我们来看看RAG进展。《Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely》(https://arxiv.org/abs/2409.14924),主要讨论了如何使大型语言模型(LLMs)更明智地使用外部数据,以提高其在现实世界任务中的性能。
从内容上看,提出了一种RAG任务分类方法,根据所需的外部数据类型和任务的主要焦点,将用户查询分为四个层次:显式事实查询、隐式事实查询、可解释理由查询和隐藏理由查询。
本文来详细的看看其中的两个问题,一个是关于问题的定义和RAG中查询的四个层次,另一个是关于RAG中的查询-文档对齐的几种策略。
会有一定收获,供大家一起思考并参考。
一、RAG检索增强问答的四个层次
先看问题的定义,将数据增强的LLM应用定义为一个函数,它根据给定的数据建立从用户输入(Query)到预期响应(Answer)的映射。

在数据增强的LLM应用领域中,可以根据它们的复杂性和所需的数据交互深度将查询进行层次化。
查询可以根据与外部数据交互的复杂性和深度,将查询分为四个层次:

对于每个级别的RAG,也可以总结出对应的挑战和实现方案

1、Level-1 显式事实(Explicit Facts)
这些查询直接询问给定数据中直接存在的显式事实,不需要任何额外的推理。这是最简单的查询形式,模型的任务主要是定位和提取相关信息。
例如,“2024年夏季奥运会将在哪里举行?”这个问题针对的是外部数据中包含的一个事实。
1)挑战:
-
数据检索难度:从大型非结构化数据集中检索相关数据段可能计算密集且容易出错。
-
评估难度:在组件级别准确评估RAG系统的性能是一个复杂任务,需要开发能够准确评估数据检索和响应生成质量的稳健指标。
2)解决方案:
-
数据检索增强:使用更先进的信息检索(IR)技术,如基于BERT的编码器,以及结合稀疏和密集检索方法,提高检索的相关性和准确性。
-
评估机制:开发更精细的评估标准,可能包括基于困惑度或困惑度增益等特定指标。
2、Level-2 隐式事实(Implicit Facts):
这些查询询问数据中的隐式事实,这些事实并不立即明显,可能需要一些常识推理或基本逻辑推断。所需信息可能分散在多个段落中,或需要简单的推理。
例如,“堪培拉所在的国家的执政党是什么?”这个问题可以通过结合堪培拉位于澳大利亚的事实和澳大利亚当前执政党的信息来回答。
1)挑战:
-
自适应检索量:不同问题可能需要不同数量的检索上下文,固定数量的检索可能导致信息噪声过多或信息不足。
-
推理与检索的协调:推理可以指导需要检索的内容,而检索到的信息可以迭代地细化推理策略。
2)解决方案:
-
迭代RAG:使用多步骤RAG过程,动态控制信息收集或纠正的步骤,直到达到正确答案。
-
图/树问题回答:使用图或树结构来自然表达文本之间的关系,适合需要从多个参考资料中综合信息的查询。
3、Level-3 可解释理由(Interpretable Rationales)
这些查询不仅要求掌握事实内容,还要求能够理解和应用数据上下文中固有的领域特定理由。这些理由通常在外部资源中明确提供,并且在通用大型语言模型的预训练阶段很少遇到或很少出现。
例如,在制药领域,LLM必须解释FDA指南文件——代表FDA当前的想法——以评估特定药物申请是否符合监管要求。同样,在客户支持场景中,LLM必须导航预定义的工作流程的复杂性,以有效地处理用户询问。在医疗领域,许多诊断手册提供了权威和标准化的诊断标准,如急性胸痛患者的管理指南。
通过有效遵循这些外部理由,可以开发出用于管理胸痛的专门LLM专家系统。这涉及到理解程序步骤和决策树,指导支持代理与客户的互动,确保响应不仅准确,而且符合公司的服务标准和协议。
1)挑战:
-
提示优化成本:优化提示过程耗时且计算量大,不同查询需要不同的背景知识和决策标准。
-
有限的可解释性:提示对LLMs的影响是不透明的,难以一致地理解和验证LLM对不同提示的响应的可解释性。
2)解决方案:
-
提示调整:使用强化学习等技术来发现最优的提示配置,以提高LLM遵循外部指令的准确性。
-
基于CoT的提示:设计链式思考(Chain-of-Thought)或思维树(Tree-of-Thoughts)提示,以促进LLM进行更复杂的推理过程。
4、Level-4 隐藏理由(Hidden Rationales):
这类查询深入到更具挑战性的领域,其中理由没有明确记录,但必须从外部数据中观察到的模式和结果中推断出来。这里所说的隐藏理由不仅指的是隐含的推理链和逻辑关系,还包括识别和提取每个特定查询所需的外部理由的固有挑战和非平凡任务。
例如,在IT运营场景中,云运营团队可能过去处理了许多事件,每个事件都有其独特的情况和解决方案。LLM必须擅长挖掘这个丰富的隐性知识库,以辨别隐含的策略和成功决策过程。
同样,在软件开发中,以前的错误调试历史可以提供隐性洞察的丰富财富。虽然每个调试决策的逐步理由可能没有系统地记录,但LLM必须能够提取指导这些决策的潜在原则。通过综合这些隐藏的理由,LLM可以生成不仅准确而且反映了经验丰富的专业人士随着时间磨练的不言而喻的专业知识和问题解决方法的响应。
1)挑战:
-
逻辑检索:对于涉及隐藏理由的查询,外部数据的帮助不仅仅依赖于实体级别或语义相似性,而是基于逻辑一致性或主题对齐。
-
数据不足:外部数据可能没有明确包含与当前查询相关的指导或答案,相关信息通常嵌入在分散的知识中或通过示例说明。
2)解决方案:
-
离线学习:通过离线方式从数据集中识别和提取规则和指导,然后在需要时检索相关内容。
-
上下文学习(ICL):使用示例进行上下文学习,利用预训练的大型语言模型的少样本学习能力,通过检索相似的示例来增强模型的推理能力。

前两个层次,显式事实和隐式事实,侧重于检索事实信息,无论是直接说明的还是需要基本推理的。这些层次挑战了LLM提取和综合数据成连贯事实的能力。相反,后两个层次,可解释理由和隐藏理由,将重点转向LLM学习和应用数据背后理由的能力。
二、关于RAG中的查询-文档对齐的几种策略
查询文档对齐的目标是将查询与外部数据中的文档片段对齐,以识别可以帮助回答查询的最佳文档片段。
如图3所示,主要有三种对齐方法:传统对齐、文档域对齐和查询域对齐。
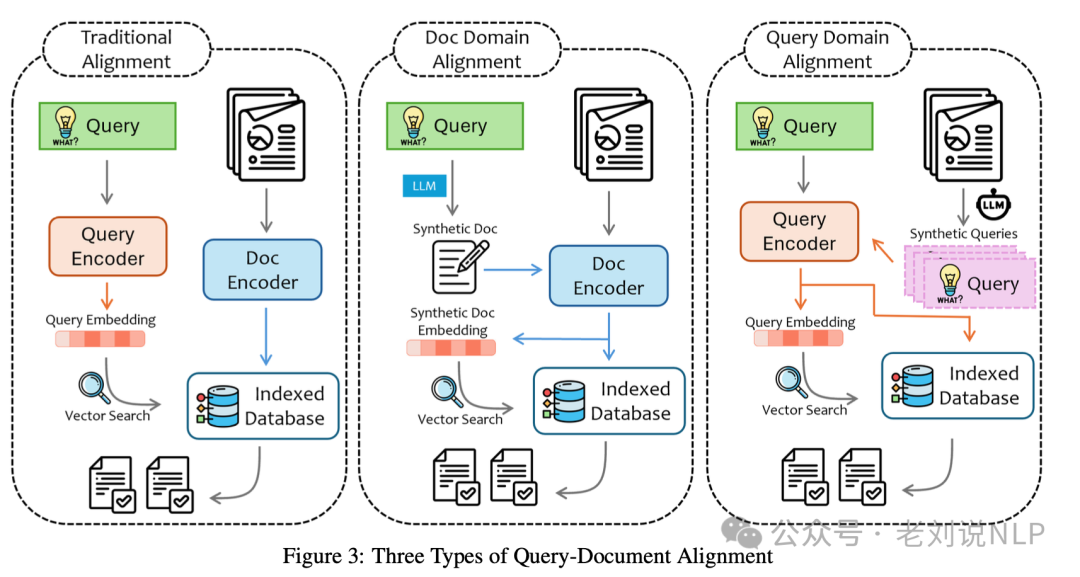
1、传统对齐
涉及将文档片段和查询映射到相同的编码空间。例如,许多基于双编码器的密集检索架构都具有专门的查询编码器。相反,如果像RAG这样的系统采用稀疏检索,则需要从查询中提取关键词进行搜索。
 通过查询改写技术可以进一步细化,这可以通过减轻用户术语不准确或描述模糊的问题来提高搜索准确性,从而有效提高搜索结果的精确度。
通过查询改写技术可以进一步细化,这可以通过减轻用户术语不准确或描述模糊的问题来提高搜索准确性,从而有效提高搜索结果的精确度。
2、文档域对齐
涉及首先生成合成答案,然后使用这些答案来回忆相关数据,有效解决了查询和检索数据不在相同分布空间的问题。

在这个领域的著名工作是HyDE。
3、查询域对齐
涉及为每个文本的原子单元生成一组合成问题,将文本片段映射到查询空间,然后检索与原始查询最接近的合成问题及其对应的文本片段。这种方法确保了为回答查询选择最相关和上下文适当的片段。

SlimPLM使用一个小的代理模型来生成启发式答案,然后用来预测回答问题所需的知识。这种方法也提供了一种有效的将查询对齐到文档空间的方法。
总结
本文主要介绍了RAG中查询的四个层次以及关于RAG中的查询-文档对齐的几种策略,这些都是很常用策略。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈