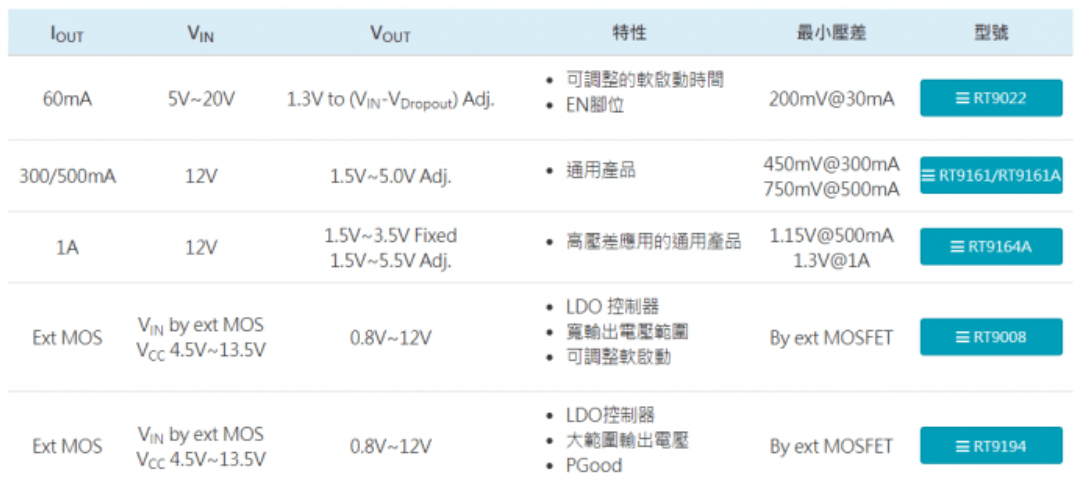
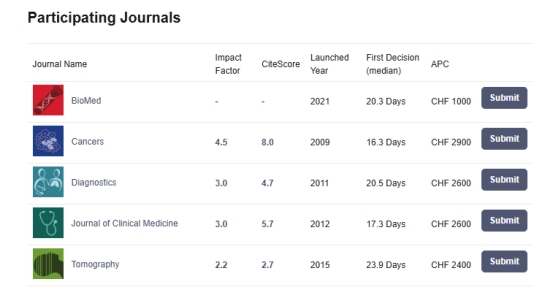
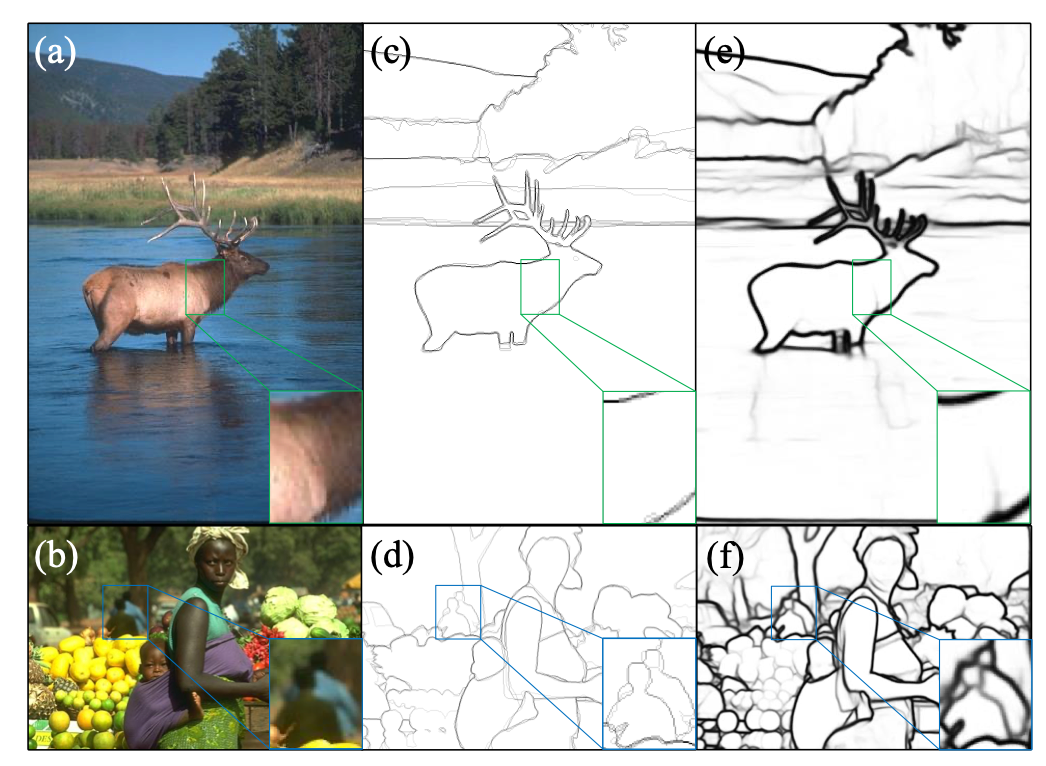
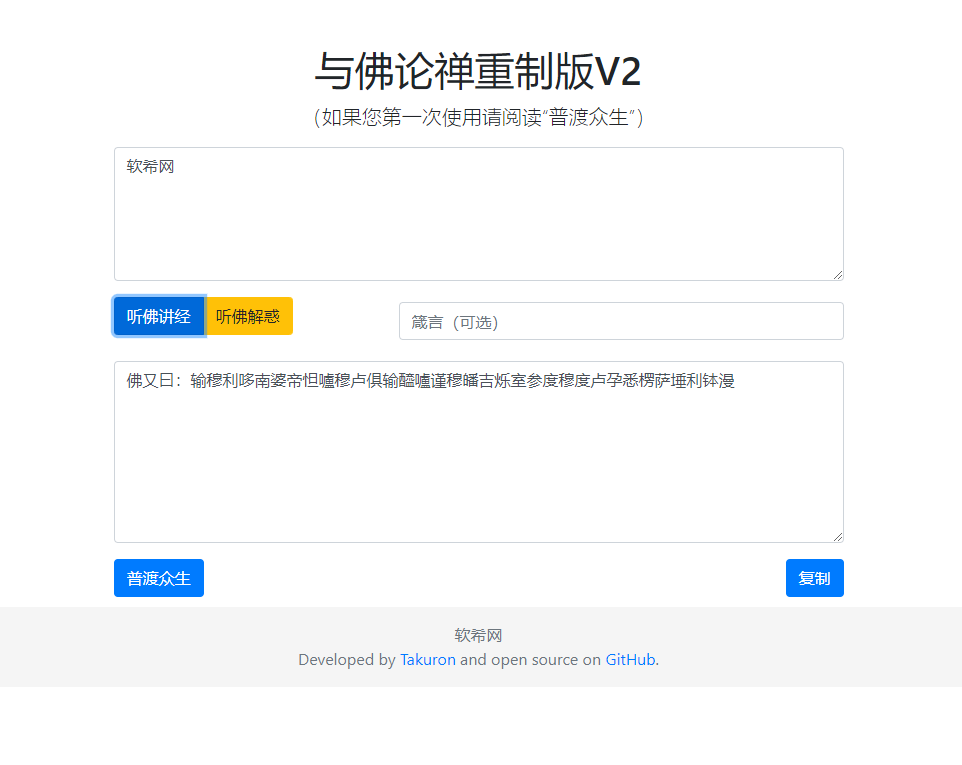
大文件分片上传,主要是为了提高上传效率,避免网络问题或者其他原因导致整个上传失败。
HTML部分没什么特殊代码,这里只写js代码。用原生js实现,框架中可参考实现
// 获取上传文件的 input框
const ipt = document.querySelector("input")
ipt.onchange = async (e) => {
// 拿到文件
const file = e.target.files[0];
if (!file) {
return
}
// 通过 cutFile函数,拿到切片后的数据结果
cutFile(file).then(res => {
// res 是一个 切片后的结果数组
// 用来上传后端
// res 数据结构大概是这样
// [
// {
// blob: Blob, // 分片文件数据
// end: 22222, // 当前分片的截止位置
// hash: 121212122dasd // 当前分片的hash值,用来确认哪些片段已经上传,哪些上传失败好重新上传
// index: 0, // 当前分片的索引(在所有分片中的位置)
// start: 0, // 当前分片的起始位置
// }
// ]
})
}
// 定义 cutFile 函数
const CHUNK_SIZE = 1 * 1024 * 1024; // 每一片文件的大小 这里暂定 每片 1MB
async function cutFile(file) {
let res = [];
let chunkCount = Math.ceil(file.size / CHUNK_SIZE); // 向上取整,即 即算出来 5.5片 就取 6片
for (let i = 0; i < chunkCount; i++) {
let chunk = await createChunks(file, i, CHUNK_SIZE)
res.push(chunk);
}
return res;
}
// 创建分片辅助函数
function createChunks (file, index, chunkSize) {
return new Promise((resolve) => {
const start = index * chunkSize;
const end = start + chunkSize; // 注意边界问题
const spark = new SparkMD5(); // 用来生成文件hash,需要安装 spark-md5
const fileReader = new FileReader();
const blob = file.slice(start, end);
fileReader.onload = e => {
spark.append(e.target.result)
resolve({
start,
end,
blob,
hash: spark.end(), // 这一步是同步任务,很耗时,如果分片很多,请考虑使用web worker开启多线程进行
index
});
}
fileReader.readAsArrayBuffer(blob)
});
}
如果分片很多,请考虑使用web worker开启多线程进行
大致思路如上,可能有些细节在使用时需要自己调整
感谢您的阅读!
面向娃编程,自己无聊写的小程序【工具人助手】,可以做题、练字。可能有小朋友的你会需要~