如何批量下载淘宝主图、详情图和SKU图?在电商行业竞争日益激烈的今天,电商从业者面临着前所未有的挑战与机遇。为了提升商品竞争力,深入分析对手策略及优化自家产品展示成为日常工作的重中之重。其中,批量下载淘宝主图、详情图和SKU图(库存单位图片)成为了一项不可或缺的任务。主图是吸引顾客点击的第一道门槛,其设计风格和呈现的信息直接影响点击率;详情图则详细展示了产品的各个角度、功能特点和使用场景,是促成转化的关键;而SKU图则帮助消费者快速区分不同规格或颜色的商品,提升购物体验。
下面小编将给大家分享几个方法,教大家怎么批量批量下载淘宝主图、详情图和SKU图,并且可以多个网页同时批量下载,这样效率就更加的高,详细的方法和步骤请往下看吧。

方法一:使用“星优图片下载助手”软件进行批量下载
步骤1,请将本次使用的“星优图片下载助手”软件下载到电脑上,随后进行安装和使用。在软件左侧可以看到很多的功能按键,本次请你点击【淘宝】图片批量下载功能。
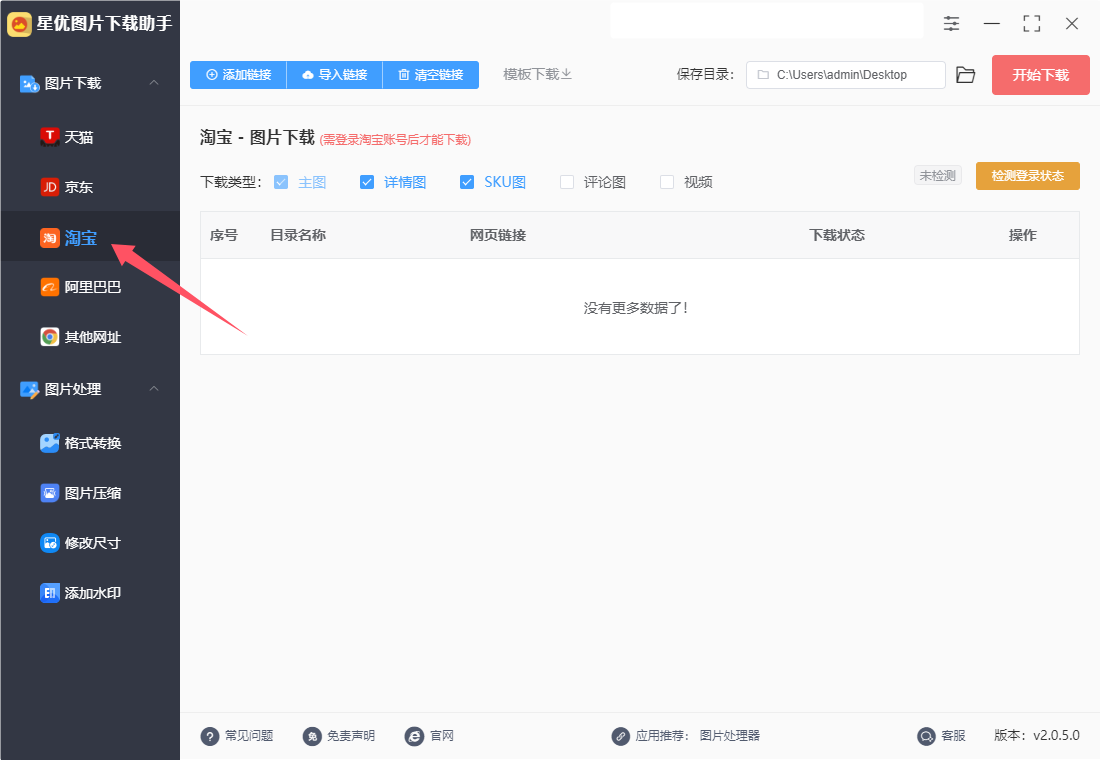
步骤2,这一步添加淘宝商品网页链接到软件里:点击【添加链接】按键后会弹出添加窗口,不过一次只能添加一个链接,多个链接需要分多次添加;点击【导入链接】按键可以一次导入多个链接到软件里,导入格式为excel,excel的第一列填写链接名,第二列填写链接。
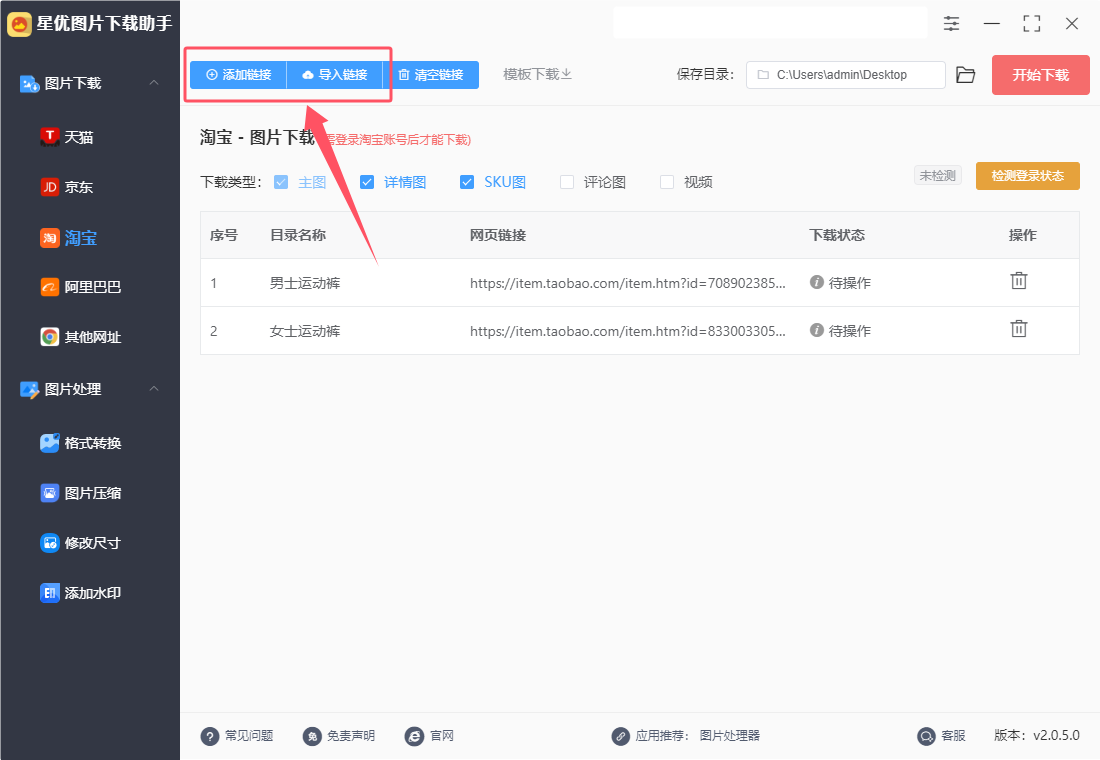
步骤3,选择要下载的图片类型,淘宝主图、详情图、SKU图、评论图和视频五种类型,需要下载哪种就勾选哪种。
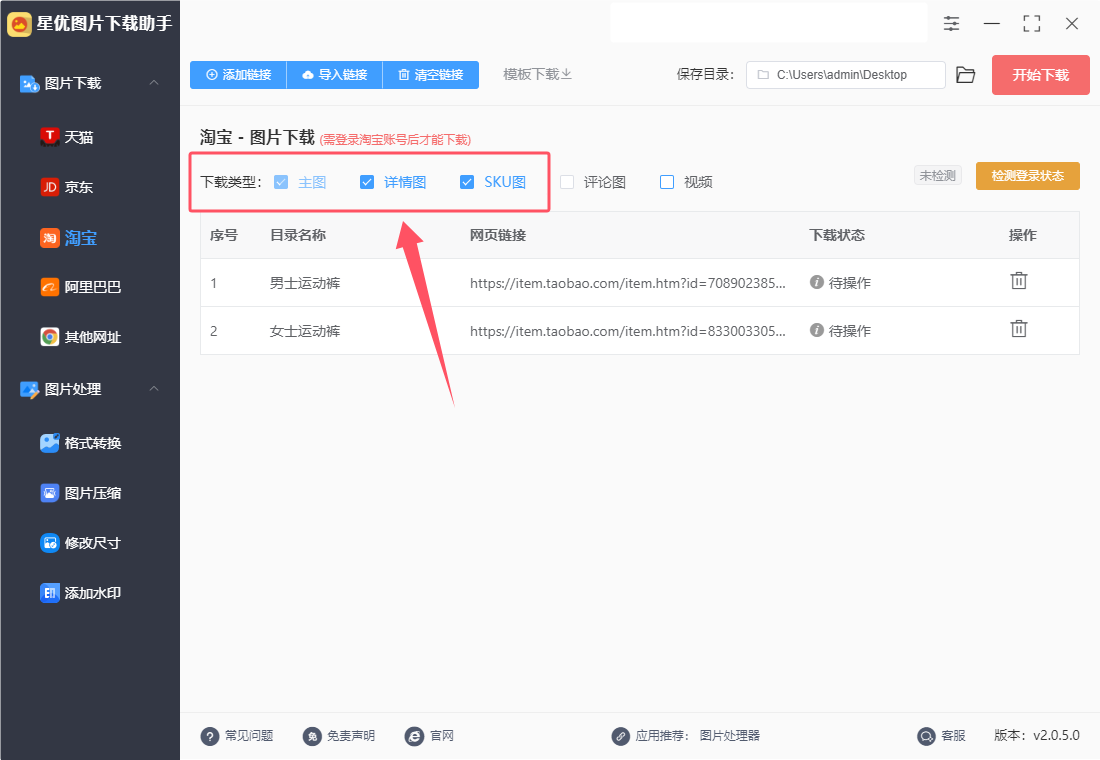
步骤4,登录淘宝账号,因为只有登录账号才能下载图片,登录步骤如下:
① 如下图所示先点击“检测登录状态”检测登录状态,检测完成后左侧会出现“未登录,点击登录淘宝账号”文字按键,点击后进行下一步。
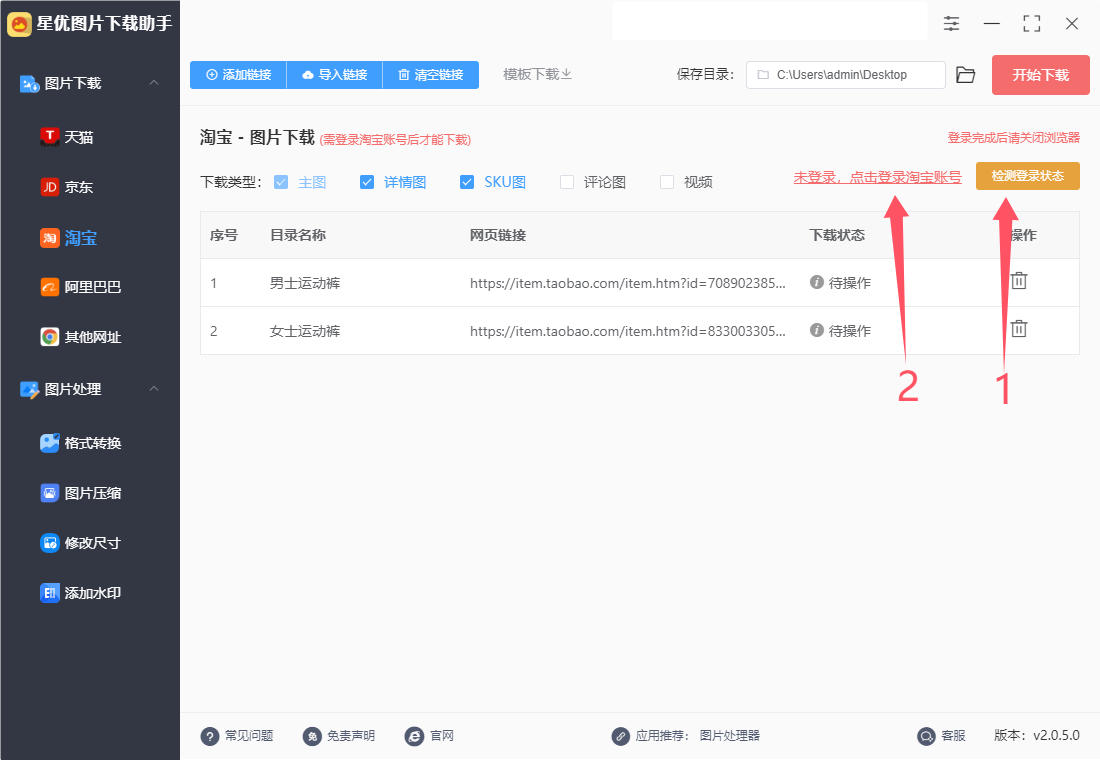
② 随后软件弹出淘宝账号登录窗口,大家在此登录自己的淘宝账号,登录完成后可以关闭窗口。

步骤5,这样准备工作就全部结束了,此时点击右上角【开始下载】红色按键即可启动图片批量下载程序,大家需要耐心等待一会,图片如果比较多则需要一点下载时间。
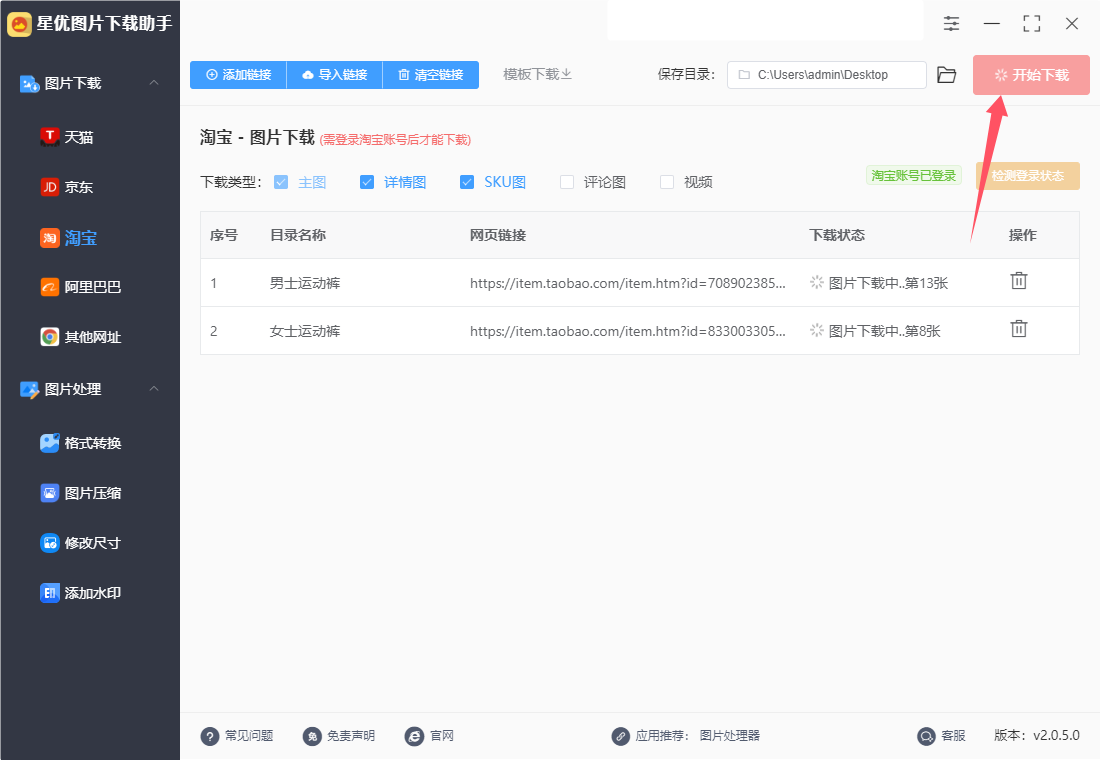
步骤6,下载完毕后软件会自动弹出保存目录,在这里你可以看到每个淘宝网页链接都会生成一个文件夹,下载的图片则保存在对应的文件夹里。
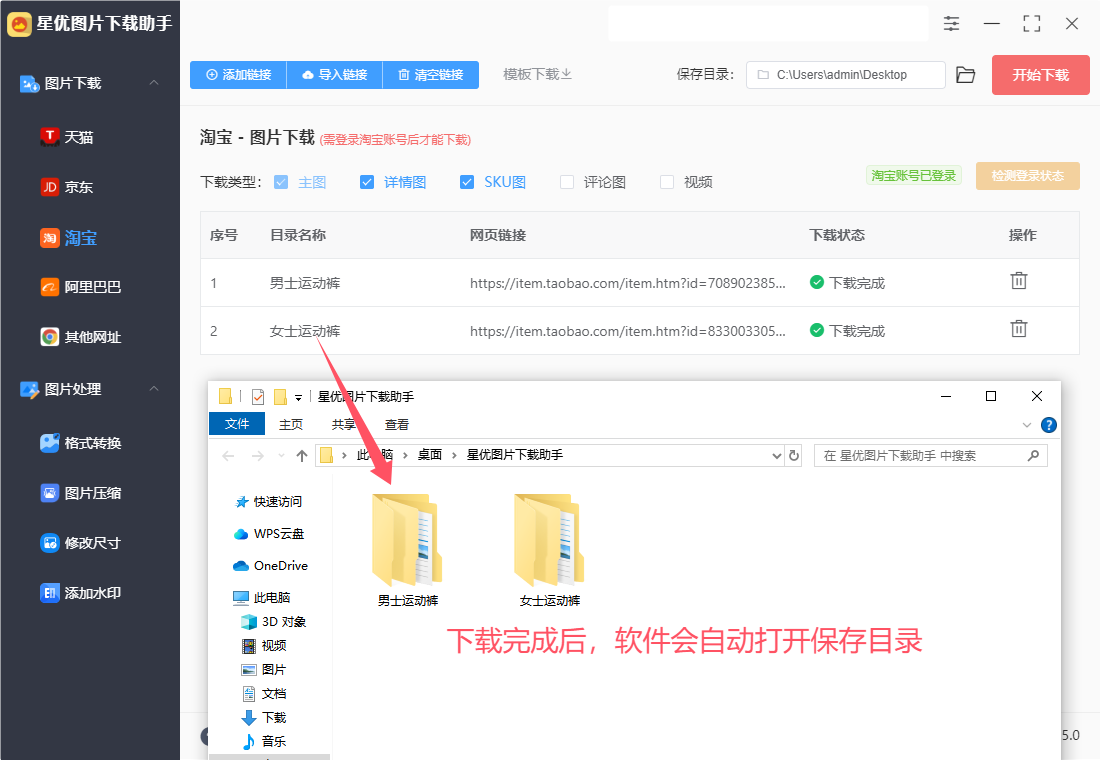
步骤7,进行仔细的检查,可以看到图片被分类下载在不同文件夹里,主图下载在主图文件夹里,详情图下载在详情图文件夹里,这样后面使用起来就非常方便。
方法二:使用Grabber批量下载
使用 Grabber 批量下载淘宝图片的步骤如下:
1. 下载并安装 Grabber
下载最新版本的安装程序。
根据系统提示完成安装。
2. 设置 Grabber
打开 Grabber 软件。
在主界面上,选择 “新建项目” 或 “New Project”。
3. 输入目标网址
在项目设置中,输入你要抓取的淘宝页面的 URL。例如,输入某个商品的详细页面链接。
4. 配置抓取规则
在 “抓取规则” 或 “Extraction Rules” 中设置需要下载的内容。通常淘宝商品图片的 URL 以特定的格式命名。
通常情况下,抓取图片的规则可以设置为:
URL 类型:选择“图像”或“图片”
过滤条件:可以根据文件格式(如 JPG、PNG)进行设置,确保只抓取你需要的格式。
5. 测试抓取
在设置好抓取规则后,可以使用 “测试抓取” 功能来确认设置是否正确,查看是否能抓取到图片链接。
如果测试成功,Grabber 会显示找到的图片链接。
6. 开始抓取
点击 “开始抓取” 按钮,Grabber 会根据设置自动下载淘宝页面上的所有图片。
你可以在抓取过程中查看进度和已下载的图片。
7. 查看和管理下载的图片
下载完成后,Grabber 会将下载的图片保存在指定的文件夹中。你可以在软件中找到下载文件的路径,或者在你的电脑上直接访问。
注意事项
淘宝限制:淘宝有时会对访问进行限制,可能需要使用 VPN 或其他工具绕过限制。
图片版权:确保在下载图片时遵循淘宝的使用条款和版权规定。
抓取速度:如果一次抓取的图片较多,可以考虑设置下载速度,以避免被网站封禁。
结论
使用 Grabber 来批量下载淘宝图片是一个高效的方式,只要配置正确的抓取规则,就能快速获取所需的商品图片。
方法三:获取图片链接后批量下载
批量获取淘宝网页里的图片链接并下载图片可以通过一些工具和方法来实现。以下是详细的步骤,涵盖使用 Python 脚本进行抓取和下载的过程。
一:准备工作
① 安装 Python:
如果你还没有安装 Python,可以从 Python 官方网站 下载并安装。
② 安装必要的库:
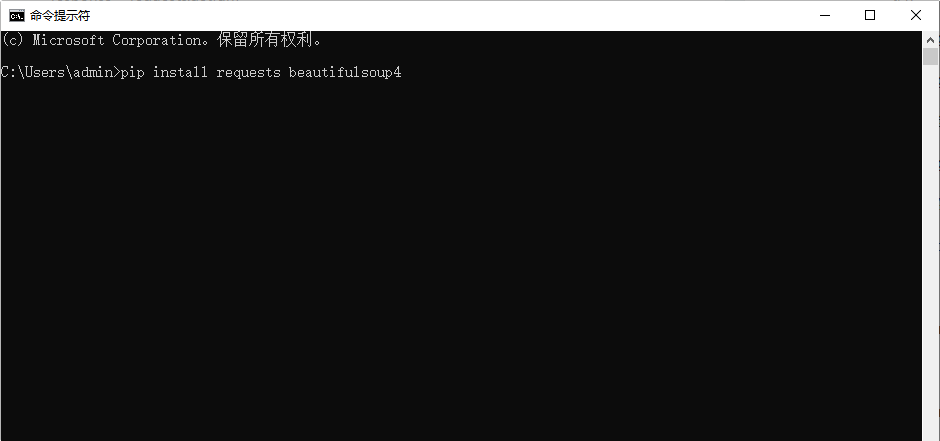
使用 pip 安装 requests 和 BeautifulSoup 库。打开命令提示符或终端,输入以下命令:
pip install requests beautifulsoup4
③ 了解基本的网页结构:
打开淘宝页面,右键点击需要提取图片的区域,选择“检查”或“查看页面源代码”,熟悉网页的 HTML 结构。
步骤 1:获取图片链接
下面是一个使用 Python 的示例代码,获取淘宝页面中的图片链接:
import requests
from bs4 import BeautifulSoup
# 设置淘宝商品页面的 URL
url = 'https://item.taobao.com/item.htm?id=XXXXXX' # 将 XXXXXX 替换为具体商品的 ID
# 发起请求
response = requests.get(url)
response.encoding = 'utf-8' # 设置编码
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 获取图片链接
image_links = []
# 根据淘宝的网页结构提取图片链接,具体情况可能需要调整选择器
for img in soup.find_all('img'):
img_src = img.get('src') or img.get('data-src')
if img_src:
image_links.append(img_src)
# 打印链接
for link in image_links:
print(link)
步骤 2:下载图片
在获取到图片链接后,可以使用以下代码批量下载这些图片:
import os
# 创建存放图片的文件夹
if not os.path.exists('taobao_images'):
os.makedirs('taobao_images')
# 下载图片
for index, link in enumerate(image_links):
try:
img_response = requests.get(link)
img_response.raise_for_status() # 检查请求是否成功
# 创建图片文件名
img_name = f'taobao_images/image_{index + 1}.jpg'
# 保存图片
with open(img_name, 'wb') as img_file:
img_file.write(img_response.content)
print(f'下载成功: {img_name}')
except Exception as e:
print(f'下载失败: {link}, 错误信息: {e}')
步骤 3:运行代码
保存代码:将上述代码分别保存为 get_images.py 和 download_images.py。
修改 URL:在 get_images.py 中将 url 替换为你想获取图片的淘宝商品页面的实际链接。
执行脚本:
在命令行中,导航到脚本所在的目录,执行:
bash
python get_images.py
然后执行:
bash
python download_images.py
小贴士
注意:淘宝可能会对频繁访问其网页的行为进行限制,请适度使用此方法。
图片格式:根据网页的不同,图片的格式可能会有所不同(如 .jpg、.png),可以在保存文件时动态设置扩展名。
获取多个页面的图片:若需批量获取多个商品的图片链接,可以在 get_images.py 中循环访问不同的商品链接。
使用爬虫框架:如果需要更加复杂的爬虫功能,可以考虑使用 Scrapy 等爬虫框架。
总结
通过上述步骤,你可以成功获取淘宝网页中的图片链接并批量下载这些图片。
为了高效地完成这些图片的收集工作,电商从业者需要借助专业的工具或软件。这些工具不仅能快速批量下载指定店铺或商品的所有相关图片,还能保持图片的高清晰度,避免信息损失。通过自动化流程,大大节省了人工搜索、逐一保存的时间,让从业者有更多精力投入到图片分析、创意优化等更有价值的工作中。此外,批量下载图片还便于建立产品资料库,为后续的营销推广、竞品分析提供坚实的数据支持。电商从业者可以根据收集到的图片信息,快速调整营销策略,提升产品曝光度和转化率,从而在激烈的市场竞争中脱颖而出。总之,批量下载淘宝主图、详情图和SKU图是电商从业者提升运营效率、优化商品展示的重要手段,借助科技力量,让电商之路更加顺畅高效。关于“如何批量下载淘宝主图、详情图和SKU图?”的解决办法介绍就到此结束了,上面方法中小编认为还是第一个方法比较简单,建议大家都去试一试。



















