hadoop、zookeeper、hbase安装
1. vmware配置
搜索:“vmware for mac”,购买正版并下载,或通过其他渠道下载均可
- 随机掉落的奇怪链接
2. 下载镜像并安装虚拟机
bug记录1
此处选用ubuntu的20以及24,分别出现无法加载安装程序、x86无法适配arm系统。
- 在虚拟机的设置界面,选中CDC,配置镜像地址。
- 将虚拟机重启后会进入安装界面
- bug:并未进入,重启后进入boot系统
- 在boot中,手动将CDC加载的优先级调整至最高,应用后重启,仍然无法解决
前者原因难以判断,但后者是由于下载了基于windows系统的ubuntu导致的,在下载中应注意标记ubuntu-ports等与mac系统相关关键词
bug记录2
此处选用centos9,正常进入安装程序,但选择完语言后进度卡住,选择后无限返回至选择语言界面。预计更换centos7继续安装
bug记录3
https://cloud.tencent.com/developer/article/2416622
该文直接分区,然后加载ubuntu,还是找iso文件吧…………
在分区后合并分区,搜索磁盘工具,点击分区,选中想要删除的分区并点击"—",最后应用,即可合并
安装记录
- 下载镜像
- https://ubuntu.com/download/server/arm
- 以上为适配于arm系统的ubuntu,该链接为官方服务器端下载链接
- Tip:并未找到国内镜像源,部分国内镜像源主要包含基于arm的插件工具,不包含安装用iso。下载过程可能较长
- 基于vmware安装虚拟机
- 按照该链接执行安装过程,https://blog.csdn.net/qq_24950043/article/details/123764210
3. 虚拟机配置
该部分内容不分先后,没有遇到的问题可以直接跳过
- 安装桌面
- 上述服务器端安装完成后默认为命令行,如需安装桌面版,参照该链接https://blog.csdn.net/qq_24950043/article/details/125774990
- 请注意,最好先更换至国内源再安装桌面版
- 过程非常长漫长

-
点击setting,搜索lan,点击语言,选中下载/删除语言,选中简体中文并下载
-
过程中发现部分磁盘空间爆了,就剩KB级别的空间了,故扩容
-
扩容前先清理盘空间
-
系统垃圾清理 # 清理旧版本的软件缓存,删除你已经卸载掉的软件包 sudo apt-get autoclean # 清理所有软件缓存,电脑上存储的安装包全部卸载 sudo apt-get clean # 删除系统不再使用的孤立软件 sudo apt-get autoremove
-
-
然后确定哪个部分的空间满了:
df -h -
将上一步中占用率较高的一个扩容即可
-
参考如下命令
lvextend -L 10G /dev/mapper/ubuntu--vg-ubuntu--lv //增大或减小至10G lvextend -L +10G /dev/mapper/ubuntu--vg-ubuntu--lv //增加10G lvreduce -L -10G /dev/mapper/ubuntu--vg-ubuntu--lv //减小10G lvresize -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv //按百分比扩容 resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv //执行调整 -
-
扩充后效果如下
-
扩容前,占用率92%
-
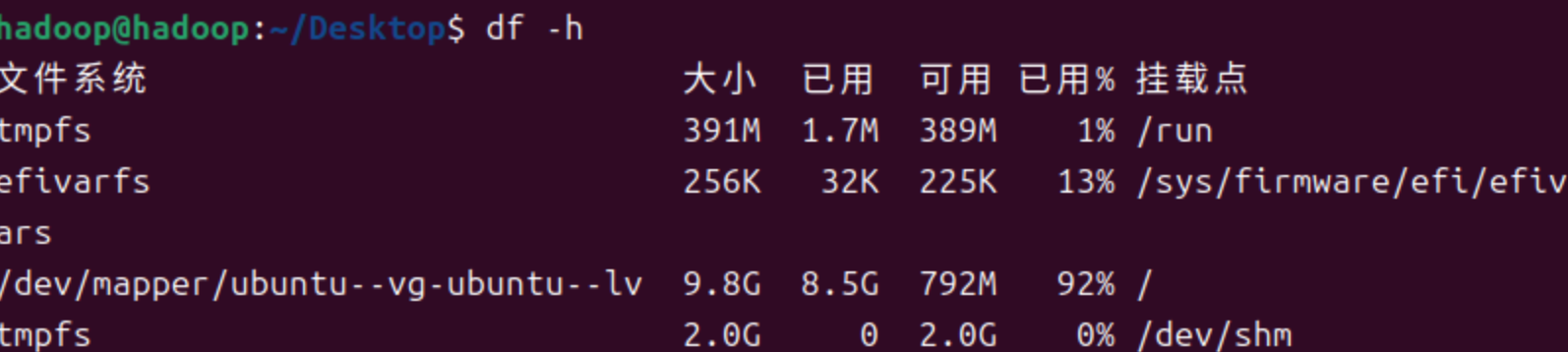
-
扩容后,占用61%
-
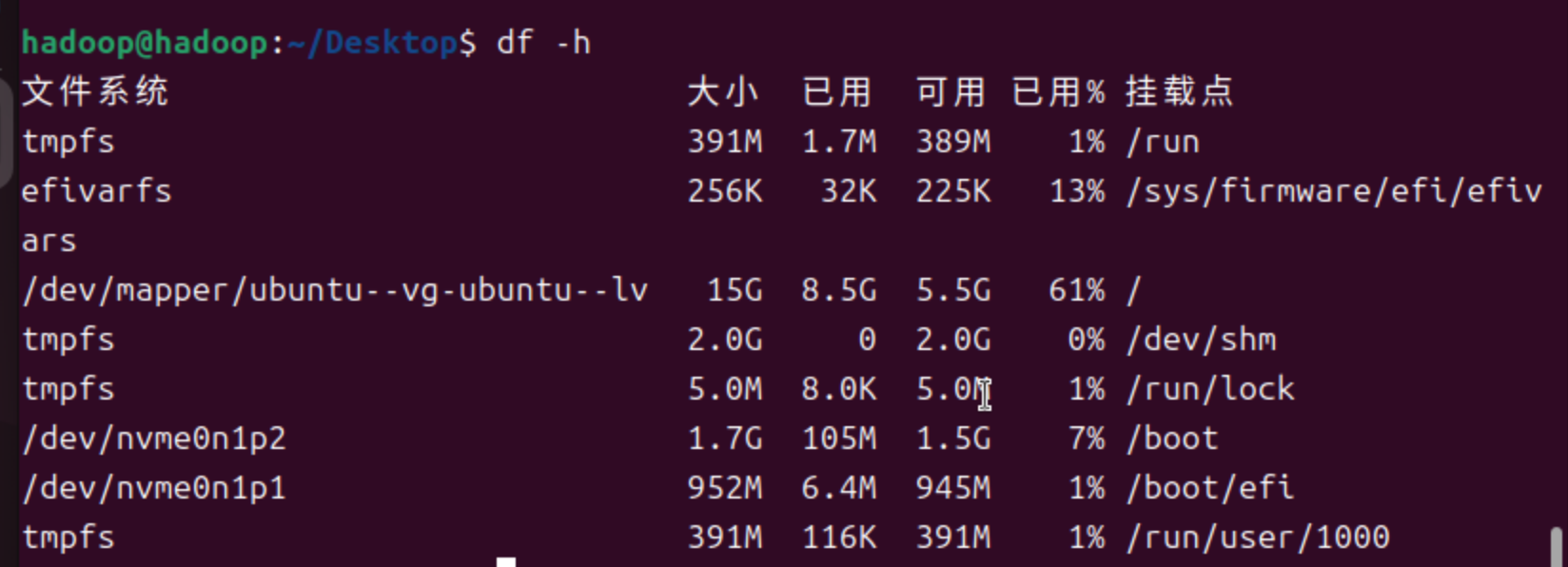
-
-
-
安装open-vm-tools
-
sudo apt-get autoremove open-vm-tools sudo apt-get install open-vm-tools sudo apt-get install open-vm-tools-desktop
-
-
配置新镜像源
- 执行如下命令
sudo cp /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak sudo vim /etc/apt/sources.list.d/ubuntu.sources- 按照清华源更新,
https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu-ports/- 在ubuntu24以后采用bed822格式,按自己版本配置即可
- 执行如下命令
-
安装jdk与jre
- 根据
java -version的返回内容确定是否安装,建议安装openjdk-8-jdk- 若正常返回路径,则说明已经安装
- 若返回一堆命令,则
sudo apt-get install default-jresudo apt-get install default-jdk
- 根据
-
配置静态ip
-
安装net-tools:
sudo apt net-tools -
查看网关:
ifconfig、route -d -
cd ~/etc/netplan,在该目录下查看,下属文件即是网络配置(名称不一定一样) -
保存副本
sudo cp 00-installer-config.yaml 00_installer-config.yaml_before -
开始修改
sudo vim 00-installer-config.yaml-
network: ethernets: eth0: dhcp4: false addresses: [192.168.1.11/24] optional: true routes: - to: default via: 192.168.1.1 nameservers: addresses: [192.168.1.1] version: 2 -
注:
gateway4这个标签已经废弃了,将网关信息写在routes下即可
-
-
应用修改
sudo netplan apply -
测试
ping baidu.com
-
-
配置无密码ssh登录
-
安装ssh服务器以及客户端
sudo apt-get install openssh-serversudo apt-get install openssh-client
-
登录本机,测试
ssh localhost -
退出登录
exit -
配置无密码登录,执行以下命令并按enter
-
cd ~/.ssh/ ssh-keygen -t rsa
-
-
cat ./id_rsa.pub >> ./authorized_keys -
再用
ssh localhost
-
4. 配置hadoop(单机)
-
下载文件,在如下链接,根据自身需求进行下载hadoop-3.4.0,aarch64为arm版本
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.4.0/
-
将已经下载好的文件移动至vmware窗口上,上传至虚拟机
- 默认的上传地址为tmp/VMwareDnD
-
该链接下执行如下命令,文件名称根据自己下载的配置
sudo tar -zxf ./hadoop-3.3.5.tar.gz -C /usr/local
-
修改文件名称为hadoop
cd /usr/localsudo mv ./xxx ./hadoop
-
赋予可执行权限
sudo chown -R hadoop ./hadoop
-
查看安装信息
-
cd ./hadoop ./bin/hadoop version
-
-
运行实例
-
新建input子目录
sudo mkdir input -
复制 “/usr/local/hadoop/etc/hadoop” 中的配置文件到 input 目录下:
sudo cp ./etc/hadoop/*.xml ./input -
运行grep实例:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep ./input ./output 'dfs[a-z.]+'- 注意修改文件名称
-
查看运行结果
cd ./outputls- 结果如下
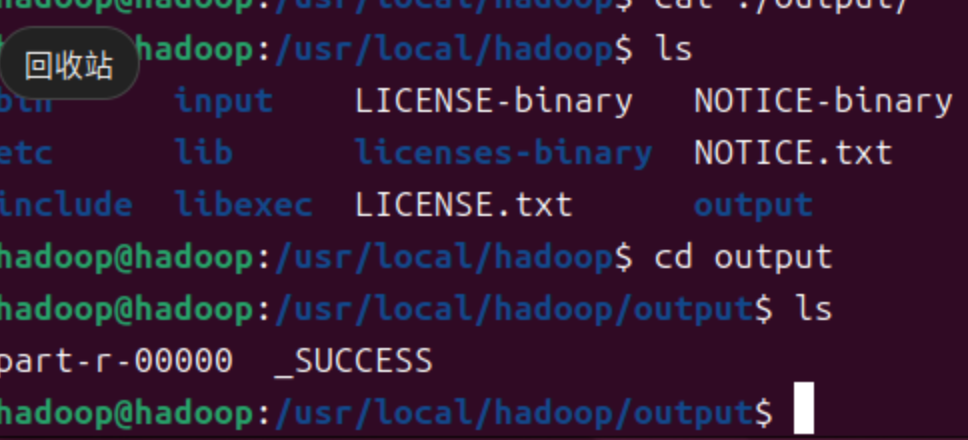
-
5. 完全分布式部署
-
创建虚拟机的完全克隆两个,并分别命名slave1、slave2
-
在虚拟机设置 → \rightarrow →网络适配器 → \rightarrow →在高级选项中生成新的mac地址
- Slave1:00:50:56:22:A3:94
- Slave2:00:50:56:28:28:D9
-
按照上面的方法配置静态ip,分别为
- Master:172.16.227.129
- Slave1:172.16.227.130
- Slave2:172.16.227.131
-
修改主机名、ip映射
sudo vim /etc/hostnamesudo vim /etc/hosts
-
使用ssh将公钥分发,
ssh-copy-id master- 注意:每个机器都要分发
-
修改配置文件,在hadoop根目录下
/etc/hadoop下- 可以根据自己的需求进行修改
-
集群规划如下
-
分别修改一下内容
-
core-site.xml
-
<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为shuaikai --> <property> <name>hadoop.http.staticuser.user</name> <value>shuaikai</value> </property> </configuration> -
hdfs-site.xml
-
<configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>master:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave2:9868</value> </property> </configuration> -
yarn-site.xml
-
<configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> -
mapred-site.xml
-
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
-
-
创建分发命令xsync
-
sudo vim /home/usr/bin/xsync -
# 编写以下内容: #!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in master slave1 slave2 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done -
设置权限
sudo chmod 777 xsync -
更新
source ~/.profile -
注:亦可将上述内容编写在某固定文件夹下,并将该文件夹添加入环境变量
~/.profile,并更新环境变量
-
-
在集群上分发
xsync $HADOOP_HOME/etc/hadoop -
配置hadoop环境变量,路径如上所示
-
export HADOOP_HOME=本机的hadoop安装路径 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-
-
debug:过高版本jdk导致的bug,cannot set priority of nodemanger&resourcemanager process
-
原因:查看日志文件后发现有一个java.lang相关的调用失败,搜索后发现是高版本jdk导致的bug,同时该文也指出
hive3.x仅支持jdk1.8(即低版本),遂决定降低版本 -
步骤如下
-
安装jdk:运行命令
apt install openjdk-8-jdk -
配置环境变量
/etc/environment、~/.bashrc -
配置hadoop环境变量
/etc/hadoop/hadoop-env.sh,修改java版本 -
xsync分发文件,source更新系统配置 -
若已经启动过,则需重新执行
hdfs namenode -format
-
-
-
执行命令
hdfs namenode -format -
执行命令
start-dfs.sh- 调用
jps查看进程 
- 调用
-
slave1执行命令
start-yarn.sh- 调用
jps查看进程 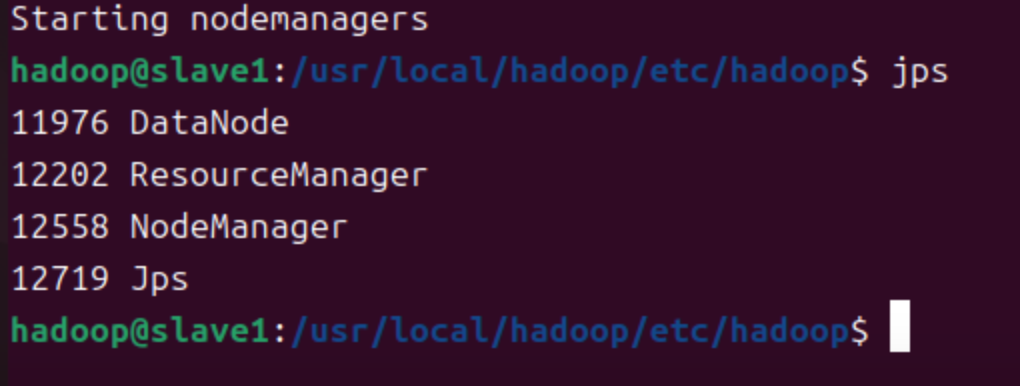
- 调用

6. 单机zookeeper
-
下载zookeeper基于清华镜像
-
上传至虚拟机并解压
tar -zxvf zookeeper -C $路径
-
转至解压目录下
cd $路径 -
重命名
mv -i zookeeper zookeeper -
转至zk目录下
cd zookeeper -
转至配置目录下
cd conf -
复制样本配置文件
cp zoo_sample.cfg zoo.cfg,复制后的才能作为运行时调用配置文件- 注:最后为服务器列表,server后的数字需要与hosts的最后一位相同
-
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/soft/apache-zookeeper-3.9.2-bin/data dataLogDir=/usr/local/soft/apache-zookeeper-3.9.2-bin/log # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # 授权监听所有ip quorumListenOnAllIPs=true # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=node11:2888:3888 server.2=node12:2888:3888 server.3=node13:2888:3888
-
修改数据存储地址
dataDir=/opt/module/zookeeper/zkData,任意路径均可 -
在文件home路径下创建日志文件夹
mkdir logs -
在
/zookeeper/bin目录下执行./zkServer.sh start- 若出现授权相关问题,则分别为上述两个文件夹授权,同时为zkData下
.pid文件授权
- 若出现授权相关问题,则分别为上述两个文件夹授权,同时为zkData下
-
配置环境变量
sudo vim ~/.bashrcexport ZK_HOME=/usr/local/zookeeperexport PATH=${ZK_HOME}/bin:$PATH
-
更新配置文件
source ~/.bashrc -
最后再运行
./zkServer.sh start

7. 完全分布式zookeeper
建议按照顺序1、2、3等命名服务器
-
将
/usr/local下所有文件通过xsync传输入slave1和slave2- 若上述方法出现权限相关问题,则在slave1和slave2上重复之前步骤
- 或者将文件压缩之后发送,然后在相应文件夹下解压即可
-
在zkdata创建myid
- 根据zoo.cfg中的server编号赋值
-
按照上述内容配置环境变量
-
创建集群启动脚本,并授权
-
touch zkStart.sh touch zkStop.sh touch zkStatus.sh -
chmod +x zkStart.sh chmod +x zkStop.sh chmod +x zkStatus.sh -
zkStart.sh内容如下 -
#!/bin/bash echo "zookeeper start 11,12,13..." # 更新配置文件,然后启动,配置文件路径按照自身配置填写,以下同理 ssh node11 "source /etc/profile;zkServer.sh start" ssh node12 "source /etc/profile;zkServer.sh start" ssh node13 "source /etc/profile;zkServer.sh start" -
zkStatus.sh内容如下 -
#!/bin/bash echo "zookeeper start 11,12,13..." ssh node11 "source /etc/profile;zkServer.sh status" ssh node12 "source /etc/profile;zkServer.sh status" ssh node13 "source /etc/profile;zkServer.sh status" -
zkStop.sh内容如下 -
#!/bin/bash echo "zookeeper start 11,12,13..." ssh node11 "source /etc/profile;zkServer.sh stop" ssh node12 "source /etc/profile;zkServer.sh stop" ssh node13 "source /etc/profile;zkServer.sh stop"
-
-
最后测试
-
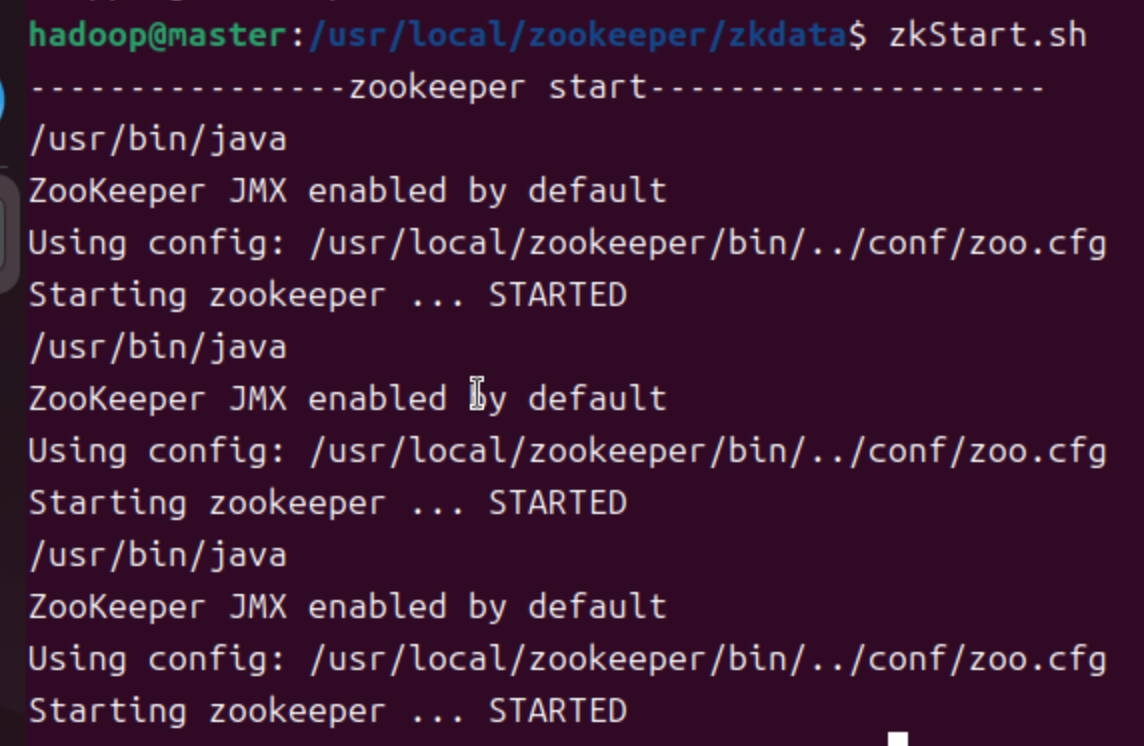
启动
-
查看状态
- tip:注意每个服务器最后一行应当是follower或者leader,若未显示,则检查当前用户是否拥有zookeeper安装目录管理权限,查看
zoo.cfg是否设置监听,IP映射名称是否与ID匹配 
- tip:注意每个服务器最后一行应当是follower或者leader,若未显示,则检查当前用户是否拥有zookeeper安装目录管理权限,查看
-
启动客户端
-
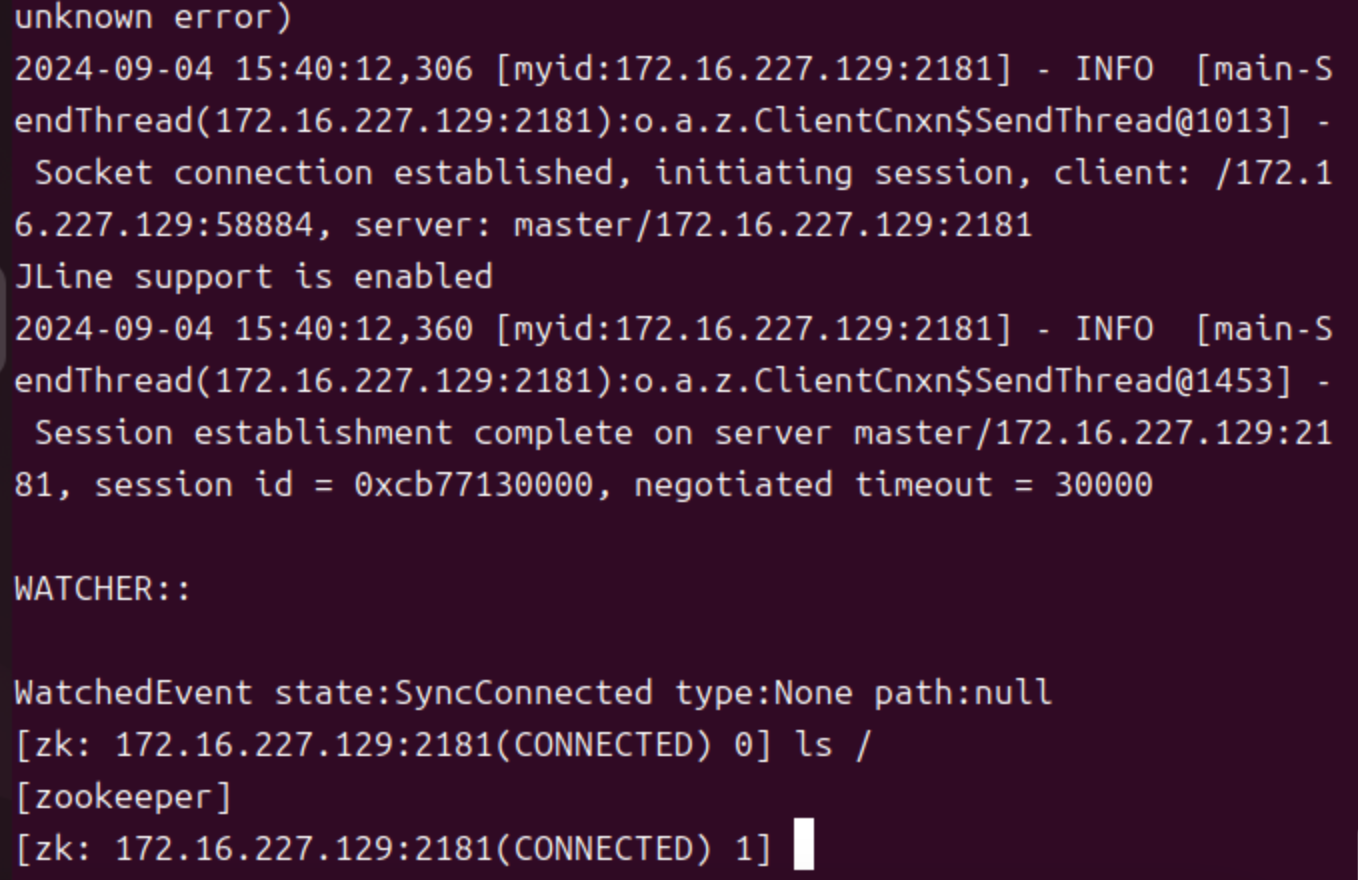
8. 磁盘扩容以及数据恢复
-
在配置hbase,磁盘空间已满导致虚拟机无法启动,重新配置虚拟机
-
尝试扩容磁盘但无效
-
将原vmdk删除
- 先写在目录
sudo umount /dev/shm - 删除目录本身
sudo rmdir /dev/shm(慎重)- 存储一些设备文件。这个目录中的文件都是保存在内存中,而不是磁盘上。其大小是非固定的,即不是预先分配好的内存来存储的。
- 验证
df -hT | grep /dev/shm - 重新挂载
sudo mount -t tmpfs -o defaults none /dev/shm
- 先写在目录
-
按照剩余容量扩容
sudo lvextend -L +<size> /dev/mapper/ubuntu--vg-ubuntu--lv
-
如果还是无效,那么可以调整文件系统的大小以利用新增的空间
sudo resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
-
数据恢复:由于各机器内容大致相同,因此采用克隆方式进行,以下主要记录克隆后操作
-
使用vmware,右键点击完全克隆
-
配置静态ip
cd /etc/netplansudo vim xxx.yaml- 将ip修改为
172.16.227.130 source netplan
-
配置主机名
- (临时)
sudo hostnamectl set-hostname new_hostname - (永久)
sudo nano /etc/hostname - 更新ip中的代称
sudo nano /etc/hosts,修改本机即可
- (临时)
-
修改zookeeper的workid
cd /usr/local/zookeeper/zkdatasudo vim workid
主从节点允许的最大时间误差
9. 单机hbase
这部分不基于zookeeper部署,仅使用hbase自带的zookeeper;后续完全分布式部署时,使用zookeeper
-
下载hbase基于清华镜像
-
tar -zxvf hbase-2.4.18-bin.tar.gz sudo mv -i hbase-2.4.18 hbase
-
-
设置环境变量
-
sudo vim ~/.bashrc export HBASE_HOME=/path/to/hbase export PATH=$PATH:$HBASE_HOME/bin source ~/.bashrc
-
-
配置hbase
-
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <!--zookeeper数据路径:注意创建目录--> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/path/to/hbase/zookeeper</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>localhost</value> </property> <property> <name>hbase.cluster.distributed</name> <value>false</value> </property> </configuration>
-
-
创建存储目录
mkdir -p /path/to/hbase/zookeeper -
格式化hbase
-
cd $HBASE_HOME/bin ./hbase-daemon.sh format
-
-
启动hbase
start-hbase.sh
10. Hbase 完全分布式部署
-
编辑hbase-env.sh
-
export HBASE_HOME=/usr/local/hbase export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64 export HBASE_MANAGES_ZK=false # 如果你已经管理了 ZooKeeper,则设置为 false export HBASE_PID_DIR=${HBASE_HOME}/run export HBASE_LOG_DIR=${HBASE_HOME}/logs export HBASE_CONF_DIR=${HBASE_HOME}/conf
-
-
编辑hadoop-env.sh
-
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64 export LANG=en_US.UTF-8
-
-
编辑hbase-site.xml
-
<configuration> <!-- 指定 ZooKeeper 服务器列表 --> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <!-- 指定 HBase 的根目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop01:8020/hbase</value> </property> <!-- 指定 ZooKeeper 客户端端口 --> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <!-- 指定 ZooKeeper 的会话超时时间 --> <property> <name>zookeeper.session.timeout.upper.limit</name> <value>60000</value> </property> <!--zookeeper数据目录--> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/zookeeper/zkdata</value> </property> <!--主从节点允许的最大时间误差--> <property> <name>hbase.master.maxlockskew</name> <value>180000</value> </property> <!-- 其他可选配置 --> <property> <name>hbase.regionserver.global.memstore.size</name> <value>0.4</value> </property> <property> <name>hbase.regionserver.maxlogs</name> <value>64</value> </property> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.WALCellCodec</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 指定HBase Master Web页面访问端口,默认端口号16010 --> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <!-- 指定HBase RegionServer Web页面访问端口,默认端口号16030 --> <property> <name>hbase.regionserver.info.port</name> <value>16030</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.wal.provider</name> <value>filesystem</value> </property> </configuration>
-
-
创建目录
-
sudo mkdir logs chmod 777 logs
-
-
修改regionservers文件
-
hadoop01 hadoop02 hadoop03
-
-
格式化hbase集群
-
# $hbase_home/bin ./format
-
-
启动hbase集群
start-hbase.sh
配置过程中的debug
-
没有format命令
- 尝试了使用守护进程启动、终端命令启动、hbase命令行启动等方式,均无该命令
- 故手动创建hbase目录以及加载hbase.rootdir
-
zookeeper相关错误导致初始化失败
-
<!--zookeeper数据目录--> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/zookeeper/zkdata</value> </property> -
确保该部分内容和zookeeper当中配置一致
-
-
hmaster未启动,可能导致无法正常关闭hbase等某些错误
- 手动启动hmaster/regionserver
hbase-daemon.sh start regionserver/master hadoop02
-
请注意查看hbase-site.xml中的各项配置,配置缺失或者错误均可能导致bug。按需配置同样重要,对于不需要的部分可以酌情处理