构建 10 万卡 GPU 集群的技术挑战
摘要
揭示AI训练集群关键基础设施挑战,探讨突破现有AI瓶颈的必要性与10万GPU集群(如OpenAI、Meta)建设所面临挑战与需求。
- 构建网络拓扑,需权衡多层交换机成本、带宽与维护。本文对比Ethernet与InfiniBand,探讨机架优化,助您明智选择。
- 并行计算 - 介绍了数据并行、张量并行和管线并行,以及如何结合使用。
- 深入剖析:揭示InfiniBand、Spectrum-X Ethernet与Broadcom Tomahawk 5等方案的成本对比,助您明智选择。
自 GPT-4 发布以来,AI 能力停滞不前。一般来说,这种观点是正确的,但原因在于还没有人能够大规模地增加单个模型的计算量。每个发布的模型的训练计算量大致在 GPT-4 的水平(约 2e25 FLOP 训练计算量)。这是因为用于这些模型的训练计算量也大致相同。以 Google 的 Gemini Ultra、Nvidia 的 Nemotron 340B 和 Meta 的 LLAMA 3 405B 为例,它们的 FLOPS 甚至比 GPT-4 更高,但由于架构劣势,这些模型未能解锁新能力。
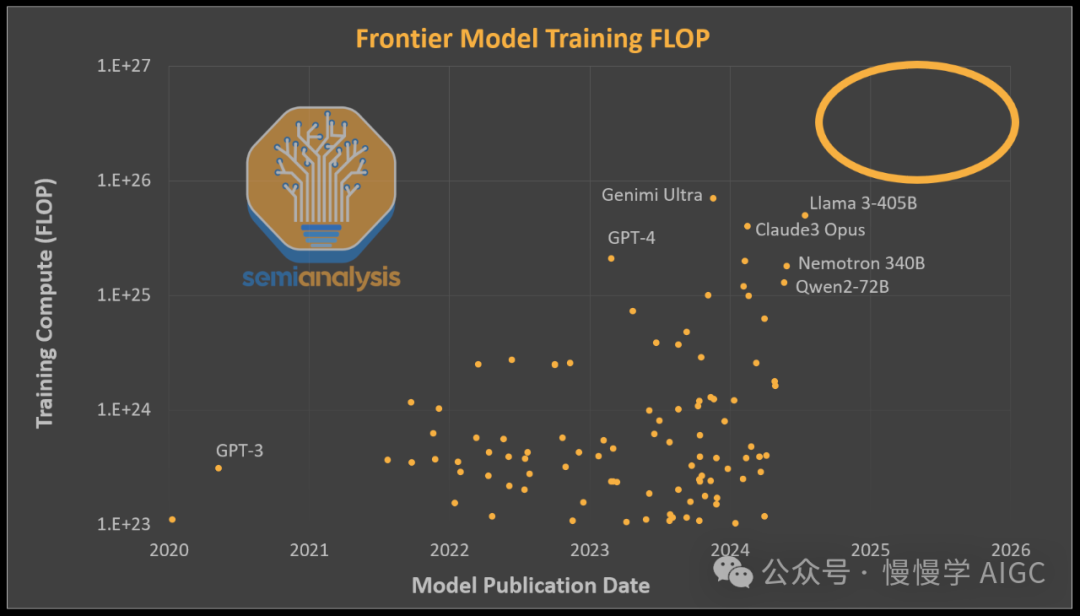
OpenAI扩大计算资源,专注于打造更小、更经济高效的推理模型如GPT-4 Turbo和GPT-4o。虽起步晚,现已开启下一层级模型训练。
AI迈向新里程碑:万亿参数多模态变换器横空出世,视频、图像、音频、文本尽收眼底。尚未有人攻克,竞争激烈,未来可期!
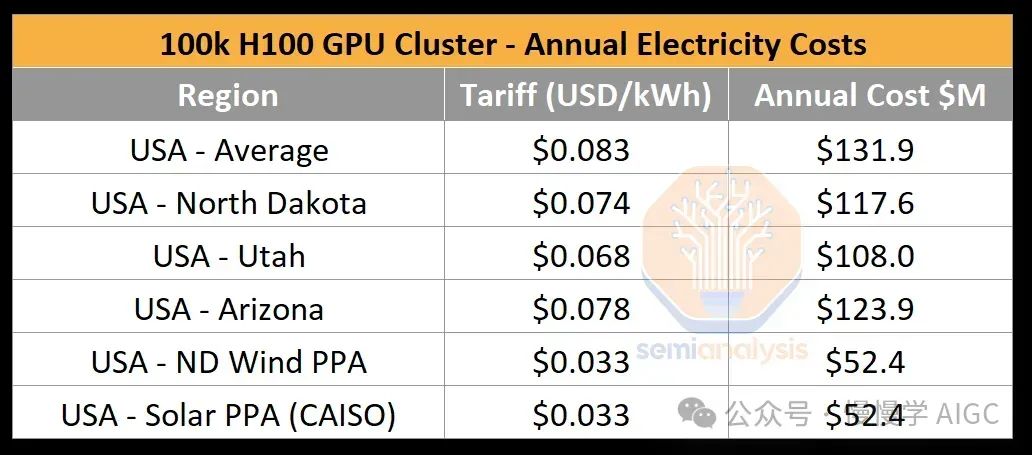
多个大型 AI 实验室,包括但不限于 OpenAI/Microsoft、xAI 和 Meta,正在竞相建立超过 10 万个 GPU 的集群。这些单个训练集群的服务器资本支出成本超过 40 亿美元,但由于 GPU 通常需要共址以进行高速芯片到芯片的网络连接,它们还受到数据中心容量和电力不足的严重限制。一个 10 万 GPU 的集群需要超过 150MW 的数据中心容量,并在一年内消耗 1.59 太瓦时的电力,按照标准费率 $0.078/kWh 计算,成本为 1.239 亿美元。
今天我们将深入探讨大型训练 AI 集群及其周围的基础设施。构建这些集群远比单纯投入金钱复杂得多。实现高利用率更为困难,因为各种组件的高故障率,尤其是网络故障。我们还将介绍电力挑战、可靠性、检查点、网络拓扑选项、并行方案、机架布局和这些系统的总物料清单。
超过一年前,我们报道了 Nvidia 的 InfiniBand 问题,导致一些公司选择 Spectrum-X 以太网而非 InfiniBand。我们还将介绍 Spectrum-X 的主要缺陷,导致超大规模用户选择 Broadcom 的 Tomahawk 5。
为了说明 10 万 GPU 集群能提供多少计算能力,OpenAI 为 GPT-4 的训练 BF16 FLOPS 为约 2.15e25 FLOP(2150 万 ExaFLOP),使用约 2 万个 A100 进行了 90 到 100 天的训练。该集群的峰值吞吐量为 6.28 BF16 ExaFLOP/秒。在一个 10 万 H100 集群上,这个数字将飙升至 198/99 FP8/FP16 ExaFLOP/秒。这是相对于 2 万 A100 集群的峰值理论 AI 训练 FLOPs 增加了 31.5 倍。
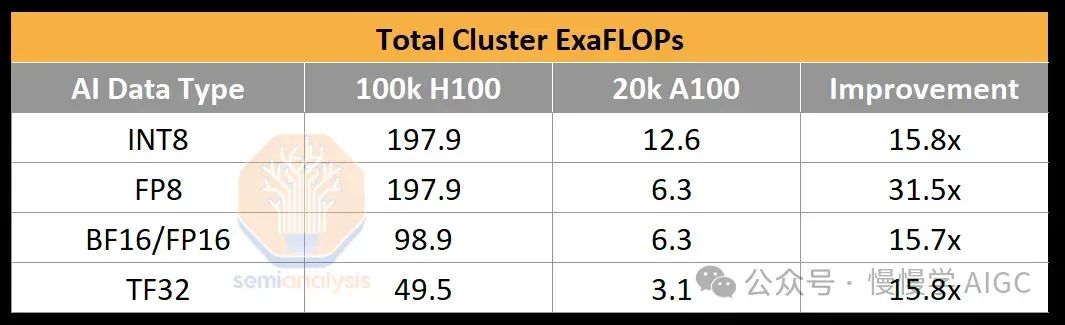
在 H100 上,AI 实验室在万亿参数训练运行中达到了高达 35% 的 FP8 模型 FLOPs 利用率(MFU)和 40% 的 FP16 MFU。回顾一下,MFU 是在考虑到开销和各种瓶颈(如功率限制、通信不稳定、重新计算、滞后和低效内核)后,峰值潜在 FLOPS 的有效吞吐量和利用率的衡量标准。使用 FP8,10 万 H100 集群只需四天即可训练 GPT-4。在一个 10 万 H100 集群上进行 100 天的训练运行,可以达到大约 6e26 的有效 FP8 模型 FLOP(600 万 ExaFLOP)。请注意,硬件的低可靠性显著降低了 MFU。
电力挑战
10 万 H100 集群所需的关键 IT 电力约为 150MW。虽然 GPU 本身只有 700W,但在每个 H100 服务器中,CPU、网络接口卡(NIC)、电源模块(PSU)每个 GPU 还需要额外约 575W。除了 H100 服务器外,AI 集群还需要一系列存储服务器、网络交换机、CPU 节点、光学收发器等项目,总共占 IT 电力的 10%。对比而言,最大的国家实验室超算 El Capitan 只需 30MW 的关键 IT 电力。政府的超级计算机与行业相比相形见绌。
现有数据中心无力承载约150MW的新部署需求。提及10万GPU集群,通常指校园内多个建筑,而非单一建筑。X.AI不得已在田纳西孟菲斯改造旧厂为数据中心,以应对电力挑战。
光学收发器网络连接成本随覆盖范围递增。长距单模DR/FR收发器可靠传输达500米至2公里,成本却是多模SR/AOC收发器的2.5倍。校园级相干800G收发器覆盖超2公里,成本更是多模收发器的10倍以上。
H100集群,每个GPU高达400G连接速度,通过简洁的交换机结构实现高效协同。大型集群则需多层交换机,光学器件成本高。网络拓扑因供应商、工作负载和资本支出而多样化。
每栋楼配备一个或多个计算单元,以铜线或多模收发器连接。长距离收发器实现“岛屿”间互联。尽管155MW难以集中供应,但我们正关注超过15个数据中心建设,如Microsoft、Meta、Google等,它们将为AI服务器与网络设备提供充足空间。
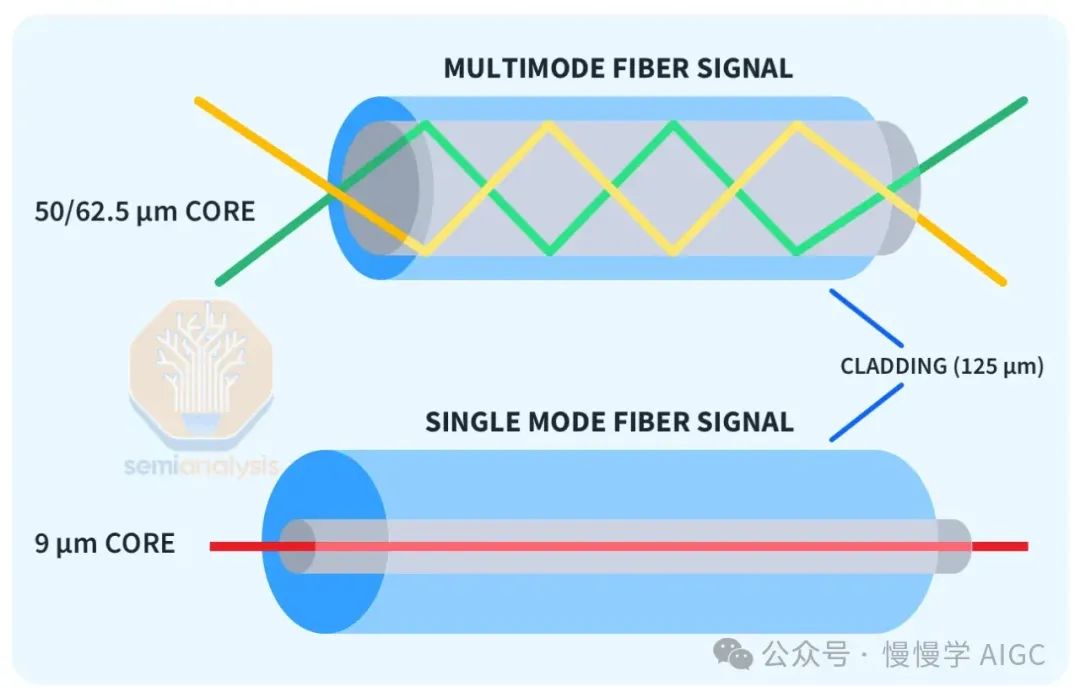
客户依据数据传输、成本、维护、电力及负载需求,选择不同网络拓扑。如Tomahawk 5交换机、InfiniBand和NVIDIA Spectrum-X。本文将揭示其背后的决策动因。
回顾并行性
深入解析网络设计三大并行性:数据、张量、流水线,理解其拓扑、可靠性及检查点策略。详尽解释,助您掌握万亿参数训练核心!
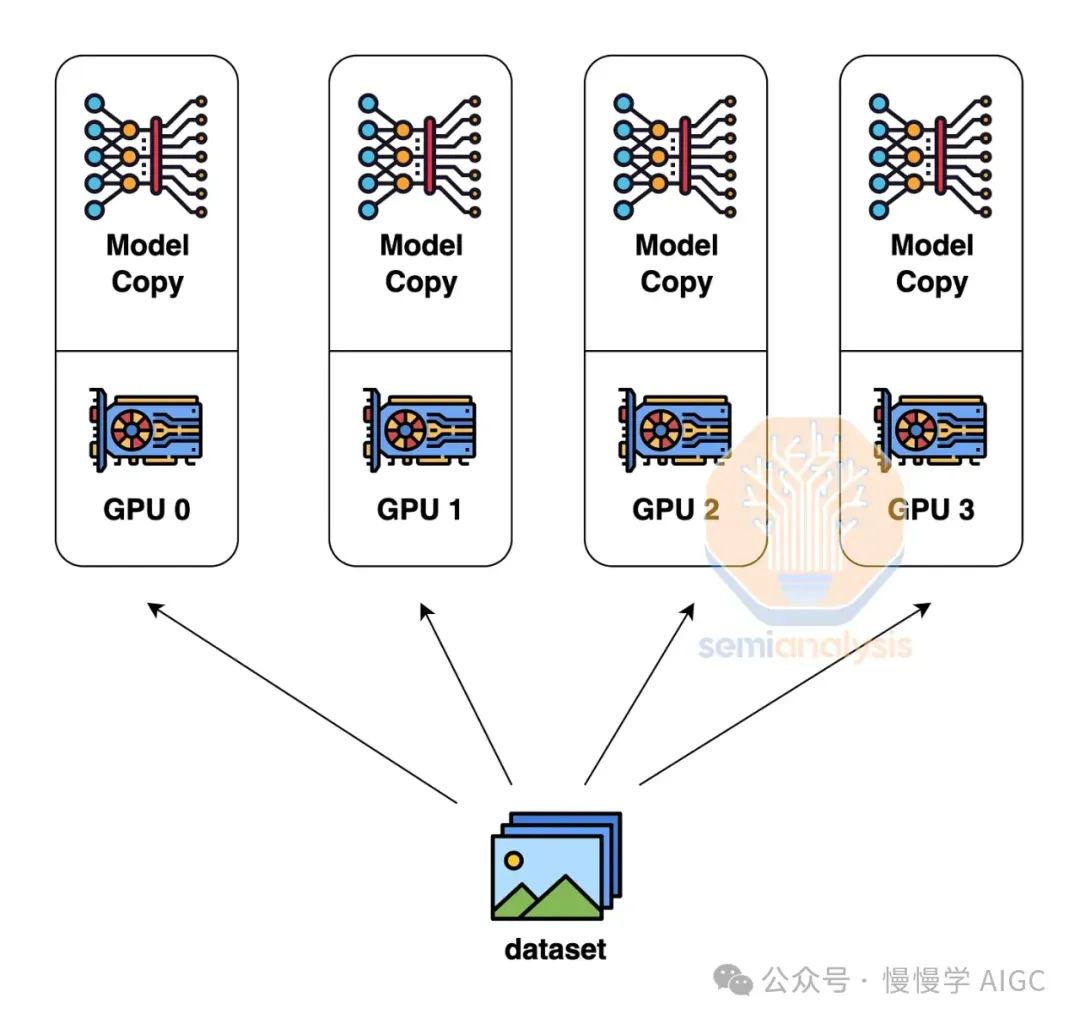
数据并行性,即每个GPU持有模型权重副本,处理不同数据子集,通信量最低,仅需求和梯度。然而,其局限性在于,仅当每个GPU内存足够存储整个模型权重、激活和优化器状态时才有效。例如,训练GPT-4等高达1.8万亿参数的模型,可能需10.8TB内存。
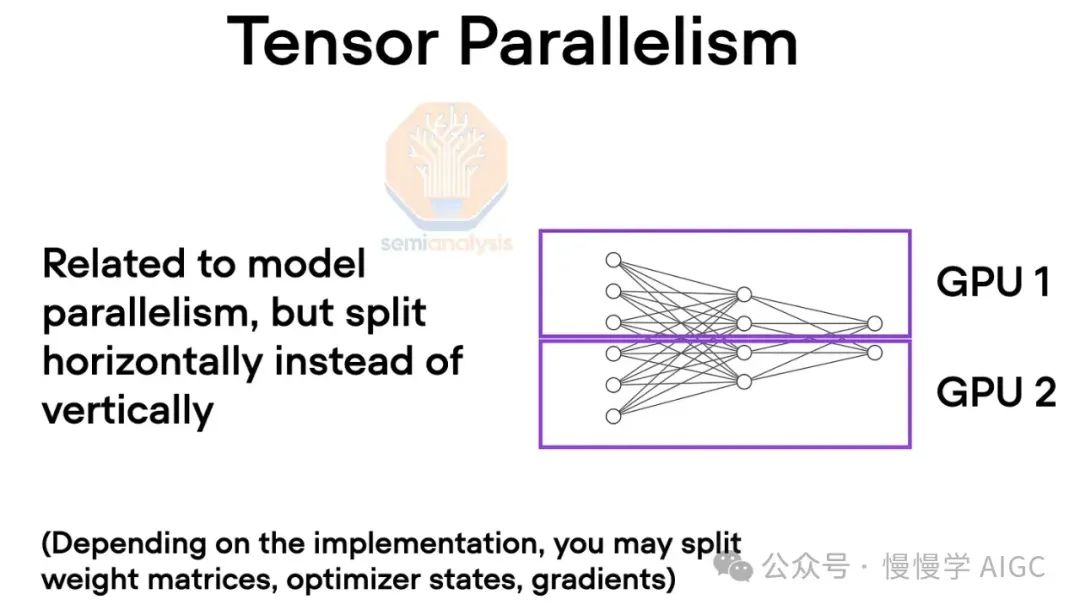
为了克服这些内存限制,使用张量并行性。在张量并行性中,每层的工作和模型权重分布在多个 GPU 上,通常跨隐藏维度分布。通过多次在每层的自注意、前馈网络和层归一化之间的全规约交换中间工作。
需要高带宽,特别是非常低的延迟。实际上,域内的每个 GPU 像一个巨大的 GPU 一样在每层上协同工作。张量并行性按张量并行性等级数量减少每个 GPU 使用的总内存。例如,今天通常使用 8 个张量并行性等级在 NVLink 上,因此这将使每个 GPU 的使用内存减少 8 倍。
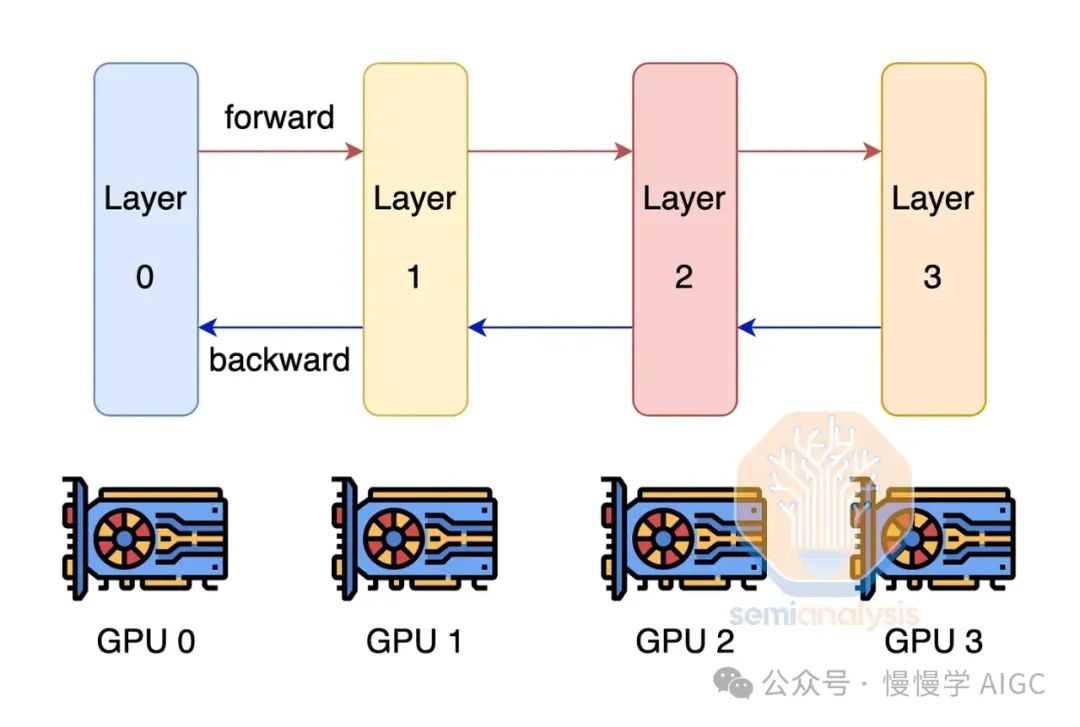
突破GPU内存极限,流水线并行技术应运而生。此法将模型分层计算,每GPU分担部分任务,输出接力至下一GPU,大幅降低内存需求。虽然通信量较高,但仍轻于张量并行,效率显著。
为提升模型FLOP利用率,我们融合张量、流水线与数据并行性,构建3D并行架构。在H100服务器内,张量并行贯穿,岛内节点以流水线并行协作,岛间则依托数据并行,优化通信效率。
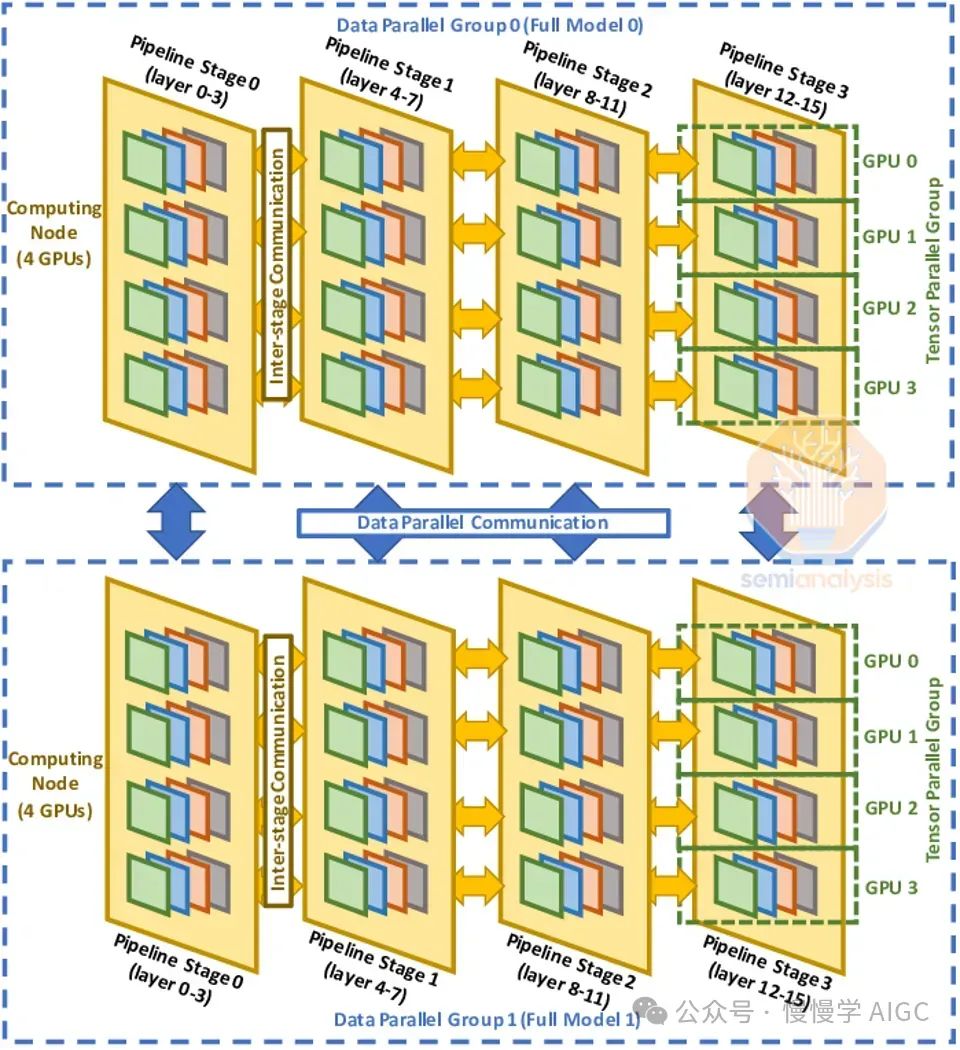
网络设计考虑因素
网络架构基于并行设计。若每个GPU以最大带宽连接至其他所有GPU,将需四层交换机,成本高昂,且每层额外网络需光学设备,导致光学器件成本激增。
大型GPU集群不采用全树架构,转而构建计算岛,岛间带宽较小。普遍采用“超额订阅”策略,如Meta的前代架构,含32,000 GPU,8个岛间全带宽,顶层7:1超额订阅,岛间网络速度仅岛内1/7。
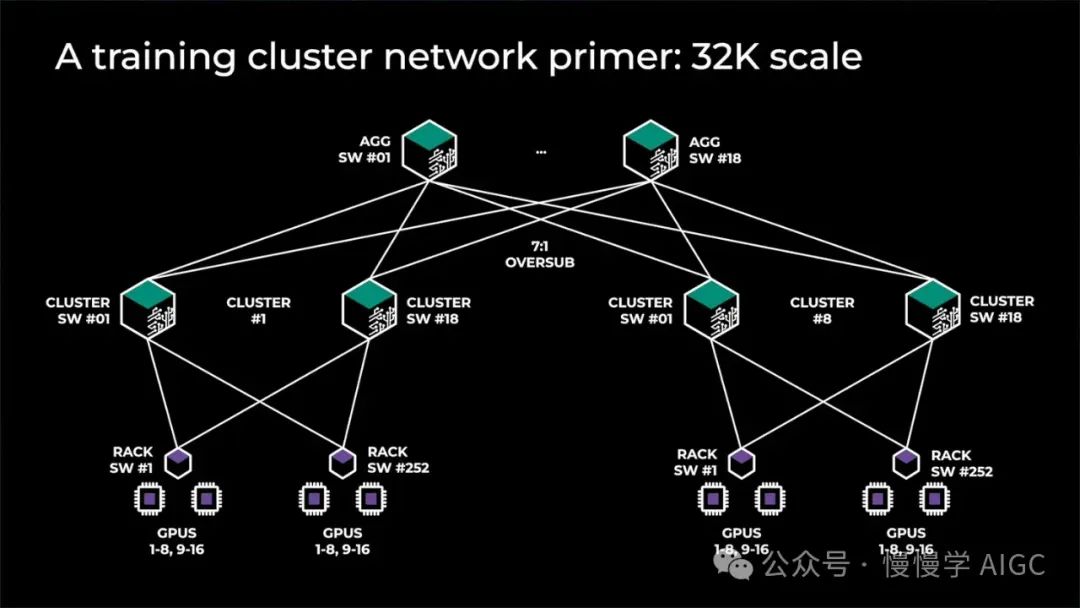
在GPU部署中,前端、后端及NVLink扩展网络各司其职。NVLink网络独步快速,胜任张量并行带宽需求。后端网络高效处理多数并行任务,但超额订阅下,仅限数据并行。
混合 InfiniBand 和前端以太网结构
这家公司巧妙运用前端以太网在InfiniBand岛屿间训练,成本更低,依托现有数据中心网络,实现高效扩展。
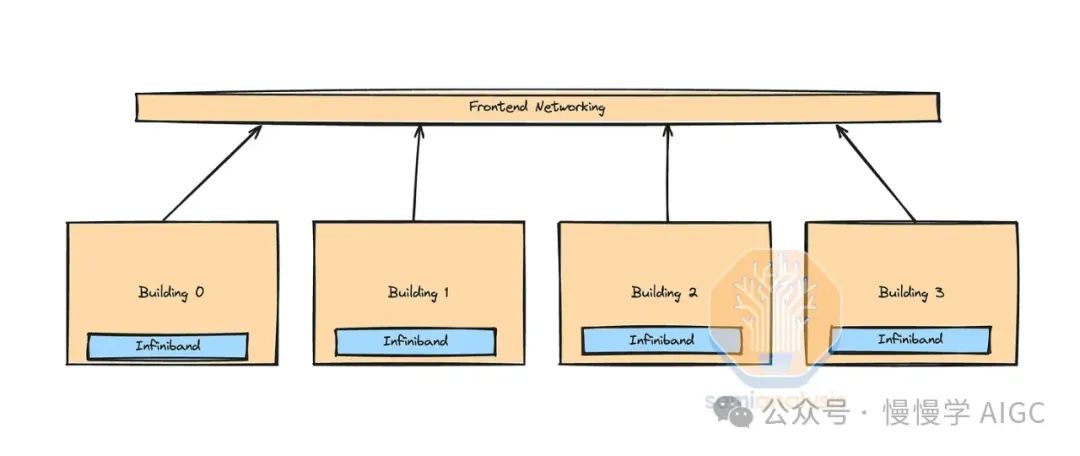
随着MoE等稀疏技术模型尺寸激增,前端网络通信量同步攀升。精妙优化权衡至关重要,否则带宽激增将令成本与后端带宽齐飞。
Google的多TPU pod训练全靠前端网络驱动,其“计算结构”ICI,最大可扩展至8960个芯片,通过昂贵的800G光交换机连接TPU水冷机架。为超越GPU,Google精心打造了更强大的TPU前端网络。
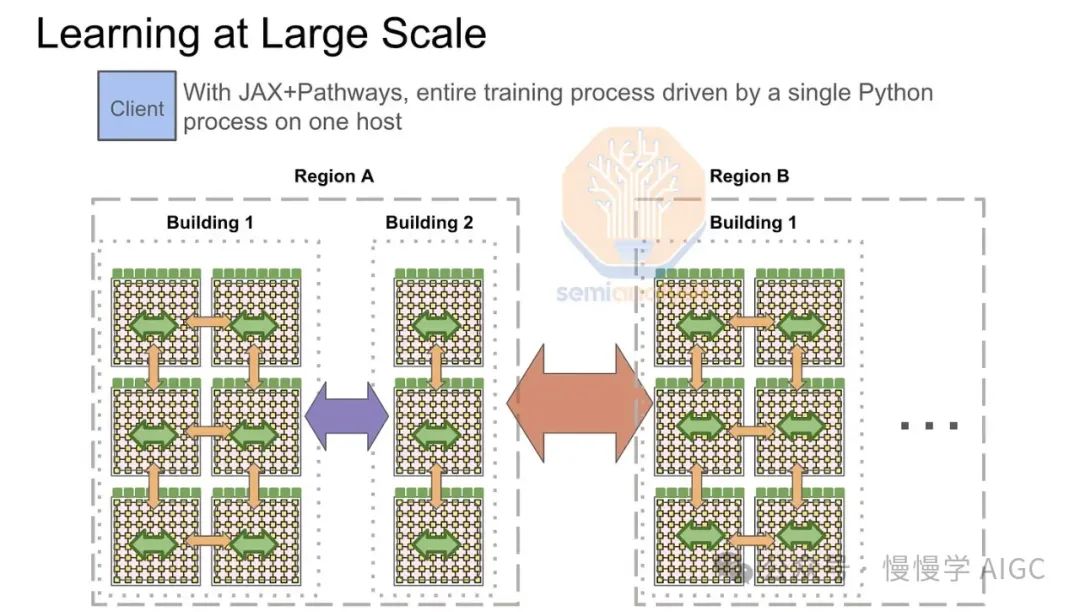
训练期间,前端网络操作需进行岛间拓扑感知的全规约。每pod在InfiniBand或ICI网络内完成本地规约散射,汇总GPU/TPU梯度子部分。随后,通过前端以太网网络在主机等级间进行跨pod all reduce,最终实现每个pod的pod级别全规约。
随着多模态数据激增,前端网络带宽面临挑战。加载大型视频与all-reduce竞争,流量不规律加剧滞后,影响建模速度与可预测性。
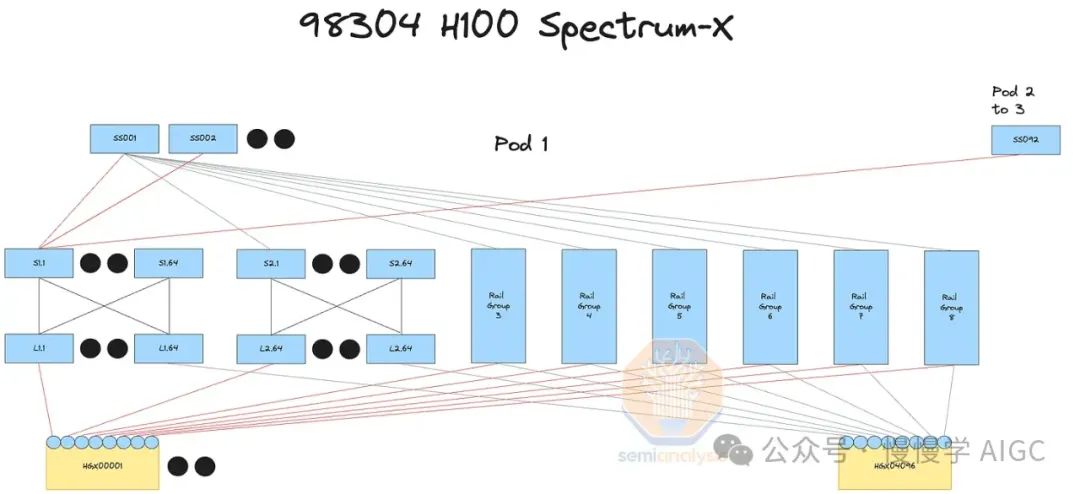
四层InfiniBand网络,7:1超额订阅,每Pod搭载24,576个H100,非阻塞三层系统。相比前端网络,升级光纤收发器更易增加带宽,轻松应对未来需求。
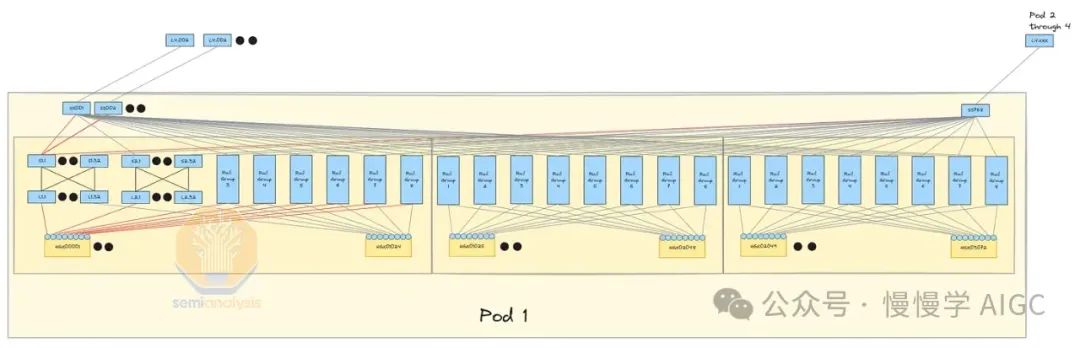
打造稳定网络新格局,前端聚焦数据加载,后端专注GPU通信,有效缓解延迟。然四层InfiniBand网络高昂成本,需额外交换机和收发器支持。
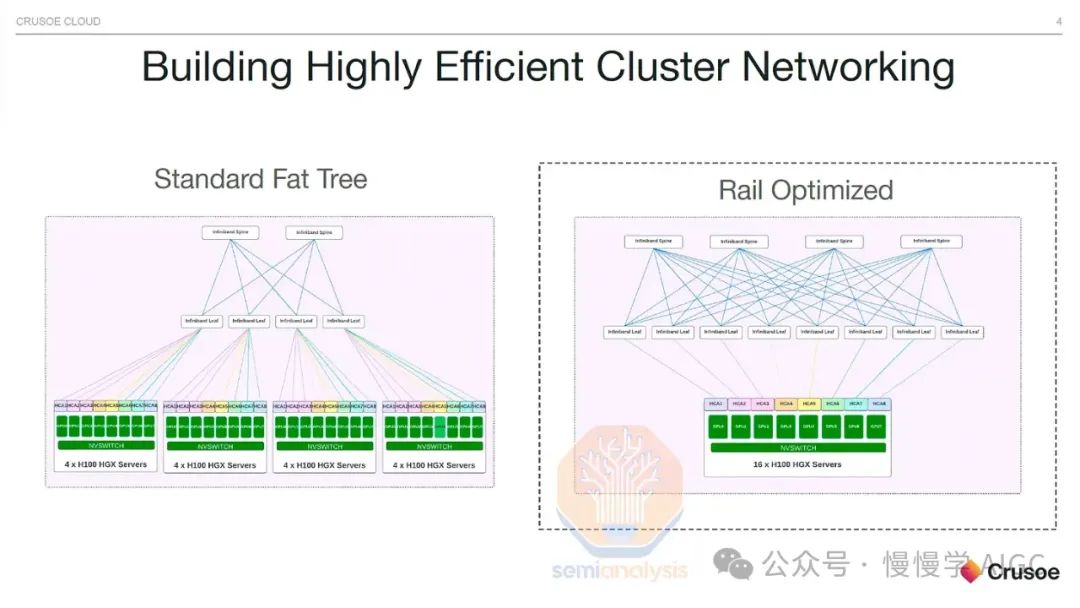
轨道优化 vs 机架中部
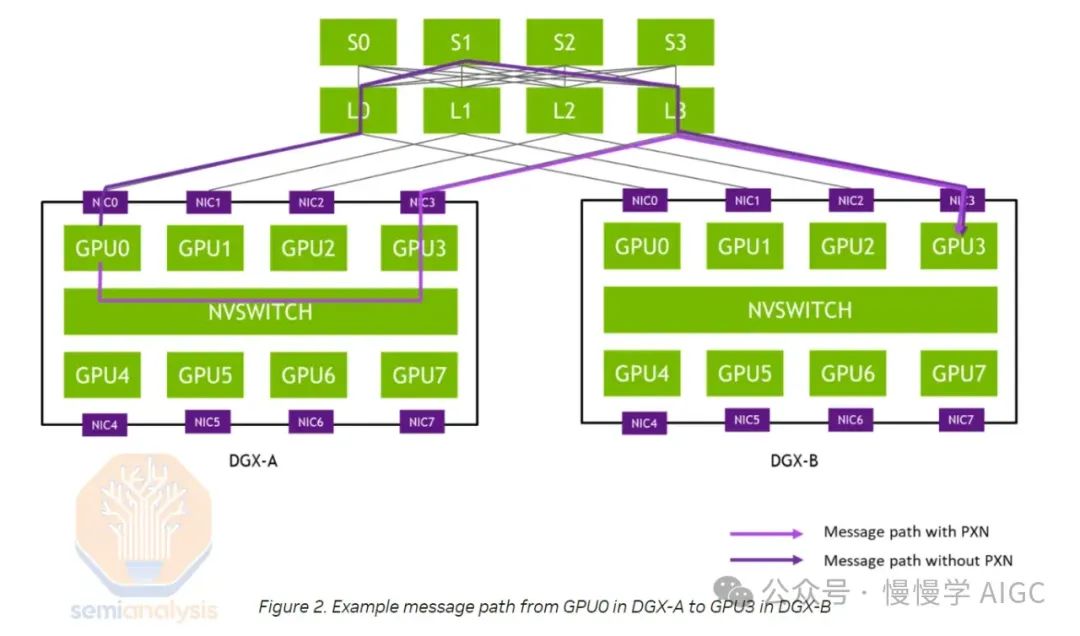
轨道优化技术让H100服务器直接连接8个叶交换机,实现GPU间单跳通信,显著提升all2all集体通信效率。此技术广泛应用于混合专家模型(MoE)的专家并行计算。
轨道优化设计虽高效,却面临挑战:叶交换机分布较散,需借助光学设备,叶脊间最长距离超50米,须采用单模光收发器,确保数据传输稳定。
通过非轨道优化设计,将98,304个光收发器替换为铜线,让25-33%的GPU结构采用铜线连接。此举简化了GPU与叶交换机的连接,不再需绕行电缆托盘和多个机架,叶交换机直接位于机架中部,每个GPU直接使用DAC铜缆连接,效率提升显著。
DAC铜缆运行更凉爽,电力消耗低,价格远低于光学设备。其更可靠的性能显著降低网络波动和故障,这是高速互连的常见难题。相比量子-2 IB交换机747瓦的功耗,光收发器功耗最高达1,500瓦。
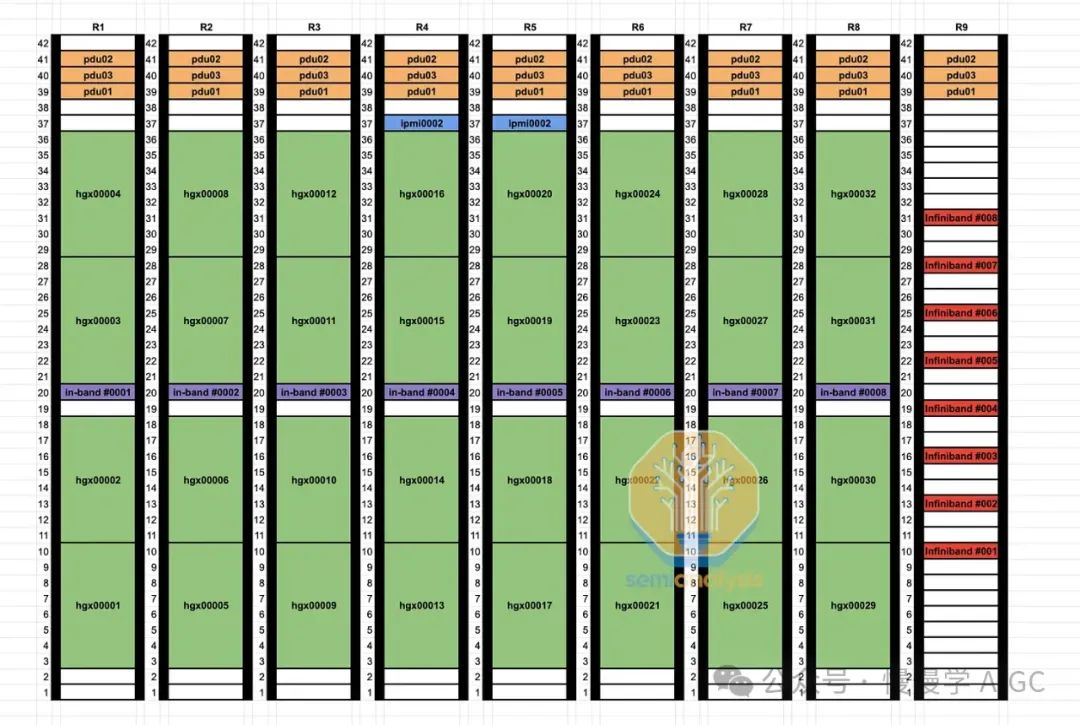
对数据中心技术人员而言,轨道优化布线耗时,每链路末端相距50米,不同机架。中部设计则简化流程:叶交换机与GPU同架,集成工厂测试便捷,效率大幅提升。
可靠性与恢复
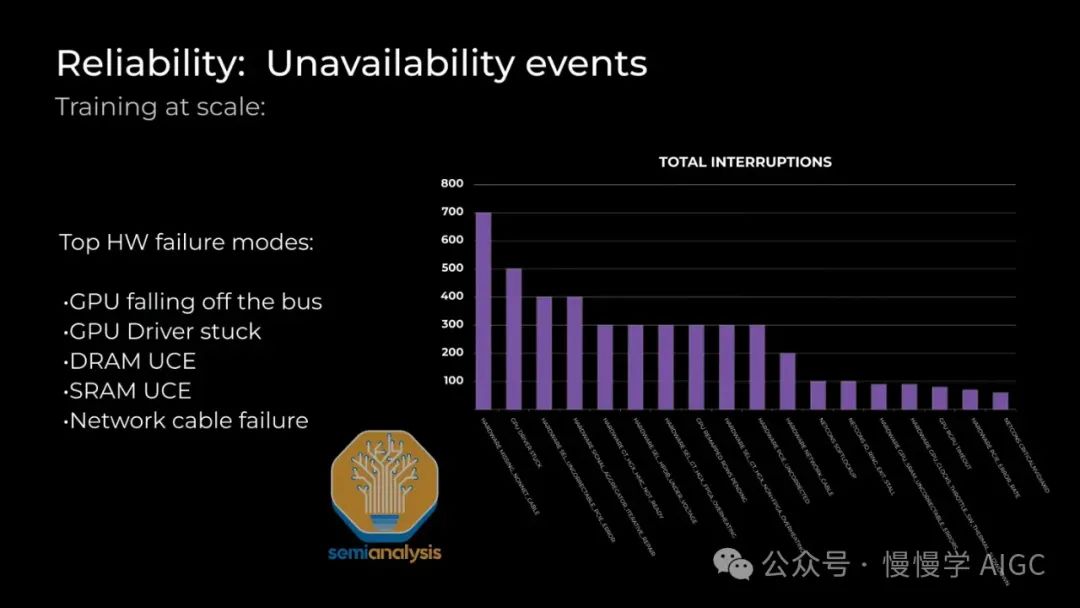
可靠性成大型集群关键挑战,常见问题包括GPU HBM ECC错误、驱动卡顿、收发器故障及NIC过热,导致节点频繁宕机或错误输出。
为降低故障恢复时间,数据中心需备有热备用节点和冷备用组件。故障发生时,迅速切换至备用节点,确保训练不间断。停机仅需简单重启,快速解决问题,确保训练持续高效运行。
简单重启无效,需专业技术人员物理诊断与设备更换。修复损坏GPU服务器耗时数小时至数天。损坏与备用热节点虽具理论FLOPS,却未积极助力模型训练。
在模型训练中,定期将检查点存储至CPU内存或NAND SSD,以防HBM ECC错误。若发生错误,需重新加载权重重启训练。故障容错技术如Oobleck,提供用户级GPU和网络故障处理方案。
不幸的是,频繁的检查点和故障容错训练会显著降低系统整体性能。集群需频繁暂停保存权重,导致每次重启最多损失99步工作。以10万集群为例,若每次迭代耗时2秒,第99步故障可能造成高达229天GPU工作量的损失。
借助后端结构,备用节点可从其他GPU快速RDMA复制,仅需约1.6秒复制80GB HBM内存中的权重。尽管最多可能丢失1步,但整体影响仅限于约3.15GPU天计算时间。
AI领域的先锋实验室已普遍采用高效故障恢复技术,而众多小公司仍依赖低效手段。采用内存重构,可令大型AI训练效率提升数个百分点。
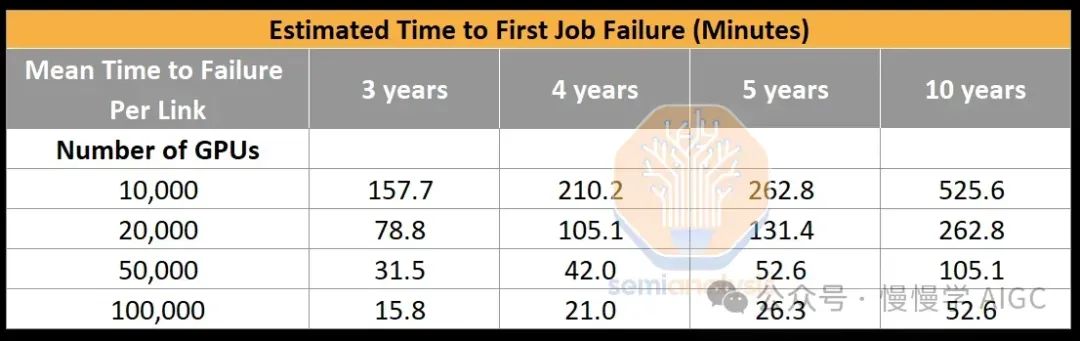
InfiniBand/RoCE链路故障频发,即便平均故障时间长达5年,众多收发器导致新集群26.28分钟内首度作业中断。光学设备故障重启10万GPU集群,恢复耗时或超模型进展。
每个GPU直接连接至ConnectX-7 NIC,网络架构无故障容错,故障处理需在用户代码中实现,增复杂度。NVIDIA与AMD网络结构挑战显著,单一组件故障即导致服务器停机。
正在进行关键升级,确保网络重构,增强节点抗脆弱性。当前状况下,单点故障如GPU或光学问题可能导致价值百万的GB200 NVL72全面停机,远超数十万美元8GPU服务器的损失。
Nvidia 注意到了这一重大问题,并添加了一个专用于可靠性、可用性和可维护性(RAS)的引擎。我们相信 RAS 引擎分析芯片级数据,如温度、恢复的 ECC 重试次数、时钟速度、电压等,预测芯片可能何时故障并警告数据中心技术人员。这将允许他们进行主动维护,如使用更高的风扇速度配置文件以维持可靠性,在稍后的维护窗口取出服务器进行进一步的物理检查。此外,在启动训练作业之前,每个芯片的 RAS 引擎将进行综合自检,如运行矩阵乘法以检测静默数据损坏(SDC)。
Cedar-7
一些客户(如 Microsoft/Openai)通过使用 Cedar Fever-7 网络模块每台服务器,而不是使用 8 个 PCIe 形式的 ConnectX-7 网络卡,来进行成本优化。使用 Cedar Fever 模块的主要好处之一是只需使用 4 个 OSFP 笼,而不是 8 个 OSFP 笼,从而允许在计算节点端使用双端口 2x400G 收发器,而不仅仅是在交换机端。这将 GPU 到叶交换机的收发器数量从 98,304 减少到 49,152。

GPU至交换机连接减半,显著缩短首次作业故障预估时间至4年,相较于单端口400G的5年,提高至42.05分钟,大幅优于未采用Cedar-7模块的26.28分钟。

Spectrum-X NVIDIA
我们正构建10万节点NVIDIA Spectrum-X以太网H100集群,年底全面上线,引领高性能计算新纪元!
去年我们报道了 Spectrum-X 在大型网络中的各种优势。除了性能和可靠性优势外,Spectrum-X 还具有巨大的成本优势。Spectrum-X 以太网的每个 SN5600 交换机有 128 个 400G 端口,而 InfiniBand NDR Quantum-2 交换机只有 64 个 400G 端口。值得注意的是,Broadcom 的 Tomahawk 5 交换机 ASIC 也支持 128 个 400G 端口,使当前一代 InfiniBand 处于劣势。
一个完全互连的 10 万集群可以是 3 层而不是 4 层。4 层而不是 3 层意味着需要多 1.33 倍的收发器。由于 Quantum-2 交换机的较低径数,10 万集群上完全互连的 GPU 数量最多限制为 65,536 个 H100。下一代 InfiniBand 交换机称为 Quantum-X800,通过具有 144 个 800G 端口解决了这一问题,虽然从“144”这个数字可以看出,这设计用于 NVL72 和 NVL36 系统,并预计在 B200 或 B100 集群中使用不多。尽管使用 Spectrum-X 可以节省成本,但不幸的是,您仍需购买 Nvidia LinkX 产品线的高价收发器,因为其他收发器可能无法工作或未经过 Nvidia 验证。
Spectrum-X 拥有先发优势,NVIDIA 库(如 NCCL)全力支持,Jensen 邀您成为其新品线先锋。相较Tomahawk 5,节省内部资源,轻松实现网络与 NCCL 的最佳性能。
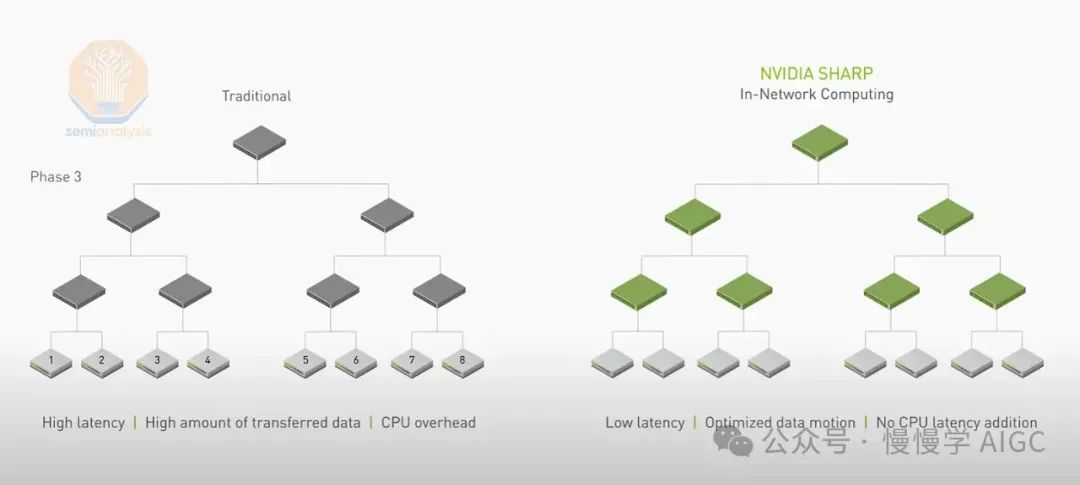
以太网虽取代InfiniBand应用于GPU结构,但无法支持SHARP内规约,限制了理论带宽提升。SHARP内规约通过交换机张量核心简化GPU间数据传输,理论带宽可翻倍。
Spectrum-X 的另一个缺点是,对于第一代 400G Spectrum-X,Nvidia 使用 Bluefield3 而不是 ConnectX-7 作为临时解决方案。我们预计在未来几代 800G Spectrum-X 中,ConnectX-8 将完美工作。
然而,Bluefield-3 和 ConnectX-7 卡之间的价格差异约为 300 美元,其他缺点是 Bluefield-3 卡的功耗增加了 50 瓦。因此,对于每个节点,额外需要 400W 的功率,降低了整体训练服务器的“智能每皮焦耳”。使用 Spectrum X 的数据中心现在需要额外的 5MW 电力用于 10 万 GPU 部署,而与 Broadcom Tomahawk 5 部署使用相同网络架构相比。
Broadcom Tomahawk 5
为规避Nvidia高昂费用,众多客户转向搭载Broadcom Tomahawk 5的交换机。Tomahawk 5与Spectrum-X SN5600同端口配置,128个400G端口,性能卓越。更佳的是,您可全球采购通用收发器和铜缆,灵活配置。
众多客户青睐与Broadcom交换机ASIC的ODM如Celestica合作,同时携手Innolight和Eoptolink等采购收发器。Tomahawk 5在交换机与收发器成本上均优于Nvidia InfiniBand,且价格低于Nvidia Spectrum-X。
遗憾需具备高超工程实力,以优化Tomahawk 5补丁及NCCL集群。原NCCL集群仅针对Nvidia Spectrum-X和InfiniBand优化。然而,若您拥有40亿美元投资10万集群,将能轻松为NCCL编写定制优化,轻松切换离InfiniBand。

探讨四种10万GPU集群网络配置及交换、收发器成本,揭示各自优势,并展示优化光学设备的GPU集群物理布局图。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-