数据集介绍
数据集采用了Kaggle实战数据集,链接如下,如有需要可自行下载
https://www.kaggle.com/datasets/atefehmirnaseri/cell-phone-price/data
数据集简要介绍
• battery_power:电池的总能量存储(毫安时)
• blue:设备是否有蓝牙功能,1 表示有,0 表示没有
• clock_speed:微处理器执行指令的速度
• dual_sim:设备是否支持同时使用两张 SIM 卡
• fc:前置摄像头的质量(以百万像素为单位)
• four_g:设备是否支持 4G 网络
• int_memory:设备的内部存储容量(以 GB 为单位)
• m_dep:设备的厚度(以厘米为单位)
• mobile_wt:设备的重量
• n_cores:处理器的核心数量
• pc:主摄像头的质量(以百万像素为单位)
• px_height:像素分辨率的高度
• px_width:像素分辨率的宽度
• ram:随机存取存储器的容量(以 MB 为单位)
• sc_h:设备屏幕的高度(以厘米为单位)
• sc_w:设备屏幕的宽度(以厘米为单位)
• talk_time:设备满电时支持的最长通话时间
• three_g:设备是否支持 3G 网络
• touch_screen:设备是否有触摸屏
• wifi:设备是否有 WiFi 功能
• price_range:设备的价格分类
其中要预测的标签值为price_range,价格范围为四分类,标签值为0,1,2,3
代码开源地址
由于Kaggle数据集并未提供测试集数据的标签值,所以本篇博客为基于其训练集数据集进行划分训练测试训练的样例讲解.
Kaggle代码地址
Phone Price Prediction MLP | Kaggle
这是我于该数据集下发布的notebook链接,里面使用本篇博客要介绍的四种测试模型中的多层感知机+层归一化+Dropout正则+leaky relu激活的模型版本,但是其在训练集上的表现并不是最好的,其中有包括数据集信息提取和特征关系矩阵的提取和可视化.
Github开源地址
https://github.com/Foxbabe1q/Cell-Phone-Price-Prediction-using-MLP
这是我样例代码的Github仓库链接,其中包含了完整的4个模型的代码,模型二进制文件,以及损失和准确率变化图,但是由于官方并没有提供测试集标签,所以这里使用训练集进行划分后训练测试,具体的四个模型的建模方式在本篇博客进行讲解
Gitee码云开源地址
深度学习_手机价格预测数据集 Cell Phone Price Prediction using MLP: 使用多层感知机对手机价格数据集进行价格预测,数据集为Kaggle开源数据集,链接如下https://www.kaggle.com/datasets/atefehmirnaseri/cell-phone-price/data
与Github仓库中的内容相同
多层感知机建模详解
6层MLP加上sigmoid激活
class SimpleNet(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 256)
self.fc3 = nn.Linear(256, 512)
self.fc4 = nn.Linear(512, 256)
self.fc5 = nn.Linear(256, 128)
self.fc6 = nn.Linear(128, output_size)
def forward(self, x):
x = F.sigmoid(self.fc1(x))
x = F.sigmoid(self.fc2(x))
x = F.sigmoid(self.fc3(x))
x = F.sigmoid(self.fc4(x))
x = F.sigmoid(self.fc5(x))
x = self.fc6(x)
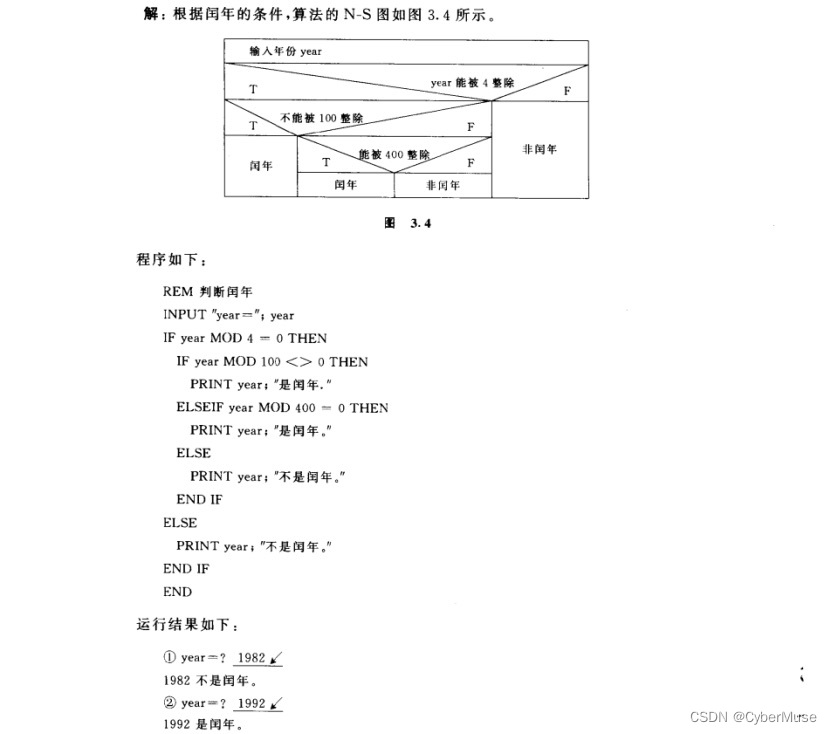
return x这里使用了简单的6层全连接层,选用了Sigmoid激活,这里由于模型层数较深,容易造成过拟合的现象,但实际表现却是最好的,测试集准确率达到了百分之97
6层MLP加上层归一化,sigmoid激活,xavier参数初始化
class SimpleNet(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.bn1 = nn.BatchNorm1d(num_features=128)
self.dropout1 = nn.Dropout(0.2)
self.fc2 = nn.Linear(128, 256)
self.bn2 = nn.BatchNorm1d(num_features=256)
self.dropout2 = nn.Dropout(0.2)
self.fc3 = nn.Linear(256, 512)
self.bn3 = nn.BatchNorm1d(num_features=512)
self.dropout3 = nn.Dropout(0.2)
self.fc4 = nn.Linear(512, 256)
self.bn4 = nn.BatchNorm1d(num_features=256)
self.dropout4 = nn.Dropout(0.2)
self.fc5 = nn.Linear(256, 128)
self.bn5 = nn.BatchNorm1d(num_features=128)
self.dropout5 = nn.Dropout(0.2)
self.fc6 = nn.Linear(128, output_size)
self.initialize_weights()
def initialize_weights(self):
nn.init.xavier_normal_(self.fc1.weight)
nn.init.xavier_normal_(self.fc2.weight)
nn.init.xavier_normal_(self.fc3.weight)
nn.init.xavier_normal_(self.fc4.weight)
nn.init.xavier_normal_(self.fc5.weight)
nn.init.xavier_normal_(self.fc6.weight)
def forward(self, x):
x = F.sigmoid(self.fc1(x))
x = self.bn1(x)
x = self.dropout1(x)
x = F.sigmoid(self.fc2(x))
x = self.bn2(x)
x = self.dropout2(x)
x = F.sigmoid(self.fc3(x))
x = self.bn3(x)
x = self.dropout3(x)
x = F.sigmoid(self.fc4(x))
x = self.bn4(x)
x = self.dropout4(x)
x = F.sigmoid(self.fc5(x))
x = self.bn5(x)
x = self.dropout5(x)
x = self.fc6(x)
return x这里为了防止模型过拟合添加了Dropout正则,神经元失活比例为0.2,并且在每层后都添加了可学习的层归一化,由于使用了sigmoid激活,所以选用了较为适合这种激活方式的xavier参数初始化,最后的在测试集上的准确率达到了百分之87
6层MLP加上ReLU激活,kaiming参数初始化
class SimpleNet(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.bn1 = nn.BatchNorm1d(num_features=128)
self.dropout1 = nn.Dropout(0.2)
self.fc2 = nn.Linear(128, 256)
self.bn2 = nn.BatchNorm1d(num_features=256)
self.dropout2 = nn.Dropout(0.2)
self.fc3 = nn.Linear(256, 512)
self.bn3 = nn.BatchNorm1d(num_features=512)
self.dropout3 = nn.Dropout(0.2)
self.fc4 = nn.Linear(512, 256)
self.bn4 = nn.BatchNorm1d(num_features=256)
self.dropout4 = nn.Dropout(0.2)
self.fc5 = nn.Linear(256, 128)
self.bn5 = nn.BatchNorm1d(num_features=128)
self.dropout5 = nn.Dropout(0.2)
self.fc6 = nn.Linear(128, output_size)
self.initialize_weights()
def initialize_weights(self):
nn.init.kaiming_normal_(self.fc1.weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.fc2.weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.fc3.weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.fc4.weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.fc5.weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.fc6.weight, nonlinearity='relu')
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.bn2(x)
x = self.dropout2(x)
x = F.relu(self.fc3(x))
x = self.bn3(x)
x = self.dropout3(x)
x = F.relu(self.fc4(x))
x = self.bn4(x)
x = self.dropout4(x)
x = F.relu(self.fc5(x))
x = self.bn5(x)
x = self.dropout5(x)
x = self.fc6(x)
return x在与上一个模型选用了相同的Dropout正则和层归一化方式后,将激活方式换为了ReLU,并将参数初始化方式换位了适合ReLU的kaiming参数初始化,最后在测试集上的准确率达到了百分之83
6层MLP加上Leaky ReLU激活,kaiming参数初始化
class SimpleNet(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.bn1 = nn.BatchNorm1d(num_features=128)
self.dropout1 = nn.Dropout(0.2)
self.fc2 = nn.Linear(128, 256)
self.bn2 = nn.BatchNorm1d(num_features=256)
self.dropout2 = nn.Dropout(0.2)
self.fc3 = nn.Linear(256, 512)
self.bn3 = nn.BatchNorm1d(num_features=512)
self.dropout3 = nn.Dropout(0.2)
self.fc4 = nn.Linear(512, 256)
self.bn4 = nn.BatchNorm1d(num_features=256)
self.dropout4 = nn.Dropout(0.2)
self.fc5 = nn.Linear(256, 128)
self.bn5 = nn.BatchNorm1d(num_features=128)
self.dropout5 = nn.Dropout(0.2)
self.fc6 = nn.Linear(128, output_size)
self.initialize_weights()
def initialize_weights(self):
nn.init.kaiming_normal_(self.fc1.weight, nonlinearity='leaky_relu')
nn.init.kaiming_normal_(self.fc2.weight, nonlinearity='leaky_relu')
nn.init.kaiming_normal_(self.fc3.weight, nonlinearity='leaky_relu')
nn.init.kaiming_normal_(self.fc4.weight, nonlinearity='leaky_relu')
nn.init.kaiming_normal_(self.fc5.weight, nonlinearity='leaky_relu')
nn.init.kaiming_normal_(self.fc6.weight, nonlinearity='leaky_relu')
def forward(self, x):
x = F.leaky_relu(self.fc1(x))
x = self.bn1(x)
x = self.dropout1(x)
x = F.leaky_relu(self.fc2(x))
x = self.bn2(x)
x = self.dropout2(x)
x = F.leaky_relu(self.fc3(x))
x = self.bn3(x)
x = self.dropout3(x)
x = F.leaky_relu(self.fc4(x))
x = self.bn4(x)
x = self.dropout4(x)
x = F.leaky_relu(self.fc5(x))
x = self.bn5(x)
x = self.dropout5(x)
x = self.fc6(x)
return x这里与上一个模型的唯一区别为将ReLU换为了Leaky ReLU,最后在测试集上的准确率也达到了百分之83
训练机制
def train():
torch.manual_seed(0)
train_dataset, test_dataset, input_dim, output_dim = create_dataset()
model = SimpleNet(input_size=input_dim, output_size=output_dim).to(device)
optimizer = optim.Adam(params=model.parameters(),lr=0.0001)
criterion = nn.CrossEntropyLoss()
epochs = 50
loss_list = []
acc_list = []
start_time = time.time()
for epoch in range(epochs):
dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
total_loss = 0.0
num = 0
start_time = time.time()
total_correct = 0
for x, y in dataloader:
output = model(x)
optimizer.zero_grad()
loss = criterion(output, y)
loss.backward()
optimizer.step()
total_loss += loss.item()*len(y)
total_correct += (torch.argmax(output, dim=1)==y).sum().item()
num += len(y)
loss_list.append(total_loss)
acc_list.append(total_correct/num)
print("epoch:%d, loss:%.2f, time:%.2f" %(epoch+1,total_loss/num,time.time()-start_time))
torch.save(model.state_dict(), 'model1.pt')
fig = plt.figure(figsize=(6,4))
axes1 = plt.subplot(1,2,1)
axes2 = plt.subplot(1,2,2)
axes1.plot(np.arange(1,epochs+1),loss_list)
axes1.grid()
axes1.set_title('loss')
axes1.set_xlabel('epoch')
axes1.set_ylabel('loss')
axes2.plot(np.arange(1,epochs+1),acc_list)
axes2.grid()
axes2.set_title('accuracy')
axes2.set_xlabel('epoch')
axes2.set_ylabel('accuracy')
fig.savefig('loss_acc1.png')
plt.show()在模型超参数设置上,选用Adam优化器,学习率设置为0.0001,epoch次数为50,batch_size为64
在选用不同模型的时候只需更改实例化的类即可,并且所有数据集在加载的时候已经经过了标准化
模型的效果可视化
6层MLP加上sigmoid激活


6层MLP加上层归一化,sigmoid激活,xavier参数初始化

6层MLP加上ReLU激活,kaiming参数初始化

6层MLP加上Leaky ReLU激活,kaiming参数初始化