金融领域交互式自证业务中涵盖信用成长、用户开户、商家入驻、职业认证、商户解限等多种应用场景,通常都需要用户提交一定的材料(即凭证)用于证明资产收入信息、身份信息、所有权信息、交易信息、资质信息等,而凭证的真实性一直是困扰金融场景自动化审核的一大难题。随着数字媒体编辑技术的发展,越来越多的AI手段和工具能够轻易对凭证材料进行篡改,大量的黑产团伙也逐渐掌握PS、AIGC等工具制作逼真的凭证样本,并对金融审核带来巨大挑战。
为此,开设AI核身-金融凭证篡改检测赛道。将会发布大规模的凭证篡改数据集,参赛队伍在给定的大规模篡改数据集上进行模型研发,同时给出对应的测试集用于评估算法模型的有效性。
- 赛事地址: https://tianchi.aliyun.com/competition/entrance/532267/introduction
在本任务中,要求参赛者设计算法,找出凭证图像中的被篡改的区域。
数据集
本次比赛将发布超大规模自研光鉴凭证数据集,该数据集整合了大量开源的图像数据和内部的业务数据。数据的构建方式为在原始图像数据上针对文字区域采用copy move,splicing,removal,局部AIGC等方式进行数字篡改编辑。
模型的泛化性也将是此次比赛重要的衡量指标,因此本次的测试集将比训练集包含更多的凭证类型和篡改编辑手法。
数据集格式如下:
- 训练集数据总量为100w,提供篡改后的凭证图像及其对应的篡改位置标注,标注文件以csv格式给出,csv文件中包括两列,内容示例如下:
| Path | Polygon |
|---|---|
| 9/9082eccbddd7077bc8288bdd7773d464.jpg | [[[143, 359], [432, 359], [437, 423], [141, 427]]] |
- 测试集分为A榜和B榜,分别包含10w测试数据。测试集中数据格式与训练集中一致,但不包含标注文件。
评价指标
采用Micro-F1作为评价指标,该分数越高表示排名越靠前。每个选手提交的文件中都包含了id和对应的region,我们的评分规则是基于这两个字段进行计算的。首先,我们会判断选手提交结果中的id是否和标签一致,请避免出现遗漏或者溢出,其次,会将选手的提交结果中每个id的region字段与真实标签进行比对和重叠度计算,再结合阈值统计出选手的TP(True Positive)、TN(True Negative)、FP(False Positive)和FN(False Negative)。
P micro = ∑ i = 1 n T P i ∑ i = 1 n T P i + ∑ i = 1 n F P i P_{\text{micro}} = \frac{\sum_{i=1}^{n}TP_{i}}{\sum_{i=1}^{n}TP_{i} + \sum_{i=1}^{n}FP_{i}} Pmicro=∑i=1nTPi+∑i=1nFPi∑i=1nTPi
R micro = ∑ i = 1 n T P i ∑ i = 1 n T P i + ∑ i = 1 n F N i R_{\text{micro}} = \frac{\sum_{i=1}^{n}TP_{i}}{\sum_{i=1}^{n}TP_{i} + \sum_{i=1}^{n}FN_{i}} Rmicro=∑i=1nTPi+∑i=1nFNi∑i=1nTPi
接着,会计算出选手的准确率P(Precision)和召回率R(Recall)。准确率是指选手正确预测出正例的比例,召回率是指选手正确预测出所有正例的能力。最后,我们将综合考虑各个类别的表现并打分,打分评价指标使用微平均Micro-F1。计算公式如下:
F 1 micro = 2 ⋅ P micro ⋅ R micro P micro + R micro F_{1_{\text{micro}}} = \frac{2 \cdot P_{\text{micro}} \cdot R_{\text{micro}}}{P_{\text{micro}} + R_{\text{micro}}} F1micro=Pmicro+Rmicro2⋅Pmicro⋅Rmicro
Baseline
赛题是一个典型的计算机视觉问题,涉及到图像处理和模式识别。赛题需要识别和定位图像中被篡改的区域。
- 物体检测模型:可以将篡改区域视为需要检测的“物体”。使用像Faster R-CNN或YOLO这样的物体检测模型,可以定位图像中的不同区域,并判断这些区域是否被篡改。
- 语义分割模型:语义分割模型可以将图像中的每个像素分配给一个类别,这可以用来识别图像中的篡改区域。U-Net、DeepLab或Mask R-CNN是常用的语义分割模型。


本任务也可以基于检测模型微调,同时允许使用基于大模型的方案等。方案不限于:
- 小模型微调(例如Faster R-CNN、ConvNeXt(Base)+UPerHead、SegNeXt、VAN(B5)+UPerHead等);
- 使用大模型(例如SAM、Grounded-SAM等);
- 多模型协同等。
鼓励选手设计全新的思路完成本任务。注意禁止使用私有数据集进行训练。
下面给出一个基于SwinTransformer (Large) + Cascade R-CNN的实验结果:
| Precision | Recall | F1 score |
|---|---|---|
| 89.3718 | 57.0489 | 69.6426 |
Baseline 实践
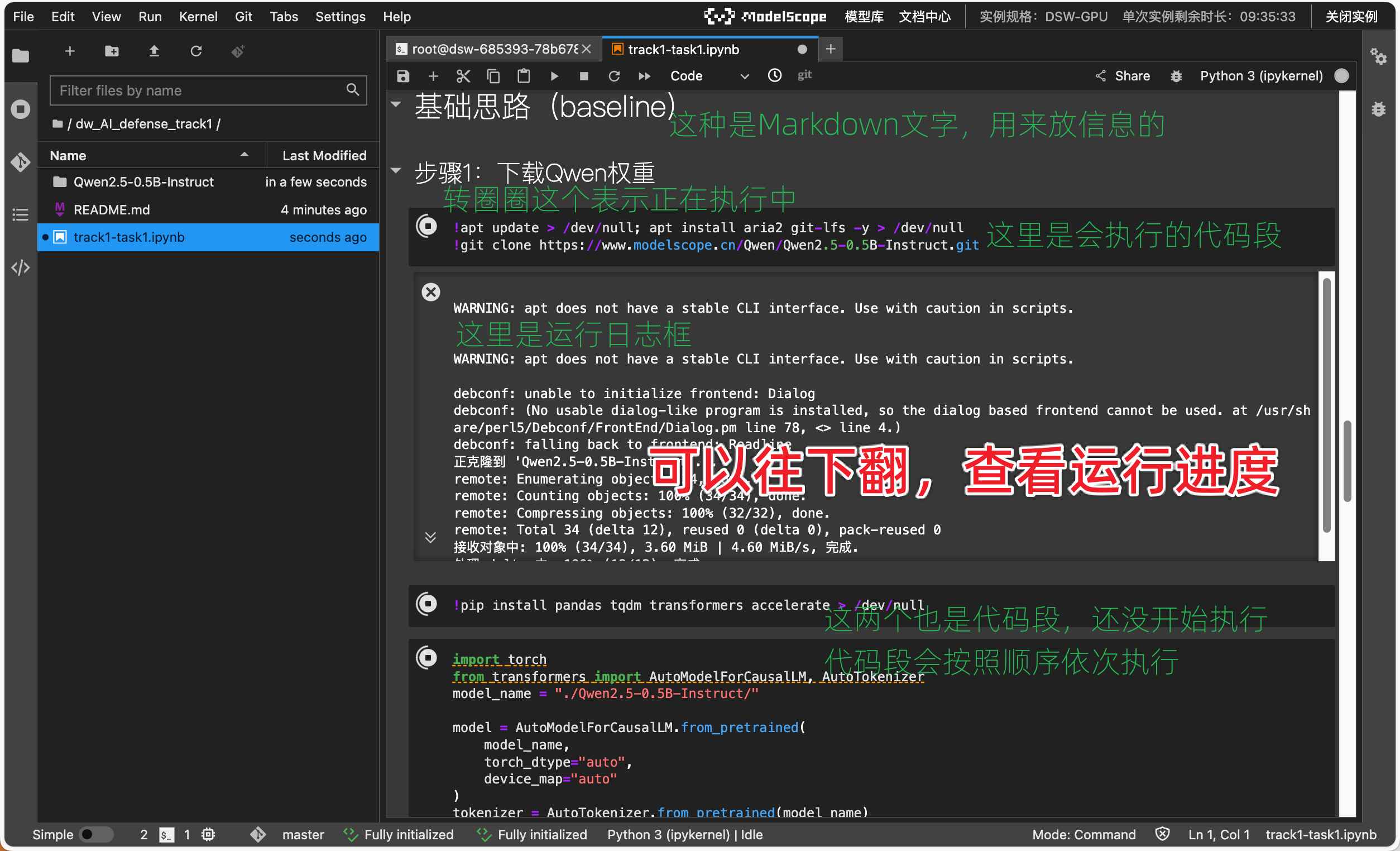
本地或者远程服务器进行,这里采用阿里的魔塔notebook来实现。ModelScope社区与阿里云合作,Notebook功能由阿里云提供产品和资源支持。
这里可以选择cpu/gpu版本进行创建环境。
打开一个终端:
下载baseline代码:
git lfs install
git clone https://www.modelscope.cn/datasets/Datawhale/dw_AI_defense_track2.git
然后执行notebook即可,按照步骤执行:
中间代码主要完成几个步骤:
- 按照YOLO格式制作数据集:
if os.path.exists('yolo_seg_dataset'):
shutil.rmtree('yolo_seg_dataset')
os.makedirs('yolo_seg_dataset/train')
os.makedirs('yolo_seg_dataset/valid')
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
# 采样训练集
for row in training_anno.iloc[:10000].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/train/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')
# 采用验证集
for row in training_anno.iloc[10000:10150].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/valid')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/valid/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')
- 训练YOLO分割模型:
from ultralytics import YOLO
model = YOLO("./yolov8n-seg.pt")
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=10, imgsz=640)
- 预测测试集:
from ultralytics import YOLO
import glob
from tqdm import tqdm
model = YOLO("./runs/segment/train6/weights/best.pt")
test_imgs = glob.glob('./test_set_A_rename/*/*')
Polygon = []
for path in tqdm(test_imgs[:]):
results = model(path, verbose=False)
result = results[0]
if result.masks is None:
Polygon.append([])
else:
Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy])
import pandas as pd
submit = pd.DataFrame({
'Path': [x.split('/')[-1] for x in test_imgs[:]],
'Polygon': Polygon
})
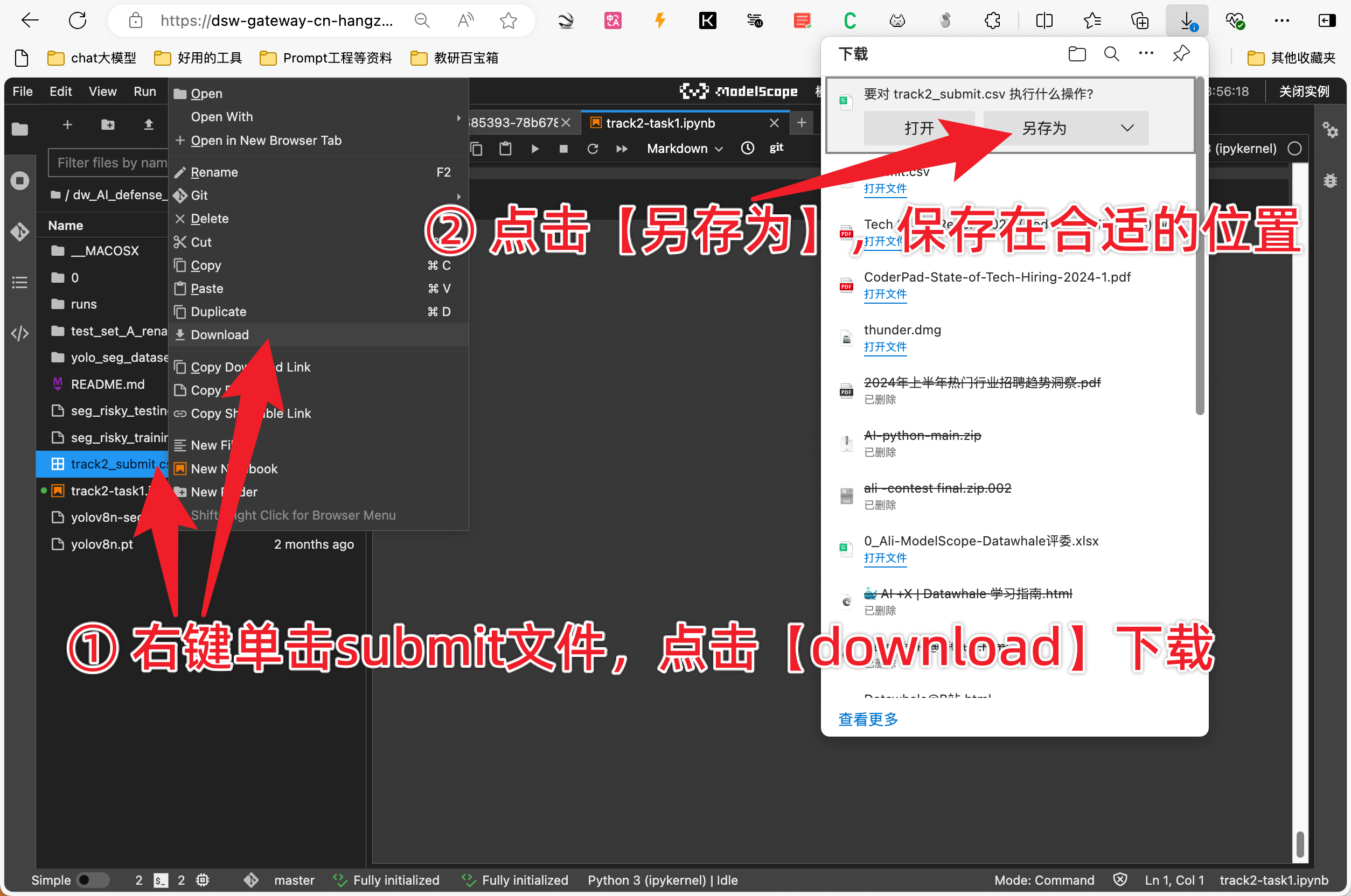
submit.to_csv('track2_submit.csv', index=None)
上述采用的是yolov8n-seg.pt基础模型,可以按照自身条件进行替换,最后将track2_submit.csv上传到比赛评测那个网页即可。
任务提交
比赛期间,参赛队伍通过天池平台下载数据,本地调试算法,在线提交结果,结果文件命名为"参赛队名称-result.csv",包含"Path"和"Polygon"列,"Polygon"列中采用轮廓点的方式存储每个篡改区域的位置,每个区域包含[左上,右上,右下,左下]4个点的坐标。
例如:
| Path | Polygon |
|---|---|
| 0/0aeaefa50ac1e39ecf5f02e4fa58a6a2.jpg | [[[139, 48], [181, 48], [181, 66], [139, 66]]] |