随着大型语言模型(LLMs)的迅速普及,如何有效地引导它们生成安全、适合特定应用和目标受众的内容成为一个关键挑战。例如,我们可能希望语言模型在与幼儿园孩子互动时使用不同的语言,或在撰写喜剧小品、提供法律支持或总结新闻文章时采用不同的风格。
目前,最成功的LLM范式是训练一个可用于多种任务的大型自回归模型。然而,现有的引导生成方法各有优缺点:
- 微调方法虽然有效,但改变了模型权重,可能会降低LLM的性能。此外,如果新应用需要独特的属性组合(如幽默但不具攻击性),就需要微调和部署新的专用模型。
- 即插即用方法不改变模型权重,而是使用额外的轻量级分类器或启发式方法来影响生成过程。这些方法灵活性高,不需要微调或托管专用模型。但由于它们通常只改变最后一层的logits,容易产生解码错误,这些错误会在自回归生成过程中级联并降低输出质量。
- 扩散模型最初在图像生成领域取得了突破,它们通过迭代"去噪"高斯噪声样本来生成目标数据分布的样本。这种迭代生成过程自然允许通过简单的似然函数进行即插即用控制。然而,目前的文本扩散模型在困惑度和生成质量上仍然不如自回归模型。
为了解决这些挑战,研究者提出了一种新的框架:扩散引导语言建模(Diffusion Guided Language Modeling, DGLM)。DGLM旨在结合自回归生成的流畅性和连续扩散的灵活性,为可控文本生成提供一种更有效的方法。
DGLM方法详解
DGLM框架包含三个主要组件:扩散网络、轻量级提示生成器和预训练的自回归解码器。其工作流程如下:
- 给定一些文本前缀,使用扩散模型采样生成可能的延续的嵌入语义提案。
- 在采样过程中,可以选择性地执行即插即用控制以强制某些条件(如低毒性)。
- 采样语义嵌入后,提示生成器将嵌入处理成软提示。
- 软提示引导自回归解码器生成与提案对齐的文本。
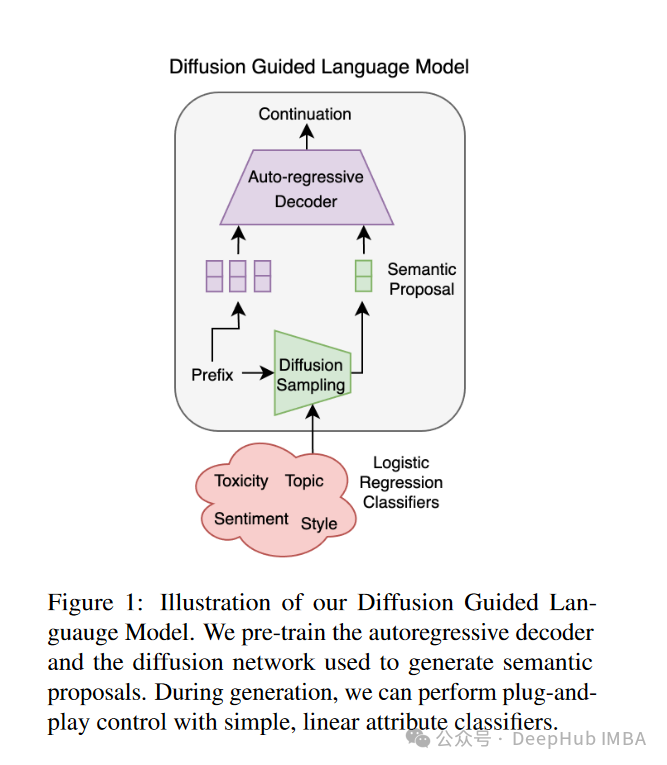
图1: DGLM框架概览。给定一些前缀,我们首先用扩散模型生成语言延续的嵌入表示。在这个阶段,我们可以选择性地用轻量级分类器进行即插即用引导干预。我们将延续嵌入映射到软提示,以引导自回归解码器生成与生成的嵌入语义对齐的语言。
语义提案条件化
DGLM在Sentence-T5的潜在空间中学习扩散模型,以生成语义提案。Sentence-T5是一个经过对比训练的句子编码器,能够捕捉高级语义,同时对浅层表面形式的变化具有鲁棒性。
为了使自回归解码器能够利用Sentence-T5嵌入,DGLM引入了一个轻量级提示生成器,将嵌入映射为解码器的软提示。在预训练阶段,提示生成器和解码器被微调以生成与冻结的Sentence-T5编码器的嵌入相对应的延续。
高斯噪声条件化
为了提高自回归解码器对扩散网络引入的小错误的鲁棒性,DGLM引入了高斯噪声增强技术。在训练过程中,提示生成器接收来自前向扩散过程的带噪声的潜变量。噪声水平动态调整提案嵌入对自回归解码器输出的影响。在低噪声水平下,解码器严重依赖提案嵌入,而在高噪声水平下,解码器回退到标准自回归生成。
在生成阶段,DGLM传递具有一些低但非零噪声水平的提案嵌入(默认设置σ² = 0.05),自回归解码器将生成与提案对齐的文本,同时纠正扩散网络引入的小错误。这也提供了一个旋钮来根据应用调整扩散网络的影响。
语义扩散
DGLM的语义扩散模型在Sentence-T5的潜在空间中操作,迭代生成由文本前缀引导的潜在文本延续。给定一个文本序列,将其分为前缀和延续部分,并使用Sentence-T5分别嵌入,记为x_pref和x_cont。
扩散网络被训练以从给定前缀嵌入恢复噪声延续嵌入。形式上,噪声潜变量由z_t = αt x_cont + σt ε给出,其中分数网络参数化为s_θ(z_t; λ; x_pref)。因此,模型学习从文本前缀可能的延续嵌入分布中采样。
扩散网络采用transformer模型架构。输入首先被独立投影,然后分割成64个特征向量。这些向量沿特征维度按元素连接,然后由transformer处理。
即插即用控制
DGLM采用了一种新颖的即插即用方法,利用Sentence-T5嵌入的语义结构来有效控制文本生成。该方法的数学公式如下:
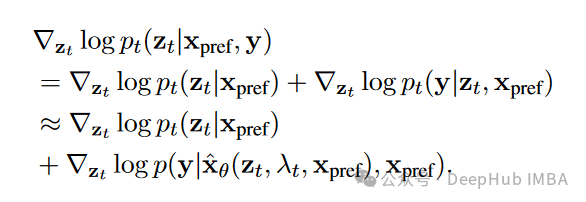
其中y是我们希望在推理时为样本x_cont强制执行的条件。
这种简化允许DGLM仅使用Sentence-T5潜在空间中的分类器进行即插即用引导。在实验中,研究者使用了简单的线性探针(即逻辑回归)。语义扩散使得即使使用如此简单的分类器也能实现有效控制。
DGLM的主要优势
- 解耦模型训练和属性控制:DGLM有效地将属性控制与核心语言模型的训练分离,消除了为每个新属性或属性组合进行昂贵微调的需求。
- 控制新属性的简单性:控制新属性只需要训练一个简单的逻辑回归分类器,使框架高度适应多样化的用户需求和偏好。
- 经验上的有效性:DGLM在多个基准数据集上的即插即用控制表现优于当前最先进的方法。
- 组合控制:DGLM天生适合同时控制多个属性,为构建高度适应性的、具有用户可控行为的语言模型开辟了道路。
实验结果与性能评估
数据集
研究者使用了以下数据集进行实验:
- 预训练数据:从C4数据集中提取了1000万个实例的子集,这仅代表C4的2.5%。研究者指出,扩大预训练语料库可能会进一步提高性能。
- 语言生成评估:从C4和OpenWebText中随机提取5000个验证实例。模型以前32个token为条件,生成32个token的延续。
- 毒性缓解实验:在Jigsaw Unintended Bias数据集上训练逻辑回归模型,并使用RealToxicityPrompts中的5,000个中性提示评估毒性缓解效果。
- 情感控制实验:使用Amazon Polarity和SST-2训练情感分类器,并使用OpenWebText中的5,000个中性提示进行情感控制。
评估指标
-
流畅性:使用开源OLMo-1B语言模型测量文本的困惑度。
-
生成质量:使用MAUVE分数,该分数通过发散前沿测量生成文本与参考文本的相似度。
-
生成多样性:使用Div指标,计算公式为:

-
引导任务评估:- 为每个提示生成25个样本。- 使用OLMo-1B困惑度评估延续的流畅性。- 使用Dist-3(每组延续中唯一3-gram的平均数)量化生成多样性。- 使用Perspective API测量生成文本的毒性。- 使用经过微调的RoBERTa-Large和DistilBERT模型评估情感。
实验结果
语言生成
研究者首先验证了DGLM在开放式语言生成任务上的有效性,不使用任何即插即用控制。结果如表1所示:

表1:语言生成评估结果。对于MAUVE分数,报告了5个随机种子的标准误差均值。
主要观察结果:
- DGLM在足够的无分类器引导强度下,能够匹配或超越参考困惑度。
- DGLM在两个数据集上consistently生成比自回归基线更多样化的文本。
- DGLM在C4数据集上实现了更强的MAUVE分数。
研究者还检查了高斯噪声增强的影响,结果如表2所示:
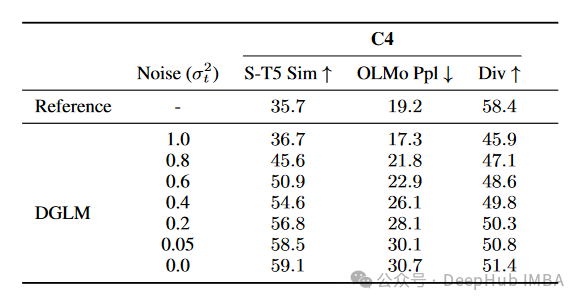
表2:高斯噪声增强的影响。σ² = 1.0对应高斯噪声,σ² = 0.0对应干净提案。
观察结果表明,高斯噪声增强使网络能够在自回归生成(低困惑度但多样性差)和扩散引导生成(更高的困惑度和多样性)之间平滑插值。较低的噪声水平单调地改善了解码器对提案的遵从度。
即插即用控制
毒性缓解
研究者使用DGLM来避免生成有毒语言。图5展示了定量结果:
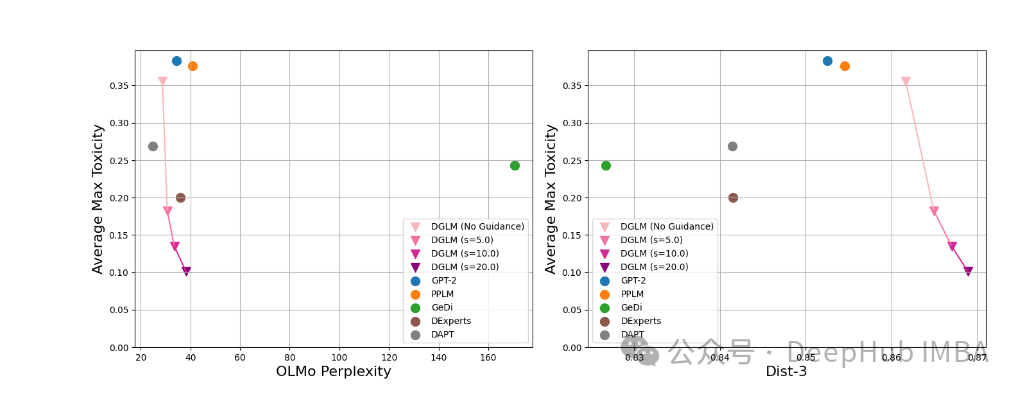
图5:增加引导权重对毒性缓解的影响。增加引导减少了毒性,对流畅性的损失最小。
主要发现:
- 使用线性探针的即插即用引导有效地缓解了毒性,对流畅性的影响可以忽略不计。
- DGLM同时实现了更低的困惑度、更低的毒性和更高的多样性,优于所有基线方法。
情感控制
研究者还应用DGLM来控制生成文本的情感。图6展示了引导生成朝向负面情感的结果:
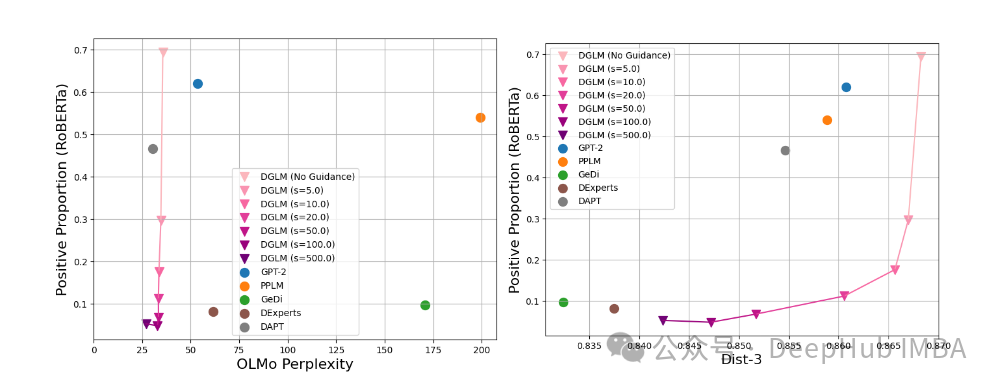
图6:增加引导权重向负面情感引导生成的效果。增加引导改善了与目标情感的一致性,同时牺牲了一些多样性。
研究者观察到,DGLM在这种情况下同样有效,可以在不损失流畅性的情况下减少(或增加)情感,并且在适度的引导值下对多样性的影响最小。
组合控制
研究者还展示了DGLM在组合多个属性分类器方面的能力。他们在AG News主题分类数据集上微调了一个额外的逻辑回归模型,然后将情感和主题分类分类器的损失相加来引导生成。表3展示了一些定性示例:

表3:同时控制两个属性生成的语言示例。
这些结果表明,DGLM成功地实现了组合控制,能够生成同时满足多个属性要求的文本。
解码开销
与自回归生成的即插即用方法相比,DGLM在生成语义提案时只产生一次性成本,然后在后续解码步骤中分摊这个成本。研究者计算了不同生成长度的运行时间,结果如表4所示:
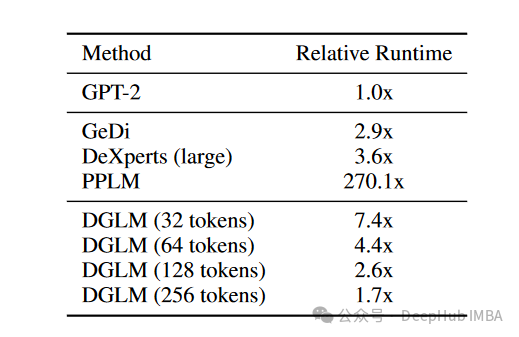
表4:与GPT-2相比的相对运行时间。
结果表明,DGLM对短序列有较大的成本,但在适度的生成长度下,相比于先前的方法,其开销减少。
结论与局限性
DGLM展示了在可控文本生成方面的强大能力,它结合了自回归和扩散的优势,使用轻量级分类器实现了多功能的属性引导文本生成。实验结果表明,DGLM在多个基准数据集上显著优于先前的即插即用方法,为构建高度适应性的、具有用户可控行为的语言模型开辟了道路。
然而,研究者也指出了DGLM的一些局限性:
- 像任何控制文本属性的系统一样,DGLM可能被滥用来引导语言朝有害的方向发展。研究人员和实践者应该仔细评估生成系统以降低这些风险。
- 在生成短文本(<32个token)时,DGLM目前的推理速度比一些即插即用基线慢。研究者预计,加速扩散模型和蒸馏扩散步骤的进展将有助于解决这个限制。
- 虽然DGLM优于最近的方法,但在可控文本生成方面仍有很大的改进空间。该框架目前使用简单的线性分类器,可能无法稳健地捕捉复杂属性。扩展DGLM以处理复杂属性可能需要更复杂的分类器。
尽管存在这些局限性,DGLM为可控文本生成领域提供了一个新的、有前景的方向。研究者希望他们的工作能够激发更多关于可靠和有益的引导语言模型的研究。
https://avoid.overfit.cn/post/e935645b2c5743458e78e333137a79b8