安装路径:先装jdk,后装JMeter
安装JDK:
下载JDK – 安装JDK – 配置环境变量 – 验证
安装Jmeter:
下载Jmeter – 安装Jmeter – 配置环境变量 – 启动验证
注意点:
下载JDK时,注意电脑操作系统是32位/64位
下载Jmeter时,注意与本机安装的JDK版本匹配
安装Jmeter时,安装路径中不能有中文/空格
JMeter文件目录结构:
Bin目录:存放的可执行的文件和配置文件
docs目录:是api文档,用于开发扩展的组件
printable_docs 目录:用户帮助手册
lib目录:存放HMeter依赖的jar包和用户扩展的所需要的jar包(在ext文件中)

修改默认配置 —— JMeter界面的汉化
永久性 —— 修改配置文件:
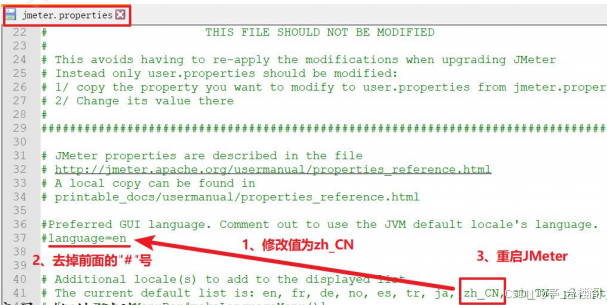


1. 找到jMeter安装目录下的bin目录
2. 打开jmeter.properties文件,把#language=en修改为 “language=zh_CN”
3. 重启JMeter即可
临时性:
启动JMeter->选择菜单‘Options’->Choose Language->Chinese (Simplified)
元件
含义:多个类似功能组件的容器(类似于类)(相当于 容器的集合 )
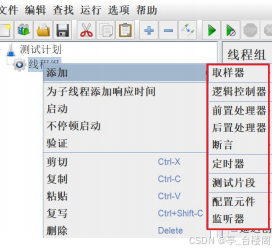
取样器:发送请求
逻辑控制器:控制语句的执行顺序
前置处理器:对请求参数进行预处理
后置处理器:对响应结果进行提取
断言:检查接口返回结果是否与预期结果一致
定时器:设置等待
测试片段:封装一段代码,供其他脚本调用
配置元件:测试数据的初始化配置
监听器:查看jmeter脚本的运行结果
组件
含义:
实现独立的某个功能(类似于
方法
)类似 取样器 中 http请求
如下接口自动化脚本的实现过程对应着
Jmeter
哪个元件?
1. 初始化测试数据
——
配置元件
2. 对请求参数进行赋值
—— 前置处理器
3. 调用GET/POST方法发送请求
—— 取样器
4. 提取响应中特定字段的值
—— 后置处理器
5. 对提取出来的值与预期结果进行对比
—— 断言
6. 在控制台查看脚本运行的结果
—— 监听器
元件与组件有什么关系 ?
元件:
多个类似功能组件的
容器
(类似于
类
)
组件:
容器中
实现独立的某个功能(类似于
方法
)
元件的作用域:
是靠测试计划的树形结构中元件的
父子关系
来确定的。
所有的组件都是
以取样器为核心
来运行的。(如果在它们的作用域内没有任何取样器,则不会被执行)
Jmeter元件作用域的原则?
取样器:核心,不和其他元件相互作用,没有作用域
逻辑控制器:只对其子节点中的取样器和逻辑控制器起作用
其他元件:
如果是某个取样器的子节点,则该元件只对其父节点起作用
如果其父节点不是取样器,则其作用域是该元件父节点下的其他所有后代节点(包括子节点,子节点的子节点等)
元件的执行顺序:
同一个作用域下不同类型元件:配置元件 - 前置处理程序 - 定时器 - 取样器 - 后置处理程序 - 断言 - 监听器
同一个作用域下多个相同类型元件: 按照在测试计划中从上到下的顺序依次执行
线程组:
线程组就是控制JMeter用于执行测试的一组用户(一个线程理解为一个测试用户 )
位置:
右键点击‘测试计划’ --> 添加 --> 线程(用户) --> 线程组
特点:
模拟用户,支持多用户操作
多个线程组可以串行执行,也可以并行执行
线程组分类:
Setup线程组:
预测试操作,所有脚本之前执行
普通线程组:
执行测试用例,可以有1个或者多个(并行/串行)
Teardown线程组:
测试后操作,所有脚本之后执行
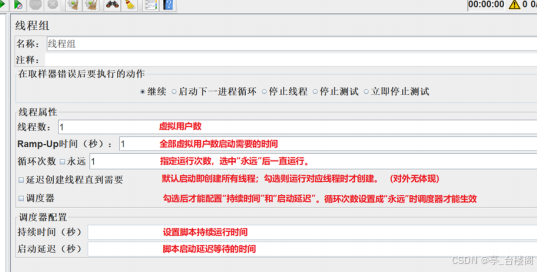
线程组 —— 参数详解:
案例分析:
使用
1
个线程组,添加
HTTP
请求(百度)
配置线程数为
2
,循环次数为
3
时,运行观察结果
配置线程数为
3
,循环次数为
2
时,运行观察结果,对比是否有不同
相同点:从请求数量来说,是完全相同的
不同点:场景不同
线程数:代表用户数,即性能测试时的负载量(线程数为
2
比线程数为
3
对应的负载量小)
循环次数:代表时间,即性能测试时的运行时间(循环次数
3
比循环次数
2
对应的时间长)
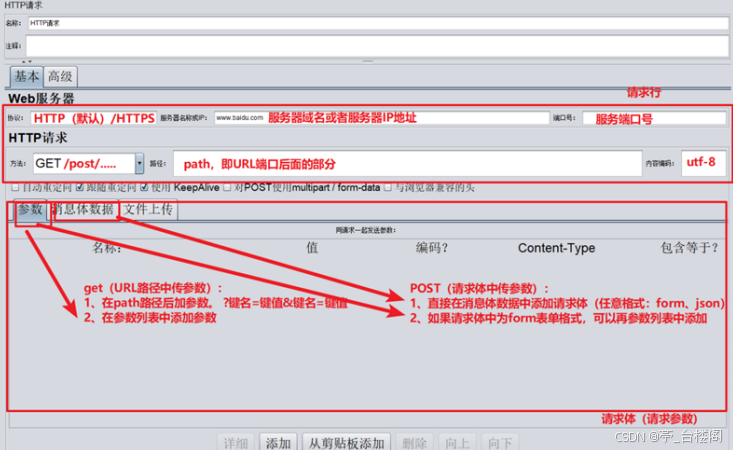
HTTP
请求:
参数介绍:
作用:
向服务器发送
http(端口号80)
及
https(端口号443)
请求
Jmeter参数化
本质:使用
参数的方式来替代脚本中的固定的测试数据 (把测试数据组织起来,用不同的测试数据 调用相同的测试方法
)
实现方式:
定义变量(最基础)
文件定义的方式(所有测试数据都是固定的情况下)
数据库的方式(灵活,业务测试常用)
函数的方式(灵活,业务测试常用)
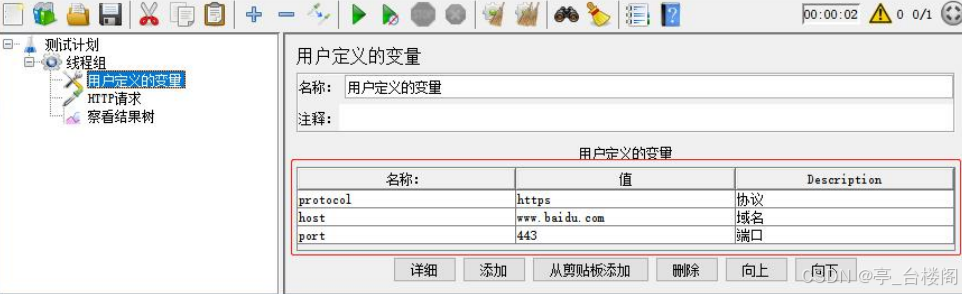
用户定义的变量:
什么时候使用用户定义的变量?
定义全局变量
使用“用户定义的变量”进行参数化的步骤?
1. 添加线程组
2. 添加用户定义的变量。
格式:变量名 – 变量值
3. 添加HTTP请求,
引用定义的变量名
。格式:
${变量名}
4. 添加查看结果树
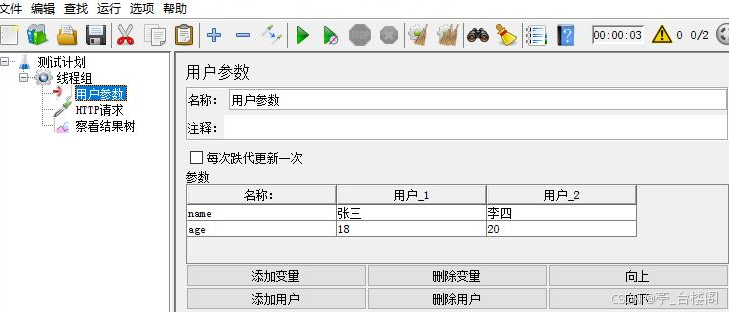
用户参数:
针对同一组参数,当不同的用户来访问时,可以获取到不同的值
位置:
测试计划 --> 线程组--> 前置处理器 --> 用户参数
参数:
使用“用户参数”进行参数化的步骤?
1. 添加线程组,设置线程数为n(表示模拟的用户数)
2. 添加用户参数
第一列添加多个变量名
后续每一列为一组用户的数据
3. 添加HTTP请求,
引用定义的变量名
。格式:
${变量名}
4. 添加查看结果树
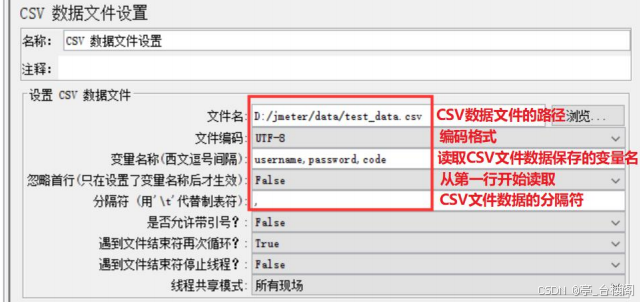
JMeter参数化 - CSV数据文件设置:让不同用户在多次循环时,可以取到不同的值
位置:
测试计划 --> 线程组--> 配置元件 --> CSV 数据文件设置
参数:
使用“CSV数据文件设置”进行参数化的步骤?
1. 定义CSV数据文件
2. 添加线程组
3. 添加CSV数据文件设置
4. 添加HTTP请求,
引用定义的变量名
。格式:
${变量名}
5. 添加查看结果树
JMeter参数化 - 函数(__counter) :
计数函数,一般做执行次数统计使用
位置:
在菜单中选择--> 选项 --> 函数助手对话框
设置:
TRUE
,每个用户有自己的计数器;
FALSE
,使用全局计数器
Name of variable in which to store the result (optional):用于存储结果的变量名(可选)
使用:
生成-复制
参数:
使用“counter函数”进行参数化的步骤?
1. 添加线程组,设置虚拟用户数和循环次数
2. 生成__counter函数
3. 添加HTTP请求,使用__counter函数。格式:
${__counter(FALSE,)}
4. 添加查看结果树
什么是参数化?
把测试数据组织起来,用
不同的测试数据
调用
相同的测试方法
。
4种参数化方式有何不同?如何选择适当的方式?
用户定义的变量:
- 作用:定义全局变量
- 局限性:每次取值(无论是否相同的用户)都是固定值
用户参数:
- 作用:保证不同的用户针对同一组参数,可以取到不同的值
- 局限性:同一个用户在多次循环时,取到相同的值
CSV数据文件设置:
- 作用:保证不同的用户及同一用户多次循环时,都可以取到不同的值
- 局限性:需要手动进行测试数据的设置
函数:
- 作用:保证不同的用户及多次循环时,都可以取到不同的值,不需要提前设置
- 局限性:输入数据有特定的业务要求时无法使用(如:登录时的用户名密码)
JMeter断言:
让程序
自动判断
预期结果和实际
结果是否一致。
JMeter在请求的返回层面有个自动判断机制(响应状态码)
- 但是请求成功了,并不代表结果一定正确,因此需要检测机制提高测试准确性。
JMeter中常用断言:
- 响应断言
- JSON断言
- 持续时间断言(Duration Assertion)
JMeter断言 – 响应断言
作用:
对HTTP请求的任意格式的响应结果进行断言
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 断言 --> 响应断言
参数配置详细介绍:
测试字段:要检查的项(实际结果)
响应文本: 来自服务器的响应文本,即主体
响应代码: 响应的状态码,例如:200
响应信息: 响应的信息,例如:OK
Response Headers: 响应头部
Request Headers: 请求头部
Request Data: 请求数据
URL样本: 请求URL
Document(text): 响应的整个文档
忽略状态:忽略返回的响应状态码
模式匹配规则:比较方式
包括:文本包含指定的正则表达式
匹配:整个文本匹配指定的正则表达式
Equals:整个返回结果的文本等于指定的字符串(区分大小写)
Substring:返回结果的文本包含指定字符串(区分大小写)
否:取反
或者:如果存在多个测试模式,
勾选代表逻辑或
(只要有一个模式匹配,则断言就是OK),不勾选代表逻辑与
(所有都必须匹配,断言才是OK)
注意:Equals和Substring模式是普通字符串,而包括和匹配模式
是正则表达式
测试模式:预期结果
即填写你指定的结果(可填写多个),按钮【添加】、【删除】是进行指定内容的管理
什么时候可以使用响应断言?
任意HTTP请求的响应结果,都可以使用响应断言
使用“响应断言”的操作步骤?
1. 添加线程组
2. 添加HTTP请求
3. 添加响应断言
测试字段:要检查的项(实际结果)
模式匹配规则:比较方式
测试模式:预期结果
4. 添加查看结果树
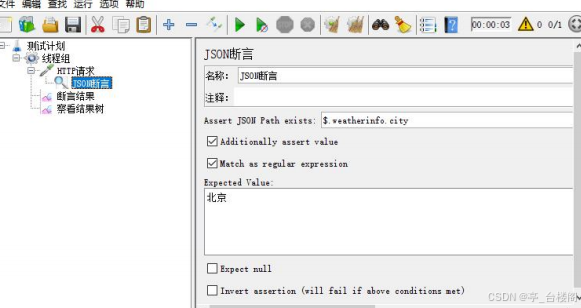
JSON断言:
对HTTP请求的JSON格式的响应结果进行断言
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 断言 --> JSON断言
参数介绍:
Assert JSON Path exists
:用于断言的JSON元素的路径
(实际结
果)
Additionally assert value
:如果您想要用某个值生成断言,请 选择复选框
Match as regular expression
:使用正则表达式断言
Expected Value
:期望值
(期望结果)
Expect null
:如果希望为空,请选择复选框
Invert assertion (will fail if above conditions met)
:反转断言(如果满足以上条件则失败)
什么时候可以使用JSON断言?
对HTTP请求的响应结果为JSON格式时,可以使用JSON断言
使用“JSON断言”的操作步骤?
1. 添加线程组
2. 添加HTTP请求
3. 添加JSON断言
填写Assert JSON Path exists
(实际结果-json路径)
勾选Additionally assert value
填写Expected Value
(期望结果)
4. 添加查看结果树
断言持续时间:
检查HTTP请求的响应时间是否超出要求范围
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 断言 --> 断言持续时间
参数:
- 持续时间(毫秒):HTTP请求允许的
最大响应时间
(
单位:毫秒
)。 超过则认为失败
什么时候可以使用断言持续时间?
测试HTTP请求的响应时间是否满足要求时,可以使用断言持续时间
使用“断言持续时间”的操作步骤?
1. 添加线程组
2. 添加HTTP请求
3. 添加断言持续时间
填写持续时间(允许的最大响应时间,单位:ms)
4. 添加查看结果树
什么是断言?
让程序
自动判断
预期结果和实际
结果是否一致。
3种断言方式有何不同?如何选择适当的方式?
响应断言: 可以针对
任意格式
的响应数据进行断言
JSON断言: 当响应数据为
JSON格式
时,优先使用JSON断言
断言持续时间: 检查HTTP请求的
响应时间
是否满足要求时,使用断言持续时间
Jmeter会自动判断响应状态码(如果状态码为4xx/5xx,判定为失败)
JMeter关联
关联:当请求之间有
依赖关系
,比如一个请求的入参是另一个请求返
回的数据,这时候就需要用到关联处理。
JMeter中常用的关联方法:
- 正则表达式提取器
- XPath提取器
- JSON提取器
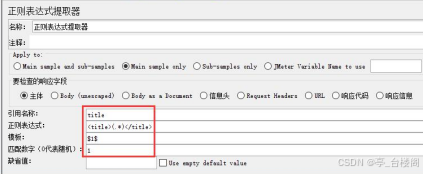
JMeter关联 – 正则表达式提取器
作用:
针对任意格式的响应数据进行提取
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 后置处理器 --> 正则表达式提取器
参数介绍:
引用名称:
存放提取出的值的
参数名称
,
供下一个请求引用,如填写title,则可用${title}引用它
正则表达式:
左边界(.*?)右边界
()
:括起来的部分就是要提取的。
.
:匹配任何字符串。
*
:0次或多次。
?
:不要太贪婪,在找到第一个匹配项后停止。
模板:
用$$引用起来
,如果在正则表达式中有多个提取值,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
匹配数字:
0代表随机取值,
-1代表全部取值
,
1代表取第一个值
缺省值:
如果参数没有取得到值,那默认给一个值让它取。
什么时候可以使用正则表达式提取器?
任意格式的响应数据,都可以使用正则表达式提取器进行提取
使用“正则表达式提取器”的操作步骤?
1. 添加线程组
2. 添加HTTP请求-传智播客
3. 添加正则表达式提取器
引用名称:存放提取出的值的
参数名称
,如填写title
正则表达式:
左边界(.*?)右边界
模板:
用$$引用起来
,表示解析出第几个()的值
匹配数字:
1表示第1个值,-1表示所有取值
4. 添加HTTP请求-百度
引用正则表达式中的引用名称。如:用${title}引用它
5. 添加查看结果树
JMeter关联 – XPath提取器
作用:
针对HTML格式的响应结果数据进行提取
位置:
添加方式:测试计划 --> 线程组--> HTTP请求 --> (右键添加) 后置处理器 --> XPath提取器
参数介绍:
Use Tidy (tolerant parser):
当需要处理的页面是HTML格式时,必须选中该选项
当需要处理的页面是XML或XHTML格式时,取消选中该选项。
引用名称:
存放提取出的值的参数名称
XPath Query:
用于提取值的XPath表达式
匹配数字:
如果XPath路径查询出许多结果,则可以选择提取哪个。 0:表示随机,-1:表示提取所有结果,1表示第一个值
缺省值:
参数的默认值
什么时候可以使用XPATH提取器?
针对HTML格式的响应数据,可以使用XPATH提取器进行提取
使用“Xpath提取器”的操作步骤?
1. 添加线程组
2. 添加HTTP请求-传智播客
3. 添加XPATH提取器
勾选Use Tidy
(tolerant parser)
引用名称:存放提取出的值的
参数名称
。如:填写title
XPath Query:用于提取值的
XPath表达式
匹配数字:0:表示随机,
-1:表示提取所有结果,1表示第一个值
4. 添加HTTP请求-百度
引用正则表达式中的引用名称。如:用
${title}引用
它
5. 添加查看结果树
JMeter关联 – JSON提取器
作用:
针对JSON格式的响应结果数据进行提取
位置:
添加方式:测试计划 --> 线程组--> HTTP请求 --> (右键添加) 后置处理器 --> JSON提取器
参数介绍:
Names of created variables:
存放提取出的值的参数名称
JSON Path Expressions:
JSON路径表达式
Match No:
如果JSON路径匹配出许多结果,则可以选择提取哪个。0 :表示随机,-1:表示提取所有结果,1表示第一个值
Default Values:
参数的默认值
什么时候可以使用JSON提取器?
针对JSON格式的响应数据,可以使用JSON提取器进行提取
使用“JSON提取器”的操作步骤?
1. 添加线程组
2. 添加HTTP请求-天气
3. 添加JSON提取器
Names of created variables:存放提取出的值的
参数名称
。如:city
JSON Path Expressions:用于提取值的
JSON路径表达式
Match No: 0:表示随机,
-1:表示提取所有结果,1表示第一个值
4. 添加HTTP请求-百度
引用正则表达式中的引用名称。如:用
${city}引用
它
5. 添加查看结果树
JMeter关联 – JMeter属性
JMeter属性的配置函数:
__setProperty函数:将值
保存成JMeter属性
__property函数:在其他线程组中使用property函数
读取属性
__setProperty函数执行
(保存JMeter属性):
需要通过
BeanShell取样器
来执行
__property函数
(读取属性):
在其他线程组中使用property函数
(1)什么时候需要使用JMeter属性?
需要实现跨线程组的数据传递时,可以使用JMeter属性
(2)使用“JMeter属性”的操作步骤?
1. 添加线程组1
2. 添加HTTP请求-天气
3. 添加JSON提取器
4. 添加BeanShell取样器(将JSON提取器提取的值保存为JMeter属性)
保存JMeter属性:
${__setProperty(pro_city,${city},)}
5. 添加线程组2
6. 添加HTTP请求-百度
(读取JMeter属性)
读取JMeter属性:${__property(pro_city,,)}
7. 添加查看结果树
什么是关联?
当请求之间有
依赖关系
,比如一个请求的入参是另一个请求返回的数据
,这时候就需要用到
关联处理。
几种关联方式有何不同?如何选择适当的方式?
同一个线程组内
,多个请求之间的关联:
如果响应数据为
JSON格式
,优先使用
JSON提取器
进行关联
如果响应数据为
HTML格式
,优先使用
XPath提取器
进行关联
如果JSON提取器和XPath提取器都无法实现关联,使用
正则表达式提取器
进行补充 —— 针对
任意格式
的响应数据
不同线程组之间
,多个请求之间的关联:
JSON提取器 +
JMeter属性
XPath提取器 +
JMeter属性
正则表达式提取器 +
JMeter属性
JMeter录制脚本
:在
没有接口文档的旧项目
当中,
快速录制web页面产生的http接口请求
,
帮助编

写接口测试脚本
。
录制时,JMeter作为
代理服务器
来拦截和转发请求与响应数据
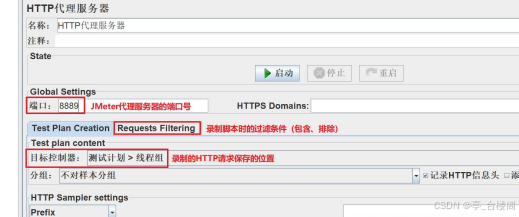
JMeter录制脚本的操作步骤:
1. 添加HTTP代理服务器,并进行配置
加HTTP代理服务器:测试计划(右键)-> 非测试元件->HTTP代理服务器
配置代理服务器的参数
2. 开启windows操作系统的浏览器代理
3.启动代理服务器,开始录制
4.在浏览器页面中进行操作,成功后,就能在JMeter当中看到抓取到的接口请求了。
(1)什么时候需要使用JMeter录制脚本?
在
没有接口文档的旧项目
当中,
通过录制http接口请求的方
式,来
快速编
写接口测试脚本
。
(2)JMeter录制脚本的操作步骤?
1. 添加HTTP代理服务器,并进行配置
设置端口:代理服务器的端口号
目标控制器:录制的脚本放到哪个容器(线程组)中
Requests Filtering(过滤条件 –
url匹配正则表达式
)
:
包含模式:包含此项。如:.*localhost.* ;
排除模式:不包含此项 如:.*.jpg.*.png .*.js
2. 开启windows操作系统的浏览器代理
配置浏览器代理:JMeter代理服务器的IP、端口号
3. 启动代理服务器,开始录制
4. 在浏览器页面中进行操作,成功后,就能在JMeter当中看到抓取到的接口请求了
JMeter直连数据库 (重点)
直连数据库的关键配置:
添加MySQL驱动jar包
方式一:在测试计划面板点击“浏览…“按钮,将你的JDBC驱动添加进来
方式二:将MySQL驱动jar包放入到lib/ext目录下,重启JMeter
配置数据库连接信息
添加方式:测试计划 --> 线程组--> (右键添加) 配置元件 --> JDBC Connection Configuration
参数介绍:
Variable Name:
mysql数据库连接池名称(JDBC请求时要引用)
Database URL:
jdbc:mysql://localhost:3306/tpshop2.0
组成:协议 + 数据库IP + 数据库端口 + 连接的数据库名称
JDBC DRIVER class:
com.mysql.jdbc.Driver(MySQL驱动包位置固定格式 —— 下拉框选择)
Username:
root(连接数据库用户名,如实填写)
Password:
(MySQL数据库密码,如实填写,如果密码为空不写)
添加JDBC请求
添加方式:测试计划 --> 线程组--> 取样器 --> JDBC Request
参数介绍:
Variable Name:
数据库连接池的名字,
需要与JDBC Connection
Configuration的Variable Name Bound Pool名字保持一致
Query Type:
查询操作:选择“Select Statement”
增加、删除、修改操作:选择“Update Statement”
Query:
填写的SQL语句,未尾不要加“;”
Variable names
:保存SQL语句返回结果的变量名
什么时候需要使用JMeter直连数据库?
用作请求的参数化
用作结果的断言
清理测试数据
准备测试数据
JMeter直连数据库?
1. 添加MySQL驱动jar包
在测试计划面板点击“浏览…“按钮,将你的JDBC驱动添加 ——
本脚本可
用
将MySQL驱动jar包放入到lib/ext目录下,重启JMeter ——
所有脚本可用
2. 配置数据库连接信息
数据库连接池名称
、
数据库URL
(协议 + 数据库IP + 数据库端口 + 连接的
数据库名称)、
数据库驱动包
(下拉框选择)、
数据库用户名密码
3. 添加JDBC请求
数据库连接池名称
、
Query Type
、
SQL语句
、
查询结果保存的变量名
JMeter逻辑控制器:
可以按照设定的逻辑控制取样器的执行顺序
JMeter中常用的逻辑控制器:
- 如果(If)控制器
- 循环控制器
- ForEach控制器
(1)IF控制器的作用是什么?
用来控制它下面的测试元素是否运行
(2)使用“IF控制器”的操作步骤?
1. 添加线程组
2. 用户定义的变量
3. 添加If控制器,判断name是否等于baidu
不勾选Interpret Condition,'${name}' == 'baidu‘
勾选,${__jexl3('${name}' == 'baidu',)}
4. 添加HTTP请求,用来访问百度
5. 添加If控制器,判断name是否等于itcast
6. 添加HTTP请求,用来访问传智播客
7. 添加查看结果树
(1)循环控制器的作用是什么?
通过设置循环次数,来实现循环发送请求
(2)使用“循环控制器”的操作步骤?
1. 添加线程组
2. 添加循环控制器 —— 设置循环次数
3. 添加HTTP请求
4. 添加查看结果树
(3)思考:线程组属性可以控制循环次数,那么循环控制器有什么
用?作用域不同
(1)
ForEach
控制器的作用是什么?
一般和用户自定义变量或者正则表达式提取器一起使用,读取返回结果中一系列相关的变量值
(2)使用“
ForEach
控制器”的操作步骤?
1. 添加线程组
2. 添加用户定义的变量/正则表达式提取器
返回一组变量:
相同的变量名+连续的数字后缀
,如:name_1..name_3
3. 添加ForEach控制器
输入变量前缀:要读取的输入变量的
固定前缀
,如:name
开始循环字段:要读取的输入变量
后缀数字的最小值-1
,如:0
结束循环字段:要读取的输入变量
后缀数字的最大值
,如:3
输出变量名称:读取输入变量的值后保存的
新变量名
,如word
4. 添加HTTP请求-百度
引用ForEach控制器中
保存的新变量名
,如:${word}
JMeter定时器 - 同步定时器
同步定时器:阻塞线程(累积一定的请求),当在
规定的时间内
达到
一定的线程数量
,这些线程会
在同一个时间点
一起释放
,瞬间产生很大的压力。
在JMeter中叫做
同步定时器
,在Loadrunner中又叫
集合点
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 定时器 --> Synchronizing Timer
参数介绍:
Number of Simulated Users to Group by:
模拟用户的数量,即指定
同时释放的线程数数量
。 -
若设置为0,等于设置为线程组中的线程数量
Timeout in milliseconds:
超时时间,即
超时多少毫秒后同时释放
指定的线程数;
如果设置为0,该定时器将会等待线程数达到了设置的线程数才释放,若没有达到设置的线程数会一直死等。
如果大于0,那么如果超过Timeout in milliseconds中设置的最大等待时间后还没达到设置的线程数,Timer将不再等待,释放已到达的线程。默认为0
(1)什么时候需要使用同步定时器?
测试抢购、秒杀或者抢红包等高并发的场景时使用
(2)使用同步定时器的操作步骤?
1. 添加线程组,设置线程数为n
2. 添加HTTP请求
3. 添加同步定时器
设置并发线程数:同时发送请求的虚拟用户数
设置超时时间:
建议设置
:不设置的话,若没有达到设置的线程数会一直死等
不能设置太小
:等待时间后还没达到设置的线程数,会释放已到达的线程
4. 添加查看结果树
5. 添加监听器-聚合报告
JMeter定时器 - 常数吞吐量定时器
作用:
让JMeter按
指定的吞吐量
执行,以
每分钟为单位
。
位置:
测试计划 --> 线程组--> HTTP请求 --> (右键添加) 定时器 --> Constant Throughput Timer
参数介绍:
Target throughput(in samples per minute):
目标吞吐量。注意这里是每个用户每分钟发送的请求数
案例要求:
模拟用户真实的业务场景要求:20 QPS
如果线程数设置为1,则目标吞吐量设置为 20 * 60 = 1200
如果线程数设置为2,则目标吞吐量设置为 20 * 60 / 2 = 600
操作步骤:
1. 添加线程组,循环次数设置成永远
2. 添加HTTP请求
3. 添加常数吞吐定时器
4. 添加查看结果树
5. 添加监听器-聚合报告
查看聚合报告的 Throughput 字段,实际值围绕设置的QPS值上下波动
(1)什么时候需要使用常数吞吐量定时器?
需要
按指定的吞吐量发送请求
时,可以使用常数吞吐量定时器
(2)使用常数吞吐量定时器的操作步骤?
1. 添加线程组,循环次数设置成永远
2. 添加HTTP请求
3. 添加常数吞吐定时器
设置目标吞吐量:每个用户每分钟发送的请求数
计算方法:要求QPS * 60 / 线程数
4. 添加查看结果树
5. 添加监听器-聚合报告
JMeter分布式
(1)什么时候需要使用分布式?
单台测试机无法满足用户要求的负载量时,使用多台机器来模拟
(2)JMeter分布式测试的原理?
执行时,
控制机会把脚本发送到每台代理机
上
代理机拿到脚本后就开始执行
,接收服务器返回的响应
执行完成后,
代理机会把结果回传给控制机
(3)JMeter分布式的配置和使用?
配置:
代理机:
修改服务端口server_port,禁用RMI SSL开关
控制机:
配置代理机远程地址remote_hosts,禁用RMI SSL开关
使用:
代理机:
命令行方式启动,
运行jmeter-server.bat文件
控制机:
运行jmeter.bat文件
,启动JMeter,运行-->远程启动/远程全部启动
JMeter测试报告 - 聚合报告
作用:
收集性能测试结束后,系统的各项性能指标。如:响应时间、并发数、吞吐量、错误率等
位置:
测试计划->右键->监听器->聚合报告
参数介绍:
-
Label:
每个请求的名称
-
样本:
各请求发出的数量
-
平均值:
平均响应时间(单位:毫秒)
-
中位数:
中位数,50% <= 时间
-
90%百分比:
90% <= 时间
-
95%百分比:
95% <= 时间
-
99%百分比:
99% <= 时间
-
最小值:
最小响应时间
-
最大值:
最大响应时间
-
异常%:
请求的错误率
-
吞吐量:
吞吐量。默认情况下表示每秒完成的请求
数,一般认为它为TPS
。
-
接收 KB/sec:
每秒接收到的千字节数
-
发送 KB/sec:
每秒发送的千字节数
JMeter测试报告 - html测试报告
作用:
JMeter支持生成HTML测试报告,以便从测试计划中获得图表和统计信息
命令:
jmeter -n -t [jmx file] -l [result file] -e -o [html report folder]
eg: jmeter -n -t hello.jmx -l result.jtl -e -o ./report
参数描述:
-n:
非GUI模式执行JMeter
-t [jmx file]:
测试计划保存的路径及.jmx文件名,路径可以是相对路径也可以是绝对路径
-l [result file]:
保存生成测试结果的文件,jtl文件格式
-e:
测试结束后,生成测试报告
-o [html report folder]:
存放生成测试报告的路径,路径可以是相对路径也可以是绝对路径
注意
:
result.jtl和report会自动生成,
如果在执行命令时result.jtl和report已存在,必须用先删
除
,否则在运行命令时就会报错
(1)聚合报告的核心内容有哪些?
响应时间、吞吐量、错误率、网路速率
(2)JMeter生成html测试报告的命令?
jmeter -n -t hello.jmx -l result.jtl -e -o ./report
注意事项:
-
如果在执行命令时result.jtl和report已存在,必须用先删除
(3)JMeter的HTML测试报告的内容?
性能统计仪表盘
性能测试过程中的详细信息报表
性能测试时TPS计算
性能测试时的TPS,大都是根据用户真实的业务数据(运营数据)来计算的
(1)并发数计算方法有哪几种?作用有什么区别?
普通方法:
- 并发数TPS = 总请求数/总时间
- 作用:可以满足系统最最基本的应用场景(每天的总请求数)的要求。
二八原则:
- 并发数TPS = 总请求数 * 80% / 总时间 * 20%
- 作用:可以满足绝大多数情况下,用户真实的业务场景要求。
根据业务运营数据的统计计算(通常用来做
稳定性测试
)
- 并发数TPS = 有效请求数 * 80% / 有效时间 * 20%
- 作用:可以满足绝大多数情况下用户真实的业务场景要求(当运营数据的统计越精确,
计算结果越准确)
根据用户峰值业务操作来计算(通常用来做
压力测试
)
- 并发数TPS = 峰值请求数 / 峰值时间 * 系数
- 作用:专门用于满足极端的用户业务场景下的性能需求
性能测试常用图表:
(1)Concurrency Thread Group 线程组的作用是什么?
阶梯加压
图形界面显示运行状态
(2)Transactions per Second和Bytes Throughput per Second有什
么作用?
•
Transactions per Second:作用是统计各个事务每秒钟成功的事务个数
•
Bytes Throughput per Second:作用是查看服务器吞吐流量
(3)Transactions per Second和聚合报告中的TPS在性能测试时的作
用有何不同,以哪个为准?
• 性能测试的结果统计,以聚合报告的结果为准
• 每秒性能指标的作用是:查看系统长时间运行过程中是否有异常出现,有则进一步分析
PerfMon组件监控服务器资源
(1)PerfMon组件的作用?
用来监控服务端的性能资源指标,包括cpu、内存、磁盘、网络等性能数据
(2)PerFMon组件监服务器控资源指标的步骤?
1. 下载ServerAgent-2.2.3.zip,并上传到服务器上进行解压
2. 启动ServerAgent程序
• 如果是windows运行startAgent.bat
• 如果是linux运行startAgent.sh
3. 编写JMeter脚本,配置运行时间
4. 添加PerFmon组件
• 服务器IP
• ServerAgent程序端口
• 待监控的指标


















![[Linux]:线程(三)](https://img-blog.csdnimg.cn/img_convert/22bc344623b8b6a0e6231fc450500f40.jpeg)