可视化、数据可视化
在狭义上,数据可视化是与信息可视化,科学可视化和可视分析学平行的概念,而在广义上数据可视化可以包含这3类可视化技术。
数据科学的主要任务
数据科学研究目的与任务
- 大数据及其运动规律的揭示
- 从数据到智慧的转化
- 数据洞见(Data Insights)
- 数据业务化
- 数据分析
- 数据驱动型决策(支持)
- 数据产品的研发
- 数据生态系统的建设
EDA探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)
• 对已有的数据(特别是调查或观察得来的原始数据)
• 在尽量少的先验假定下进行探索,
• 并通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
EDA方法与验证性分析的主要区别
• EDA不需要事先假设,而验证性分析需要事先提出假设;
• EDA中采用的方法往往比验证性分析简单;
• 在一般数据科学项目中,探索分析在先,而验证性分析在后。
对原始数据的预处理,包括集成、变换、规约怎么做的
数据集成基本类型
- 内容集成
- 结构集成
数据集成的3个基本问题
- 模式集成
- 数据冗余
- 冲突检测与消除
数据规约
维规约(Dimensionality reduction)
• 主成分分析(Principal Component Analysis,PCA)
• 奇异值分解(Singular Value Decomposition,SVD)
• 离散小波转换(Discrete Wavelet Transform,DWT)
值规约(NumerosityReduction)
• 参数模型(如简单线性回归模型和对数线性模型等)
• 非参数模型(如抽样、聚类、直方图等)
数据仓库
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的HiveQL
查询功能,可以将HiveQL语句转换为MapReduce任务进行运行。
最初,Hive是由Facebook开源,主要用于解决海量结构化的日志数据统计问题。
主要特色在于定义了一种类似SQL的查询语言(HiveQL,HQL),将其转化为MapReduce任务在Hadoop上执行,通常用于离线分析。
其优点是学习成本低,可以通过类似SQL语句快速实现简单的MapReduce统计,不需发专门的MapReduce应用,适合基于数据仓库的统计分析需要。
时间序列,时间序列的数据是用来做什么的
时间序列分析
- 时间序列是按时间顺序的一组数字序列。
- 时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。
- 时间序列预测一般反映3种实际变化规律
-
- 趋势变化
- 周期性变化
- 随机性变化
通常,一个时间序列由4种要素组成:
➢ 趋势
➢ 季节变动
➢ 循环波动
➢ 不规则波动
时间序列建模包括以下3个主要阶段:
➢ 第一阶段、用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据。
➢ 第二阶段、根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并发现动态数据中的跳点与拐点。
➢ 第三阶段、辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。
云计算的一些特点
什么是云计算(cloud computing)?
云计算是一种按使用计费的计算模型,提供对可配置的计算资源(例如网络,服务器,存储,应用程序和服务)进行按需存取。
云计算具有以下6个基本特点
- 按需自助服务
- 泛在接入
- 资源池化
- 快速弹性
- 计费服务
- 高可靠性
云计算服务可以分为三类
¢ 基础设施即服务
¢ 平台即服务
¢ 软件即服务
云计算服务的部署方式有四大类
公有云、社区云、私有云和混合云。
云计算与其他计算模式的区别
- 并行计算是相对于串行计算来讲的,可分为时间上的并行、和空间上的并行。
- 分布式计算通过把整个计算任务,分解成一系列的小任务,分布到各个节点上分别执行,最后把结果合并,获得最终结果,侧重点在于任务的划分。
- 集群计算通过网络把一组松散的计算机节点紧密地连接在一起,协同完成计算工作,在许多方面它们可以被视为单个系统。
- 网格计算将虚拟化的异构计算资源作为一个虚拟的计算机集群,节点分布更广泛,支持更多不同类型的计算机。
- 云计算底层的核心技术是虚拟化,把计算、存储、网络等硬件予以抽象、转换后呈现出来。云计算是上述技术发展的新阶段,或者说是这些概念的商业实现。
MapReduce是怎么工作的
MapReduce计算框架源自一种分布式计算模型,其输入和输出值均为<key, value>键/值对,其计算过程分为两个阶段——map阶段和reduce阶段,并分别以两个函数map()和reduce()进行抽象。MapReduce程序员需要通过自定义map()和reduce()函数表达此计算过程。
➢ map()函数
➢ reduce()函数
实现过程
首先,当用户程序调用MapReduce框架时,将输入文件分成M个数据块,每个数据块的大小一般为16MB~64MB。接着,在计算机集群中启动大量的复制程序,主要步骤如图6-6所示 用户可以通过可选的参数来控制数据块的大小。
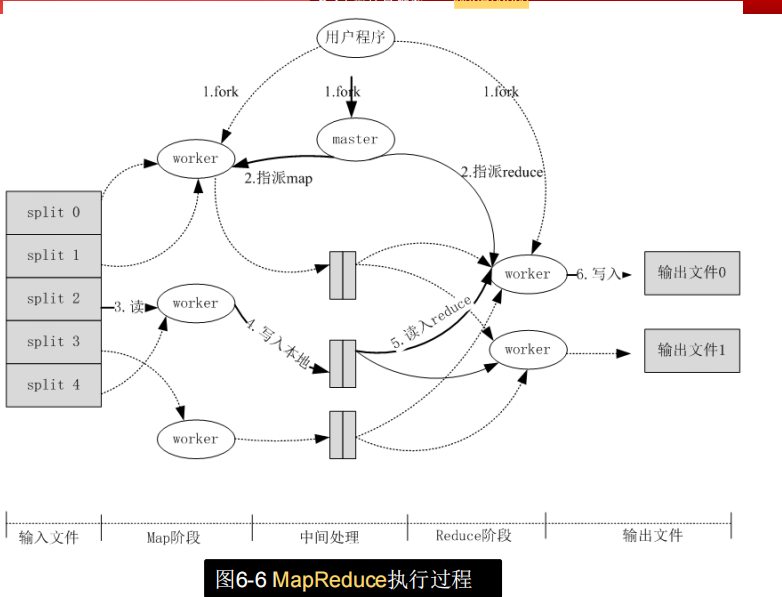
主要特征
(1)以主从结构的形式运行
(2)map()函数与reduce()函数之间的数据处理。
➢ Shuffle处理
➢ Combiner()函数
➢ Partition()函数/分区函数
(3)<key, value>类型的输入/输出
map(K1, V1) –> list (K2, V2)
combine(K2, list(V2)) –> list(K2, V2)
partition(K2, V2) –> integer
reduce(K2, list(V2)) –> list(K3, V3)
(4)容错机制的复杂性
➢ Worker故障
➢ Master故障
(5)数据存储位置的多样性
➢ 源文件:GFS
➢ Map处理结果:本地存储
➢ Reduce处理结果:GFS
➢ 日志:GFS
(6)任务粒度大小的重要性
在MapReduce中,通常把Map拆分成了M个片段、把Reduce拆分成R个片段执行。
(7)任务备份机制的必要性
➢ 有一些慢的节点(“落伍者”)会限制剩下程序的执行速度
➢ “推测性的执行(Speculative execution)”的任务备份机制——当作业中大多数的任务都已经完成时,系统在几个空闲的节点上调度执行剩余任务的拷贝,并在多个Worker同时进行相同的剩余任务。
关键技术
(1)分区函数
(2)Combiner()函数
(3)跳过损坏记录
(4)本地执行
(5)状态信息
(6)计数器
机器学习的聚类、分类算法的特点
分类分析
分类分析
➢ 一种将复杂问题简单化之后,再进行分析和处理的一种数据分析方法,即将大量数据若干个类别之后,分析类别的统计特征,通过类别的特征概括具体数据。
【注意】从统计分析角度看,分类和预测是两个相互关联和转化的概念。
➢ 当目标值的类型为分类型时,称之为分类;
➢ 当目标值的类型为连续型时,称之为预测。
分类分析的算法
• 决策树
• 决策表
• 贝叶斯网络
• 神经网络
• 支持向量机
• KNN算法
【注意】不同算法对分类和预测的支持不同,例如贝叶斯网络和决策表只能处理分类型目标值的分类分析。
聚类分析
与分类分析不同的是,聚类分析所要求划分的类别是未知。
聚类分析中的“聚类要求”有两条:
➢ 每个分组内部的数据具有比较大的相似性;
➢ 组间的数据具有较大不同。
聚类分析方法
➢ 分层聚类
➢ K-means 聚类
➢ Kohonen Network聚类等
怎么描述数据的质量
数据质量
基本属性
• 数据正确性(Correctness)
• 数据完整性(Integrity)
• 一致性(Consistency)
扩展属性
• 形式化程度(Formalization)
• 时效性(Timeliness)
• 精确性(Accuracy)
• 自描述性(SelfDescription)
数据库的类型
数据库的类型
关系数据库
层次数据库
⽹状数据库
⾯向对象数据库
XML数据库
关系数据库
关系数据技术不断趋于成熟
➢ 事务处理能力
➢ 两段封锁协议
➢ 两段提交协议
➢ 坚实的理论基础
➢ 标准化程度高
➢ 产品的成熟度高
- ➢ Oracle公司的Oracle
- ➢ IBM公司的DB2
- ➢ Sybase公司的Sybase
- ➢ 微软公司的SQL Server
- ➢ MySQL AB 公司开发的MySQL
NoSQL
NoSQL 是指那些非关系型的、分布式的、不保证遵循ACID 原则的数据存储系统。相对于关系数据库,NoSQL数据库的主要优势体现在:
➢ 易于数据的分散存储与处理
➢ 数据的频繁操作代价低以及数据的简单处理效率高
➢ 适用于数据模型不断变化的应用场景
CouchDB、Redis、MongoDB、Riak、Membase、Neo4j、Cassandra、HBase(配合 ghshephard使用)
关系云
关系云是在云计算环境中部署和虚拟化的关系数据库,进而使传统关系数据库具备云计算的弹性计算、虚拟化、按需服务和高经济性等特征。关系云代表了数据管理的一个重要发展方向,其关键在于实现:
➢ 事务处理
➢ 弹性计算
➢ 负载均衡等
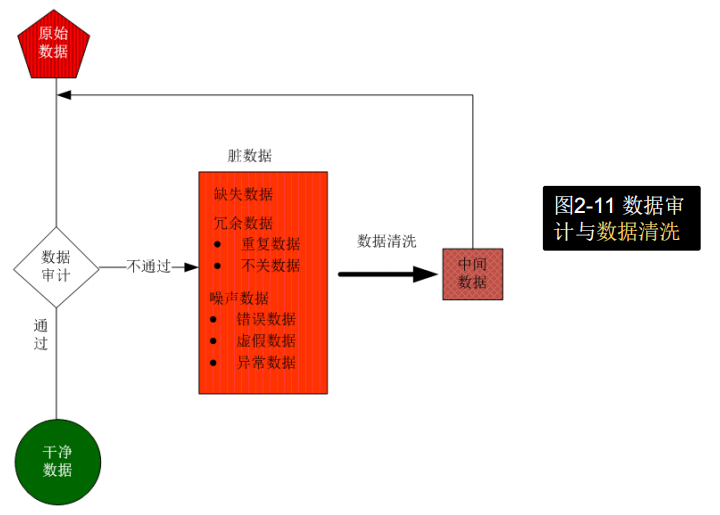
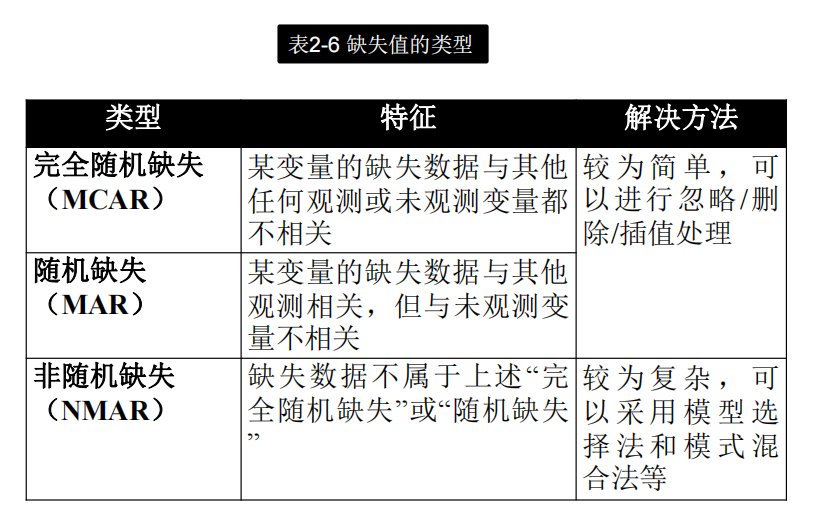
数据审计,数据审计是干什么的
数据审计是指按照数据质量的一般规律与评价方法,对数据内容及其元数据进行审计,发现其中存在的“问题”,例如:
- 缺失值(缺少数据)
- 噪声值(异常数据)
- 不一致值(相互矛盾的数据)
- 不完整值(被篡改或无法溯源的数据)

数据清洗,去除噪声数据,怎么去处理的
去除噪声数据有哪些方法?分箱怎么操作的,分箱的方式等深、等宽时候怎么处理,边界值处理还是均值处理,怎么计算
缺失数据处理
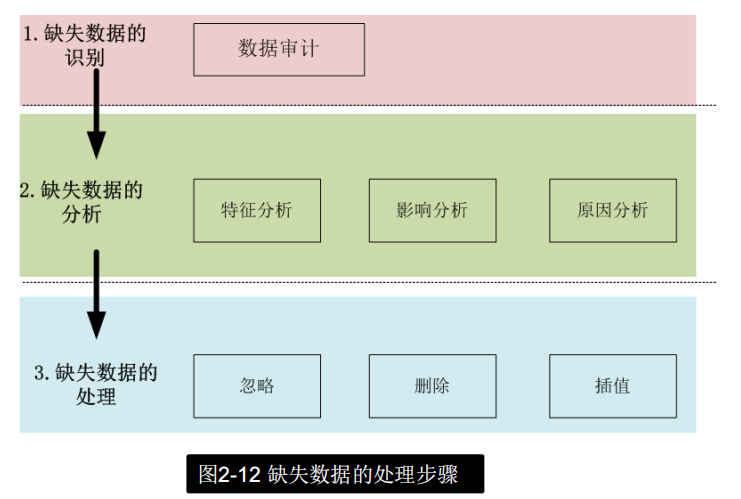
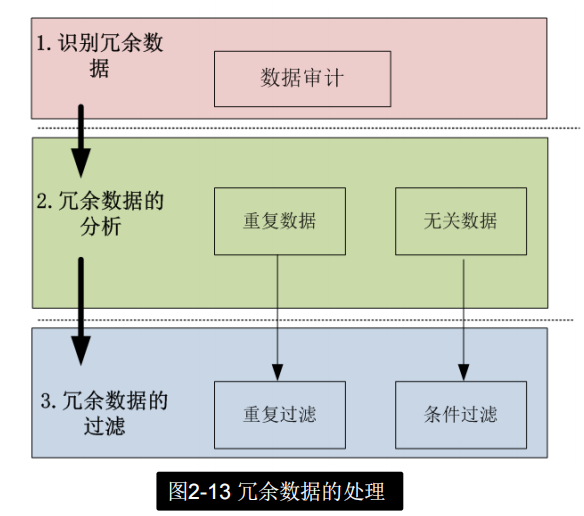
冗余数据处理
噪声数据处理
噪声数据的存在形式
- 错误数据
- 虚假数据
- 异常数据
-
- 离群数据或孤立数据
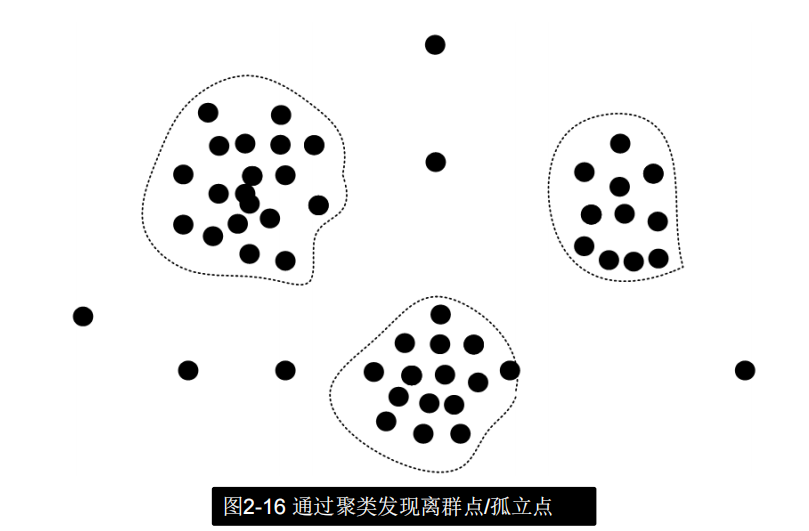
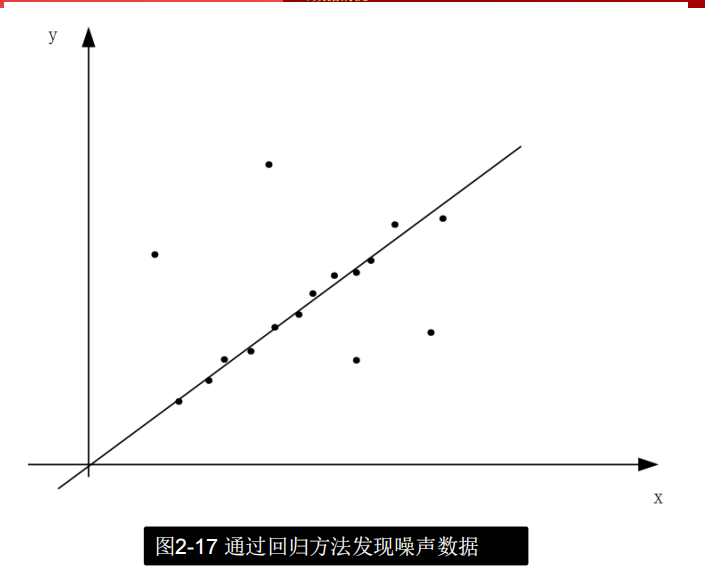
噪声数据的处理方法
- 分箱(Binning)
- 聚类(Clustering)
- 回归(Regression)
分箱处理的步骤与类型
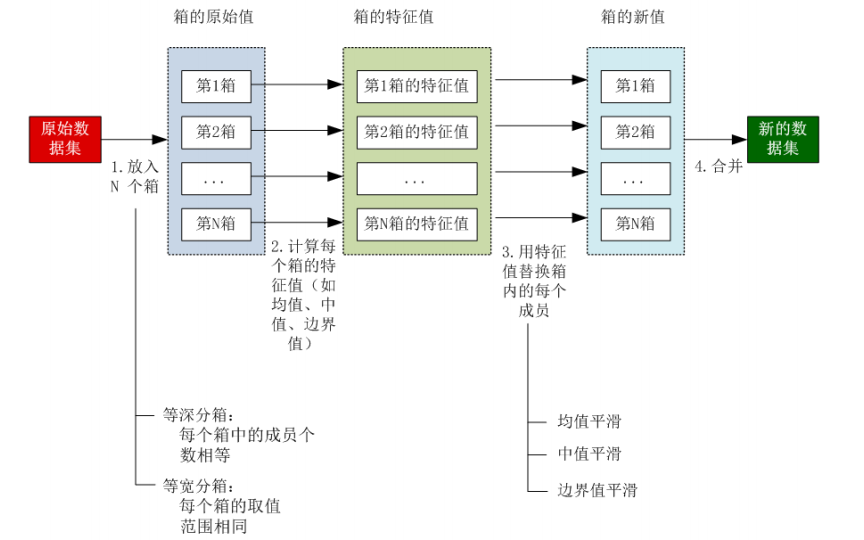
均值平滑与边界值平滑
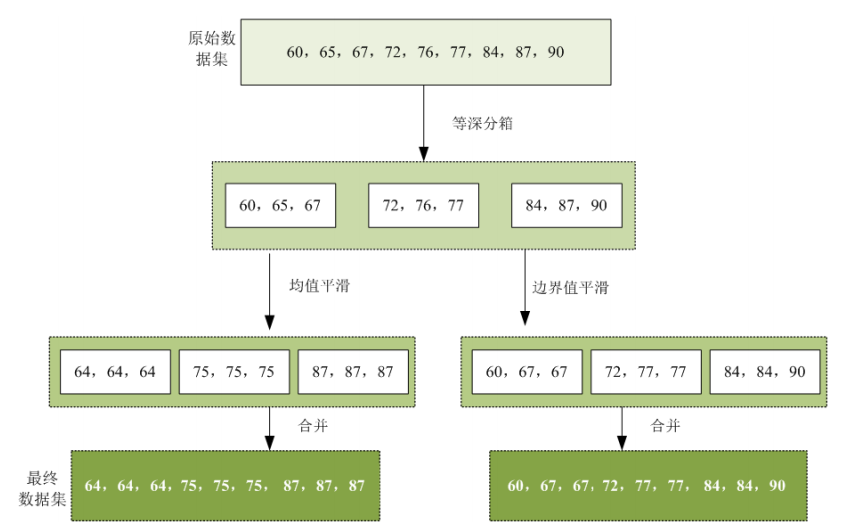
标准化,标准化怎么计算的,标准化的方式
数据标准化处理(Data Normalization)
- 0-1标准化(0-1 normalization)
- z-score 标准化(zeromean normalization)


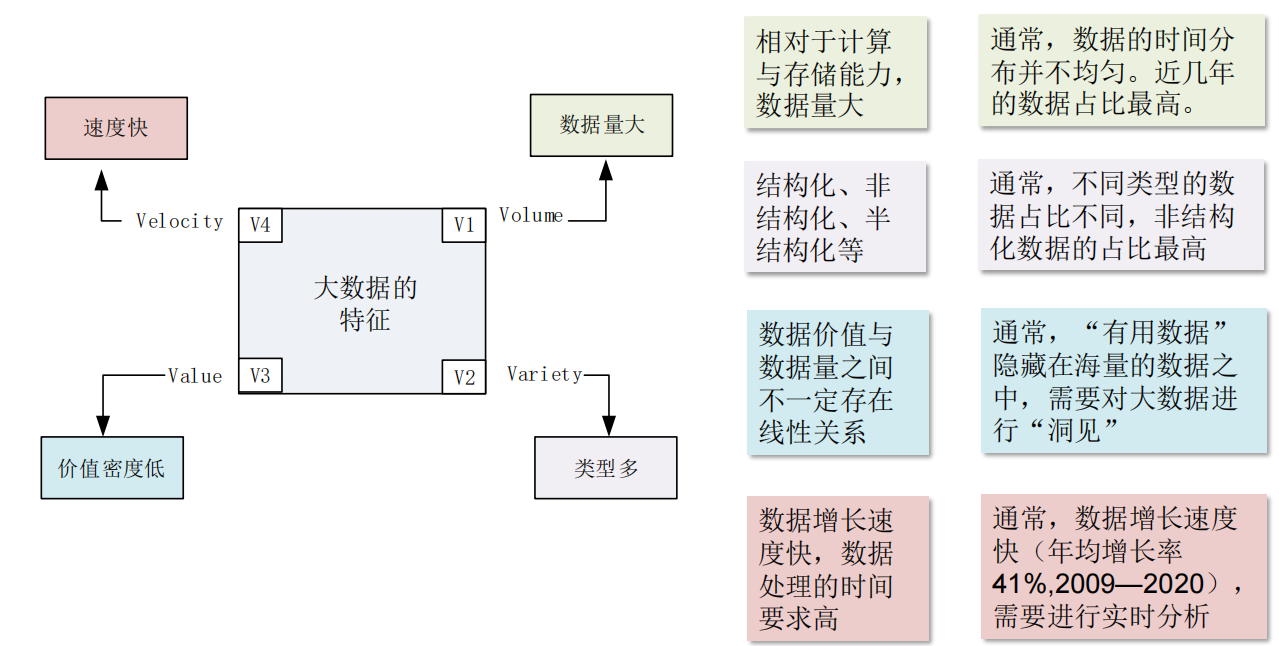
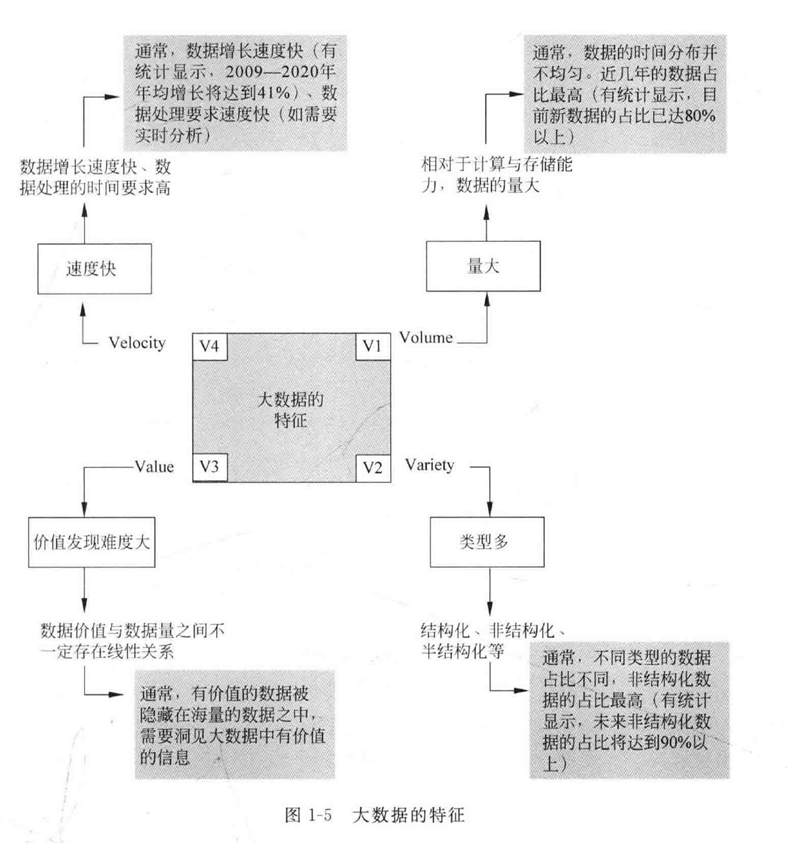
大数据的特征特点,怎么去理解这些特点
如何理解大数据的4V特征
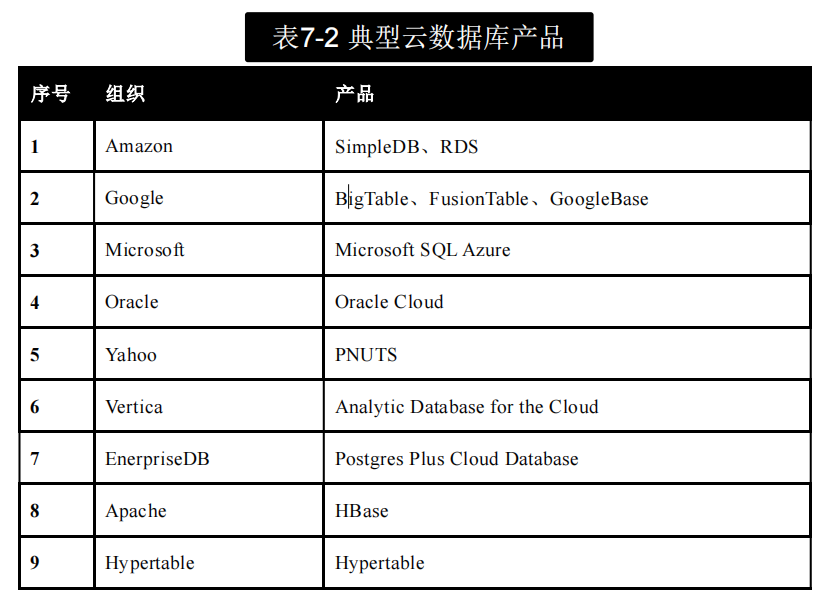
常见的数据库,成熟的关系型?数据库有哪些,优缺点(关系型?)应该怎么发展?怎么去用
关系数据库的优缺点
关系数据库的优势
- 数据一致性高。由于关系数据库具有较为严格的事务处理要求,它能够保持较高的数据一致性。
- 数据存储的冗余度低。 由于关系数据库是以规范化理论为前提,通常,相同字段只能保存一处,数据冗余性较低,数据更新的开销较小。
- 处理复杂查询的能力强。关系数据库中可以进行 join等复杂查询。
- 成熟度高。关系数据库技术及其产品已经较为成熟,稳定性高,系统缺陷少
关系数据库的不足之处
- 不善于处理大量数据的读写操作。在关系数据库中,为了提高读写效率,一般采用主从模式,即数据的写入由主数据库负责,而数据的读入由从数据库负责。因此,主数据库上的写入操作往往成为瓶颈。
- 不适用于数据模型不断变化的应用场景。在关系数据库及其应用系统中,数据模型和应用程序之间的偶合高。当数据模型发生变化(如新增或减少一个字段等)时,需要对应用程序代码进行修改。
- 数据的频繁操作代价大。为了确保关系数据库的事务处理和数据一致性,对关系数据库进行修改操作时往往需要采用共享锁(又称读锁)和排他锁(又称读/写锁)的方式放弃多个进程同时对同一个数据进行更新操作。
- 数据的简单处理效率较低。在关系数据库中,SQL 语言编写的查询语句需要完成解析处理才能进行。因此,当数据操作非常简单时,也需要进行解析、加锁、解锁等操作,导致关系数据库对数据的简单处理效率较低。
NoSQL
术语NoSQL可以理解为“Not Only SQL”的缩写,也就是说NoSQL为数据处理提供了一种补充方案。
NoSQL 是指那些非关系型的、分布式的、不保证遵循ACID 原则的数据存储系统。相对于关系数据库,NoSQL数据库的主要优势体现在:
➢ 易于数据的分散存储与处理
➢ 数据的频繁操作代价低以及数据的简单处理效率高
➢ 适用于数据模型不断变化的应用场景
需要注意的是,提出NoSQL技术的目的并不是替代关系数据库技术,而是对其提供一种补充方案。
➢ 如果需要处理关系数据库擅长的问题,那么仍然首选关系数据库技术;
➢ 如果需要处理关系数据库不擅长的问题,那么不再仅仅依赖于关系数据库技术,可以考虑更加适合的数据存储技术,如NoSQL技术等。