ICDAR 比赛简介
ICDAR 比赛 https://rrc.cvc.uab.es/是国际公认的文字领域权威的比赛,文字领域顶会论文里的数据测评和测评指标往往都来源于ICDAR比赛的数据和指标,每年一般会有几个大类的赛事,然后每个赛事会细分3-4个比赛。ICDAR竞赛因其极高的技术难度和强大的实用性享誉国内外,与赛后非正式刷榜不同,ICDAR官方认证的正式竞赛采用全新的数据集,并且在比赛期间不公布参赛团队的信息和成绩,同时限制了结果提交时间和次数,是一项较高难度的“盲打”比赛。
ICDAR24历史地图文字识别比赛介绍
https://rrc.cvc.uab.es/?ch=28
数字化历史地图上的文字包含了地理参考的政治和文化背景的宝贵信息,但由于这些地图为不可搜索的光栅格式,大量信息难以获取。这个挑战旨在解决检测和识别地图文本信息(如地名)的独特挑战。尽管该任务与以往的阅读竞赛有相似之处,但历史地图文本提取面临的挑战包括大量的密集文本区域、旋转和弯曲的文本以及不常⻅的场景文本提取问题的广泛间隔字符。该比赛集结了日常文字领域各种难题,值得去探索和攻克。
比赛内容为:
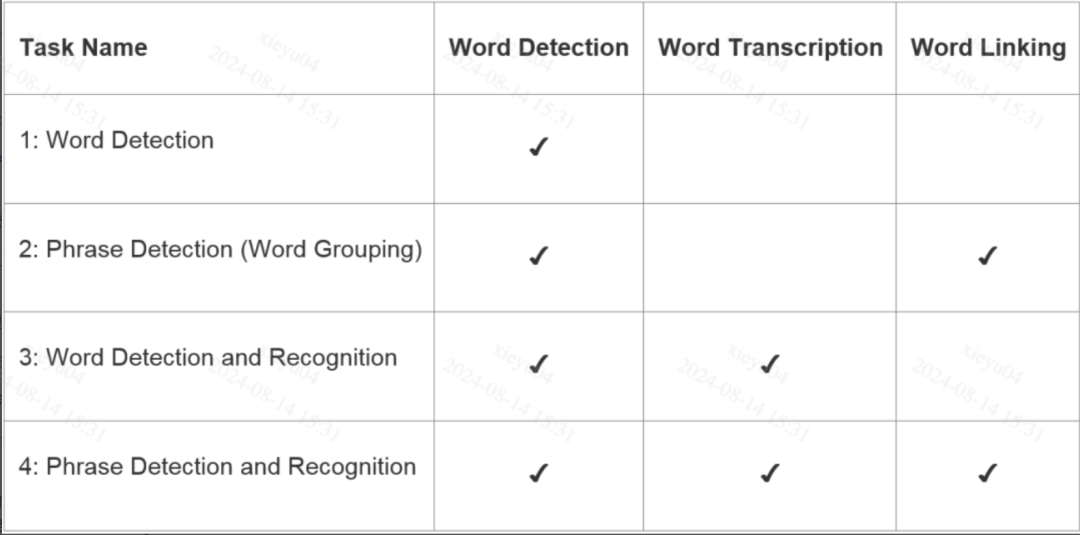
赛事主要分了4个任务:
-
任务1,历史地图单词检测任务,主要解决密集文本和弯曲文本等的检测问题
-
任务2,历史地图短词检测任务,主要是解决如何合理拼接或切分词句的检测问题
-
任务3,历史地图单词检测与识别任务,主要解决各类地图文本,包括带有旋转角度单词的检测和识别
-
任务4,历史地图短词检测与识别任务,主要解决各类地图文本合理的拼接或切分的检测识别问题
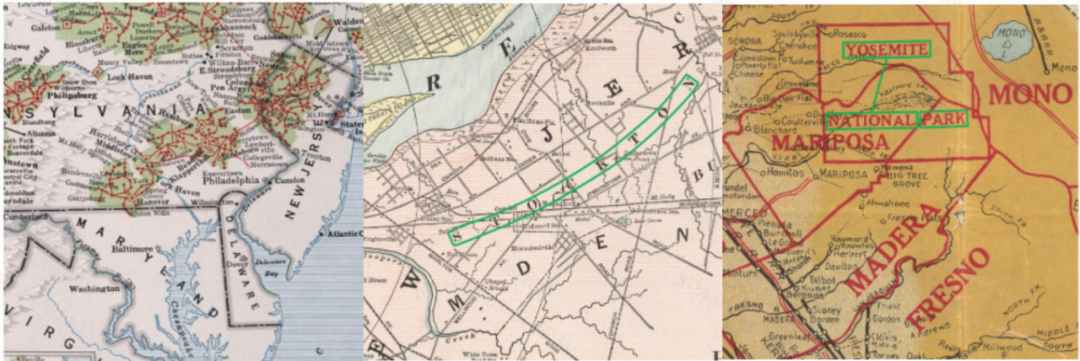
在本次赛事中,我们(bilibili人工智能平台部)获得了3个第一,1个第二;分别是,任务1地图单词检测任务获得第一,比第二高出了2.75%;任务2 历史地图短词检测任务获得第二,比第一差了0.39%,;任务3历史地图的检测和识别任务获得第一,比第二超越了7.73%;任务4历史地图短词检测与识别任务获得第一,比第二高出 1.1%。如下表所示,我们在所有任务上列出了与第二名对比的结果。
| 任务名 | 结果对比 |
| 历史地图的检测任务 | 高出第二 +2.75% |
| 历史地图的检测链接任务 | 低于第一 -0.39% |
| 历史地图的检测和识别任务 | 高出第二 +7.73% |
| 历史地图的检测和识别链接任务 | 高出第二 +1.1% |
荣誉证书

由于整个赛事用的方法算法框架基本吻合,我们将成绩最好且最有代表性的任务3所用的技术细节展开具体介绍。
任务三 Detection-Recognition 介绍
https://rrc.cvc.uab.es/?ch=28&com=evaluation&task=3
任务介绍:此任务需要检测出历史地图图片中的文字位置并准确识别,检测框以单词作为切分。
比赛结果:在历史地图的检测和识别任务中,我们取得了最佳结果,相比于第二名的结果,超越了其 7.73%。此外,如下表所示,我们在所有任务上列出了与第二名对比的结果。
我们将会分两部分介绍我们的方法:
1)简单介绍自研的模型(DNTextSpotter [8]);此模型相关论文已被ACM MM2024 录用;
2)如何训练得到最终的竞赛结果。
01 我们是怎么做的?
历史地图数据由于密集复杂且存在弯曲多变的文本,因此在模型选型上,我们需要使用一种全面的表达方式来表示文本位置信息,同时我们也要确保模型在端到端有用更高的精度。
1.1 技术背景
Transformer架构在计算机视觉领域取得的成就,如DETR [1] 设计了目标检测领域的一个新范式。越来越多的端到端的文本识别器也开始基于该DETR架构。这类方法中比较经典端到端的识别器有TESTR [2] 与DeepSolo [3] 。其中TESTR 设计两个Decoder分别做检测和识别任务,DeepSolo进一步改进了TESTR的双重Decoder架构,使用了一个Decoder来处理检测和识别两个任务。虽然这些方法在取得了显著成就,但是他们忽略了DETR范式中引发的新问题——二分图匹配的不稳定性。在通用的目标检测任务中,DN-DETR [4] 首次指出使用DETR架构时二分图匹配的不稳定性问题,并提出了降噪训练来解决这个问题。DINO [5] 进一步提出了对比降噪训练方法以进一步提高去噪训练的性能。
不幸的是,对于场景文本识别任务来说,各降噪训练方法没有考虑到场景文字中任意形状特点,以及需要做比单纯的分类任务更复杂的识别任务,使得这种降噪训练方法难以在该任务中发挥作用。基于此,我们提出了一种新的降噪训练方法DNTextSpotter,该方法专门为处理任意形状文本的基于 Transformer 的文本识别器设计,不仅能够有效地识别出任意形状的文本,还能够高效地识别出密集的文字和小目标的文字。
1.2 混合训练策略
为了解决预训练成本过高的问题,我们还提出了混合训练策略,该策略在极小的训练代价下让我们的方法达到了目前的最佳结果。该方法使用了更少量的词表下进行的预训练权重(即论文代码中公开的权重,并且词表只包含不区分大小写的英文字母和数字),进一步在使用了更大的词表(包含了更多的符号以及特殊字符)中的历史地图数据集上微调。比赛结果表明,加载预训练权重在更大词表中训练并不会影响性能,甚至在后续的比赛结果中,发现还提升了性能。
02 模型细节
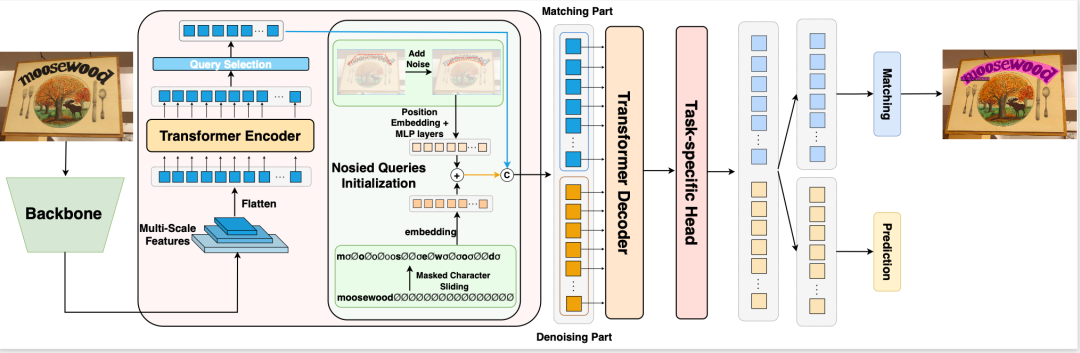
2.1 DNTextSpotter网络架构简介
我们采用了bilibili人工智能平台部和苏州大学联合自研的基于DeepSolo [2] DNTextSpotter的网络结构(https://qianqiaoai.github.io/projects/dntextspotter/)。该网络架构包含了骨干网络、编码器和解码器三部分。首先,我们是用骨干网络ViTAE-v2 [3] 提取图片的全局特征;继而将这些特征输入进由可变形自注意力组成的编码器部分进一步提取图片的全局特征。解码器用于局部特征的学习,并且解码器输入的查询(Query)分为匹配部分查询和降噪部分查询两部分。此外,降噪部分只在训练时候使用,推理时移除。最后使用不同的预测头并行预测不同的任务。(注意:考虑到计算资源的限制,我们训练比赛数据集时,加载完预训练的权重后,会移除掉DNTextSpotter的降噪部分的参数来训练。)
2.2 模型优化(如何训练)
2.2.1 数据预处理
数据的数量和质量确定了一个模型的性能能够达到的上限,而好的数据预处理是使得算法有效的一个关键组成部分。本次比赛的检测任务标注的数据格式为多边形的顶点坐标,并且单词属性为同一类别的多边形标注在同一个列表中。识别任务的标注为每一个检测框内都有一个单词。我们需要将这些数据中的多边形的标注转化成贝塞尔控制点坐标的标注。这是因为我们所采用的DNTextSpotter模型,只适合贝塞尔控制点的输入格式。并且历史地图的文字多以任意形状的存在,使用贝塞尔曲线的建模方式很好地适应了这种文字形式。最后,在将这些数据输入进模型之前,我们会对数据通过设计的算法进行检查,检查出异常的标注,并将其移除。
2.2.2 数据增强
考虑到竞赛的训练集图片有限(200张),在将图片输入进模型之前,我们采用了随机的旋转(-45度45 度),缩放,裁剪,光照,对比度,饱和度调整的数据增强来增加数据的多样性。其中我们分析了历史地图数据集,发现历史地图都为高分辨率图像,所以我们采用了随机缩放策略,每一步迭代的过程中均从(500,1400, 1500, 1600, 1700, 1800, 1900, 2000) 随机选择最小边的图分辨率,并将最大边的分辨率进行同等比例的缩放。特别地,我们的随机选择中有一个500的最小边,这是考虑到地图数据集中会存在某些字符较大,输入图片为高分辨率时不好识别,所以我们额外添加了 500 为可能选择的最小边。
2.2.3 损失函数的选择
我们采用了Focal Loss来计算检测到的内容是否为文本的二分类损失, CTC Loss [7] 计算识别部分的损失,以及L1 Loss计算坐标的损失。
2.3 混合训练策略
我们除了使用最先进的DNTextSpotter之外,我们只需要非常少的计算资源,2 张显存40g以上显卡即可完成全部的训练内容,并且达到SOTA结果。并且我们在比赛任务上的训练只需要几个小时就可以完成。
首先,我们建立了历史地图数据出现的所有词表的一个新的词表,但是我们并不是从 0 开始训练新的词表构成的端到端的识别框架。我们首先加载了在公开数据集上(使用的是公开数据集的词表)训练的预训练权重。然后冻结住除了词嵌入层和文本预测头的所有参数,使用这些公开的数据集(也包括比赛提供的数据集)在新的词表上重新训练词嵌入层和文本预测头。最后将新训练好的权重全部更新为可学习的参数,加载比赛提供的数据集,训练整个端到端的网络。这种训练策略的调整,相比于从 0 开始训练无疑是大大节省了训练开销,我们未来会进一步对比从 0 开始的训练结果。
2.4 为什么选择DNTextSpotter
现有的研究发现,检测和识别任务具有协同作用,这种协同是指在一个统一的端到端的算法框架中进行检测和识别既可以提升检测性能,也可以提升识别性能。考虑到这一点,我们尝试使用一个既可以做检测任务又可以做识别任务的框架来做检测,以此提升检测的性能。而DNTextSpotter 是目前端到端的检测和识别的SOTA模型之一。除此之外,我们对DNTextSpotter进行可视化研究发现,DNTextSpotter对密集任务和小目标的效果特别好。而历史地图中大多数的目标都是密集且小的文本。
03 比赛结果
3.1 评测方式
本任务评测方式略有不同,对检测框有更严格的指标,以更好评测端到端的真实情况。
3.1.1 检测任务的评估
为了更好地评估 OCR检测任务,比赛使用了 PDQ (Panoptic Detection Quality) 作为最终的竞赛结果。该指标综合考虑了模型检测的紧密度 (T) 和精度 (F 分数)。通过紧密度和 F 分数的乘积,可以确保模型不仅能够正确检测目标,还能保证预测框与真实框的重叠程度较高。
具体计算如下
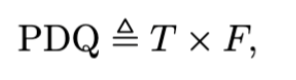
其中,紧密度(T)是所有真正匹配(True Positive, TP)区域中真实值和预测值的平均交并比(IoU)
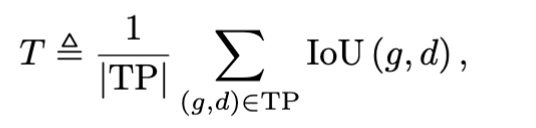
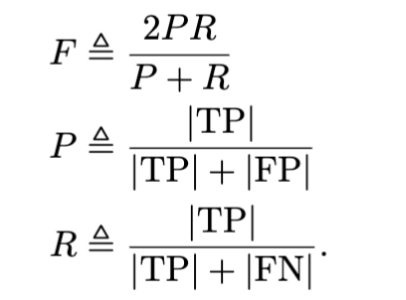
F 分数是精确率(Precision, P)和召回率(Recall, R)之间的调和平均数,用于综合评估检测结果的精确性和覆盖度。
3.1.2 检测和识别任务的评估
比赛中引入了全景词质量Panoptic Word Quality (PWQ)指标,PWQ 有效地将定位精度(紧密度)、检测质量(多边形存在/不存在)和词级别的识别精度结合成一个无参数的度量。PWQ是词级别使用的指标,优先考虑定位良好且文字识别准确的检测结果。这部分指标的计算与检测任务中提到的PDQ类似,在此基础上,真阳性样本除了满足IoU阈值外,还必须有匹配的转录文本。正样本的计算方式如下:
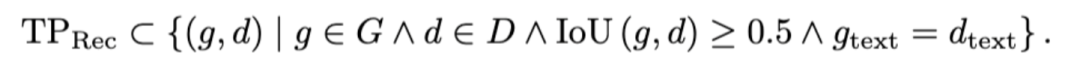
然而,PWQ 仅考虑了词级别的识别精度(且词级别识别非常严格),某些任务可能需要更精细的字符级别评估。因此,为了更好地应对这些复杂任务的需求,比赛中进一步引入了全景字符质量 Panoptic Character Quality (PCQ) 指标 ,PCQ 使用字符级别的编辑距离来衡量识别精度,作为最终的结果评估。PCQ的计算如下:
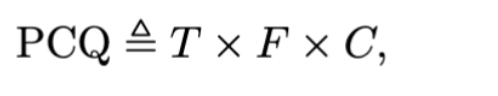
其中,T和F与原始PDQ指标相同(3.1.1小节),C表示在匹配的真阳性检测中,每个词的文本的平均互补归一化编辑距离。其中C 因子的计算如下:
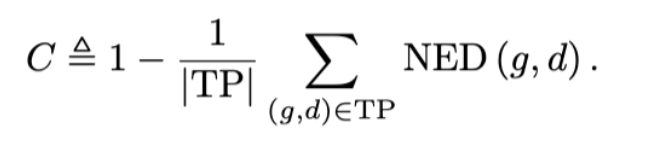
这里 NED 即是检测文本和真实文本之间的标准化编辑距离,用来衡量字符级别的识别精度。
通过结合 T、F 和 C 三个因素,PCQ 能够全面评估模型在定位精度、检测质量和字符级别识别精度上的表现,特别适合需要精确字符级别识别的复杂任务。
3.2 比赛结果数据
通过在多个基准上测试我们的自研方法,在各个基准数据集上都取得了目前最佳的结果。并且,在最新的匿名提交的 ICDAR2024 的历史地图竞赛中,我们也凭借该方法在该赛道的多个任务中获得了第一名(图片中的MapText [Task Name] Strong Pipeline),如最下面的图片所示(考虑到篇幅,我们只截取了前三名的结果)。
1 .检测结果

2.检测链接结果

3.检测和识别结果

4 .检测识别和链接结果

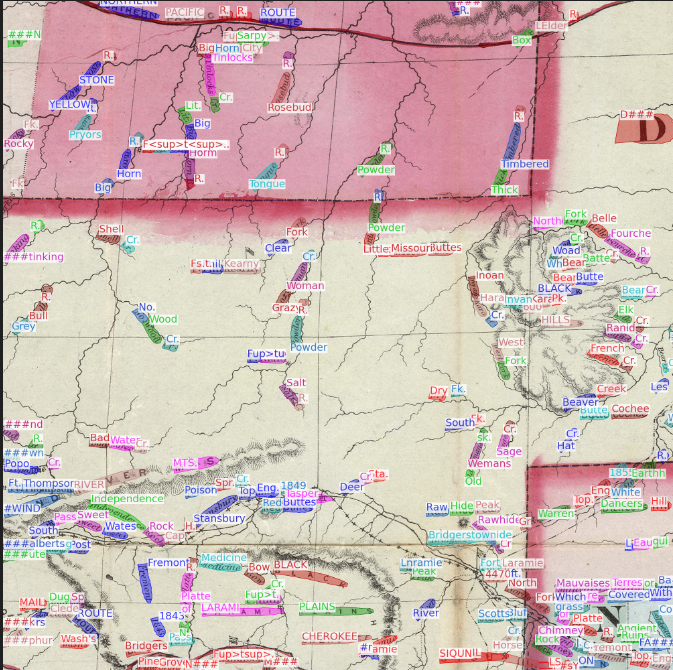
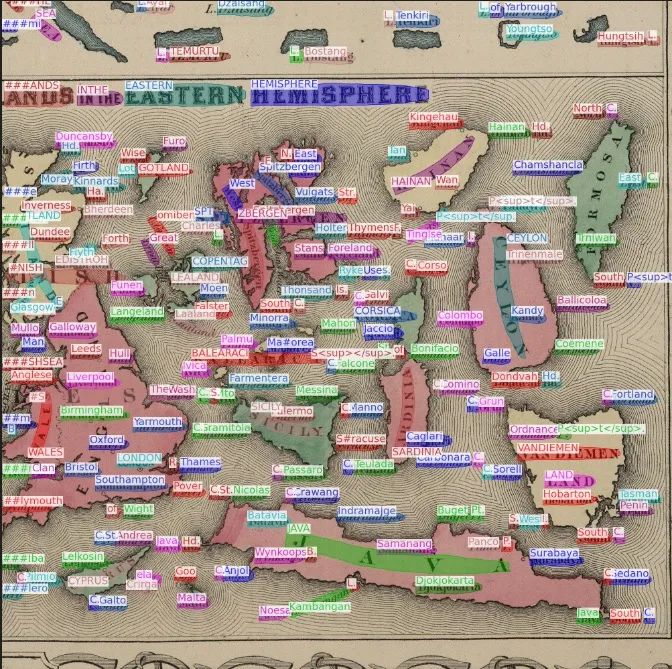
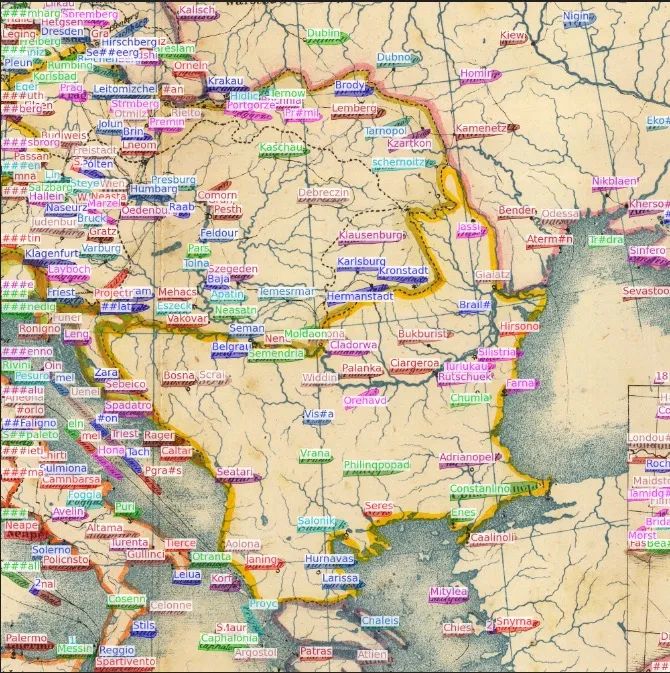
3.3可视化结果样例
我们对比赛中测试集的部分结果进行了图片可视化展示。可以明显看到,即使在文本实例分布极为密集的图片中,我们依然取得了强悍的识别性能。即使有些文字倾斜程度近乎 90 度,我们依然能够识别出来。经过这些可视化结果的分析,我们发现我们的模型可以做到检测并识别出任意形状、极为密集且高度旋转的复杂样本的。
04 业务中应用
1.视频稿件&直播场景中的多文本识别
在视频稿件&直播场景中,检测并识别画面中所有出现的文本实例,尤其是动态变化的复杂场景中,例如路标、内嵌字幕、内嵌弹幕以及用户生成的内容等。即使文本数量庞大、排列复杂、倾斜角度极大,模型依然可以精准识别。视频直播场景中的多文本识别可以辅助实现实时内容监控、摘要生成、以及互动性增强等等。
2.大规模批量视频内容自动画面文本标注
针对成百上千个视频进行批量处理,自动检测并标注每个视频中的文本信息。特别是在涉及复杂字体或特殊排版的情况下,模型能够高效完成任务,从而极大提升视频内容的整理与检索效率。
3.图片中品牌识别和监控
在复杂、多样的背景下,如动态广告牌、运动中的车辆标识或隐蔽在图案中的品牌名,模型能够准确识别这些文本信息。这在广告投放效果分析、品牌保护、版权监控等方面具有显著优势。
4.异形文字检测与识别
此方案不仅可以识别标准的语言的文本,甚至还能处理异形文字(如艺术字体、手写字体等)。这样有助于自动内容安全的保障和更优质的内容理解。
这些场景不仅能展现出此方案在复杂、高强度任务中的出色表现,还能为bilibili平台带来更多创新的应用和商业机会,进一步提升用户体验和平台竞争力。
05 总结与展望
通过本次挑战赛,我们验证了我们使用的模型,以及我们采用的训练策略的有效性。此次竞赛尽管长尾识别问题仍未完全解决,但我们的方法在整体上展示出了良好的性能。我们也将继续优化模型结构和训练策略,特别是在数据增强和迁移学习等方面,以进一步提升对长尾类别的识别能力。展望未来,bilibili人工智能平台部将持续跟进业内最新动态以保持技术的先进性,来更好的服务公司业务团队。最后,关于DNTextSpotter[8]感兴趣的小伙伴们,也可以留意我们之后的推文,我们会对该方法的技术细节进行更详细的阐述。
参考文献
[1] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020, August). End-to-end object detection with transformers. In European conference on computer vision (pp. 213-229). Cham: Springer International Publishing.
[2] Zhang, X., Su, Y., Tripathi, S., & Tu, Z. (2022). Text spotting transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9519-9528).
[3] Ye, M., Zhang, J., Zhao, S., Liu, J., Liu, T., Du, B., & Tao, D. (2023). Deepsolo: Let transformer decoder with explicit points solo for text spotting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 19348-19357).
[4] Li, F., Zhang, H., Liu, S., Guo, J., Ni, L. M., & Zhang, L. (2022). Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13619-13627).
[5] Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., ... & Shum, H. Y. (2022). Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605.
[6] Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988).
[7] Graves, A., Fernández, S., Gomez, F., & Schmidhuber, J. (2006, June). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (pp. 369-376).
[8] Xie, Y., Qiao, Q., Gao, J., Wu, T., Huang, S., Fan, J., ... & Sun, H. (2024). DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training. arXiv preprint arXiv:2408.00355.
-End-
作者丨Jerry酱、seasonxy、道玄















![[含文档+PPT+源码等]精品大数据项目-基于python爬虫实现的大数据岗位的挖掘与分析](https://img-blog.csdnimg.cn/img_convert/bcd835087bdf6be5c5115e4af597adaa.png)