事先声明一下,仅分享爬虫经验,不会对网站有影响的,也请想要实操的小伙伴不要对网站频繁访问,如有侵权请联系我删除文章
文章目录
- 代码展示
- 步骤解析
- 思路整理
- 节点树
- xPath语法
- 分析网页结构
- 实战思路
- 获取源代码
- 源代码转化成节点树
- 提取信息
- 文本处理
- 写入文件
- 整理成函数
- 从目录页获取每个独立页面的链接!
代码展示
import requests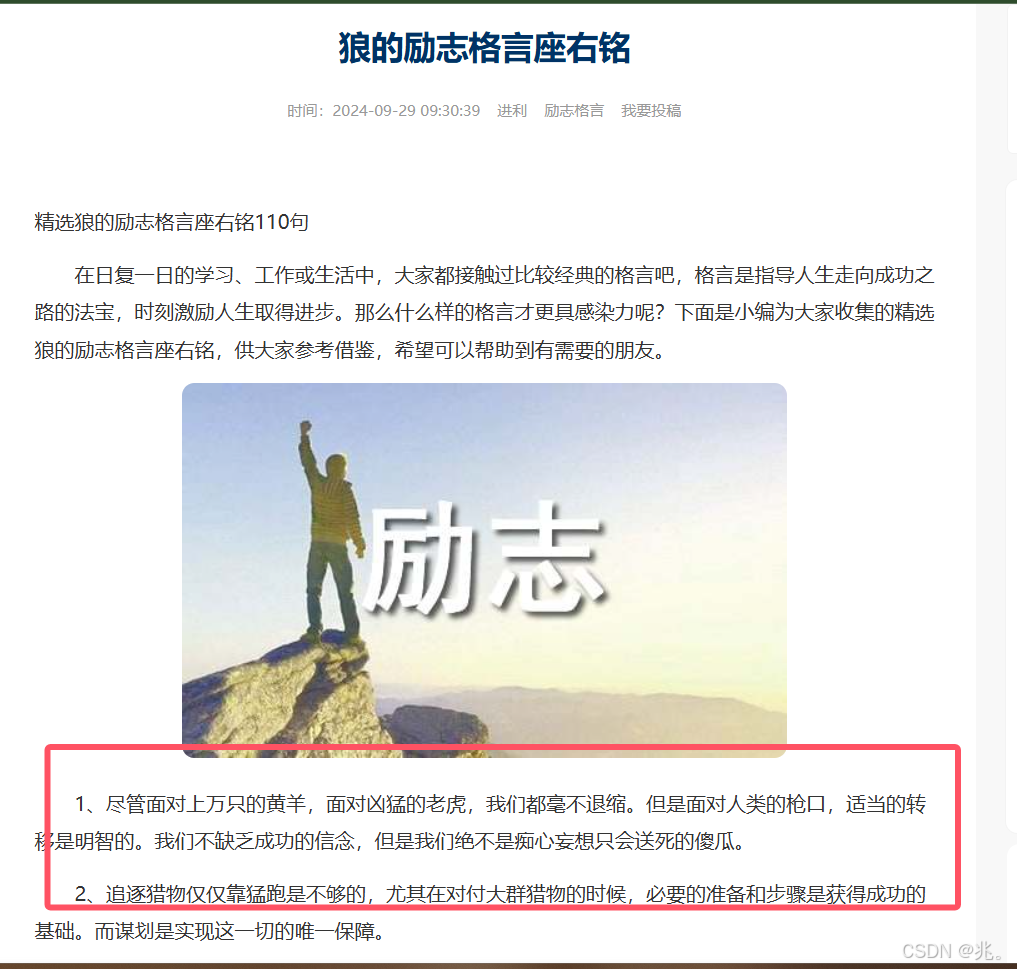
from lxml import etree
def pachong(url):
results = requests.get(url=url)
html = etree.HTML(results.text)
link = html.xpath('//div[@class="content"]//p/text()')
wenben = "".join(link)
listtt = wenben.split()
print(listtt[0])
title = listtt[0]
with open(f'{title}.text','wb') as f:
for i in listtt:
f.write((i + '\n\n').encode('utf-8'))
print(f'已完成……{title}')
url = 'https://www.yjbys.com/lizhi/geyan/'
rt = requests.get(url=url)
html = etree.HTML(rt.text)
lianjie = html.xpath('//div[@class="newlist"]//dt//a/@href')
for link in lianjie:
pachong(link)
上面就是实现对一个网站某些内容的板块的爬取
步骤解析
- 访问人生格言目录页面
- 获取各种分支格言的链接
- 按照链接批次访问格言详细页面
- 提取格言内容
- 把格言保存到本地文件中
思路整理
首先是点开一个网站,确定我们想要爬取的内容

这里我们想要得到的是框起来的内容
然后看这段内容是在源代码里面还是包里面,如果是源代码那就简单多了使用xPath语法把这些内容摘出来就可以了,如果是在包里面,就需要使用其他的方法

很明显,这些信息都是包含在源代码里面
节点树
一般而言,这个网站的源代码的结构跟一个树相似,有html这个根,还有各种分支,也就是head和body等等
这个结构一般是对称的,比如上面这个页面中,<p></p>由p节点开始,再由p节点结束
xPath语法
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于bookstore 元素的子元素的book元素 |
| //title[@lang] | 选取所有拥有名为lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为eng的lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore元素的所有book元素,且其中的price 元素的值须大于35.00。 |
| /bookstore/book[price>35.00]/title | 选取bookstore元素中的book元素的所有title 元素,且其中的 price 元素的值须大于 35.00。 |
这个语法是拆分信息的重点
分析网页结构
在刚刚上面那个图片中,第一个框里面,就是一个节点,属性是class=“content”
所以我们要在源代码中查找一个叫div的节点,属性是class=“content”
用xPath语法就是//div[@class=“content”]
找到这个节点之后,还要他下面的所有p节点,很明显在网页上的一段话都是相互分开的,由很多个p节点
这一步用xPath语法就是//div[@class=“content”]//p
找到每一个p节点之后,还要里面的文本部分
这一步用xPath语法就是//div[@class=“content”]//p/text()
实战思路
获取源代码
使用requests模块
点击网页中任意一个包,发现是get请求
经过测试发现不需要请求头就可以获取数据,只需要一个链接,就可以得到源代码了,非常容易
再打印一下返回值,检查是不是200
再转换成text格式
源代码转化成节点树
这里我们用到了lxml库里面的etree模块
from lxml import etree
需要提取安装lxml库
html = etree.HTML(rt.text)
这一步就是把text格式源代码转换成节点树
提取信息
对节点树提取信息
link = html.xpath('//div[@class="content"]//p/text()')
打印link检查是不是那些文本,得到了文本之后就是对文本进行处理
文本处理
这些文本还需要用join进行格式处理
这时候已经是一个个独立的文本了,再进行列表化使用split函数

写入文件
然后就是获取这篇文章的标题作为文件名,开始创建文件,这里就是列表的第0位元素
接着就是使用for循环把元素依次写入文件
url = 'https://www.yjbys.com/lizhi/geyan/315372.html'
rt = requests.get(url=url)
# print(rt.text) # 查看源代码
html = etree.HTML(rt.text) # 把源代码导入节点树
content = html.xpath('//div[@class="content"]//p/text()') # 从任意未知查找属性为class="content"的节点 在该节点所有是p节点的文本部分拿出来
wenben = "".join(content) # 这部分是把文本部分转换成join的格式
print(wenben.split()) # 把文本转成列表格式
listtt = wenben.split()
print(listtt[0]) # 把每一句话都当成列表的一个元素,再逐个写入文件
title = listtt[0]
with open(f'{title}.text','wb') as f:
for i in listtt:
# 将行转换为字节并写入文件
f.write((i + '\n\n').encode('utf-8'))
print(f'已完成……{title}')
这个代码实现了对一个页面进行爬取
整理成函数
把上面这个单文件操作改成一个函数
发现只需要一个链接就可以获取信息,我们也只需要给一个链接

从目录页获取每个独立页面的链接!
发现每个链接都是在节点div属性是class="newlist"下面的所有dt节点的a节点的href属性
用xPath语法就是//div[@class=“newlist”]//dt//a/@href
这里的链接有很多,我们还是把他看成列表,再次使用for循环,把获取到的链接给上面的函数
在成功下载文件后给自己一个提示,就可以在项目文件夹中看到爬取的信息了
















![开源版GPT-4o来了!互腾讯引领风潮,开源VITA多模态大模型,开启自然人机交互新纪元[文末领福利]](https://i-blog.csdnimg.cn/direct/a5e92a790bf947da9b4578e6326a6970.png)