最近几天一直在找相关资料,坑太多,也可能我菜的成分更多一点吧!记录下来,以观后用;

背景
-
我手里有一个正点原子的K210的开发板;
-
刚刚安装了wsl2下的
ubuntu22.04 -
我手里有正点原子的源码,但是源码中只有输出好的kmodel模型文件,我并不知道kmodel怎么来的,由此疑问;

-
所以我想尝试用Pyttorch搞个简单的模型跑一下MNIST数据集,然后放进K210里面运行,补充上面的疑问之处;
-
了解到共有如下步骤:模型训练——>导出"model.pth"——>“model.onnx”——>“model.kmodel”——>编译产物"xxx.bin"——>烧录——>成功运行;
-
然后我成功的在"model.onnx"——>"model.kmodel"卡壳了;
需求
- 准备可以转换的onnx模型文件
- 准备转换所需的软件和脚本
- 修改和使用转换所需的脚步
- 执行onnx转kmodel
- 编译烧录之后可以成功运行
步骤
- 我的设备是k210的,根据nncase官网所说,nncase2.x版本不支持,所以我选择nncase1.9;
- 下载和安装时依据我ubuntu的python版本3.10选择如下:
# 下载nncase
root@2b11cc15c7f8:/mnt# wget -P https://github.com/kendryte/nncase/releases/download/v1.9.0/nncase-1.9.0.20230322-cp310-cp310-manylinux_2_24_x86_64.whl
# 安装nncase
root@2b11cc15c7f8:/mnt# pip3 install nncase-1.9.0.20230322-cp310-cp310-manylinux_2_24_x86_64.whl

3. 准备onnx模型
def pth_to_onnx():
# 加载模型
model = OptimizedMobileNetV1()
model.load_state_dict(torch.load('./to_kmodel_test/demo_model.pth'))
# 模型放到cpu上
model = model.to(device)
model.eval()
# 模型输入shape
input_shape = (1, 1, 28, 28)
input_data = torch.randn(input_shape).to(device)
# 模型转onnx,这里注意1.x的nncase不支持动态shape,不能使用dynamic_axes,否则影响转换kmodel
torch.onnx.export(model, input_data, './to_kmodel_test/demo_model.onnx',
do_constant_folding=True,) # 是否执行常量折叠优化
# input_names=["input"], # 输入名
# output_names=["output"], # 输出名
# dynamic_axes={"input": {0: "batch_size"}, # 批处理变量
# "output": {0: "batch_size"}})
# 加载并检查模型
model_onnx = onnx.load('./to_kmodel_test/demo_model.onnx')
onnx.checker.check_model(model_onnx)
print(onnx.helper.printable_graph(model_onnx.graph))
# 使用onnxsim进行模型精简
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, './to_kmodel_test/demo_model.onnx')
print("model to onnx done!")
- 安排转换脚本
我是从 这里 找到的,这里我重命名为onnx_to_kmodel_copy.py
以下代码我只修改了cpl_opt.input_shape = [1, 3, 224, 224]为我的模型输入shapecpl_opt.input_shape = [1, 1, 28, 28]
import argparse
import os
import sys
from pathlib import Path
import cv2
import nncase
import numpy as np
print(os.getpid())
def preproc(img, input_size, transpose=True):
if len(img.shape) == 3:
padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114
else:
padded_img = np.ones(input_size, dtype=np.uint8) * 114
r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1])
resized_img = cv2.resize(
img,
(int(img.shape[1] * r), int(img.shape[0] * r)),
interpolation=cv2.INTER_LINEAR,
).astype(np.uint8)
padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img
padded_img = cv2.cvtColor(padded_img, cv2.COLOR_BGR2RGB)
if transpose:
padded_img = padded_img.transpose((2, 0, 1))
padded_img = np.ascontiguousarray(padded_img)
return padded_img, r
def read_images(imgs_dir: str, test_size: list):
imgs_dir = Path(imgs_dir)
imgs = []
for p in imgs_dir.iterdir():
img = cv2.imread(str(p))
img, _ = preproc(img, test_size, True) # img [h,w,c] rgb,
imgs.append(img)
imgs = np.stack(imgs)
return len(imgs), imgs.tobytes()
def main(onnx: str, kmodel: str, target: str, method: str, imgs_dir: str, test_size: list, legacy: bool, no_preprocess: bool):
cpl_opt = nncase.CompileOptions()
cpl_opt.preprocess = not no_preprocess
# (x - mean) / scale
if legacy:
cpl_opt.swapRB = False # legacy use RGB
cpl_opt.input_range = [0, 1]
cpl_opt.mean = [0.485, 0.456, 0.406]
cpl_opt.std = [0.229, 0.224, 0.225]
else:
cpl_opt.swapRB = True # new model use BGR
cpl_opt.input_range = [0, 255]
cpl_opt.mean = [0, 0, 0]
cpl_opt.std = [1, 1, 1]
cpl_opt.target = target # cpu , k210, k510!
cpl_opt.input_type = 'uint8'
cpl_opt.input_layout = 'NCHW'
# cpl_opt.input_shape = [1, 3, 224, 224]
cpl_opt.input_shape = [1, 1, 28, 28]
cpl_opt.quant_type = 'uint8' # uint8 or int8
compiler = nncase.Compiler(cpl_opt)
with open(onnx, 'rb') as f:
imp_opt = nncase.ImportOptions()
compiler.import_onnx(f.read(), imp_opt)
# ptq
if imgs_dir is not None:
ptq_opt = nncase.PTQTensorOptions()
ptq_opt.calibrate_method = method
ptq_opt.samples_count, tensor_data = read_images(
imgs_dir, test_size)
ptq_opt.set_tensor_data(tensor_data)
compiler.use_ptq(ptq_opt)
compiler.compile()
kmodel_bytes = compiler.gencode_tobytes()
with open(kmodel, 'wb') as of:
of.write(kmodel_bytes)
of.flush()
if __name__ == '__main__':
parser = argparse.ArgumentParser("YOLOX Compile Demo!")
parser.add_argument('onnx', default='model/yolox_nano_224_new.onnx', help='model path')
parser.add_argument('kmodel', default='yolox_nano_224_new.kmodel', help='bin path')
parser.add_argument('--target', default='cpu',
choices=['cpu', 'k210', 'k510'], help='compile target')
parser.add_argument('--method', default='no_clip',
choices=['no_clip', 'l2', 'kld_m0', 'kld_m1', 'kld_m2', 'cdf'],
help='calibrate method')
parser.add_argument('--test_size', default=[224, 224],
nargs='+', help='test size')
parser.add_argument("--imgs_dir", default=None, help="images dir")
parser.add_argument("--legacy", default=False,
action="store_true", help="To be compatible with older versions")
parser.add_argument("--no_preprocess", default=False,
action="store_true", help="disable nncase preprocess for debug")
args = parser.parse_args()
main(args.onnx, args.kmodel, args.target, args.method, args.imgs_dir,
args.test_size, args.legacy, args.no_preprocess)
- 执行onnx转换kmodel
root@2b11cc15c7f8: python3 ./to_kmodel_test/onnx_to_kmodel_copy.py ./to_kmodel_test/demo_model.onnx ./to_kmodel_test/demo_model.kmodel --legacy --target=k210
# 以下为执行成功输出
16303
1. Import graph...
1.1 Pre-process...
|Dequantize:
|Normalize:
2. Optimize target independent...
3. Optimize target dependent...
5. Optimize target dependent after quantization...
6. Optimize modules...
7.1. Merge module regions...
7.2. Optimize buffer fusion...
7.3. Optimize target dependent after buffer fusion...
8. Generate code...
SUMMARY
INPUTS
成功后如下:

- 编译时需要用v1.9版本的
nncaseruntime替换掉原来版本的,保持版本对齐才行,否则编译成功后运行可能出错
# nncaseruntime运行时库
root@2b11cc15c7f8:/mnt# wget https://github.com/kendryte/nncase/releases/download/v1.9.0/nncaseruntime-riscv64-none-k210.zip
替换路径:
kendryte-standalone-sdk/lib/nncase/v1/
删除该路径下的

将解压nncaseruntime-riscv64-none-k210.zip后的文件放进去就可以编译了
探索过程中遇到的问题
- 找不到转换的可用脚本 or 可用命令,一开始看网上大佬2022年的博客用到的nncase都是0.5左右版本的,用到的是ncc命令,更有大佬直接下源码编译,好吧我菜,看官网的使用说明,提供的程序试了有问题,毕竟程序可能是针对2.x版本的,而我的是1.9,最后才在https://github.com/kendryte/nncase/blob/v1.9.0/examples/下找到了yolox的例子,看了 readme ,yolox目录下的model目录有
yolox_nano_224.onnx文件,我就尝试了python tools/compile.py model/yolox_nano_224.onnx yolox_nano_224.kmodel --legacy发现可以,这个过程断断续续花了我3天吧,苦逼啊; - 使用脚本进行onnx转kmodel的时候,死活提示缺少xx shape信息,尝试把模型换成全连接的没问题,
 后穷尽手段后加了nncase 的QQ群,问了专业人士,好,结论如下:
后穷尽手段后加了nncase 的QQ群,问了专业人士,好,结论如下:
1.x的nncase不支持动态shape,不能使用dynamic_axes,否则影响转换kmodel
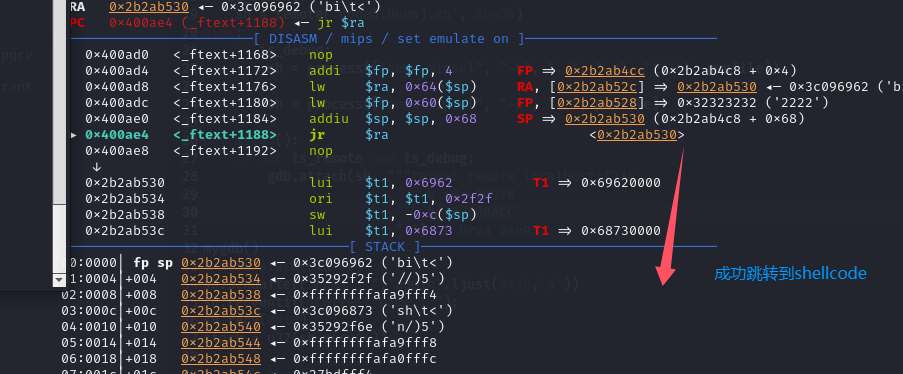
- 终于烧录好,运行时却提示失败,G…,要崩溃了呀,不想玩了,我的模型才100多k,编译后的bin也就1M+
[..m/runtime_module.cpp:65 (shape_reg)] id < shape_regs_.size() = false (bool)
error: Result too large
还好有前人踩坑,大佬回答,一句话我就秒懂,发现编译时需要用v1.9版本的nncaseruntime替换掉原来版本的,保持版本对齐才行
https://github.com/kendryte/kendryte-standalone-sdk/issues/133

![[ComfyUI]太赞了!阿里妈妈发布升级版 Flux 图像修复模型,更强细节生成,更高融合度以及更大分辨率支持](https://img-blog.csdnimg.cn/img_convert/d75751f946039cbef1ac1c1b48830a98.png)