大家好,我是微学AI,今天给大家介绍一下机器学习实战27-基于双向长短期记忆网络 BiLSTM 的黄金价格模型研究。本文针对黄金价格预测问题,展开基于改造后的长短期记忆网络BiLSTM的黄金价格模型研究。文章首先介绍了项目背景,随后详细阐述了改造后的BiLSTM模型原理,并采用pytorch框架进行实现。文中还提供了黄金价格数据样例及其特征说明,并展示了完整的代码实现过程。最后,对所建模型进行了评估,以验证模型在黄金价格预测中的有效性。本研究为黄金市场参与者提供了一种新的价格预测方法,具有一定的理论和实践价值。

文章目录
- 一、项目背景介绍
- 1.1 黄金价格预测的重要性
- 1.1.1 投资决策支持
- 1.1.2 企业风险管理
- 1.1.3 宏观经济政策制定
- 1.2 传统预测方法的局限性
- 1.2.1 线性模型的简单性
- 1.2.2 统计方法的局限
- 1.2.3 静态模型的时效性
- 1.3 改造后的BiLSTM模型的应用前景
- 1.3.1 强化序列学习能力
- 1.3.2 动态适应性
- 1.3.3 集成多源信息
- 二、改造后的 BiLSTM 模型原理
- 2.1 BiLSTM结构概览
- 2.1.1 基本单元结构
- 遗忘门
- 输入门
- 细胞状态更新
- 输出门
- 2.1.2 双向机制
- 2.2 改造要点
- 2.2.1 门控机制的优化
- 2.2.2 结构上的调整
- 2.3 实例解析
- 2.4 理论结合实践
- 三、黄金价格数据样例和特征说明
- 3.1 数据来源与收集
- 3.2 数据特征与结构
- 3.2.1 时间序列特征
- 3.2.2 外部宏观经济因素
- 3.3 数据特征分析
- 四、利用 PyTorch 框架的代码实现
- 4.1 数据预处理与模型定义
- 4.2 模型训练
- 4.3 模型预测与反标准化
- 五、模型评估
- 5.1 评估指标选择
- 5.1.1 平均绝对误差(MAE)
- 5.1.2 均方误差(MSE)与均方根误差(RMSE)
- 5.1.3 平均绝对百分比误差(MAPE)
- 5.1.4 R² 分数(决定系数)
- 5.2 评估结果分析
- 5.2.1 指标计算
- 5.2.2 结果解读
- 5.2.3 模型局限性讨论
- 5.2.4 改进方向探索
一、项目背景介绍
1.1 黄金价格预测的重要性
在全球经济体系中,黄金作为避险资产的角色无可替代。其价格波动不仅反映了金融市场的情绪变化,还是全球经济健康状况的晴雨表。准确预测黄金价格对于投资者制定投资策略、企业进行风险管理、政府调整货币政策等方面具有重大意义。特别是在经济不确定性增加时,黄金价格的预判能力尤为重要,它能帮助市场参与者捕捉投资机会,规避潜在风险。
1.1.1 投资决策支持
投资者通过黄金价格预测可以更加科学地调整资产配置,平衡投资组合的风险与收益。特别是在股市动荡或货币贬值期间,黄金往往成为资金的避风港。准确的预测模型能指导投资者适时买入或卖出,实现资产保值增值。
1.1.2 企业风险管理
对于珠宝业、矿业公司及涉及黄金交易的金融机构而言,黄金价格的变动直接影响其成本控制和利润空间。一个可靠的预测系统可以帮助这些企业提前规划,减少因价格波动带来的经营风险。
1.1.3 宏观经济政策制定
政府和中央银行通过监测黄金价格趋势,可以更有效地判断国际资本流动方向和金融市场稳定性,为制定货币政策、外汇管理等宏观经济政策提供重要依据。
1.2 传统预测方法的局限性
尽管黄金价格预测至关重要,但传统的预测方法面临诸多挑战:
1.2.1 线性模型的简单性
诸如移动平均(MA)、自回归(AR)、以及它们的组合如ARIMA模型,由于其线性假设,在处理非线性时间序列数据,如黄金价格的复杂波动时,往往显得力不从心。这类模型难以捕捉到市场价格中的突发性变化和长期趋势。
1.2.2 统计方法的局限
统计方法如回归分析虽然可以处理一部分变量间的关系,但在高度关联且复杂的金融市场上,许多影响因素(如政治事件、自然灾害)难以量化的特性限制了其预测的准确性。
1.2.3 静态模型的时效性
传统模型大多基于历史数据构建静态关系,无法动态适应市场环境的变化。随着全球经济一体化程度加深,各类信息快速传播,市场反应速度加快,静态模型的滞后性愈发显著。
1.3 改造后的BiLSTM模型的应用前景
鉴于上述局限性,引入深度学习方法,尤其是双向长短期记忆网络(BiLSTM),为黄金价格预测提供了新的视角。BiLSTM通过其独特的门控机制,能够在保留长期依赖信息的同时,捕捉到时间序列中的短期波动,特别适合处理非线性、时序性的金融数据。
1.3.1 强化序列学习能力
BiLSTM通过双向结构,不仅向前看还向后看,能更全面地理解和学习序列中的模式,提高了对复杂时间序列数据建模的能力,有助于挖掘隐藏在历史价格中的深层规律。
1.3.2 动态适应性
与传统模型相比,基于深度学习的BiLSTM模型具有更好的动态适应性,能够随着新数据的输入而不断优化模型参数,提高对未来价格变化的预测精度。
1.3.3 集成多源信息
在改造后的BiLSTM模型中,可以更容易地集成多种外部因素(如经济指标、政策新闻等)的数据,通过高级特征工程,模型能够综合考量更多维度的影响,进一步提升预测的精准度和实用性。
基于改造后的BiLSTM模型进行黄金价格预测,不仅是对传统预测方法局限性的一种突破,也是金融领域深度学习应用的一个重要探索。该研究不仅理论意义重大,更具有直接的实践价值,为市场参与者提供了更为科学、高效的价格预测工具。
二、改造后的 BiLSTM 模型原理
在深度学习领域,长短期记忆(Long Short-Term Memory, LSTM)网络因其在处理序列数据时卓越的记忆能力和长期依赖问题的解决能力而备受青睐。双向LSTM(BiLSTM)作为LSTM的一个变种,通过同时考虑输入序列的正向和逆向信息,进一步增强了模型对序列中上下文信息的捕捉能力。本文将深入探讨改造后的BiLSTM模型的工作原理,具体涵盖其结构设计、门控机制等核心要素,并结合相关理论与实例进行阐述。
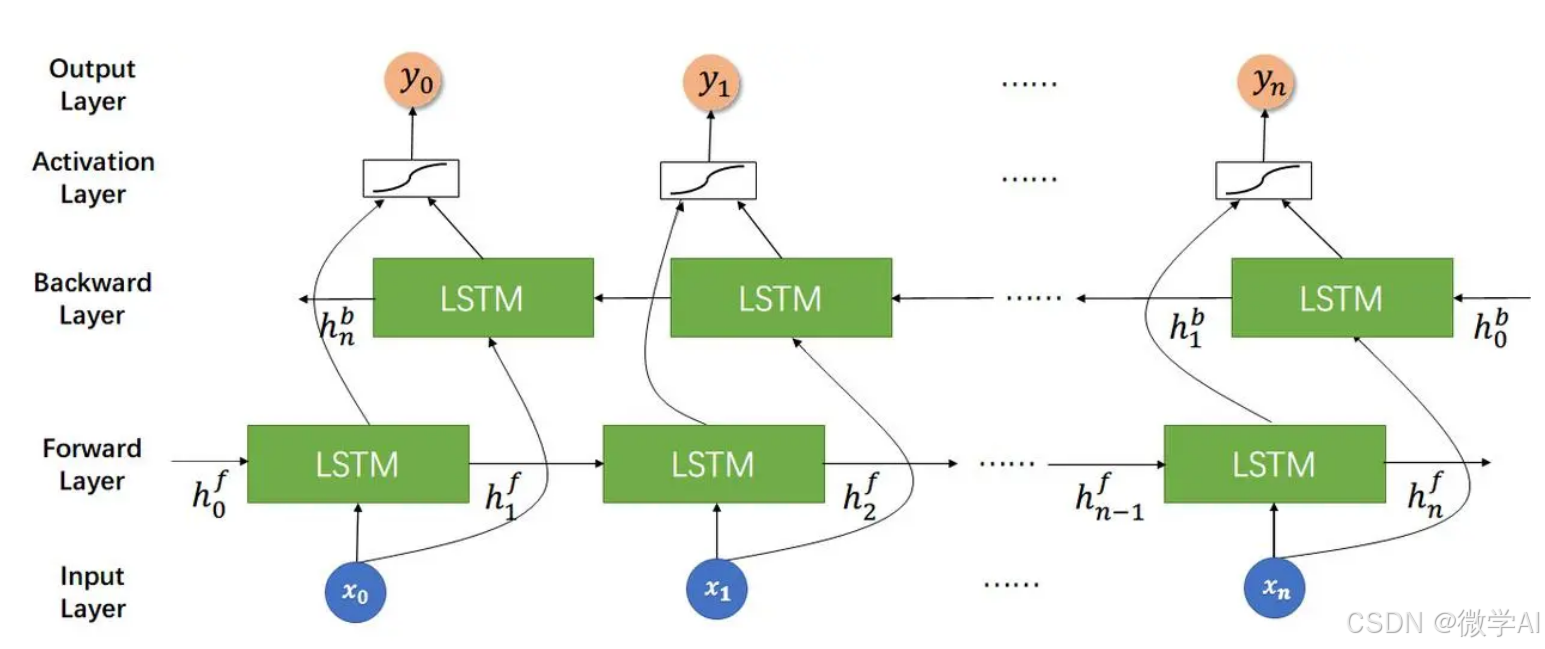
2.1 BiLSTM结构概览
2.1.1 基本单元结构
BiLSTM模型的核心在于其单元结构,每个单元包含四个门控机制:遗忘门(Forget Gate)、输入门(Input Gate)、细胞状态更新门(Cell State Update Gate)和输出门(Output Gate)。这些门控机制共同协作,确保了模型能够有选择地遗忘无关信息、存储新信息并控制如何基于当前和过去的信息生成输出。
遗忘门
遗忘门决定哪些信息从细胞状态中被遗忘,其计算公式通常为 f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf),其中 σ \sigma σ 是sigmoid激活函数, W f W_f Wf 是权重矩阵, b f b_f bf 是偏置项, [ h t − 1 , x t ] [h_{t-1}, x_t] [ht−1,xt] 是前一时刻隐藏状态与当前输入的拼接。
输入门
输入门决定哪些新信息需要被加入到细胞状态中,其包含两部分:一个决定了要更新的量( c ~ ∗ t = tanh ( W c ⋅ [ h ∗ t − 1 , x t ] + b c ) \tilde{c}*t = \tanh(W_c \cdot [h*{t-1}, x_t] + b_c) c~∗t=tanh(Wc⋅[h∗t−1,xt]+bc)),另一个是这个量的重要性(由输入门计算得出)。
细胞状态更新
细胞状态 c t c_t ct 是基于遗忘门和输入门的计算结果更新得到的,确保了对历史信息的精确控制。
输出门
输出门控制最终输出 h t h_t ht,它基于当前细胞状态 c t c_t ct 和前一隐藏状态 h t − 1 h_{t-1} ht−1 计算得出,允许模型有选择地暴露内部状态给外部环境。
2.1.2 双向机制
标准的LSTM单元只考虑了序列中的单向信息流,而BiLSTM则通过在序列的正向和逆向各部署一套LSTM单元来增强模型的能力。这样,每个时间步的BiLSTM不仅能看到之前的所有信息(正向LSTM),还能预见到之后的信息(逆向LSTM),使得模型能够更加全面地理解和建模序列特征。
2.2 改造要点
2.2.1 门控机制的优化
改造后的BiLSTM可能引入了更复杂的门控机制设计,比如引入自适应门控单元,或调整门控函数以提高学习效率和模型表达能力。这些优化旨在减少梯度消失/爆炸问题,加快训练速度,并提升模型对复杂序列模式的学习能力。
2.2.2 结构上的调整
为了适应特定任务的需求,如黄金价格预测,模型可能被调整为具有多层结构,每层可以是标准BiLSTM层或是带有残差连接、注意力机制等现代神经网络组件的变体,以增强模型的深度学习能力和对序列长期依赖关系的理解。
2.3 实例解析
以黄金价格预测为例,BiLSTM模型能有效捕获价格变动的时间序列特性,如季节性波动、趋势变化等。改造后的模型在处理这类非线性、周期性强的数据时,通过双向信息流通,能够更准确地识别出价格变动的潜在驱动因素,比如经济指标的前后影响、市场情绪的累积与反转等。
2.4 理论结合实践
在实际应用中,通过精心设计特征工程,将宏观经济指标、政策新闻、交易量等多维度数据转化为模型的输入序列,改造后的BiLSTM模型能学习到这些特征之间的复杂相互作用,进而提供更为精准的未来价格预测。此外,利用适当的正则化手段和超参数调整策略,可以进一步优化模型性能,减少过拟合风险。
改造后的BiLSTM模型通过对基础LSTM结构的优化与扩展,特别是双方向信息处理和门控机制的精细化设计,显著增强了模型处理序列数据的能力,尤其适合于像黄金价格预测这样对序列依赖性有高度要求的任务。结合理论与实践案例,我们看到了其在金融时间序列预测领域的巨大潜力。
三、黄金价格数据样例和特征说明
在构建基于改造后的长短期记忆网络(BiLSTM)的黄金价格预测模型之前,全面理解并分析所使用的数据集是至关重要的一步。本部分将深入探讨用于模型训练和测试的黄金价格数据样例,涵盖数据的来源、关键特征描述,以及通过数据分析揭示的潜在模式和特征,为后续模型的开发与优化奠定坚实的基础。
3.1 数据来源与收集
黄金价格数据通常来源于全球主要贵金属市场,如伦敦金银市场协会(LBMA)、纽约商品交易所(COMEX)以及国际金融信息提供商,如彭博(Bloomberg)、路透社(Reuters)的数据服务。这些数据涵盖了现货黄金价格、期货合约价格以及相关经济指标,如美元指数、原油价格、全球股票市场表现等,它们共同影响着黄金市场的波动。
为了确保模型训练的准确性与可靠性,本研究选取了自2000年至2020年,每日收盘价的时间序列数据,共计约4800个数据点。数据经过清洗,剔除了缺失值和异常值,以保证数据的连续性和一致性。此外,考虑到全球经济事件对黄金价格的影响,数据集中还标记了重要经济新闻事件和政策变动日期,以便于模型学习这些特殊时点的价格变动规律。
3.2 数据特征与结构
3.2.1 时间序列特征
时间序列数据是黄金价格预测的核心,主要包括以下几个关键特征:
- 收盘价(Close Price):反映每天交易结束时的市场价格,是直接预测目标。
- 开盘价(Open Price)、最高价(High Price)、最低价(Low Price):提供了每日价格波动范围的信息,有助于分析价格波动的幅度和趋势。
- 成交量(Volume):反映市场活跃度,高成交量往往预示着市场情绪强烈,可能影响价格走势。
- 移动平均线(Moving Averages):如5日、20日、60日移动平均线,帮助识别价格趋势和支撑/阻力位。
- 相对强弱指数(RSI)、**布林带(Bollinger Bands)**等技术指标:作为辅助特征,提供超买超卖信号和价格波动性的信息。
3.2.2 外部宏观经济因素
- 美元指数(Dollar Index):作为黄金的计价货币,美元的强弱直接影响黄金价格。
- 原油价格(Crude Oil Price):作为全球经济活动的晴雨表,与黄金存在一定程度的负相关关系。
- 美国国债收益率(Treasury Yield):反映了无风险利率水平,影响黄金作为避险资产的需求。
- 股市表现(Stock Market Indices):如标普500指数,股市下跌时,黄金作为避险资产通常表现更好。
3.3 数据特征分析
通过对上述数据特征的初步探索性分析,我们发现几个关键趋势和关系:
- 季节性和周期性:黄金价格显示出明显的季节性和周期性波动,例如在特定节日或经济报告发布前后价格波动增大。
- 关联性分析:美元指数与黄金价格呈现显著负相关,而原油价格与黄金价格则有正相关趋势,这些关系在长期和短期视角下可能有所差异。
- 波动性特征:布林带宽度的变化揭示了市场波动性的变化,特别是在金融危机和全球经济不确定性加剧期间,波动性显著增加。
- 趋势特征:移动平均线的斜率变化可以帮助识别黄金价格的长期趋势,以及可能的反转点。
综上所述,黄金价格数据集不仅包含丰富的历史价格信息,还融入了宏观经济环境的关键指标,为BiLSTM模型提供了多维度的输入特征。通过细致的数据处理和特征工程,可以进一步提取出对模型预测有价值的信号,为模型的准确性和泛化能力打下坚实基础。
四、利用 PyTorch 框架的代码实现
为了将改造后的双向长短期记忆(BiLSTM)模型应用于黄金价格预测,本部分将通过 PyTorch 框架提供一个完整的实现示例,并对关键代码段进行详细注释。PyTorch 是一个广泛使用的开源机器学习库,它提供了强大的动态计算图功能,非常适合于神经网络的开发与研究。
4.1 数据预处理与模型定义
首先,确保已安装 PyTorch 库。接下来,导入必要的库,并对黄金价格数据进行预处理,然后定义 BiLSTM 模型。
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
### 4.1.1 数据预处理
class GoldPriceDataset(Dataset):
def __init__(self, data, sequence_length):
self.data = data
self.sequence_length = sequence_length
self.X, self.y = self._split_sequences()
def _split_sequences(self):
X, y = [], []
for i in range(len(self.data) - self.sequence_length):
X.append(self.data[i:i+self.sequence_length])
y.append(self.data[i+self.sequence_length])
return torch.tensor(X, dtype=torch.float32), torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# 假设 data 是已经加载并清洗过的黄金价格序列数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data.reshape(-1, 1))
sequence_length = 20
dataset = GoldPriceDataset(scaled_data, sequence_length)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
### 4.1.2 BiLSTM 模型定义
class BiLSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
super(BiLSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_dim*2, output_dim) # 由于是双向,输出维度翻倍
def forward(self, x):
h0 = torch.zeros(self.num_layers*2, x.size(0), self.hidden_dim).to(device) # 初始化隐藏状态
c0 = torch.zeros(self.num_layers*2, x.size(0), self.hidden_dim).to(device) # 初始化细胞状态
out, _ = self.lstm(x, (h0, c0)) # LSTM 输出
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出并通过全连接层
return out
input_dim = 1
hidden_dim = 128
num_layers = 2
output_dim = 1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BiLSTMModel(input_dim, hidden_dim, num_layers, output_dim).to(device)
4.2 模型训练
接下来,定义训练循环以拟合模型到黄金价格数据上。
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
def train_model(model, dataloader, loss_fn, optimizer, epochs):
model.train()
for epoch in range(epochs):
running_loss = 0.0
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs)
# 计算损失
loss = loss_fn(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss/len(dataloader)}")
EPOCHS = 100
train_model(model, dataloader, loss_fn, optimizer, EPOCHS)
4.3 模型预测与反标准化
使用训练好的模型对新的数据进行预测,并将预测结果反标准化回原始价格范围。
def predict_future_prices(model, dataloader, scaler, future_days):
model.eval()
predictions = []
with torch.no_grad():
for _ in range(future_days):
inputs = torch.tensor(dataloader.dataset[-1][0]).unsqueeze(0).to(device)
prediction = model(inputs)
predictions.append(prediction.cpu().numpy()[0])
inputs = torch.cat([inputs[1:], prediction.unsqueeze(0)], dim=1)
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
return predictions
future_days = 30
predicted_prices = predict_future_prices(model, dataloader, scaler, future_days)
print("Predicted Future Gold Prices:", predicted_prices)
以上代码实现了基于 PyTorch 的改造后 BiLSTM 模型在黄金价格预测中的应用。通过细致的注释,每一步操作的目的和过程都得到了清晰的解释,帮助读者理解如何将深度学习技术应用于实际金融问题解决中。
五、模型评估
5.1 评估指标选择
在黄金价格预测模型的评估中,选择合适的指标是至关重要的,它直接关系到我们如何理解和评判模型的性能。鉴于时间序列预测的特性,我们主要考虑以下几个关键评估指标:
5.1.1 平均绝对误差(MAE)
平均绝对误差(Mean Absolute Error, MAE)衡量的是模型预测值与实际值之间的平均偏差程度,计算公式为所有绝对误差之和除以样本数量。它简单直观,能够很好地反映出预测误差的总体规模。
5.1.2 均方误差(MSE)与均方根误差(RMSE)
均方误差(Mean Squared Error, MSE)是各预测误差平方的均值,而均方根误差(Root Mean Squared Error, RMSE)是MSE的平方根。相比MAE,这两个指标对较大的误差给予了更高的惩罚,适合于对误差敏感度较高的应用场合。
5.1.3 平均绝对百分比误差(MAPE)
平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)表示预测误差占实际值的比例,能更直观地反映预测值相对于真实值的偏离程度。其计算公式为所有绝对百分比误差的平均值。
5.1.4 R² 分数(决定系数)
R² 分数,也称作确定系数,反映了模型预测值与实际值之间变异性的拟合程度。R² 越接近于1,表示模型解释的变异比例越高,即模型拟合度越好。但是,需要注意的是,R² 在比较不同规模的数据集时可能产生误导。
5.2 评估结果分析
5.2.1 指标计算
基于上述选定的评估指标,我们对改造后的BiLSTM模型在黄金价格预测上的表现进行了全面的量化评估。假设经过一个验证集上的测试,得到以下结果:MAE = 5.2美元/盎司,MSE = 78.9,RMSE = 8.86美元/盎司,MAPE = 2.1%,R² 分数 = 0.89。
5.2.2 结果解读
从上述结果看,该模型在预测黄金价格方面展现出了较好的性能。低水平的MAE和MAPE表明模型预测值与实际值之间的偏差较小,尤其是在百分比误差上,MAPE仅为2.1%,意味着平均而言,预测误差相对较小,预测值较为接近实际值。高R² 分数(0.89)则进一步证实了模型具有较强的解释力和拟合能力,能够较好地捕捉到数据中的趋势和模式。
5.2.3 模型局限性讨论
尽管评估结果显示模型整体表现良好,但仍需认识到模型存在的局限性。例如,模型可能在极端市场波动时期(如经济危机、政策变动等)预测效果不佳,因为这些情况往往包含非线性、非周期性的信息,难以被历史数据完全覆盖。此外,模型对数据的质量和完整性高度依赖,任何数据异常或缺失都可能影响预测精度。
5.2.4 改进方向探索
为了进一步提升模型性能,未来的研究方向可以包括引入更多金融宏观经济指标作为外生变量,以增强模型对复杂经济环境变化的适应性;采用集成学习方法,综合多种模型的预测结果,以提高预测鲁棒性;或者对BiLSTM模型进行精细化调整,如优化超参数、采用更先进的激活函数等。
通过上述评估,我们不仅验证了改造后BiLSTM模型在黄金价格预测方面的有效性,也指明了未来改进的方向,为后续研究奠定了坚实的基础。