用户到底为什么而买单/产品和研发要抛弃的历史包袱

在大模型时代之前,其实企业和企业之间的软件产品壁垒来自两个地方:
交互,让用户用起来感觉舒服。
打磨,我花了五年修复了用户遇到的一万个bug,所以我的产品比你好。
但是无论如何,你很难构建技术壁垒。非你加产品不可的情况几乎只是梦里的事情。但是大模型时代的应用产品,是可以做到的,效果好到用户压根离不开,其他企业则可能和你至少有三个月或者半年的差距,用户别无选择。
所以产品不要只想着交互,研发不要只想着所谓打磨,有非常多的机会你可以做出别人做不出的效果,而效果在AI时代,才是让用户 wow 的东西。
什么叫 llm-native 应用

llm-native,就是充分挖掘大模型的,以大模型为全流程驱动,就像当年数据库之于web。
应用到底能不能做厚

很多人看到我这句话,其实并没有理解这句话的含义。inference scaling 是应用层继续做厚的起点,同样的模型,可能最终效果差异会很大。这在之前是不太现实的。现在对大模型应用就是“包了Prompt 的代码” 想法的人还大有人在,在之前确实你很难做出差异,但是现在可以了。inference scaling就是天然留给应用层的模型扩展点。
推理到底是变快了还是变慢了
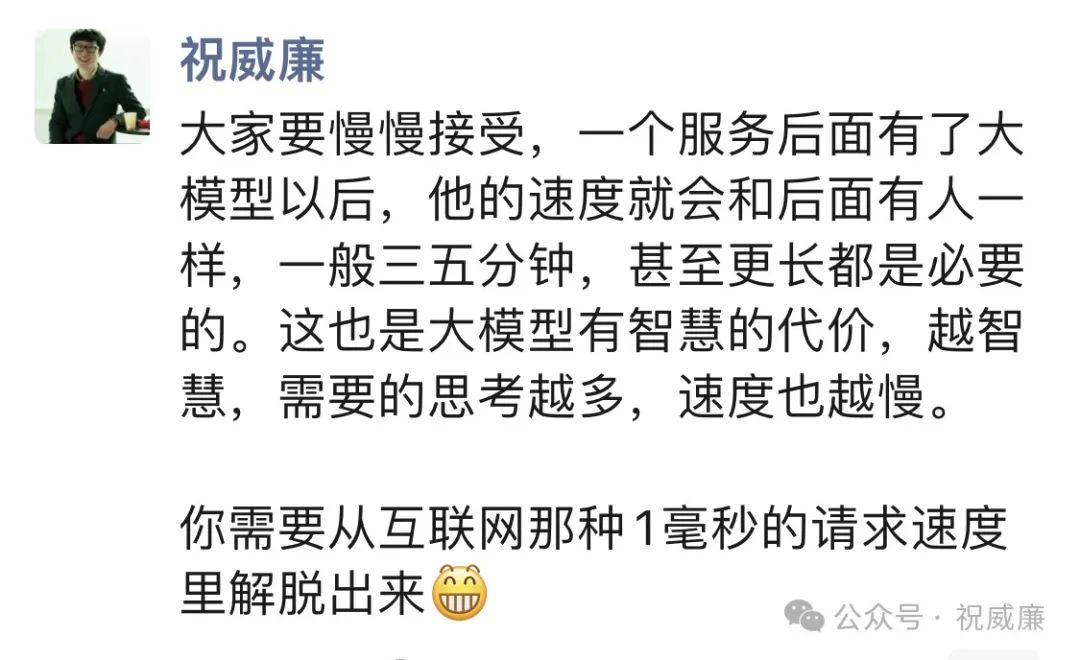
很多人无法理解这句话,无论硬件还是推理软件都是越来越快的牙。
推理提升的速度一定架不住需求的复杂度上升 需要有这个认知 这事就通了。所谓需求,实际上是用户需要更大的输入,更好的输出效果,要达成这个目标,目前要么继续加大参数,要么在推理时消耗更多token(更多思考),这些会进一步增加了窗口大小,显存使用以及计算量。需求永远都是比现有效果要高很多的,所以虽然推理的速度在提升,但提升速度会远不如人们对效果的需求,这种失衡的结果就是,大家感觉有大模型的应用越来越慢了。