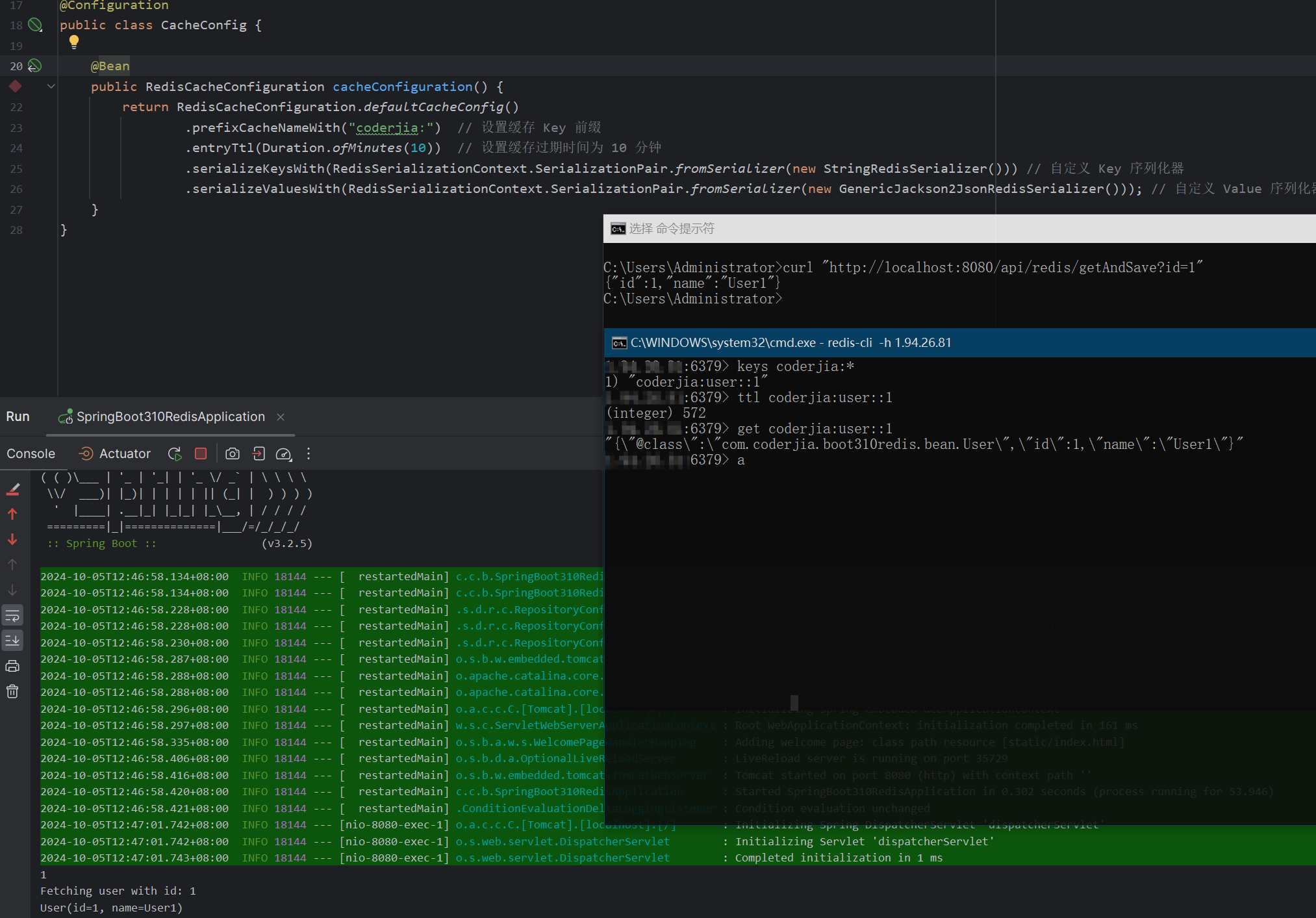
用智谱清言和kimi搜出来的结果都没法在notepad生效,后面在overflow上找到的答案比较靠谱。
查找:^[^\n]*\n([^\n]*)
替换:\1

删除偶数行
查找:^([^\n]*)\n[^\n]*
替换:\1
代码解释
^:这个符号代表字符串的开始。在多行模式下,它也可以匹配每一行的开始。
[^\n]*:这部分是一个字符类匹配(character class match)。[^\n] 表示匹配除了换行符 \n 之外的任意字符。星号 * 表示匹配前面的字符类零次或多次。[^\n]* 匹配从每一行开始到该行末尾(换行符之前)的所有字符。
\n:换行符的表示。它匹配文本中的换行符。
([^\n]*):这部分再次使用了 [^\n]*,匹配除了换行符之外的任意字符,零次或多次。不过,这次它被括号 () 包围,表示一个捕获组(capturing group)。这意味着匹配到的文本可以被后续操作(如替换、提取等)单独引用。
\1:在正则表达式中, \1代表对第一个捕获组(capturing group)的引用。捕获组是通过将正则表达式的一部分放入圆括号 () 中来创建的。这样,匹配该部分的文本可以在后续的正则表达式操作中被引用或者在替换操作中被重用。例如,考虑正则表达式 (a)b\1:(a) 是第一个捕获组,它匹配字母 a。b 直接匹配字母 b。\1 引用了第一个捕获组的内容,即这里它代表字母 a。所以,这个正则表达式会匹配字符串 "aba",其中 "a" 被捕获为第一个组,然后是 "b",接着是对第一个捕获组的引用,也就是另一个 "a"。