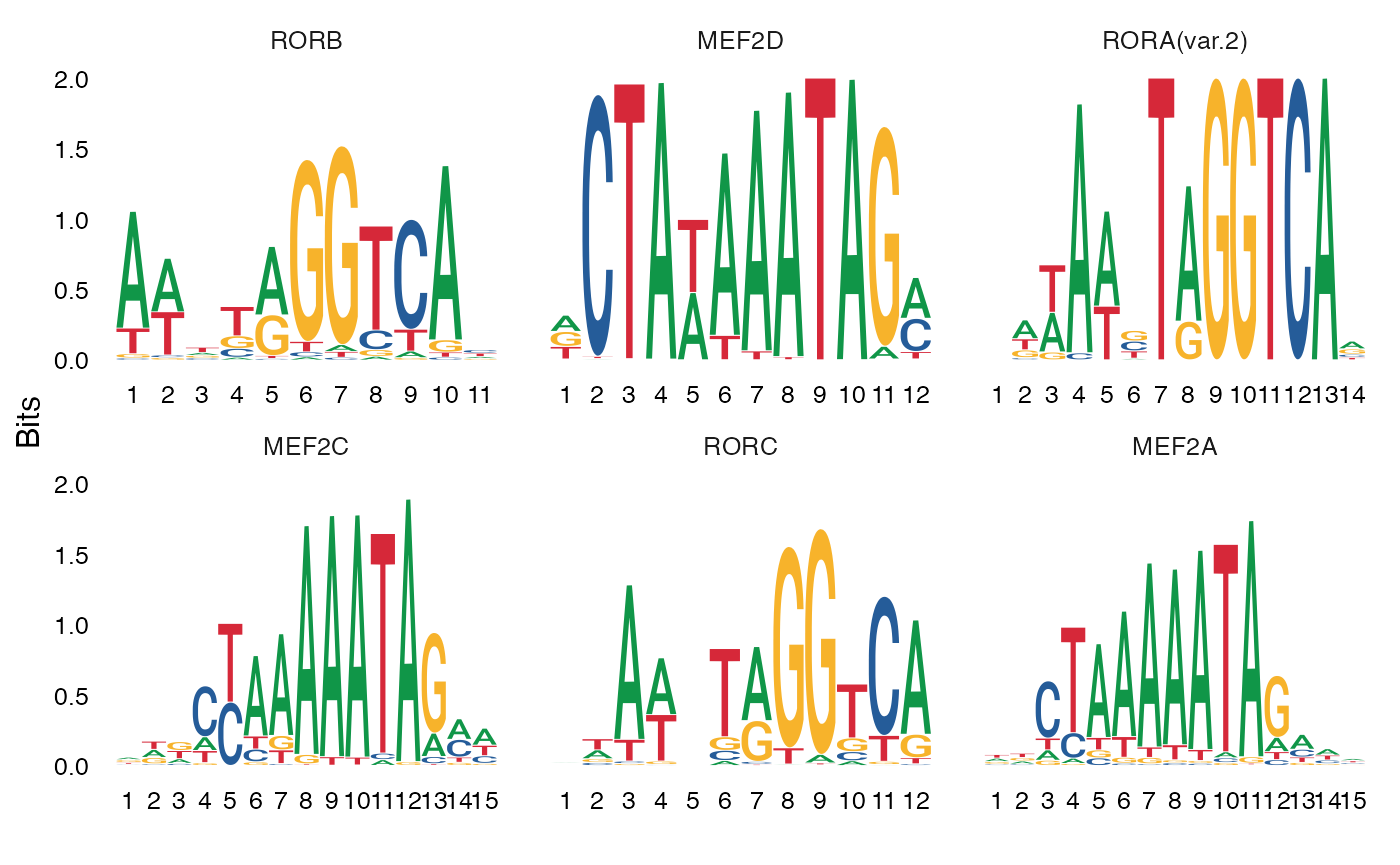
介绍
论文地址:https://arxiv.org/pdf/2404.12633
网络虚拟化(NV)是一种创新技术,在 5G 网络和云计算等领域日益受到关注。NV 可通过网络切片和共享基础设施在同一物理网络上部署多个用户提交的虚拟网络请求(VNR),并满足不同的网络服务需求。
然而,这项引人入胜的技术的核心是虚拟网络嵌入(VNE),这是一个极具挑战性的组合优化问题:VNE 需要处理巨大的组合爆炸和差异化需求。虽然解决方案空间巨大,但根据用户服务的具体要求,不同 VNR 拓扑及其相关资源需求的整合也会发生动态变化。
近年来,强化学习(RL)已成为解决虚拟神经网络问题的一种有前途的方法。然而,由于单向行动设计和 "一刀切 "的学习策略所造成的局限性,现有的基于 RL 的 VNE 方法在可探索性和通用性方面受到了限制。
在本文中,我们为 VNE 提出了一个灵活多变的新 RL 框架 FlagVNE,旨在提高解空间的可探索性,为不同规模的 VNR 学习专门的策略,并实现对未知分布的快速适应。.这种创新方法将为复杂网络环境中的 VNE 开辟新的可能性。
相关研究
相关研究分为两类:传统方法和基于学习的方法。
传统方法
- 早期的 VNE 问题是通过严格的方法(如整数线性规划)来解决的,但这在实际的大规模场景中被证明是不切实际的。
- 随后,人们提出了节点排序等启发式算法。虽然这些算法能在可接受的时间内找到解决方案,但它们在很大程度上依赖于人工设计,而且往往是为特定场景量身定制的,限制了它们在一般情况下的性能。
基于学习的方法
- 最近,机器学习技术被用于解决 VNE,从而带来了更快、更高效的解决方案。
- 特别是,强化学习(RL)作为一种智能决策框架,已显示出巨大的潜力,可通过 MDP 建模有效解决 VNE 问题。
- 作者将现有的基于 RL 的方法统一到一个通用框架中,该框架由三个关键要素组成:MDP 建模、策略架构和学习方法。
- 这些方法将 VNE 解决方案的构建过程建模为基于行动的单向 MDP,利用各种神经网络构建策略模型,并学习处理不同规模 VNR 的单一通用策略。
- 然而,由于单向行动设计和一刀切的学习策略导致可探索性和通用性有限,这些现有方法影响了整体性能。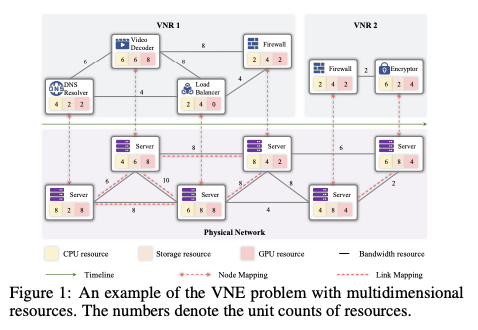 图 1 显示了一个具有多维资源的 VNE 问题示例。它描述了多个 VNR 映射到物理网络的情况,并显示了两个阶段:节点映射和链路映射。
图 1 显示了一个具有多维资源的 VNE 问题示例。它描述了多个 VNR 映射到物理网络的情况,并显示了两个阶段:节点映射和链路映射。
拟议方法(FlagVNE)
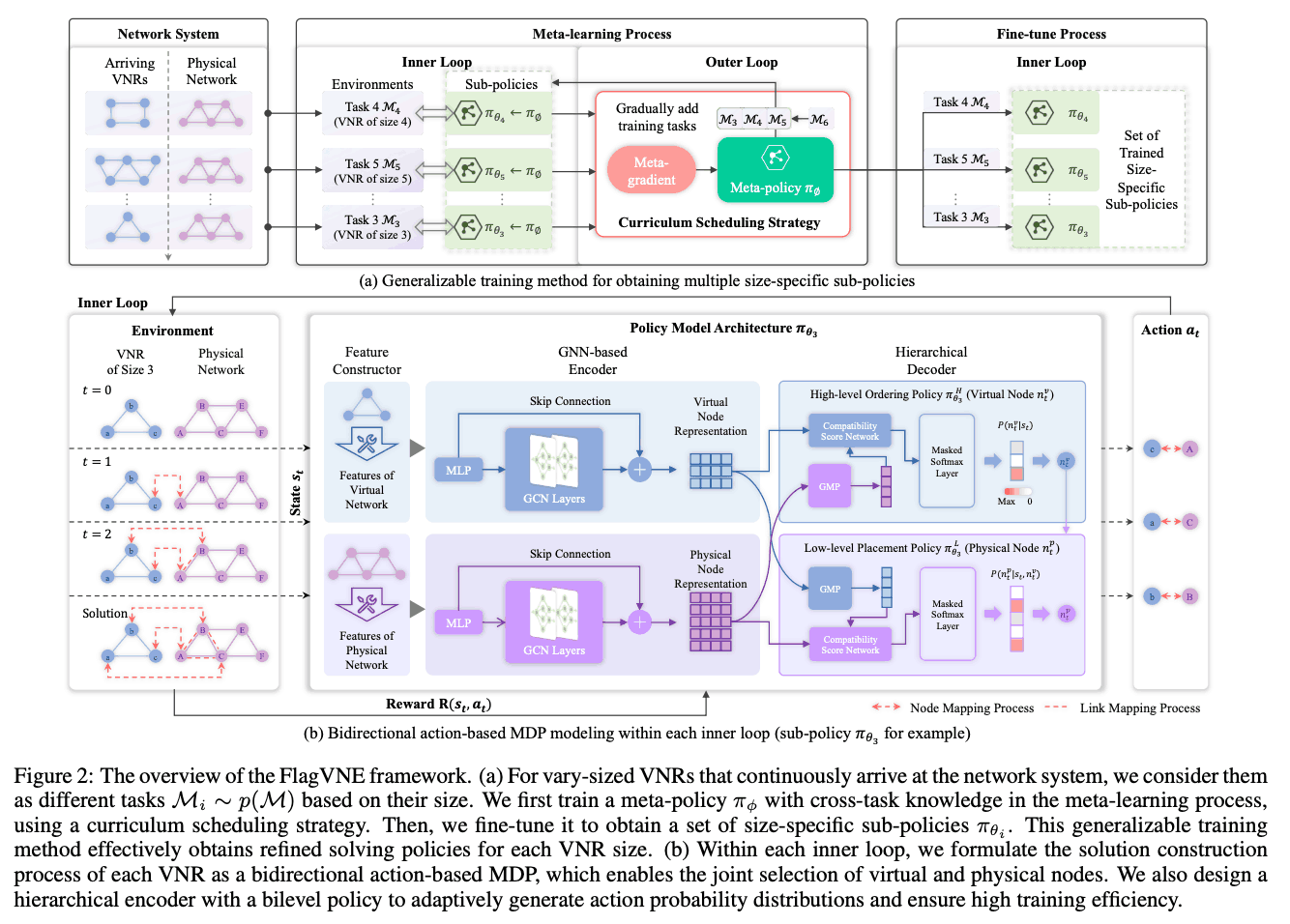 图 2 是 FlagVNE 框架的概览。(a) 显示了通用学习方法,(b) 显示了基于行动的双向 MDP 建模和分层策略架构。拟议方法的主要组成部分包括
图 2 是 FlagVNE 框架的概览。(a) 显示了通用学习方法,(b) 显示了基于行动的双向 MDP 建模和分层策略架构。拟议方法的主要组成部分包括
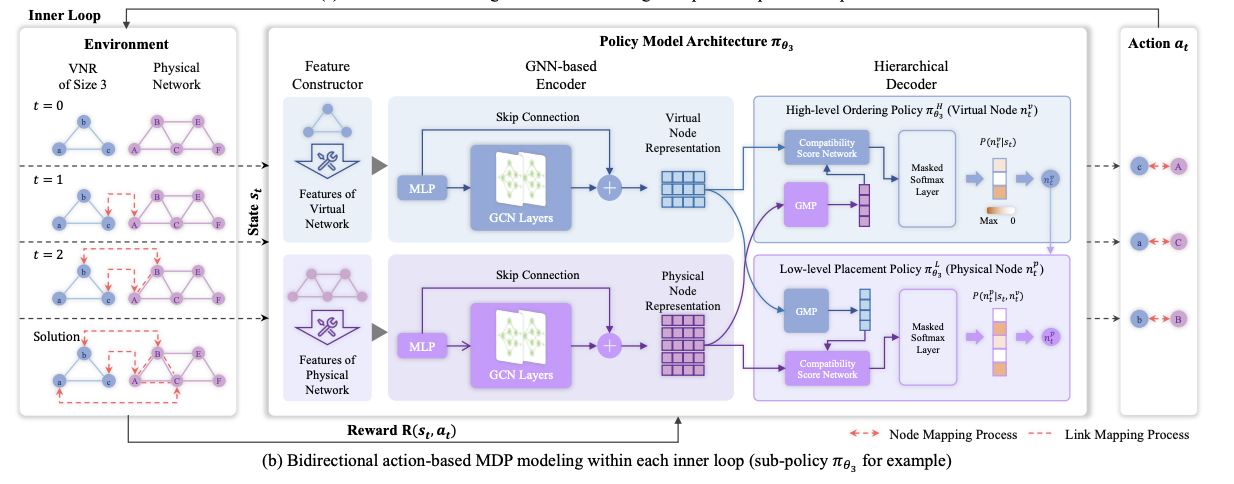
1. 基于行动的双向 MDP 模型 (图 2(b)): - 提出了一种新的 MDP 模型,允许同时选择虚拟节点和物理节点。
- 这提高了代理探索和利用的灵活性,增加了对解决方案空间的探索。
- 设计了分层解码器和双层策略,以应对庞大而多变的行动空间。
2. 分级策略架构 (图 2(b)):–分解为两个方面:虚拟节点的排序和物理节点的放置。
- 设计了具有两层策略(高层排序策略和低层放置策略)的分层解码器。
- 这样就能生成自适应行为概率分布并提高学习效率。
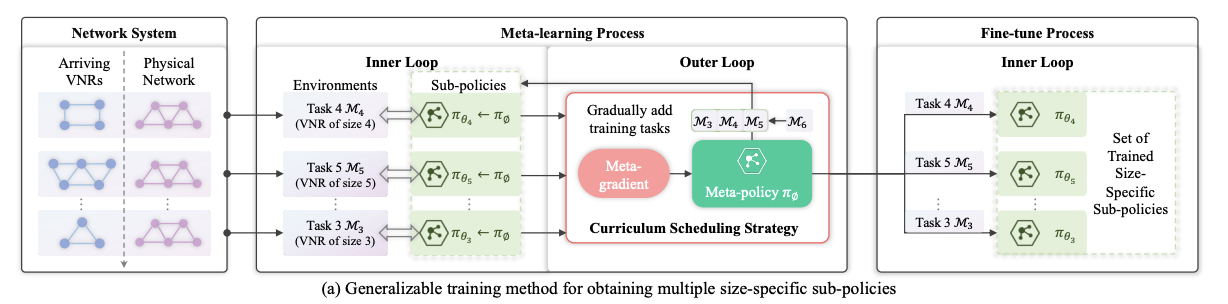
3. 基于元强化学习的多功能学习方法 (图 2(a)):–提出了高效学习多种特定规模策略并使其快速适应新规模的方法。
- 在学习元策略后,针对每种 VNR 大小(包括未知大小)的特定大小策略都会得到快速微调。
- 使用课程调度策略逐步纳入大型 VNR,以减少部分最优收敛。
试验
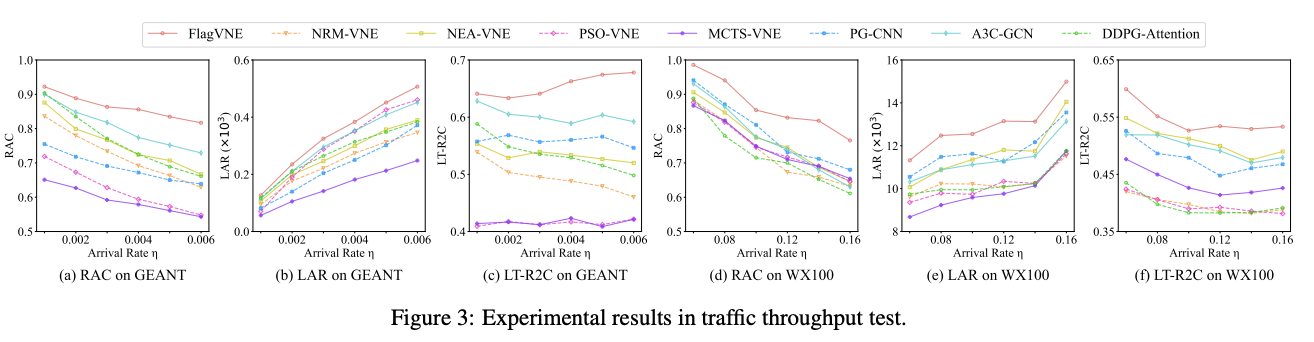 图 3 显示了所有算法在不同流量吞吐量下的性能:随着 VNR 到达率的增加,所有算法的 RAC 都会下降,但 FlagVNE 总是能达到最佳性能。当资源竞争激烈时,FlagVNE 的改进效果尤为明显。
图 3 显示了所有算法在不同流量吞吐量下的性能:随着 VNR 到达率的增加,所有算法的 RAC 都会下降,但 FlagVNE 总是能达到最佳性能。当资源竞争激烈时,FlagVNE 的改进效果尤为明显。
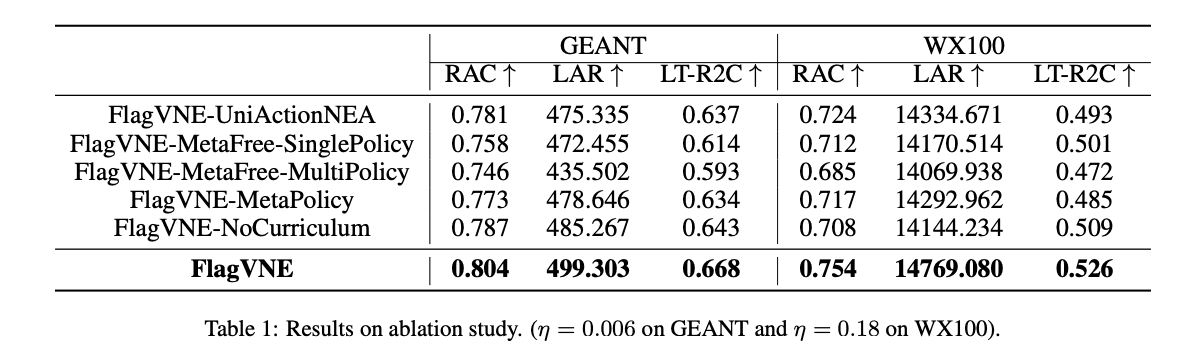 表 1 列出了消融研究的结果,表明 FlagVNE 的每个组成部分都对最终的性能提升做出了贡献。其中,基于元强化学习的学习方法和课程安排策略的有效性得到了证明。这些结果表明,FlagVNE 在提高可探索性和通用性方面表现出色。
表 1 列出了消融研究的结果,表明 FlagVNE 的每个组成部分都对最终的性能提升做出了贡献。其中,基于元强化学习的学习方法和课程安排策略的有效性得到了证明。这些结果表明,FlagVNE 在提高可探索性和通用性方面表现出色。
结论
本文提出了一种新的 VNE RL 框架 FlagVNE,以提高可探索性和通用性。实验结果表明,FlagVNE 可用于复杂网络环境中的有效资源分配。未来,FlagVNE有望应用于更大型、更动态的网络场景,以检验其有效性。另一个有趣的方向是将 FlagVNE 应用于其他资源管理问题。