前言

1引言
Stable Diffusion 是 2022 年发布的深度学习文生图模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补和外补绘制,以及在提示词指导下产生图生图的翻译。
¸算法原理
Stable Diffusion 是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在 2015 年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。
潜在扩散模型通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像。这样可以降低生成过程中所需的计算资源和时间,并提高生成质量和多样性。
Stable Diffusion 模型使用了一个 Transformer 编码器来将文本输入转换为一个固定长度的向量,并将其与每个潜在表示向量相结合。这样可以使得模型能够根据文本输入调整生成过程,并保持与文本内容和风格一致。
¸发展历史
Stable Diffusion 的前身是 Disco Diffusion,一个由 Somnai 开发并于 2022 年 6 月发布到 Google Colab 平台上的开源工具。
Disco Diffusion 利用了 OpenAI 的 DALL-E 模型作为预训练基础,并使用了 LDMs 作为生成方法。Disco Diffusion 能够产生高分辨率和高质量的图片,但缺点也很明显,那就是速度非常慢,动辄半个小时起步。
Somnai 后来加入了 AI 艺术项目实验室 Midjourney,并对 Disco Diffusion 进行了改进,平均 1 分钟能出图。
Stable Diffusion 是由 Stability AI 领导并与 EleutherAI 和 LAION 合作开发并于 2022 年 8 月底开源发布到 GitHub 上的项目。Stability AI 提供了大量计算资源支持,EleutherAI 提供了技术支持和协助,LAION 提供了数据资源支持。
Stable Diffusion 在 LAION-5B 的一个子集上训练了一个 LDMs 模型专门用于文图生成。该模型能够在消费级 GPU 上,在 10 秒级别时间生成图片,并且具有很强的泛化能力和创造力。
2022 年 11 月 24 日,Stability AI 发布了 Stable Diffusion 2.0 版本,不久之后又发布了 2.1 版本。
下面,我们选择一篇文章[1]以图解方式让大家快速了解 Stable Diffusion 背后的技术。
本次教程将使用AI绘画工具 Stable Diffusion 进行讲解,如还未安装SD的小伙伴可以扫描免费获取哦~
2工作方式
从文本描述中创建具有高品质视觉效果的图像不失为一项吸引人的创举,它表明人类创造艺术的方式正在发生转变。Stable Diffusion[2] 的发布是这一发展中的一个里程碑,因为它为大众提供了一个在图像质量、速度和相对较低的资源/内存需求方面的高性能模型。
在尝试了 AI 图像生成之后,你可能会开始想知道它是如何工作的。本篇就是对 Stable Diffussion 的工作原理作一个图解,以便快速了解这个技术。

Stable Diffusion 用途广泛,因为它可以以多种不同的方式使用。让我们首先关注仅从文本生成图像 (text2img)。上图显示了一个示例文本输入和生成的图像。除了文本到图像,另一种主要的使用方式是让它改变图像(此时输入是文本 + 图像)。

下面让我们深入一些,这将有助于解释组件及其交互以及图像生成各选项/参数的含义。
3Stable Diffusion 总体架构
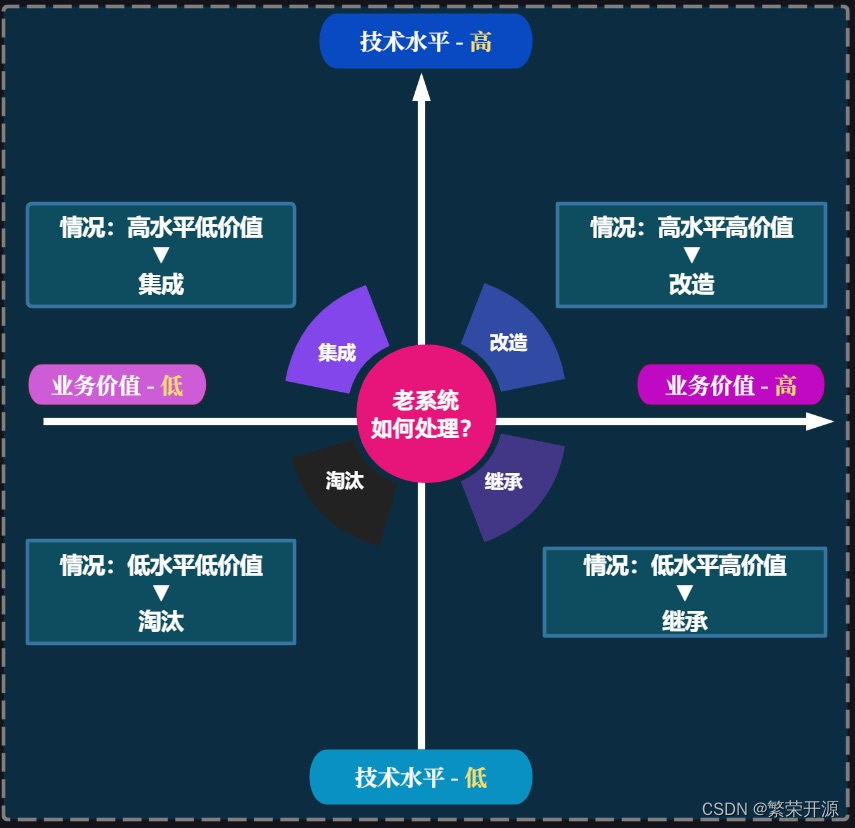
Stable Diffusion 并不是一个单一的模型,而是一个由多个组件和模型组成的系统。
当我们仔细观察时,我们可以做的第一个观察是有一个文本理解组件,它将文本信息转换为数值表示,捕捉文本的涵义。

我们从一个高级视图开始,我们将在本文后面介绍更多机器学习细节。但是,我们可以说这个文本编码器是一种特殊的 Transformer 语言模型(技术上:CLIP 模型的文本编码器)。它获取输入文本并输出代表文本中每个 token 的数字列表(每个 token 一个向量)。
然后将该信息呈现给图像生成器,图像生成器本身由几个组件组成。

图像生成器经历两个阶段:
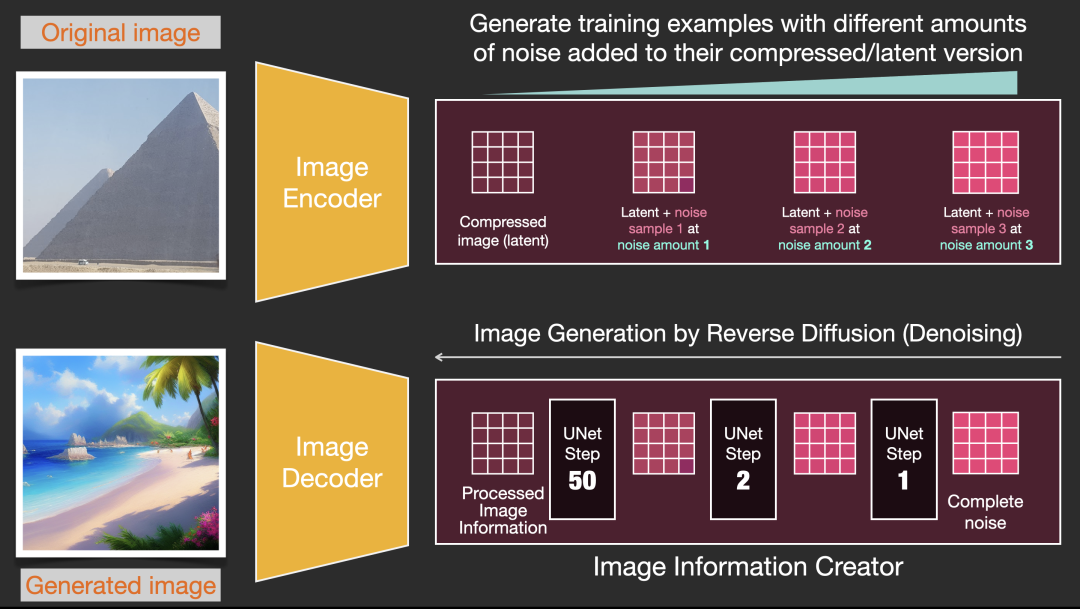
1、图像信息创建者
该组件是 Stable Diffusion 的秘诀。与以前的模型相比,它实现了很多性能提升。
该组件运行多个 steps 以生成图像信息。Stable Diffusion 接口和库中的 steps 参数,通常默认为 50 或 100。
图像信息创建者完全在图像信息空间(或者潜空间)中工作。此属性使其比以前在像素空间中工作的扩散模型更快。从技术上讲,这个组件由一个 UNet 神经网络和一个调度算法组成。
“扩散”这个词描述了这个组件中发生的事情。正是信息的逐步处理导致最终生成高质量图像。
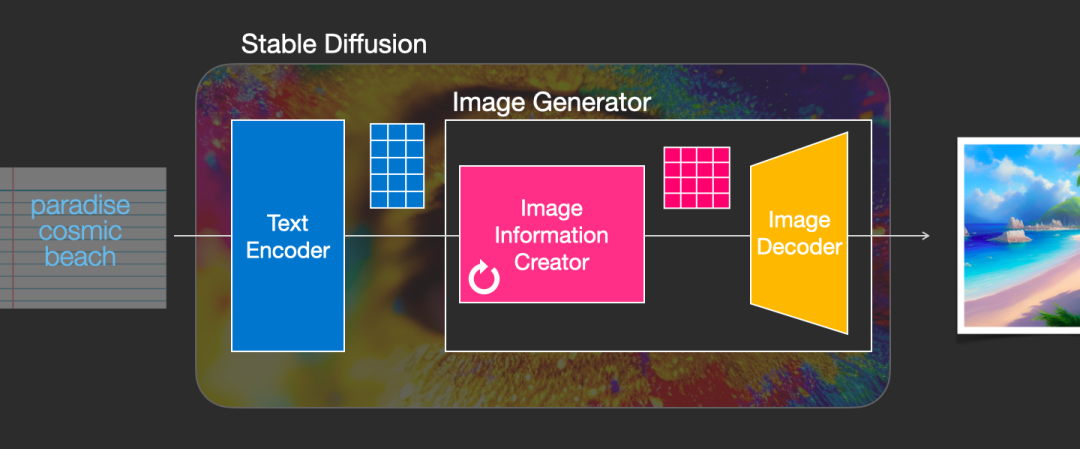
2、图像解码器
图像解码器根据从信息创建者那里获得的信息绘制一幅图画。它只在过程结束时运行一次以生成最终像素图像。

有了这个,我们就可以看到构成 Stable Diffusion 的三个主要组件(每个组件都有自己的神经网络):
-
ClipText 用于文本编码。输入:文本。输出:77 个 token 嵌入向量,每个向量有 768 个维度
-
UNet + Scheduler 逐步处理/扩散潜空间中的信息。输入:文本嵌入和由噪声组成的起始多维数组。输出:处理后的信息数组
-
使用处理后的信息数组绘制最终图像的**自动编码器解码器。**输入:处理后的信息数组,尺寸:(4, 64, 64) 输出:生成的图像,尺寸:(3, 512, 512) ,分别对应(红/绿/蓝,宽,高)

4到底什么是扩散?
扩散是发生在粉红色“图像信息创建者”组件内部的过程。具有表示输入文本的 token 嵌入和随机起始图像信息数组,该过程生成一个信息数组,图像解码器使用该信息数组绘制最终图像。

这个过程以 step-by-step 的方式发生。每一步都会添加更多相关信息。为了直观地了解这个过程,我们可以检查随机潜在数组(latents array),看看它是否转化为视觉噪声。在这种情况下,目视检查是将其通过图像解码器。
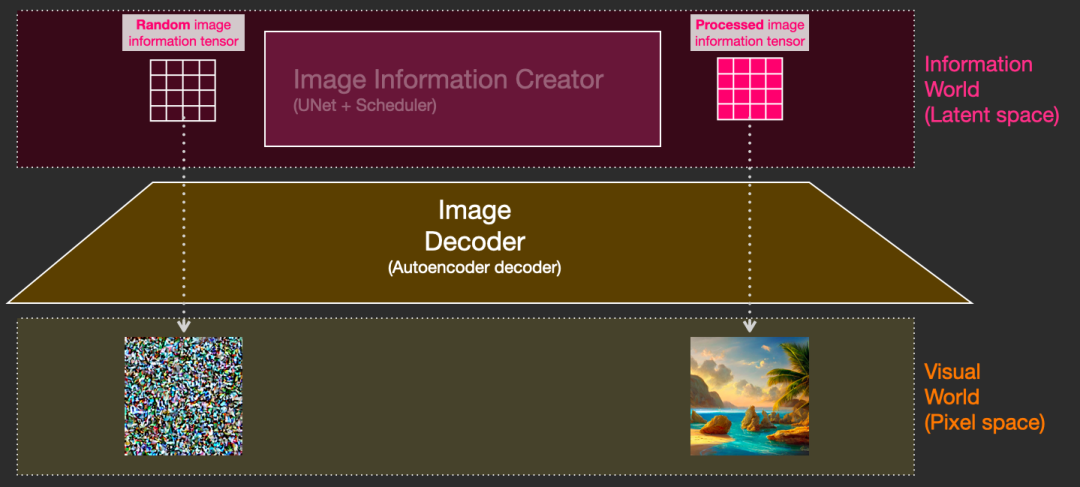
扩散发生在多个步骤中,每个步骤都对输入的潜在数组进行操作,并产生另一个潜在数组,该数组更类似于输入文本以及模型从训练模型的所有图像中获取的所有视觉信息。
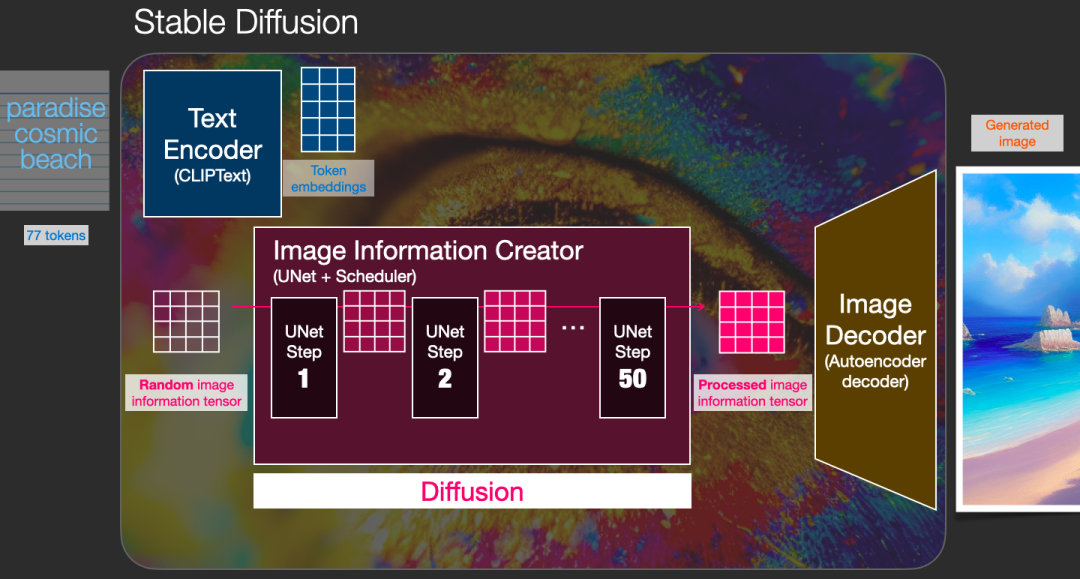
我们可以将这些潜在数组可视化,以查看在每个步骤中添加了哪些信息。
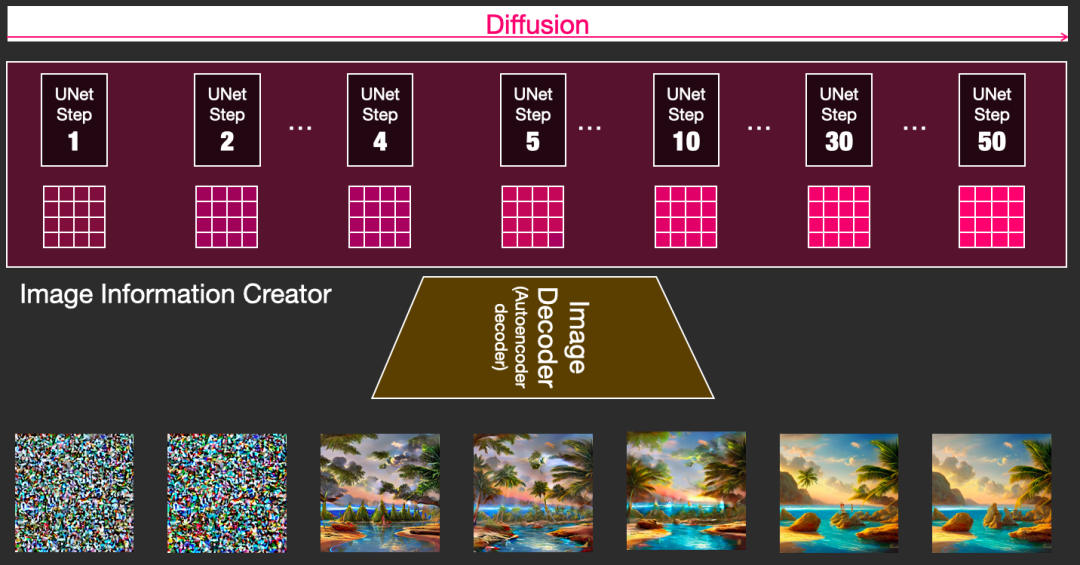
这个过程令人叹为观止。

在本例中,第 2 步和第 4 步之间发生了一些特别有趣的事情。就好像轮廓从噪音中浮现出来。

¸扩散如何运作
使用扩散模型生成图像的中心思想依赖于我们拥有强大的计算机视觉模型。给定足够大的数据集,这些模型可以学习复杂的操作。扩散模型通过将问题框定如下来处理图像生成:
假设我们有一张图像,我们会产生一些噪声,并将其添加到图像中。

现在可以将其视为训练示例。我们可以使用相同的公式来创建大量训练示例来训练图像生成模型的核心组件。

虽然此示例显示了从图像(数量 0,无噪声)到全噪声(数量 4,全噪声)的一些噪声量值,但我们可以轻松控制要添加到图像中的噪声量,因此我们可以将其分散到数十个步骤中,为训练数据集中的每个图像创建数十个训练示例。

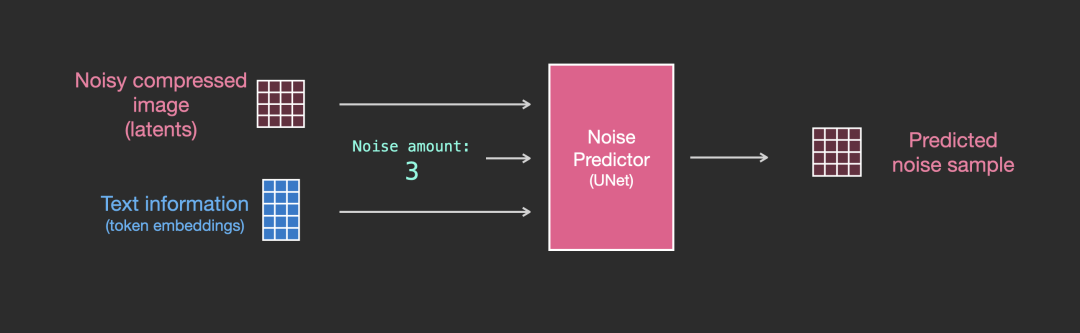
有了这个数据集,我们可以训练噪声预测器并最终得到一个很好的噪声预测器,它在特定配置下运行时实际创建图像。训练步骤看起来很熟悉:

现在让我们看看这如何生成图像。
¸通过去噪来绘制图像
经过训练的噪声预测器可以通过输入噪声图像和去噪步骤数量预测噪声采样。
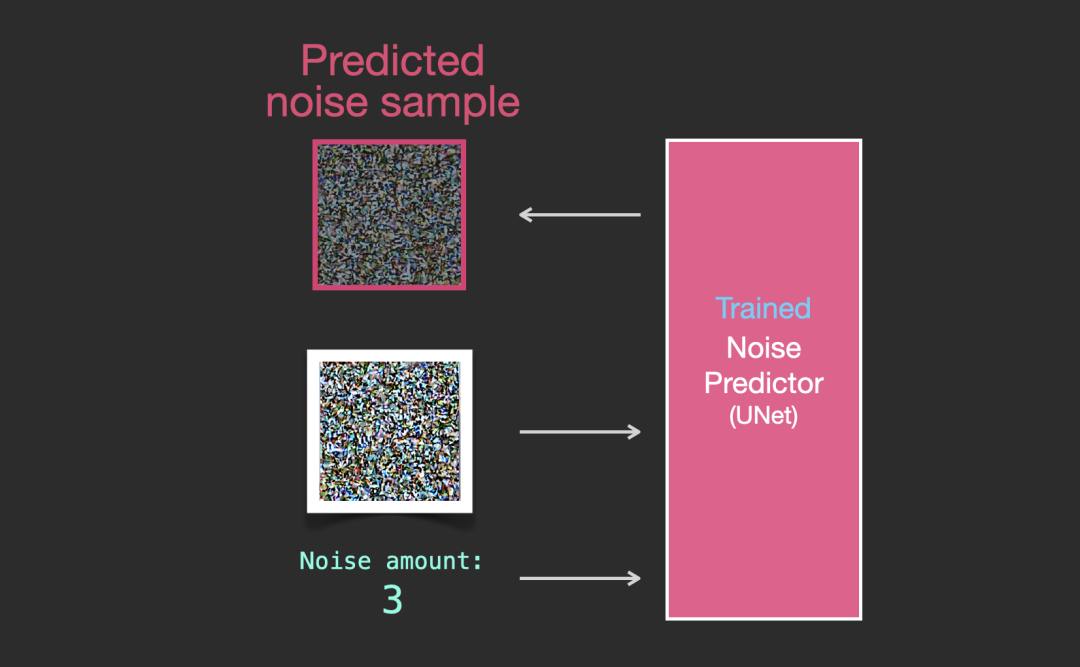
采样噪声是预测的,因此如果我们从图像中减去它,我们得到的图像更接近于训练模型的图像(不是确切的图像本身,而是分布:例如天空通常是蓝色,并且在地面之上;人有两只眼睛等)。
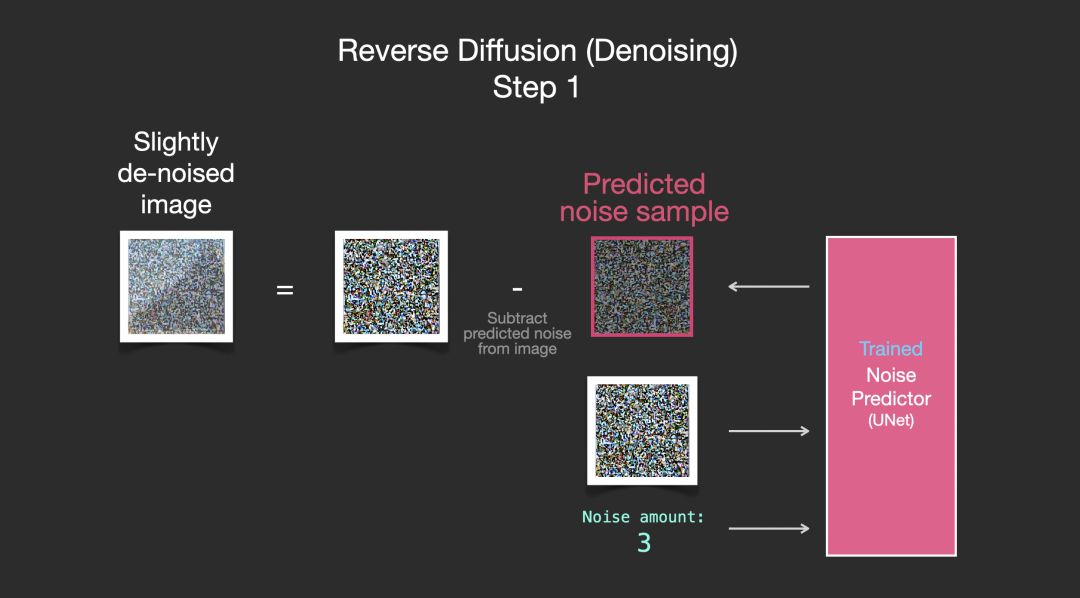
如果训练数据集是美观的图像(例如,LAION[3],Stable Diffusion 是在其上进行训练的),那么生成的图像往往也会美观。如果我们在徽标图像集上训练它,我们最终会得到一个徽标生成模型。
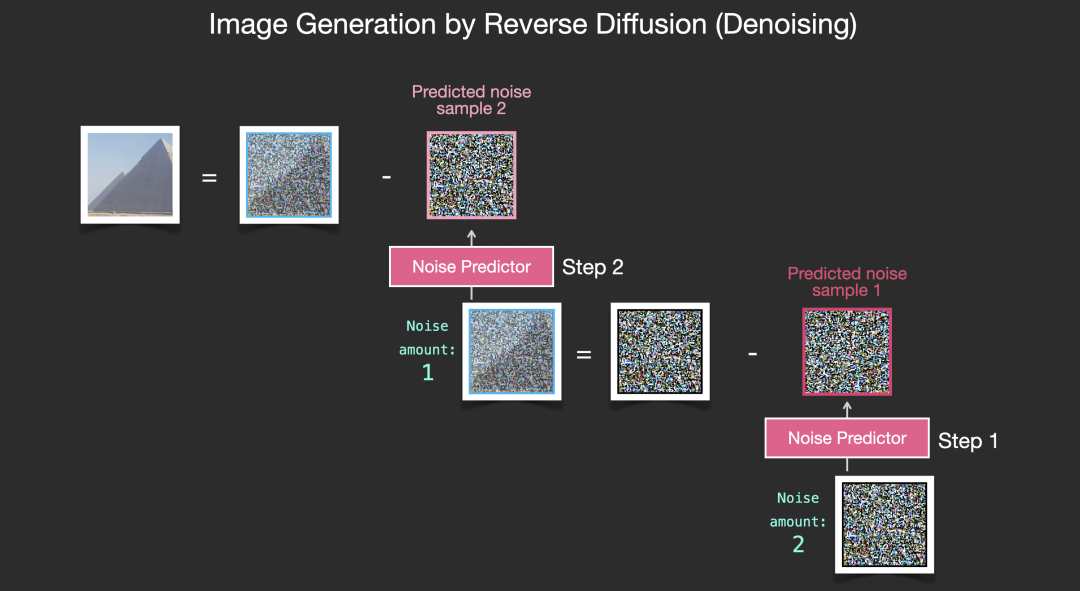
以上总结了扩散模型对图像生成的过程,这也是论文 DDPM[4] 中所述的。有了扩散的概念后,你不仅了解了 Stable Diffusion 的主要组成部分,也了解了 Dall-E 2 和 Google 的 Imagen。
请注意,到目前为止我们描述的扩散过程生成图像时没有使用任何文本数据。所以如果我们部署这个模型,它会生成漂亮的图像,但我们无法控制它是金字塔、猫还是其他任何东西的图像。在接下来的部分中,我们将描述如何将文本合并到流程中以控制模型生成的图像类型。
5速度提升:在(潜在)数据上扩散
为了加快图像生成过程,Stable Diffusion 论文不是在像素图像本身上运行扩散过程,而是在图像的压缩版本上运行。
这样的压缩,以及后面的解压缩/绘画,是通过自编码器完成的。自编码器使用其编码器将图像压缩到潜在空间中,然后使用解码器仅使用压缩信息重建图像。

现在正向扩散过程是在压缩潜空间上完成的。噪声切片是应用于那些潜空间的噪声,而不是像素图像。因此,噪声预测器实际上经过训练以预测压缩表示(潜空间)中的噪声。

正向过程(使用自编码器的编码器)是我们生成数据以训练噪声预测器的方式。训练完成后,我们可以通过运行反向过程(使用自编码器的解码器)来生成图像。
这两个流程如 LDM/Stable Diffusion 论文的图 3 所示:
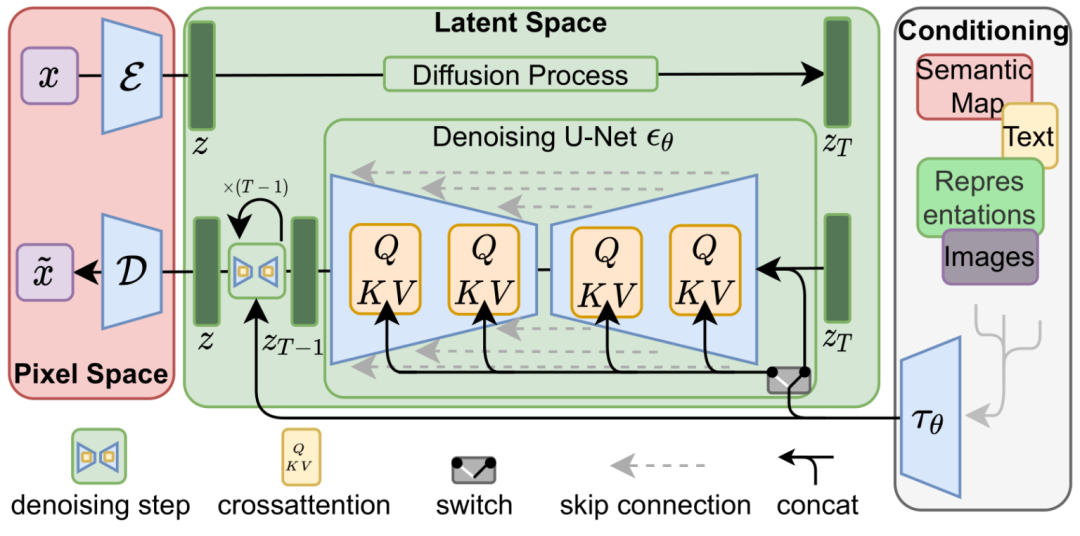
该图还显示了“调节”组件,在本例中是描述模型应生成的图像的文本提示。因此,让我们来进一步探究文本组件。
¸文本编码器
Transformer 语言模型用作语言理解组件,它接受文本提示并生成 token 嵌入。发布的 Stable Diffusion 模型使用的是 ClipText(一种基于 GPT 的模型[5]),而当时论文中使用的是 BERT[6]。
Imagen 论文表明语言模型的选择很重要。与较大的图像生成组件相比,较大的语言模型对生成的图像质量的影响更大。
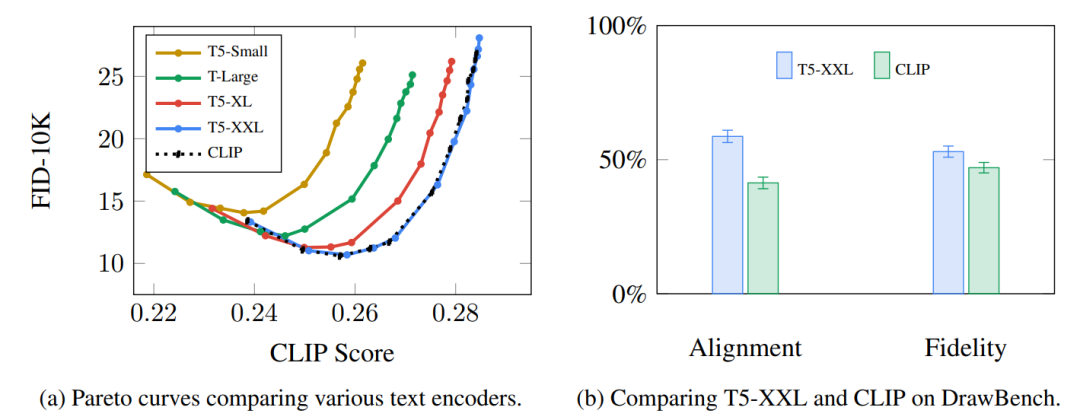
更大/更好的语言模型对图像生成模型的质量有显着影响。资料来源:Saharia 等人的 Google Imagen 论文[7] 图 A.5。
早期的 Stable Diffusion 模型只是插入了 OpenAI 发布的预训练 ClipText 模型。未来的模型可能会切换到 CLIP 的新发布和更大的OpenCLIP[8]变体(2022 年 11 月更新:足够真实,Stable Diffusion V2 使用 OpenClip[9])。这个新版本包括大小高达 354M 参数的文本模型,而不是 ClipText 中的 63M 参数。
¸CLIP 是如何训练的
CLIP 在图像及其说明的数据集上进行训练。想象一个看起来像这样的数据集,有 4 亿张图片及其说明:

图像及其说明的数据集。
实际上,CLIP 是根据从网络上抓取的图像及其“alt”标签进行训练的。
CLIP 是图像编码器和文本编码器的组合。它的训练过程可以简化为同时考虑图像及其标题。我们分别使用图像和文本编码器对它们进行编码。
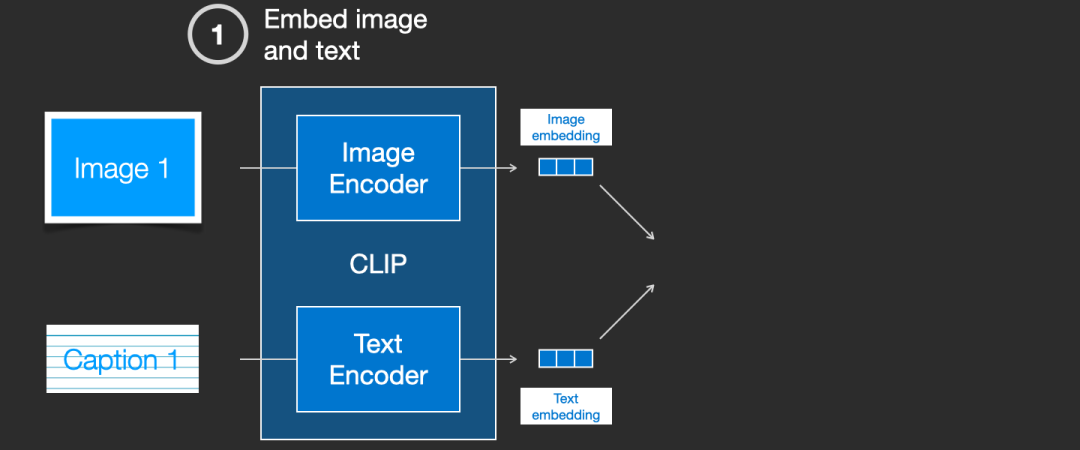
然后我们使用余弦相似度比较生成的两个嵌入。当开始训练过程时,相似度会很低,即使文本正确地描述了图像。
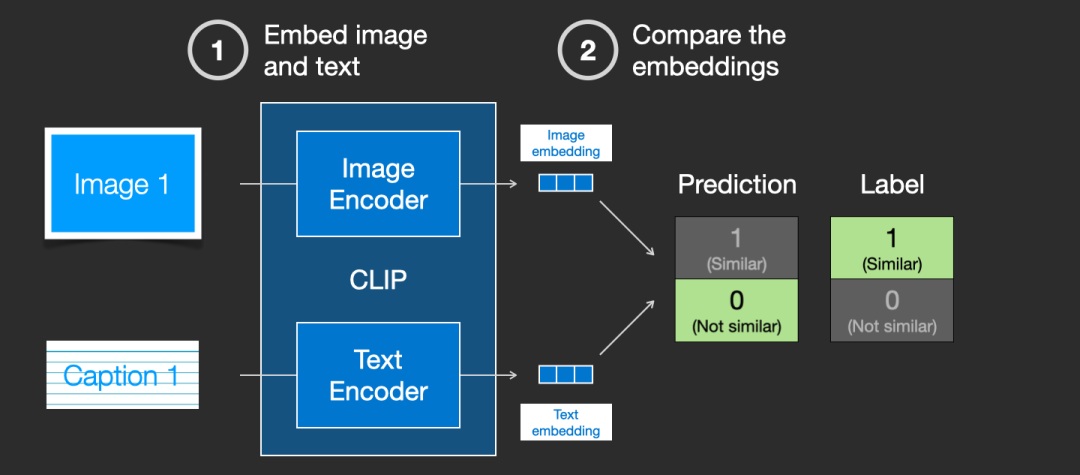
接着更新这两个模型,以便下次嵌入它们时,生成的嵌入更加相似。
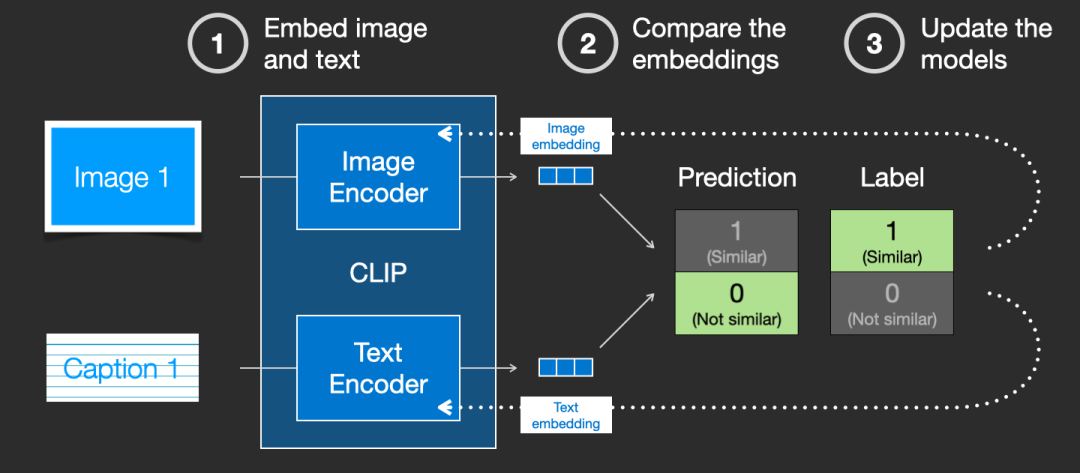
通过在数据集中重复此操作最终使编码器能够生成嵌入,其中狗的图像和句子“a picture of a dog”是相似的。就像在 word2vec[10] 中一样,训练过程也需要包括不匹配的图像和标题的反例,并且模型需要为它们分配低相似度分数。
6文本信息融入图像生成
为了使文本成为图像生成过程的一部分,我们必须调整噪声预测器以使用文本作为输入。

现在的数据集已经包含了文本编码。由于我们在潜空间中操作,因此输入图像和预测噪声都在潜空间中。

为了更好地了解文本标记在 Unet 中的使用方式,下面进一步深入了解 Unet。
¸Unet 噪声预测器的层(无文本)
先来看一个不使用文本的扩散 Unet,它的输入和输出看起来像下面这样:
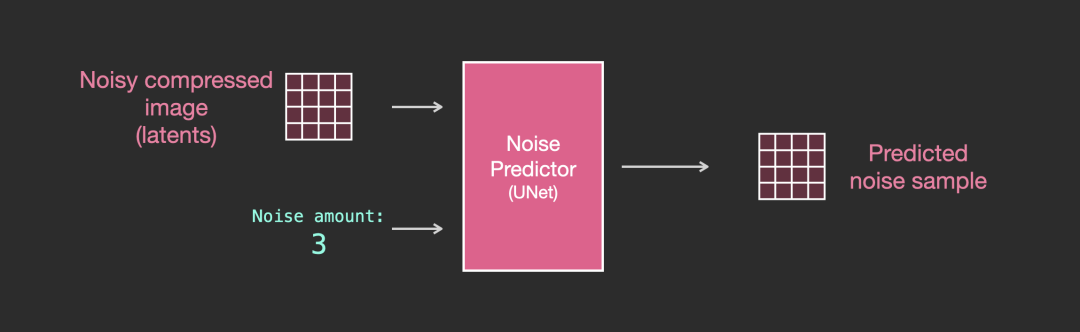
在里面,可以看到:
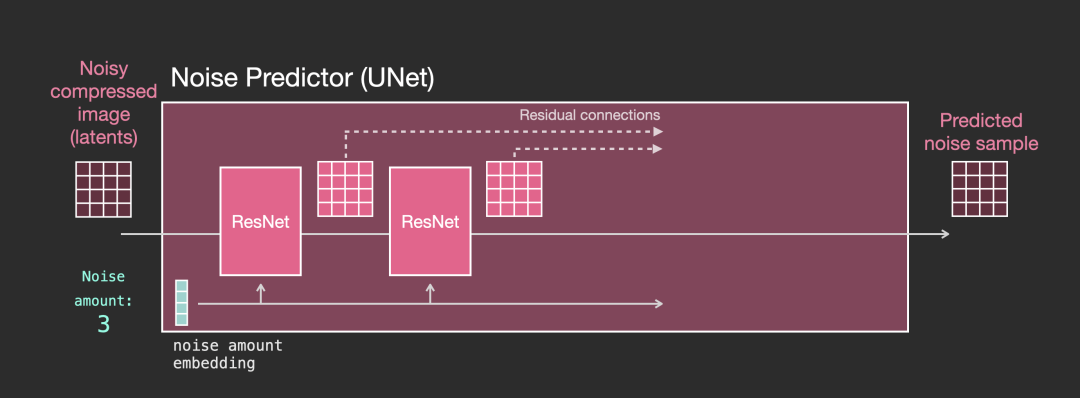
-
Unet 是一系列用于变换潜在数组的层
-
每一层都对前一层的输出进行操作
-
一些输出被(通过残差连接)馈送到网络稍后的处理中
-
时间步长被转换为时间步长嵌入向量,并在层中使用
¸带文本的 Unet 噪声预测器层
现在让我们看看如何改变这个系统以包括对文本的注意力。
添加对文本支持的系统的主要调整是在 ResNet 块之间添加一个注意力层。

请注意,ResNet 块不会直接查看文本。但是注意力层将这些文本表示合并到潜向量中。现在,下一个 ResNet 可以在其处理过程中利用合并的文本信息。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!