微信公众号:EW Frontier
关注可了解更多的雷达、通信、人工智能相关代码。问题或建议,请公众号留言;
如果你觉得EW Frontier对你有帮助,欢迎加入我的知识星球或面包多,更多代码等你来学
知识星球:https://wx.zsxq.com/dweb2/index/group/15552518881412
面包多:https://mbd.pub/o/author-a2mYl2tsbA==/workQQ交流群:554073254
主要内容

概述
近年来,基于深度学习的目标检测算法在图像领域得到了广泛的探索。在雷达领域,尽管目标检测已经获得了一定程度的普及,但很难找到不同研究之间的系统比较。这是由于几个原因。首先,在相关研究中看到了各种输入和输出格式,例如面向概率的目标检测、深度雷达检测器和基于 CNN 的道路使用者检测。其次,没有合适的公共数据集可以作为该领域研究的基准。因此,研究人员选择构建自己的数据集。在大多数雷达研究中可以找到的一个常见点是它们只针对动态目标,因为对动态目标的检测比静态目标更丰富。
在本文中,我们介绍了一种新的数据集,并提出了一种新的动态道路使用者目标检测模型。我们的贡献如下:
-
介绍了一种新的数据集,其中包含 RAD 表示形式的雷达数据,并为各种对象类别提供了相应的注释。该数据集可在 Google Drive 上找到。
-
提出了一种在 RAD 数据的所有维度上以笛卡尔形式生成真实标签的自动注释方法。
-
提出了一种新的雷达目标检测模型。我们的模型采用了基于 ResNet 的 backbone 。主干网的最终形式是在对雷达数据进行深度学习模型的系统探索后实现的。受 YOLO Head 的启发,我们提出了一种新的双检测头,其中 3D 检测头用于 RAD 数据,2D 检测头用于笛卡尔坐标数据
基于距离-方位-多普勒的雷达数据集
用于数据收集的传感器包括一台德州仪器 (TI) AWR1843-BOOST 雷达和一对来自 The Imaging Source 的 DFK 33UX273 立体相机。下图显示了我们的传感器设置。

两种传感器的配置均如表 I 和表 II 所示。由于我们可以将虚拟天线的数量视为发射器和接收器的数量的组合,因此模数转换器 (ADC) 数据的大小可以计算为 (256, 8, 64)。由于雷达仰角的分辨率有限,我们选择只考虑来自它的二维鸟瞰信息。
对于数据同步,时间戳被手动添加到雷达输出中,以便与摄像机同步。实施是使用机器人操作系统 (ROS) 进行的。我们还在数据采集期间重新校准了两个传感器的记录时间戳。
传感器校准是通过自制的三面体角反射器实现的,如上图所示。为了使角反射器易于相机识别,其正面安装了彩色三角形泡沫板。从立体相机帧到雷达帧的投影矩阵是根据 Calibration 计算的。
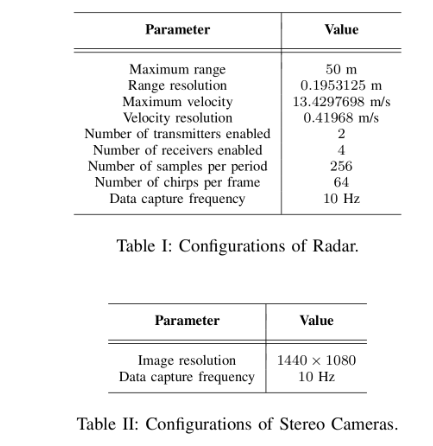
用于调频连续波 (FMCW) 雷达的传统数字信号处理 (DSP) 分为两个步骤。首先,对接收到的模数转换器 (ADC) 信号的每个维度执行快速傅里叶变换 (FFT)。此步骤的主要输出是距离-方位-多普勒 (RAD) 频谱。其次,采用恒定虚警率 (CFAR) 过滤掉噪声信号。有两种主要的 CFAR 算法,即 Cell-Averaging CFAR (CA-CFAR) 和 Order-Statistic (OS-CFAR)。OS-CFAR 由于其高质量的输出通常更适合学术用途,而 CA-CFAR 由于速度而经常在工业中使用。此步骤的输出通常转换为笛卡尔坐标,并以点云的形式呈现,这是各种应用基于集群的雷达数据分析的基础。在我们的数据集中,雷达数据预处理采用 2D OS-CFAR 算法。
在 2D OS-CFAR 的距离多普勒 (RD) 输出上,由于多普勒轴上的速度相干性,可以很容易地检测到刚体,例如车辆。对于人类,Deep Radar Detector 表明,不同身体部位的不同运动可能会导致 RD 光谱上的不同输出模式。然而,当雷达的距离分辨率达到一定水平时,几乎无法观察到人体运动的复杂性。因此,它们也可以被视为刚体。一个例子如下图所示。出现在 RD 光谱上的刚体的一个特性是,尽管物体和雷达之间存在角度差异,但它们通常以线性模式呈现。因此,通过连接 RD 光谱上的离散模式,我们成功地丰富了传统 2D OS-CFAR 的检测率。
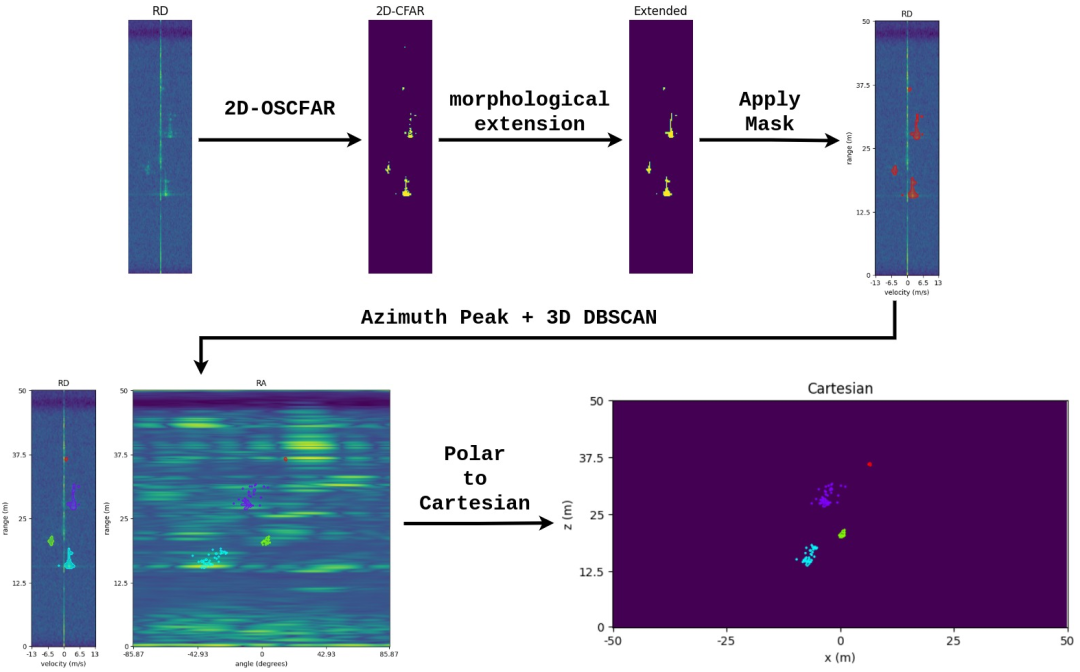
在这项研究中,我们使用立体视觉进行地面实况标记。整个过程可以描述如下。首先,使用 OpenCV 实现立体深度估计以生成视差图。然后,将 Mask-RCNN 用于立体图像,并将预测掩码与类别预测一起应用于相应的视差图。最后,使用三角测量,生成具有预测类别的实例级点云输出。
最后,可以通过匹配雷达实例和上面获得的立体实例来生成数据集。我们的数据集可在 Google Drive 上找到。
RADDet
最先进的基于图像的对象检测算法由 3 个部分组成,一个主干、一个颈部和一个检测头(YOLOv4、FCOS、Focal Loss)。受此启发,我们基于广泛使用的 ResNet 构建了我们的骨干网络。在图像域中,neck 层用于提取多个级别的输出,以处理对象的比例变化。然而,与图像不同的是,距离会因几何图形而改变物体的大小,而雷达则揭示了物体的真实比例。因此,我们的研究中不考虑多分辨率颈部层。最后,我们提出了一种基于知名的基于锚点的算法 YOLO 的新型双检测头。下图显示了我们提议的架构的数据流。
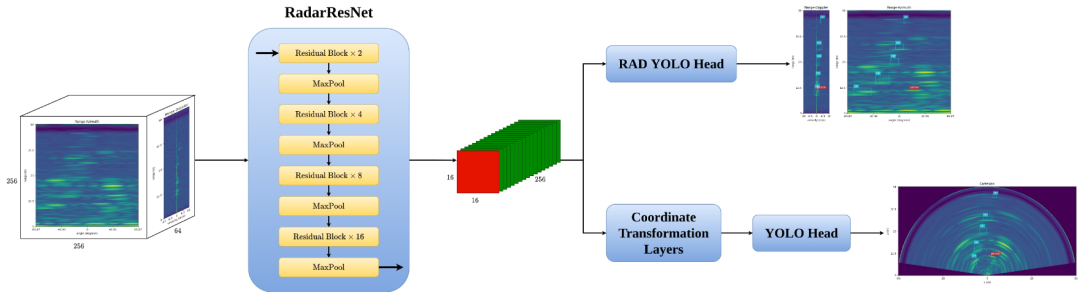
3D 头部将特征图处理成 [16, 16, 4 * num_of_anchors * (7 + num_of_classes)],其中 7 代表对象性和 3D 框信息。3D 框信息由 3D 中心点 [x, y, z] 和大小 [w, h, d] 组成。2D 检测头由两部分组成;一个坐标转换层,用于将特征图从极坐标表示转换为笛卡尔形式,以及一个经典的 YOLO Head。
测试
为了直观地检查模型的性能,我们通过测试集运行了模型,并将预测框与真实框进行了比较。下图显示了一些可视化示例。我们真诚地希望这项研究和数据集能够弥合基于图像的目标检测和基于雷达的目标检测之间的差距,并激发更多自主雷达算法的开发。

数据集网址:需梯子
https://drive.google.com/drive/folders/1v-AF873jP8p6waChF3pSSqz6HXOOZgkC


















