全连接神经网络概述

输入层在左点自外,相应的输出层在右点之外, 这就像一个函数,y=f(x),x即输入,f即隐藏层,y即输出,或者是y=model(x)
全连接神经网络的结构单元
主要是从单元到整体,就是基础模块不停叠加,对于model只有一个神经元,比如输入X1,X2,X3,b1,X1*W11,X2*W12,X3*W13,b1作为偏移值,几个值相加+b1,即a*(X1*W11+X2*W12+X3*W13+b)类似一个输入w矩阵,得到
多个模型套来套去,每一组隐藏层都有他们的w和b
激活函数
往往是非线性的,resnet来实现不让线性神经网络过深过拟合,就是神经网络需要引入非线性因素,否则多层等价于一层,而这个非线性因素就是激活函数
这里我们考虑把线性函数h(x)=cx作为激活函数,把y(x)=h(h(h(x))的运算对应3层神经网络,这个运算会进行y(x)=c*c*c*x的乘法运算,但是同样的处理可以由y(x)=ax(注意,这里a=c**3)一次乘法运算(既没有隐藏层的神经网络)来表示。
sigmoid函数

如果两侧不为0,我们管这个叫梯度消失。我们希望导数左右要平稳值,"不要大不要小"
Tanh函数

ReLU函数
 在底部可以直接为0不再更新w和b,不像sigmoid和tanh函数有一个缓慢的变化
在底部可以直接为0不再更新w和b,不像sigmoid和tanh函数有一个缓慢的变化
wb是神经元之间的权重,激活函数是乘上去的,后面会利用损失函数来反向传播优化wb,激活函数让输出为0了,哪还有损失,就优化不了wb了.记住就行了,在导数中,反向传播找到找到最佳w、b参数进而获取最优输出
Leaky ReLU函数 
优点在于不让导数等于0从而让wb不更新 ,但是函数在正负不对称导致如此缺点
神经网络的前向传播

本质还是计算一个函数的结果, 经过如上三个公式计算后,得到y,可以再用sigmol或者softmax分类

需要P9的ai总结
神经网络的损失函数

通过这个公式我们来判断这个模型最后的误差大不大,训练的过程中误差大不大。每训练也能更新一次,其中训练集和验证集进行一个拟合而且验证集要比训练集大一点,如果验证集先减小在变大,就叫做过拟合
现在我们前向传播这个结果已经有了,真实值也有了,这两个也有误差了,误差叫做JX.一旦网络产生了预测输出,就会使用损失函数(如均方误差、交叉熵等)与真实标签(即目标值)进行比较,以量化预测值与实际值之间的差距。损失值越小,表示模型的预测越准确。接着反向传播,从最后一层开始,反向地通过每一层计算损失关于各参数(权重和偏置)的梯度。这些梯度下降信息用于指导如何调整参数以减少未来的损失值。不断重复以上过程
反向传播-梯度下降法
 往往定义学习值a往往定义为0.05到0.001之间
往往定义学习值a往往定义为0.05到0.001之间

 链式求导法则,上图中部分的b1应该为b2
链式求导法则,上图中部分的b1应该为b2
 更新后再次计算y=model(x),拟合
更新后再次计算y=model(x),拟合
- 1000份的x和y
- 搭建模型model
- 开始训练
- 前向传播y
- 计算误差y-y帽 ---->J(x)
- 反向传播(梯度下降w=w-a*)
- 训练轮次结束
- 产生model并更新wb
- 开始测试x--->y
- 应用
全连接神经网络的问题
假设有一个三通道发哈士奇图像,28*28*3,如果是灰度图就是*1,按行展开,导致空间信息损失了,我记得机器学习是用卷积核提取特征的,由于二维数组变成一维,全连接无法避免破坏空间信息
卷积神经网络 
卷积运算过程



步幅
步幅就是输入平移的部分
填充
import->卷积->池化->卷积->池化->卷积.............我们发现卷积会导致矩阵变得越来越小,因此步幅和填充都可以帮助控制下一层的输出图的大小
步幅st=1,填充pd=1,从而实现得到4*4的结果
输入特征图计算公式
 在kears,pytorch中结果出现小数一般我们选择向下取整,当然也有例外,尽量丢失,也不要瞎填充,数据混乱
在kears,pytorch中结果出现小数一般我们选择向下取整,当然也有例外,尽量丢失,也不要瞎填充,数据混乱
多通道数据卷积
 以这张图为例的话,它就是4×4乘以三嘛这样的一个数据嘛,那么此时这样的数据他怎么去做卷积运算呢,通道数是三的话,那么我们卷积核的通道数肯定是三,人为去设定我们卷积核大小是3×3,输入特征图的通道数的变化而变化,也是3×3.
以这张图为例的话,它就是4×4乘以三嘛这样的一个数据嘛,那么此时这样的数据他怎么去做卷积运算呢,通道数是三的话,那么我们卷积核的通道数肯定是三,人为去设定我们卷积核大小是3×3,输入特征图的通道数的变化而变化,也是3×3.
假设它的填充填充是零
不符是一
那么这个通道呢它的卷积核是多少
卷积多少
咱们看一下公式嘛
呃它是这样的公式
我们再把公式一写A
加上一对不对
那么它的卷积核是这里输入是4+0嘛
减去3÷1加一
这里等于多少呃
明显等于二嘛
那么很显然输出等于
就这个通道它的输出特征图是二对吧
2×2
那么这个通通呢是多少呢
也是2×2嘛
那这个通道它输出也是2×2嘛
然后每个特征组合对应的卷积和它做一个什么
做个卷积运算嘛
这个这个明白吧
这个做卷积运算嘛
这个很简单
对不对
然后的话很显然他最后输出一个特征
每个通道都疏通都是2×2的一个大小吗
对不对
202大小张特征图嘛
这输出征图
然后最后你要把这个每个特征图对应的位置
比如这个位置和这个位置和这个位置值相加
最后得出一张特征图
也就是不管你前面有多少个特征图
假设这类特征图假设啊去极端一点
假如这个啊这个是4×4
这个通道数假设是100
那么四乘四一百这样
那这个通道有没有啊
有啊
很多同学说这怎么可能呢
是吧啊
不是啊
在我们卷积神经网络中
这个通道很大
往往很就比如说是一百二百二百三百
四百一千啊
是很正常的好吧
那么卷积核肯定是多少
我卷积核肯定也是
假设它的大小是3×3
那很显然它那个通道数是多少
是100也是100
然后最后你就算你
你每个通道都会得出一张特征图吗
比如说这个呢
呃最后得出一个通胀总大小是多少
就是每个通道得数通大小2×2是吧
那2×2的话有100个通道的话
那肯定有100
然后再把这个100个就是这样子的
100中间有100个张对应的值
对应的值
对应的值相加相加之后就得出一张特征图
也就是不管你的通道数是多少
你是100也好
1000也好
1亿也好
我最后输出它的特征图
通道肯定是一肯定是一啊
肯定是一是吧
当然很多同学说哎不对啊
我怎么看有些特征数字是几百几千呢
这里我这里要强调一点
就是卷积核数量
11的情况下
输出特征图才是一啊
所以很显然这个卷积核的数量和我们什么
和我们那个什么
和我们最后的输出特征的通道是有关的
但是呢假设这里我们就是数量是一啊
我们后面会讲啊
数数量是多的话
怎么怎么去输入特征
什么样的情况啊
假如是一的话
输入特征肯定是一
然后的话嗯以这个为例的话
那么就是什么呢
这里的特征这个特征图和大卷集合相乘呃
做减轻预算和做简易预算
做减轻运算
最后把所得出的一个结果相加相加
然后最后得出单张特征图
所以这里就是63啊
这里有58呀
51啊
这里就多了一个维度嘛
多了个最后一个那个操作嘛是吧
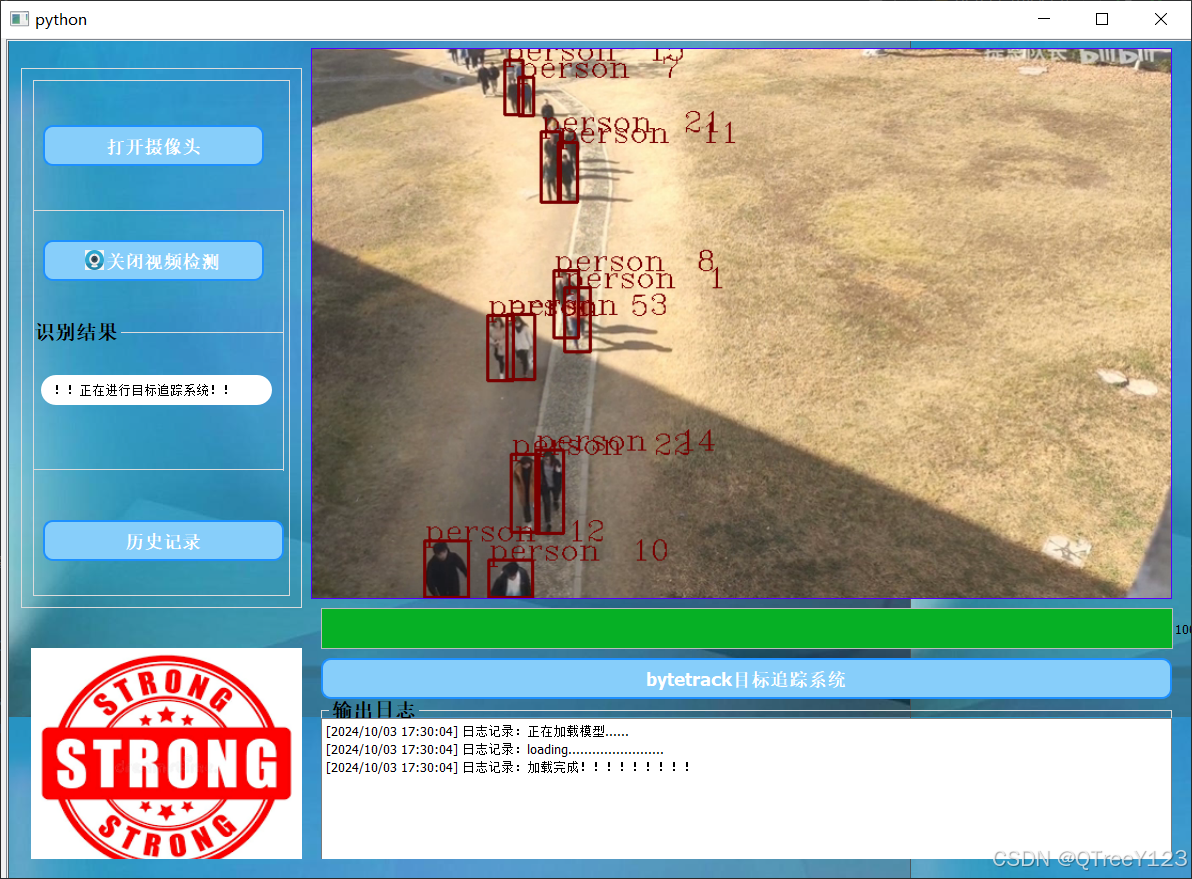
 前面那个卷积运算和前面是一样的,然后说到这里,大家可能不好理解,我们来看一下,我们以这个图为理解,假设我们那个输入特征图的通道就是高是H,宽是W,通道数是C,假设通道数是1000没问题吧。那么不管你这个通道数是多少,我对应的卷积核的通道数肯定是1000是吧,你这个C我也是C嘛。然后决定和它的高和宽是我们人为去设的,高比如说我们3×3是吧,这里输入4×4是吧,这里3×3没有问题吧是吧。然后你做卷积运算之后,我们得出的特征图肯定是高和高,高乘以宽,再乘以一,是这样的,明白我的意思吧。所以这个图就比相对来说比较立体立体一点,方便大家去理解。然后的话,嗯,然后的话很多同学说哎这不对呀,我输的这图是什么,往我看有通道书有很多呀,他他是这样的,我前面讲了个什么,就是卷积核的数量呃,卷积核在干什么,卷积核的高和宽我们认为去设置,然后这个通道数它会自动去匹配什么,匹配我们输入特征的一个呃高和宽啊,不是这个通道数,对不对。然后呢,把卷积和服和的数量我们也可以去设置是吧,那么可以设置,比如说这个设置FN个,那么很显然这里是第一个,第二个一直到FN个,FN个,然后的话来这里和他做一个,做一个什么卷积运算,最后得出一张特征图吗一张,而这里也是一张,这里也是一张,然后所有的计算完之后,它组合到一起,就或者什么,获得我们一个FN个通道的一个输出,他的努,对吧,也就是你输入的特征图是这样子对不对是吧,那我们卷积核它肯定是什么,FH乘以FW再乘以C,那么此时我们的设定,我们像这样的一个卷积核呢,它有多少个呢,有FN个,那么此时它输出的一个卷积核,输出特征图大小是什么,那就是OH乘以什么,ow乘以什么乘以FN,FN就是我们输入特征图的通道。一句话 输入通道数等于卷积核通道数,输出通道数等于卷积核个数
前面那个卷积运算和前面是一样的,然后说到这里,大家可能不好理解,我们来看一下,我们以这个图为理解,假设我们那个输入特征图的通道就是高是H,宽是W,通道数是C,假设通道数是1000没问题吧。那么不管你这个通道数是多少,我对应的卷积核的通道数肯定是1000是吧,你这个C我也是C嘛。然后决定和它的高和宽是我们人为去设的,高比如说我们3×3是吧,这里输入4×4是吧,这里3×3没有问题吧是吧。然后你做卷积运算之后,我们得出的特征图肯定是高和高,高乘以宽,再乘以一,是这样的,明白我的意思吧。所以这个图就比相对来说比较立体立体一点,方便大家去理解。然后的话,嗯,然后的话很多同学说哎这不对呀,我输的这图是什么,往我看有通道书有很多呀,他他是这样的,我前面讲了个什么,就是卷积核的数量呃,卷积核在干什么,卷积核的高和宽我们认为去设置,然后这个通道数它会自动去匹配什么,匹配我们输入特征的一个呃高和宽啊,不是这个通道数,对不对。然后呢,把卷积和服和的数量我们也可以去设置是吧,那么可以设置,比如说这个设置FN个,那么很显然这里是第一个,第二个一直到FN个,FN个,然后的话来这里和他做一个,做一个什么卷积运算,最后得出一张特征图吗一张,而这里也是一张,这里也是一张,然后所有的计算完之后,它组合到一起,就或者什么,获得我们一个FN个通道的一个输出,他的努,对吧,也就是你输入的特征图是这样子对不对是吧,那我们卷积核它肯定是什么,FH乘以FW再乘以C,那么此时我们的设定,我们像这样的一个卷积核呢,它有多少个呢,有FN个,那么此时它输出的一个卷积核,输出特征图大小是什么,那就是OH乘以什么,ow乘以什么乘以FN,FN就是我们输入特征图的通道。一句话 输入通道数等于卷积核通道数,输出通道数等于卷积核个数
池化层
最大池化
事实上池化层在神经网络不算网络层,因为没有参数,不像卷积核w那样可以更新
平均池化
 很明显的在划定内找到最大值和平均值
很明显的在划定内找到最大值和平均值

卷积神经网络整体结构

在不断的卷积池化中,信息已经'面目全非',因此再全连接输出层,实现分类or回归预测