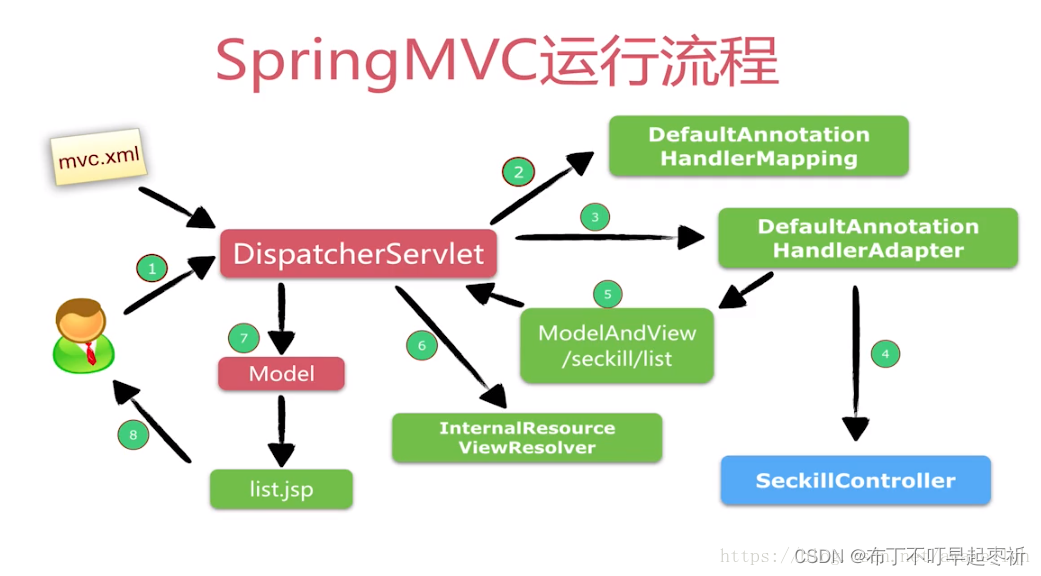
交叉熵(Cross-Entropy)是信息论中的一个重要概念,也是在机器学习和深度学习中用于分类任务的常见损失函数。它衡量的是两个概率分布之间的差异,特别是模型的预测概率分布与真实分布的差异。
交叉熵最初是从信息论引入的,首先我们先来看一下什么是信息量,什么是熵,什么是相对熵。信息量用于衡量一个事件发生所携带的信息。信息量用于衡量在一个不确定的环境中,某个事件发生时,能带来多少信息。信息量通常用比特(bit)来表示。对于一个发生概率为 p 的事件,其信息量定义为:
熵是一个系统中所有可能事件的不确定性或平均信息量的度量。它衡量的是整个系统的平均不确定性。当我们对系统的不确定性越大,熵值就越高。熵越大,表示系统的随机性或混乱程度越高。对于一个离散随机变量 X ,它的熵定义为:
相对熵(Kullback-Leibler 散度,简称KL散度)用于衡量两个概率分布之间的差异。它告诉我们,如果我们使用一个概率分布 q 来近似真实的概率分布 p,我们在信息上会有多少额外损失。KL散度越大,说明两个分布的差异越大。如果两个分布完全相同,则 KL 散度为0,表示我们没有任何信息损失。如果两个分布差异很大,则 KL 散度会较大,表示我们需要更多的额外信息来弥补近似分布和真实分布之间的差异。

根据类别数的不同,分为二元交叉熵和类别交叉熵: