- 论文:https://arxiv.org/pdf/2309.07597
- 代码:GitHub - FlagOpen/FlagEmbedding: Retrieval and Retrieval-augmented LLMs
- 机构:BAAI
- 领域:embedding model
- 发表:SIGIR 2024

研究背景
- 研究问题:这篇文章要解决的问题是如何显著推进中文通用文本嵌入领域的发展。具体来说,作者提出了C-Pack,一套资源包,包括三个关键资源:C-MTP(中文大规模文本对训练数据集)、C-MTEB(中文大规模文本嵌入基准)和BGE(BAAI通用嵌入模型家族)。
- 研究难点:该问题的研究难点包括:需要大规模、多样化的训练数据来提高嵌入模型的判别力;需要扩展模型规模和训练数据规模以提高模型的泛化能力;需要优化训练方法,包括预训练、对比学习和任务特定的微调;需要建立适当的基准来全面评估文本嵌入的通用性。
- 相关工作:该问题的研究相关工作有:Contriever、GTR、Sentence-T5、Sentence-Transformer、E5、OpenAI文本嵌入等。这些工作主要集中在英文场景下的通用文本嵌入,而中文领域的相关研究和资源较为匮乏。
研究方法
这篇论文提出了C-Pack来解决中文通用文本嵌入的问题。具体来说,
-
C-MTEB(中文大规模文本嵌入基准):C-MTEB是MTEB的中文扩展,收集了35个公开可用的数据集,涵盖6种任务类型。通过标准化评估协议和建立评估管道,确保不同嵌入模型可以在公平的基础上进行评估。


-
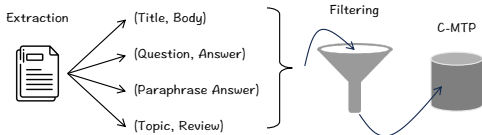
C-MTP(中文大规模文本对训练数据集):C-MTP由两部分组成:C-MTP(未标记)和C-MTP(标记)。C-MTP(未标记)来自大规模无标签网络语料库,如百度百科、知乎和新闻网站,共1亿对文本。C-MTP(标记)来自高质量标记数据集的整合,共83.8万对文本。数据经过过滤和语义过滤,确保文本对的语义相关性。
-

-
BGE(BAAI通用嵌入模型家族):BGE基于BERT架构,提供三种模型规模:小型(0.24亿参数24M)、基础(1.02亿参数102M)和大型(3.26亿参数326M)。模型经过三个阶段训练:预训练、通用对比学习和任务特定微调。
-
训练方法:训练方法包括预训练、通用对比学习和任务特定微调。预训练使用Wudao语料库,采用MAE(masked autoencoder)风格的方法。通用对比学习在C-MTP(未标记)上进行,通过对比成对文本和其负样本进行学习。任务特定微调在C-MTP(标记)上进行,结合指令微调和硬负样本挖掘。
实验设计
实验设计包括以下几个方面:
- 数据收集:C-MTP(未标记)主要来自百度百科、知乎、新闻网站等大规模无标签网络语料库。C-MTP(标记)来自T2-Ranking、mMARCO-Zh、DuReader等高质量标记数据集。
- 样本选择:C-MTP(未标记)共1亿对文本,C-MTP(标记)共83.8万对文本。数据经过过滤和语义过滤,确保文本对的语义相关性。
- 参数配置:BGE模型提供三种规模:小型(2.4亿参数)、基础(1.02亿参数)和大型(3.26亿参数)。对比学习采用大批量(最大19200),以提高嵌入的判别力。
结果与分析
- 总体性能:BGE模型在C-MTEB上的平均性能显著优于现有中文文本嵌入模型,特别是在检索任务和STS任务上。大型模型的泛化能力最强,小型模型在保持较高性能的同时,更适合高通量应用。

- 数据集分析:C-MTP(未标记)对嵌入的检索质量有显著影响,而对其他任务的影响较小。C-MTP(标记)在检索、重排序、STS和成对分类任务上有显著提升。

- 训练方法分析:对比学习采用大批量显著提高了嵌入质量,特别是在检索任务上。指令微调显著提升了任务特定微调的质量,特别是在检索、STS、成对分类和重排序任务上。


总体结论
这篇论文提出了C-Pack,一套全面的资源包,用于推动中文通用文本嵌入领域的发展。C-Pack包括C-MTEB、C-MTP和BGE,并通过优化的训练方法实现了显著的性能提升。实验结果表明,BGE模型在C-MTEB上取得了最先进的性能,验证了C-Pack的有效性和实用性。C-Pack的发布为中文通用文本嵌入的开发、评估和应用提供了坚实的基础,推动了该领域的进一步发展。
论文评价
优点与创新
- C-MTEB基准:建立了C-MTEB,作为C-MTEB的中国扩展,收集了35个公开数据集,涵盖6种任务类型,并标准化了评估协议和管道。
- C-MTP训练数据:创建了一个包含1亿对文本的大规模训练数据集,主要来源于网络语料库,并通过语义过滤和数据清理策略提高了数据质量。
- BGE模型系列:提供了一组预训练的中文通用文本嵌入模型,包括小(24M参数)、基础(102M参数)和大(326M参数)三种规模,显著提升了模型在C-MTEB上的表现。
- 训练方法:整合并优化了训练方法,包括嵌入导向的预训练、通用对比学习和任务特定的微调,帮助社区复现最先进的模型并进行持续改进。
- 英文数据集:除了中文数据集外,还发布了英文文本嵌入的数据集,并且英文模型在英文MTEB基准上达到了最先进的表现。
- 广泛认可:项目在技术社区中广受欢迎,BGE模型系列自发布以来在HuggingFace上获得了超过2000万的下载量,并被多个主要的RAG和文本嵌入框架集成。
不足与反思
- 数据集规模和质量:尽管C-MTP是无标签数据集的主要来源,但其规模和质量仍需进一步提高,以更好地支持嵌入模型的训练。
- 模型微调:尽管任务特定的微调显著提升了模型性能,但如何更有效地利用不同类型的标注数据进行微调仍需进一步研究。
- 对比学习:虽然使用了大批量的对比学习,但如何进一步优化负样本的选择和生成策略仍需探索。
- 多任务学习:多任务学习策略在一定程度上缓解了不同任务之间的冲突,但仍需进一步研究如何平衡不同任务的训练效果。
关键问题及回答
问题1:C-MTEB基准是如何构建的?其主要目的是什么?
C-MTEB(Chinese Massive Text Embedding Benchmark)是MTEB(Massive Text Embedding Benchmark)的中文扩展。其主要目的是建立一个全面评估中文文本嵌入通用性的基准。C-MTEB通过以下步骤构建:
- 数据收集:收集了35个公开可用的中文数据集,这些数据集涵盖了检索、重排序、语义文本相似度(STS)、分类、对分类和聚类等6种任务类型。
- 标准化评估协议:为了确保不同嵌入模型可以在公平的基础上进行评估,C-MTEB设立了标准化的评估协议。
- 评估管道:建立了评估管道,使得不同任务类型的评估可以自动化进行,并便于结果的提交和比较。
通过这些步骤,C-MTEB能够全面测量中文嵌入模型在不同任务上的表现,从而提供一个可靠的评估平台。
问题2:C-MTP训练数据集是如何构建的?其组成和规模如何?
C-MTP(Chinese Massive Text Pairs)训练数据集由两部分组成:C-MTP(未标记)和C-MTP(标记)。
- C-MTP(未标记):主要来自大规模无标签语料库,如百度百科、知乎和新闻网站,共1亿对文本。这些数据通过从网页中提取标题-正文、副标题-段落、问题-答案等结构形成文本对。数据经过一般过滤和语义过滤,以确保文本对的语义相关性。
- C-MTP(标记):集成了多个高质量的标记数据集,如T2-Ranking、DuReader和NLI-Zh,共838,465对文本。这些数据主要用于进一步增强训练数据的质量。
总体来看,C-MTP(未标记)提供了大规模的无标签数据,而C-MTP(标记)则提供了高质量的标注数据,两者共同用于训练和微调文本嵌入模型。
问题3:BGE模型是如何训练的?其训练过程包括哪些主要阶段?
BGE(BAAI General Embeddings)模型基于BERT架构,提供三种模型规模:小型(24M参数)、基础(102M参数)和大型(326M参数)。其训练过程包括以下主要阶段:
- 预训练:使用Wudao语料库进行预训练,采用MAE(Masked Autoencoder)风格的方法。预训练的目标是将污染文本编码成其嵌入,并在其上恢复干净文本。
- 通用对比学习:在C-MTP(未标记)数据集上进行对比学习,通过大规模无标签数据集学习区分正样本和负样本。
- 任务特定微调:在C-MTP(标记)数据集上进行任务特定的微调。微调过程中结合了指令微调和硬负样本挖掘。指令微调通过为每个文本对附加任务特定的指令来帮助模型适应不同任务。
通过这三个阶段的训练,BGE模型能够在各种任务上实现高性能。