7.2晚上投的,发邮件约到了7.3晚上 总时长1小时10分钟左右
-
自我介绍
-
拷打项目30min
-
缓存三兄弟
-
Redis除了缓存,还能做什么
-
Redis的数据结构,什么时候用哈希,什么时候用字符串
-
线程池的执行流程
-
MySQL索引的数据结构
-
聚簇索引和非聚簇索引
-
索引选择使用哪些字段
-
使用联合索引要注意什么
-
表级锁
-
hashMap的底层数据结构
算法:lc-3.无重复字符的最长子串
反问:几轮面试,多久出结果,还需要学习什么
整体体验很好,感谢美团!
作者:ljk250531 链接:7.3美团—Java日常实习面经_牛客网 来源:牛客网
算法题:
包没写出来的 第一眼没什么想法
题解 使用滑动窗口 从第一行遍历到最后一行 然后用了hashset去加和删除 以及判断是否包含
其他解 还是滑动窗口 但是就相当于用遍历数组的方式代替了hashset 就是遍历右侧节点 如果左边界 和当前的值重复的话 那么左边的所有都删除了

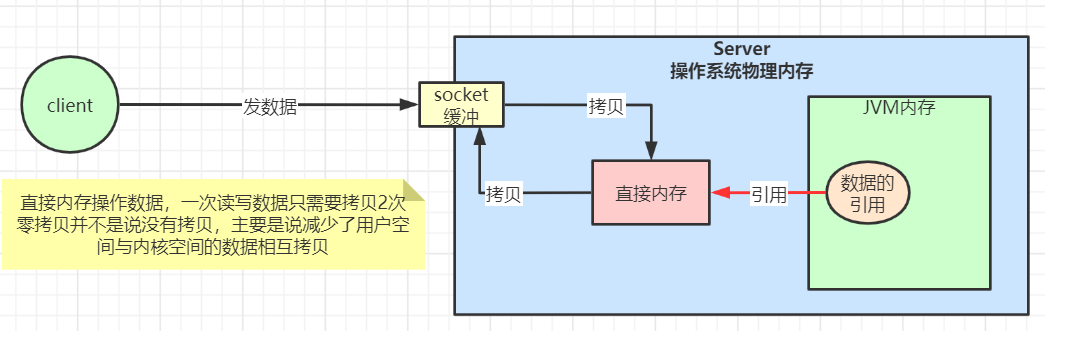
Redis 缓存三兄弟
缓存击穿 : 热点key 多个数据同时访问导致崩溃
缓存穿透 : 大量访问缓存里边不存在的数据
缓存雪崩 :多个热点key同时失效
Redis 除了缓存还能
主从集群 分片集群 内存回收 哨兵,,,,,,
Redis的数据结构,什么时候用哈希,什么时候用字符串
Redis的五大数据类型:String、Hash、List、Set和ZSet
String适用于简单字符缓存、分布式锁等
Hash适合存储对象;
List可用于实现栈、队列;
Set处理无序不重复元素集合;
ZSet常用于排行榜场景。(这个不是很懂)
原文链接:https://blog.csdn.net/q2qwert/article/details/131837969
线程池的执行流程

MySQL索引的数据结构
-
B+Tree索引:
- 特点:B+树是一种多路平衡查找树,其所有叶子节点在同一层,且叶子节点通过指针相连,构成了一个有序的链表。在B+树中,所有非叶子节点仅起到索引作用,包含子树所有节点的最大值,而叶子节点则包含了所有的关键字(值)。
- 优势:由于B+树的非叶子节点只存储索引信息,因此可以容纳更多的节点元素,使得树的高度相对较低,从而减少了查找过程中磁盘I/O的存取次数。此外,叶子节点通过链表相连,便于区间查找和遍历。
- 应用:MySQL的InnoDB存储引擎默认采用B+树作为索引的数据结构。
-
Hash索引:
- 特点:哈希索引采用哈希算法,将键值换算成新的哈希值,并映射到对应的槽位上。哈希索引的查询效率通常很高,因为在没有产生哈希冲突的情况下,通常只需要一次检索就可以找到目标数据。
- 限制:哈希索引只能用于对等比较(如=、in),不支持范围查询(如between、>、<等)。此外,哈希索引也无法利用索引完成排序操作,因为哈希索引是无序排列的。
- 应用:在MySQL中,Memory存储引擎支持哈希索引。InnoDB存储引擎虽然本身不直接支持哈希索引,但具有自适应哈希功能,可以在特定条件下将B+树索引转化为哈希索引
聚簇索引和非聚簇索引
聚簇索引是物理索引,它将索引与数据放在一起。
非聚簇索引的数据存储与索引是分开的。非聚簇索引的叶子节点指向了对应的数据行,而不是直接存储数据。(就是二级索引)
索引选择使用哪些字段

使用联合索引要注意什么

表级锁

hashMap的底层数据结构
感觉之前见过这句话












![[Python学习日记-39] 闭包是个什么东西?](https://i-blog.csdnimg.cn/direct/9c3d53b4dd8f4ee2b55ba32912e53cb4.png)