💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
本人主要分享计算机核心技术:系统维护、数据库、网络安全、自动化运维、容器技术、云计算、人工智能、运维开发、算法结构、物联网、JAVA 、Python、PHP、C、C++等。
不同类型针对性训练,提升逻辑思维,剑指大厂,非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。
2.1 urllib库的使用(非重点)
urllib的官方文档
urllib是Python中自带的HTTP请求库,也就是说不用额外安装就可以使用,它包含如下四个模块:
requests:基本的HTTP请求模块,可以模拟发送请求
error:异常处理模块
parse:一个工具模块,提供了许多URL处理方法,比如拆分、解析、合并等。
robotparser:它主要用来识别网站的robots.txt文件,让后判断哪些内容可以爬取,哪些不能爬取,用得比较少。
2.1.1 request模块
发送请求
# 2.1 使用urllib库中的request模块发送一个请求的例子
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))使用request.urlopen()来向百度首页发起请求,返回的是http.client.HTTPResponse对象,这个对象主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等属性。将返回的HTML代码以utf-8的编码方式读取并打印出来。上面的代码执行后将返回百度的主页的HTML代码。
我运行的效果如下:
<!DOCTYPE html><!--STATUS OK-->
<html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取
信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。">
后面省略无数字......接下来再看这个例子:
# 2.2 使用urllib中的request模块发起一个请求并获取response对象中的信息的例子
# 2.2 使用urllib中的request模块发起一个请求并获取response对象中的信息的例子
import urllib.request
response = urllib.request.urlopen("http://www.python.org")
print(response.read().decode('utf-8')[:100]) # 截取返回的html代码的前100个字符的信息
print("response的类型为:" + str(type(response)))
print("response的状态为:" + str(response.status))
print("response的响应的头信息:" + str(response.getheaders()))
print("response的响应头中的Server值为:" + str(response.getheader('Server')))上面的代码使用urlopen()方法向指定的链接发起了一个请求,得到一个HTTPResponse对象,然后调用HTTPResponse的方法和属性来获取请求的状态、请求头信息等
下面是我的执行结果:
<!doctype html>
<!--[if lt IE 7]> <html class="no-js ie6 lt-ie7 lt-ie8 lt-ie9"> <![endif]-->
<!-
response的类型为:<class 'http.client.HTTPResponse'>
response的状态为:200
response的响应的头信息:[('Connection', 'close'), ('Content-Length', '50890'), ('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'DENY'), ('Via', '1.1 vegur, 1.1 varnish, 1.1 varnish'), ('Accept-Ranges', 'bytes'), ('Date', 'Mon, 17 May 2021 08:59:57 GMT'), ('Age', '1660'), ('X-Served-By', 'cache-bwi5163-BWI, cache-hkg17920-HKG'), ('X-Cache', 'HIT, HIT'), ('X-Cache-Hits', '1, 3886'), ('X-Timer', 'S1621241997.260514,VS0,VE0'), ('Vary', 'Cookie'), ('Strict-Transport-Security', 'max-age=63072000; includeSubDomains')]
response的响应头中的Server值为:nginxdata参数
data参数是可选的,该参数是bytes类型,需要使用bytes()方法将字典转化为字节类型,并且,该参数只能在POST请求中使用。
# 2.3 data参数的使用
import urllib.request
# 使用urllib中的parse模块中的urlencode方法来将字典转化为字节类型,编码方式为utf-8
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())这次我们请求的是http://httpbin.org/post这个网址,这个网址可以提供http请求测试,它可以返回请求的一些信息,其中包括我们传递的data参数。
timeout参数
timeout参数用来设置超时时间,单位为秒,意思是如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常。
# 2.4 timeout参数的使用
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com', timeout=1)
print(response.read())运行结果就不展示了。
其他参数
除了data参数和timeout参数外,还有context参数,它必须是ssl.SSLContext类型,用来指定SSL设置
Request类
urlopen()可以实现基本的请求的发起,但这不能构造一个完整的请求,如果要在请求中加入Headers等信息,就可以利用更强大的Request类来构建。
# 2.5 Request类的使用
import urllib.request
request = urllib.request.Request('https://python.org')
print(type(request))
response = urllib.request.urlopen(request) # 传入的是Request对象
print(response.read().decode('utf-8'))request的构造方法:
Requests(url, data, headers, origin_host, unverifiablem, method)
url:请求的url链接
data:必须为字节流(bytes)类型
headers:请求头信息
origin_req_host:请求方的host名称或者IP地址
unverifiable:表示这个请求是否是无法验证的,默认为False。
method:指示请求使用的方法,比如:GET、POST、PUT等
下面是例子:
# 2.6 Request类的使用
from urllib import request, parse
url = "http://httpbin.org/get"
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='GET')
response = request.urlopen(req)
print(response.read().decode('utf-8'))我们依然请求的是测试网址http://httpbin.org/get,它会返回我们发起的请求信息,下面是我的运行结果:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)",
"X-Amzn-Trace-Id": "Root=1-60a236ed-01f68c862b09c8934983ae80"
},
"origin": "221.176.140.213",
"url": "http://httpbin.org/get"
}从结果中,我们可以看到我们发起的请求中包含了我们自己设置的User-Agent,Host和我们请求中包含的数据 ‘name’: ‘Germey’。
2.1.2 error模块
urllib中的error模块定义了由request模块产生的异常,如果出现了问题,request模块就会抛出error模块中的异常。
下面介绍其中用得比较多的两个异常:URLError和HTTPError。
URLError
URLError类是error异常模块的基类,由request模块产生的异常都可以通过捕获这个异常来处理。
# 2.7 URLError的使用例子
from urllib import request, error
# 打开一个不存在的网页
try:
response = request.urlopen('https://casdfasf.com/index.htm')
except error.URLError as e:
print(e.reason)运行结果:
[Errno 11001] getaddrinfo failedHTTPError
它是URLError的子类,专门用来处理HTTP请求错误,比如认证请求失败等。它有如下3个属性:
code:返回HTTP状态码
reason:返回错误的原因
headers:返回请求头
# 2.8 HTTPError对象的属性
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')运行结果:
Not Found
404
Server: GitHub.com
Date: Tue, 16 Feb 2021 03:01:45 GMT
Content-Type: text/html; charset=utf-8
X-NWS-UUID-VERIFY: 8e28a376520626e0b40a8367b1c3ef01
Access-Control-Allow-Origin: *
ETag: "6026a4f6-c62c"
x-proxy-cache: MISS
X-GitHub-Request-Id: 0D4A:288A:10EE94:125FAD:602B33C2
Accept-Ranges: bytes
Age: 471
Via: 1.1 varnish
X-Served-By: cache-tyo11941-TYO
X-Cache: HIT
X-Cache-Hits: 0
X-Timer: S1613444506.169026,VS0,VE0
Vary: Accept-Encoding
X-Fastly-Request-ID: 9799b7e3df8bdc203561b19afc32bb5803c1f03c
X-Daa-Tunnel: hop_count=2
X-Cache-Lookup: Hit From Upstream
X-Cache-Lookup: Hit From Inner Cluster
Content-Length: 50732
X-NWS-LOG-UUID: 5426589989384885430
Connection: close
X-Cache-Lookup: Cache Miss2.1.3 parse模块
parse模块是用来处理url的模块,它可以实现对url各部分的抽取、合并以及连接装换等。
下面介绍parse模块中常用的几个方法:
urlparse()
实现url的识别和分段
# 2.9 urllib库中parse模块中urlparse()方法的使用
from urllib.parse import urlparse
result = urlparse('http://www.biadu.com/index.html;user?id=5#comment')
print(type(result), result)
result1 = urlparse('www.biadu.com/index.html;user?id=5#comment', scheme='https')
print(type(result1), result1)
result2 = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(type(result2), result2)
result3 = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result3.scheme, result3[0], result3.netloc, result3[1], sep="\n")运行结果:
<class 'urllib.parse.ParseResult'> ParseResult(scheme='http', netloc='www.biadu.com', path='/index.html', params='user', query='id=5', fragment='comment')
<class 'urllib.parse.ParseResult'> ParseResult(scheme='https', netloc='', path='www.biadu.com/index.html', params='user', query='id=5', fragment='comment')
<class 'urllib.parse.ParseResult'> ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html#comment', params='', query='', fragment='')
http
http
www.baidu.com
www.baidu.com 可以看到,urlparse()方法将url解析为6部分,返回的是一个ParseResult对象,这6部分是:
scheme:😕/前面的部分,指协议
netloc:第一个/的前面部分,指域名
path:第一个/后面的部分,指访问路径
params:;后面的部分,指参数
query:问号后面的内容,指查询条件
fragment:#号后面的内容,值锚点
所以,可以得出一个标准的链接格式:
scheme://netloc/path;params?query#fragment一个标准的URL都会符合这个规则,我们就可以使用urlparse()这个方法来将它拆分开来。
urlparse()方法还包含三个参数:
urlstring:必选项,即待解析的URL
scheme:默认协议,假如这个链接没有带协议信息,会将这个作为默认的协议。
allow_fragments:即是否忽略fragment。如果它被设置为false,fragment就会被忽略,它 会被解析为path、params或者query的一部分,而fragment部分为空
urlunparse()
它和urlparse()方法相反,它接收的参数是一个可迭代对象(常见的有列表、数组、集合),它的长度必须为6。
# 2.10 parse模块中的urlparse方法的使用
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))上面的例子中传入的是一个包含6个元素的列表,当然可以是其他类型,如元组,只需要这个可迭代对象的长度为6个就可以了。
urlsplit()
和urlparse()方法相似,只不过它不再单独解析params这一部分,而将params加入到path中,只返回5个结果
# 2.11 parse模块中的urlsplit方法的使用
from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result)运行结果:
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.html;user', query='id=5', fragment='comment')urlunsplit()
和urlsplit()方法相反,传入的参数也是一个可迭代的对象,例如列表、元组等,长度必须为5。
# 2.12 parse模块中的urlunsplit方法的使用
from urllib.parse import urlunsplit
data = ['http', 'www.baidu.com', 'index.html', 'a=6', 'comment']
print(urlunsplit(data))运行结果:
http://www.baidu.com/index.html?a=6#commenturljoin()
该方法接收两个参数,一个是base_url,另外一个是新的url,该方法会分析新url中的scheme、netloc、path三部分的内容是否存在,如果某个不存在,就用base_url中的来替换。
urlencode()
将字典类型转换为url中的参数
# 2.13 parse模块中的urlencode方法的使用
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': '22'
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)运行结果:
http://www.baidu.com?name=germey&age=22parse_qs()、parse_qsl()
parse_qs:反序列化,将get请求参数转化为字典
parse_qsl:反序列化,将get参数转化为元组组成的字典
# 2.14 parse模块中parse_qs和parse_qsl方法的使
from urllib.parse import parse_qs, parse_qsl
# 反序列化,将参数转化为字典类型
query = 'name=germey&age=22'
print(parse_qs(query))
# 反序列化,将参数转化为元组组成的列表
print(parse_qsl(query))运行结果:
{'name': ['germey'], 'age': ['22']}
[('name', 'germey'), ('age', '22')]quote()、unquote()
quote:将内容转化为URL编码的格式,URL中带有中文参数时,有可能会导致乱码的问题,用这个方法就可以将中文字符转化为URL编码。
unquote:和quote()方法相反,将URL解码
# 2.15 parse模块中quote()方法和unquote()方法的使用
from urllib.parse import quote, unquote
keyword = '书包'
url = 'https://www.baidu.com/?wd=' + quote(keyword)
print(url)
url = 'https://www.baidu.com/?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))运行结果:
https://www.baidu.com/?wd=%E4%B9%A6%E5%8C%85
https://www.baidu.com/?wd=壁纸urllib中的robotparse模块可以实现robots协议的分析,用得不多,这里就不再介绍。
2.2 requests库的使用(重点)
学习爬虫,最基础的便是模拟浏览器向服务器发出请求。
requests文档
2.2.1. requests库的介绍
利用Python现有的库可以非常方便的实现网络请求的模拟,常见的有urllib、requests等。requests模块是Python原生的一款基于网络请求的模块,功能非常强大,效率极高。
作用:模拟浏览器发起请求
2.2.2 requests库的安装
requests库是Python的第三方库,需要额外安装,在cmd中输入以下代码使用pip安装:
pip install requests
2.2.3 requests库的使用
要检查是否已经正确安装requests库,在编辑器或Python自带的IDLE中导入requests库:
import requests执行后没有发生错误就说明你已经正确安装了requests库。
也可以在cmd命令行窗口中输入:
pip list
后按回车,就会显示所有pip已安装的第三方库,在列表中看到request库就表明成功安装requests库。
下面介绍Requests库的7个主要方法:
方法 介绍
requests.request() 构造一个请求,支撑以下的各种基础方法,不常用
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET,常用
requests.head() 获取HTML网页头信息的方法,对应于HTTP的
requests.post() 向HTML页面提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTM页面提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML页面提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
2.2.3.1 requests.get()方法
requests.get(url, params=None, **kwargs)
url : 要获取页面的url链接,必选
params :url中的额外参数,字典或字节流格式,可选
**kwargs : 12个控制访问的参数,可选
我们在浏览器中输入一个url后按下enter,其实是发起一个get请求。同样,使用requests库发起一个get请求,可以使用requests库下的get()方法,requests.get()方法可以构造一个向服务器请求资源的Request对象并返回一个包含服务器资源的Response对象。request对象和response对象是requests库中的2个重要对象,response对象包含服务器返回的所有信息,也包含请求的request信息,下面是response对象的属性:
属性 说明
r.status_code HTTP请求的返回状态,200表示成功,404表示失败
r.text HTTP响应内容的字符串形式,即url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容编码方式,如果header中不存在charset,则认为编码为ISO-8859-1,r.text根据r.encoding显示网页内容
r.apparent_encoding 从内容中分析出的响应内容的编码方式(备用编码方式,一般比较准确)
r.content HTTP响应内容的二进制形式
下面是一个使用requests.get()方法访问百度并打印出返回的response对象的各种属性的例子:
import requests
# 2.16 使用requests.get()方法发送一个get()请求
r = requests.get("https://www.baidu.com")
print("r的状态码为:", r.status_code)
print("r的内容为:", r.text)
print("从r的header中推测的响应内容的编码方式为:", r.encoding)
print("从r的内容中分析出来的响应内容编码方式为:", r.apparent_encoding)
print("r内容的二进制形式为:", r.content)2.2.3.2 requests.request()方法
requests.request(method, url, **kwargs)
method : 请求方式,对应get/put/post/head/patch/delete/options7种
url : 要获取页面的url链接
**kwargs : 控制访问的参数,共13个
**kwargs:控制访问的参数,都为可选项:
控制访问参数 说明
params 字典或字节序列,作为参数增加到url中
data 字典、字节序列或文件对象,作为request的内容
json JSON格式的数据,作为request的内容
headers 字典,HTTP定制头
cookies 字典或cookieJar,Request中的cookie
auth 元组,支持HTTP认证功能
files 字典类型,传输文件
timeout 设置超时时间,秒为单位
proxies 字典类型,设置代理服务器,可以增加登录认证
allow_redirects True/False,默认为True,重定向开关
stream True/False,默认为True,获取内容立即下载开关
verify True/False,默认为True,认证SSL证书开关
cert 本地SSL证书路径
下面只介绍几个常用的参数。
params:字典或字节序列,作为参数增加到url中
import requests
# 2.17 请求参数params参数的使用
kv = {"key1": "value1", "key2": "value2"}
r = requests.request('GET', 'http://httpbin.org/get', params=kv)
# 也可写成: r = requests.get('http://httpbin.org/get', params=kv)
print(r.url)
print(r.text)如果向网站http://httpbin.org/get发起一个get请求,该网站会将你的请求头的信息返回回来。
print(r.url)将输出:
http://httpbin.org/get?key1=value1&key2=value2,
可以看到,已经将字典作为参数增加到url中了!
同时上面的代码print(r.text)也将请求放回的信息也打印出来了:
{
“args”: {
“key1”: “value1”,
“key2”: “value2”
},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-600f8cf4-6af557655f1c1a771135e7fb”
},
“origin”: “117.150.137.110”,
“url”: “http://httpbin.org/get?key1=value1&key2=value2”
}
上面就是我们发起的请求的相关信息,有请求头、发起请求的浏览器、参数等。
data:字典、字节序列或文件对象,作为request的内容
import requests
# 2.18 请求参数data的使用
data = 'data'
r = requests.request('POST', 'http://httpbin.org/post', data=data)
# 也可写成: r = requests.post('http://httpbin.org/post', data=data)
# 这发起的是POST请求,可以看3.4
print(r.text)我执行后的结果:
{
“args”: {},
“data”: “data”,
“files”: {},
“form”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “4”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-600f8f3d-46564aa85b91258f2d1c7511”
},
“json”: null,
“origin”: “117.150.137.110”,
“url”: “http://httpbin.org/post”
}
可以看到,"data"已经作为request的内容了。
json:JSON格式的数据,作为request的内容
import requests
# 2.19 请求参数json的使用
kv = {'key1':'value1'}
r = requests.request('POST', 'http://httpbin.org/post', json=kv)
# 也可写成:r = requests.post('http://httpbin.org/post', json=kv)
print(r.text)我执行后的结果:
{
“args”: {},
“data”: “{“key1”: “value1”}”,
“files”: {},
“form”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “18”,
“Content-Type”: “application/json”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-600f8f00-2419855b4f772b4851c12cdd”
},
“json”: {
“key1”: “value1”
},
“origin”: “117.150.137.110”,
“url”: “http://httpbin.org/post”
}
headers:字典、HTTP定制头
请求头Headers提供了关于请求、响应或其他发送实体的信息。对于爬虫而言,请求头非常重要,有很多网站会通过检查请求头来判断请求是不是爬虫发起的。
那如何找到正确的Headers呢?
在Chrome中或其他浏览器打开要请求的网页,右击网页任意处,在弹出的菜单中单击“检查"选项,在这里插入图片描述
点击Network,点击下面的资源列表中的任意一个,我点击的是第一个,在右边弹出的界面中找到Requests Headers,就可以看到Requests Headers中的详细信息:
在这里插入图片描述
我们将Requests Headers中的user-agent对应的信息复制下来,用在下面的代码中:
import requests
# 2.20 请求参数headers的使用
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
r = requests.request('POST', 'http://httpbin.org/post',headers=headers)
# 也可写成: r = requests.post('http://httpbin.org/post',headers=headers)
print(r.text)我的运行结果:
{
“args”: {},
“data”: “”,
“files”: {},
“form”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “0”,
“Host”: “httpbin.org”,
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36”,
“X-Amzn-Trace-Id”: “Root=1-600f9f2f-016953bc4635251a20212054”
},
“json”: null,
“origin”: “117.150.137.110”,
“url”: “http://httpbin.org/post”
}
可以看到,我们的请求头中的user-Agent已经变成我们自己构造的了!
timeout:设置超时时间,秒为单位
import requests
# 2.21 请求参数timeout的使用
r = requests.request('GET', 'http://www.baidu.com', timeout=10)
# 也可写成: r = requests.request('http://www.baidu.com', timeout=10)proxies:字典类型,设定访问代理服务器,可以增加代理验证
import requests
# 2.22 请求参数proxies的使用
pxs = {
'http': 'http://user:pass@10.11.1:12344'
'https': 'https://10.10.10.1.12344'
}
r = requests.request('GET', 'http://www.baidu.com', proxies=pxs)
# 也可写成: r = requests.get('http://www.baidu.com', proxies=pxs)cookies: 字典或cookieJar,Request中的cookie
首先看一下获取cookie的过程:
import requests
# 2.23 请求参数cookies的使用
r = requests.request('GET', 'https://www.baidu.com')
# 也可写成: r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)运行结果如下:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315
第一行是直接打印的cookie信息,我们发现它是RequestCookieJar类型。第二行是遍历的Cookie的信息。我们也可以使用Cookie来保持登录状态,以登录百度为例,首先,登录百度,让后用上面我教你的方法来获取Requests Headers中的user-agent和cookie的信息,将它们设置到Headers中,然后发送请求:
import requests
# 2.24 使用cookies的实例
headers = {
'Cookie': 'BIDUPSID=A41FB9F583DE46FF509B8F9443183F5C;\
PSTM=1604237803; BAIDUID=A41FB9F583DE46FF6179FBA5503669E3:FG=1;\
BDUSS=jdRb3ZMQTR5OX5XYTd1c0J3eUVSWGVlRVgxZ0VlMjRFR3dGMkZZMDlMNWR\
3eWRnRVFBQUFBJCQAAAAAABAAAAEAAACzkIz7vfDP~rarMzIxAAAAAAAAAAAAAAAAAA\
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF02AGBdNgBgW;\
BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33437_33344_\
31253_33284_33398_33459_26350; delPer=0; PSINO=3; BD_HOME=1; BD_UPN=123\
14753; BA_HECTOR=2k808k8h0000a18g001g0v9e80r',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, \
like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.50'
}
r = requests.request('GET', "https://www.baidu.com", headers=headers)
# 也可以写成 r = requests.get("https://www.baidu.com", headers=headers)
print(r.text)这样,我们就实现了用Python模拟登录到百度了,结果中包含我们只有登录百度后才能查看的信息。
2.2.3.3 处理requests库的异常
在上面的代码中,r=requests.get(“https://www.baidu.com”),并不是在任何时候都会成功,如果链接打错或访问的链接不存在,则会产生异常。下面列出了常见的异常:
异常 说明
requests.ConnectionError 网络链接错误,入DNS查询失败,拒绝链接等
requests.HTTPError HTTP错误异常
requests.URLRequired URL缺失异常
requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
requests.ConnectionTimeout 链接远程服务器超时异常
requests.Timeout 请求URL超时,产生超时异常
处理异常,可以使用requests.raise_for_status()方法,该方法在其内部判断r.status_code是否等于200,不需要增加额外的if语句:
import requests
# 2.25 处理发送请求过程中的异常
try:
# 下面的链接错了,将打印输出"参数异常"
r = requests.get("https://www.baidu.co")
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("产生异常")2.2.3.4 发送POST请求
除了GET请求外,有时还需要发送一些编码为表单形式的数据,如在登录的时候请求就为POST,因为如果使用GET请求,密码就会显示在URL中,这是非常不安全的。如果要实现POST请求,其实在上面的介绍requests.request( )方法时就已经实现了,你也可以看看下面用requests.post()方法实现的代码,对比后发现,requests.post()方法其实就是将requests.request(‘POST’, …)方法给包装起来了,这也是为什么说requests.request()方法是实现其他方法的基础了,上面的例子中也建议大家不用requests.request()方法。
import requests
# 2.26 发送POST请求
key_dict = {'key1':'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
# 也可写成: r = requests.request('POST', 'http://httpbin.org/post', data=key_dict)
print(r.text)按照上面的requests.request()方法的13个访问参数,你就会将其应用到requests.get()或requests.post()方法中了吧!在来看一个例子:
import requests
r = requests.get('http://www.baidu.con', timeout=3)
print(r.text)2.2.3.5 requests库的使用实例:TOP250电影数据、抓取二进制数据
打开豆瓣电影TOP250的网站,右键鼠标,使用“检查"功能查看该网页的请求头:
在这里插入图片描述
按照下面提取请求头中的重要信息:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.50',
'Host': 'movie.douban.com'
}使用这个headers构造请求头并爬取前25个电影的名称,提取部分的代码大家看不懂没关系,大家只要看懂请求发起代码的实现:
import requests
from bs4 import BeautifulSoup
# 2.27 发送get请求爬取豆瓣电影的前25个电影
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.50',
'Host': 'movie.douban.com'
}
r = requests.get('https://movie.douban.com/top250', headers=headers, timeout=10)
try:
r.raise_for_status()
soup = BeautifulSoup(r.text, 'html.parser')
movies = soup.find_all('div', {'class': 'hd'})
for each in movies:
print(each.a.span.text.strip())
except:
print("error")执行后将输出:
肖申克的救赎
霸王别姬
阿甘正传
这个杀手不太冷
…
下面是一个抓取favicon.ico图标的例子:
import requests
# 2.28 发送get请求爬取图片
r = requests.get('https://github.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)运行结束后,文件夹中将出现名为favicon.ico的图标。上面的代码先使用get方法发起一个get请求,让后将请求返回的内容以wb(二进制)写入favicon.ico文件中。
2.3 正则表达式(重点)
2.3.1 正则表达式的介绍
本节中,我们看一下正则表达式的相关用法。正则表达式是处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证都不在话下。
正则表达式是用来简介表达一组字符串的表达式,正则表达式是一种通用的字符串表达框架。正则表达式可以用来判断某字符串的特征归属。
在爬虫中,我们使用它来从HTML中提取想要的信息就非常方便了。
例如:正则表达式:
p(Y|YT|YTH|YTHO)?N
它可以表示:
‘PN’
‘PYN’
‘PYTN’
‘PYTHN’
‘PYTHON’
这5个字符串。
正则表达式语法由字符和操作符构成,上面的例子中的() | ? 都是操作符,其他的是字符。
下面是正则表达式的常用的操作符:
操作符 说明 实例
. 表示任何单个字符,除了换行符
[ ] 字符集,对单个字符给出取值范围 [abc]表示a、b、c,[a-z]表示a到z单个字符
[^ ] 非字符集,对单个字符给出排除范围 [^abc]表示非a非b非c的单个字符
* 前一个字符0次或无限次扩展 abc*表示ab、abc、abcc、abccc等
+ 前一个字符1次或无限次扩展 abc+表示abc、abcc、abccc等
? 前一个字符0次或1次扩展 abc?表示ab、abc
| 左右表达式中任意一个 abc|def表示abc、def
{m} 扩展前一个字符m次 ab{2}c表示abbc
{m, n} 扩展前一个字符m至n次(含n) ab{1,2}c表示abc、abbc
^ 匹配字符串开头 ^abc表示abc且在一个字符串的开头
$ 匹配字符串结尾 abc$表示abc且在一个字符的结尾
( ) 分组标记,内部只能使用|操作符 (abc)表示abc,(abc|def)表示abc、def
\d 数字,等价于[0-9]
\D 匹配非数字
\w 匹配非特殊字符,即a-z、A-Z、0-9、_、汉字
\W 匹配特殊字符,即非字母、非数字、非汉字、非_
\n 匹配一个换行符
\s 匹配空白
\S 匹配非空白
正则表达式语法实例:
正则表达式 对应字符串
p(Y|YT|YTH|YTHO)?N ‘PN’,‘PYN’,‘PYTN’,‘PYTHN’,‘PYTHON’
PYTHON+ ‘PYTHON’,‘PYTHONN’,‘PYTHONNN’ …
PY[TH]ON ‘PYTON’,‘PYHON’
PY[^TH]?ON ‘PYON’,‘PYaON’,‘PYbON’,‘PYcON’ …
PY{ : 3}N ‘PN’,‘PYN’,‘PYYN’、‘PYYYN’
经典正则表达式实例:
正则表达式 对应字符串
^[A-Za-z]+$ 由26个字母组成的字符串
^[A-Za-z0-9]+$ 由26个字母和数字组成的字符串
^\d+$ 整数形式的字符串
^[0-9]*[1-9][0-9]*$ 正整数形式的字符串
[1-9]\d{5} 中国境内的邮政编码,6位
[\u4e00-\u9fa5] 匹配中文字符
\d{3}-\d{8}|\d{4}-\d{7} 国内电话号码,010-68913536
\d+.\d+.\d+.\d+. 或 \d{1,3}.\d{1,3}.\d{1,3}.\d{1,3} 匹配IP地址的字符串
其实正则表达式不是Python仅有的,它也出现在其他的编程语言中,只不过语法可能有一点不同。Python中的re库提供了整个正则表达式的实现,下面就来介绍re库。
2.3.2 Re库
2.3.2.1 Re库的介绍
Re库是Python的标准库,主要用于字符串匹配。
re文档
python中的re库文档
2.3.2.2 Re库的使用
要使用Re库,必须先安装re库:
pip install re
re库的主要功能函数:
函数 说明
re.match() 从一个字符串的开始位置起匹配正则表达式
re.search() 在一个字符串中搜索匹配正则表达式的第一个位置
re.findall() 搜索字符串,以列表类型返回全部能匹配的字符串
re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
2.3.2.2.1 re.match()方法
re.match(pattern, string, flags=0)
pattern:正则表达式(可以是字符串或原生字符串)
string:待匹配字符串
flags:正则表达式使用时的控制标记(可选)
常见的控制标记:
常用标记 说明
re.I re.IGNORECASE 忽略正则表达式的大小写,[A-Z]能够匹配小写字符
re.M re.MULTILTNE 正则表达式中的^操作符能够将给定字符串的每一行当做匹配开始
re.S re.DOTALL 正则表达式中的.操作符能够匹配所有的字符,默认匹配除换行符以外的所有字符
match()方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果,否则,返回None:
import re
# 2.29 re.match()方法的使用
content = 'dfs 234 d 3 34'
result = re.match('..', content)
print(type(result))
print(result)
print(result.group())
print(result.span())下面是执行结果:
<class 're.Match'>
<re.Match object; span=(0, 2), match='df'>
df
(0, 2)从结果可以看出,re.match()方法返回一个re.Match对象,该对象有两种常用的方法:
group():匹配结果的内容,如果有分组,则分组是从1开始的,group[1]表示第一个分组,group[2]表示第二个分组,以此类推。
span():输出匹配到的字符串在原字符串中的起始位置,上面的(0,2)中的0和2就代表了df在’dfs 234 d 3 34’中的起始位置。
正则表达式…匹配到的字符串是df。
2.3.2.2.2 使用分组
上面的例子中,我们用match()方法匹配到了我们想要的字符串,但是,如果我们想要的字符串在匹配结果中该怎么办?
例如:
# 2.30 使用分组()
import re
content = 'a1234567atsea'
result = re.match('a\d{7}a', content)
print(result)
print(result.group())
print(result.span())我们要在content中将数字提取出来,我们发现数字都包含在a这个字母中间,所以用a\\d{7}a这个正则表达式来提取,\d表示任意一个数字,再用{7}将\d(任意一个数字)匹配7个,运行结果如下:
a1234567a
(0, 9)我么发现匹配结果中开头和结尾都包含了一个a,如何只得到1234567能,我们只需要使用分组,并将上面的代码修改一下就行了:
import re
# 2.31 分组()的使用
content = 'a1234567atsea'
result = re.match('a(\d{7})a', content)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
a1234567a
(0, 9)
1234567将正则表达式中的\d{7}的两边加上小括号,将其作为一个分组,在匹配结果中使用group(1)将分组取出,可以看到,我们想要的1234567就在匹配结果中的第一个分组中了(group(1))。
2.3.2.2.3 通用匹配和匹配操作符
在使用正则表达式的时候,要熟练使用.*(通用匹配),其中,.可以匹配任意一个字符,*(星)代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了(换行符除外)。
下面来看一个通用匹配(.*)的例子:
import re
# 2.32 通用匹配(.*)的使用
content = 'rtgfga1234567atsea'
result = re.match('.*(\d{7}).*', content)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
rtgfga1234567atsea
(0, 18)
1234567上面的例子中,我们使用了.*来匹配数字前的任意字符串和数字之后的任意字符串,在使用分组获得 我们想要的数字。
有时候,我们要匹配的字符中包括操作符该怎么办?可以使用\来将操作符转义,请看下面的例子:
import re
# 2.33 在正则表达式中使用转义符
content = '12df www.baidu.com df'
result = re.match('12df\s(www\.baidu\.com)\sdf', content)
print(result.group())
print(result.span())
print(result.group(1))在content中,我们要提取www.baidu.com,其中的.是操作符,在写正则表达式时,我们不能用.来匹配. 因为.代表任意一个字符,我们用\来将其转义,就可以用\.来匹配点了。运行结果如下:
12df www.baidu.com df
(0, 21)
www.baidu.com2.3.2.2.4 贪婪与非贪婪
由于.*代表任意字符串,这就有一个问题,例如:
import re
# 2.34 贪婪模式
content = 'dfadas1234567assedf'
result = re.match('df.*(\d+).*df', content)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
dfadas1234567assedf
(0, 19)
7(\d+)分组只匹配到了7这一个数字,我们想要匹配1234567,这是为什么?
这就涉及到了贪婪与非贪婪,由于.*可以匹配任意长度的字符串,所以.*就尽可能的的匹配较多的字符,于是,它就匹配了adas123456,而只让\d+只匹配到一个7。
贪婪:让.*匹配尽可能多的字符
非贪婪:让.*匹配尽可能少的字符
默认.*是贪婪的,要让.*是非贪婪的,只需要在.*的后面加上?,即:.*?
知道如何将.*设置为非贪婪模式后,我们就可以将上面的代码改为如下的代码:
import re
# 2.35 非贪婪模式
content = 'dfadas1234567assedf'
result = re.match('df.*?(\d+).*?df', content)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
dfadas1234567assedf
(0, 19)
1234567这就匹配到了我们想要的1234567了。
2.3.2.2.5 控制标记
正则表达式可以包含一些可选标志修饰符来控制匹配的模式,常见的控制标记大家可以看上面介绍re.match()方法中列出的控制标记表格。下面的代码中,我们任然是提取字符串中的所有数字:
import re
content = 'dfadas1234567assedf'
result = re.match('^df.*?(\d+).*?df$', content)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
dfadas1234567assedf
(0, 19)
1234567我们成功将字符串中的所有数字提取出来了,但是,我将content修改一下:
import re
content = '''dfadas1234567ass
edf'''
result = re.match('^df.*?(\d+).*?df$', content)
print(result.group())
print(result.span())
print(result.group(1))再运行:
Traceback (most recent call last):
File "E:/pycharmWorkStation/venv/Include/draft/test.py", line 6, in <module>
print(result.group())
AttributeError: 'NoneType' object has no attribute 'group'
Process finished with exit code 1发现出错了!原因是.匹配任意一个除了换行符之外的任意字符,所以.*?匹配到换行符就不能匹配了,导致我们没有匹配到任何字符,放回结果为None,而在第6行,我们调用了None的group()方法。
要修正这个错误,我们只需要添加一个re.S控制标记,这个标记的作用是使.匹配任意一个包括换行符在内的字符。
import re
# 2.36 控制标记的使用
content = '''dfadas1234567ass
edf'''
result = re.match('^df.*?(\d+).*?df$', content, re.S)
print(result.group())
print(result.span())
print(result.group(1))运行结果如下:
dfadas1234567ass
edf
(0, 30)
1234567这个re.S控制标记在网页匹配中经常用到。因为HTMl节点经常会换行,加上它,就可以匹配节点与节点中的换行了。
2.3.2.2.6 re.search()
上面讲的match()方法是从字符串的开头开始匹配的,一旦开头就不能匹配,就会导致匹配的失败,请看下面的例子:
import re
# 2.37 re.match()方法是从头开始匹配的
content = 'df colle 123'
result = re.match('colle\s123', content)
print(result.group())
print(result.span())运行结果出错,没有匹配到结果,返回的是None,None对象没有group()方法。
re.search():在匹配时扫描整个字符串,让后返回成功匹配的第一个结果,如果搜索完了还未找到匹配的,就返回None。也就是说,正则表达式可以是字符串的一部分
import re
# 2.38 re.search()方法的使用
content = 'df colle 123'
result = re.search('colle\s123', content)
print(result.group())
print(result.span())运行结果:
colle 123 (3, 12)
2.3.2.2.7 re.findall()
上面所讲到的search()方法可以返回匹配到的第一个内容,如果我们想要得到所有匹配到的结果就可以使用findall()方法。
re.findall():搜索字符串,以列表类型返回全部能匹配的子串
import re
# 2.39 re.findall()方法的使用
content = 'df colle 123 colle 123'
result = re.findall('colle\s123', content)
print(result)运行结果:
['colle 123', 'colle 123']2.3.2.2.8 re.sub()
re.sub():将文本中所以匹配的内容替换为指定的文本
import re
# 2.40 re.sub()方法的使用
content = 'dfcolle123colle123'
content = re.sub('\d', '', content)
print(content)运行结果:
dfcollecolle上面的代码中,我们将content中所有与\d(任意一个数字)匹配的结果替换为’ ',就去掉了content中所有的数字。
2.3.2.2.9 re.compile()
re.compile():将正则字符串编译成正则表达式对象,可以用来复用。
import re
# 2.41 re.compile()方法的使用
content1 = 'dfcolle123colle123'
content2 = 'sdf123e'
content3 = 'ss23dsfd'
pattern = re.compile('\d')
content1 = re.sub(pattern, '', content1)
content2 = re.sub(pattern, '', content2)
content3 = re.sub(pattern, '', content3)
print(content1,' ',content2,' ',content代码中,我们将’\d‘编译为一个正则表达式对象,并在下面的代码中将它复用。
运行结果:
dfcollecolle sdfe ssdsfd2.3.3 使用Re来爬取tx视频
下面来使用re来获取tx视频主页中的所有链接和排行榜中所有的电影名称。
打开tx视频的主页,右击,“检查”,选择“元素”: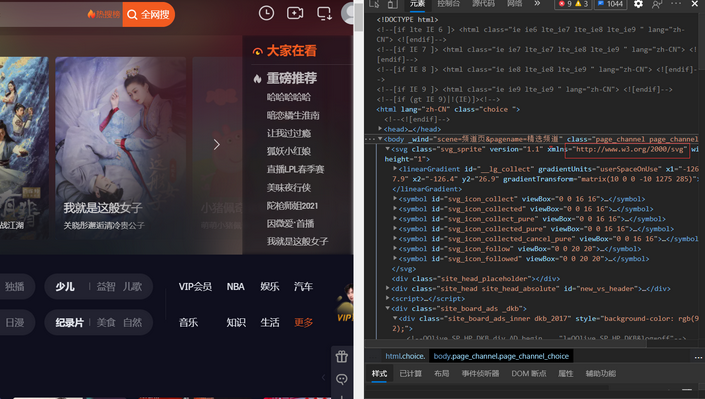
随便找到一个链接,例如我在图中画出来的,根据它写出匹配所有连接的正则表达式:
'"((https|http)://.*?)"'按照如下的图示来获取请求的URL、user-Agent、cookie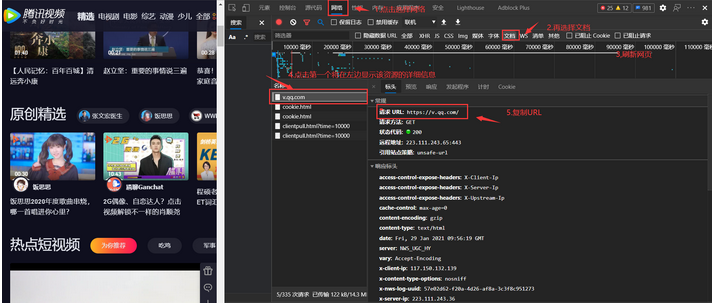
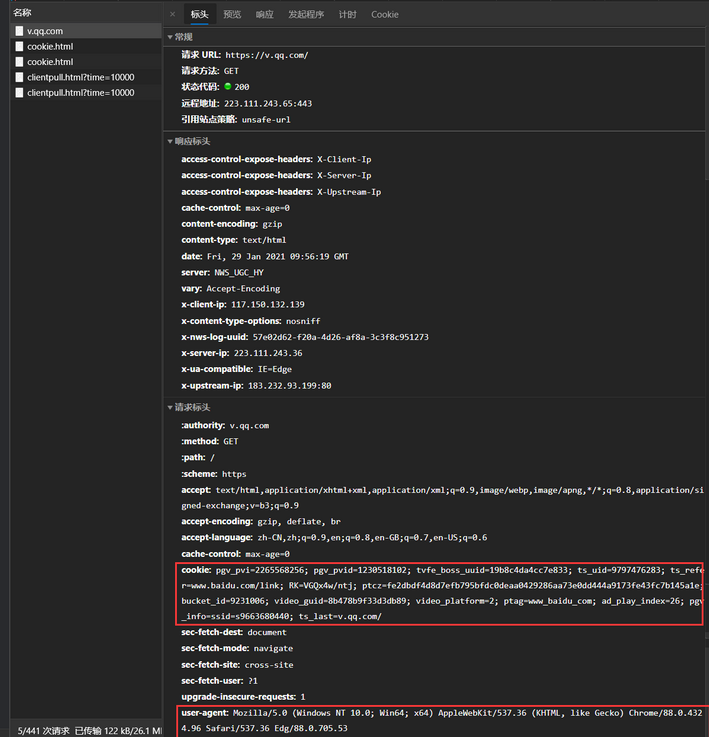
重新回到“元素”:
按照如下操作获取排行榜里中电影所在的元素: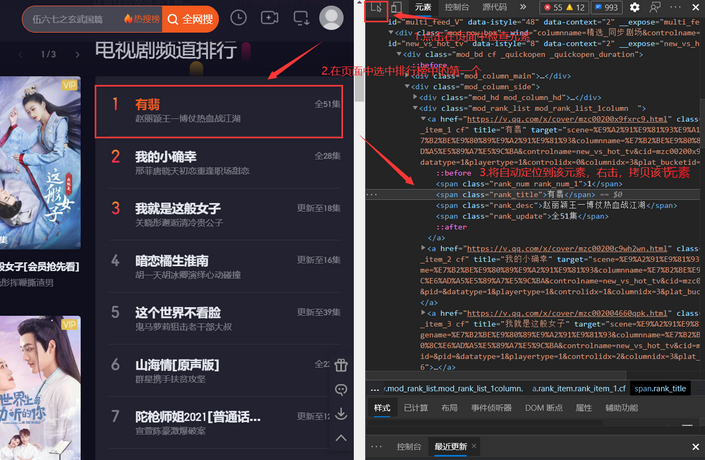
重复上面的操作,多获取几个排行榜中电影名所在的元素:
例如:
<span class="rank_title">有翡</span>
<span class="rank_title">我的小确幸</span>
<span class="rank_title">我就是这般女子</span>根据它写出提取排行榜电影名称的正则表达式为:
‘<span\sclass=“rank_title”>(.*?)’根据上面步骤得出的信息可以写出如下代码:
import re
import requests
# 2.42 使用re爬取腾讯视频的小例子
url = "https://v.qq.com/" # 要爬取的链接
headers = { # 构造请求头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'\
' AppleWebKit/537.36 (KHTML, like Gecko) C'\
'hrome/88.0.4324.96 Safari/537.36 Edg/88.0.'\
'705.53',
'cookie': 'pgv_pvi=2265568256; pgv_pvid=1230518102; tvfe'\
'_boss_uuid=19b8c4da4cc7e833; ts_uid=9797476283'\
'; ts_refer=www.baidu.com/link; RK=VGQx4w/ntj; '\
'ptcz=fe2dbdf4d8d7efb795bfdc0deaa0429286aa73e0dd'\
'444a9173fe43fc7b145a1e; ptag=www_baidu_com; ad_pl'\
'ay_index=77; pgv_info=ssid=s5748488123; ts_last=v.'\
'qq.com/; bucket_id=9231006; video_guid=8b478b9f33d3db'\
'89; video_platform=2; qv_als=cyHwW4MZHa8e9NWRA1161181'\
'1694iJW+zw==',
}
proxy={ # 代理
"HTTP": "113.3.152.88:8118",
"HTTPS":"219.234.5.128:3128",
}
r = requests.get(url=url, headers=headers, proxies=proxy, timeout=3) # 传入url、headers、proxies、timeout构造get请求
print("状态码为:", r.status_code) # 打印状态码
r.encoding = r.apparent_encoding # 将编码方式设置为备用编码方式
pattern = re.compile('"((https|http)://.*?)"', re.S) # 使用re来获取所有的链接,并打印前5个
links = re.findall(pattern, r.text)
print("链接个数为:", len(links))
for i in range(5):
print(links[i][0])
pattern1 = re.compile('<span\sclass="rank_title">(.*?)</span>', re.S) # 使用re来获取排行榜中所有的电影名称并
movies = re.findall(pattern1, r.text)
print() # 将排行榜中的所有电影名称打印出来
for i in movies:
print(i)当然,这是我的代码,大家可以将其中的cookie、user-agent和proxy替换为自己的。
运行结果如下:
状态码为: 200
链接个数为: 1331
http://m.v.qq.com/index.html?ptag=
https://puui.qpic.cn/vupload/0/common_logo_square.png/0
http://www.w3.org/2000/svg
https://v.qq.com/
https://film.qq.com/
有翡
我的小确幸
我就是这般女子
暗恋橘生淮南
这个世界不看脸
山海情[原声版]
陀枪师姐2021[普通话版]
黑白禁区
大秦赋
陈情令
长安伏妖
诡婳狐
除暴
赤狐书生
有匪·破雪斩
蜘蛛侠:平行宇宙
重案行动之捣毒任务
武动乾坤:九重符塔
昆仑神宫
绝对忠诚之国家利益
哈哈哈哈哈
王牌对王牌 第6季
欢乐喜剧人 第7季
我就是演员 第3季
平行时空遇见你
现在就告白 第4季
你好生活 第2季
非常完美
乘风破浪的姐姐slay全场
天赐的声音 第2季
斗罗大陆
开心锤锤
狐妖小红娘
雪鹰领主
武神主宰
灵剑尊
猪屁登
万界仙踪
当然,这是我的运行结果,大家的运行结果可能和我不一样,因为排行榜是会变化的。












![[SAP ABAP] 数据元素添加参数ID(Parameter ID)](https://i-blog.csdnimg.cn/direct/8c8cf95ade974ddc83c7004b8d8a150b.png)