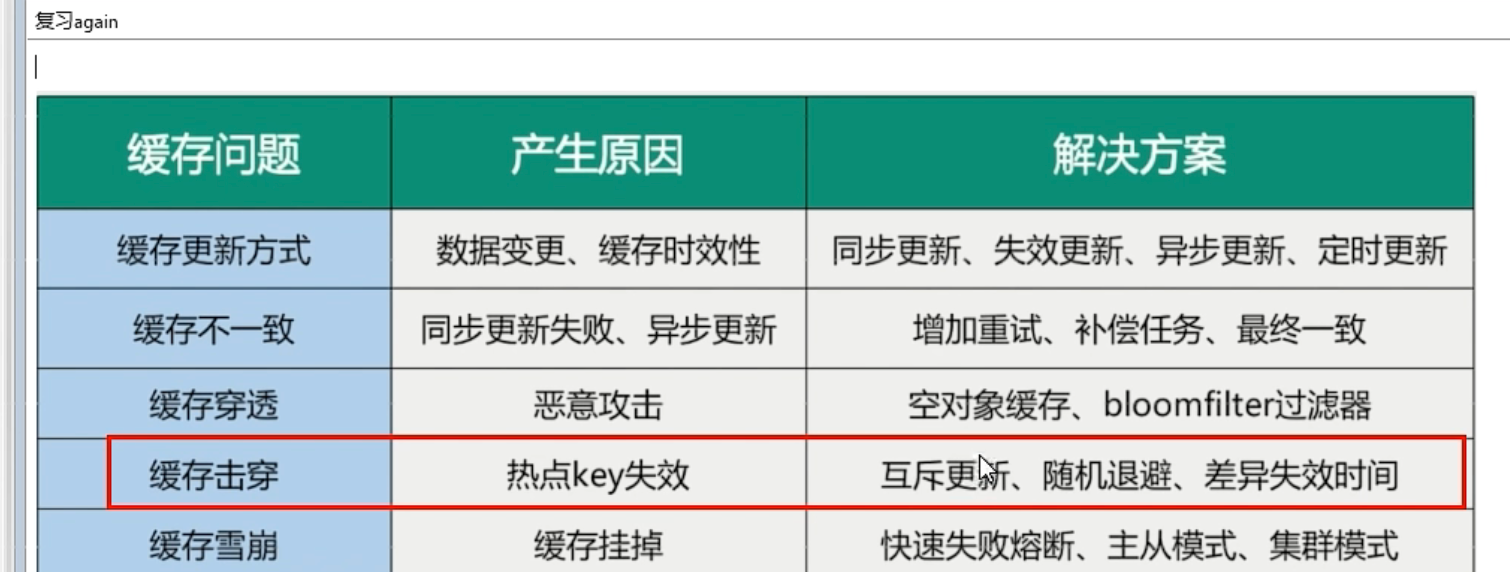
今天我们即将要开始讲解算法中第一块儿难啃地骨头--递归了,相信有不少小伙伴都因递归而迷惑过,本文就来给大家详细的讲解一下递归到底是什么东西。让你也能瞬间将他打回原形。
递归的理解
在学习递归之前,我们先理解递归。什么是递归呢?从名字上看我们可以想到递进+回归两个词,那么我们实际的递归也有这么两个过程,只不过有些人将它称为前进状态和后退状态,也有人将后者称为回溯地过程。不过我们后面会有单独的一个讲解回溯的章节,所以我在这里就按我的理解来称呼了。(称呼什么的无所谓,主要是你能理解这个过程)。从另一个官方的角度来解释递归,就是一种解决问题的方法,它通过函数调用自身来实现。
递归的故事
博主在网上搜寻资料时,看到大多数都是通过“从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的是什么呢?讲的是"从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的是什么呢?讲的是"从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的是什么呢?讲的是“讲完了,睡觉”"讲完了,睡觉"讲完了,睡觉”这个例子来引入递归的。我觉得这个故事对递归的说明还不是那么地贴切。在这里我给出另一个生动的故事来形象化这个概念:
一个小孩在一个高大的山上。他想知道山的另一边是什么样子,于是他决定向下走。(问题引入:功能需求)
他问他遇到的每一个人:“山的另一边有什么?”其中一个人告诉他:“这里也有个小孩,他知道山的另一边更清楚。”于是这个小孩找到下一个小孩,问:“你知道山的另一边有什么吗?”这个小孩又回答:“等一下,我再去问我的朋友。”(解决方法:拆解问题,层层递推)
这样,孩子们通过询问,把问题层层递归地传递下去,直到某个小孩找到一个真正到了山的另一边的人,得到了答案。(结束条件:基线状态)
然后这个小孩从别人口中得知山的另一边,他就回头告诉问他的那个人山的另一边是什么,依次回退。(问题解决,依次回归)
这个过程就是递归:通过拆解问题,直到找到简单和直接的解决方案。
故事图解:

代码:
string kid(vector<string>& kids, int i){
if(kids[i]=="我知道了")
return kids[i];//如果第i个小孩知道了,就将这个答案返回去
//else,否则执行下面的代码
return kid(kids,i+1);//在这群孩子中,返回下一个孩子知道的答案,下一个不知道的话,会一直往下问,直到有个孩子知道答案,就开始将答案返回了。
};
string kid(vector<string>& kids, int i){
if(kids[i]=="我知道了") return kids[i];
string ans=kid(kids,i+1);
return ans;
}代码图解 :

递归的代码示例
让我们来看一个简单的代码示例——计算阶乘。阶乘是一个经典的递归问题,可以用递归来优雅地解决。
#define Long long long
Long function(int n)
{
if(n==0)return 1;//确定结束条件
return n*function(n-1);//递归调用
}在这个例子中:
功能:计算一个数的阶乘。
结束条件:当 `n` 等于 0 时,返回 1(因为 0! = 1)。
等价关系式:其他情况下,`n! = n * (n-1)!`。这个表达式使得我们能把问题分解为更小的部分,最终能解决。

在这里,假设main()是主调函数 f(int a)就作为main()的被调函数。main()调用f(6),f(6)调用f(5),f(5)调用f(4),f(4)调用f(3),f(3)调用f(2),f(2)调用f(1);而f(1)达成了结束条件,开始返回f(1)的值,在f(2)中f(1)调用完毕,就返回f(2)的值,依次回归。直至f(6)返回,回到main()主函数。
递归的优缺点
一、优点
1. 优雅性:递归允许我们以一种简洁和优雅的方式编写代码,特别适合解决具有递推关系的问题。
2. 清晰性:通常情况下,使用递归可以使代码更易读。
二、缺点
1. 栈溢出:递归调用会消耗栈空间,如果递归深度过大,可能会导致栈溢出。
2. 性能问题:在某些情况下,递归的性能不如迭代算法,尤其是没有使用尾递归优化或记忆化的情况下。
优化递归
1. 尾递归:尾递归指的是递归调用是函数的最后一步,可以通过编译器优化避免堆栈增长,从而减少栈溢出的风险。
2. 记忆化:记忆化是一种优化技术,保存已计算的结果,以避免重复计算。这在处理重叠子问题时尤为有效,例如在求 Fibonacci 数列时。
一、尾递归
略
二、记忆化
1201:菲波那契数列
时间限制: 1000 ms 内存限制: 65536 KB【题目描述】
菲波那契数列是指这样的数列: 数列的第一个和第二个数都为1,接下来每个数都等于前面2个数之和。
给出一个正整数a,要求菲波那契数列中第a个数是多少。
【输入】
第1行是测试数据的组数n,后面跟着n行输入。每组测试数据占1行,包括一个正整数a(1<=a<=20)。
【输出】
输出有n行,每行输出对应一个输入。输出应是一个正整数,为菲波那契数列中第a个数的大小。
正常来说,这道题很简单,写一个计算斐波那契第i位的递归函数就可以了。
#include <bits/stdc++.h>
using namespace std;
#define Long long long
Long func(int n) {
if (n == 1 || n == 2)return 1;//斐波那契数列第一二项是必然已知的。所以这就是我们的基线条件
return func(n - 1) + func(n - 2);//斐波那契的等价关系式也是已知的,前两项之和
}
int main() {
int n; cin >> n;
for (int i = 0; i < n; i++) {
int x; cin >> x;
cout << func(x) << endl;
}
return 0;
}
对于斐波那契第5个数,需要推到出来,我们正常的步骤是17步。 (一会跟后面对比一下)
对于本题而言,需要输出n组数据,每次打印第i个数据斐波那契数列的值。假如我们第一组数据是100,第二组数据是99,我们每次都调用递归,是不是感觉它很烦,明明第99位斐波那契数我已经推到出来过了,我还要重新推导。所以,我们需要采用记忆化的方法,来解决这个问题。
#include <bits/stdc++.h>
using namespace std;
#define Long long long
Long fib[25]={0,1,1};
Long fuc(int i){
if(fib[i]) return fib[i];
fib[i]=func(i-1)+func(i-2);
return fib[i];
}
int main() {
int n; cin >> n;
for (int i = 0; i < n; i++) {
cin >> x;
cout<<fuc(x)<<endl;
}
return 0;
}我们定义一个全局数组(此处又称记忆数组)fib,用fib[i]来表示第i个斐波那契数的值。初始我们将fib[1]和fib[2]的值设置为1。这次再进行斐波那契数列的递归调用时,我们每推导出一个fib[i]都先给他存起来,之后求func(i)时我们就可以直接拿fib[i]这个数组的值了。这就是记忆化的过程。

我们可以明显的看出来,少了四步,然而这只是fib5,当求的位数越大时,调用栈的次数就会少,记忆化的优势就越明显。( 这个结构类似于二叉搜索树)。由于左面的子树的存储的位数比右面都要靠后,当我一条线走完左面的子树时,右面的子树全部都被存储到了记忆化数组中去,之后就不用再依次往下递归了,从这个角度来说,树的深度越大,记忆化的好处越明显。
递归的知识串烧
一、递归、递推、迭代
1、递推:其对应英文应该是recurrence relation(Inductive),即递推关系。什么是递推关系呢?从数学角度,递推关系往往可以用数学公式来表示。比如,高中学的等差数列、等比数列,a1=1, an=再比如fibonacci,Fn = Fn-1+Fn-2.递推可以理解是数学上的概念。从已知到未知, 从1 往 n推(未知)。递进 依次 推算。
2、递归:对应英文recursion,这是一个计算机科学里的概念,其定义为函数自己调用自己。计算机科学里除了递归,还有一个是迭代,它们和递推三者的关系,可以理解为:
在编程里,递推关系可以通过递归或者迭代来实现,但是递归和迭代又不仅仅只能用来实现递推关系。从未知到已知 Recursive是从n(未知)往1推, 再层层返回归纳
3、迭代(辗转) --Iterative ,不断将结果当做变量带入,就叫迭代
总结:
1,从程序上看,递归表现为自己调用自己,迭代则没有这样的形式。
2,递归是从问题的最终目标出发,逐渐将复杂问题化为简单问题,最终求得问题
是逆向的。迭代是从简单问题出发,一步步的向前发展,最终求得问题。是正向的。
3,递归中,问题的n要求是计算之前就知道的,而迭代可以在计算中确定,不要求计算前就知道n。
4,一般来说,递推的效率高于递归(当然是递推可以计算的情况下)
二、递归与栈
在C++中,递归和栈有着密切的关系。以下是它们之间的一些关键联系:
-
调用栈:
- 当一个函数被调用时,程序会将该函数的执行状态(包括参数、局部变量和返回地址)压入调用栈中。递归调用函数时,每次调用都会在栈上创建一个新的帧,包含该调用的上下文信息。
-
递归函数:
- 递归函数是直接或间接调用自身的函数。每个递归调用都会把当前函数的信息推入栈中,直到达到基准条件(即递归停止条件),这时栈开始逐层回退,逐步返回结果。
-
栈溢出:
- 由于每次递归调用都会占用栈空间,如果递归深度过大,可能会导致栈溢出(stack overflow),从而使程序崩溃。这通常会发生在递归深度过大或者没有合适的基准条件时。
-
栈的使用:
- 在递归过程中,每个调用都有其独立的局部变量和状态,这些信息都存储在栈中。因此,栈为递归提供了存储上下文的机制。
-
尾递归优化:
- 在某些编程语言中,如果一个递归调用是函数的最后一步(尾递归),编译器可以优化这个调用,以避免增加栈深度。不过,C++标准并不保证支持尾递归优化,因此在C++中使用尾递归仍然需要谨慎。
综上所述,递归依赖于栈来管理函数调用的状态,理解二者的关系能够帮助我们更有效地使用递归,同时避免可能的问题。
注意事项
尽管递归是一种强大的工具,有时并不是所有问题都适合用递归来解决。在选择使用递归时,应考虑问题的特性,确保其能提升代码的可读性和可维护性。
结语
递归是一种解决问题的策略,通过函数自我调用来分解问题。它需要明确的功能、结束条件和等价关系式,尽管递归有其优点和缺点,但在适当的情况下,它能够提供简洁和优雅的解决方案。
感谢大家观看!