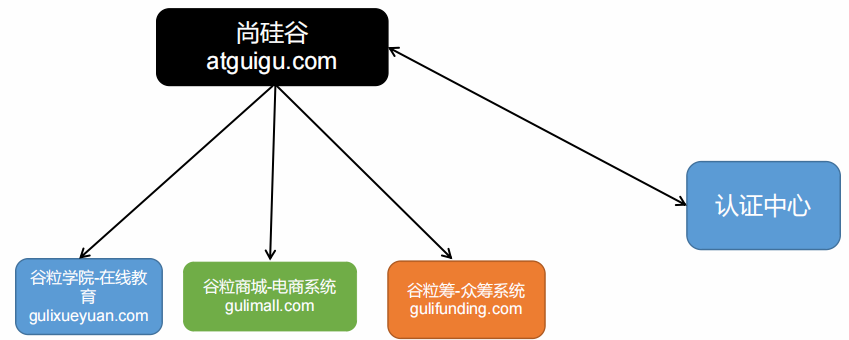
Utralytics YOLO V11🚀
之后做项目要用到YOLO,然后也是趁着这个机会捡一下YOLO的相关的知识,这篇博客记录一下,配置Utralytics建立一个训练YOLO的环境,然后使用官方提供的COCO.yaml文件进行自动下载和训练的完整过程,整个过程也是比较曲折,里面涉及到的细节有很多,最终是做出了一个可实现的版本。
Ultralytics是一家专注于开发先进计算机视觉模型的技术公司,特别是在目标检测和图像识别任务方面。它最为人知的是创建和维护了YOLO(You Only Look Once)系列模型,这些模型因其速度快、精度高而被广泛应用于实时目标检测。公司的模型,如YOLOv5和YOLOv8,旨在易于实现、高效并且在各种应用场景中具有很强的性能表现,包括安防系统和自动驾驶等领域。Ultralytics还提供工具、教程和开源代码,帮助工业和科研领域的用户更好地使用这些模型。

文章目录
- Utralytics YOLO V11🚀
- 1.新建Conda 虚拟环境
- 2.安装GPU pytroch
- 3.安装Utralytics
- 4.下载YOLO V11 模型
- 5.下载COCO数据集
- 6.下载 COCO.yaml
- <font color="blue">7.搭建训练文件目录
- 8.制作txt格式标签
- 9.制作存储图片路径的txt文件
- 10.修改yaml文件
- 11.进行训练
- 🎂Code训练代码
- 12.结束
1.新建Conda 虚拟环境
首先是要新建一个虚拟环境,10月份了,我之前用的都是3.10,然后我觉得python官方的最新的稳定版本应该是更新了,通过查看官网我发现,现在的最新的稳定版本是3.11了,所以的话这次打算安装了一个最新的稳定版本。
https://www.python.org/downloads/

- 在Anaconda 命令提示窗中输入如下新建环境命令(这里由于我之前安装过其他3.11版本,所以没出进度条直接用的本地缓存进度)
conda create --name ultralytics python=3.11

- 在命令提示行内输入python,可以看到安装的python版本,我们的命令安装的python版本为3.11.7。

2.安装GPU pytroch
首先需要进入我们上一步建立好的虚拟环境
conda activate ultralytics

- 然后win+R 打开系统命令窗口输入cmd(这是另外一个命令窗口)

输入下面的命令查看cuda版本(前提已经安好了GPU的各项驱动)
nvidia-smi

- 我自己的CUDA版本是12.6,然后进入pytroch官网,去找安装pytroch的下载命令。https://pytorch.org/,首先
Package这一行我们选Conda,因为我们用的的是Anaconda建立的虚拟环境,用conda命令安装会舒服些。然后在ompute Platform一行选一个自己能安装的版本,例如我的CUDA版本是12.6,然后我就选了12.4。

然后把下面的下载命令复制下来,复制到之前的Conda的命令提示框中。

输入命令之后,按回车,出现如下内容。

拉到下面,然后输入y然后回车。

然后由于之前我在其他虚拟环境中下载过对应版本的pytroch,所以没出进度条,直接出现了done,表示下载完成。

然后,输入pip list 看到pytorch已经下载成功了。

3.安装Utralytics
然后就是安装Utralytics,这个也是很简单粗暴,直接按照官方提示 pip install 安装就行了,我自己配置了清华园下载能稍微快点。
pip install ultralytics


然后再输入一下pip list 就可以看到 pytroch 和 ultralytics 都已经被正确安装了。

4.下载YOLO V11 模型
进入到Ultralytics 的YOLO V11 的下载界面,然后点进去之后稍微下滑一下就能看到Performance Metrics然后需要什么版本点蓝色的版本名称完就可以下了。然后左侧是其他版本的YOLO版本的模型文件下载地址。(如果要从官网主页面进的话,就是先点上方选项卡的Models选项卡,然后点左侧的YOLO 11)
https://docs.ultralytics.com/models/yolo11/#supported-tasks-and-modes


5.下载COCO数据集
在Kaggle里下载就行了,27个G大概解压之后。
https://www.kaggle.com/datasets/awsaf49/coco-2017-dataset?resource=download

6.下载 COCO.yaml
https://docs.ultralytics.com/datasets/detect/coco/#usage
然后就是下载COCO,数据集的yaml文件。
COCO(Common Objects in Context)数据集是一个广泛使用的计算机视觉数据集,旨在支持对象检测、分割和图像标注等任务。它包含了超过33万张复杂的日常生活场景图片,覆盖了80类常见物体,每张图片中物体被标注在不同的上下文环境中,具有丰富的多样性。COCO数据集以其精细的标注和多种任务的支持而闻名,广泛用于训练和评估深度学习模型,尤其是在目标检测和图像语义分割领域。



7.搭建训练文件目录
- 这块我折腾了一阵才整明白,首是新建一个项目,然后把coco2017数据集解压进来,然后把下载的coco.yaml也拖进去。
然后在项目文件下下新建一个datasets文件下,然后datasets文件下下再建两个新的文件夹images和labels。

然后把coco2017中的 train2017和val2017粘到datasets/images里(这两个文件还挺大的,最好是在外部文件夹复制粘贴,不要在Pycharm内复制粘贴)

然后在labels下面也建两个空文件夹,一个是train2017,一个是val2017。

8.制作txt格式标签
在项目文件下下新建了一个make_label.py文件,然后需要用coco2017中annotation中的json文件解析成txt类型的标签。

把下面代码粘贴进去,然后训练集和验证集各运行一次,代码参考了一方热衷博主的博客,在此表示感谢。
import os
import json
from tqdm import tqdm
import argparse
# 生成训练集标签(换成自己的路径)
json_path = r'E:\YOLO_V11\coco2017\annotations\instances_train2017.json'
label_path = r'E:\YOLO_V11\datasets\labels\train2017'
# 生成验证集标签 (换成自己的路径)
# json_path = r'E:\YOLO_V11\coco2017\annotations\instances_val2017.json'
# label_path = r'E:\YOLO_V11\datasets\labels\val2017'
parser = argparse.ArgumentParser()
parser.add_argument('--json_path', default=json_path, type=str,
help="input: coco format(json)")
parser.add_argument('--save_path', default=label_path, type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {}
for i, category in enumerate(data['categories']):
id_map[category['id']] = i
# 通过事先建表来降低时间复杂度
max_id = 0
for img in data['images']:
max_id = max(max_id, img['id'])
img_ann_dict = [[] for i in range(max_id + 1)]
for i, ann in enumerate(data['annotations']):
img_ann_dict[ann['image_id']].append(i)
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt"
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann_id in img_ann_dict[img_id]:
ann = data['annotations'][ann_id]
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
运行生成训练集txt文件形式代码。

运行生成验证集txt文件形式代码。

运行之后,labels下的两个文件夹内充斥着大量的txt标签文件,下面是labels/train2017文件下的txt文件。

9.制作存储图片路径的txt文件
在项目文件下下新建一个make_txt.py

代码粘贴进去,然后也是训练集运行一遍测试集运行一遍得到两个txt文件。
import os
# 指定要读取的文件夹路径
# folder_path = r"E:\YOLO_V11\datasets\images\train2017" # 替换为你的文件夹路径
# output_file = "train.txt" # 存储结果的txt文件
folder_path = r"E:\YOLO_V11\datasets\images\val2017" # 替换为你的文件夹路径
output_file = "val.txt" # 存储结果的txt文件
# 获取文件夹中所有文件的绝对路径
file_paths = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
# 将文件路径按行写入txt文件
with open(output_file, "w") as f:
for file_path in file_paths:
f.write(file_path + "\n")
print(f"文件路径已存储在 {output_file} 中。")
然后得到两个包含训练集和测试集图片的绝对路径。

10.修改yaml文件
把数据集训练集测试集图片路径改了。

改成自己的,然后test不用管给注释掉。

11.进行训练
在项目文件下下新建一个train.py文件复制下面的代码,把下载好的权重托进去。

🎂Code训练代码
在这里为了得到结果,直接设置了epochs=1,这里multiprocessing.freeze_support()起的是线程保护作用,因为我如果不加这个的话,会报线程错位。
from ultralytics import YOLO
import multiprocessing
if __name__ == "__main__":
multiprocessing.freeze_support()
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco.yaml", epochs=1, imgsz=640)
训练输出
D:\ProgramData\anaconda3\envs\utralytics\python.exe E:\YOLO_V11\train.py
Ultralytics 8.3.6 🚀 Python-3.11.10 torch-2.4.1 CUDA:0 (NVIDIA GeForce RTX 4070 Ti, 12281MiB)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco.yaml, epochs=1, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\detect\train
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]
23 [16, 19, 22] 1 464912 ultralytics.nn.modules.head.Detect [80, [64, 128, 256]]
YOLO11n summary: 319 layers, 2,624,080 parameters, 2,624,064 gradients, 6.6 GFLOPs
Transferred 499/499 items from pretrained weights
Freezing layer 'model.23.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLO11n...
AMP: checks passed ✅
train: Scanning E:\YOLO_V11\datasets\labels\train2017... 118287 images, 1021 backgrounds, 0 corrupt: 100%|██████████| 118287/118287 [00:41<00:00, 2822.60it/s]
train: WARNING ⚠️ E:\YOLO_V11\datasets\images\train2017\000000099844.jpg: 2 duplicate labels removed
train: WARNING ⚠️ E:\YOLO_V11\datasets\images\train2017\000000201706.jpg: 1 duplicate labels removed
train: WARNING ⚠️ E:\YOLO_V11\datasets\images\train2017\000000214087.jpg: 1 duplicate labels removed
train: WARNING ⚠️ E:\YOLO_V11\datasets\images\train2017\000000522365.jpg: 1 duplicate labels removed
train: New cache created: E:\YOLO_V11\datasets\labels\train2017.cache
val: Scanning E:\YOLO_V11\datasets\labels\val2017... 5000 images, 48 backgrounds, 0 corrupt: 100%|██████████| 5000/5000 [00:02<00:00, 2493.98it/s]
val: New cache created: E:\YOLO_V11\datasets\labels\val2017.cache
Plotting labels to runs\detect\train\labels.jpg...
0%| | 0/7393 [00:00<?, ?it/s]optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000119, momentum=0.9) with parameter groups 81 weight(decay=0.0), 88 weight(decay=0.0005), 87 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs\detect\train
Starting training for 1 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/1 4.01G 1.159 1.298 1.214 240 640: 100%|██████████| 7393/7393 [08:57<00:00, 13.76it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 157/157 [00:21<00:00, 7.20it/s]
all 5000 36781 0.632 0.478 0.518 0.364
1 epochs completed in 0.156 hours.
Optimizer stripped from runs\detect\train\weights\last.pt, 5.5MB
Optimizer stripped from runs\detect\train\weights\best.pt, 5.5MB
Validating runs\detect\train\weights\best.pt...
Ultralytics 8.3.6 🚀 Python-3.11.10 torch-2.4.1 CUDA:0 (NVIDIA GeForce RTX 4070 Ti, 12281MiB)
YOLO11n summary (fused): 238 layers, 2,616,248 parameters, 0 gradients, 6.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 157/157 [00:18<00:00, 8.61it/s]
all 5000 36781 0.632 0.477 0.518 0.364
person 2693 11004 0.77 0.64 0.73 0.499
bicycle 149 316 0.694 0.383 0.449 0.255
car 535 1932 0.643 0.525 0.56 0.353
motorcycle 159 371 0.697 0.598 0.639 0.402
airplane 97 143 0.801 0.776 0.852 0.653
bus 189 285 0.777 0.677 0.743 0.614
train 157 190 0.827 0.754 0.827 0.657
truck 250 415 0.492 0.437 0.446 0.301
boat 121 430 0.588 0.344 0.389 0.205
traffic light 191 637 0.63 0.317 0.39 0.206
fire hydrant 86 101 0.935 0.714 0.798 0.626
stop sign 69 75 0.587 0.606 0.627 0.578
parking meter 37 60 0.66 0.45 0.514 0.384
bench 235 413 0.553 0.271 0.301 0.197
bird 125 440 0.584 0.377 0.41 0.259
cat 184 202 0.775 0.803 0.853 0.665
dog 177 218 0.702 0.693 0.741 0.604
horse 128 273 0.729 0.719 0.752 0.562
sheep 65 361 0.707 0.643 0.713 0.474
cow 87 380 0.715 0.6 0.692 0.481
elephant 89 255 0.664 0.837 0.826 0.624
bear 49 71 0.672 0.887 0.869 0.69
zebra 85 268 0.757 0.835 0.88 0.643
giraffe 101 232 0.836 0.838 0.882 0.678
backpack 228 371 0.488 0.162 0.174 0.0897
umbrella 174 413 0.641 0.462 0.504 0.331
handbag 292 540 0.545 0.0821 0.147 0.0784
tie 145 254 0.59 0.382 0.403 0.257
suitcase 105 303 0.586 0.455 0.495 0.338
frisbee 84 115 0.751 0.722 0.782 0.584
skis 120 241 0.602 0.339 0.38 0.197
snowboard 49 69 0.458 0.275 0.333 0.216
sports ball 169 263 0.741 0.441 0.501 0.341
kite 91 336 0.589 0.53 0.569 0.382
baseball bat 97 146 0.56 0.37 0.405 0.208
baseball glove 100 148 0.702 0.453 0.509 0.303
skateboard 127 179 0.73 0.642 0.659 0.437
surfboard 149 269 0.685 0.435 0.512 0.32
tennis racket 167 225 0.717 0.618 0.683 0.403
bottle 379 1025 0.637 0.382 0.449 0.293
wine glass 110 343 0.702 0.297 0.394 0.245
cup 390 899 0.618 0.426 0.486 0.348
fork 155 215 0.611 0.288 0.345 0.239
knife 181 326 0.393 0.138 0.164 0.0938
spoon 153 253 0.415 0.119 0.146 0.0937
bowl 314 626 0.634 0.463 0.517 0.379
banana 103 379 0.532 0.28 0.352 0.205
apple 76 239 0.367 0.238 0.201 0.14
sandwich 98 177 0.556 0.475 0.461 0.348
orange 85 287 0.415 0.404 0.337 0.259
broccoli 71 316 0.524 0.332 0.349 0.196
carrot 81 371 0.394 0.296 0.265 0.16
hot dog 51 127 0.55 0.465 0.464 0.345
pizza 153 285 0.676 0.611 0.671 0.508
donut 62 338 0.591 0.476 0.499 0.387
cake 124 316 0.535 0.462 0.491 0.345
chair 580 1791 0.586 0.327 0.395 0.243
couch 195 261 0.629 0.598 0.607 0.46
potted plant 172 343 0.61 0.36 0.395 0.223
bed 149 163 0.674 0.571 0.642 0.465
dining table 501 697 0.535 0.437 0.431 0.298
toilet 149 179 0.728 0.76 0.803 0.649
tv 207 288 0.688 0.632 0.695 0.523
laptop 183 231 0.729 0.658 0.705 0.556
mouse 88 106 0.797 0.66 0.724 0.532
remote 145 283 0.475 0.276 0.303 0.178
keyboard 106 153 0.651 0.562 0.63 0.456
cell phone 214 262 0.605 0.374 0.405 0.277
microwave 54 55 0.609 0.6 0.652 0.5
oven 115 143 0.583 0.462 0.504 0.347
toaster 8 9 0.738 0.333 0.493 0.304
sink 187 225 0.635 0.476 0.516 0.345
refrigerator 101 126 0.553 0.611 0.628 0.495
book 230 1161 0.41 0.127 0.184 0.0884
clock 204 267 0.832 0.592 0.66 0.457
vase 137 277 0.57 0.466 0.452 0.299
scissors 28 36 0.541 0.278 0.302 0.241
teddy bear 94 191 0.675 0.529 0.587 0.416
hair drier 9 11 1 0 0 0
toothbrush 34 57 0.353 0.263 0.215 0.128
Speed: 0.1ms preprocess, 0.7ms inference, 0.0ms loss, 0.5ms postprocess per image
Results saved to runs\detect\train
Process finished with exit code 0

运行之后会默认生成一个run文件下,每训练一次就会生成一个train文件下,下一次就是train1,再下一次train2,依次增加。

weight文件中有训练好的权重,最后依次和最优的一次。

下面是一些结果图片。




12.结束
写完了,这篇主要是记录了,实现流程的全过程,这里还有一些没有解释的细节,等我缓一缓,然后静一静慢慢再把一些细节的解释给补上。