作者 / 得物技术 - 仁慈的狮子
目录
一、背景
1. 局限性
2. 向前一步
二、原理剖析
1. 系统架构
2. 工作模式
3. reporter
三、稳定性验证
四、案例分析
五、写在最后
一、背景
线上问题的定位与优化是程序员进阶的必经之路,常见的问题定位手段有日志排查、分布式链路追踪和性能分析等,其中日志排查主要用来定位业务逻辑问题,分布式链路主要用来定位请求链路中具体是哪个环节出了问题,而如果服务本身的性能出了问题,如一段时间复杂度高的代码引发了CPU占比飙升、内存泄漏等,则需要依赖性能分析工具来帮我们定位此类问题。
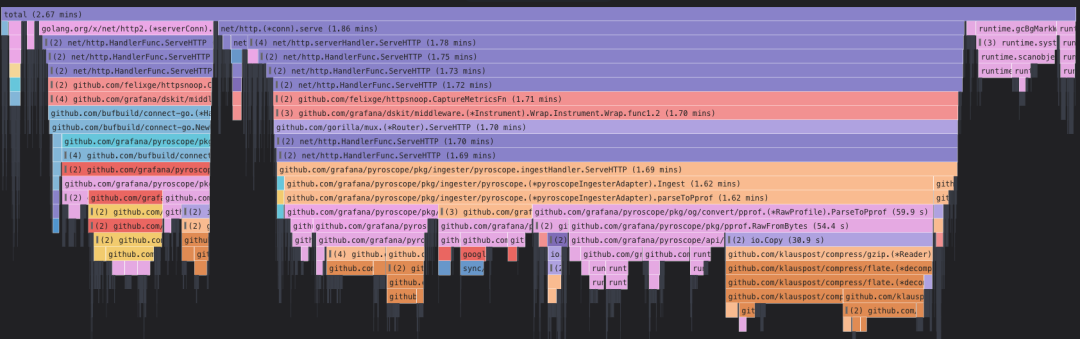
在Golang技术栈中,pprof则是性能分析的一大杀器,它可以帮助我们获取到程序的运行时现场(profile data),并以可视化的形式展示出来,火焰图是其中最为常见的一种展现形式:
我们如果想要借助pprof的能力进行性能分析,通常的步骤是:
-
程序中导入
net/http/pprof包,并开放端口用于获取profile数据; -
使用go tool中集成的pprof工具,访问端口下载profile数据,然后在本地对profile数据进行解析并可视化展示。
1.1 局限性
在微服务盛行的当下,很多系统根据业务发展需要,都被拆分成了几十甚至上百个微服务,就拿得物社区业务来讲,整体业务被拆分成了推荐服务、内容服务、引力服务、标签服务等数十个微服务,并且为了提高服务的可用性,每个服务又是以多实例的形式部署。如此多服务的如此多实例,在人力有限的情况下,很难做到一切都在掌控中,一旦线上某个服务的某个实例出现了异常,即便我们可以通过告警快速感知,但是也很难保证可以及时捕获到服务运行时的现场信息。下图所示的是实际生产环境发生过的一次异常,可以看出发生的时间是在凌晨,试问如果遇到这种情况,我们该如何应对?
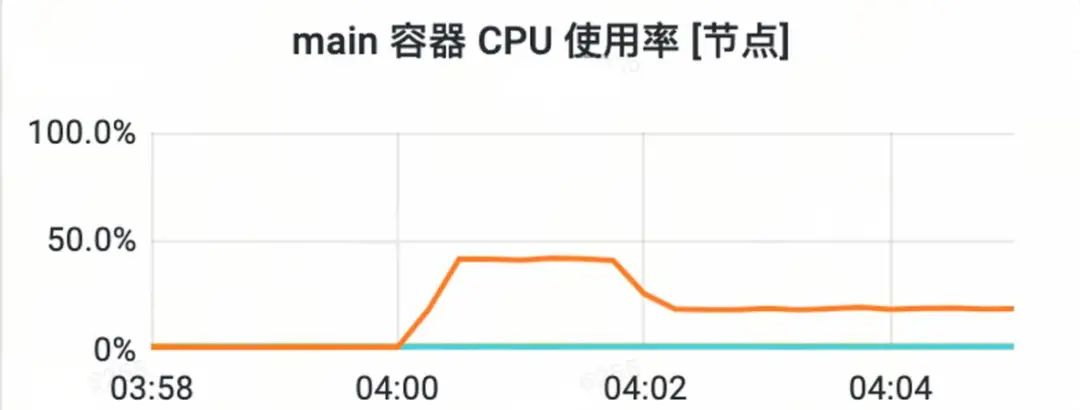
因此可以说,仅仅凭借pprof提供的基础能力,我们很难应对在复杂的业务系统中突发的性能问题。
1.2 向前一步:
工欲善其事,必先利其器!
既然人为手动采集profile数据的方式不再适用,那就朝自动化的方向演进,于是,便诞生了Conan!Conan的核心功能包括profile数据自动化采集、存储和展示,旨在为Golang系统提供一套用于性能分析的自动化解决方案。
二、原理剖析
2.1 系统架构
Conan为常见的C/S架构,client端是集成了Conan SDK的应用,应用运行期间,SDK会负责在恰当的时机采集应用的profile数据,并上报到server端;server端我们使用Pyroscope进行搭建,Pyroscope是一个开源平台,算得上是持续化profiling中的代表之作,在Conan中,Pyroscope负责将client上报的profile数据进行高效存储,并提供可视化界面,支持以火焰图等多种形式展示这些profile数据。Conan整体架构如下图所示:
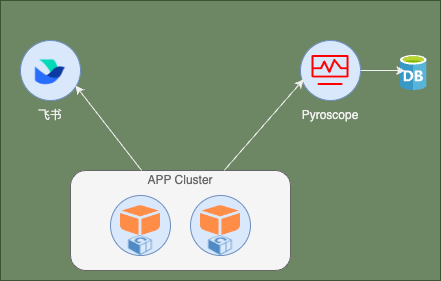
2.2 工作模式
前面提到,SDK会在“恰当”的时机采集应用的profile数据,那么这个时机该如何确定?其实,时机的确定也就是对应着不同的使用诉求,我们搜集了多位资深研发的宝贵建议,总结提炼得出了如下两种最常见的使用场景:
-
在应用真正发生性能问题的时候进行profile数据的采集,精准的捕捉问题现场;
-
持续化的采集,定期分析采集下来的profile数据从而发现可优化的点,将此作为日常巡检的工作;
为了满足这两种最核心的诉求,我们对应推出了Conan的两种工作模式:自适应模式和持续化模式。
自适应模式
所谓“自适应”,就是你告诉Conan具体在什么情况下应用可以被认定为发生了性能问题,一旦这种情况发生,Conan就会采集profile数据。在Conan中,认定的条件被分为了两大类:
-
环比涨幅:Conan会定时搜集某项资源的使用情况,以最近N次的搜集为一个时间窗口,对比最近一次采集的结果与前N-1次采集结果的均值,从而计算环比,如果环比涨幅达到设置的阈值,则认为应用出现了性能问题;
-
具体阈值:应用某种资源的使用情况达到了某个具体的值,如:CPU使用率达80%,则会被认为发生了性能问题;
接下来我们进一步看看,在自适应模式下,Conan究竟是怎么工作的:
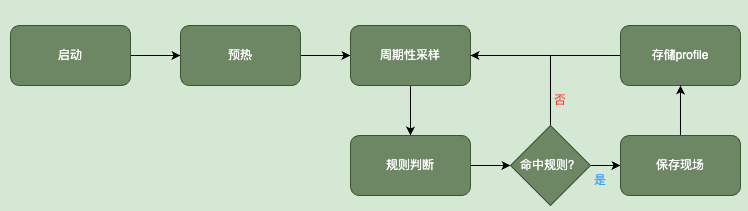
预热
考虑到进程在启动的过程中,各种资源的使用率存在较大的波动,为了避免被误判为异常,Conan会先根据设定的间隔采集对各项指标进行预采样,这个过程是个预热阶段,不会对采集到的指标数据进行任何规则判断。
周期性采样
预热阶段结束后,Conan进入正式的周期性采样阶段,默认每隔5s采样一次,我们可以通过相应的配置修改采样周期。Conan使用固定大小的循环链表缓存近N次采样的数据。
Conan在每一次采样周期里,将对进程的CPU使用率、RSS使用率和goroutine数这三项指标进行采集。
-
CPU指标
Conan使用gopsutil采集进程CPU的使用率,但是gopsutil给到的CPU使用率是乘以了CPU核数的结果,看起来不太直观,因此我们还需要转换一道,即除以CPU核数,将使用率变成百分制(0%~100%)。此时思考一个问题,如何准确地获取到进程可以使用的CPU核数?这需要分以下几种情况分别探究:
-
进程使用了
runtime.GOMAXPROCS限制其能够使用的最大CPU核数。这需要显示地告诉Conan,然后Conan在采集CPU指标时同样会使用runtime.GOMAXPROCS获取进程能够使用的最大CPU核数; -
进程在容器环境运行。我们知道在Linux系统中,容器使用Cgroup实现资源的限制,所以当Conan发现进程是在容器中运行后,会从
/sys/fs/cgroup/cpu/cpu.cfs_quota_us和/sys/fs/cgroup/cpu/cpu.cfs_period_us文件中获取到信息,然后计算出CPU核数:cores=quota / period; -
进程在裸机上运行。如果上述两种情况都不是,Conan则判断进程直接运行在裸机上,会通过调用
runtime.NumCPU获取CPU核数。
-
RSS指标
Resident Set Size is the amount of physical memory currently allocated and used by a process (without swapped out pages). It includes code, data and shared libraries (which are counted in every process which uses them)
一般来讲,RSS是衡量一个进程使用了多少物理内存的合理指标,因此Conan只将注意力放到它的身上。
同样的,Conan也是使用gopsutil来获取进程正在使用的物理内存大小。但是要计算使用率,还需要知道进程可以使用的物理内存上限,这将分为两种情况进行探究:
-
进程运行在容器中。Conan会从
/sys/fs/cgroup/memory/memory.limit_in_bytes文件中获知进程可以使用的最大物理内存。 -
进程运行在逻辑上。Conan借助gopsutil库获知进程可使用的物理内存上限。
-
goroutine指标
采集goroutine数就相对简单了,Conan使用golang标准库runtime提供的NumGoroutine方法获取进程中活跃的goroutine数。
规则判定
当采集到各项指标后,Conan将这些指标数据与事先设定好的规则进行匹配,进而判断进程的资源使用是否出现了异常。
资源使用率异常主要分为两种情况:
-
突刺。短时间内资源使用率达到一个比较高的水位,然后很快又降了下去;
-
资源使用率缓慢的上涨,逐渐涨到一个较高水位;
对于第一种异常,我们可以使用环比的规则来判定,比如:CPU环比上涨了30%,这里的环比是当前值与近N次采样的均值进行对比。但是如果资源使用率本来就很低(如5%),即便环比上涨了100%我们也认为属于正常情况,这时候还需要一个下限规则,比如:CPU使用率达到了40%;而对于第二种异常,环比的规则就不太适用了,我们应该使用绝对值的规则来进行判断,比如:CPU使用率达到了50%。这三种规则均适用于前述的各项指标。另外,Conan还考虑到了以下两种情况:
-
任何形式的profiling,都有一定的性能损耗,所以Conan对CPU使用率做了上限的限制,即当CPU使用率达到了我们预先设定的上限,Conan不再进行任何profiling;
-
在go1.19之前,goroutine dump会Stop the world,goroutine数越多,STW时间越长。因此,Conan允许对goroutine profiling设置上限规则,即当goroutine数达到上限后后,不再进行goroutine profiling。
持续化模式
持续化模式顾名思义就是指定时地持续化采集profile数据,比如每5秒采集一次,在这种模式下,不管应用处于什么状况,都会在固定的时间间隔后进行profile数据的采集。
持续化模式的实现相比于自适应模式简单了很多,核心逻辑便是定时的采集profile数据,此处不再赘述。
保存现场(profiling)
不管是自适应模式,还是持续化模式,最终都会在各自认为合适的时机采集profile数据(profiling)。在Conan中,我们使用标准库pprof提供的能力进行profiling,profile数据有两种格式:binary和text,其中binary是经过压缩过后得到的,这种形式的数据需要我们借助go tool pprof之类的工具才能打开;text使用的是传统文本格式,可以用常用的文本编辑器打开,我们平常通过浏览器访问http端口进行profiling时传输的数据就是这种格式,text没有经过压缩,profiling时比较吃内存,这也是为什么我们每次在浏览器进行profiling时服务的内存会有较大的波动。Conan选择了前者。
另外,在自适应模式中,考虑到很多异常是持续性的,且profiling有一定开销,所以为了尽量降低profiling对应用的影响,Conan提供了冷静期的机制,允许前后两次profiling存在一定空窗期,而且支持针对每种指标单独设定冷静期。
2.3 reporter
接下来需要思考的问题是:采集下来的profile如何处理?考虑到多样化的需求,以及结合Conan自身两种工作模式的特性,我们设计出reporter这样一种组件,它的作用就是专门负责将采集下来的profile数据上报到某个地方。我们将reporter设计成了接口,大家可以通过实现接口来扩展自己的reporter,然后将其注入即可:
type ProfileReporter interface {Report(...) errorName() string}func WithProfileReporter(r ...ProfileReporter) Option {//...}
根据得物自身业务的需要,Conan内置了两种reporter:飞书 reporter和pyroscope reporter。
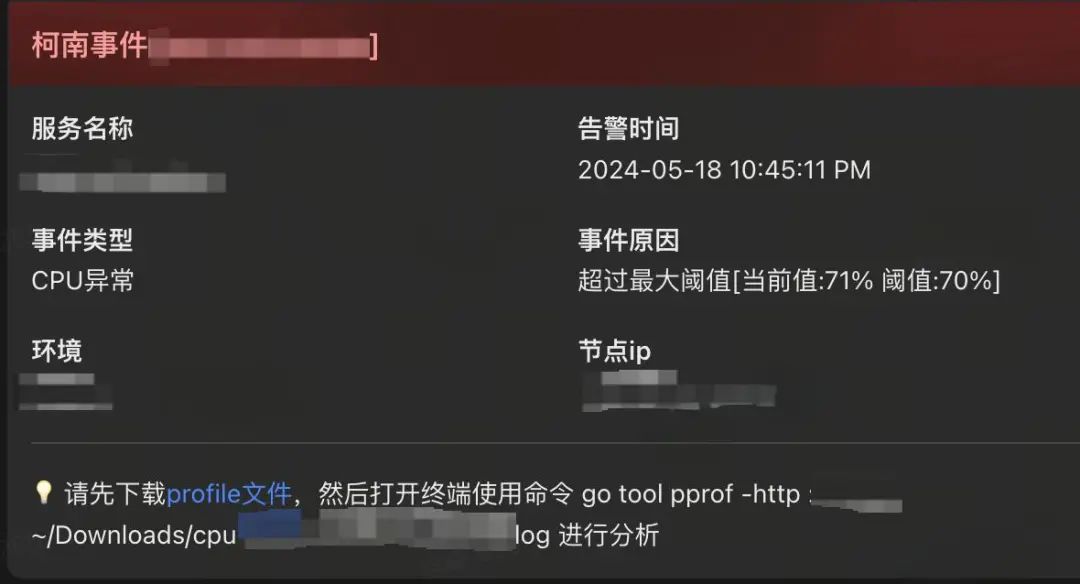
飞书 reporter
飞书reporter是专门为自适应模式而设计。以自适应模式运行的应用,在采集到profile数据之后,会先将数据落盘(默认存储目录为/tmp,也可以指定落盘的路径),然后通过给定的飞书机器人webhook链接发送飞书消息,消息里面带有下载链接,我们可以通过点击链接将profile数据从远端运行的应用那里下载到本地,然后用go pprof工具进行分析。飞书消息样式如下:
pyroscope reporter
大家不免发现,飞书reporter有个局限性,就是采集下来的profile数据存储在应用运行环境的磁盘上,如果我们的应用是运行在如k8s这种虚拟化的环境中,大多数情况下我们保存下来的profile数据会随着容器的重建而被清理掉。因此,为了应对这个问题,我们需要有个中心化的地方专门来存储采集的profile数据。为了避免重复造轮子,经过长时间的调研,我们最终选择了开源平台Pyroscope,它不仅能够满足我们中心化存储的诉求,还能够提供精美的可视化界面来展示profile数据,大大降低了使用门槛。对应地,我们也提供了pyroscope reporter来专门对接Pyroscope,只需要提供Pyroscope的访问地址,便可以将采集下来的profile数据上报给Pyroscope,然后通过访问它的web页面来进行浏览:
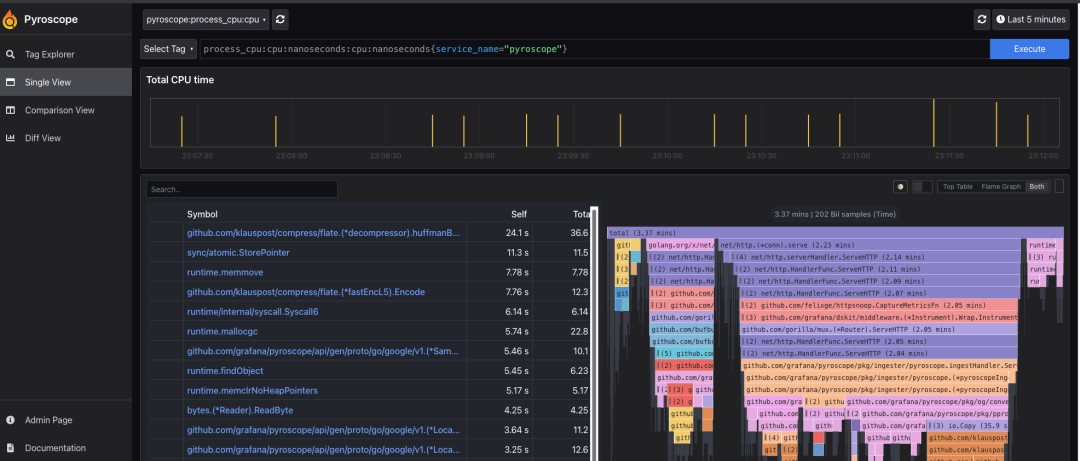
三、稳定性验证
看到这里,或许有些读者心中不免对Conan多了几分认可。但是又因为不知道这玩意儿自己的稳定性和开销如何,担心放到生产上会有问题。
目前为止,得物社区业务的数十个核心服务已经接入了Conan,且稳定运行了一年多。另外,我们还对Conan进行了混沌演练,量化了其在两种不同模式下带来的开销。以自适应模式为例,结果如下表所示:
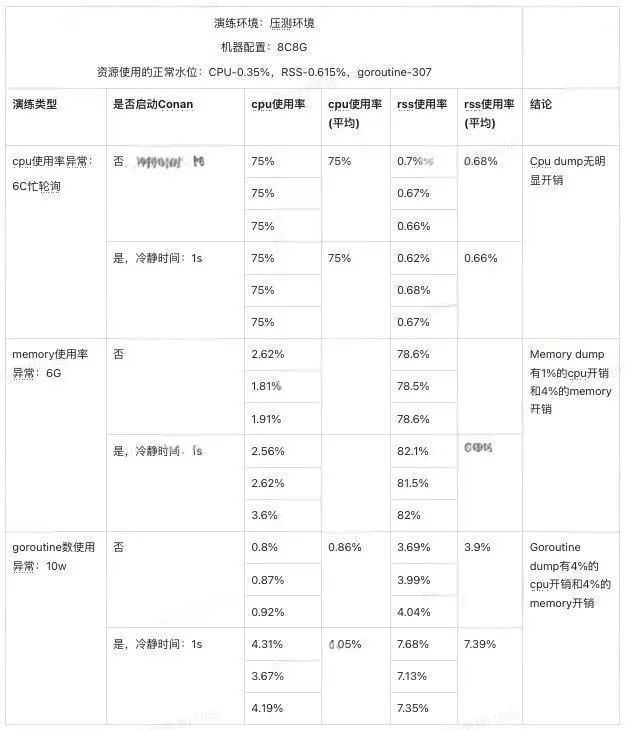
我们通过注入故障代码让服务的CPU使用率、memory使用率以及goroutine数上涨到一个比较高的水位,然后对比Conan启用前后各资源使用率来了解Conan在极端异常下的表现。从结果来看,Conan在极端异常情况下的开销能够控制在5%以内。
四、案例分析
前面花了大量的篇幅来讲解Conan的实现原理,现在各位看官不免心生疑虑:这玩意儿到底行不行?能不能如它所宣导的那样帮我们及时捕获线上问题的现场?接下来,我们借助一个实际的案例来体会下Conan给我们带来的便利之处。
在某一次的迭代需求中,产品给出了一个公式,让研发根据公式计算出一个分数。在实现的时候,我们用一个t+1的脚本来计算这个分数,该脚本中用了一个第三方库来解析公式,并获取最终计算结果。上线前我们只验证了这个库功能的正确性,并未探究它的性能,这也为后来线上异常的发生埋了雷。
脚本上线后第一天的凌晨4点(脚本在这个时间点运行),就发生了线上告警:
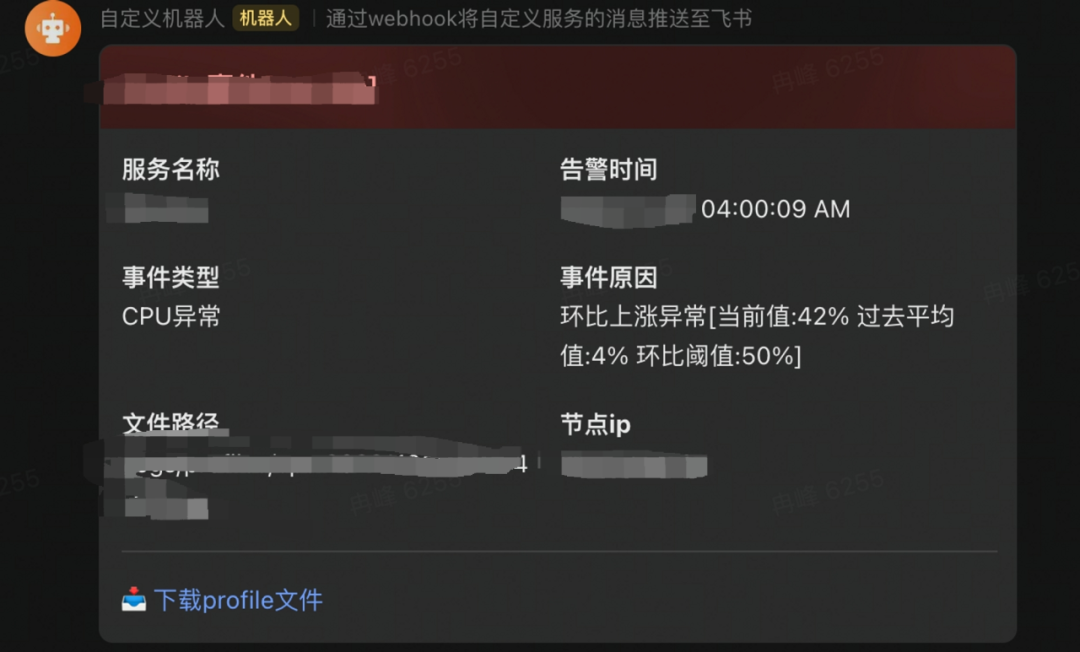
对应监控如下:
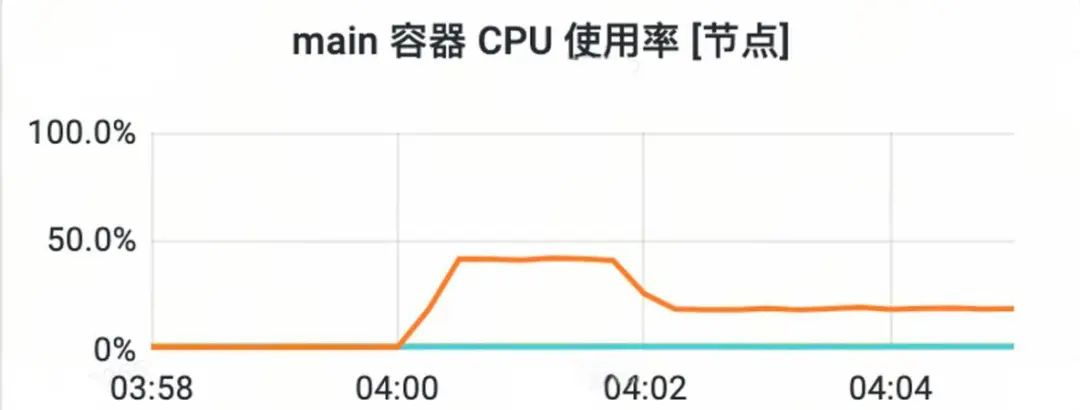
发生告警的时候我相信大多数同仁都正做着美梦吧。没关系,Conan已经帮我们把问题现场保存了下来,我们只需要在上班后打开飞书,进入告警群,找到相关的告警信息然后将profile数据下载到本地,最后借助go tool pprof工具打开profile文件,定位问题:
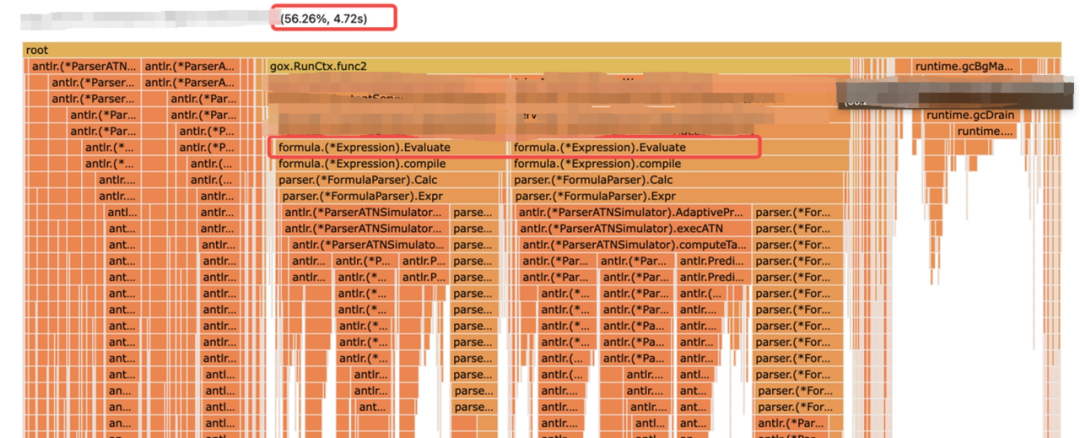
通过火焰图可知,原来是上述第三方库在计算排序分时消耗了大量的CPU。找到问题的根因之后,我们便可有针对性地解决。解决方案此处不赘述。
如果没有接入Conan,异常本身是否被感知到就是个未知数,因为CPU使用率虽说有飙升,但是没有达到一般告警的水位;即便被感知到,排查的思路大致也是这个过程:抓住凌晨4点这个关键线索,排查在这个时间点运行的脚本有哪些,然后分析每个脚本的代码,推测出比较耗CPU的逻辑,接着benchmark进行验证,最后试着修复代码,观察效果,如果CPU使用率降下去了就说明问题解决了。对比接入了Conan之后的排查过程,效率实属提升了不少。
五、写在最后
得物技术发展至今,为了给得物日益庞大的业务规模和日趋复杂的业务形态充当稳定可靠的支柱,我们始终将稳定性放在最为重要的位置,“稳定”二字可以说已经深深烙印在了我们每个得物技术er的内心。Conan作为得物技术助力得物业务稳定发展的一个非常小的案例,它以性能分析作为切入点,为我们提供了从应用异常感知、到profile数据下载、存储,最后到profile数据可视化展示的一整套解决方案。
往期回顾
1. 浅析Java类隔离规避依赖冲突的实现原理|得物技术
2. 包材推荐中的算法应用|得物技术
3. 得物自建 Redis 无人值守资源均衡调度设计与实现
4. 暗水印显隐术助力生产排障提效|得物技术
5. 深入理解 Babel - 微内核架构与 ECMAScript 标准化|得物技术
文 / 仁慈的狮子
欢迎关注得物技术,获取技术干货~
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。