我们每次训练出来的模型,一般都会生成 20-30 个,至于哪个模型符合要求,较为理想呢?
接下来需要对每个 LoRA模型 进行逐一对比测试。
为了测试模型的泛化性,可选择使用一些较为特殊的提示词,看看各个模型对提示词的接收程度:
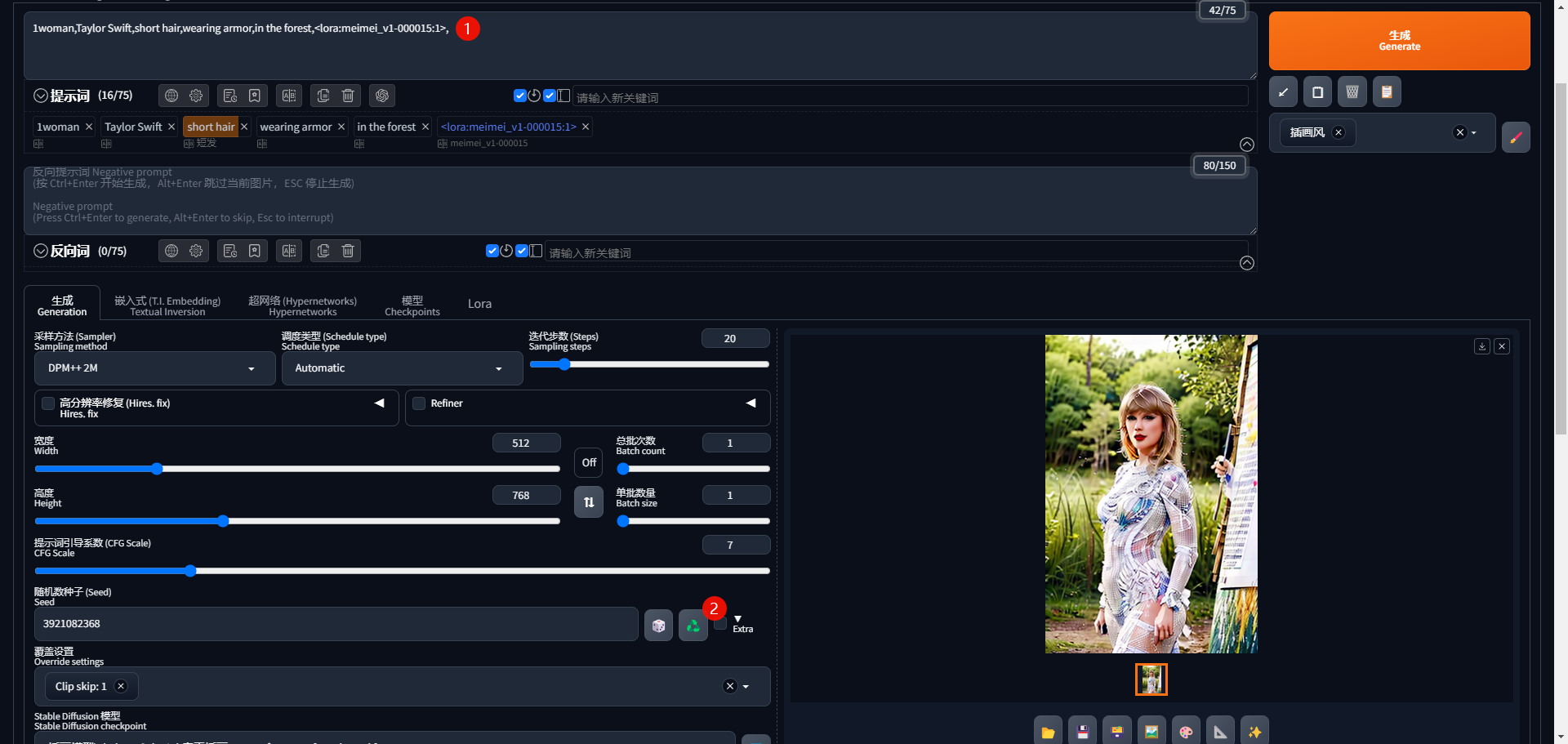
1woman,Taylor Swift,short hair(短头发),wearing armor(穿着盔甲),in the forest(在森林里),
并且固定种子数,以便于对各个 LoRA 的出图效果对比:
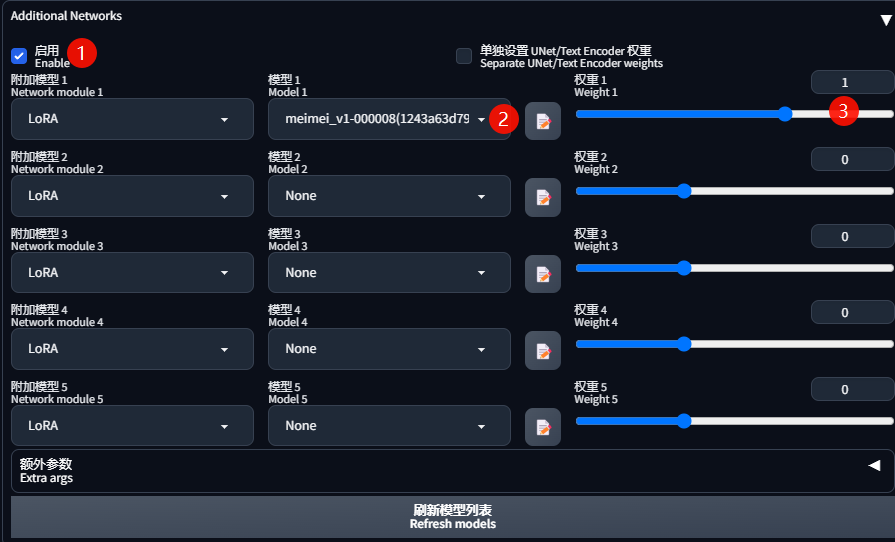
开启「Additional Networks」,在「模型1」中添加任意一个训练出来的 LoRA,权重值设置为 1:
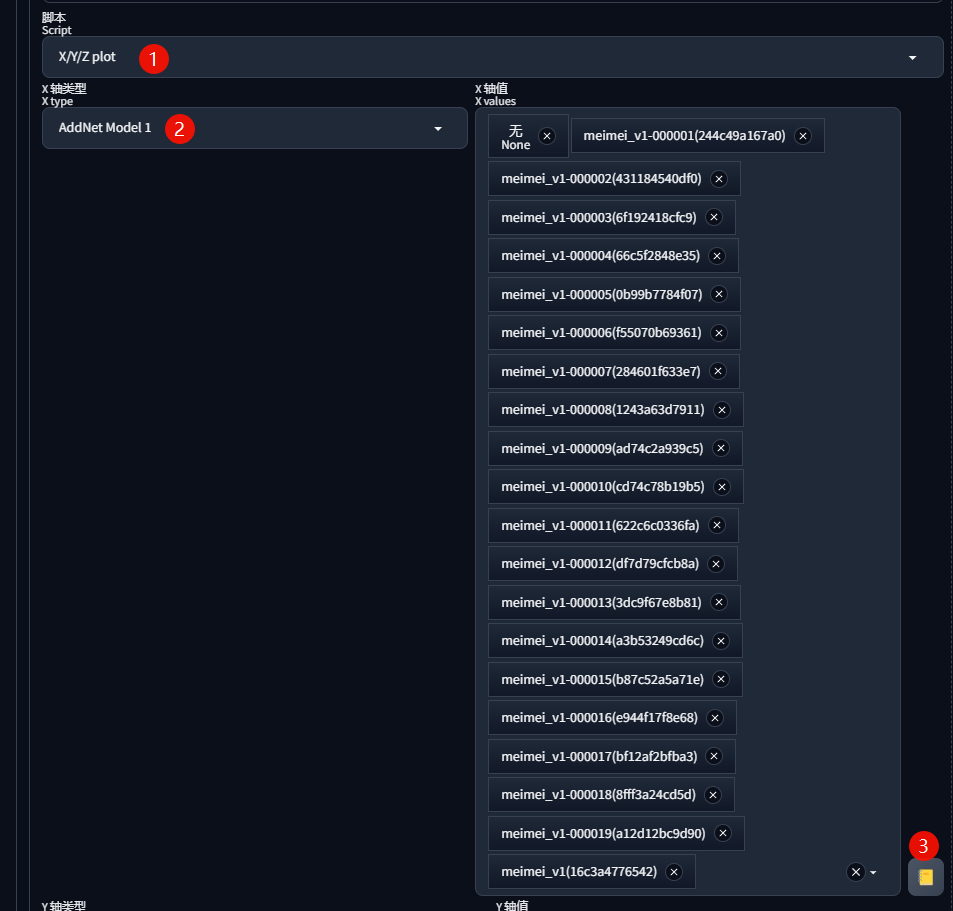
底部的脚本选择「X/Y/Z plot」,x轴类型选择「AddNet Model 1」,点击x轴值输入框右侧的 📒 按钮加载所有的训练LoRA模型:
点击「生成」,等待生成结果:


上面👆展示了15个模型的出图,其中我较为满意的(既能符合提示词,像霉霉,又能保持插画风格),只有03、06、07号模型。
越往后,模型已经开始忽略 盔甲 这个提示词了,而且越来越接近真人模型,缺少插画风格。
我想其中的原因是:随着训练轮次越多,AI已经把素材的特征完全学定型了。
因此,从10轮过后的模型,都可以直接删掉。
再更换其他的提示词,多试几轮,留下出满意的 LoRA 模型以后使用。
我最终选择留下 06、07 两个模型,其他的都可以选择删掉。
今天先分享到这里~
开启实践:SD绘画 | 为你所做的学习过滤

















![LeetCode[中等] 45. 跳跃游戏 II](https://i-blog.csdnimg.cn/direct/7cf5f957d52a45bbac71b95016cb2b4c.png)