类似的东西,你通过破坏文本来训练系统,但你破坏图像,从中删除补丁,然后训练一个巨大的神经网络重建。你得到的特征并不好,而且你也知道它们不好,因为如果你现在训练同样的架构,但你用标签数据、图像的文字描述等对它进行监督训练,你确实能得到很好的表征,在识别任务上的表现比你做这种自监督的再训练要好得多。
结构是好的,编码器的结构也是好的,但事实上,你训练系统重建图像,并不能使它产生良好的图像通用特征。那还有什么选择呢?另一种方法是联合嵌入。
JEPA(联合嵌入预测架构)
Lex Fridman:联合嵌入架构与 LLM 之间的根本区别是什么?JEPA 能带我们进入 AGI 吗?
Yann LeCun:首先,它与 LLM 等生成式架构有什么区别?LLM 或通过重构训练的视觉系统会生成输入。它们生成的原始输入是未损坏、未转换的,因此你必须预测所有像素,而系统需要花费大量资源来实际预测所有像素和所有细节。而在 JEPA 中,你不需要预测所有像素,你只需要预测输入的抽象表示。这在很多方面都要容易得多。因此,JEPA 系统在训练时,要做的就是从输入中提取尽可能多的信息,但只提取相对容易预测的信息。世界上有很多事情是我们无法预测的。树上的叶子会以一种你无法预测的方式移动,而你并不关心,也不想预测。因此,你希望编码器基本上能消除所有这些细节。它会告诉你树叶在动,但不会告诉你具体发生了什么。因此,当你在表示空间中进行预测时,你不必预测每片树叶的每个像素。这样不仅简单得多,而且还能让系统从本质上学习到世界的抽象表征,其中可以建模和预测的内容被保留下来,其余的则被编码器视为噪音并消除掉。
Lex Fridman:你是说语言,我们懒得用语言,因为我们已经免费得到了抽象的表述,而现在我们必须放大,真正思考一般的智能系统。我们必须处理一塌糊涂的物理现实和现实。而你确实必须这样做,从完整、丰富、详尽的现实跳转到基于你所能推理的现实的抽象表征,以及所有诸如此类的东西。
Yann LeCun:没错。那些通过预测来学习的自监督算法,即使是在表征空间中,如果输入数据的冗余度越高,它们学习到的概念也就越多。数据的冗余度越高,它们就越能捕捉到数据的内部结构。因此,在知觉、视觉等感官输入中,冗余结构要比文本中的冗余结构多得多。语言可能真的代表了更多的信息,因为它已经被压缩了。你说得没错,但这也意味着它的冗余度更低,因此自监督的效果就不会那么好。
Lex Fridman:有没有可能将视觉数据的自监督训练与语言数据的自监督训练结合起来?尽管你说的是 10 到 13 个 token,但其中蕴含着大量的知识。这 10 到 13 个 token 代表了我们人类已经弄明白的全部内容,包括 Reddit 上的废话、所有书籍和文章的内容以及人类智力创造的全部内容。
Yann LeCun:嗯,最终是的。但我认为,如果我们太早这样做,就有可能被诱导作弊。而事实上,这正是目前人们在视觉语言模型上所做的。我们基本上是在作弊,在用语言作为拐杖,帮助我们克服视觉系统的缺陷从图像和视频中学习良好的表征。
这样做的问题是,我们可以通过向语言模型提供图像来改进它们,但我们甚至无法达到猫或狗的智力水平或对世界的理解水平,因为它们没有语言。它们没有语言,但对世界的理解却比任何 LLM 都要好得多。它们可以计划非常复杂的行动,并想象一系列行动的结果。在将其与语言结合之前,我们如何让机器学会这些?显然,如果我们将其与语言相结合,会取得成果,但在此之前,我们必须专注于如何让系统学习世界是如何运作的。
结语
我们做视频理解多年,对LeCun谈到的难点有深刻体会,也非常赞同视觉等高维信息对于AI理解世界是至关重要的,这也许就是通向AGI的道路。不过,2024年2月19日,”人工智能教父“ Geoffrey Hinton在牛津大学的公开演讲上, 强调LLM具备真正的理解能力。