在标准 RAG 中,输入文档包含文本数据。LLM 利用上下文学习,通过检索与所提查询上下文相匹配的文本文档块来提供更相关、更准确的答案。
但是,如果文档包含图像、表格、图表等以及文本数据,该怎么办?
不同的文档格式包括:
- PDF(便携式文档格式):通常用于跨平台共享保留其格式的文档,但由于其非结构化布局,因此很难从中提取数据。
- Microsoft Word 文档(.doc、.docx):灵活且广泛使用,但可能包含表格、图像、页眉和页脚,使提取变得具有挑战性。
- Excel 电子表格(.xls、.xlsx):虽然 Excel 文件更具结构性,但它们可能包含复杂的多页数据、合并单元格和公式。
- 扫描图像(.jpg、.png、.tiff):扫描文档增加了另一层复杂性,因为它们需要光学字符识别 (OCR) 先将图像转换为文本,然后再提取数据。
- HTML 和纯文本文件:虽然提取数据比较简单,但这些格式中可能布局的多样性使其变得并非易事。
每种格式都有自己的结构和挑战,但真正的困难来自这些格式中的差异。例如,PDF 可以是单列或多列,可能包含表格或图表,并且可以有页眉、页脚、图像或图表。这种广泛的可能性使得创建通用解决方案变得不切实际。
处理此类文档的主要挑战:
- 格式多变性:不同格式具有不同的特征,使数据提取变得复杂。例如,PDF 可能包含图像或表格,而扫描的文档可能质量较差或手写。
- 数据完整性:确保提取数据的准确性和完整性至关重要。不准确的数据会导致决策失误和运营效率低下。
- 容量管理:文档数量的增加可能会使传统的提取方法不堪重负,因此需要高级解决方案来有效处理大型数据集。
标准 LLM 将忽略这些附加信息。在这里,RAG 系统必须依靠 OCR 工具从表格、图像等中提取信息。但是,对于具有复杂格式、表格或图像的文档,OCR 准确度通常较低。尽管 OCR 技术近年来有了显着改进,并且通常用于从扫描图像中提取文本。但是,它仍然会产生错误,尤其是在扫描质量较差的情况下,并且难以处理复杂的布局,例如多列 PDF 或包含文本和图像混合的文档。这将导致不相关或误导性的文本块被索引,当检索和扩充到 LLM 上下文中时,会对 LLM 合成的答案的质量产生负面影响。
随着大型语言模型及其理解文本和图像的能力的快速发展,我们可以利用它们从图像、图表和表格中推断信息的能力。
在这里,我们将使用多模态 LLM ColPali 从复杂的 PDF 文档中推断信息。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是 ColPali?
ColPali 是一种基于视觉语言模型 (VLM) 的新型模型架构和训练策略的模型,可有效地根据文档的视觉特征对其进行索引。它是 PaliGemma-3B 的扩展,可生成文本和图像的 ColBERT 样式多向量表示。它在论文《ColPali:使用视觉语言模型进行高效文档检索》中进行了介绍
在 RAG 系统中,它用作视觉检索器:
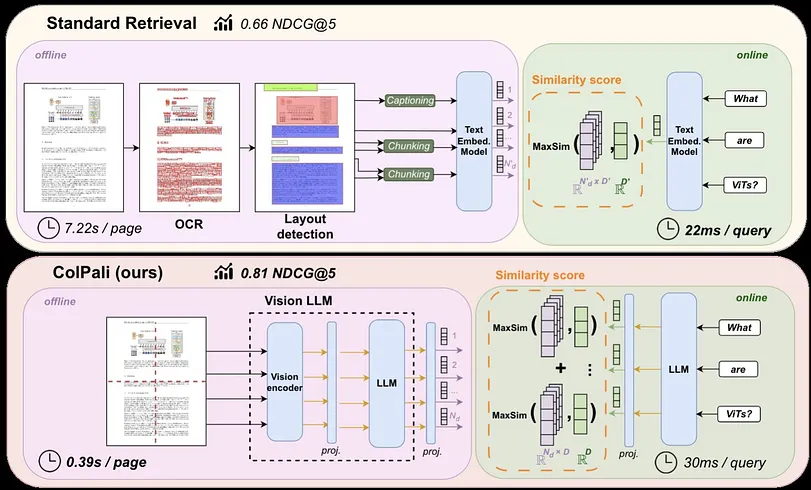
ColPali 的一项关键创新是将图像块映射到与文本相似的潜在空间中。它使用 COLBERT 策略解锁文本和图像之间的有效交互。
ColPali 基于两个观察结果:
- 多向量表示和后期交互评分可提高检索性能。
- 视觉语言模型在理解视觉内容方面表现出非凡的能力。
ColPali 用于将多模态文档转换为图像表示,然后计算它们的多向量表示,并将其存储为索引。VLM 可以进一步使用它来回答问题。
2、什么是 COLBERT?
ColBERT 代表 BERT 上的情境化后期交互,是一种专为高效信息检索而设计的创新模型。它在论文“ColBERT:通过 BERT 上的语境化后期交互实现高效且有效的段落搜索”中进行了介绍
ColBERT 的主要特点:
- 标记级表示:与将标记表示压缩为单个向量的传统模型不同,ColBERT 为每个标记维护单独的嵌入。这允许在查询词和文档词之间进行更细致的相似度计算。
- 后期交互机制:ColBERT 采用后期交互策略,其中查询和文档在检索的最后阶段之前分开处理。该机制通过允许进行详细比较而无需预先进行详尽的计算来提高效率。
- 改进的检索性能:ColBERT 在各种基准测试中都表现出卓越的性能,甚至在某些任务中优于更大的模型。它的设计使其能够有效地处理复杂的查询和文档结构。
- 版本:原始 ColBERT 模型已被 ColBERTv2 所取代,该模型融合了去噪监督和残差压缩等增强功能,进一步提高了其在检索任务中的有效性和效率。
ColBERT 特别适合需要高精度搜索任务的应用,使其成为自然语言处理和信息检索等领域的宝贵工具。
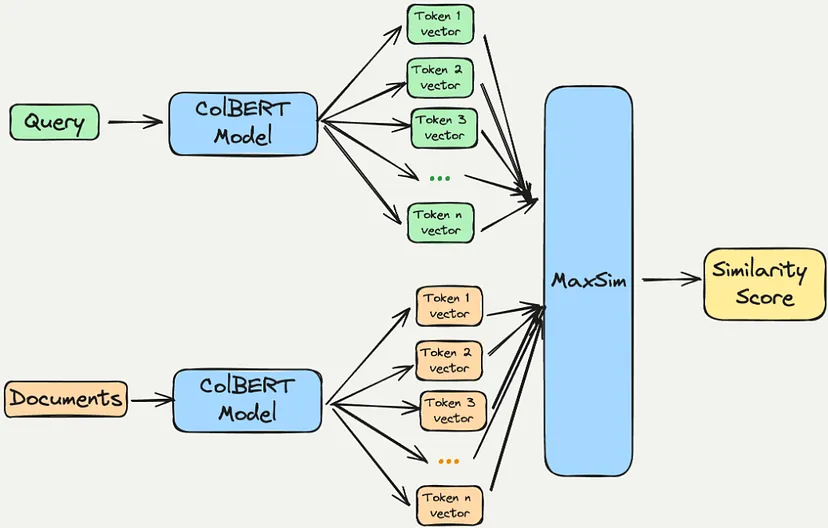

早期交互会增加计算复杂度,因为它需要考虑所有可能的查询-文档对,因此对于大规模应用来说效率较低。
后期交互模型(如 ColBERT)通过允许预先计算文档表示并在最后采用更轻量级的交互步骤(侧重于已编码的表示)来优化效率和可扩展性。这种设计选择可以缩短检索时间并减少计算需求,使其更适合处理大型文档集合。
3、什么是视觉语言模型?
视觉语言模型 (VLM) 是集成视觉和文本信息的高级 AI 系统,使它们能够执行需要理解和基于图像生成文本的各种任务。以下是它们的主要特征和应用的概述:
定义和功能:
- 多模态学习:VLM 同时从图像及其相应的文本描述中学习。这使它们能够将视觉特征与语言表达联系起来,从而增强它们理解两种模态中的上下文和语义的能力。
- 生成能力:这些模型可以根据图像输入生成文本输出,使其可用于图像字幕等任务,在这些任务中,它们可以为给定的图像创建描述性文本。
主要特点:
- 图像和文本编码:VLM 通常由用于图像和文本的单独编码器组成。它们融合来自这些编码器的信息以全面理解输入数据。
- 零样本学习:许多 VLM 表现出强大的零样本能力,这意味着它们可以很好地推广到新任务而无需额外的训练数据。
- 空间感知:某些模型可以捕获图像内的空间关系,从而使它们能够在识别图像中的特定对象或区域时输出边界框或分割蒙版
多模态 RAG 实施步骤:
- 使用 ColPali 对所需输入文档进行编码,并将生成的嵌入索引并存储在 VectorStore 中。
- 然后使用 ColPali 对用户查询进行编码,并使用生成的嵌入从 VectorStore 中检索可能包含文本和图像的类似文档块。
- 然后,RAG 系统使用检索到的块作为输入,通过用户查询增强上下文,以方便 VLM 响应用户查询。
多个向量数据库支持多向量架构或 ColBERT 样式表示,从而实现对高维向量数据的高效索引和检索。以下是一些值得注意的选项:
- Vespa:Vespa 引入了多向量支持,允许每个文档索引多个向量。此功能允许根据每个文档中最接近的向量检索文档,使其适用于复杂的数据表示和语义搜索应用程序。
- Pinecone:Pinecone 专为管理向量嵌入而设计,并支持高级查询功能,包括处理多个向量表示。它针对 AI 应用进行了优化,使其成为需要细致入微的数据表示任务的有力候选者。
- Qdrant:Qdrant 是一个专门的矢量数据库,可以高效地索引和检索高维矢量数据。虽然它主要关注单矢量嵌入,但它适用于各种架构,包括可能需要多矢量设置的架构
所需的技术栈:
- 用于运行 Qwen2-VL-7b-Instruct VLM 的 Transformers 库。
- 如果我们想在消费级 GPU(24 GB VRAM)上运行 VLM(Qwen2-VL),则需要 Flash Attention。
- Byaldi 是 ColPali 存储库的包装器,这使得 ColPali 可以非常轻松地用于 RAG
- qwen_vl_utils 以方便 Qwen-VL 的输入处理。
- pdf2image 用于将 PDF 页面转换为图像。这是必要的,因为 Qwen2-VL 无法编码 PDF 文件。
- byaldi 需要 popller-utils 来索引 PDF 页面。
- Groq 使用 Llava 模型作为 VLM 并检查响应质量
代码实现:
需要google colab Nvidia A100
安装所需的依赖项:
!pip install -qU byaldi
!pip install -qU accelerate
!pip install -qU flash_attn
!pip install -qU qwen_vl_utils
!pip install -qU pdf2image
!pip install -qU groq
!python -m pip install git+https://github.com/huggingface/transformers!sudo apt-get update
!apt-get install poppler-utils下载数据:
!mkdir Data
!wget https://arxiv.org/pdf/2409.06697 -O Data/input.pdf导入必要的依赖:
from byaldi import RAGMultiModalModel
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
from pdf2image import convert_from_path
import groq从 byaldi 使用 RAGMultiModal 加载 ColPali:
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali")加载视觉模型:
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="cuda")使用 byaldi 索引 PDF 文件:
RAG.index(input_path="Data/input.pdf",
index_name="multimodal_rag",
store_collection_with_index=False,
overwrite=True,)根据用户查询从 Vectorstore 检索上下文:
text_query = "What is the type of star hosting thge kepler-51 planetary system?"
results = RAG.search(text_query,k=3)
results
###### RESPOSNE #####
[{'doc_id': 1, 'page_num': 1, 'score': 25.125, 'metadata': {}, 'base64': None},
{'doc_id': 1, 'page_num': 8, 'score': 24.875, 'metadata': {}, 'base64': None},
{'doc_id': 1, 'page_num': 9, 'score': 24.125, 'metadata': {}, 'base64': None}]转换为实际图像数据:
images = convert_from_path("Data/input.pdf")
image_index = results[0]["page_num"] -1显示所选文档图像:
from IPython.display import Image,display
display(images[image_index])
from IPython.display import Image,display
display(images[1])
保存图像:
from PIL import Image
# Assuming 'img' is your image object
images[image_index].save('image1.jpg')设置Groq Api Key:
from google.colab import userdata
import os
os.environ["GROQ_API_KEY"] = userdata.get("GROQ_API_KEY")使用 GROQ 合成响应 — llava-v1.5–7b-4096-preview 模型
LLaVA V1.5 7B(预览版)-Groq
- 模型 ID:llava-v1.5–7b-4096-preview
- 描述:LLaVA(大型语言和视觉助手)是一个开源、经过微调的多模态模型,可以生成图像的文本描述,在多模态指令跟踪任务上取得了令人印象深刻的性能,并在某些基准上超越了 GPT-4。
- 上下文窗口:4,096 个令牌
限制:
- 预览模型:Llava V1.5 7B 目前处于预览阶段,应用于实验。
- 图像大小限制:包含图像 URL 作为输入的请求的最大允许大小为 20MB。
大于此限制的请求将返回 400 错误。 - 请求大小限制(Base64 编码图片):包含 Base64 编码图片的请求的最大允许大小为 4MB。大于此限制的请求将返回 413 错误。
- 每个请求单个图片:每个请求只能处理一个图片。包含多个图片的请求将返回 400 错误。
- 每个请求单个用户消息:目前不支持多轮对话,每个请求只允许一条用户消息。包含多个用户消息的请求将返回 400 错误。
- 无系统提示或助手消息:目前不支持系统消息和助手消息。包含系统或助手消息的请求将返回 400 错误。
- 无工具使用:目前不支持工具使用。包含工具使用或函数调用的请求将返回 400 错误。
- 无 JSON 模式:目前不支持 JSON 模式。启用 JSON 模式的请求将返回 400 错误。
from groq import Groq
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "/content/image1.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
client = Groq()
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": text_query},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
model="llava-v1.5-7b-4096-preview",
)
print(chat_completion.choices[0].message.content)
## Response ##
The type of star hosting the Kepler-51 planetary system is a F-type main-sequence star, known as Fp Lacertae. This star is located at roughly 3,090 light-years from Earth. Fp Lacertae is considered a B-type dwarf star, meaning it emits a relatively larger amount of intense light, and the planet Kepler 51i is seen orbitsing the star.使用 QWEN2-VL-7B-INSTRUCT 视觉语言模型进行响应合成:
messages = [
{"role":"user",
"content":[{"type":"image",
"image":images[image_index]
},
{"type":"text","text":text_query}
]
}
]
#
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
#
image_inputs,video_inputs = process_vision_info(messages)
#
inputs = processor(text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt")
inputs = inputs.to("cuda")
#
generate_ids = model.generate(**inputs,
max_new_tokens=256)
#
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)]
#
output_text = processor.batch_decode(generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
#
print(output_text[0])
#### RESPONSE ####
'The host star of the Kepler-51 planetary system is a G-type star.'在这里我们观察到 Qwen2-VL 呈现出更准确、更好的结果。
提出另一个查询:
text_query = "What is the age of the star hosting the kepler-51 planetary system?"
#
messages = [
{"role":"user",
"content":[{"type":"image",
"image":images[image_index]
},
{"type":"text","text":text_query}
]
}
]
#
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
#
image_inputs,video_inputs = process_vision_info(messages)
#
inputs = processor(text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt")
inputs = inputs.to("cuda")
#
generate_ids = model.generate(**inputs,
max_new_tokens=256)
#
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)]
#
output_text = processor.batch_decode(generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
#
print(output_text[0])
#
################ RESPONSE ##################################
The host star is a G-type star of age ~500 Myr.4、结束语
ColPali 代表了多模态文档检索的重大进步,将 VLM 的优势与创新的架构选择相结合。它能够有效地处理和检索复杂文档中的信息,使其成为不断发展的 AI 驱动数据分析和检索系统领域中一种有价值的工具。
在这里,我们使用 ColPali 作为视觉检索器,使用 Qwen2-VL 作为视觉语言模型,构建了一个多模态 RAG 管道。我们还使用 Llava 模型测量了性能。
原文链接:多模态RAG实现 - BimAnt