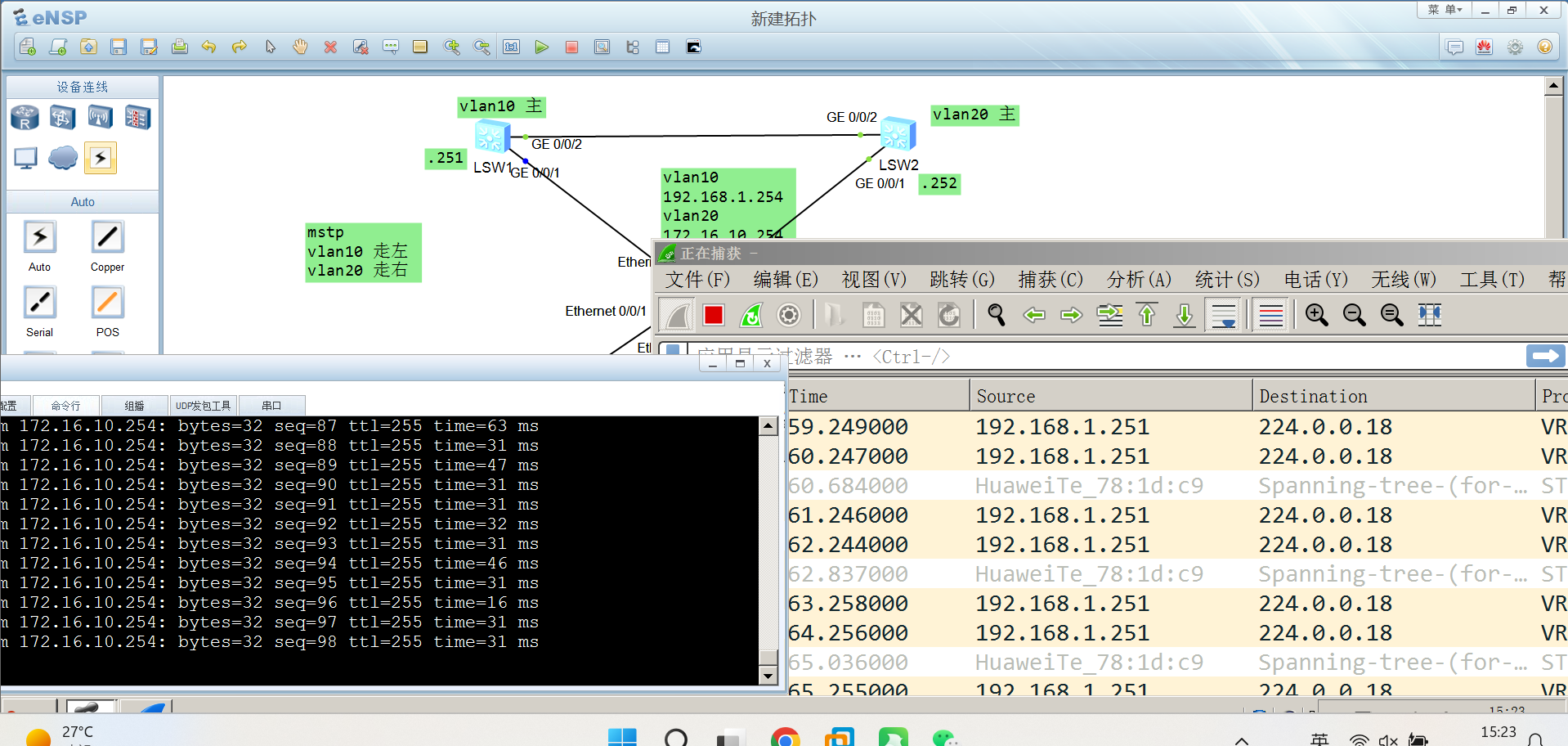
IJCAI24
推荐指数: #paper/⭐⭐⭐
领域:图增强+强化学习
胡言乱语:
不愧是清华组的论文,这个实验的目的是利用强化学习去生成对比学习的增强视图。但是,其仍然有一些小问题:其本质实际是对以往的图增强方法套了一层强化学习的壳(因此好像也没有获得oral或者spotlight),个人觉得提升应该不明显。但是明显是一个有趣的方向
个人觉得可以继续做的方向:
- 大图+强化学习自增强视图。实际上,理论上应该为每个sample子图自适应生成视图(由于大图的每个子领域的多样性,理论上适用的增强也不同)。因此,在大图上为每个子图分配自适应相应的增强视图
-
- 其结合之前的一篇偏理论分析的文章–Perfect Alignment May be Poisonous to Graph Contrastive Learning会更好。这篇文章探讨了什么样的图增强和增强后的结果相关。个人觉得改文章提出的策略可以自适应的生成增强图
-
- 当然,1和2结合起来会更好(其实对neurips的一篇偏理论文章很感兴趣,但是没有会员资格,提前看不了,有大佬可以提前帮忙下载一篇不)
-
问题背景
-
1.什么样的视图是好视图?
- 良好的增强视图如何变化以提升GCL的性能?我们认为,一个好的增强视图应该保持渐进进化的特征,类似于人类认知中的逐步学习进展,当连续几天学到的东西之间存在联系时,更容易理解和接受新信息。言而总之 会学习的视图是好视图
-
2.保存更好的原始图图结构信息
- 在特定的图结构中,边沿删除或者节点删除损坏图结构信息。一些GCL使用无需增强的方法例如编码器perturbation去处理这个问题。但是,扰乱率有很难确定。那么,是否有一种方案在不干扰编码器的情况下去保留原始图的基本结构信息?
-
解决方法:
10.1. 我们提出动态调整GDA的参数,去自适应学习好视图
10. 我们学习到加权边来构造新视图,而无需删除节点或者边,属性
11.### 但是随之面临的挑战:
11. 现有的图强化学习不适合GDA
12.2. 如何基于图环境设计有效的激活函数仍不确定
贡献:
- 我们提出了GRA框架,这是GCL的一种新型GDA,基于强化学习。该框架为GDA制定了马尔科夫决策过程,并保留了原始的图结构信息
-
- 我们设计GA 2C模型作为GRA框架的实例,以实现连续且可学习的图数据增强
-
整体框架
-
冻结GDA参数的GCL框架

- 如图可见,其主要方法就是学习到一个增强视图A来作为对比学习的增强视图。本方法的视图增强部分便以此为参考:
-
我们的GRA框架

-
GRA 框架
10.### Min-max对比学习损失优化以及积累回报函数
min
ϕ
,
φ
L
N
C
E
(
g
φ
(
f
ϕ
(
f
ϕ
(
G
i
)
)
,
g
φ
(
f
ϕ
(
A
ω
~
i
∗
(
G
i
)
)
)
)
s.t.
ω
~
i
∗
=
arg
max
ω
~
i
R
(
ω
~
i
)
.
\min_{\boldsymbol{\phi},\boldsymbol{\varphi}}\mathcal{L}_{\mathbf{NCE}}(g_{\boldsymbol{\varphi}}(f_{\boldsymbol{\phi}}(f_{\boldsymbol{\phi}}(\mathcal{G}_{i})),\:g_{\boldsymbol{\varphi}}(f_{\boldsymbol{\phi}}(A_{\tilde{\boldsymbol{\omega}}_{i}^{*}}(\mathcal{G}_{i}))))\\\text{s.t. }\tilde{\boldsymbol{\omega}}_{i}^{*}=\arg\max_{\tilde{\boldsymbol{\omega}}_{i}}R(\tilde{\boldsymbol{\omega}}_{i}).
ϕ,φminLNCE(gφ(fϕ(fϕ(Gi)),gφ(fϕ(Aω~i∗(Gi))))s.t. ω~i∗=argω~imaxR(ω~i).
GDA的马尔科夫决策:
(这部分需要强化学习相关知识,看莫凡的课程就可以了地址链接
P
(
G
~
i
(
t
+
1
)
∣
G
~
i
(
t
)
)
=
P
(
G
~
i
(
t
+
1
)
∣
G
~
i
(
1
)
,
⋯
,
G
~
i
(
t
)
)
.
\mathbb{P}(\tilde{\mathcal{G}}_i^{(t+1)}|\tilde{\mathcal{G}}_i^{(t)})=\mathbb{P}(\tilde{\mathcal{G}}_i^{(t+1)}|\tilde{\mathcal{G}}_i^{(1)},\cdots,\tilde{\mathcal{G}}_i^{(t)}).
P(G~i(t+1)∣G~i(t))=P(G~i(t+1)∣G~i(1),⋯,G~i(t)).
GDA的马尔科夫决策可以被三元组定义为:
(
S
s
t
a
t
e
,
S
a
c
t
i
o
n
,
R
^
)
(\mathcal{S}_{\mathrm{state}},\mathcal{S}_{\mathrm{action}},\hat{R})
(Sstate,Saction,R^)
我们可以设计奖励函数为:
R
(
t
)
=
−
I
(
Z
i
(
t
)
,
Z
~
i
(
t
)
)
,
Z
i
(
t
)
=
g
φ
(
f
ϕ
(
G
i
(
t
)
)
)
,
Z
~
i
(
t
)
=
g
φ
(
f
ϕ
(
G
~
i
(
t
)
)
)
.
R^{(t)}=-\mathcal{I}(Z_i^{(t)},\tilde{Z}_i^{(t)}),\\\boldsymbol{Z}_i^{(t)}=g_{\boldsymbol{\varphi}}(f_{\boldsymbol{\phi}}(\mathcal{G}_i^{(t)})),\quad\tilde{\boldsymbol{Z}}_i^{(t)}=g_{\boldsymbol{\varphi}}(f_{\boldsymbol{\phi}}(\tilde{\mathcal{G}}_i^{(t)})).
R(t)=−I(Zi(t),Z~i(t)),Zi(t)=gφ(fϕ(Gi(t))),Z~i(t)=gφ(fϕ(G~i(t))).
保存图结构信息通过图重新加权
假设原始的图权重矩阵为
E
G
i
∈
R
N
i
×
N
i
\boldsymbol{E}_{\mathcal{G}_i}{\in}\mathbb{R}^{N_i\times N_i}
EGi∈RNi×Ni
增强视图就为:
A
u
g
E
R
W
:
E
G
i
↦
E
G
i
∘
ω
~
i
(
t
)
,
\mathrm{Aug}_{\mathrm{ERW}}:\boldsymbol{E}_{\mathcal{G}_i}\mapsto\boldsymbol{E}_{\mathcal{G}_i}\circ\tilde{\boldsymbol{\omega}}_i^{(t)},
AugERW:EGi↦EGi∘ω~i(t),
w
w
w即为加权矩阵。当t=0时,
w
w
w为全一矩阵
举个例子,
[
[
1.0
,
0.6
,
0.8
]
T
,
[
0.6
,
1.0
,
0
]
T
,
[
0.8
,
0.0
,
1.0
]
T
]
[[1.0,0.6,0.8]^\mathrm{T},[0.6,1.0,0]^\mathrm{T},[0.8,0.0,1.0]^\mathrm{T}]
[[1.0,0.6,0.8]T,[0.6,1.0,0]T,[0.8,0.0,1.0]T] 即代表(v1,v2)的权重为0.6,(v1,v3)代表权重为0.8
GA2C model

那么,显然就有一个问题,是我们如何获得权重矩阵,以及加权后的特征
ω
~
i
(
t
+
1
)
=
Sigmoid
(
Reshape
(
H
i
(
t
)
)
)
,
H
i
(
t
)
=
BN
(
C
C
(
R
D
(
{
h
v
,
k
(
t
)
∣
v
∈
G
~
i
(
t
)
}
)
∣
k
=
1
,
⋯
,
K
)
)
,
h
v
,
k
(
t
)
=
MLP
θ
A
(
∑
u
∈
N
i
(
v
)
∪
{
v
}
[
ω
~
i
(
t
)
]
v
,
u
⋅
h
u
,
k
−
1
(
t
)
d
(
v
)
⋅
d
(
u
)
)
,
\begin{aligned}&\tilde{\boldsymbol{\omega}}_i^{(t+1)}=&\text{Sigmoid}(\text{Reshape}(\boldsymbol{H}_i^{(t)})),\\&\boldsymbol{H}_i^{(t)}=&\text{BN}(\mathrm{CC}(\mathrm{RD}(\left\{\boldsymbol{h}_{v,k}^{(t)}|v{\in}\tilde{\mathcal{G}}_i^{(t)}\right\})|k{=}1,\cdots,K)),\\&\boldsymbol{h}_{v,k}^{(t)}=&\text{MLP}_{\theta_A}(\sum_{u\in\mathcal{N}_i(v)\cup\{v\}}\frac{[\tilde{\boldsymbol{\omega}}_i^{(t)}]_{v,u}\cdot\boldsymbol{h}_{u,k-1}^{(t)}}{d(v)\cdot d(u)}),\end{aligned}
ω~i(t+1)=Hi(t)=hv,k(t)=Sigmoid(Reshape(Hi(t))),BN(CC(RD({hv,k(t)∣v∈G~i(t)})∣k=1,⋯,K)),MLPθA(u∈Ni(v)∪{v}∑d(v)⋅d(u)[ω~i(t)]v,u⋅hu,k−1(t)),
如图,权重矩阵是通过特征
H
H
H通过reshape变为的。sigmoid是sigmoid激活函数。得到权重矩阵后,RD是readout函数。CC是拼接层(将1-k层的特征嵌入拼接起来)。BN是batch normalization layer。最后,通过低k层的加权聚合函数,得到嵌入h。
如下的细节:
- h v , k ( 0 ) = [ X G i ] v h_{v, k}^{(0)} = \left[ X_{\mathcal{G}_{i}} \right]_{v} hv,k(0)=[XGi]v
-
- GDA参数矩阵 ω ~ i ( t + 1 ) \tilde{\omega}_i^{(t+1)} ω~i(t+1)由 G ~ i ( t ) \tilde{\mathcal{G}}_i^{(t)} G~i(t)得到
-
新视图的生成(相当于DQB的Action函数)
- G ~ i ( t + 1 ) = A ω ~ i ( t + 1 ) ( G i ( t ) ) \tilde{\mathcal{G}}_i^{(t+1)}=A_{\tilde{\boldsymbol{\omega}}_i^{(t+1)}}(\mathcal{G}_i^{(t)}) G~i(t+1)=Aω~i(t+1)(Gi(t))
- A即Actor的A。
-
评估子模型的结构 (相当于期待的输出,有点类似于Q函数)
- V是评估重写参数矩阵的Value(价值)
- 评估子模型评估 V ~ i ( t + 1 ) \tilde{V}_i^{(t+1)} V~i(t+1)依据关于 G ~ i ( t + 1 ) \tilde{\mathcal{G}}_i^{(t+1)} G~i(t+1)的边权重信息
-
V
~
i
(
t
)
=
Reshape
(
M
i
(
t
)
)
,
M
i
(
t
)
=
BN
(
C
C
(
R
D
(
{
m
v
,
k
(
t
)
∣
v
∈
G
~
i
(
t
)
}
)
∣
k
=
1
,
⋯
,
K
)
)
m
v
,
k
(
t
)
=
MLP
θ
C
k
(
∑
u
∈
N
i
(
v
)
∪
{
v
}
[
ω
~
i
(
t
)
]
v
,
u
⋅
m
u
,
k
−
1
(
t
)
d
(
v
)
⋅
d
(
u
)
)
,
\begin{aligned}&\tilde{V}_i^{(t)}=\text{Reshape}(\boldsymbol{M}_i^{(t)}),\\&\boldsymbol{M}_i^{(t)}=\text{BN}(\mathrm{CC}(\mathrm{RD}(\left\{\boldsymbol{m}_{v,k}^{(t)}|v{\in}\tilde{\mathcal{G}}_i^{(t)}\right\})|k{=}1,\cdots,K))\\&\boldsymbol{m}_{v,k}^{(t)}=\text{MLP}_{\theta_C}^k(\sum_{u\in\mathcal{N}_i(v)\cup\{v\}}\frac{[\tilde{\boldsymbol{\omega}}_i^{(t)}]_{v,u}\cdot\boldsymbol{m}_{u,k-1}^{(t)}}{d(v)\cdot d(u)}),\end{aligned}
V~i(t)=Reshape(Mi(t)),Mi(t)=BN(CC(RD({mv,k(t)∣v∈G~i(t)})∣k=1,⋯,K))mv,k(t)=MLPθCk(u∈Ni(v)∪{v}∑d(v)⋅d(u)[ω~i(t)]v,u⋅mu,k−1(t)),
10.### 我们可以更新如下:
我们因此可以评价A(advantage-value函数)
A ~ i ( t ) = Q ~ i ( t ) − V ~ i ( t ) = R ( t + 1 ) + γ V ~ i ( t + 1 ) − V ~ i ( t ) , \tilde{A}_i^{(t)}{=}\tilde{Q}_i^{(t)}-\tilde{V}_i^{(t)}{=}R^{(t+1)}+\gamma\tilde{V}_i^{(t+1)}-\tilde{V}_i^{(t)}, A~i(t)=Q~i(t)−V~i(t)=R(t+1)+γV~i(t+1)−V~i(t),
如上,A表示通过动作的实际输出(Q)与期待输出(V)之间的差异。上述部分就是标准的强化学习步骤,如下作者重写了部分。
更新critic
优化目标位最大化:
J
C
=
∑
t
=
1
T
(
A
~
i
(
t
)
)
2
\mathcal{J}_C=\sum_{t=1}^T(\tilde{A}_i^{(t)})^2
JC=t=1∑T(A~i(t))2
梯度被重写为:
∇
θ
C
J
C
=
d
d
θ
C
∑
t
=
1
T
(
A
~
i
(
t
)
)
2
,
\nabla_{\theta_C}\mathcal{J}_C=\frac d{d\theta_C}\sum_{t=1}^T(\tilde{A}_i^{(t)})^2,
∇θCJC=dθCdt=1∑T(A~i(t))2,
Actor的更新
(其就相当于Qlearning的
Q
~
i
(
t
)
\tilde{Q}_i^{(t)}
Q~i(t))
优化目标为:最大化:
J
A
=
∑
t
=
1
T
l
o
g
π
i
(
ω
~
i
(
t
+
1
)
∣
G
~
i
(
t
)
)
⋅
A
~
i
(
t
)
\mathcal{J}_{A}=\sum_{t=1}^{T}\mathrm{log}\pi_{i}(\tilde{\omega}_{i}^{(t+1)}|\tilde{\mathcal{G}}_{i}^{(t)})\cdotp\tilde{\boldsymbol{A}}_{i}^{(t)}
JA=t=1∑Tlogπi(ω~i(t+1)∣G~i(t))⋅A~i(t)
梯度被重写为:
∇
θ
A
J
A
=
∑
t
=
1
T
d
log
π
i
(
ω
~
i
(
t
+
1
)
∣
G
~
i
(
t
)
)
d
θ
A
⋅
A
~
i
(
t
)
,
\nabla_{\theta_A}\mathcal{J}_A=\sum_{t=1}^T\frac{d\text{log}\pi_i(\tilde{\boldsymbol{\omega}}_i^{(t+1)}|\tilde{\mathcal{G}}_i^{(t)})}{d\theta_A}\cdotp\tilde{\boldsymbol{A}}_i^{(t)},
∇θAJA=t=1∑TdθAdlogπi(ω~i(t+1)∣G~i(t))⋅A~i(t),
结果