-
第一周第一天-MySQL的SQL语句解析
-
数据库的介绍
-
什么是数据库
- 数据库是存储和管理数据的系统或集合,通常用于支持软件系统的高效数据处理和查询。它能够以结构化的方式组织数据,使用户可以快速存储、更新、查询和删除数据。数据库不仅保存数据,还提供了并发性控制、数据安全、备份和恢复等重要功能。
-
数据库的种类
-
关系型数据库(Relational Database, RDBMS)
- 使用表格(表、行、列)来组织和存储数据,数据之间通过关系进行关联。
- 采用结构化查询语言(SQL)来进行操作。
- 常见的关系型数据库:
- MySQL
- PostgreSQL
- Oracle
- Microsoft SQL Server
- MariaDB
-
非关系型数据库(NoSQL Database)
- 不使用传统的表格结构,适合处理大规模、非结构化数据。
- 通常用于高并发、可扩展的系统中,数据可以存储为键值对、文档、列族等形式。
- 常见的非关系型数据库:
- MongoDB
- Cassandra
- Redis
- CouchDB
-
内存数据库(In-memory Database)
- 数据存储在内存中,而不是磁盘上,提供极高的读写速度。
- 常用于需要快速数据处理的场景,如缓存、实时分析等。
- 常见的内存数据库:
- Redis
- Memcached
-
图数据库(Graph Database)
- 专门为存储和查询图状数据结构(节点和边)设计,适合处理社交网络、推荐系统等关系复杂的应用场景。
- 常见的图数据库:
- Neo4j
- ArangoDB
-
时间序列数据库(Time-series Database)
- 专为处理时间序列数据设计,常用于物联网、金融、监控等场景。
- 常见的时间序列数据库:
- InfluxDB
- Prometheus
-
-
生产环境常用的数据库
-
MySQL(mariaDB的产生是因为担心MySQL闭源,MySQL原作者开发的新开源项目)
- 开源且广泛使用的关系型数据库,适用于中小型应用以及大型的Web服务。
-
PostgreSQL
- 功能强大且支持复杂查询的开源关系型数据库,适用于需要处理复杂数据操作的系统。
-
Oracle
- 商用的关系型数据库系统,具有极强的性能和可靠性,常用于大型企业级应用。
-
Microsoft SQL Server
- 微软的关系型数据库,常见于Windows生态系统中的企业应用。
-
MongoDB
- 典型的文档型NoSQL数据库,适合需要快速扩展、处理海量数据的应用,常见于互联网公司。
-
Redis
- 高性能的内存数据库,常用于缓存、会话管理等需要高吞吐量的场景。
-
-
关系型数据库
-
关系型数据库介绍
- 关系型数据库(Relational Database, RDBMS)是一种通过表格形式来存储和组织数据的数据库类型。每张表由行(记录)和列(字段)构成,表与表之间通过关系来连接,从而实现对复杂数据的管理。
-
关系型数据库小结
-
优势:
- 数据一致性强:关系型数据库通过事务、约束等手段确保数据一致性,特别适合财务等高精度、高可靠性场景。
- 复杂查询支持:可以通过SQL进行复杂的多表查询、聚合和联接,适合数据分析和复杂数据管理。
- 数据规范化:通过表结构设计,避免数据冗余和不一致问题。
-
劣势:
- 扩展性有限:在海量数据或高并发应用中,关系型数据库的性能和扩展性受到约束,特别是在横向扩展方面。
- 性能瓶颈:复杂的表联接和事务处理在面对大规模数据时,可能导致性能问题。
-
使用场景:
- 适用于具有复杂数据结构、数据关系明确、对数据一致性要求高的场景,如金融、银行、电子商务系统等。
-
-
-
非关系型数据库
-
非关系型数据库简介
- 非关系型数据库(NoSQL,Not Only SQL)是一类不遵循传统关系型数据库表结构的数据库,主要用于处理大规模、非结构化数据,特别是在互联网和大数据领域。NoSQL数据库能够更好地应对高并发、海量数据和灵活的数据模型需求。
-
非关系型数据库分类
-
键值数据库(Key-Value Database)
- 数据以键值对的形式存储,类似于哈希表,查询时通过键快速找到对应的值。
- 常见数据库:Redis、DynamoDB、Riak
-
文档数据库(Document Database)
- 数据以文档的形式存储,通常使用JSON、BSON或XML格式,每个文档都可以有不同的结构。
- 常见数据库:MongoDB、CouchDB
-
列族数据库(Column Family Database)
- 数据以列的形式存储,常用于处理稀疏数据和大规模数据的查询优化。
- 常见数据库:Cassandra、HBase
-
图数据库(Graph Database)
- 专门处理图状结构的数据库,节点和边可以高效地表示实体及其关系,适用于社交网络、推荐系统等场景。
- 常见数据库:Neo4j、ArangoDB
-
时间序列数据库(Time-series Database)
- 主要用于存储时间序列数据,适合处理物联网设备数据、金融数据等。
- 常见数据库:InfluxDB、Prometheus
-
-
-
-
安装MySQL(在linux上,csdn上这么多也没说要按照仓库啊!!!!)
- yum remove 其他数据库
- 添加mysql仓库:sudo yum install https://dev.mysql.com/get/mysql80-community-release-el7-5.noarch.rpm(要刷新一下yum repolist)
- 安装mysql:sudo yum install mysql-community-server(可能会报错,如果是验证失败就关闭验证)
- 启动并且开机自启动:sudo systemctl start mysqld;
sudo systemctl enable mysqld - 获取 MySQL 临时密码:sudo grep 'temporary password' /var/log/mysqld.log
- 运行 MySQL 安全设置:使用临时密码登录 MySQL(看看可不可以用),然后在shell中运行安全设置程序来配置 root 密码等安全选项:mysql_secure_installation
- 我想设置简单密码,但是必须要完成密码重置后才可以
- 登录 MySQL:查看密码策略设置:SHOW VARIABLES LIKE 'validate_password%';
- 修改密码策略(可选):
- 设置密码策略为 LOW:SET GLOBAL validate_password.policy = LOW;设置最小密码长度为 6:SET GLOBAL validate_password.length = 6;可以选择降低对特殊字符和数字的要求:SET GLOBAL validate_password.mixed_case_count = 0; SET GLOBAL validate_password.number_count = 0; SET GLOBAL validate_password.special_char_count = 0;更改密码:ALTER USER 'root'@'localhost' IDENTIFIED BY '简单密码';
- 设置密码策略为 LOW:SET GLOBAL validate_password.policy = LOW;设置最小密码长度为 6:SET GLOBAL validate_password.length = 6;可以选择降低对特殊字符和数字的要求:SET GLOBAL validate_password.mixed_case_count = 0; SET GLOBAL validate_password.number_count = 0; SET GLOBAL validate_password.special_char_count = 0;更改密码:ALTER USER 'root'@'localhost' IDENTIFIED BY '简单密码';
- 我想设置简单密码,但是必须要完成密码重置后才可以
- 使用新密码登录 MySQL:mysql -u root -p
- 怎么切换版本
- 查看已启用的 MySQL 仓库:yum repolist enabled | grep mysql
- 禁用 MySQL 8.0 仓库:sudo yum-config-manager --disable mysql80-community启用 MySQL 5.7 仓库:sudo yum-config-manager --enable mysql57-community(这一步就是在配置文件内修改enable=1/0)
- 启用目标版本仓库后,你可以通过
yum安装 MySQL 5.7。(步骤和mysql80一样,要先删除80) - 验证一下:mysql --version
-
结构化查询语言SQL(exit退出mysql)
-
数据定义语言ddl
-
-- 数据定义语言(DDL)命令 -- 1. 创建数据库 CREATE DATABASE database_name; -- 创建一个名为 database_name 的新数据库 -- 用于创建一个新的数据库,包含数据表和其他数据库对象。 -- 2. 删除数据库 DROP DATABASE database_name; -- 删除名为 database_name 的数据库 -- 用于永久删除指定的数据库及其所有内容,操作不可逆。 -- 3. 使用数据库 USE database_name; -- 选择并使用指定的数据库 -- 在执行后续命令时,指定要操作的数据库,确保所有操作在该数据库中进行。 -- 4.创建表命令 CREATE TABLE table_name ( -- 创建一个名为 table_name 的新表 column1 datatype [constraints], -- 定义第一列的名称、数据类型及可选约束 column2 datatype [constraints], -- 定义第二列的名称、数据类型及可选约束 ... -- 可以添加更多列 PRIMARY KEY (column_name), -- 指定主键,唯一标识表中的每一行 FOREIGN KEY (column_name) REFERENCES other_table(column_name), -- 定义外键约束,引用其他表的主键 UNIQUE (column_name), -- 定义唯一约束,确保该列中的值唯一 CHECK (condition), -- 定义检查约束,确保列中的值满足指定条件 DEFAULT default_value -- 定义默认值,当插入时未指定该列的值时使用 ); -- 用于定义表的结构,包括列名称、数据类型、约束等。 -- 示例:创建一个名为 Employees 的表 CREATE TABLE Employees ( -- 创建一个名为 Employees 的表 EmployeeID INT NOT NULL AUTO_INCREMENT, -- 定义 EmployeeID 列,设置为非空且自动增加 FirstName VARCHAR(50) NOT NULL, -- 定义员工的名字,设置为非空 LastName VARCHAR(50) NOT NULL, -- 定义员工的姓氏,设置为非空 HireDate DATE DEFAULT CURRENT_DATE, -- 定义雇用日期,默认为当前日期 Salary DECIMAL(10, 2), -- 定义薪资,允许两个小数位 PRIMARY KEY (EmployeeID) -- 将 EmployeeID 列设为主键 ); -- 使用 AUTO_INCREMENT 生成唯一标识符,EmployeeID 列的值在每次插入新行时自动增加 -- 5. 删除表 DROP TABLE table_name; -- 删除名为 table_name 的表 -- 用于永久删除指定的表及其所有数据,操作不可逆。 -- 6. 修改表 ALTER TABLE table_name -- 修改表结构 ADD column_name datatype; -- 添加新列 -- 例如:ALTER TABLE table_name ADD age INT; -- 添加一个名为 age 的整数列 ALTER TABLE table_name MODIFY column_name new_datatype; -- 修改已有列的数据类型 -- 例如:ALTER TABLE table_name MODIFY age VARCHAR(3); -- 将 age 列的数据类型改为 VARCHAR(3) ALTER TABLE table_name DROP COLUMN column_name; -- 删除指定的列 -- 例如:ALTER TABLE table_name DROP COLUMN age; -- 删除名为 age 的列 -- 7. 添加约束 ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE (column_name); -- 为指定列添加唯一约束 -- 用于确保在列中不允许重复的值。 ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (column_name) REFERENCES other_table (other_column); -- 添加外键约束 -- 用于定义两张表之间的关系,确保数据的完整性。 ALTER TABLE table_name ADD CONSTRAINT constraint_name CHECK (condition); -- 添加检查约束 -- 用于确保列中的数据满足特定条件。 -- 8. 删除约束 ALTER TABLE table_name DROP CONSTRAINT constraint_name; -- 删除指定的约束 -- 用于删除已存在的约束(如主键、外键或唯一约束)。 -- 9. 创建索引 CREATE INDEX index_name ON table_name (column_name); -- 在指定列上创建索引 -- 用于加速对表中数据的查询操作,通常在经常查询的列上创建索引。 -- 10. 删除索引 DROP INDEX index_name ON table_name; -- 删除指定的索引 -- 用于删除先前创建的索引,以释放存储空间或提高性能。 -- 11. 重命名表 ALTER TABLE old_table_name RENAME TO new_table_name; -- 将表重命名 -- 用于更改表的名称,保持表的内容不变。 -- 12. 重命名列 ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name; -- 将列重命名 -- 用于更改表中列的名称,保持列的数据不变。 -- 13. 创建视图 CREATE VIEW view_name AS -- 创建一个名为 view_name 的视图 SELECT column1, column2 FROM table_name WHERE condition; -- 视图可以用来简化复杂查询 -- 用于定义一个虚拟表,可以简化对复杂查询的访问。 -- 14. 删除视图 DROP VIEW view_name; -- 删除名为 view_name 的视图 -- 用于永久删除指定的视图。 -- 15. 创建触发器 CREATE TRIGGER trigger_name -- 创建一个触发器 AFTER INSERT ON table_name -- 触发器将在插入操作后执行 FOR EACH ROW BEGIN -- 触发器执行的操作,例如: INSERT INTO log_table (log_message) VALUES ('Record inserted'); END; -- 用于在特定事件发生时自动执行一段 SQL 代码。 -- 16. 删除触发器 DROP TRIGGER trigger_name; -- 删除名为 trigger_name 的触发器 -- 用于永久删除指定的触发器。 -- 17. 创建存储过程 CREATE PROCEDURE procedure_name (parameter1 datatype, parameter2 datatype) -- 创建一个存储过程 BEGIN -- 存储过程的 SQL 语句 END; -- 用于封装一组 SQL 语句,可以多次调用,支持参数传递。 -- 18. 删除存储过程 DROP PROCEDURE procedure_name; -- 删除名为 procedure_name 的存储过程 -- 用于永久删除指定的存储过程。 -- 19. 创建函数 CREATE FUNCTION function_name (parameter1 datatype) RETURNS return_datatype -- 创建一个函数 BEGIN -- 函数的 SQL 语句 RETURN value; -- 返回计算结果 END; -- 用于封装一组 SQL 语句,并返回单个值,可以在查询中使用。 -- 20. 删除函数 DROP FUNCTION function_name; -- 删除名为 function_name 的函数 -- 用于永久删除指定的函数。 -- 21. 描述表的结构 DESC table_name; -- 显示名为 table_name 的表的结构 -- 或 DESCRIBE table_name; -- 也可以使用 DESCRIBE 关键字 -- 用于查看表中各列的详细信息,帮助理解表的设计。
-
-
数据操纵语言dml
- 数据操纵语言用于对数据库中的数据进行操作,包括插入、更新和删除数据。
-
-- 数据操纵语言(DML)命令 -- 插入单条数据 INSERT INTO table_name (column1, column2, ...) -- 指定要插入数据的表名和列名 VALUES (value1, value2, ...); -- 指定要插入的值,与列名一一对应 -- 插入多条数据 INSERT INTO table_name (column1, column2, ...) -- 指定要插入数据的表名和列名 VALUES (value1_1, value2_1, ...), -- 第一条记录的值 (value1_2, value2_2, ...); -- 第二条记录的值 -- 可以继续添加更多记录,以逗号分隔 -- 更新数据 UPDATE table_name -- 指定要更新数据的表名 SET column1 = value1, column2 = value2, ... -- 指定要更新的列及其对应的新值 WHERE condition; -- 指定更新的条件,只有满足条件的记录会被更新 -- 如果未指定 WHERE 子句,将更新表中所有记录 -- 更新所有记录 UPDATE table_name SET column1 = value1; -- 更新表中所有记录的指定列为新值 -- 删除数据 DELETE FROM table_name -- 指定要删除数据的表名 WHERE condition; -- 指定删除的条件,只有满足条件的记录会被删除 -- 如果未指定 WHERE 子句,将删除表中所有记录 -- 删除所有记录 DELETE FROM table_name; -- 删除表中所有记录,但保留表的结构和定义 -- 查询数据 SELECT column1, column2, ... -- 指定要查询的列名,多个列用逗号分隔 FROM table_name -- 指定要查询的表名 WHERE condition; -- 指定查询的条件,只有满足条件的记录会被返回 -- 查询所有数据 SELECT * FROM table_name; -- 查询表中所有列的所有记录,* 表示所有列 -- 使用聚合函数统计记录 SELECT COUNT(*) FROM table_name; -- 统计表中的记录总数,返回满足条件的记录数量 -- 使用分组统计 SELECT column1, COUNT(*) -- 查询指定列及其记录计数 FROM table_name GROUP BY column1; -- 按 column1 分组,将相同值的记录合并,计算每组的数量 -- 使用排序 SELECT column1, column2, ... -- 查询指定列 FROM table_name ORDER BY column1 ASC|DESC; -- 按照指定列进行排序,ASC 表示升序,DESC 表示降序 -- 使用分组与排序结合 SELECT column1, COUNT(*) -- 查询指定列及其记录计数 FROM table_name GROUP BY column1 -- 按 column1 分组 ORDER BY COUNT(*) DESC; -- 按计数结果降序排序 -- 使用条件限制返回结果 SELECT column1, column2, ... -- 查询指定列 FROM table_name WHERE condition -- 指定查询的条件 LIMIT number; -- 限制返回结果的数量,number 是返回的最大行数 -- 使用 DISTINCT 关键字避免重复值 SELECT DISTINCT column1, column2 -- 查询唯一的列值,避免重复记录 FROM table_name; -- 指定要查询的表 -- 使用 LIKE 进行模糊查询 SELECT column1, column2 -- 查询指定列 FROM table_name WHERE column1 LIKE 'pattern'; -- 指定模糊查询的模式,使用 % 通配符表示任意字符 -- 使用 IN 进行多值匹配 SELECT column1, column2 -- 查询指定列 FROM table_name WHERE column1 IN (value1, value2, ...); -- 指定匹配多个值的条件,只有列值在指定列表中的记录会被返回 -- 使用 JOIN 连接多个表 SELECT a.column1, b.column2 -- 查询多个表中的指定列 FROM table_a a -- 第一个表,a 是表的别名 JOIN table_b b ON a.common_column = b.common_column; -- 通过公共列连接表,b 是第二个表的别名 -- 使用 UNION 合并多个查询结果 SELECT column1 FROM table_name_1 -- 从第一个表查询指定列 UNION -- 合并结果,去除重复 SELECT column1 FROM table_name_2; -- 从第二个表查询指定列 -- UNION ALL 可用于包括重复值 -- 使用 HAVING 进行分组后条件限制 SELECT column1, COUNT(*) -- 查询指定列及其记录计数 FROM table_name GROUP BY column1 -- 按 column1 分组 HAVING COUNT(*) > 1; -- 限制只返回记录计数大于 1 的分组
-
事物控制语言tcl
- 事务控制语言用于管理数据库事务,确保数据的一致性和完整性。
-
-- 事务控制语言(TCL)命令 -- 开始事务 BEGIN; -- 开始一个新的事务,后续的操作将在该事务中进行 -- 该命令表示后续所有的数据库操作将被视为一个整体,只有在提交时才会生效。 -- 提交事务 COMMIT; -- 提交当前事务,将所有在该事务中的操作永久保存到数据库中 -- 一旦提交,所有更改将不可逆,其他用户可以看到这些更改。 -- 回滚事务 ROLLBACK; -- 回滚当前事务,撤销自事务开始以来所做的所有操作 -- 此命令用于恢复到事务开始之前的状态,所有未提交的更改将被撤销。 -- 设置保存点 SAVEPOINT savepoint_name; -- 创建一个保存点,允许在后续的回滚中返回到该保存点 -- 保存点是在事务中定义的,允许将事务分割为多个可恢复的部分。 -- 回滚到保存点 ROLLBACK TO savepoint_name; -- 将事务回滚到指定的保存点,撤销保存点之后的所有操作 -- 这使得开发者可以在事务中选择性地撤回某些操作,而不是全部撤回。 -- 使用示例 BEGIN; -- 开始事务 -- 执行多个 SQL 操作 INSERT INTO table_name (column1, column2) VALUES (value1, value2); -- 插入数据 UPDATE table_name SET column1 = new_value WHERE condition; -- 更新数据 DELETE FROM table_name WHERE condition; -- 删除数据 -- 根据条件决定是否提交或回滚 IF some_condition THEN COMMIT; -- 如果条件满足,提交事务 ELSE ROLLBACK; -- 否则,回滚事务 END IF; -- 示例中的条件逻辑可以根据业务需求进行修改,例如根据插入、更新或删除的结果决定是否提交事务。
-
数据查询语言dql
- 数据查询语言用于从数据库中查询数据。它通常使用
SELECT语句来检索数据。 -
-- 数据查询语言(DQL)命令 -- 1. 基本查询 SELECT column1 as '别名', column2, ... -- 指定要查询的列名,多个列用逗号分隔 FROM table_name; -- 指定要查询数据的表名 -- 该命令用于从指定的表中查询数据。如果需要查询所有列,可以使用 `SELECT *`。 -- 2. 使用条件查询 SELECT column1, column2, ... FROM table_name WHERE condition; -- 使用 WHERE 子句指定查询条件,返回满足条件的记录 -- WHERE 子句可以用于过滤数据,例如根据特定的列值或表达式筛选记录。 -- 3. 使用 DISTINCT 去重 SELECT DISTINCT column1 -- 查询唯一的列值,避免返回重复的记录 FROM table_name; -- DISTINCT 用于确保查询结果中的值都是唯一的,避免重复值的出现。 -- 4. 使用 ORDER BY 排序 SELECT column1, column2, ... FROM table_name ORDER BY column1 ASC|DESC; -- 按照指定列进行排序,ASC 为升序,DESC 为降序 -- 通过 ORDER BY 子句,可以按一个或多个列进行排序,方便用户对结果进行排列。 -- 5. 使用 LIMIT 限制返回记录数 SELECT column1, column2, ... FROM table_name LIMIT number; -- 限制返回的记录数量,number 表示最大行数 -- 该命令通常用于控制返回结果的行数,特别是在返回大量数据时用于分页或性能优化。 -- 6. 使用 LIKE 进行模糊查询 SELECT column1, column2, ... FROM table_name WHERE column1 LIKE 'pattern'; -- 使用 LIKE 进行模式匹配,% 表示任意多个字符 -- LIKE 通常用于进行模糊匹配查询,支持通配符 `%` 和 `_`。 -- 7. 使用聚合函数进行统计 SELECT COUNT(*), SUM(column1), AVG(column1), MAX(column1), MIN(column1) FROM table_name; -- 使用聚合函数进行统计操作 -- 聚合函数用于对查询结果进行汇总操作,如计数、求和、平均值、最大值和最小值。 -- 8. 使用 GROUP BY 分组查询 SELECT column1, COUNT(*) FROM table_name GROUP BY column1; -- 按指定列进行分组,统计每个组的记录数 -- GROUP BY 用于将结果集按一个或多个列分组,可以结合聚合函数对每组数据进行统计。 -- 9. 使用 HAVING 对分组结果进行过滤 SELECT column1, COUNT(*) FROM table_name GROUP BY column1 HAVING COUNT(*) > 1; -- 使用 HAVING 对分组后的结果进行过滤 -- HAVING 通常与 GROUP BY 一起使用,用于对分组后的结果进行进一步过滤。 -- 10. 使用 JOIN 进行多表查询 SELECT a.column1, b.column2 FROM table_a a JOIN table_b b ON a.common_column = b.common_column; -- 使用 JOIN 连接多个表 -- JOIN 用于在多张表之间根据公共列进行关联查询,可以通过 INNER JOIN、LEFT JOIN、RIGHT JOIN 等类型连接表。 -- 11. 使用 UNION 合并查询结果 SELECT column1 FROM table_name_1 UNION SELECT column1 FROM table_name_2; -- 合并两个查询结果,去除重复值 -- UNION 用于将多个查询的结果合并在一起,并自动去重。 -- 12. 使用 SUBQUERY 进行子查询 SELECT column1 FROM table_name WHERE column2 IN (SELECT column2 FROM other_table WHERE condition); -- 使用子查询 -- 子查询可以在主查询中作为条件,允许在查询中嵌套其他查询。 -- 13. WITH 子句(公用表表达式,CTE) WITH cte_name AS ( SELECT column1, column2 FROM table_name WHERE condition ) SELECT * FROM cte_name; -- 使用公用表表达式(CTE)进行更复杂的查询 -- CTE 使查询更具可读性,尤其是在嵌套查询较多时。 -- 14. CASE 语句 SELECT column1, CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ELSE default_result END AS alias_name FROM table_name; -- 根据条件返回不同的结果 -- 用于条件逻辑,允许在查询中返回不同的值。 -- 15. EXISTS 关键字 SELECT column1 FROM table_name WHERE EXISTS (SELECT 1 FROM other_table WHERE condition); -- 检查子查询的结果是否存在 -- 用于检查某个条件是否至少返回一条记录。 -- 16. GROUP_CONCAT 函数 SELECT column1, GROUP_CONCAT(column2) FROM table_name GROUP BY column1; -- 将多个行合并为一个字符串 -- 在分组结果中将多行数据合并为一个字符串。 -- 17. LIMIT 和 OFFSET 结合使用 SELECT column1, column2 FROM table_name LIMIT number OFFSET offset_value; -- 用于分页查询 -- 限制查询结果的数量,同时指定从哪一行开始返回记录。 -- 18. FULL OUTER JOIN SELECT a.column1, b.column2 FROM table_a a FULL OUTER JOIN table_b b ON a.common_column = b.common_column; -- 返回两个表中的所有记录 -- 返回左表和右表的所有记录,即使在其中一个表中没有匹配的记录。 -- 19. INTERSECT SELECT column1 FROM table_name_1 INTERSECT SELECT column1 FROM table_name_2; -- 返回两个查询的交集 -- 获取两个查询结果的共同记录。 -- 20. ROLLUP 和 CUBE SELECT column1, SUM(column2) FROM table_name GROUP BY column1 WITH ROLLUP; -- 生成分组的汇总数据 -- ROLLUP 和 CUBE 用于生成多维汇总数据。 -- 21. UNNEST(适用于支持数组的数据库) SELECT UNNEST(array_column) FROM table_name; -- 将数组列展开为多行 -- 将数组或集合类型的数据展开成多个行。
- 数据查询语言用于从数据库中查询数据。它通常使用
-
数据控制语言dcl
- 数据控制语言用于控制对数据的访问权限,管理用户的权限。
-
-- 数据控制语言(DCL)命令 -- 1. 授予权限 GRANT privilege_type ON object_type object_name TO user_name; -- 授予指定用户权限 -- privilege_type:可以是 SELECT(查询)、INSERT(插入)、UPDATE(更新)、DELETE(删除)、ALL PRIVILEGES(所有权限)等。 -- object_type:可以是 TABLE(表)、DATABASE(数据库)、PROCEDURE(存储过程)等。 -- object_name:指定权限授予的对象名称,例如:my_database.my_table。 -- user_name:需要授予权限的用户名或角色,通常以 'username'@'host' 的形式指定。 -- 例: -- GRANT SELECT ON my_database.my_table TO 'username'@'localhost'; -- 授予指定用户在指定表上的 SELECT 权限 -- 2. 撤销权限 REVOKE privilege_type ON object_type object_name FROM user_name; -- 撤销指定用户的权限 -- privilege_type、object_type、object_name 和 user_name 的含义与 GRANT 命令相同。 -- 例: -- REVOKE SELECT ON my_database.my_table FROM 'username'@'localhost'; -- 撤销指定用户在指定表上的 SELECT 权限 -- 3. 显示用户权限 SHOW GRANTS FOR user_name; -- 显示指定用户的权限 -- 用于查看特定用户在数据库中的所有权限,以便确认其访问权限。 -- 例: -- SHOW GRANTS FOR 'username'@'localhost'; -- 显示指定用户的所有权限信息 -- 4. 创建角色 CREATE ROLE role_name; -- 创建一个新的角色 -- 用于定义一组权限,这些权限可以集中管理并分配给多个用户。 -- 例: -- CREATE ROLE 'my_role'; -- 创建一个名为 my_role 的角色 -- 5. 授予角色权限 GRANT privilege_type ON object_type object_name TO role_name; -- 将权限授予角色 -- 角色可以集成多个权限,方便管理和分配。 -- 例: -- GRANT SELECT, INSERT ON my_database.my_table TO 'my_role'; -- 授予角色在指定表上的 SELECT 和 INSERT 权限 -- 6. 授予角色给用户 GRANT role_name TO user_name; -- 将角色授予指定用户 -- 通过角色管理权限的分配,提高权限管理的灵活性。 -- 例: -- GRANT 'my_role' TO 'username'@'localhost'; -- 将名为 my_role 的角色授予指定用户 -- 7. 撤销角色 REVOKE role_name FROM user_name; -- 从指定用户撤销角色 -- 撤销用户对角色的访问权限,从而限制其权限。 -- 例: -- REVOKE 'my_role' FROM 'username'@'localhost'; -- 从指定用户撤销角色 -- 8. 删除角色 DROP ROLE role_name; -- 删除指定的角色 -- 删除不再需要的角色及其权限定义。 -- 例: -- DROP ROLE 'my_role'; -- 删除名为 my_role 的角色 -- 9. 设定默认角色 SET DEFAULT ROLE role_name TO user_name; -- 为用户设定默认角色 -- 在用户登录时自动使用该角色的权限。 -- 例: -- SET DEFAULT ROLE 'my_role' TO 'username'@'localhost'; -- 将 my_role 设为指定用户的默认角色 -- 10. 角色权限检查 SET ROLE role_name; -- 切换到指定角色 -- 允许用户在登录会话中使用角色的权限。 -- 例: -- SET ROLE 'my_role'; -- 切换到名为 my_role 的角色 -- 11. 显示当前用户 SELECT CURRENT_USER(); -- 显示当前连接的用户 -- 用于确认当前连接的用户身份,特别是在多用户环境下。 -- 例: -- SELECT CURRENT_USER(); -- 查询当前用户信息 -- 12. 显示当前数据库 SELECT DATABASE(); -- 显示当前使用的数据库 -- 用于确认当前连接操作的是哪个数据库。 -- 例: -- SELECT DATABASE(); -- 查询当前数据库信息
-
-
MySQL数据库导入导出
-
-- 1. 导出整个数据库 -- 使用 mysqldump 命令导出名为 database_name 的数据库到一个 SQL 文件中 -- 该命令在命令行中执行,而非 SQL 中 -- 示例:mysqldump -u username -p database_name > database_dump.sql -- 2. 导出特定表 -- 导出名为 table_name 的特定表到一个 SQL 文件中 -- 该命令在命令行中执行 -- 示例:mysqldump -u username -p database_name table_name > table_dump.sql -- 3. 导出数据结构而不导出数据 -- 仅导出名为 database_name 的数据库结构,不包括数据 -- 该命令在命令行中执行 -- 示例:mysqldump -u username -p -d database_name > database_structure.sql -- 4. 导出所有数据库 -- 导出所有数据库到一个 SQL 文件中 -- 该命令在命令行中执行 -- 示例:mysqldump -u username -p --all-databases > all_databases_dump.sql -- 5. 导入数据库 -- 使用 mysql 命令将名为 database_dump.sql 的 SQL 文件导入到名为 database_name 的数据库中 -- 示例:mysql -u username -p database_name < database_dump.sql -- 6. 导入特定表 -- 将名为 table_dump.sql 的 SQL 文件导入到已存在的目标数据库中 -- 示例:mysql -u username -p database_name < table_dump.sql -- 注意事项 -- - 在导入操作前,建议备份目标数据库,以防数据丢失 -- - 确保在执行导入和导出操作的用户具有足够的权限 -- - 在导出或导入大数据集时,可以考虑使用事务以确保数据一致性 -- - 设置适当的字符集(如 UTF-8)以避免字符编码问题 -- 7. 使用图形界面工具 -- 对于不熟悉命令行的用户,可以使用 phpMyAdmin、MySQL Workbench、Navicat 等图形界面工具进行简单易用的导入和导出操作
-
-
云计算:MySQL
news2026/2/9 23:27:13


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2198656.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
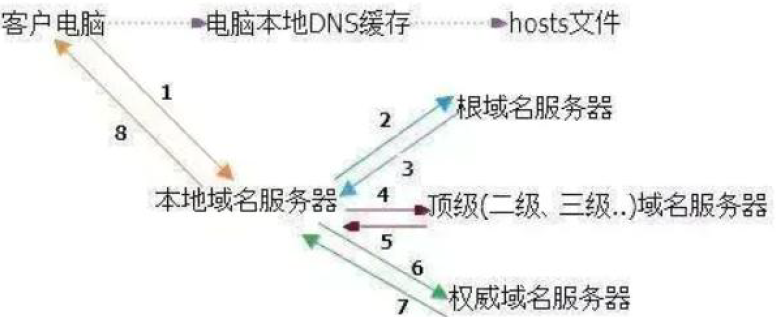
网络知识_001_浏览器输入域名
文章目录 网络模型IP地址,子网掩码,网关,网络地址,广播地址,NAT转换浏览器输入域名到网页打开发生了什么DNS获取顺序 网络模型
模型协议工具报文添加信息作用应用层http,https,ftp,…

Apache Flume 启动报错及解决方法
在使用 Apache Flume 时,可能会遇到启动报错的情况,其中一个常见问题就是 log4j 错误。本文将结合三个实际案例来分析这个问题,并提供相应的解决方法。 一、问题现象 案例一 执行命令 flume-ng agent -n a1 -c ../conf/ -f ./flume_info.conf…

Matlab绘图总结(进阶)
本文在前文的基础上进一步整理画图方法
MATLAB画动图_CSDN博客 1. 基础图形绘制
1.1 rectangle(矩形,圆形)
在前文中,讲解了如何使用rectangle,rectangle本意是用来画矩形的,其中,Curvature可…
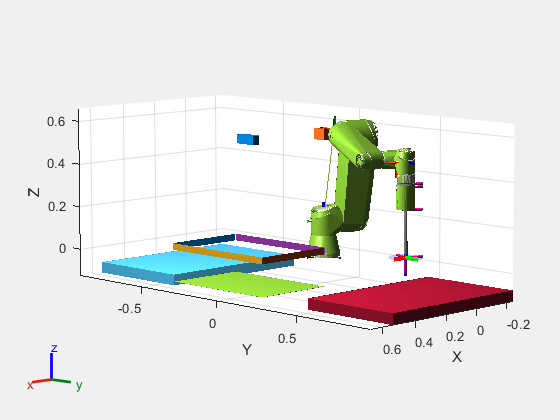
MATLAB - 机器人机械臂设计轨迹规划器
系列文章目录 前言 本示例介绍了一种设计抓取和轨迹规划器的方法,该规划器可用于垃圾箱拣选系统。 在机器人技术中,垃圾箱拣选包括使用机械手从垃圾箱中取出物品。智能垃圾箱拣选是这一过程的高级版本,具有更强的自主性。使用摄像系统感知部件…

基于sklearn的机器学习应用平台 v2.0
基于sklearn的机器学习应用平台 v2.0 链接:https://pan.baidu.com/s/1nvHMTrtBmtPLT4oNXdw74A 提取码私信博主获取
关于作者 作者:小白熊
作者简介:精通python、matlab、c#语言,擅长机器学习,深度学习,机…

数据结构-4.6.KMP算法(旧版下)-朴素模式匹配算法的优化
一.绪论: 当主串字符和模式串字符不匹配时会执行jnext[j]来改变模式串的指针,但主串的指针不变。 二.求模式串的next数组:
1.例一:
如模式串abcabd,当第六个字符d匹配失败时,此时主串中前五个字符abcab都…

Golang | Leetcode Golang题解之第462题最小操作次数使数组元素相等II
题目: 题解:
func partition(a []int, l, r int) int {x : a[r]i : l - 1for j : l; j < r; j {if a[j] < x {ia[i], a[j] a[j], a[i]}}a[i1], a[r] a[r], a[i1]return i 1
}func randomPartition(a []int, l, r int) int {i : rand.Intn(r-l1…

【学习笔记】零基础入门汇编语言(ARM架构+汇编的实际应用)
目录
一.汇编的前世今生 二.寄存器 三.ARM指令集
1.指令格式 2.寻址方式
3.伪指令
4.基本指令
4.1数据传输指令
4.2存储器访问指令
4.3压栈和出栈指令
4.4跳转指令
4.5算术运算指令
4.6逻辑运算指令
四.C语言与汇编混合编程
1.混合编程前置条件 2.混合编程优势
3.…

五款专业三维数据处理工具:GISBox、Cesiumlab、OSGBLab、灵易智模、倾斜伴侣深度解析
随着三维数据处理技术的广泛应用,尤其是在城市规划、地理信息系统(GIS)、工程监测等领域,处理倾斜摄影、三维建模以及大规模数据管理的需求日益增加。以下是五款我精心挑选的倾斜摄影和三维数据处理工具——GISBox、Cesiumlab、OS…

和鲸科技创始人范向伟:拐点即将来临,AI产业当前的三个瓶颈
在科技迅猛发展的时代,人工智能(AI)无疑已经成为引领新一轮产业革命的核心动力之一。全球企业纷纷拥抱AI技术,试图借助其变革力量在竞争中突围,然而业界对AI产业化的拐点何时来临却众说纷纭。毕竟AI技术从实验室到商业…

三 星 SCX-4521F 硒 鼓 清 零 及 一 般 故 障 维 修 浅 谈
基本参数
耗材容量:SCX-4521D3/XIL(3000页)
功 率:平均功率350W、休眠模式10W
一般故障讲解
一、三星SCX-4521F打印机更换硒鼓(或加粉)后仍显示墨粉用尽
(加粉清零、关闭碳粉通知) 按菜单------#1934(快速按完)------屏幕会有TECH字母显示------菜单------向…

PCB缺陷检测数据集 xml 可转yolo格式 ,共10688张图片
PCB缺陷检测数据集(yolov5,v7,v8) 数据集总共有两个文件夹,一个是pcb整体标注,一个是pcb部分截图。 整体标注有6个分类,开路,短路等都已经标注,标注格式为xml,每个文件夹下有100多张…

html内嵌其他网页iframe
在很多情况下,需要将其他网页内嵌到自己的网页,如: 只需要使用iframe标签即可,通过src属性指定网站地址即可,代码如下: <!DOCTYPE html>
<html lang"en">
<head><meta ch…

苹果手机怎样一键删除照片:快速清理指南
在数字化时代,手机照片的积累如同记忆的沉淀,但过多无用的照片也会占据宝贵的存储空间。对于苹果手机用户来说,如何高效地一键删除照片是一个常见的需求。本文将介绍几种方法,帮助你快速清理苹果手机中的照片。
1. 使用系统相册的…

论文解析三: D2-Net 用于联合描述和检测局部特征的可训练CNN
目录 1.D2-Net摘要2.D2-Net关键点介绍3. Joint Detection and Description (联合检测和描述)3.1 Feature Extraction3.2 Feature Detection3.2.1 Hard feature detection (硬特征检测)3.2.1 Soft Feature Detection(软特征检测) 3…

如何在VScode中加入系统安装好的python环境
在vscode的ipynb文件中,加入的环境总是找不到自己电脑当中已有的环境。这可能是由于自己电脑中的python没有安装ipynb对应的包,因而监测不出来。

【自动驾驶】控制算法(十二)横纵向综合控制 | 从理论到实战全面解析
写在前面: 🌟 欢迎光临 清流君 的博客小天地,这里是我分享技术与心得的温馨角落。📝 个人主页:清流君_CSDN博客,期待与您一同探索 移动机器人 领域的无限可能。 🔍 本文系 清流君 原创之作&…

MP2155升降压芯片全解析——概况、性能、应用电路、输出电压调节计算
MP2155概述
功能: MP2155是一款高效率、低静态电流的升降压转换器,可在高于、低于或等于输出电压的输入电压下工作。该器件为采用单节锂离子或多节碱性电池供电的产品提供电源解决方案。
数据: MP2155 可在 2V 至 5.5V 的输入电压下工作&am…

<<迷雾>> 第10章 用机器做一连串的加法(2)--寄存器 示例电路
使用多个触发器可以构成一个寄存器 info::操作说明 单击按钮开关产生上升沿信号, 将 D 的输入存在 Q 端 primary::在线交互操作链接 https://cc.xiaogd.net/?startCircuitLinkhttps://book.xiaogd.net/cyjsjdmw-examples/assets/circuit/cyjsjdmw-ch10-02-register-by-multipl…

《Programming from the Ground Up》阅读笔记:p147-p180
《Programming from the Ground Up》学习第9天,p147-p180总结,总计34页。
一、技术总结
1.Physical memeory
p152, Physical memory refers to the actual RAM chips inside your computer and what they contain.
物理地址指的RAM,即我们…