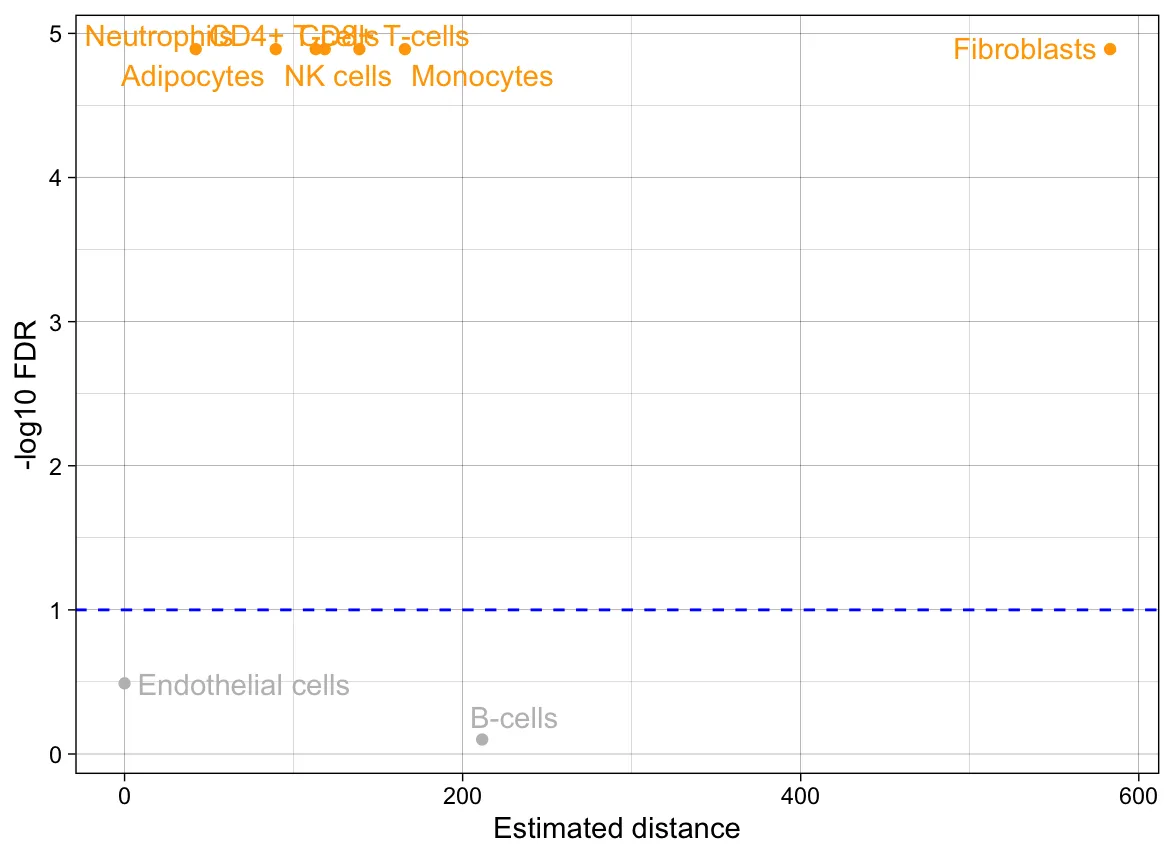
Detailing the Temporary Build Directory
在本章中,我们将尝试了解映像生成后临时构建目录的内容,并了解 BitBake 如何在烘焙过程中使用它。此外,我们还将了解这些目录中的某些内容如何在出现问题时作为有价值的信息来源来帮助我们。
In this chapter, we will try to understand the contents of the temporary build directory after image generation and see how BitBake uses it in the baking process. In addition, we will learn how some of these directories can assist us by acting as a valuable source of information when things do not work as expected.
1,Detailing the build directory
构建目录是每个 Poky 用户的中心信息和工件源。其主要目录如下
The build directory is a central information and artifact source for every Poky user. Its main directories are as follows:
* conf: 这里包含我们用来控制 Poky 和 BitBake 的配置文件。我们在第 2 章 “构建基于 Poky 的系统 ”中首次使用了该目录。它存储了一些配置文件,如 build/conf/local.conf 和 build/conf/bblayers.conf。
* downloads:存储所有下载的工件。它起到下载缓存的作用。我们曾在第 5 章 “掌握 BitBake 工具 ”中详细介绍它。
* sstate-cache: 它包含打包数据的快照。它主要用于加速未来的编译过程,因为它被用作编译过程的缓存。该文件夹在第 7 章 “理解打包支持”中有详细介绍。
* tmp:这是临时构建目录,也是本章的重点。
* conf: This contains the configuration files we use to control Poky and BitBake. We first used this directory in Chapter 2, Baking Our Poky-Based System. It stores configuration files, such as build/conf/local.conf and build/conf/bblayers.conf.
* downloads: This stores all the downloaded artifacts. It works as a download cache. We talked about it in detail in Chapter 5, Grasping the BitBake Tool.
* sstate-cache: This contains the snapshots of the packaged data. It is a cache mainly used to speed up the future build process, as it is used as a cache for the building process. This folder is detailed in Chapter 7, Assimilating Packaging Support.
* tmp: This is the temporary build directory and the main focus of this chapter.
2,Constructing the build directory
在前几章中,我们从抽象的概要上详细了解了 Poky 的输入和输出。我们已经知道,BitBake 使用元数据生成不同类型的人工制品,包括映像。除了生成的工件,BitBake 还会在此过程中创建其他内容,这些内容可根据我们的目标以多种方式使用。
In the previous chapters, we learned about Poky’s inputs and outputs in abstract high-level detail. We already know that BitBake uses metadata to generate different types of artifacts, including images. Besides the generated artifacts, BitBake creates other content during this process, which may be used in several ways, dependent on our goals.
在编译过程中,BitBake 会执行多项任务并不断修改编译目录。因此,我们可以按照通常的 BitBake 执行流程更好地理解它,如下所示:
BitBake performs several tasks and continuously modifies the build directory during the build process. Therefore, we can understand it better by following the usual BitBake execution flow, as follows:
* 获取:BitBake 执行的第一个操作是下载源代码。这一步可能会修改构建目录,因为它会尝试使用缓存下载的源代码副本,或执行下载并将其存储在构建/下载目录中。
* Fetching: The first action executed by BitBake is to download the source code. This step may modify the build directory as it tries to use the cached downloaded copy of the source code or performs the download and stores it inside the
build/download directory.
* 源代码准备: 完成源代码获取后,必须对其进行准备;例如,解压缩压缩包或克隆本地缓存的 Git 目录(来自下载缓存)。准备工作在 build/tmp/work 目录中进行。源代码准备就绪后,就会应用所需的修改(例如,应用必要的补丁并检出正确的 Git 修订版)。
* Source preparation: After completing the source code fetching, it must be prepared; for example, the unpacking of a tarball or a clone of a locally cached Git directory (from the download cache). This preparation happens in the
build/tmp/work directory. When the source code is ready, the required modifications are applied (for example, applying necessary patches and checking out the correct Git revision).
* 配置和构建: 编译过程从可直接使用的源代码开始。它涉及构建选项的配置(例如 ./configure)和构建(例如 make)。
* Configuration and building: The building process starts with the ready-to-use source code. It involves the configuration of build options (for example,
./configure) and building (for example,
make).
* 安装: 然后在
build/tmp/work/<...>/image 下的暂存目录中安装已构建的工件(例如
make install)。
* Installing: The built artifacts are then installed (for example, make install) in a staging directory under build/tmp/work/<...>/image.
* 封装系统根目录: 交叉编译所需的工件,如库、头文件和其他文件,会被复制到 build/tmp/work/<...>/recipe-sysroot 和 build/tmp/work/<...>/recipe-sysroot-native,有时还会被修改。
* Wrapping the sysroot: The artifacts required for cross-compilation, such as libraries, headers, and other files, are copied and sometimes modified to
build/tmp/work/<...>/recipe-sysroot and
build/tmp/work/<...>/recipe-sysroot-native.
* 创建软件包: 软件包使用已安装的内容生成,可能会将这些内容分割成多个软件包,这些软件包可以以不同的格式提供,例如
.rpm、.ipk、.deb 或
.tar。
* Creating the packages: The packages are generated using the installed contents, potentially splitting this content across multiple packages, which can be provided in different formats, for example, .rpm, .ipk, .deb, or .tar.
* 质量保证(QA)检查: 在构建配方时,构建系统会对输出执行各种 QA 检查,以确保发现并报告常见问题。
* Quality Assurance (QA) checks: When building a recipe, the build system performs various QA checks on the output to ensure that common issues are detected and reported.
3,Exploring the temporary build directory
了解临时编译目录 (build/tmp) 至关重要。临时编译目录是在编译开始后创建的,它对于帮助我们找出某些操作与预期不符的原因至关重要。
Understanding the temporary build directory (
build/tmp) is critical. The temporary build directory is created just after the build starts, and it’s essential for helping us identify why something didn’t behave as expected.
下图显示了 build/tmp 目录的内容:
The following figure shows the contents of the
build/tmp directory:

[ Figure 6.1 – Contents of build/tmp ]
其中最重要的目录如下:
The most critical directories found within it are as follows:
* 部署: 这里包含构建产品,如映像、二进制包和 SDK 安装程序。
* sysroots-components: 它包含 recipes-sysroot 和 recipes-sysroot-native 的表示,可让 BitBake 知道每个组件的安装位置。这将用于在构建过程中创建特定于配方的系统根目录。
* sysroots-uninative: 它包括 glibc(一个 C 库),在生成本地实用程序时使用。这反过来又提高了共享状态工件在不同主机发行版之间的重用性。
* 工作: 其中包含工作源代码、任务配置、执行日志和生成软件包的内容。
* 工作共享: 这是一个工作目录,用于与多个配方共享源代码。work-shared 仅用于部分配方,例如 linux-yocto 和 gcc。
* deploy: This contains the build products, such as images, binary packages, and SDK installers.
* sysroots-components: This contains a representation of recipes-sysroot and recipes-sysroot-native, which allows BitBake to know where each component is installed. This is used to create recipe-specific sysroots during the build.
* sysroots-uninative: This includes glibc (a C library), which is used when native utilities are generated. This, in turn, improves the reuse of shared state artifacts across different host distributions.
* work: This contains the working source code, a task’s configuration, execution logs, and the contents of generated packages.
* work-shared: This is a work directory used for sharing the source code with multiple recipes. work-shared is only used by a subset of recipes, for example, linux-yocto and gcc.
4, Understanding the work directory
build/tmp/work 目录按体系结构编排。例如,在使用 qemux86-64 机器时,我们有以下四个目录:
The build/tmp/work directory is organized by architecture. For example, when working with the qemux86-64 machine, we have the following four directories:

[ Figure 6.2 – The contents of the build/tmp/work directory ]
图 6.2 显示了 x86-64 主机和 qemux86-64 目标机 配套下build/tmp/work 下可能存在的目录示例。它们与体系结构和机器有关,如下所示:
Figure 6.2 shows an example of possible directories under build/tmp/work for an x86-64 host and a qemux86-64 target. They are architecture- and machine-dependent, as follows:
* all-poky-linux: 该目录包含架构无关软件包的工作编译目录。这些软件包大多是脚本或基于解释语言的软件包,例如 Perl 脚本和 Python 脚本。
* core2-64-poky-linux: 该目录包含基于 x86-64 的目标常用软件包的工作编译目录,这些软件包使用了针对 core2-64 的优化调整。
* qemux86_64-poky-linux: 该目录包含 qemux86-64 机器专用软件包的工作构建目录。
* x86_64-linux: 此目录包含针对在构建主机上运行的软件包的工作构建目录。
* all-poky-linux: This directory contains the working build directories for the architecture-agnostic packages. These are mostly scripts or interpreted language-based packages, for example, Perl scripts and Python scripts.
* core2-64-poky-linux: This directory contains the working build directories for the packages common to x86-64-based targets using the optimization tuned for core2-64.
* qemux86_64-poky-linux: This directory contains the working build directories for packages specific to the qemux86-64 machine.
* x86_64-linux: This directory holds the working build directories for the packages that are targeted to run on the build host machine.
这种组件化结构对于在一个构建目录中为多台机器和体系结构构建系统映像和软件包而不发生冲突是必要的。我们将使用的目标机器是 qemux86-64。
This componentized structure is necessary to allow building system images and packages for multiple machines and architectures within one build directory without conflicts. The target machine we will use is qemux86-64.
build/tmp/work 目录在检查错误行为或构建失败时非常有用。其内容按照以下模式编排在子目录中:
The build/tmp/work directory is useful when checking for misbehavior or building failures. Its contents are organized in sub-directories following this pattern:
[ Figure 6.3 – The pattern used in sub-directories of the build/tmp/work directory ]
图 6.3 所示目录树下的部分目录如下:
Some of the directories under the tree shown in Figure 6.3 are as follows:
* <sources>:这是要编译的软件的源代码。WORKDIR 变量指向此目录。
* image: 包含配方安装的文件。
* packages: 输出软件包的提取内容存储在这里。
* packages-split: 输出软件包中已提取并分割成子目录的内容存储在此处。
* temp: 此处存储 BitBake 的任务代码和执行日志。
* <sources>: This is extracted source code of the software to be built. The WORKDIR variable points to this directory.
* image: This contains the files installed by the recipe.
* package: The extracted contents of output packages are stored here.
* packages-split: The contents of output packages, extracted and split into sub-directories, are stored here.
* temp: This stores BitBake’s task code and execution logs.
Tip
我们可以在 build/conf/local.conf 文件中添加 INHERIT += “rm_work”,在每个配方编译周期后自动删除工作目录,以减少磁盘使用量。
We can automatically remove the work directory after each recipe compilation cycle to reduce disk usage, adding INHERIT += "rm_work" in the build/conf/local.conf file.
所有架构的工作目录结构都是一样的。每个配方都会创建一个以配方名称命名的目录。以特定机器的工作目录和 sysvinit-inittab 配方为例,我们可以看到如下内容:
The structure of the work directory is the same for all architectures. For every recipe, a directory with the recipe name is created. Taking the machine-specific work directory and using the sysvinit-inittab recipe as an example, we see the following:

[ Figure 6.4 – Content of build/tmp/work/qemux86_64-poky-linux/sysvinit-inittab/2.88dsf-r10 ]
sysvinit-inittab 配方就是一个很好的例子,因为它是针对特定机器的。该配方包含 inittab 文件,该文件定义了启动登录进程的串口控制台,而登录进程因机器而异。
The sysvinit-inittab recipe is an excellent example, as it is machine-specific. This recipe contains the inittab file that defines the serial console to spawn the login process, which varies from machine to machine.
Note
构建系统使用的目录如上图所示,此处不再详述。因此,除非你正在进行构建工具的开发,否则不需要使用它们。
The build system uses the directories shown in the preceding figure that are not detailed here. Therefore, you should not need to work with them, except if you are working on build tool development.
我们将在第 10 章 “Yocto 项目的调试 ”中介绍如何使用工作目录进行调试。
The work directory is handy for debugging purposes; we cover this in Chapter 10, Debugging with the Yocto Project.
5,Understanding the sysroot directories
sysroot 目录在 Yocto 项目中起着至关重要的作用。它为每个配方创建了一个独立、隔离的环境。为每个配方设置的这个环境对于确保可重复性和避免主机软件包的污染至关重要。
The sysroot directory plays a critical role in the Yocto Project. It creates an individual and isolated environment for each recipe. This environment, set for each recipe, is essential to ensure reproducibility and avoid contamination with the host machine’s packages.
创建 3.3.17 版的 procps 配方后,我们会得到两套系统根目录:recipes-sysroot 和 recipes-sysroot-native。
After we build the procps recipe, version 3.3.17, we get two sets of sysroot directories – recipes-sysroot and recipes-sysroot-native.
在每个 sysroot 设置中,都有一个名为 sysroot-provides 的子目录。该目录列出了各自系统根上安装的软件包。以下是 recipe-sysroot 目录:
Inside each sysroot set, there is a sub-directory called sysroot-provides. This directory lists the packages installed on each respective sysroot. Following is the recipe-sysroot directory:

[ Figure 6.5 – Content of the recipe-sysroot directory under build/tmp/work for recipe procps ]
recipe-sysroot-native 目录包括在构建过程中主机系统使用的构建依赖项。它包括编译器、链接器、工具等。同时,recipe-sysroot 目录还包含目标代码中使用的库和头文件。下图显示了 recipe-sysroot-native 目录:
The recipe-sysroot-native directory includes the build dependencies used on the host system during the build process. It encompasses the compiler, linker, tools, and more. At the same time, the recipe-sysroot directory has the libraries and headers used in the target code. The following figure shows the recipe-sysroot-native directory:

[ Figure 6.6 – Content of the recipe-sysroot-native directory under build/tmp/work for recipe procps ]
当我们发现头文件丢失或链接失败时,必须仔细检查系统根目录(目标和主机)的内容是否正确。
When we see a missing header or a link failure, we must double-check whether our sysroot directory (target and host) contents are correct.
6, Summary
在本章中,我们探讨了图像生成后临时构建目录的内容。我们还了解了 BitBake 如何在生成过程中使用临时构建目录。
In this chapter, we explored the contents of the temporary build directory after image generation. We saw how BitBake uses it during the baking process.
在下一章中,我们将更好地了解 Poky 是如何进行打包的,如何使用 package feed、Package Revision (PR) 服务,以及它们如何帮助我们进行产品维护。
In the next chapter, we will better understand how packaging is done in Poky, how to use package feeds, the Package Revision (PR) service, and how they may help our product maintenance.


![[大语言模型-算法优化] 微调技术-LoRA算法原理及优化应用详解](https://i-blog.csdnimg.cn/direct/7d81fb702c5b42b4a9adc2a8a6bee102.png)