1.项目目标
1.1 需求概述
现在我们要统计某学校学生的成绩信息,筛选出成绩在60分及以上的学生。
1.2 业务分析
如果我们想实现该需求,可以通过编写一个MapReduce程序,来处理包含学生信息的文本文件,每行包含【学生的姓名,科目,分数】,以逗号分隔,要求如下:
分别编写一个Student类和一个Mapper类;
Student 类包含以下字段:姓名(String)、科目(String)、分数(int);
需要自定义 Student 对象的序列化和反序列化方法,以便Hadoop能够正确处理它;
Mapper类将输入文本数据解析为 Student 对象,并且只输出成绩大于60分的学生;
以固定字符串"学生信息"为Key,Student对象为Value,作为该Mapper的输出。
2. 新建项目
如果没有进行配置项目,则需要先进行配置,可以参考下文的前半部分:
大数据处理从零开始————8.基于Java构建WordCount项目-CSDN博客
如果配置好就可以直接进行下一步。新建项目后,确定好项目的名称,组ID,工作ID的信息。
打开pom.xml文件,添加项目配置,添加如下配置。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<!--<scope>test</scope>-->
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
</dependencies>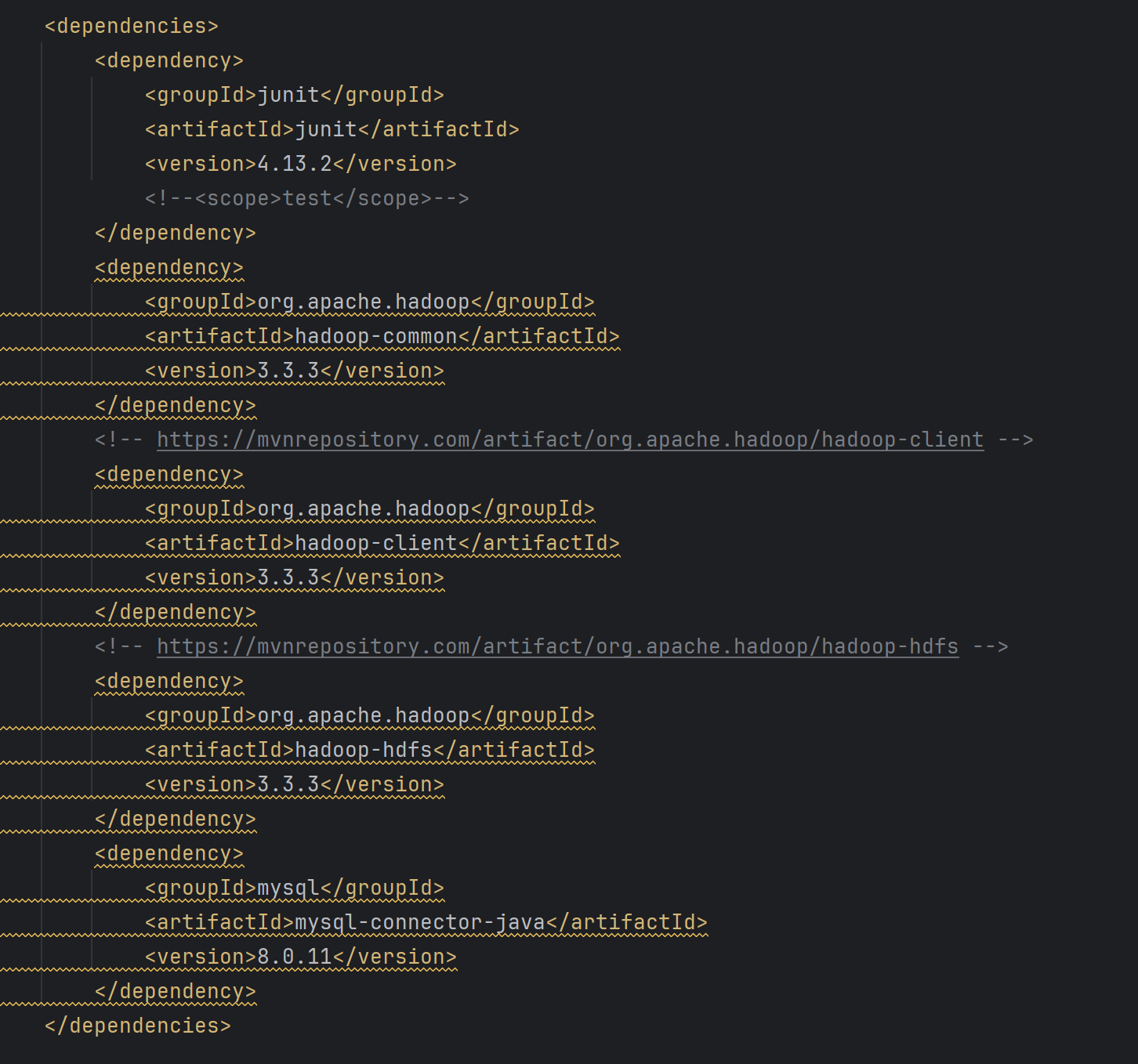
如果pom.xml全部标红可以看上一节解决方法,完全相同。
3.完善项目代码
3.1 创建Student类
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements Writable {
private String name;
private String subject;
private int score;
public Student() {
}
public Student(String name, String subject, int score) {
this.name = name;
this.subject = subject;
this.score = score;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeUTF(subject);
out.writeInt(score);
}
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
subject = in.readUTF();
score = in.readInt();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "姓名:" + name + ", 科目:" + subject + ", 分数:" + score;
}
}在这里可能由很多人不明白,我们来解释一下这段代码的关键点:
首先它实现了Writable接口,Writable接口主要实现了序列化和反序列化。Writable接口定义了两个方法。1. void write(DataOutput out):主要用于将对象的字段写入数据输入流DataOutput中;在实现此方法时,需要按照某种顺序依次写入对象的所有属性,确保与readFields方法对应。2.void readfields(DataInput in):该方法用于从数据输入流 DataInput 中读取对象的字段;按照与 write 方法相同的顺序读取,确保数据能正确映射回对象的属性。
其次重写了toString方法。

3.2 实现Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class StudentMapper extends Mapper<LongWritable, Text, Text, Student> {
private static final Text outputKey = new Text("学生信息");
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 解析每行文本
String line = value.toString();
String[] fields = line.split(",");
// 创建Student对象
if (fields.length == 3) {
String name = fields[0].trim();
String subject = fields[1].trim();
int score = Integer.parseInt(fields[2].trim());
// 只输出成绩大于60分的学生
if (score > 60) {
Student student = new Student(name, subject, score);
context.write(outputKey, student);
}
}
}
}首先通过泛型确保了输入形式是key——value的形式。
然后创建了一个名为 outputKey 的常量,它代表输出的键,值为 "学生信息"。这个常量在整个类中是共享的,避免了在每次调用 map 方法时重复创建。
接着实现了map方法,在map方法中先将输入值逐行改成字符串数组形式;然后检查字段数组是否为三,确保数组行格式正确,接着分别提取姓名、科目和分数,并进行适当的修剪以去除多余的空格,进一步使用 Integer.parseInt() 方法将分数字符串转换为整数;最后输出大于60分的人。

3.3 构建驱动器StudentDriver类
在构建完map类后,程序并不能直接运行,因此我们还要构建一个Driver类来驱动程序。Driver类是一个 Hadoop MapReduce 程序的驱动程序,负责设置作业的配置并启动 MapReduce 任务。
import org.apache.hadoop.conf.Configuration; // 导入 Hadoop 配置类
import org.apache.hadoop.fs.Path; // 导入路径类,用于文件路径处理
import org.apache.hadoop.io.Text; // 导入 Text 类,表示字符串形式的键
import org.apache.hadoop.mapreduce.Job; // 导入 Job 类,用于定义一个 MapReduce 作业
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; // 导入输入格式类
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; // 导入输出格式类
public class StudentDriver {
public static void main(String[] args) throws Exception {
// 检查命令行参数数量,要求输入两个参数
if (args.length != 2) {
System.err.println("Usage: StudentDriver <input path> <output path>");
System.exit(-1); // 如果参数数量不对,打印用法并退出
}
// 创建 Hadoop 配置对象
Configuration conf = new Configuration();
// 创建一个新的 Job 实例,作业名称为 "Student Info Filter"
Job job = Job.getInstance(conf, "Student Info Filter");
// 设置程序的 Jar 文件位置
job.setJarByClass(StudentDriver.class);
// 设置使用的 Mapper 类
job.setMapperClass(StudentMapper.class);
// 设置 Mapper 的输出键值类型
job.setMapOutputKeyClass(Text.class); // 输出键的类型为 Text
job.setMapOutputValueClass(Student.class); // 输出值的类型为 Student(自定义类型)
// 设置最终输出的键值类型
job.setOutputKeyClass(Text.class); // 输出键的类型为 Text
job.setOutputValueClass(Student.class); // 输出值的类型为 Student
// 设置输入和输出路径
FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出路径
// 提交作业,并根据完成情况退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}详细解释看代码注释。

4.运行程序
首先给程序打包。

然后给程序重命名。

接着上传到hadoop中。

启动hadoop,并将程序上传到hadoop中。
./myhadoop.sh start 启动hadoop
cd /user/local/data #转到文件夹下
ll #查看是否上传成功
vim student #创立测试文件
hdfs dfs -put student /cs #将student上传到/cs中注意:我这里有cs,如果没有的话,应该先用下面命令创建/cs
hdfs dfs mkdir /cs #在hadoop下创建一个cs文件。

运行jar包:hadoop jar map.jar com.jyd.StudentDriver /cs /ssoutput

查看结果: hdfs dfs -cat /ssoutput/part-r-00000