前言
1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
c/c++语言
数据结构与算法
GDB
设计模式
操作系统
系统编程
网络原理
网络编程
mysql
redis
服务器
RPG
本文为第一篇,后续会陆续更新。
共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接: https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i 需要的同学自取即可。
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
最后祝各位同学都能拿到自己满意的offer,成功上岸!
一、c/c++
01.智能指针实现原理
1.智能指针是一个类
这个类的构造函数中传入一个普通指针,析构函数中释放传入的指针。智能指针的类都是栈上的对象,所以当函数(或程序)结束时会自动被释放.
2.最常用的智能指针:
2.1 std::auto_ptr,
有很多问题。 不支持复制(拷贝构造函数)和赋值(operator =),但复制或赋值的时候不会提示出错。因为不能被复制,所以不能被放入容器中。
2.2 C++11引入的unique_ptr,
也不支持复制和赋值,但比auto_ptr好,直接赋值会编译出错。实在想赋值的话,需要使用:std::move。
例如:
std::unique_ptr p1(new int(5));
std::unique_ptr p2 = p1; // 编译会出错
std::unique_ptr p3 = std::move(p1); // 转移所有权, 现在那块内存归p3所有, p1成为无效的指针.
2.3 C++11或boost的shared_ptr,
基于引用计数的智能指针。可随意赋值,直到内存的引用计数为0的时候这个内存会被释放。
2.4 C++11或boost的weak_ptr,弱引用。
引用计数有一个问题就是互相引用形成环,这样两个指针指向的内存都无法释放。需要手动打破循环引用或使用weak_ptr。顾名思义,weak_ptr是一个弱引用,只引用,不计数。如果一块内存被shared_ptr和weak_ptr同时引用,当所有shared_ptr析构了之后,不管还有没有weak_ptr引用该内存,内存也会被释放。所以weak_ptr不保证它指向的内存一定是有效的,在使用之前需要检查weak_ptr是否为空指针。
3.智能指针的实现
下面是一个基于引用计数的智能指针的实现,需要实现构造,析构,拷贝构造,=操作符重载,重载*-和>操作符。
template <typename T>
class SmartPointer {
public:
//构造函数
SmartPointer(T* p=0): _ptr(p), _reference_count(new size_t){
if(p)
*_reference_count = 1;
else
*_reference_count = 0;
}
//拷贝构造函数
SmartPointer(const SmartPointer& src) {
if(this!=&src) {
_ptr = src._ptr;
_reference_count = src._reference_count;
(*_reference_count)++;
}
}
//重载赋值操作符
SmartPointer& operator=(const SmartPointer& src) {
if(_ptr==src._ptr) {
return *this;
}
releaseCount();
_ptr = src._ptr;
_reference_count = src._reference_count;
(*_reference_count)++;
return *this;
}
//重载操作符
T& operator*() {
if(_ptr) {
return *_ptr;
}
//throw exception
}
//重载操作符
T* operator->() {
if(_ptr) {
return _ptr;
}
//throw exception
}
//析构函数
~SmartPointer() {
if (--(*_reference_count) == 0) {
delete _ptr;
delete _reference_count;
}
}
private:
T *_ptr;
size_t *_reference_count;
void releaseCount() {
if(_ptr) {
(*_reference_count)--;
if((*_reference_count)==0) {
delete _ptr;
delete _reference_count;
}
}
}
};
int main()
{
SmartPointer<char> cp1(new char('a'));
SmartPointer<char> cp2(cp1);
SmartPointer<char> cp3;
cp3 = cp2;
cp3 = cp1;
cp3 = cp3;
SmartPointer<char> cp4(new char('b'));
cp3 = cp4;
}
02.智能指针,里面的计数器何时会改变
智能指针将一个计数器与类指向的对象相关联,引用计数跟踪共有多少个类对象(shared_ptr对象?)共享同一指针。它的具体做法如下:
1、当创建类的新对象时,初始化指针,并将引用计数设置为1
2、当对象作为另一个对象的副本时,复制构造函数复制副本指针,并增加与指针相应的引用计数(加1)
3、使用赋值操作符对一个对象进行赋值时,处理复杂一点:
(赋值判断要先判断 是否是自己给自己赋值)
先使左操作数的指针的引用计数减1(为何减1:因为指针已经指向别的地方),如果减1后引用计数为0,则释放指针所指对象内存。
然后增加右操作数所指对象的引用计数(为何增加:因为此时做操作数指向对象即右操作数指向对象)。
析构函数:调用析构函数时,析构函数先使引用计数减1,如果减至0则delete对象。
03.智能指针和管理的对象分别在哪个区(智能指针本身在栈区,托管的资源在堆区,利用了栈对象超出生命周期后自动析构的特征,所以无需手动delete释放资源。
智能指针和管理的对象分别在不同的区域中。
智能指针通常是一个对象,它会在堆上动态分配内存空间,因此它本身所占用的内存位于堆区。当智能指针被销毁时,由于其析构函数会自动释放其所占用的内存空间,因此不需要手动释放。
而被管理的对象则可能位于不同的区域中,具体取决于该对象是如何创建的。如果该对象是通过new运算符在堆上动态分配内存,则其所占用的内存位于堆区;如果该对象是作为栈变量或全局变量定义,则其所占用的内存位于栈区或静态数据区。当引用计数为0时,智能指针会自动调用delete运算符来释放被管理的对象所占用的内存空间。
04.面向对象的特性:多态原理
1.原理介绍
多态可以让同名函数,因为函数指向对象的不同,而去调用该对象中该名称的函数。
其实底层就是因为虚表的一些神奇操作。
操作系统为构成多态的每个类增加了一个虚函数表。这个虚函数表中存放的就是virtual关键词修饰的虚函数的首地址。编译器运行的时候通过虚表中存储的函数首地址去调用对应的函数。从而达到我们多态的目的。
2.验证虚表的存在
打印两个一模一样的类的大小
一个实现多态,一个没有实现。
namespace test7 {
//求一个正常的class大小
class Person {
public:
void test() {};
private:
int _a;
};
class Student {
public:
virtual void test() {};
private:
int _a;
};
void mytest() {
Person s1;
Student s2;
std::cout << sizeof(s1) << std::endl;
std::cout << sizeof(s2) << std::endl;
}
//求一个有虚表的class的大小
};
运行结果:
我们发现实现多态的类比没实现的大四个字节(一个指针大小)
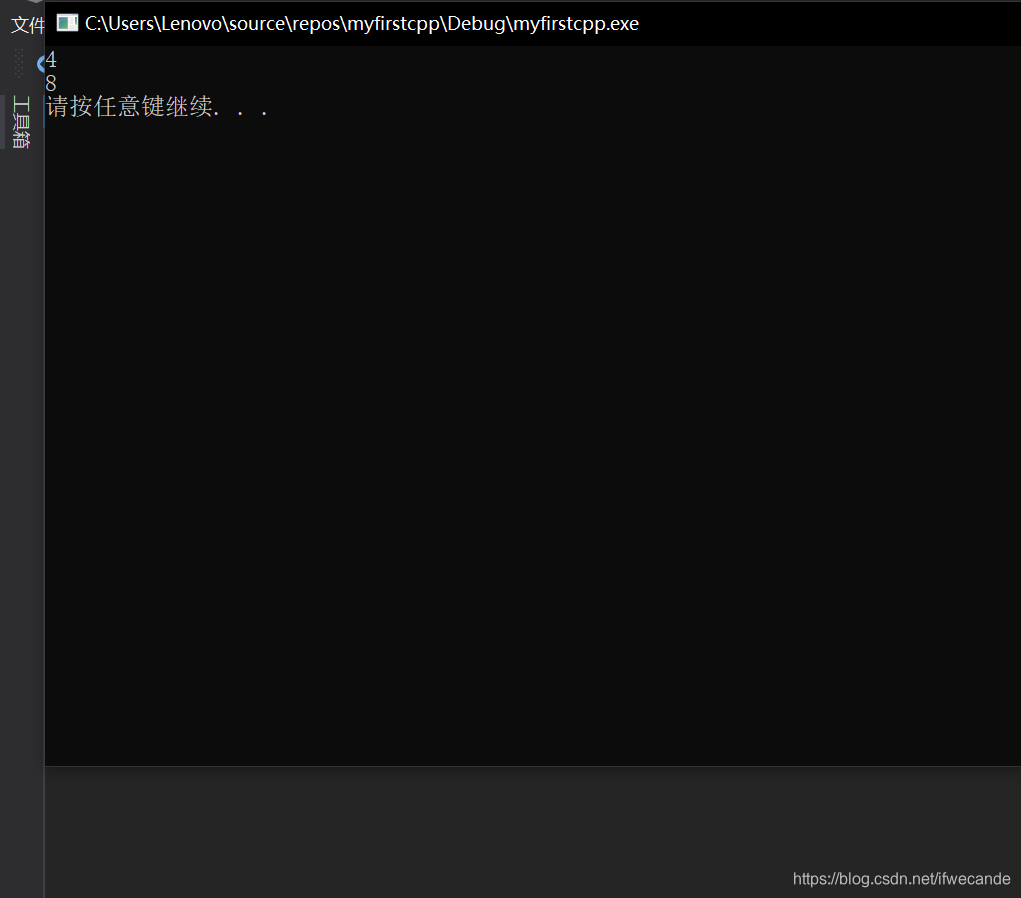
3.对虚表中存储的函数地址进行打印
虚函数表本质是一个存虚函数指针的指针数组,这个数组最后面放了一个nullptr。利用这个特性我们进行类型强转,于是可以打印出这个续表中存储的各个函数指针的数值。
namespace test8 {
//student 继承person 打印出指针 深入验证虚表存储的是什么
class Person {
public:
virtual void Example1() {
std::cout << "pex1" << std::endl;
}
virtual void Example2() {
std::cout << "pex2" << std::endl;
}
virtual void Example3() {
std::cout << "pex3" << std::endl;
}
virtual void Example4() {
std::cout << "pex4" << std::endl;
}
private:
int _a;
};
class Student : public Person {
public:
virtual void Example1() {
std::cout << "sex1" << std::endl;
}
virtual void Example2() {
std::cout << "sex2" << std::endl;
}
virtual void Example3() {
std::cout << "sex3" << std::endl;
}
virtual void Example5() {
std::cout << "sex5" << std::endl;
}
private:
int _b;
};
typedef void(*VFPTR) ();
void MyPrint(VFPTR vTable[])
{
// 依次取虚表中的虚函数指针打印并调用。调用就可以看出存的是哪个函数
std::cout << " 虚表地址>" << vTable << std::endl;
for (int i = 0; vTable[i] != nullptr; ++i)
{
printf(" 第%d个虚函数地址 :0X%x,->", i, vTable[i]);
VFPTR f = vTable[i];
f();
}
std::cout << std::endl;
}
int mytest() {
Person s1;
Student s2;
//打印出虚函数表的数值
VFPTR* vTableb = (VFPTR*)(*(int*)&s1);
MyPrint(vTableb);
VFPTR* vTabled = (VFPTR*)(*(int*)&s2);
MyPrint(vTabled);
return 0;
}
};
运行结果:
于是发现,父子类中都有一张虚表,用来存放虚函数的地址,子类重写了父类中的虚函数时,子类的虚表会指向新的地址,该地址是存放重写的虚函数的。(函数都在代码段)
当没有重写时候,父子的虚表都指向同一个地址。
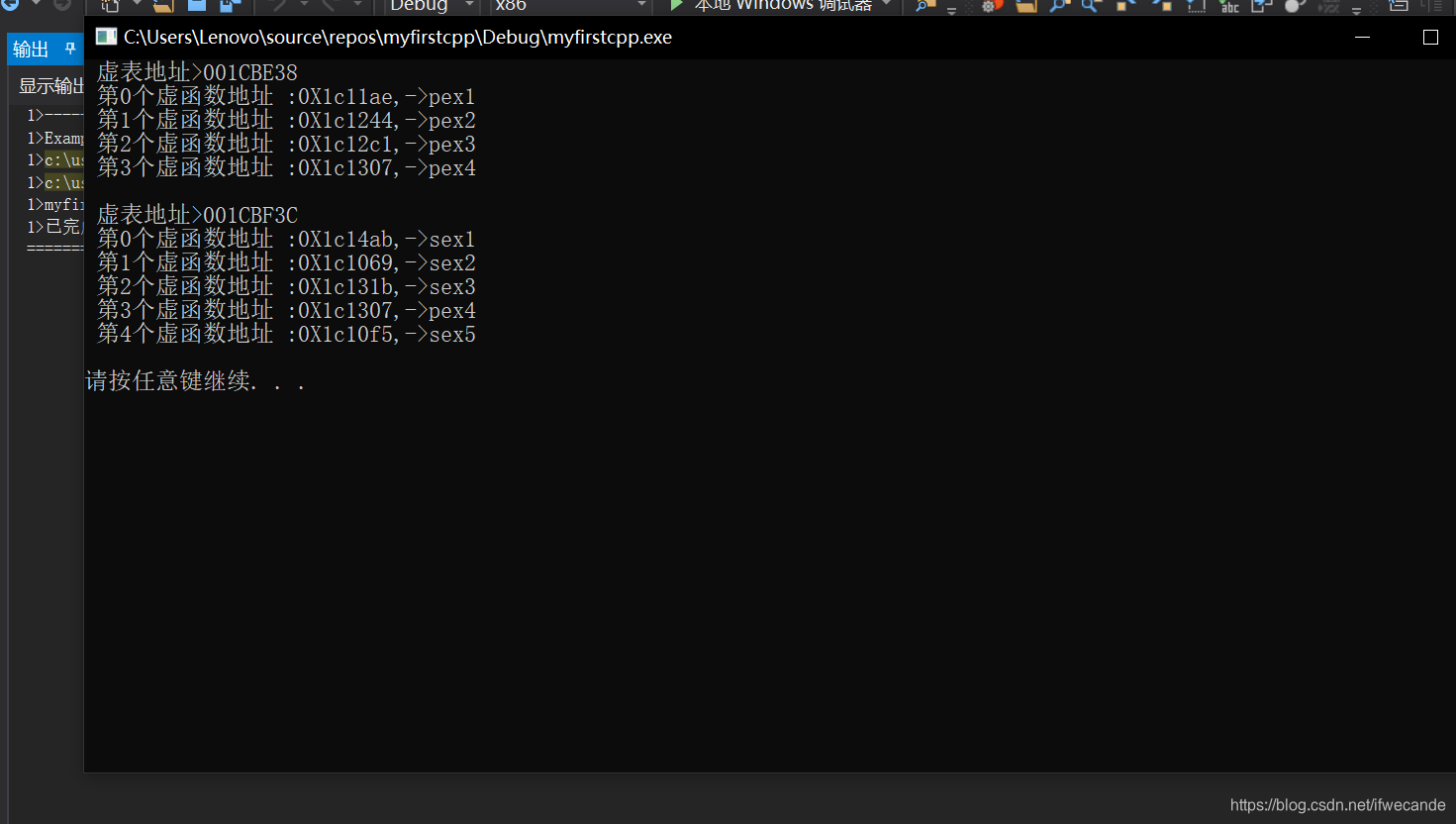
4.单继承和多继承的虚函数表
单继承的虚表如上面所示,父子类各有一张。而出现多继承的时候,子类中就会存在1张虚表包含了n个父类虚表的虚表,每张虚表都来自于不同的父类。
代码所示:
using namespace std;
namespace test9 {
class Base1 {
public:
virtual void func1() { cout << "Base1::func1" << endl; }
virtual void func2() { cout << "Base1::func2" << endl; }
private:
int b1;
};
class Base2 {
public:
virtual void func1() { cout << "Base2::func1" << endl; }
virtual void func2() { cout << "Base2::func2" << endl; }
private:
int b2;
};
class Derive : public Base1, public Base2 {
public:
virtual void func1() { cout << "Derive::func1" << endl; }
virtual void func3() { cout << "Derive::func3" << endl; }
private:
int d1;
};
typedef void(*VFPTR) ();
void PrintVTable(VFPTR vTable[])
{
cout << " 虚表地址>" << vTable << endl;
for (int i = 0; vTable[i] != nullptr; ++i)
{
printf(" 第%d个虚函数地址 :0X%x,->", i, vTable[i]);
VFPTR f = vTable[i];
f();
}
cout << endl;
}
void mytest()
{
Derive d;
VFPTR* vTableb1 = (VFPTR*)(*(int*)&d);
PrintVTable(vTableb1);
VFPTR* vTableb2 = (VFPTR*)(*(int*)((char*)&d + sizeof(Base1)));
PrintVTable(vTableb2);
}
};
运行结果:
先继承的类虚表在前面,后继承的类的虚表在后边。
子类中父类没有的虚函数会默认放在第一张虚表中。
5.结构总结
对于一个普通的A类
内存布局为:函数存在数据段(类成员共享)成员变量存在栈(由具体情况而定)
一般情况下,类大小计算只需要考虑成员变量
class A{
void func(){}
int a};
对于一个内部存在虚函数的B类
class B{
virtual void func(){}
int b};
内存布局为:函数存在数据段(类成员共享)成员变量存在栈(由具体情况而定),但是在类的起始位置会存在一个虚表指针(4/8字节), 指向虚函数表所在位置。
计算时需要额外考虑虚表指针。
多继承时的内存布局
C继承A,又继承B,在C的内存布局中,会按照先后顺序进行数据的存放, A前B后,A开始位置是A的虚表指针, B的开始位置是B的虚表指针,C中就有多个虚表。
与虚继承对比
虚继承解决了多继承产生的菱形继承问题,底层实际是产生数据冗余和二义性的地方不存储对应数据,而是选择存储一个指向虚基表的指针,通过虚基表中的偏移量来找到对应的数据。
多态实现了,一个对象指向谁调用谁。底层是在类的起始位置存储了一个虚函数表地址,当程序运行起来时,通过在虚函数表中查找对应的函数,来实现指向谁调用谁。
05.介绍一下虚函数,虚函数怎么实现的
用virtual关键字申明的函数叫做虚函数,虚函数肯定是类的成员函数;
存在虚函数的类都有一个一维的虚函数表叫做虚表,类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是和对象对应的;
多态性是一个接口多种实现,是面向对象的核心,分为类的多态性和函数的多态性;
多态用虚函数来实现,结合动态绑定;
纯虚函数是虚函数再加上 = 0;
抽象类是指包括至少一个纯虚函数的类。纯虚函数:virtual void fun()=0;即抽象类!抽象基类不能定义对象。必须在子类实现这个函数,即先有名称,没有内容,在派生类实现内容。
06.多态和继承在什么情况下使用
1.继承和多态的区别是什么:
第一种说法:
继承和多态的区别:
继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力
多态是指同一个实体同时具有多种形式。
第二种说法:
继承:
继承给对象提供了从基类(父类)获取字段和方法的能力。继承提供了代码的重用性,也可以在不修改类的情况下给现存的类添加新特性。
多态:
多态是编程语言给不同的底层数据类型做相同的接口展示的一种能力。同一个方法或接口中的同一个引用类型,使用不同的实例而执行不同操作
2.多态应用有几个条件,都分别是什么:
多态应用的三个条件:
2.1 继承关系
2.2 子类重写父类的方法
2.3 父类引用 指向子类对象
07.除了多态和继承还有什么面向对象方法
除了多态和继承,面向对象编程还有以下方法:
- 封装:将数据和行为封装到一个类中,并对外提供公共接口。这样可以隐藏内部实现细节,避免直接访问数据导致的错误。
- 抽象:通过抽象类或接口定义通用的行为规范,并由具体的子类实现具体细节。这样可以提高代码复用性和可扩展性。
- 组合:通过组合不同类来创建新的对象,从而实现更复杂的功能。比如在一个汽车类中组合轮胎、发动机等其他类来创建一个完整的汽车对象。
- 接口隔离原则(ISP):将大型接口分解为更小、更专一的接口,避免客户端依赖于不需要使用的方法。
- 依赖倒置原则(DIP):高层模块不应该依赖低层模块,它们都应该依赖于抽象。这样可以减少模块间的耦合度,提高代码灵活性和可重用性。
总之,在面向对象编程中,以上方法是常见的技巧和设计原则,它们可以帮助我们写出高质量、易于维护、可扩展和灵活的代码。
08.C++内存分布。什么样的数据在栈区,什么样的在堆区
1.栈区(satck)
由编译器自动分配释放, 存放函数的参数值,局部变量等。主要存放函数的参数以及局部变量。在函数完成执行,系统自行释放栈区内存,不需要用户管理。整个程序的栈区的大小可以在编译器中由用户自行设定,VS中默认的栈区大小为1M,可通过VS手动更改栈的大小。64bits的Linux默认栈大小为10MB,可通过ulimit -s临时修改。
例如: 参数buf,参数bufsize和size都是存放在栈区.当函数执行完毕的时候,自动释放
void recev(char* buf, int bufsize){
int size;
}
2.堆区
一般由程序员分配释放(动态内存申请与释放),若程序员不释放,程序结束时可能由操作系统回收。,堆的总大小为机器的虚拟内存大小。
说明:c++中new操作符本质上是使用了malloc进行内存的申请,new和malloc的区别如下:
(1)malloc是C语言中的函数,而new是C++中的操作符。
(2)malloc申请之后返回的类型是void*,而new返回的指针带有类型。
(3)malloc只负责内存的分配而不会调用类的构造函数,而new不仅会分配内存,而且会自动调用类的构造函数。
(4)由new分配的内存块放在堆区,用delete结束生命,由malloc等分配的内存块放在自由存储区,和堆类似,用free来结束生命。
例如:下面的src所指向的内存空间就是在堆区
char* src = (char*) malloc(sizeof(buf) * sizeof(10));
09.C++内存管理(RAII啥的)
在C++中,内存管理是一个非常重要的问题。为了避免内存泄漏、悬垂指针等问题,可以使用RAII(Resource Acquisition Is Initialization)技术来进行内存管理。
RAII是一种利用对象的生命周期来管理资源的技术。它的基本原则是,在对象构造时获取资源,在对象析构时释放资源。这样,当对象被销毁时,它所占用的资源也会自动被释放,从而避免了手动释放内存或资源可能产生的错误。
具体实现方式包括:
- 使用智能指针:智能指针是一种自动化管理内存的机制,它通过类似于引用计数的方式来确保在没有任何对象引用该内存块时能够自动释放对应的内存空间。C++标准库提供了shared_ptr和unique_ptr两个类模板来支持智能指针。
- 使用容器:C++标准库提供了各种容器类型(如vector、list、map等),这些容器会自动管理其中元素所占用的空间。当容器被销毁时,其中所有元素所占用的空间也会被自动释放。
- 自定义类:在类中封装需要管理的资源,并在构造函数中申请资源,在析构函数中释放资源即可实现RAII技术。
10.C++从源程序到可执行程序的过程
源程序(source code)→预处理器(preprocessor)→编译器(compiler)→汇编程序(assembler)→目标程序(object code)→连接器(链接器,Linker)→可执行程序(executables)
1.预处理
生成test.i文件,做一下处理:
- 展开宏定义
- 处理#if,#end,#ifndef
- 处理#include指令,把.h文件插入对应位置
- 删除注释
2.编译
- 编译过程所进行的是对预处理后的文件进行语法分析,词法分析,语义分析,符号汇总,然后生成汇编代码文件test.s
- 词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。词法分析程序实现这个任务。词法分析程序可以使用lex等工具自动生成。
- 语法分析是编译过程的一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等.语法分析程序判断源程序在结构上是否正确.源程序的结构由上下文无关文法描述.
- 语义分析是编译过程的一个逻辑阶段. 语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查, 进行类型审查
生成test.s文件
3.汇编
将汇编代码转成二进制文件,二进制文件就可以让机器来读取。每一条汇编语句都会产生一句机器语言。生成test.o文件
4.链接
将二进制文件变成一个可执行文件。链接会涉及到动态链接和静态链接。
11.一个对象=另一个对象会发生什么(赋值构造函数)
如果没有定义赋值构造函数,编译器会自动定义“合成的赋值构造函数”,
与其他合成的构造函数,是“浅拷贝”(又称为“位拷贝”)。
定义:
Human& operator=(const Human& other);
实现:
Human& Human::operator=(const Human& other){
//当other = other时;
if (this == &other) return *this;
//假如 f1 = f2;
//自动调用, f1.operator=(f2)
this->name = other.name;
this->age = other.age;
this->sex = other.sex;
strcpy_s(this->addr,ADDR_LEN, other.addr);
//返回对象的引用,是为了做链式处理: f1 = f2 = f3;
return *this;
}
调用:
对象赋值时自动调用
//调用赋值构造函数
lisi = zhangsan;
Human.h
#pragma once
#include <string>
#include <iostream>
#include <Windows.h>
using namespace std;
class Human {
public:
Human();
~Human();
Human(string name, int age, string sex);
//定义了一个赋值构造函数
Human& operator=(const Human& other);
string getName() const;
string getSex() const;
int getAge() const;
const char* getAddr()const;
void setAddr(char* addr);
void description() const;
private:
string name; //姓名
string sex; //性别
int age; //年龄
char* addr; //地址
};
Human.cpp
#include "Human.h"
#define ADDR_LEN 64
Human::Human() {
name = "无名";
sex = "未知";
age = 18;
const char* addr_s = "China";
addr = new char[ADDR_LEN];
strcpy_s(addr, ADDR_LEN, addr_s);
}
Human::Human(string name, int age, string sex) {
this->age = age;
this->name = name;
this->sex = sex;
const char* addr_s = "China";
addr = new char[ADDR_LEN];
strcpy_s(addr, ADDR_LEN, addr_s);
}
Human& Human::operator=(const Human& other){
//当other = other时;
if (this == &other) return *this;
//假如 f1 = f2;
//自动调用, f1.operator=(f2)
this->name = other.name;
this->age = other.age;
this->sex = other.sex;
strcpy_s(this->addr,ADDR_LEN, other.addr);
//返回对象的引用,是为了做链式处理: f1 = f2 = f3;
return *this;
}
string Human::getName() const {
return name;
}
string Human::getSex() const {
return sex;
}
int Human::getAge() const {
return age;
}
const char* Human::getAddr() const{
return addr;
}
void Human::setAddr(char* addr){
if (!addr) return;
strcpy_s(this->addr, ADDR_LEN, addr);
}
main.cpp
#include "Human.h"
using namespace std;
void showMsg(const Human &man1, const Human& man2) {
cout << "张三地址: " << man1.getAddr() << endl;
cout << "李四地址: " << man2.getAddr() << endl;
}
int main(void) {
Human zhangsan("张三", 18, "男");
Human lisi;
//调用赋值构造函数
lisi = zhangsan;
cout << "张三修改地址前" << endl;
showMsg(zhangsan, lisi);
zhangsan.setAddr((char*)"新加坡");
cout << "张三修改地址后" << endl;
showMsg(zhangsan, lisi);
system("pause");
return 0;
}
12.如果new了之后出了问题直接return。会导致内存泄漏。怎么办(智能指针,raii)
1.检查。在return的时候,判断指针是否为空,如果为空指针,再进行return。
2.可以使用智能指针。
13.c++11的智能指针有哪些。weak_ptr的使用场景。什么情况下会产生循环引用
- unique_ptr:独占所有权的智能指针,只有一个指向该内存的引用,并且当该指针超出作用域或被删除时会自动释放所管理的对象。不支持拷贝和赋值操作。
- shared_ptr:多个共享所有权的智能指针,可以有多个指向同一块内存空间,由计数器来记录当前有多少个shared_ptr同时引用该对象。当最后一个shared_ptr超出作用域或被删除时才会释放所管理的对象。
- weak_ptr:弱引用智能指针,不会增加所管理对象的引用计数。它通常与shared_ptr配合使用,可以检测是否存在循环依赖关系,并避免因循环引用导致的内存泄漏问题。
weak_ptr主要应用在解决循环引用问题上。当两个或多个类之间互相持有shared_ptr成员变量时(即形成了循环依赖),如果这些shared_ptr都是直接相互引用而没有使用weak_ptr进行中介,则可能导致内存泄漏,因为它们互相引用将永远不会使得对方的计数器为0从而无法释放资源。此时可以使用weak_ptr解决这个问题,在其中一个类中使用weak_ptr成员变量来引用另一个类的shared_ptr,从而使得循环依赖关系被打破。
产生循环引用的情况通常是由于两个或多个类之间互相持有shared_ptr成员变量,例如:
class A {
public:
std::shared_ptr<B> b;
};
class B {
public:
std::shared_ptr<A> a;
};
在这种情况下,如果a和b都是shared_ptr类型,并且互相持有对方的引用,则可能形成循环依赖。当a和b被销毁时,它们所管理的对象将无法释放,从而导致内存泄漏。
14.多进程fork后不同进程会共享哪些资源
fork函数是创建一个新的进程作为原进程的子进程,创建的子进程和父进程存在很多的相似性,首先父子进程的虚拟存储空间的用户空间是相同的,是将父进程的拷贝给子进程。同时父子进程对文件的操作是共享方式。因为父进程的文件描述符表被拷贝给了子进程(具体的原理参虚拟存储器的内容,私有对象写时拷贝实现了父子进程之间形成相互独立的地址空间)。因此父进程打开的所有文件描述符都在子进程中保存了(每个进程都有独立的描述符表)。由于所有的进程共享文件表、v-node表,所以父子进程的描述符表也是相同的,所以父子进程对文件是以共享的方式存在的。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/wait.h>
int main()
{
int fd;
char c[3];
/*打开文件foobar.txt,采用的是只读形式*/
fd = open("foobar.txt",O_RDONLY,0);
if(fork()==0)//子进程
{
read(fd,&c,2);/*读文件的一个字节到c中*/
c[2]='\0';
printf("c = %s\n",c);
exit(0);
/*子进程结束*/
}
/*下面是父进程的读操作*/
wait(NULL);
read(fd,&c,2);
c[2]='\0';
printf("c = %s\n",c);
exit(0);
}
其中foobar.txt中的内容是foobar。
编译调试以后的结果是:
[gong@Gong-Computer cprogram]$ gcc -g fileshare2.c -o fileshare2
[gong@Gong-Computer cprogram]$ ./fileshare2
c = fo
c = ob
原因分析:由于父子进程是以共享的方式控制已经打开文件的,因此对文件的操作也是相互影响的,因此读写文件的位置也会发生相应的改变。父(子)进程的文件读写位置会随着子(父)进程的文件读写位置改变而改变,因为此时改变的是文件表的文件位置项,而文件表是所有进程共享的,任何一个进程的修改都会影响到别的进程。但是父(子)进程对描述符的修改不会影响子(父)进程的描述符,因为close(fd)的操作只是改变文件表述符表中的内容,而该表是每个进程相互独立的,因此不会改变其他进程的表。
15.多线程里线程的同步方式有哪些
- 互斥锁(Mutex):用于保护临界区,确保同时只有一个线程可以进入临界区。
- 信号量(Semaphore):控制同时访问特定资源的线程数量。
- 条件变量(Condition Variable):等待某些条件满足后再继续执行。
- 屏障(Barrier):所有线程都必须到达屏障点,才能继续执行下一步操作。
- 读写锁(Read-Write Lock):允许多个读操作并发进行,但是写操作必须互斥执行。
- 自旋锁(Spin Lock):在获取锁之前不断循环检查锁是否可用,避免上下文切换带来的开销。
- 原子操作(Atomic Operation):在单个CPU指令中完成数据的读取和修改,避免竞争条件。
这些同步方式都有各自的优缺点和适用场景,在实际使用中需要根据具体情况进行选择。
16.size_of是在编译期还是在运行期确定
《C语言程序设计》中对sizeof的描述:C语言提供了一个编译时(compile-time) 一元运算符 sizeof,它可以用来计算任一对象的长度。 表达式sizeof 对象以及sizeof(类型名)将返回一个整型值,它等于指定对象或类型占用的存储空间字节数。
依据上述描述,可以得出结论sizeof的值是在编译时确定的,而非运行期确定。
如一下举例代码:
// 需在C99标准的编译器下编译, ANSI C (即C89)下编译不通过
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {int n;scanf("%d",&n);int arr[n];printf("%d\n",sizeof(n++));printf("%d\n",sizeof(arr));printf("%d",n);return 0;
}
上述代码开始输入3 给 n
输出结果为: 4 12 3
即sizeof(n++)中的++未执行,(在sizeof后使用函数,同样在求函数返回值大小时,函数也不会执行)但sizeof(arr) 一定不是在编译时确定的。 不同的输入得到动态数组大小不一。
在c99没有出现之前,sizeof是由编译时确定的,sizeof对一个类型求出的值可以当一个常量来用。但C99中引入了动态数组(定义一个数组,其大小由运行时确定)导致sizeof作用于动态数组时的值不再是常量。
结论
sizeof是一种运算符不是函数,所得出的值在编译期确定,可以求出静态分配内存的数组的长度,但不能求出动态分配的内存的大小。
17.函数重载的机制。重载是在编译期还是在运行期确定
重载:
1.发生在编译期,在同一个类,多个同名的方法(方法名必须同名),这些方法起着不同的作用。
2.从类的角度:重载发生在同一个类中
3.参数列表:重载必须保持不一致(类型不同,个数不同,顺序不同)反正就是不一样
4.返回值和访问修饰符可以不相同
5.构造方法:可以被重载
18.指针常量和常量指针
指针常量和常量指针是 C/C++ 语言中的两个概念。
指针常量是一个指针,它所指向的内存地址不能被修改,但是可以通过该指针来修改所指向的内存区域的值。例如:
int a = 10;
int b = 20;
int* const p = &a; // 指针常量p只能指向a
*p = 30; // 可以修改p所指向的a变量的值
// p = &b; // 错误:不能改变p所保存的地址
上述代码中,定义了一个整型变量a和b,并且定义了一个指针常量p,该指针只能指向a。在后续代码中,可以通过*p来修改a变量的值,但是无法将p重新赋值为其他地址。
常量指针是一个指向常量对象(即不能被修改)的指针。也就是说,通过该指针不能修改所指向的内存区域的值。例如:
int a = 10;
const int* p1 = &a; // 常量指针p1只能读取a的值
// *p1 = 20; // 错误:不能通过p1来修改a的值
int b = *p1 + 5; // 可以通过*p1来读取a当前保存的值,并进行计算
上述代码中,定义了一个整型变量a,并且定义了一个常量指针p1,该指针只能读取a的值。在后续代码中,可以通过p1来读取a当前保存的值,并进行计算,但是无法通过p1来修改a的值。
总结:
- 指针常量:所指向的内存地址不能被修改,但是可以通过该指针来修改所指向的内存区域的值。
- 常量指针:指向常量对象(即不能被修改)的指针,通过该指针不能修改所指向的内存区域的值。
19.vector的原理,怎么扩容
扩容原理概述
新增元素:Vector通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素;
对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了 ;
初始时刻vector的capacity为0,塞入第一个元素后capacity增加为1;
不同的编译器实现的扩容方式不一样,VS2015中以1.5倍扩容,GCC以2倍扩容。
GCC下测试
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> vec;
cout << vec.capacity() << endl;
for (int i = 0; i<10; ++i)
{
vec.push_back(i);
cout << "size: " << vec.size() << endl;
cout << "capacity: " << vec.capacity() << endl;
}
return 0;
}
输出结果:
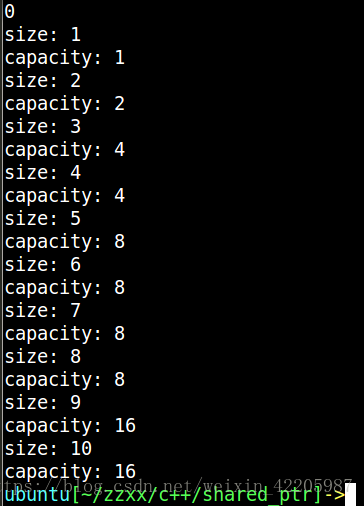
从这里我认为vector的初始的扩容方式代价太大,初始扩容效率低, 需要频繁增长,不仅操作效率比较低,而且频繁的向操作系统申请内存容易造成过多的内存碎片,所以这个时候需要合理使用resize()和reserve()方法提高效率减少内存碎片的,
resize()
- resize方法被用来改变vector中元素的数量,我们可以说,resize方法改变了容器的大小,且创建了容器中的对象;
- 如果resize中所指定的n小于vector中当前的元素数量,则会删除vector中多于n的元素,使vector得大小变为n;容量不会变(capacity)
- 如果所指定的n大于vector中当前的元素数量,小于capacity容量值,则会在vector当前的尾部插入适量的元素,使得vector的大小变为n,在这里,如果为resize方法指定了第二个参数,则会把第二个参数值初始化为该指定值,如果没有为resize指定第二个参数,则会初始化为默认的初始值 0;容量不会变(capacity)
- 如果resize所指定的n不仅大于vector中当前的元素数量,还大于vector当前的capacity容量值时,则会自动为vector重新分配存储空间; 容量会变(capacity)
当之前的size*2小于resize时,容量为resize的大小
当之前的size*2大于resize时,容量为size*2
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> vec;
cout << vec.capacity() << endl;
for (int i = 0; i<6; ++i) //之前的容量为6 *2 = 12
{
vec.push_back(i+1);
cout << "size: " << vec.size() << endl;
cout << "capacity: " << vec.capacity() << endl;
}
for(int i = 0; i < vec.size(); i++)
{
cout << vec[i] << endl;
}
vec.resize(9);// resize= 9
for(int i = 0; i < vec.size(); i++)
{
cout << vec[i] << endl;
}
cout << "size: " << vec.size() << endl;
cout << "capacity: " << vec.capacity() << endl; 容量=12
return 0;
}
输出结果:
0
size: 1
capacity: 1
size: 2
capacity: 2
size: 3
capacity: 4
size: 4
capacity: 4
size: 5
capacity: 8
size: 6 //size = 6
capacity: 8
1
2
3
4
5
6
1
2
3
4
5
6
0
0
0
size: 9
capacity: 12
reserve():
- reserve方法被用来重新分配vector的容量大小;
- 只有当所申请的容量大于vector的当前容量时才会重新为vector分配存储空间;重新分配后的容量即reserve大小,size大小没有变,所以不会产生新的对象
- 小于当前容量则没有影响,size、capacity都没有影响
- reserve方法对于vector元素大小没有任何影响,不创建对象。
vector中数据的随机存取效率很高
O(1)的时间的复杂度,但是在vector 中随机插入元素,需要移动的元素数量较多,效率比较低
#include <iostream>
#include <vector>
using namespace std;
class A
{
public:
A()
{
cout << "construct" << endl; //构造函数
}
A(const A &a)
{
cout << "copy construct" << endl; //拷贝构造函数
}
~A()
{
cout << "destruction" << endl; //析构函数
}
};
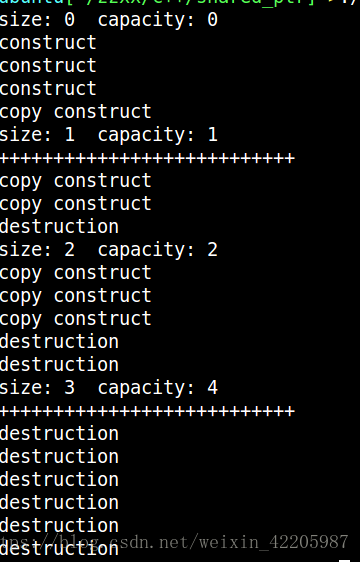
int main(void)
{
vector<A> p;
cout <<"size: "<<p.size() << " "<<"capacity: "<< p.capacity()<< endl;//size = 0 capacity=0
A a;//调用构造函数
A b;//调用构造函数
A c;//调用构造函数
p.push_back(a);//调用拷贝构函数放入p中
cout <<"size: "<<p.size() << " "<<"capacity: "<< p.capacity()<< endl;//size=1 capacity=1
cout << "+++++++++++++++++++++++++++\n";
p.push_back(b);//容量不够 扩容成2倍 将原来的a拷贝构造到新的位置 将b拷贝构造到新的位置 析构原来位置的a
cout <<"size: "<<p.size() << " "<<"capacity: "<< p.capacity()<< endl;//size=2 capacity=2
p.push_back(c);//容量不够 扩容2倍 将a、b分别拷贝构造到新的位置 将c拷贝构造到新的位置 析构原来位置的a、b
cout <<"size: "<<p.size() << " "<<"capacity: "<< p.capacity()<< endl;//size=3 capacit=4
cout << "+++++++++++++++++++++++++++\n";
//析构a、b、c、以及析构向量中的三个对象
}
输出结果:
20.介绍一下const
1、const是一个C语言(ANSI C)的关键字,具有着举足轻重的地位。
2、它限定一个变量不允许被改变,产生静态作用。
3、使用const在一定程度上可以提高程序的安全性和可靠性。
4、另外,在观看别人代码的时候,清晰理解const所起的作用,对理解对方的程序也有一定帮助。
5、另外CONST在其它编程语言中也有出现,例如Pascal、C++、PHP5、B#.net、HC08 C、C#等。
21.引用和指针的区别
引用是对象的别名, 操作引用就是操作这个对象, 必须在创建的同时有效得初始化(引用一个有效的对象, 不可为NULL), 初始化完毕就再也不可改变, 引用具有指针的效率, 又具有变量使用的方便性和直观性, 在语言层面上引用和对象的用法一样, 在二进制层面上引用一般都是通过指针来实现的, 只是编译器帮我们完成了转换。 之所以使用引用是为了用适当的工具做恰如其分的事, 体现了最小特权原则。
22.Cpp新特性知道哪些
1.C++11
- auto 关键字:自动类型推导。
- nullptr 关键字:空指针。
- range-based for 循环:基于范围的 for 循环。
- lambda 表达式:匿名函数。
- constexpr 关键字:编译期常量表达式。
- 右值引用和移动语义:减少了拷贝构造函数和赋值运算符的开销。
2.C++14
- 泛型 lambda 表达式:可以在 lambda 表达式中使用 auto 参数类型。
- 变长参数模板函数(Variadic templates):可变数量的模板参数列表。
- C++17
- if 与 switch 语句中初始化变量支持直接列表初始化。
- 结构化绑定(Structured bindings):可以方便地解包元组或结构体中的成员变量。
- 具有自动类型推断能力的新表达式语法(class template argument deduction, deduction guides)。
3.C++20
- Concepts 概念(Concepts): 类似于接口,用于描述一个类型所需满足的条件,简化了模板类或函数对泛型参数类型约束的实现方式。
- 协程(Coroutines): 异步编程的一种实现方式,在异步代码执行完毕后回到原来位置继续执行同步代码。
- 初始化上下文限制(Designated Initialization): 可以通过指定初始化成员变量的方式方便地初始化类对象。
- 三路比较运算符(Three-way comparison operator): 简化了自定义类型的比较操作实现,增强了可读性和可维护性。
23.类型转换
const_cast:从字面意思上就可以理解,去除变量的const属性。
static_cast:静态类型转换,一般用于基本类型间的转换,如char->int
dynamic_cast:动态转换,同于多态之间的类型转换
reinterpret_cast:用于不同类型的指针类型的转换。
24.RAII基于什么实现的(生命周期、作用域、构造析构)
1.何为RAII
RAII是Resource Acquisition Is Initialization的缩写,是由C++之父Bjarne Stroustrup提出来的,直接翻译过来就是资源获取即初始化,是一个非常强大的编程概念。RAII理念是借助对象的作用域/生存周期来管理资源,因此也有呼声将其更名为Scope-Bound Resource Management。在这个概念中资源所指的不仅是内存,也可以指文件描述符,套接字,数据库句柄等。资源的生命周期等同于资源对象的作用域。RAII是C++中管理资源、避免内存泄漏的好方法。在C++中,在创建一个类对象时会自动调用类的构造函数,对象超出作用域时会自动调用析构函数。RAII的思想就是将资源与对象的生命周期绑定。
RAII可以总结为两点,
- 将资源封装到类中
- 构造函数获取资源并初始化类中的常量,否则要抛出异常
- 释放资源,不抛异常
- 通过RAII型的类的实例来使用资源
- 资源的生命周期和类的实例的生命周期相同
- 带有open/close,lock/unlock,init/copyFrom/destroy成员函数的类通常不是RAII型的类。
C++中,STL中的很多类都遵守RAII规则,如std::string/std::vector等,都是在构造函数中获取资源,在析构函数中自动清除,不需要显式的清除资源。STL中还提供了一些遵守RAII规则的封装器用以管理用户提供的资源。如:
- std::unique_ptr/std::shared_ptr用于管理动态内存
- std::lock_guard/std::unique_lock/std::shared_lock用以管理互斥锁
2.RAII型的类和使用
以unique_lock为例说明RAII型类的使用。
#include <memory>
#include <iostream>
#include <thread>
#include <functional>
#include <mutex>
#include <chrono>
using namespace std;
void increase(std::string name, int n)
{
for(auto i=0; i<n; i++) {
std::cout << name << ": " << i << std::endl;
std::this_thread::sleep_for(200ms);
}
}
int main()
{
int n = 5;
auto f1 = std::bind(&increase, "t1", std::placeholders::_1);
auto f2 = std::bind(&increase, "t2", std::placeholders::_1);
auto t1 = std::make_unique<std::thread>(std::bind(f1, n));
auto t2 = std::make_unique<std::thread>(std::bind(f2, n));
t1->join();
t2->join();
}
// t1: 0t2
// : 0
// t2: 1
// t1: 1
// t2: 2
// t1: 2
// t2: 3
// t1: 3
// t2: 4
// t1: 4
上面的代码中,没有做线程同步,两个线程的输出混淆在一起,这不是我们想要的结果。最简单的方式就是使用互斥锁,
void increase(std::string name, int n)
{
mtx.lock();
for(auto i=0; i<n; i++) {
std::cout << name << ": " << i << std::endl;
std::this_thread::sleep_for(200ms);
}
mtx.unlock();
}
// t1: 0
// t1: 1
// t1: 2
// t1: 3
// t1: 4
// t2: 0
// t2: 1
// t2: 2
// t2: 3
// t2: 4
上面互斥锁的使用,需要手动的设置lock和unlock,这不符合RAII的思想,而使用unique_lock/lock_guard,可以在创建lock变量的时候就自动上锁,在lock变量超出作用域,生命周期结束变量销毁时会自动释放锁。其中unique_lock还可以接受defer_lock可以推迟加锁,此时需要手动的上锁和释放锁unique_lock就不符合RAII规则了。
void increase(std::string name, int n)
{ std::unique_lock<std::mutex> ul(mtx);
for(auto i=0; i<n; i++) {
std::cout << name << ": " << i << std::endl;
std::this_thread::sleep_for(200ms);
}
}
// t1: 0
// t1: 1
// t1: 2
// t1: 3
// t1: 4
// t2: 0
// t2: 1
// t2: 2
// t2: 3
// t2: 4
在3中,作者基于RAII原则实现了一个互斥锁,其功能和std::lock_guard类似。
其他的诸如管理文件描述符,套接字,登陆信息的上下文等,使用RAII规则时类似。
25.手撕:Unique_ptr,控制权转移(移动语义)手撕:类继承,堆栈上分别代码实现多态
1.手撕 Unique_ptr,控制权转移(移动语义)
Unique_ptr 是 C++11 标准库中的一个智能指针类,用于管理动态分配的资源。它通过 RAII 技术实现自动释放所管理的资源,并且支持控制权转移(move semantics),可以将指针对象的所有权从一个对象转移到另一个对象。
以下是手撕 Unique_ptr 的示例代码:
template <typename T>
class Unique_ptr {
public:
// 构造函数:初始化指针为 nullptr
Unique_ptr() : ptr(nullptr) {}
// 构造函数:接收一个原始指针作为参数
explicit Unique_ptr(T* p) : ptr(p) {}
// 移动构造函数:将右值引用转移赋值给左值引用
Unique_ptr(Unique_ptr&& other) noexcept {
this->ptr = other.ptr;
other.ptr = nullptr;
}
// 析构函数:自动释放所管理的资源
~Unique_ptr() {
delete ptr;
}
// 按值交换函数:使用 std::swap 实现快速交换两个对象
void swap(Unique_ptr& other) noexcept {
std::swap(this->ptr, other.ptr);
}
// 赋值运算符重载:支持控制权转移(move semantics)
Unique_ptr& operator=(Unique_ptr&& other) noexcept {
if (this != &other) {
delete this->ptr;
this->ptr = other.ptr;
other.ptr = nullptr;
}
return *this;
}
// 禁止拷贝构造函数和拷贝赋值运算符
Unique_ptr(const Unique_ptr&) = delete;
Unique_ptr& operator=(const Unique_ptr&) = delete;
// 获取原始指针的引用
T* get() const noexcept {
return ptr;
}
private:
T* ptr; // 原始指针,不可共享所有权
};
2.手撕类继承,堆栈上分别代码实现多态
类继承和多态是 C++ 面向对象编程中的重要概念。在类之间建立父子关系,可以使得子类继承父类的成员变量和成员函数,并且可以通过虚函数实现多态。
以下是手撕类继承并在堆栈上分别创建父子类对象并调用虚函数的示例代码:
#include <iostream>
class Base {
public:
virtual void foo() {
std::cout << "Base::foo()" << std::endl;
}
};
class Derived : public Base {
public:
void foo() override {
std::cout << "Derived::foo()" << std::endl;
}
};
int main() {
Base b; // 创建基类对象
Derived d; // 创建派生类对象
b.foo(); // 调用基类虚函数
d.foo(); // 调用派生类虚函数
Base* pb = &b; // 基类指针指向基类对象
pb->foo(); // 调用基类虚函数
pb = &d; // 基类指针指向派生类对象
pb->foo(); // 调用派生类虚函数
return 0;
}
此示例中,Base 是父类,Derived 是子类,通过在 Base 中声明一个虚函数 foo(),并在 Derived 中重写该函数实现多态。在 main 函数中分别创建了一个基类对象和一个派生类对象,并调用它们的虚函数。最后将基类指针分别指向基类对象和派生类对象,并调用其虚函数验证多态效果。
26.unique_ptr和shared_ptr区别
shared_ptr 类
shared_ptr 允许多个指针指向同一个对象,智能指针也是模板,定义如下:
shared_ptr<string> p1; //可以指向string
shared_ptr<list<int>> p2; //可以指向int的list
智能指针的使用方式与普通指针类似,解引用一个智能指针返回它指向的对象。例如判断是否为空:
//如果p1不为空,检查它是否指向一个空string
if (p1 && p1->empty())
*p1 = "liusir"; //如果p1指向一个空string,解引用p1,赋新值
shared_ptr 和 unique_ptr 共有操作

shared_ptr 独有操作

make_shared 函数
最安全的分配和使用动态内存的方法是调用一个名为make_shared的标准库函数。此函数在动态内存中分配一个对象并初始化它,返回指向此对象的shared_ptr。
当要用make_shared时,必须指定想要创建的对象的类型,如下:
//指向一个值为42的int的shared_ptr
shared_ptr<int> p3 = make_shared<int>(42);
//p4指向一个值为"9999999999"的string
shared_ptr<string> p4 = make_shared<string>(10,'9');
//p5指向一个值初始化的int,值为0
shared_ptr<int> p5 = make_shared<int>();
也可以使用auto定义一个对象来保存make_shared的结果,更为简单:
//p6指向一个动态分配的空vector<string>
auto p6 = make_shared<vector<string>>();
当进行拷贝或赋值操作时,每个shared_ptr都会记录有多少个其他shared_ptr指向相同的对象:
auto p = make_shared<int>(42); //p指向的对象只有p一个引用者
auto q(p); //p和q指向相同对象,此对象有两个引用者
我们可以认为每个shared_ptr都有一个关联的计数器,通常称其为引用计数。无论何时我们拷贝一个shared_ptr,计数器都会递增。
unique_ptr 类
unique_ptr 独占所指向的对象。与shared_ptr不同,某个时刻只能有一个unique_ptr指向一个给定对象。当unique_ptr被销毁时,它所指向的对象也被销毁。
与shared_ptr不同,没有类似make_shared的标准库函数返回一个unique_ptr。所以初始化unique_ptr必须采用直接初始化形式,如下:
unique_ptr<double> p1; //可以指向一个double的unique_ptr
unique_ptr<int> p2(new int(42)); //p2指向一个值为42的int
由于unique_ptr拥有它指向的对象,因此unique_ptr不支持普通的拷贝或赋值操作:
unique_ptr<string> p1(new string("hello"));
unique_ptr<string> p2(p1); //错误:unique_ptr不支持拷贝
unique_ptr<string> p3;
p3 = p2; //错误:unique_ptr不支持赋值
unique_ptr 独有操作

虽然我们不能拷贝或赋值unique_ptr,但可以通过调用release或者reset将指针的所有权从一个(非const)unique_ptr转移给两一个unique:
unique_ptr<string> u1(new string("hello ls"));
//将所有权从u1转移给u2;
unique_ptr<string> u2(u1.release()); //release将u1置空
unique_ptr<string> u3(new string("u3"));
//将所有权从u3转移给u2
u2.reset(u3.release()); //reset释放了u2原来指向的内存
release成员返回unique_ptr当前保存的指针并将其置空。因此,u2被初始化为u1原来保存的指针,而u1被置空。
调用release会切断unique_ptr和它原来管理的对象间的联系。release返回的指针通常会被用来初始化另一个智能指针或给另一个智能指针赋值。如果我们不用另一个智能指针来保存release返回的指针,我们的程序就要负责资源的释放,如下:
auto u = u2.release(); //删除u2
delete(u);
示例程序:
代码:
#include <iostream>
#include <memory>
#include <string>
using namespace std;
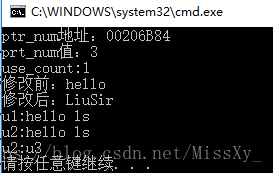
int main()
{
shared_ptr<int> ptr_num;
ptr_num = make_shared<int>(3); //shared_ptr数字为3
cout << "ptr_num地址:" << ptr_num << endl;
cout << "prt_num值:" << *ptr_num << endl;
cout << "use_count:" << ptr_num.use_count() << endl; //查看计数器
shared_ptr<string> ptrStr = make_shared<string>("hello"); //string 类型
cout << "修改前:" << *ptrStr << endl;
if (ptrStr && !ptrStr->empty())
{
*ptrStr = "LiuSir";
}
cout << "修改后:" << *ptrStr << endl;
unique_ptr<string> u1(new string("hello ls"));
cout << "u1:" << *u1 << endl;
//将所有权从u1转移给u2;
unique_ptr<string> u2(u1.release()); //release将u1置空
cout << "u2:" << *u2 << endl;
unique_ptr<string> u3(new string("u3"));
//将所有权从u3转移给u2
u2.reset(u3.release()); //reset释放了u2原来指向的内存
cout << "u2:" << *u2 << endl;
auto u = u2.release(); //删除u2
delete(u);
return 0;
}
运行结果:
27.右值引用
1.右值引用的含义
《C++ primer》第5版中说明了右值引用的含义:
所谓右值引用就是必须绑定到右值的引用
举例来说:
int i = 42;
int &r = i; // 左值引用绑定到左值上
int &&rr = i; // 错误,右值引用不能绑定到左值上
int &&rri = i * 42; //正确,i*42是右值
此外,《C++ primer》中还说明了右值引用的重要性质:
只能绑定到一个将要销毁的对象
需要注意的是,右值引用变量本身是左值,所以不能用一个右值引用变量初始化一个右值引用。
int &&rx = rri; //错误,rri是一个右值引用变量,是左值
那么,到底为什么说一个右值引用变量是一个左值呢?左右值的理解就是,
- 程序员可以取地址的是左值。
- 程序员不能取地址的是右值。
这里,rri是一个变量,具有名字,可以取地址,所以说是左值。
2.左值引用和右值引用的区别
学了左值引用和右值引用,自然要问这两个的区别是什么?左值引用和右值引用的区别就是初始化使用的规则不一样,其余都一样。
左值引用:只能使用左值进行初始化(除了,常量左值引用可以使用字面量初始化)
右值引用:只能使用右值初始化
在使用的时候,左值引用和右值引用无任何区别。
3.编译器如何对待右值引用?
既然右值引用只能绑定到右值上,并且右值引用变量本身是左值,自然就有以下疑问:
问题1:右值引用绑定的是右值,而右值是将要消亡的,但是右值引用变量本身又是左值,左值就代表着是持久的。那么把编译器是如何实现的?
问题2:按照我的这篇随笔中的理解,我把右值理解成水,把引用理解成标签,那么把一个右值引用(标签)绑定到了右值(水)上,就说不通了,怎么解释?
来看一下汇编代码:
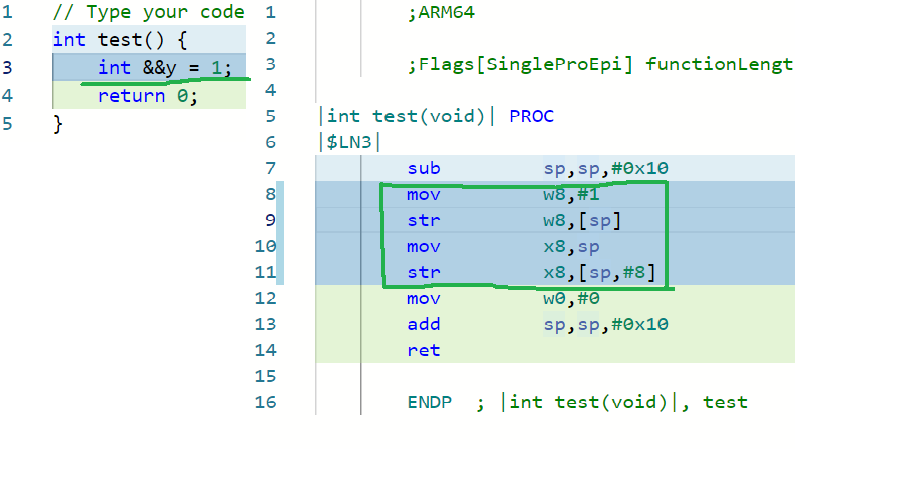
右值引用的反汇编例子
可以看出,当一个右值引用变量绑定到右值的时候,编译器会将右值存储到栈内存中,并且将该地址赋值给右值引用。
也就是说,当一个即将消亡的值被一个右值引用变量绑定时,编译器会先把该值保存到栈上,然后把保存位置的内存地址赋值给右值引用。 从水桶和水的关系解释,编译器先创建了一个水桶,把水倒进水桶,并把标签贴到该水桶上。这就是当一个右值引用绑定到右值时,编译器的做法。
4.用法
当然,平时使用的话还是无需关心编译器怎么处理的细节,只需要关心什么时候能用,什么时候不能用就行了。
什么时候不能用:
- 函数返回内部变量的右值引用:
比如:
int && test() {
int x = 1;
return x + 1; // 未定义行为,最好别用
}
什么时候能用:
右值引用主要的用途:
- 实现移动语义。
- 实现完美转发。
28.函数参数可不可以传右值
当你需要在函数内copy参数 并且 要将copy的结果保存在非该函数的栈内 时。
这两个条件必须同时都满足。
最典型的例子,就是STL的那些支持add操作的容器:因为在你给一个容器add元素时,你第一copy了外面传递进来的元素第二将这个元素存储在了容器里。
比如vector的push_back就有两个版本:一个push_back的参数类型是const &,另一个是&&。
这么做的好处就是如果传递进来的是一个右值,那么此时在push_back里就只需要move而不需要copy。
比如,vec.push_back(MyClass()); // 此时参数为右值,调用第二个版本的push_back
========================== BONUS =========================
如果只满足第一个条件而不满足第二个条件,没有右值引用时我们是这样写的:
void func1(const T &t)
{
T local = t;
// use local
}
上面这个函数,不论传递进来的实参是左值还是右值,结果都是调用了一次copy构造函数
而如果我们这样写:
void func2(T t)
{
// use t
}
此时如果传递进来左值,那么依然调用了一次copy构造函数;而如果传递进来了右值,则调用的是move构造函数。
那么问题来了:在只满足第一个条件的前提下,我们是不是应该彻底放弃const T &而全部使用值传递呢?这个问题等效于:是不是move一定比copy好所以能move就应该尽量move?
答案是:NO。
现在很多“大牛”喜欢这么写:
MyClass::Myclass(std::string str) : str_member(std::move(str)){}
在上面这行代码中,如果实参是左值,则调用一次copy一次move;如果实参是右值,则调用两次move。
而如果我们依然用以前的const std::string &str做参数,则不论实参是左值还是右值,均调用一次copy。
很显然,“大牛”默认了一个事实:
move的代价很低、低到多做一次move没什么关系(实参为左值时);而copy代价非常高,高到用两次move换一次copy都是很值得(实参为右值时)。
因此,如果你的参数类型的确符合上面的事实,那么按照“大牛"的做法就是没问题的;但是并非所有的参数类型都符合上述事实。
以std::string为例:
因为当你传递std::string为参数且这个字符串的长度并不十分长时,如果用func1的方法,编译器是可以做一些优化工作的(SSO: small string optimization 这种优化是基于string内部的char *);而如果你用func2,SSO就不存在了而SSO要比“把copy改成move所带来的优化”更优。(Effective Modern C++)
退一步讲,即使没有“短小的std::string”的优化问题,对于那些体量小的、不存在需要考虑深拷贝和浅拷贝差别的、甚至只会使用trivial构造的类,我们依然可以使用func1的方式,就算你换用func2,对效率的提升是微乎其微甚至是不存在的。
而如果连第一个条件都不满足,怎么办?
很显然,答案是:以前怎样现在还怎样。
如果你并不在函数内copy参数,那么const T &显然是最好的方法。
29.参考c/c++堆栈实现自己的堆栈。要求:不能用stl容器。
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。经分析,C++实现堆栈,程序应实现入栈、出栈、判断栈的状态(主要是判断栈是否为空,是否为满)、获取栈顶元素、求栈的长度、清空栈中元素、输出栈中元素、销毁栈这八大功能。于是,写了一个利用数组实现这些功能的简单的程序。
#include<iostream>
using namespace std;
const int maxsize=5;
class Stack
{
public:
Stack() //构造函数,定义一个空栈
{
a=new int[maxsize];
top=0;
}
~Stack(){} //析构函数
void Push(int e); //入栈
void Pop(); //出栈
void GetTop(); //读栈顶元素
int StackSize(); //求栈长
void ClearStack(Stack s); //清空栈
bool IsEmpty(); //判断栈是否为空
bool IsFull(); //判断栈是否为满
bool Destroy(); //销毁栈
void Print(); //输出栈中元素
private:
int *a;
int top;
};
void Stack::Push(int e)
{
if(!IsFull())
{
a[top++]=e;
}
else
cout<<"栈已满,"<<e<<"未入栈!"<<endl;
}
void Stack::Pop()
{
if(!IsEmpty())
{
top--;
}
else
cout<<"栈为空!"<<endl;
}
void Stack::GetTop()
{
cout<<"栈顶元素为:"<<a[top-1]<<endl;
}
int Stack::StackSize()
{
return top;
}
void Stack::ClearStack(Stack s)
{
while(top!=0)
{
s.Pop();
top--;
}
}
bool Stack::IsEmpty()
{
if(top==0)
return true;
else
return false;
}
bool Stack::IsFull()
{
if(top>=maxsize)
return true;
else
return false;
}
bool Stack::Destroy()
{
delete this;
return true;
}
void Stack::Print()
{
if(!IsEmpty())
{
int i=top-1;
cout<<"栈内元素为:";
while(i>=0)
{
cout<<a[i]<<" ";
i--;
}
cout<<endl;
}
else
cout<<"栈为空!"<<endl;
}
void function(Stack S)
{
int n,e,i,j,k=1;
while(k){
cout<<"Please choose one function\n1:入栈\n2:求栈长\n3:读栈顶元素\n4:出栈\n5:判空\n6:判满\n7:输出栈\n8:将栈清空\n9:销毁栈\n10:退出"<<endl;
cin>>i;
switch(i)
{
case 1:
j=0;
cout<<"Please input the number of elements less than "<<maxsize<<":"<<endl;
cin>>n;
if(n>maxsize)
{
cout<<"error,please input again:"<<endl;
cin>>n;
}
while(j<n)
{
cout<<"Please input new element:"<<endl;
cin>>e;
S.Push(e);
j++;
}
break;
case 2:
cout<<"栈的长度为:"<<S.StackSize()<<endl;
break;
case 3:
S.GetTop();
break;
case 4:
S.Pop();
cout<<"已出栈!"<<endl;
break;
case 5:
if(S.IsEmpty())
cout<<"该栈为空!"<<endl;
else
cout<<"该栈不空!"<<endl;
break;
case 6:
if(S.IsFull())
cout<<"该栈已满!"<<endl;
else
cout<<"该栈未满!"<<endl;
break;
case 7:
S.Print();
break;
case 8:
S.ClearStack(S);
cout<<"已清空!"<<endl;
break;
case 9:
cout<<"栈已销毁!"<<endl;
case 10:
k=0;
break;
}
}
}
int main()
{
Stack St;
function(St);
return 0;
}
30.stl容器了解吗?底层如何实现:vector数组,map红黑树,红黑树的实现
1.vector
vector 的底层实现是一个动态数组,使用连续的内存空间存储元素。当向 vector 中添加元素时,如果当前容量不足,则会重新分配一段更大的内存空间,并将原有数据复制到新的内存空间中。
2.map
map 的底层实现是一棵红黑树(Red-Black Tree),它是一种自平衡二叉查找树。在红黑树上进行插入、删除和查找操作的时间复杂度均为 O(log n)。
3.unordered_map
unordered_map 的底层实现是一个哈希表(Hash Table)。当向 unordered_map 中添加元素时,会计算每个元素的哈希值,并将其放入对应的桶中。多个元素可能会散落在同一个桶中,因此每个桶都需要维护一个链表或者红黑树来处理冲突。
4.list
list 的底层实现是一个双向链表,每个节点保存前后两个指针和一个数据项。由于节点之间并不连续,所以无法通过下标随机访问元素。但由于可以在常数时间内插入或删除节点,在某些场景下比 vector 更加高效。
5.deque
deque(Double Ended Queue)也称作双端队列,它的底层实现是一个动态数组的序列,每个节点都是固定大小的块。deque 的特点是支持在队首和队尾进行常数时间的插入和删除操作,并且可以通过下标随机访问元素。
6.set
set 的底层实现也是一棵红黑树(Red-Black Tree)。由于红黑树具有自平衡性质,因此所有操作的时间复杂度均为 O(log n)。
7.unordered_set
unordered_set 的底层实现是一个哈希表(Hash Table),每个桶中保存了若干个元素。当添加或查找元素时,先计算元素的哈希值并确定所在的桶,然后对桶中所有元素进行线性查找或使用开放地址法解决冲突。
8.queue
queue 是一个先进先出(FIFO)的数据结构。其底层实现可以采用 vector 或者 deque。
9.priority_queue
priority_queue 是一个优先级队列,内部维护了一个堆(Heap),默认情况下使用大根堆来存储元素。其底层实现可以采用 vector 或者 deque。
31.完美转发介绍一下 去掉std::forward会怎样?
完美转发是一种 C++ 技术,用于在函数模板中精确地将参数传递到另一个函数,同时保留原始参数的类型信息和左右值属性。它是通过使用通用引用(也称为万能引用)和 std::forward 函数来实现的。
通常情况下,在编写函数模板时,我们需要将传递给函数的参数传递给另一个函数。例如:
template<typename T>
void foo(T arg) {
bar(arg);
}
在上面的代码中,我们定义了一个函数模板 foo,其中的参数 arg 是一个模板参数类型,它会被传递给另一个函数 bar,但是这样会丢失一些信息,例如参数的左右值属性、是否为 const 或 volatile 限定符等等。
为了避免这种情况,可以使用通用引用和 std::forward 函数来实现完美转发。例如:
template<typename T>
void foo(T&& arg) {
bar(std::forward<T>(arg));
}
在上面的代码中,我们使用 T&& 声明了一个通用引用类型的参数 arg,然后利用 std::forward 函数将 arg 转发给另一个函数 bar。std::forward 函数会根据参数的左右值属性和类型信息,正确地将参数转发给目标函数,并保留原始参数的所有属性。
完美转发是一种 C++ 技术,可以在函数模板中精确地传递参数,同时保留原始参数的类型信息和左右值属性。它是通过使用通用引用和 std::forward 函数来实现的。掌握它的用法可以提高代码的可读性和效率。
std::forward()函数的使用
std::forward 是一个 C++11 中的库函数,用于实现完美转发。它可以将给定的参数转发到另一个函数中去,并保留原始参数的类型信息和左右值属性。
std::forward 主要用于处理通用引用类型(即使用 && 或 template T&& 声明的类型),这些类型可能是左值引用或右值引用,也可能是 const 或 volatile 限定符。通过使用 std::forward,我们可以将这些通用引用类型的参数精确地传递到目标函数中去,避免不必要的拷贝操作。
以下是 std::forward 的语法:
template <typename T>
T&& forward(typename std::remove_reference<T>::type& arg) noexcept;
template <typename T>
T&& forward(typename std::remove_reference<T>::type&& arg) noexcept;
示例代码如下:
#include <iostream>
#include <utility>
void print(const std::string& str) {
std::cout << "Lvalue: " << str << std::endl;
}
void print(std::string&& str) {
std::cout << "Rvalue: " << str << std::endl;
}
template<typename T>
void foo(T&& arg) {
print(std::forward<T>(arg));
}
int main() {
std::string s = "Hello, world!";
foo(s); // Lvalue: Hello, world!
foo(std::move(s)); // Rvalue: Hello, world!
return 0;
}
在上面的示例代码中,我们定义了两个函数 print,一个接受左值引用类型的参数,另一个接受右值引用类型的参数。然后,我们定义了一个模板函数 foo,其中的参数 arg 是一个通用引用类型,可以同时接受左值引用和右值引用。
在 foo 函数中,我们使用 std::forward 函数将 arg 转发给 print 函数,并保留原始参数的类型信息和左右值属性。当我们传递一个左值时,arg 的类型被推导为 std::string& 类型,然后使用 std::forwardstd::string& 将参数转发给 print(const std::string&) 函数。而当我们传递一个右值时,arg 的类型被推导为 std::string&& 类型,然后使用 std::forwardstd::string&& 将参数转发给 print(std::string&&) 函数。
总之,在 C++ 中,std::forward 函数的作用是实现完美转发,它可以将通用引用类型的参数精确地传递到目标函数中去,并保留原始参数的类型信息和左右值属性。
32.完美转发介绍一下 去掉std::forward会怎样?
完美转发是一种 C++ 技术,用于在函数模板中精确地将参数传递到另一个函数,同时保留原始参数的类型信息和左右值属性。它是通过使用通用引用(也称为万能引用)和 std::forward 函数来实现的。
通常情况下,在编写函数模板时,我们需要将传递给函数的参数传递给另一个函数。例如:
template<typename T>
void foo(T arg) {
bar(arg);
}
在上面的代码中,我们定义了一个函数模板 foo,其中的参数 arg 是一个模板参数类型,它会被传递给另一个函数 bar,但是这样会丢失一些信息,例如参数的左右值属性、是否为 const 或 volatile 限定符等等。
为了避免这种情况,可以使用通用引用和 std::forward 函数来实现完美转发。例如:
template<typename T>
void foo(T&& arg) {
bar(std::forward<T>(arg));
}
在上面的代码中,我们使用 T&& 声明了一个通用引用类型的参数 arg,然后利用 std::forward 函数将 arg 转发给另一个函数 bar。std::forward 函数会根据参数的左右值属性和类型信息,正确地将参数转发给目标函数,并保留原始参数的所有属性。
完美转发是一种 C++ 技术,可以在函数模板中精确地传递参数,同时保留原始参数的类型信息和左右值属性。它是通过使用通用引用和 std::forward 函数来实现的。掌握它的用法可以提高代码的可读性和效率。
std::forward()函数的使用
std::forward 是一个 C++11 中的库函数,用于实现完美转发。它可以将给定的参数转发到另一个函数中去,并保留原始参数的类型信息和左右值属性。
std::forward 主要用于处理通用引用类型(即使用 && 或 template T&& 声明的类型),这些类型可能是左值引用或右值引用,也可能是 const 或 volatile 限定符。通过使用 std::forward,我们可以将这些通用引用类型的参数精确地传递到目标函数中去,避免不必要的拷贝操作。
以下是 std::forward 的语法:
template <typename T>
T&& forward(typename std::remove_reference<T>::type& arg) noexcept;
template <typename T>
T&& forward(typename std::remove_reference<T>::type&& arg) noexcept;
示例代码如下:
#include <iostream>
#include <utility>
void print(const std::string& str) {
std::cout << "Lvalue: " << str << std::endl;
}
void print(std::string&& str) {
std::cout << "Rvalue: " << str << std::endl;
}
template<typename T>
void foo(T&& arg) {
print(std::forward<T>(arg));
}
int main() {
std::string s = "Hello, world!";
foo(s); // Lvalue: Hello, world!
foo(std::move(s)); // Rvalue: Hello, world!
return 0;
}
在上面的示例代码中,我们定义了两个函数 print,一个接受左值引用类型的参数,另一个接受右值引用类型的参数。然后,我们定义了一个模板函数 foo,其中的参数 arg 是一个通用引用类型,可以同时接受左值引用和右值引用。
在 foo 函数中,我们使用 std::forward 函数将 arg 转发给 print 函数,并保留原始参数的类型信息和左右值属性。当我们传递一个左值时,arg 的类型被推导为 std::string& 类型,然后使用 std::forwardstd::string& 将参数转发给 print(const std::string&) 函数。而当我们传递一个右值时,arg 的类型被推导为 std::string&& 类型,然后使用 std::forwardstd::string&& 将参数转发给 print(std::string&&) 函数。
总之,在 C++ 中,std::forward 函数的作用是实现完美转发,它可以将通用引用类型的参数精确地传递到目标函数中去,并保留原始参数的类型信息和左右值属性。
32.介绍一下unique_lock和lock_guard区别?
1.锁
锁用来在多线程访问同一个资源时防止数据竞险,保证数据的一致性访问。多线程本来就是为了提高效率和响应速度,但锁的使用又限制了多线程的并行执行,这会降低效率,但为了保证数据正确,不得不使用锁,它们就是这样纠缠。
本文主要讨论 c++11 中的两种锁:lock_guard 和 unique_lock。这两种锁都可以对std::mutex进行封装,实现RAII的效果。绝大多数情况下这两种锁是可以互相替代的,区别是unique_lock比lock_guard能提供更多的功能特性(但需要付出性能的一些代价)
结合锁进行线程间同步的条件变量使用,请参考条件变量 condition variable 。
2.lock_guard
lock_guard 通常用来管理一个 std::mutex 类型的对象,通过定义一个 lock_guard 一个对象来管理 std::mutex 的上锁和解锁。在 lock_guard 初始化的时候进行上锁,然后在 lock_guard 析构的时候进行解锁。这样避免了人为的对 std::mutex 的上锁和解锁的管理。
定义如下:
template<class Mutex> class lock_guard;
它的特点如下:
(1) 创建即加锁,作用域结束自动析构并解锁,无需手工解锁
(2) 不能中途解锁,必须等作用域结束才解锁
(3) 不能复制
注意:
lock_guard 并不管理 std::mutex 对象的声明周期,也就是说在使用 lock_guard 的过程中,如果 std::mutex 的对象被释放了,那么在 lock_guard 析构的时候进行解锁就会出现空指针错误。
示例代码如下:
#include <thread>
#include <mutex>
#include <iostream>
int g_i = 0;
std::mutex g_i_mutex;
void safe_increment()
{
const std::lock_guard<std::mutex> lock(g_i_mutex);
++g_i;
std::cout << std::this_thread::get_id() << ": " << g_i << '\n';
}
int main()
{
std::cout << "main: " << g_i << '\n';
std::thread t1(safe_increment);
std::thread t2(safe_increment);
t1.join();
t2.join();
std::cout << "main: " << g_i << '\n';
}
输出:
main: 0
140641306900224: 1
140641298507520: 2
main: 2
3.unique_lock
unique_lock 和 lock_guard 一样,对 std::mutex 类型的互斥量的上锁和解锁进行管理,一样也不管理 std::mutex 类型的互斥量的声明周期。但是它的使用更加的灵活,支持的构造函数如下:

简单地讲,unique_lock 是 lock_guard 的升级加强版,它具有 lock_guard 的所有功能,同时又具有其他很多方法,使用起来更强灵活方便,能够应对更复杂的锁定需要。
特点如下:
- 创建时可以不锁定(通过指定第二个参数为 std::defer_lock),而在需要时再锁定
- 可以随时加锁解锁
- 作用域规则同 lock_grard,析构时自动释放锁
- 不可复制,可移动
- 条件变量需要该类型的锁作为参数(此时必须使用 unique_lock)
示例代码:
#include <mutex>
#include <thread>
#include <chrono>
struct Box {
explicit Box(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void transfer(Box &from, Box &to, int num)
{
std::unique_lock<std::mutex> lock1(from.m, std::defer_lock);
std::unique_lock<std::mutex> lock2(to.m, std::defer_lock);
std::lock(lock1, lock2);
from.num_things -= num;
to.num_things += num;
}
int main()
{
Box acc1(100);
Box acc2(50);
std::thread t1(transfer, std::ref(acc1), std::ref(acc2), 10);
std::thread t2(transfer, std::ref(acc2), std::ref(acc1), 5);
t1.join();
t2.join();
}
4.总结
所有 lock_guard 能够做到的事情,都可以使用 unique_lock 做到,反之则不然。
那么何时使用 lock_guard 呢?很简单,需要使用锁的时候,首先考虑使用 lock_guard。它简单、明了、易读。如果用它完全 ok,就不要考虑其他了。如果现实不允许,再使用 unique_lock 。
33.C代码中引用C++代码有时候会报错为什么?
在C代码中引用C++代码可能会导致以下问题:
- 名称空间问题:C语言没有命名空间的概念,而C++有。因此,在引用C++代码时,需要使用特定的方式指定命名空间。如果未正确指定命名空间,则会出现名称冲突和编译错误。
- C++特有的关键字:C++中有一些关键字(如new、delete等)是在C语言中不存在的,因此在引用C++代码时需要注意这些关键字是否与C语言中已存在的标识符重复。
- 类型转换问题:由于C和C++对类型转换的机制不同,因此在引用C++代码时需要注意类型转换是否正确。
- 编译器差异:由于不同编译器实现不同,在编译混合代码时可能会遇到一些编译器相关的问题。
为了解决这些问题,可以采取以下措施:
- 在头文件中使用extern "C"声明来告知编译器该部分为纯粹的“C”语言,以免发生函数命名错误或者变量名重复等情况。
- 将被调用函数放入一个独立的源文件中进行编写,并将其链接到应用程序。
- 在调用 C++ 函数时尽量不要涉及 C++ 特有的内容(例如类、模板等),尽可能地使用 C 风格的语言特性,以免出现类型转换问题。
- 确保使用相同版本的编译器和链接器,并且在项目中使用统一的编译选项。
34.静态多态有什么?
静态多态是指在编译期确定函数的调用方式,也称为编译时多态。其主要实现方式是函数重载和运算符重载。
1.函数重载:同名函数可以有不同的参数列表和返回类型,编译器会根据传入的参数类型、数量和顺序等信息来确定具体调用哪个函数。例如:
int add(int a, int b) {
return a + b;
}
double add(double a, double b) {
return a + b;
}
2.运算符重载:对于某些运算符(如+、-、*、/等),C++允许程序员自定义该运算符在特定情况下的行为。例如:
class Vector {
public:
Vector operator+(const Vector& rhs) const {
Vector result(x + rhs.x, y + rhs.y);
return result;
}
private:
double x, y;
};
静态多态的优点是效率高,因为函数调用过程在编译期已经确定了,不需要再在运行时进行查找。缺点是灵活性较差,一旦确定了函数的调用方式,在运行时无法改变。
35.map为啥用红黑树不用avl树?(几乎所有面试都问了map和unordered_map区别)
红黑树:适用于大量插入和删除,因为它是非严格的平衡树;只要从根节点到叶子节点的最长路径不超过最短路径的2倍,就不用进行平衡调节.查找效率是 O(logn),红黑树舍去了严格的平衡,使其插入,删除,查找的效率稳定在 O(logn)
HashMap查找时间复杂度:
- 在没有地址冲突时,效率 O(1)
- 有少量地址冲突,在冲突的地址拉链(建链表),效率在 O(1) ~ O(logn) 之间
- 有大量地址冲突,在冲突的地址建红黑树,效率 O(logn)
**AVL树:**AVL 树是严格的平衡树,上述的最短路径与最长路径的差不能超过 1,AVL 允许的差值小;在进行大量插入和删除操作时,会频繁地进行平衡调整,严重降低效率;AVL也是 O(logn);查找没问题 O(logn),但是为了保证高度平衡,动态插入和删除的代价也随之增加,综合效率肯定达不到 O(logn)
36.inline 失效场景
inline函数在以下情况下可能会失效:
- 函数体过大:当函数体非常庞大时,编译器可能会放弃将其展开成内联代码。因为将大量的代码复制到调用点可能会导致代码膨胀,反而影响程序性能。
- 函数中含有循环或递归:如果函数中含有循环或递归等结构,那么展开成内联代码后可能会导致代码量增加,反而降低程序的执行效率。
- 调用处过多:如果一个内联函数被频繁地调用,在展开成内联代码后可能会导致可执行文件大小增加、缓存未命中率升高等问题,从而影响程序性能。
- 对于虚函数、递归函数和带有动态绑定(如多态)的函数通常不会进行内联优化。
- 编译器限制:一些编译器对于inline关键字并不完全支持。比如某些编译器可能只支持inline关键字作为建议,并不能保证将其视为强制要求来处理。
37.C++ 中 struct 和 class 区别
1.C++中struct和class的区别
C++中的struct其实是为了与C的兼容性而留下来的。
C++的struct和class其实大部分都是相同的用法,基本上可以用class做的事都可以用struct来进行
两者都可以继承,都有成员函数,都可以有构造函数和析构函数
但是主要使用来说,struct常用于表示多种数据类型的集合,而类是用户自定义数据类型
下面我们讲几点区别
1.1 默认权限不同
权限分为成员访问权限和继承权限
默认成员权限:class是私有的,struct是公有的
默认继承权限:class是private,struct是public
1.2是否能定义模板参数
class可以定义模板参数 template,而没有template
2.C++的struct和C的struct区别
2.1 C语言中:struct是用户自定义数据类型(UDT);C++中struct是抽象数据类型(ADT),支持成员函数的定义,(C++中的struct能继承,能实现多态)
2.2 C中struct是没有权限的设置的,且struct中只能是一些变量的集合体,可以封装数据却不可以隐藏数据,而且成员不可以是函数
2.3 C++中,struct增加了访问权限,且可以和类一样有成员函数,成员默认访问说明符为public(为了与C兼容)
2.4 struct作为类的一种特例是用来自定义数据结构的。一个结构标记声明后,在C中必须在结构标记前加上struct,才能做结构类型名(除:typedef struct class{};);C++中结构体标记(结构体名)可以直接作为结构体类型名使用,此外结构体struct在C++中被当作类的一种特例
38.如何防止一个头文件 include 多次
前言:一般来说,程序员会遵守只包含一次头文件的规则,但会有一种情况程序员可能在不知情的情况下多次包含同一个头文件,即可能使用了包含另一个头文件的头文件。
例如:如下三个文件
// 头文件h1.h
...//文件内容
//头文件h2.h
#include"h1.h"//包含头文件h1.h
...//文件内容
//源文件c.cpp
#include"h1.h"
#include"h2.h"//这时由于头文件h2.h中已经包含过头文件h1.h,因此头文件h1.h被重复包含
...//文件内容
解决方法:使用预处理编译指令#ifndef(if not define)
//头文件h1.h
#ifndf H1
#define H1
...//文件内容
#endif
解释:
在所有头文件中加上如上的三行代码,编译器在首次遇到该文件时,H1还没有被定义,则将继续执行#ifndef和#endif之间的内容,并且其中#define H1语句定义了H1。如果在源文件中重复包含这个一个头文件时,编译器会第二次遇到该文件,由于第一次遇到时#define H1语句定义了H1,于是在第二次遇到该文件并执行#ifndef H1时会发现已经定义过H1,于是跳过#ifndef和#endif之间的内容,避免重复执行执行头文件中内容(比如结构声明,函数声明,函数定义等)。
注:#ifndf 后的名称是自己选择的,尽量选择一个在其他地方一般不太可能被定义的名称,以免重复定义。
39.lambda表达式的理解,它可以捕获哪些类型
1.lambda表达式
等价于匿名函数对象,又称为“闭包”(closure),更便捷,表达更直接。表达式要素包括:
1:捕获列表
2:参数列表
3:mutable修饰符,表达传值或传引用
4:noexcept
5:返回值类型声明 ->
6:表达式体{...}
lambda表达式可接受参数,可返回值,可模板化,也可以通过传值或传引用从闭包范围内访问变量。
编译器将lambda表达式编译为具名函数对象
2.捕获列表
lambda表达式,从闭包作用域捕获变量而获得状态,分为传值和传引用。
捕获变量登记与函数对象中的示例数据成员。
[=] 值捕获所有变量
[&] 引用捕获所有变量
[&x] 引用捕获x变量
[x] 值捕获x
[=,&x] 默认值捕获,x变量通过引用捕获
[&,x] 默认引用捕获,x通过值捕获
[this] 捕获当前对象,可访问所有共有成员,C++20中不允许隐式捕获this
[=,x],[&,&x] 错误,重复指定
注意:即便默认要值捕获,全局变量总是使用引用捕获
使用初始化捕获表达式表达move捕获
3.示例及分析
#include <iostream>
#include <vector>
using namespace std;
class Point{
public:
double x;
double y;
void print() const {
std::cout << x<< ", "<<y<<endl;;
}
};
int number=100; //全局变量可以在lambda修改,跨越所有,捕获类型管理不到
int main()
{
Point p1{100,200};
Point p2{100,200};
//=表示值捕获,就是将外部变量拷贝进来,声明的时候,只能用auto,因为是匿名对象
//如果没有mutable,会报错,不允许修改p1,p2;如果修改捕获对象,就需要mutable
auto lambda1 = [=] (int n) mutable //p1,p2为外部变量,实际调用了拷贝构造函数
{
p1.x+=n; //从外部拷贝进来了,此处修改不影响外部p1
p1.y+=n;
p2.x+=n;
p2.y+=n;
p1.print(); //print()有个const,如果此时p1,p2没修改(即上面4行不存在),如果print没有const,lambda也需要mutable(编译器认为调用函数也可能更改了)
p2.print();
number++; //全局变量直接使用
};
//Lambda_Value lambda1(p1,p2);
lambda1(10); //外部看不到p1,p2,打印110,210
lambda1(10); //多执行一次,会改变lambda对象内部的p1,p2,栈上的lambda对象没有销毁,120,220
p1.print(); //不改变外部的p1,p2,所以此处打印是一样的,100,200
p2.print();
cout<<sizeof(lambda1)<<endl; //没有捕获,就是一个空类,有捕获后,就有32byte
cout<<sizeof(Point)<<endl; //
cout<<"lambda1------------"<<endl;
auto lambda2 = [&] (int n) //引用捕获,不用mutable,lambda内部修改会传递到外部
{
p1.print();
p2.print();
p1.x+=n;
p1.y+=n;
p2.x+=n;
p2.y+=n;
number++; //全局的执行也有效果
};
//Lambda_Ref lambda2(p1,p2);
lambda2(100);//p1,p2先打印原始值,之后 p1:200,300; p2:200,300
p1.print(); //200,300
p2.print();
p1.x+=5; //p1.x = 205
p1.y+=5; //p1.y = 305
p2.x+=5;
p2.y+=5;
lambda2(100); //引用捕获,外部更改也会影响引用捕获内部变量,先打印205,305,之后305,405
//return lambda2; //隐蔽错误,因为lambda2是引用捕获,函数返回后,p1,p2销毁了,值捕获就没有问题
cout<<number<<endl; //lambda内部修改此处表现出来了
cout<<sizeof(lambda2)<<endl;//只是引用,大小不计算引用参数大小
cout<<"lambda2------------"<<endl;
auto lambda3 = [=, &p1] () //默认值捕获,但p1使用引用捕获
{
p1.x++;
p1.y++; //p1修改外部更改,306,406
p2.print(); //值捕获305,405
};
lambda3();
//auto lambda4 = [ &, &p1] () 或者 auto lambda4 = [ =, p1] () 都是重复性错误
auto lambda4 = [ &, p1] () //默认引用捕获,p1是值捕获
{
p1.print();
p2.x++; //引用捕获,p2:306,406
p2.y++;
};
lambda4();
// auto lambda5 = [p2, &number] () //失败,number不能
auto lambda5 = [p2] () //单独对p2值捕获
{
p2.print(); //306,406
};
lambda5();
auto lambda6 = [&p1] () //单独对p1引用捕获
{
p1.x++;
p1.y++;
};
lambda6();
}
4.捕获原理
//引用lambda内存模型,表达式内部p1,p2就是外部的p1,p2
//引用就是同一个地址,本质就是一个别名
struct Lambda_Ref{
//引用就是一个指针,就是8byte,引用的大小固定了
Point& p1; //生命周期不好管理
Point& p2;
Lambda_Ref( Point& p1, Point& p2):p1(p1),p2(p2)
{
}
void operator()(int n) {
p1.x+=n;
p1.y+=n;
p2.x+=n;
p2.y+=n;
}
};
//值捕获生成的代码
struct Lambda_Value{
Point p1;
Point p2;
Lambda_Value(const Point& p1, const Point& p2):p1(p1),p2(p2) //传值,拷贝
{
}
void operator()(int n) {
p1.x+=n;
p1.y+=n;
p2.x+=n;
p2.y+=n;
}
};
5.编译、结果输出
kongcb@tcu-pc:~/testcode/lambda$ g++ lamba_capture.cpp -o lamba_capture
kongcb@tcu-pc:~/testcode/lambda$ ./lamba_capture
110, 210
110, 210
120, 220
120, 220
100, 200
100, 200
32
16
lambda1------------
100, 200
100, 200
200, 300
200, 300
205, 305
205, 305
104
16
lambda2------------
305, 405
306, 406
306, 406
40.友元friend介绍
友元是指:
采用类的机制后实现了数据的隐藏与封装,类的数据成员一般定义为私有成员,成员函数一般定义为公有的,依此提供类与外界间的通信接口。但是,有时需要定义一些函数,这些函数不是类的一部分(注意友元函数不是类的一部分),但又需要频繁地访问类的数据成员,这时可以将这些函数定义为该函数的友元函数。除了友元函数外,还有友元类,两者统称为友元。友元的作用是提高了程序的运行效率(即减少了类型检查和安全性检查等都需要时间开销),但它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。
class` `Data{
``public` `:
``...``friend ` `int` `set` `(` `int` `&m);` `//友元函数friend class peop; //友元类``...
``}
友元分为友元函数和友元类,两种具有不同的调用形式:
A友元函数:
友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以
声明,声明时只需在友元的名称前加上关键字friend,其格式如下:
friend 类型 函数名(形式参数);
1.友元函数的声明可以放在类的私有部分,也可以放在公有部分,它们是没有区别的,都说明是该类的一个友元函数。
2.一个函数可以是多个类的友元函数,只需要在各个类中分别声明。友元函数的调用与一般函数的调用方式和原理一致。
B友元类
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。当希望一个
类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。
例如,以下语句说明类B是类A的友元类:
class A{
…
public:
friend class B;
…
};
经过以上说明后,类B的所有成员函数都是类A的友元函数,能存取类A的私有成员和保护成员。
使用友元类时注意:
(1) 友元关系不能被继承。
(2) 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
(3) 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明
(4) 友元函数并不是类的成员函数,因此在类外定义的时候不能加上class::function name
下面我们完整的看一个友元的例子:

1 #include
2 #include
3 class Point//声明
4 {
5 public:
6 Point(double xx, double yy) { x=xx; y=yy; }//默认构造函数
7 void Getxy();//公有成员函数
8 friend double Distance(Point &a, Point &b);//友元函数
9 private:
10 double x, y;
11 };
12
13 void Point::Getxy()
14 {
15 cout<<"("<
16 }
17
18 double Distance(Point &a, Point &b) //注意函数名前未加类声明符
19 {
20 double dx = a.x - b.x;
21 double dy = a.y - b.y;
22 return sqrt(dx*dx+dy*dy);
23 }
24
25 void main()
26 {
27 Point p1(3.0, 4.0), p2(6.0, 8.0);
28 p1.Getxy();
29 p2.Getxy();
30 double d = Distance(p1, p2);
31 cout<<"Distance is"<
32 }
41.move函数
1.值类型(value category)

此图片取自https://zh.cppreference.com/w/cpp/language/value_category网站,这里介绍了C++的所用值类型,但常用的只有后两个,左值,右值,那左值,右值是什么呢?很多博客视频都有介绍很多很多,听得头都大了,那还是用我们自己的话说吧!
左值:可以出现在 operator= 左侧的值;
右值:可以出现在 operator= 右侧的值;
当然这并不是全部正确的,但百分之90多都是这种情况,但有例外:
std::string();类似这种一个类加括号也就是临时变量都是右值;
函数的形参永远是左值;
好了记住红色部分就能分清楚C++值类型了,这个就是基础了,是不是很简单呢,cool,那么下来我们就看看什么是移动语义了。
2.移动语义
移动究竟是干什么呢?我们还是不看那令人头痛的官方解释了,真的会令人栓Q,我还是用我自己理解的话说吧,方便理解和记忆,他就是这么一个情况:
假如我们有两个指针 一个指针A,一个指针B,指针A指向了一个很复杂的内容,此时我们需要指针B指向这个很复杂的内容,之后我们就不需要指针A了,它可以滚蛋了,可以析构掉了,这个就是移动语义,结果就是将原来指针A指向的内存交给了指针B,指针A不指向任何内存。相当于B偷走了A的东西。
相对的有移动语义就有复制语义,复制语义就是B指针要想获得同样的内容就会发生拷贝,大部分都是深拷贝(浅拷贝,深拷贝有机会我会补上一篇博客的),结果就是指针A指向一片内存,指针B指向了另一片内存,但两片内存中存储的内容是相同的,大大的浪费性能。
那我们如何实现我们想要的效果呢?就是move语句了
3.std::move
终于到move了,有了上面几个基础就可以开始理解move是什么了,首先记住一句话:
std::move 并不会进行任何移动
好家伙,什么啊,一下整蒙了move不进行移动,别急我们先看一下例子
#include<vector>
class Vector
{
private:
int x, y, z;
public:
Vector(int x, int y, int z) :x(x), y(y), z(z) {}
};
int main()
{
std::vector<Vector> vec;
vec.push_back(Vector(1,2,3));//2
Vector a(4,5,6);
vec.push_back(a);//1
vec.push_back(std::move(a));//2
}
我们来看一下这段代码,第一个push_back里是一个临时变量还记得吗?临时变量都是右值,第二个push_back,因为a是个左值所以传入的参数是个左值,第三个push_back我们使用了move方法本质上我们希望他变成一个右值进而发生移动语义,就是一个偷的过程,而不是复制的过程,让我们进到源码里看看是什么情况.要记住move 它不进行任何移动.还要知道一件事:
在运行期move是无作为的.
_CONSTEXPR20_CONTAINER void push_back(const _Ty& _Val) { // insert element at end, provide strong guarantee
emplace_back(_Val);
}
_CONSTEXPR20_CONTAINER void push_back(_Ty&& _Val) {
// insert by moving into element at end, provide strong guarantee
emplace_back(_STD move(_Val));
}
我们看到了一个push_back的重载我们通过调试可以得知,第一个push_back调用的是源码的第二个,第二个push_back调用的是源码的第一个,第三个调用的是第二个(偷懒一下),要注意的是
(_Ty&& _Val)它并不是一个万能引用,因为vector是一个类模板,(之后我会出博客讲到万能引用和引用叠加等等…)这里的TY就是type的意思就是参数的类型,会进行模板推导.第一个push_back的参数是一个左值引用的形式,第二个是右值引用的形式,第二个会触发一个移动语义,将原先的a的内存偷了过来。
为了加深理解,我们看一下move的源码并且拿过来将代码变为下面这样,变成我们自己的move看看是否能运行成功。
#include<vector>
#include <type_traits>
// FUNCTION TEMPLATE move
template <class _Ty>
constexpr std::remove_reference_t<_Ty>&& move(_Ty&& _Arg) noexcept { // forward _Arg as movable
return static_cast<std::remove_reference_t<_Ty>&&>(_Arg);
}
class Vector
{
private:
int x, y, z;
public:
Vector(int x, int y, int z) :x(x), y(y), z(z) {}
};
int main()
{
std::vector<Vector> vec;
vec.push_back(Vector(1,2,3));
Vector a(4,5,6);
vec.push_back(a);
vec.push_back(move(a));
}
我们可以看到我们将move搬过来实现一样可以运行成功,我们来看源码,_
t是C++14之后将原来的type的形式全部都变成type reference的形式,remove_reference_t就是将这个函数木板的类别<_Ty>它的加引用的情况都给去掉了,无论是左值引用(&)还是右值引用(&&)都会移除掉,之后再用static_cast强转为右值引用的形式,那么我们能看出move就是将参数原来的修饰符全部都删掉,在强转为右值引用输出,就是这么简单,move没有干任何移动的过程,所以还是那句话:
std::move 并不会进行任何移动
真正的移动是要自己写的,发生在之后也就是这里
public:
template <class... _Valty>
_CONSTEXPR20_CONTAINER decltype(auto) emplace_back(_Valty&&... _Val) {
// insert by perfectly forwarding into element at end, provide strong guarantee
auto& _My_data = _Mypair._Myval2;
pointer& _Mylast = _My_data._Mylast;
if (_Mylast != _My_data._Myend) {
return _Emplace_back_with_unused_capacity(_STD forward<_Valty>(_Val)...);
}
_Ty& _Result = *_Emplace_reallocate(_Mylast, _STD forward<_Valty>(_Val)...);
#if _HAS_CXX17
return _Result;
#else // ^^^ _HAS_CXX17 ^^^ // vvv !_HAS_CXX17 vvv
(void) _Result;
#endif // _HAS_CXX17
}
然而move的作用也就是强行转换成右值引用。
42.模版类的作用
模板的作用我们已经知道了,类模板的作用就是建立一个可以公用的类,这个类模板里面的成员及其数据类型不用制定,同样是由一个虚拟的类型来表示的。类模板中的数据成员以及成员函数的参数和返回值都可以进行任意数据类型的选择,一个类模板定义好之后,可以减少定义声明符合该模板的类的数量。
类的使用如下:
template<class T>
类
由此可以看出函数模板和类模板之间的区别很简单,在template之后跟的是函数就是函数模板,跟的是类就是类模板。
来个简单的例子来看一下:
template<class nameType,class priceType>
class Car
{
public:
Car(nameType name, priceType price)
{
this->C_name = name;
this->C_price = price;
}
nameType C_name;
priceType C_price;
};
需要多少种类型,就在尖括号<>中写入多少种类型的定义。在定义好类模板之后,要通过类模板来实例化对象:
Car<string, int> p1("宝马", 100);
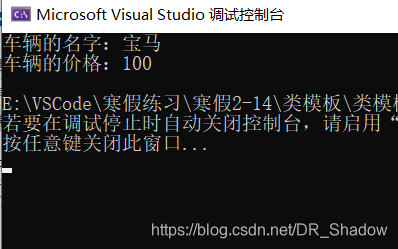
尖括号<>中的string和int代表用到的参数类型吗,<>代表模板参数列表,就是将string和int等类型作为了参数,而“宝马”和“100”则是对象实例化后的数据成员,即string---->nameType,宝马---->name,int---->priceType,100---->price,这四个和模板中的是一一对应起来的。
下面定义一个函数将车辆的信息打印出来:
void Car<string,int>::printCar()
{
cout << "车辆的名字:" << C_name << endl;
cout << "车辆的价格:" << C_price << endl;
}
这是在类外定义,注意同样要加上尖括号<>,在类内定义则不需要,直接定义即可。整个代码如下:
#include<iostream>
#include<string>
using namespace std;
template<class nameType,class priceType>
class Car
{
public:
Car(nameType name, priceType price)
{
this->C_name = name;
this->C_price = price;
}
void printCar();
nameType C_name;
priceType C_price;
};
void Car<string,int>::printCar()
{
cout << "车辆的名字:" << C_name << endl;
cout << "车辆的价格:" << C_price << endl;
}
void test()
{
Car<string, int> p1("宝马", 100);
p1.printCar();
}
void main()
{
test();
}
运行结果为:
1.类模板和函数模板的区别
类模板和函数模板的定义方式相近,在声明标识语句之后跟的是函数就是函数模板,跟的是类就是类模板,从上面的例子我们可以看出,类模板是没有办法自己推导出数据类型的,但是类模板在模板参数列表中可以有默认参数。
Car car1("宝马", 100); //报错
这样的语句是直接报错的,因为类模板没有办法进行数据类型的推导的。
template<class nameType,class priceType = int>
.
.
.
Car<string>car1("奔驰", 200);
模板参数列表为默认参数,因此后面的语句不会报错。整体代码如下。
#include <iostream>
using namespace std;
#include<string>
template<class nameType,class priceType = int>
class Car
{
public:
Car(nameType name,priceType price)
{
this->C_name = name;
this->C_price = price;
}
void printCar()
{
cout << "车的名字是:" << C_name << endl;
cout << "车的价格是:" << C_price << endl;
}
nameType C_name;
priceType C_price;
};
void test()
{
// Car car1("宝马",100);//报错
Car<string,int>car1("宝马", 100);
car1.printCar();
}
void test01()
{
Car<string>car1("奔驰", 200);//模板中有默认参数时候,尖括号的int可以省略不写
car1.printCar();
}
void main()
{
test();
test01();
}
2.类模板成员函数的创建
在这里要提到的一点, 就是类模板中的成员函数在调用时候才被创建,不同于一般类中的成员函数,在一开始就可以创建。
#include<iostream>
#include<string>
using namespace std;
class Car1
{
public:
void printCar1()
{
cout << "Car1调用" << endl;
}
};
class Car2
{
public:
void printCar2()
{
cout << "Car2调用" << endl;
}
};
template<class T>
class Car
{
public:
T m_car;
void fun01()
{
m_car.printCar1();
}
void fun02()
{
m_car.printCar2();
}
};
int main()
{
return 0;
}
上面的代码是可以进行编译的,并且还可以通过,按照逻辑分析一波,在类模板中,我定义了一个参数m_carT,但是它的类型是T,是一个未知的数据类型,你并不知道它是Car1还是Car2的变量,问题就来了,一个未知类型的变量调用其他类中的成员函数为什么不会报错?
这是因为类模板中的成员函数只有在被调用的时候才会去创建,在未被调用的时候并不存在 ,类模板中的两个成员函数fun01和fun02都没有被调用,因此是没有被创建出来的,在这里我们如果加入一个test函数来对其进行调用,看一下是否报错:
void test()
{
Car<Car1>car1;
car1.fun01();
car1.fun02();//编译不通过只要在于这一句,因为car1是Car1类型的对象
}
然后编译报错,因为car1是Car1类型的对象,再加上一个Car2类型的变量car2执行car2.fun02()即可通过。
void test()
{
Car<Car1>car1;
Car<Car2>car2;
car1.fun01();
car2.fun02();
}
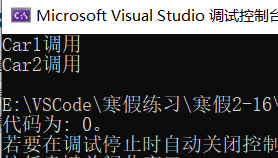
3.类模板对象传参
类模板可以实例化的对象,如果将对象传入到函数,就是将类模板对象作为函数参数进行传参。
提到传参,我们肯定是比较熟悉的了。类模板对象作为函数参数进行传入的方式一般有三种:一、指定传入的类型,直接显示对象的数据类型;二、参数模板化,将对象中的参数变为模板进行传递;三、将整个类模板化,将对象模板化进行传参。上面的例子就是第三种方式的传参。
下面是指定传入的类型进行传参
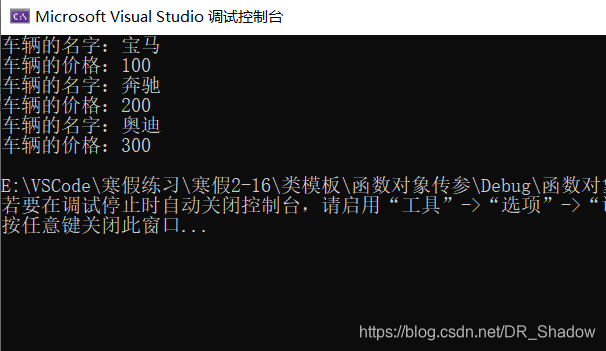
//将car1作为一个实参传入到函数中,在函数体内调用类模板内的函数
void showcar1(Car<string, int> &p) //指定传入的类型
{
p.printCar();
}
...
void test()
{
Car<string, int>car1("宝马", 100);
showcar1(car1);
}
这种方式没有直接调用类模板中的printCar,而是通过一个新的函数将对象作为一个实参传入到一个显得函数中,并在新的函数中对类模板中的函数进行调用。
然后是第二种方式:
//实现参数模板化
template<class T1,class T2>
void showcar2(Car<T1,T2>&p)
{
p.printCar();
}
...
void test01() //参数模板化的test
{
Car<string, int>car2("奔驰", 200);
showcar2(car2);
}
参数模板化的重点在于所需要的参数类型变为模板,同样是通过template来实现的,在尖括号中输入所需要的参数类型的个数,在具体的函数实现中使用模板来定义实例对象的类型。(我总感觉这一点不就是函数模板嘛!为啥非要这么写呢?)
接下来是第三种方式:
//整个类模板化
template<class T>
void showcar3(T &p)
{
p.printCar();
}
....
void test02() //整个类模板化的test
{
Car<string, int>car3("奥迪", 300);
showcar3(car3);
}
这种方式我们应该比较熟悉了,直接将整个类变成一个模板,需要什么类型的数据就取什么类型。
上面三种传参方式的全部代码和运行结果如下:
#include<iostream>
#include<string>
using namespace std;
template<class nameType, class priceType>
class Car
{
public:
Car(nameType name, priceType price)
{
this->C_name = name;
this->C_price = price;
}
void printCar();
nameType C_name;
priceType C_price;
};
void Car<string, int>::printCar()
{
cout << "车辆的名字:" << C_name << endl;
cout << "车辆的价格:" << C_price << endl;
}
//将car1作为一个实参传入到函数中,在函数体内调用类模板内的函数
void showcar1(Car<string, int> &p)
{
p.printCar();
}
//实现参数模板化
template<class T1,class T2>
void showcar2(Car<T1,T2>&p)
{
p.printCar();
}
//整个类模板化
template<class T>
void showcar3(T &p)
{
p.printCar();
}
void test()//指定传入类型的test
{
Car<string, int>car1("宝马", 100);
showcar1(car1);
}
void test01() //参数模板化的test
{
Car<string, int>car2("奔驰", 200);
showcar2(car2);
}
void test02() //整个类模板化的test
{
Car<string, int>car3("奥迪", 300);
showcar3(car3);
}
void main()
{
test();
test01();
test02();
}
希望大家可以进行对比并理解他们之间的不同,能够给大家带来一些帮助!
43.模版和泛型的区别
泛型和模板都提供支持参数化类型的语言功能。但是,它们是不同的,有不同的用途。本主题提供了一个概述的许多差异。
泛型和C + +模板之间的主要差异:
- 泛型是通用的,直到它们在运行时类型取代。模板是专门在编译的时候,所以他们不仍然
- 特别是公共语言运行库支持仿制药在MSIL。由于运行时知道仿制药,具体类型可以被取代时,泛型类型的引用程序集包含一个泛型类型。相比之下,模板,解决成普通类型在编译时产生的类型可能不会专门在其他组件中。
- 专门在两个不同的组件与同类型参数的泛型是相同的类型。专门在两个不同的组件与同类型参数的模板被认为是由运行时是不同的类型。
- 泛型一段可执行代码,用于所有的引用类型参数(这是不正确的值类型,它有一个独特的值类型实施每)作为一个单一的生成。 JIT编译器知道泛型和引用或值类型作为类型参数,能够对代码进行优化。模板生成单独的运行时代码为每个专业化。
- 泛型不允许非类型的模板参数,,如模板<int I】C {}。模板允许他们。
- 泛型不允许显式特例(即一个特定类型的模板的自定义实现)。模板做。
- 泛型不允许部分专业化(类型参数)的一个子集的自定义实现。模板做。
- 泛型不允许被用作类型参数的泛型类型的基类。模板做。
- 不允许泛型类型参数的默认值。模板做。
- 模板支持模板的模板参数(如模板<模板类X>类MyClass),但仿制药没有。
结合模板和泛型
在仿制药的基本区别有用于构建应用程序相结合的模板和泛型的影响。例如,假设你有一个模板类,你想创建一个通用的包装,使该模板其他语言作为一种通用的。你不能有泛型类型参数,然后通过虽然模板,因为模板在编译的时候,需要有该类型的参数,但通用将无法解决,直到运行时的类型参数。嵌套一个通用的模板里面也不会奏效,因为有没有办法扩大模板在编译的时候可以在运行时实例任意泛型类型。
**例子:**下面的例子显示了一个简单的例子,使用模板和泛型。在这个例子中,模板类通过它的参数通过通用类型。相反的是不可能的。
这个成语可能被用来当你想建立的现有通用的API与模板代码,是当地一个Visual C + +组装,或当你需要来添加额外的参数化层泛型类型,以利用某些功能时,模板不支持仿制药。
// templates_and_generics.cpp
// compile with: /clr
using namespace System;
generic <class ItemType>
ref class MyGeneric {
ItemType m_item;
public:
MyGeneric(ItemType item) : m_item(item) {}
void F() {
Console::WriteLine("F");
}
};
template <class T>
public ref class MyRef {
MyGeneric<T>^ ig;
public:
MyRef(T t) {
ig = gcnew MyGeneric<T>(t);
ig->F();
}
};
int main() {
// instantiate the template
MyRef<int>^ mref = gcnew MyRef<int>(11);
}
Output
F
44.内存管理:C++的new和malloc的区别
1、new/delete是C++关键字,需要编译器支持。malloc/free是库函数,需要头文件支持;
2、使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地指出所需内存的尺寸。
3、new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
4、new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。
5、new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
45.new可以重载吗,可以改写new函数吗
new可以被重载,并且可以通过改写new函数来实现自定义内存管理。
在C++中,重载运算符new和delete函数是实现自定义内存分配和释放的一种方式。通过重载这两个函数,可以控制对象的创建和销毁过程。当使用new运算符创建对象时,编译器会先调用new函数分配内存空间,然后再调用构造函数初始化对象;而在删除对象时,编译器会先调用析构函数释放资源,然后再调用delete函数释放内存空间。
因此,改写new函数可以实现以下功能:
- 自定义内存分配策略:通过改变申请、释放内存大小和顺序等方式来优化程序性能。
- 内存泄漏检测:记录每次申请的内存地址和大小,在程序退出前打印未被释放的内存信息。
- 越界检查:在申请或者释放内存时进行越界检查以避免出现数组越界等错误。
- 统计信息:记录程序中所有的申请和释放操作,并统计相关信息如总共分配了多少内存、最大分配量、平均值等等。
需要注意的是,在重载运算符new和delete时需要保证与标准库的兼容性。同时也需要注意不要破坏语言本身规定好的堆栈管理机制。
46.C++中的map和unordered_map的区别和使用场景
1.需要引入的头文件不同
map: #include < map >
unordered_map: #include < unordered_map >
2.内部实现机理不同
map: map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
unordered_map: unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。哈希表详细介绍
3.优缺点以及适用处
map:
- 优点:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高
缺点: 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间 - 适用处:对于那些有顺序要求的问题,用map会更高效一些
unordered_map:
- 优点: 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点: 哈希表的建立比较耗费时间
- 适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
总结:
- 内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
- 但是unordered_map执行效率要比map高很多
- 对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的
4.map和unordered_map的使用
unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。其底层实现是完全不同的,上方已经解释了,但是就外部使用来说却是一致的。
5.C++ Map常见用法说明
常用操作汇总举例:
#include <iostream>
#include <unordered_map>
#include <map>
#include <string>
using namespace std;
int main()
{
//注意:C++11才开始支持括号初始化
unordered_map<int, string> myMap={{ 5, "张大" },{ 6, "李五" }};//使用{}赋值
myMap[2] = "李四"; //使用[ ]进行单个插入,若已存在键值2,则赋值修改,若无则插入。
myMap.insert(pair<int, string>(3, "陈二"));//使用insert和pair插入
//遍历输出+迭代器的使用
auto iter = myMap.begin();//auto自动识别为迭代器类型unordered_map<int,string>::iterator
while (iter!= myMap.end())
{
cout << iter->first << "," << iter->second << endl;
++iter;
}
//查找元素并输出+迭代器的使用
auto iterator = myMap.find(2);//find()返回一个指向2的迭代器
if (iterator != myMap.end())
cout << endl<< iterator->first << "," << iterator->second << endl;
system("pause");
return 0;
}
此时用的是unordered_map,输出的结果为:

若把unordered_map换成map,输出的结果为:

47.他们是线程安全的吗
-
线程安全: 线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
如何保证呢:
1、使用线程安全的类;
2、使用synchronized同步代码块,或者用Lock锁; > 由于线程安全问题,使用synchronized同步代码块 原理:当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。 另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
3、多线程并发情况下,线程共享的变量改为方法局部级变量;
48.c++标准库里优先队列是怎么实现的?
一、堆以及建堆函数
优先队列的核心思想之一就是堆排。但是注意!堆可不是堆栈的堆!
【定义】堆,其实是用vector组成的完全树(因为完全树再层序遍历的时候就是用向量也可以完美表现)。其思想就是先构建出堆,然后会出现一个顶点一定为(最大或最小)的偏序。然后每次把顶点拿走之后再下滤即可。
【步骤】首先根据性质定义好构造建堆下数据结构中优先队列的性质,里面是完全二叉树的性质)
下滤函数–主要使用递归(用于下文的建堆和删顶)
因为主要用递归,所以要记住其需要的三个参数:加&的vector,这个里面放着建堆用的数据。i表示父节点,也是要将左右两个子树合并起来的关键。最后一个i合并建堆就结束了。heapsize是为了确保过程中,不要过了vector的界(其实这个size一直就是vector的size)。
1、先根据性质找到左右子节点的位置:由于父节点为i ii
左子节点为:2 i + 1 2i+12i+1右子节点:2 i + 2 2i+22i+2。
2、父节点将与左右子节点大于它并且更大的那个进行互换
(注意此处有两个条件,不仅要大于父节点,他俩还只能取一次,此时技巧来了!)
2.2定义一个large = i ii,然后large会分别与左右节点比较,并只要大于它,large就等于他。这样两个if过后,它就是最大的那个了。
2.3上一小步中定义两个if,一个条件是左右别超界爆炸,另一条件判断左右在vector中是否大于父节点,如都不大直接别判断了。
2.4 此时如果large不是i,即存在有比他大的子节点了,就直接swap一下,然后接着进行递归。即下一个继续传入a,但是父节点就是large了,其中size一直不变
【ps】难道large为i就不递归了吗,还真就是这样,不递归了!
记忆代码:
void low_update(vector<int>& nums, int i,int heap_size) {
int left = 2*i+1;int right = 2*i+2;int large = i;
if(left < heap_size && nums[left]>nums[large]) large = left;//由此看出是升序
if(right < heap_size && nums[right]>nums[large]) large = right;
if(large!=i)
{
swap(nums[i],nums[large]);
low_update(nums, large, heap_size);
}
}
建堆函数
【思想】根据floyd算法,自下而上的下滤,从下面两两合并最终合成一个完整树。
其实就是从下向上的拿vector倒序建,建完整体没顺序,但是只要符合操作上下滤,顶点就一直是极值。就一个for循环,从后往前传一半的i就行了!
因此for(int i = n/2;i>=0;i–)!!!其他没孩子无所谓了。
void build_heap(vector<int>& nums,int n) {
for(int i = n/2;i>=0;i--)
{
low_update(nums,i,n);
}
}
三、删顶(取一次删一次,取几次删剩下的就是要求的了)
注意是涉及到上滤的
1、先建堆–此后vector可就是堆的形状了!
2.1、pop出去【其实仔细想想不知道如何pop呀】但是联系下一步有个妙招
2.2、头跟尾巴交换位置,再下滤
3、将两个第二步融合一下,就是将头和尾巴交换位置,然后size-1之后,放入下滤就ok了!
最后,返回头,也就是nums[0]
二、调用在stl库里面的优先队列priority_queue
首先,需要引入库#include 。下面将分别根据建堆所需的数据类型情况进行分类描述:
首先,大根堆就是每次取最大值,小根堆就是每次取最小值。但是,对于最大和最小堆栈在定义排序顺序时,是与sort中的逻辑正好相反的。(如在下面情况1中,greater对应的是最小堆,而在sort中的greater()对应的是从大到小排!原因可见情况3讲解)
建堆
1、单个数的情况
//小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//大顶堆
priority_queue <int,vector<int>,less<int> >q;
//默认大顶堆
priority_queue<int> a;
里面可以是正常int,但更多的是pair,会对前面的进行排序,取后面的就可以!
2、两个数pair的情况
pair的比较,先比较第一个元素,第一个相等比较第二个。
//小顶堆
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> q;
//大顶堆
priority_queue<pair<int, int>, vector<pair<int, int>>, less<>> q;
//默认大顶堆
priority_queue<pair<int, int>, vector<pair<int, int>>> q;
当pair想比较第二个的时候,可以选择前后切换即可。
3、自定义类型的情况
若要使相对树的节点等不是Int类型的使用优先队列,则可以通过重定义操作符"<",以链表的节点为例,可以这样声明优先队列。
struct Status {
int val;
ListNode *ptr;
bool operator < (const Status &rhs) const {
return val > rhs.val;
}//注意这个是最小堆,最小堆是>;最大堆是<,两个堆都需要重定义<
};
priority_queue <Status> q//这样就能直接声明定义了
由于堆原理中,默认是下面的左右子节点大于上面的父节点,便让父节点跟最大的那个换一下,而此处修改便是找最大的那个条件,即该结构中源代码是<,而编写的新仿函数或者重载<,使其return 大于的才对,就是将<变成了>。因此就会从默认的由小到大排转成了由大到小排!
4、仅仅想重构“比较规则”的情况
可以使用重构()函数的方法(其逻辑比较顺序与上面的重构<函数一模一样):
struct cmp1
{
bool operator()(char &a,char &b) { return a < b; }//这是大根堆
//注意这里定义的逻辑跟sort定义是反着的
};
struct cmp2
{
bool operator()(pair<double,vector<int>>&p1,pair<double,vector<int>>&p2)
{
return p1.first > p2.first;//小顶堆是大于号
}
};
priority_queue<char,vector<char>,cmp1> a;//例如a中有'a'和'b',此时top出来的是b
priority_queue<pair<double,vector<int>>,vector<pair<double,vector<int>>>,cmp2> b;
5、想通过sort那样使用匿名函数快速定义排序顺序
在 priority_queue 的构造函数中,可以传入一个比较函数作为参数,用于指定元素的优先级比较方式。
因此我们可以先声明一个匿名函数,随后使用decltype函数来使该函数变为一个type从而使用。
auto cmp = [&](const int& a, const int &b) {
return cnt[a] < cnt[b];//此处cnt可由上文完成定义(最大堆--跟sort正好相反)
};
priority_queue<int, vector<int>, decltype(cmp)>pq{cmp};
堆操作
以上面堆栈a为例:
加入堆节点:a.push(‘a’);
删除堆顶节点:a.pop();
取出堆顶节点:a.top();
49.gcc编译的过程
一、总体概述
GCC的编译流程分为四个步骤:
1、预处理(Pre-Processing)
2、编译(Compiling)
3、汇编 (Assembliang)
4、链接(Linking)
二、解释步骤
XXX为源文件
YY为生成的文件
1、预处理(Pre-Processing)
预处理用于将所有的#include头文件以及宏定义替换成其真正的内容,预处理之后得到的仍然是文本文件,但文件体积会大很多。
将 .c 文件转换为 .i 文件,使用gcc命令:gcc -E XXX -o YY
对应于预处理命令 cpp
2、编译(Compiling)
将预处理之后的程序转换为特定的汇编代码 (assembly code) 的过程。
将 .c/.h 文件转换为 .s 文件,使用gcc命令:gcc -S XXX -o YY
对应于编译命令 cc -S
3、汇编 (Assembliang)
汇编过程将上一步的汇编代码转成机器码(machine code),这一步产生的文件叫 目标文件 ,是二进制格式。此步骤会为每一个源文件产生一个目标文件。
将 .s 文件转换为 .o 文件,使用gcc命令:gcc -c XXX -o YY
对应于汇编命令 as
4、链接(Linking)
链接过程将多个目标文件以及所需的库文件( .so 等)链接成最终可执行文件(executable file)。
将 .o 文件转换为 可执行程序,使用gcc命令: gcc -o YY XXX
对应于链接命令 ld
总结起来编译过程就上面的四个过程:预编译处理(.c) --> 编译、优化程序(.s、.asm)--> 汇编程序(.obj、.o、.a、.ko) --> 链接程序(.exe、.elf、.axf等)。
三、案例
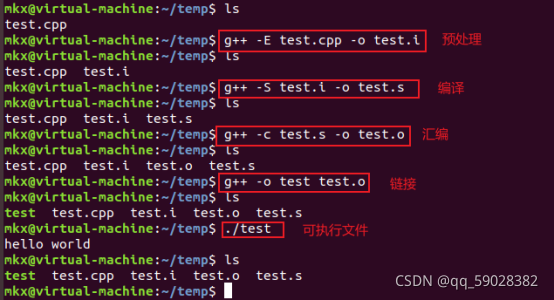
四、个人练习
目录结构
├── test.c
└── inc
├── mymath.h
└── mymath.c
demo源文件
// test.c
#include <stdio.h>
#include "mymath.h"// 自定义头文件
int main(){
int a = 2;
int b = 3;
int sum = add(a, b);
printf("a=%d, b=%d, a+b=%d\n", a, b, sum);
}
头文件定义
// mymath.h
#ifndef MYMATH_H
#define MYMATH_H
int add(int a, int b);
int sum(int a, int b);
#endif
头文件实现
// mymath.c
int add(int a, int b){
return a+b;
}
int sub(int a, int b){
return a-b;
}
--------------------------------------------------------------------分隔线------------------------------------------------------------
编译过程
1、预处理
gcc -E -I./inc/ test.c -o test.i
2、编译
gcc -S -I./inc test.c -o test.s
3、汇编
gcc -c test.s -o test.o
执行到此步骤时,需要生成其他目标文件,例如 mymath.o
如下执行:
cd inc/
gcc -E mymath.c -o mymath.i
gcc -S mymath.i -o mymath.s
gcc -c mymath.s -o mymath.o
4、链接
gcc -o test.out test.o ./inc/mymath.o
结果图:

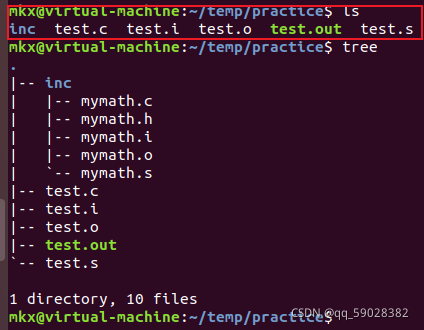
五、补充
Makefile
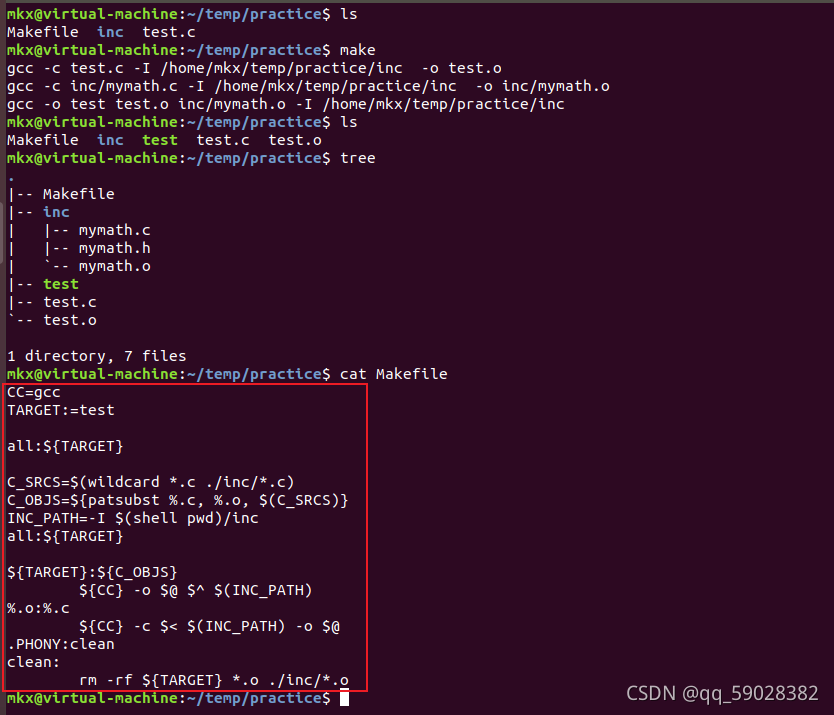
GCC的基本用法和选项
GCC的最基本用法是:gcc [options] [filenames]
-c,只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o的后缀的目标文件,通常用于编译不包含主程序的子程序文件。
-o output filename ,确定输出文件名称为output filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。
-g,产生符号调试工具(GUN的gdb)所必要的符号资讯,想要对源代码进行调试,我们必须加入这个选项
-O,对程序进行优化编译、连接,采用这个选项,整个源代码会在编译、连接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高,但是,编译、连接的速度会相对慢一些。
-O2,比-O更好的优化编译、连接,当然整个编译、连接过程会很慢。
-I dirname,将dirname所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
-L dirname,将dirname 所指出的目录加入到程序函数档案库文件的目录列表中,是在链接过程中使用的参数。
GCC的错误类型及对策
第一类:C语法错误
错误信息:文件source.c中第n行语法错误(systex error)。有些情况下,一个简单的语法错误,gcc会出一大堆错误,我们要保持头脑清醒,不要被吓到!
第二类:头文件错误
错误信息:找不到头文件head.h(Can not find include file head.h)。这类错误是源代码文件中的包含头文件有问题,可能的原因有头文件名错误、指定的头文件所在目录名错误等,也可能是错误的使用双引号和尖括号。
第三类:档案库错误
错误信息:链接程序找不到所需的函数库(ld:-lm:No such file or directory)。这类错误是与目标文件相连接的函数库有错误,可能的原因是函数库名错误、、指定的函数库所在目录名称错误等,检查的方法是使用find命令在可能的目录中寻找相应的函数库名,确定档案库及目录的名称并修改程序中及编译选项中的名称。
第四类:未定义符号
错误信息:有未定义的符号(Undefined symbo1)。这类错误是在连接过程中出现的,可能有两种原因:一是使用者自己定义的函数或者全局变量所在源代码文件,没有被编译连接,或者干脆还没有定义,这需要使用者根据实际情况修改源程序,给出全局变量或者函数的定义体;二是未定义的符号是一个标准的库函数,在源程序中使用了该库函数而连接过程中还没有给定相应的函数库的名称,或者是该档案库的目录名称有问题,这时需要使用档案库维护命令ar检查我们需要的库函数到底位于哪–个函数库中,确定之后,修改gcc连接选项中的-1和-L项。
其他介绍:
GNU工具
编译工具:把一个源程序编译为一个可执行程序
调试工具:能对执行程序进行源码或者汇编级调试
软件工程工具:用于协助多人开发或者大型软件项目的管理。如make、CVS、Subvision
其他工具:用于把多个文件链接成可执行文件的连接器,或者用作格式转换的工具
GCC简介
全称为GUN CC,GUN项目中符合ANSI C标准编译系统
编译如C、C++、Object C、JAVA、Fortran、Pascal、Modula-3和Ada等多种语言
GCC是可以在多种硬件平台上编译出可执行程序的超级编译器,其执行效率与一般的编辑器相比平均效率高出20%~30%
一个交叉平台编译器,适合在嵌入式平台领域的开发编译
gcc所支持后缀名解释

编译器的主要组件
分析器:将源语言程序代码转换为汇编语言(C到汇编),所以分析器需要知道目标机器的汇编语言。
汇编器:汇编器将汇编语言代码转换为CPU可以执行的字节码。
链接器:将汇编器生成的单独的目标文件组合成可执行的应用程序。连接器需要知道这种目标格式以便于工作。
标准C库:核心的C语言库都有一个主要的C库来提供,如果在应用程序中用到了C库中的函数,这个库就会通过链接器和源代码连接来生成最终的可执行程序。
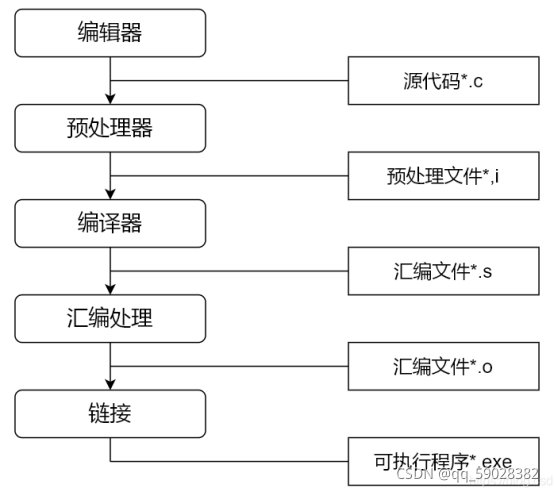
50.C++ Coroutine
在C++里,一个函数如果其函数体实现中包含co_await、co_yield、co_return中任何一个关键字,那么这个函数就是一个coroutine。其中:
- co_await:挂起当前的coroutine
- co_return:从当前coroutine返回一个结果
- co_yield:返回一个结果并且挂起当前的coroutine
一个coroutine要能被编译期识别并通过编译,在某些情况下要自己去特化coroutine_traits。下面就一个简单的coroutine来说一说C++编译器是如何修改这个coroutine的。
[ ](javascript:void(0)😉
](javascript:void(0)😉
1 // 我们假定这个模板函数是一个coroutine
2 template <typename TRet, typename … TArgs>
3 TRet func(TArgs args…)
4 {
5 body; // body里至少包含了co_await、co_yield、co_return三者之一。
6 }
[ ](javascript:void(0)😉
](javascript:void(0)😉
那么这个函数会被编译器改成如下形式:
[ ](javascript:void(0)😉
](javascript:void(0)😉
1 // 它会被编译期展开成如下形式
2 template <typename TRet, typename ... TArgs>
3 TRet func(TArgs args...)
4 {
5 using promise_t = typename coroutine_traits<TRet, TArgs...>::promise_type;
6
7 promise_t promise;
8 auto __return__ = promise.get_return_object(); // 这个__return__会被编译器特殊处理
9
10 co_await promise.initial_suspend();
11
12 try
13 { // co_return expr; => promise.return_value(expr); goto final_suspend;
14 body; // co_return; => promise.return_void(); goto final_suspend;
15 } // co_yield expr; => co_await promise.yield_value(expr);
16 catch (...)
17 {
18 promise.set_exception(std::current_exception());
19 }
20
21 final_suspend:
22 co_await promise.final_suspend();
23 }
[ ](javascript:void(0)😉
](javascript:void(0)😉
以上是一个coroutine的基本形式。事实上看完之后会发现,一个coroutine的关键主要还是和其关联的promise。
和coroutine promise关联的另外一个概念,叫awaitable。Awaitable可以称为一个可等待对象。一个awaitable对象需要实现3个相关函数:
- await_ready:awaitable实例是否已经ready
- await_suspend:挂起awaitable。该函数会传入一个coroutine_handle类型的参数。这是一个由编译器生成的变量。suspend过程可以指定该coroutine何时何地以何种方式被resume。比方说实现suspend函数时,将coroutine_handle放到threadpool中。那么当前的coroutine接下来就运行在线程池指派的后台线程中运行了。
- await_resume:当coroutine重新运行时,会调用该函数。
所以要让一个类型能够awaitable,有三种手段:
- 该类型相关代码无法修改时,需要实现:
- bool await_ready(T &);
- void await_suspend(T &, coroutine_handle<promise_type>);
- auto await_resume(T &); auto视具体情况而定
- 该类型相关代码可以修改时,需要增加3个成员函数:
- bool await_ready();
- void await_suspend(coroutine_handle<promise_type> ch);
- auto await_resume();
- 实现operator co_await操作符,返回一个可等待的代理类型,并且实现了上述三个函数。
51.extern C有什么作用
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言语法进行编译,而不是C++的。
extern 是变量或函数的申明,告诉编译器在其它文件中找这个变量或函数的定义。
这里需要的是“声明”,不是“定义”!根据C++标准的规定,一个变量声明必须同时满足两个条件,否则就是定义:
(1)声明必须使用extern关键字;(2)不能给变量赋初值
extern int a; //声明
int a; //定义
int a = 0; //定义
extern int a =0; //定义
52.c++ memoryorder/elf文件格式/中断对于操作系统的作用
1.memory_order
C++11引入了原子操作和内存模型,其中memory_order是用于指定原子操作的内存顺序的枚举类型。它可以控制多个线程之间对共享变量的读写顺序,以保证程序正确性。
2.ELF文件格式
ELF(Executable and Linkable Format)文件格式是Linux系统下可执行文件和目标文件的标准格式。它包含了代码、数据、符号表、重定位信息等,并且支持动态链接,即可执行程序在运行时才加载所需库。
3.中断对于操作系统的作用
中断是计算机硬件向CPU发出的一种异步信号,用于通知CPU发生了某些事件或需要处理某些任务。在操作系统中,中断被广泛应用于各种设备驱动程序和进程调度等方面。
当一个进程请求进行IO操作或者受到外部事件触发时,例如键盘输入、网络接收等,会向操作系统发送一个中断信号。操作系统通过中断处理程序来响应这个信号,并根据具体情况将其转化为相应的进程调度或设备驱动程序等操作。
53.C++的符号表
在C++编译过程中,符号表是一种重要的数据结构,用于记录程序中定义和引用的变量、函数等符号信息。通常情况下,每个源文件都会生成一个对应的符号表。
具体来说,符号表主要包含以下信息:
- 符号名称:即变量或函数名。
- 符号类型:区分不同类型的符号,如全局变量、局部变量、函数等。
- 符号大小:指该符号所占用的内存空间大小。
- 符号地址:指该符号在内存中的地址。
- 符号绑定:指该符号是强绑定还是弱绑定(即静态链接还是动态链接)。
- 符号可见性:指该符号对其他模块是否可见。
通过符号表,编译器可以在链接过程中找到正确的代码位置,并确保程序运行时能够正确访问各个变量和函数。同时,在进行动态链接时也需要使用到符号表信息。
54.C++的单元测试
1.单元测试的基本组成
1.1 模块化
模块化定义了我们如何组织单元测试,以文件为单位,以命名空间为单位,以类为单位,这些都是单元测试模块化的方式。比如CppUnit以类为单位组织测试用例,GTest通过宏TEST_F组织测试用例。
1.2 夹具
夹具,选自机械加工的专用名词,表示加工前,对加工物进行固定。夹具可以用于组织测试用例,但更重要的是为模块里的每个测试添加一些在测试前后需要执行的通用操作。
1.3 测试方法
具体的测试用例执行体。
1.4 断言/期望
用于检查一个测试是否成功或失败,检查的项目包括但不限于:
- 是否返回某一具体的值
- 是否抛某种异常
- 是否不抛异常
- 某函数是否被调用,调用次数以及调用参数
1.5 Mock & Fake & Stub
- Mock 提前准备好并明确了某些期望的对象。通过检查对象的期望是否达成来进行交互测试
- Fake 不可用于生产环境的假对象,比如内存文件系统,用于隔离外部依赖
- Stub 桩对象,用于模拟某些操作或对象,隔离外部依赖,专注代码单元功能的验证
2.单元测试的基本准则
2.1 准确性
单元测试的断言或期望应准确,包含关键核心逻辑的验证,但也应该避免无效断言,防止代码迭代过程不必要的维护成本。
2.2 单一性
一个单元测试应该始终只关注一个函数的测试。
2.3 自动性
单元测试应该能够比较简单地自动化执行,方便进行CI集成。
2.4 完备性
单元测试应完备,覆盖基本的代码逻辑和分支。对于核心流程,希望能够达到 90% 的覆盖率,非核心流程要求 60% 以上。
2.5 可重复性
多次执行(任何环境任何时间)结果唯一,且可以重复执行。
2.6 可测性
表示代码的可测性,比如代码逻辑应该做到高类聚低耦合,依赖抽象而不是具体。常见的方式有:封装抽象、依赖注入。
3.C++单元测试的常用框架
GTest & GMock
CppUnit
gs…)
4 {
5 using promise_t = typename coroutine_traits<TRet, TArgs…>::promise_type;
6
7 promise_t promise;
8 auto return = promise.get_return_object(); // 这个__return__会被编译器特殊处理
9
10 co_await promise.initial_suspend();
11
12 try
13 { // co_return expr; => promise.return_value(expr); goto final_suspend;
14 body; // co_return; => promise.return_void(); goto final_suspend;
15 } // co_yield expr; => co_await promise.yield_value(expr);
16 catch (…)
17 {
18 promise.set_exception(std::current_exception());
19 }
20
21 final_suspend:
22 co_await promise.final_suspend();
23 }
[[外链图片转存中...(img-uPycxDlX-1728628913820)]](javascript:void(0);)
以上是一个coroutine的基本形式。事实上看完之后会发现,一个coroutine的关键主要还是和其关联的promise。
和coroutine promise关联的另外一个概念,叫awaitable。Awaitable可以称为一个可等待对象。一个awaitable对象需要实现3个相关函数:
1. await_ready:awaitable实例是否已经ready
2. await_suspend:挂起awaitable。该函数会传入一个coroutine_handle类型的参数。这是一个由编译器生成的变量。suspend过程可以指定该coroutine何时何地以何种方式被resume。比方说实现suspend函数时,将coroutine_handle放到threadpool中。那么当前的coroutine接下来就运行在线程池指派的后台线程中运行了。
3. await_resume:当coroutine重新运行时,会调用该函数。
所以要让一个类型能够awaitable,有三种手段:
1. 该类型相关代码无法修改时,需要实现:
- bool await_ready(T &);
- void await_suspend(T &, coroutine_handle<promise_type>);
- auto await_resume(T &); auto视具体情况而定
2. 该类型相关代码可以修改时,需要增加3个成员函数:
- bool await_ready();
- void await_suspend(coroutine_handle<promise_type> ch);
- auto await_resume();
3. 实现operator co_await操作符,返回一个可等待的代理类型,并且实现了上述三个函数。
# 51.extern C有什么作用
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言语法进行编译,而不是C++的。
extern 是变量或函数的申明,告诉编译器在其它文件中找这个变量或函数的定义。
这里需要的是“声明”,不是“定义”!根据C++标准的规定,一个变量声明必须同时满足两个条件,否则就是定义:
(1)声明必须使用extern关键字;(2)不能给变量赋初值
extern int a; //声明
int a; //定义
int a = 0; //定义
extern int a =0; //定义
# 52.c++ memoryorder/elf文件格式/中断对于操作系统的作用
1.memory_order
C++11引入了原子操作和内存模型,其中memory_order是用于指定原子操作的内存顺序的枚举类型。它可以控制多个线程之间对共享变量的读写顺序,以保证程序正确性。
2.ELF文件格式
ELF(Executable and Linkable Format)文件格式是Linux系统下可执行文件和目标文件的标准格式。它包含了代码、数据、符号表、重定位信息等,并且支持动态链接,即可执行程序在运行时才加载所需库。
3.中断对于操作系统的作用
中断是计算机硬件向CPU发出的一种异步信号,用于通知CPU发生了某些事件或需要处理某些任务。在操作系统中,中断被广泛应用于各种设备驱动程序和进程调度等方面。
当一个进程请求进行IO操作或者受到外部事件触发时,例如键盘输入、网络接收等,会向操作系统发送一个中断信号。操作系统通过中断处理程序来响应这个信号,并根据具体情况将其转化为相应的进程调度或设备驱动程序等操作。
# 53.C++的符号表
在C++编译过程中,符号表是一种重要的数据结构,用于记录程序中定义和引用的变量、函数等符号信息。通常情况下,每个源文件都会生成一个对应的符号表。
具体来说,符号表主要包含以下信息:
1. 符号名称:即变量或函数名。
2. 符号类型:区分不同类型的符号,如全局变量、局部变量、函数等。
3. 符号大小:指该符号所占用的内存空间大小。
4. 符号地址:指该符号在内存中的地址。
5. 符号绑定:指该符号是强绑定还是弱绑定(即静态链接还是动态链接)。
6. 符号可见性:指该符号对其他模块是否可见。
通过符号表,编译器可以在链接过程中找到正确的代码位置,并确保程序运行时能够正确访问各个变量和函数。同时,在进行动态链接时也需要使用到符号表信息。
# 54.C++的单元测试
## 1.单元测试的基本组成
#### 1.1 模块化
模块化定义了我们如何组织单元测试,以文件为单位,以命名空间为单位,以类为单位,这些都是单元测试模块化的方式。比如CppUnit以类为单位组织测试用例,GTest通过宏`TEST_F`组织测试用例。
#### 1.2 夹具
夹具,选自机械加工的专用名词,表示加工前,对加工物进行固定。夹具可以用于组织测试用例,但更重要的是为模块里的每个测试添加一些在测试前后需要执行的通用操作。
#### 1.3 测试方法
具体的测试用例执行体。
#### 1.4 断言/期望
用于检查一个测试是否成功或失败,检查的项目包括但不限于:
- 是否返回某一具体的值
- 是否抛某种异常
- 是否不抛异常
- 某函数是否被调用,调用次数以及调用参数
#### 1.5 Mock & Fake & Stub
- **Mock** 提前准备好并明确了某些期望的对象。通过检查对象的期望是否达成来进行**交互测试**
- **Fake** 不可用于生产环境的假对象,比如内存文件系统,用于隔离外部依赖
- **Stub** 桩对象,用于模拟某些操作或对象,隔离外部依赖,专注代码单元功能的验证
## 2.单元测试的基本准则
#### 2.1 准确性
单元测试的断言或期望应准确,包含关键核心逻辑的验证,但也应该避免无效断言,防止代码迭代过程不必要的维护成本。
#### 2.2 单一性
一个单元测试应该始终只关注一个函数的测试。
#### 2.3 自动性
单元测试应该能够比较简单地自动化执行,方便进行CI集成。
#### 2.4 完备性
单元测试应完备,覆盖基本的代码逻辑和分支。对于核心流程,希望能够达到 90% 的覆盖率,非核心流程要求 60% 以上。
#### 2.5 可重复性
多次执行(任何环境任何时间)结果唯一,且可以重复执行。
#### 2.6 可测性
表示代码的可测性,比如代码逻辑应该做到高类聚低耦合,依赖抽象而不是具体。常见的方式有:封装抽象、依赖注入。
## 3.C++单元测试的常用框架
#### [GTest & GMock](https://links.jianshu.com/go?to=https%3A%2F%2Fgoogle.github.io%2Fgoogletest%2Fprimer.html)
#### [CppUnit](https://links.jianshu.com/go?to=https%3A%2F%2Fagiledeveloper.com%2Farticles%2FUTCPP.pdf)
#### [cpp-stub](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Fcoolxv%2Fcpp-stub)