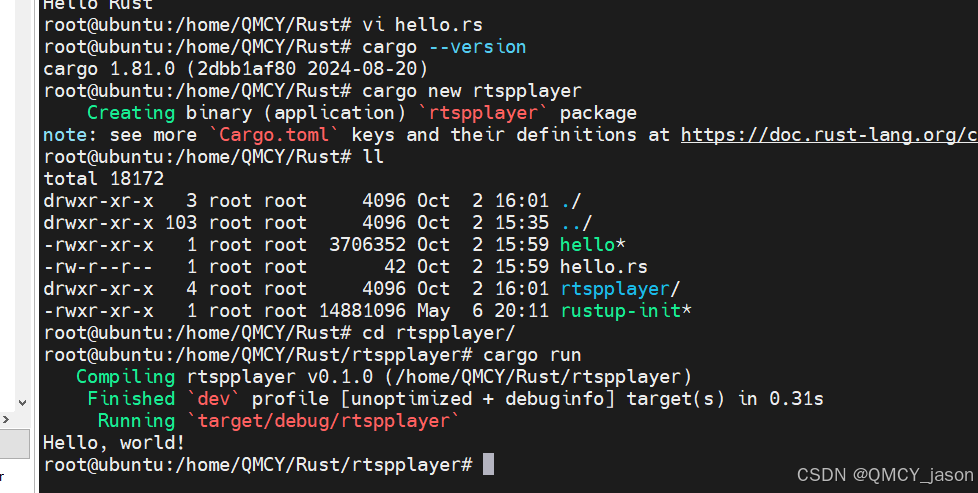
一、模型本地部署准备
1、
conda create -n ollama python==3.8
2、
curl -fsSL https://ollama.com/install.sh | sh
3、验证安装
安装完成后,通过运行以下命令来验证Ollama是否正确安装:
ollama --version

4、启动ollama
ollama serve
模型地址:
- https://ollama.com/library/glm4
- https://ollama.com/library/codegeex4
安装
#执行以下命令即可部署运行ollama run glm4
ollama run codegeex4二、codegeex4部署运行
1、
ollama run codegeex4
启动之后,就可以进行对话测试了。
2、模型对话体验
Ollama启动后可以直接输入提示信息,按回车键发送即可

三、下载GGUF模型
- glm-4-9b-chat-GGUF
- codegeex4-all-9b-GGUF
使用modelscope下载
先安装 pip install modelscope
命令1
modelscope download --model=LLM-Research/glm-4-9b-chat-GGUF --local_dir . glm-4-9b-chat.Q5_K.gguf
命令2
modelscope download --model=LLM-Research/codegeex4-all-9b-GGUF --local_dir . codegeex4-all-9b-Q5_K_M.gguf
3.1
四、使用
-
启动ollama服务
ollama serve -
创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下:
FROM /path/to/glm-4-9b-chat.Q5_K.gguf
#FROM /path/to/codegeex4-all-9b-Q5_K_M.gguf
# set parameters
PARAMETER stop "<|system|>"
PARAMETER stop "<|user|>"
PARAMETER stop "<|assistant|>"
TEMPLATE """[gMASK]<sop>{{ if .System }}<|system|>
{{ .System }}{{ end }}{{ if .Prompt }}<|user|>
{{ .Prompt }}{{ end }}<|assistant|>
{{ .Response }}"""
3.创建自定义模型
使用ollama create命令创建自定义模型ollama create myglm4 --file ModelFile
4.运行模型ollama run myglm4
五、模型API调用
ollama启动后会对外提供端口为11434的API服务,我们可以基于API进行模型对话测试
1)API调用测试一:
curl http://localhost:11434/api/chat -d '{
"model": "codegeex4",
"stream": false,
"messages": [
{ "role": "user", "content": "什么是AI大模型" }
]
}'
模型返回如下:
{"model":"codegeex4","created_at":"2024-08-14T08:21:18.066601982Z","message":{"role":"assistant","content":"AI大模型,通常是指基于深度学习的复杂神经网络架构,如深度神经网络(DNN)、卷积神经网络(CNN)或Transformer等。这些模型在处理大量数据时表现出极高的效率和准确度,可以应用于各种不同的任务,例如图像识别、自然语言处理、语音识别和生成、机器翻译、推荐系统等。\n\nAI大模型的训练需要大量的计算资源和数据,通常需要使用高性能的硬件设备,如图形处理器(GPU)或张量处理单元(TPU)。这些模型在参数数量上通常非常大,包含数百万甚至数十亿个参数。通过在大规模数据集上的迭代学习,它们能够从数据中自动提取出高级特征和模式,从而实现高度自动化、高效和智能的应用。\n\n随着技术的进步,AI大模型不仅在学术界得到了广泛的研究和应用,也在工业界取得了显著的成功,推动了人工智能的快速发展。"},"done_reason":"stop","done":true,"total_duration":1951689855,"load_duration":26872764,"prompt_eval_count":10,"prompt_eval_duration":20903000,"eval_count":179,"eval_duration":1860269000}
2)API调用测试二:
curl http://localhost:11434/api/chat -d '{
"model": "codegeex4",
"stream": false,
"messages": [
{ "role": "user", "content": "请使用python编写一个快速排序" }
]
}'
模型返回如下:
{"model":"codegeex4","created_at":"2024-08-14T08:19:05.686416111Z","message":{"role":"assistant","content":"当然可以。快速排序(Quick Sort)是一种高效的排序算法,采用分而治之的策略将一个大列表分成两个小列表。下面是一个简单的Python实现:\n\n```python\ndef quick_sort(arr):\n if len(arr) \u003c= 1:\n return arr\n else:\n pivot = arr[0]\n less_than_pivot = [x for x in arr[1:] if x \u003c= pivot]\n greater_than_pivot = [x for x in arr[1:] if x \u003e pivot]\n return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)\n\n# 测试\nif __name__ == \"__main__\":\n test_list = [3, 6, 8, 10, 1, 2, 1]\n print(\"原始列表:\", test_list)\n sorted_list = quick_sort(test_list)\n print(\"排序后的列表:\", sorted_list)\n```\n\n这个代码定义了一个名为`quick_sort`的函数,它接受一个列表作为参数并返回排序后的列表。这个实现使用了分而治之的策略:首先选择一个“基准”元素(在这个例子中是列表的第一个元素),然后重新排列列表中的所有元素,使得那些比基准小的元素都在基准的前面,而比基准大的元素都在基准的后面。这个过程在较小的子列表上递归重复进行,直到整个列表排序完成。\n\n请注意,这个实现是为了演示和理解算法基本概念而设计的。在实际应用中,快速排序通常会有更高效的版本,特别是在处理大数据集时。"},"done_reason":"stop","done":true,"total_duration":3541571137,"load_duration":26828645,"prompt_eval_count":13,"prompt_eval_duration":20696000,"eval_count":322,"eval_duration":3451936000}
参考:国产开源代码模型之光:CodeGeeX4 - ALL - 9B本地部署体验实战大全-CSDN博客
参考:【ollama】ollama运行GLM4-9B和CodeGeeX4-ALL-9B_ollama glm4-CSDN博客