作者: 数据源的TiDB学习之路 原文来源: https://tidb.net/blog/818f84f0
TiDB Lightning 是用于从静态文件导入 TB 级数据到 TiDB 集群的工具,常用于 TiDB 集群的初始化数据导入。在开源社区版本中,TiDB Lightning 支持以下文件类型的导入:
- Dumpling 生成的文件
- CSV 文件
- Amazon Aurora 生成的 Apache Parquet 文件
在企业版本TiDB v7.5.1中,TiDB Lightning增加了对Hive ORC文件格式的支持,本文简要描述如何使用 Lightning 导入 ORC 文件。
准备ORC文件
首先需要准备好 ORC 文件,这可以通过从 Hive 中使用 hdfs get 命令导出,示例如下。
这里 /path/to/hdfs/orc/file.orc 是 HDFS 上的 ORC 文件路径, /local/path/to/save/file.orc 是你希望将文件保存到的本地文件系统路径。确保本地路径存在,并且你有足够的权限去写入指定的本地路径。如果本地路径不存在,命令会失败。如果你没有指定本地文件名,那么文件会保持原有的名字和扩展名。
hdfs dfs -get /path/to/hdfs/orc/file.orc /local/path/to/save/file.orc
确认ORC文件能正常解析
保证 ORC 文件是可用的,要验证 ORC 文件可用,可以使用 orc-tools 工具尝试解析。orc-tools 是一个 jar 包,可以通过 java 命令行方式来使用,主要包括两种方式:解析数据、解释元数据。
- 解析数据
java -jar orc-tools-1.6.3-uber.jar data orc文件名
样例输出:
[root@host-xx packages]# java -jar orc-tools-1.6.3-uber.jar data 000000_0
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Processing data file 000000_0 [length: 24442]
{"sysday":"20160102","workday":"20151231","isworkday":"0","lastday":"20160101","nextday":"20160103","lastworkday":"20151231","nextworkday":"20160104","updatetime":"2018-08-02 17:26:05.42"}
{"sysday":"20160207","workday":"20160205","isworkday":"0","lastday":"20160206","nextday":"20160208","lastworkday":"20160205","nextworkday":"20160215","updatetime":"2018-08-02 17:26:05.42"}
{"sysday":"20160214","workday":"20160205","isworkday":"0","lastday":"20160213","nextday":"20160215","lastworkday":"20160205","nextworkday":"20160215","updatetime":"2018-08-02 17:26:05.42"}
{"sysday":"20160221","workday":"20160219","isworkday":"0","lastday":"20160220","nextday":"20160222","lastworkday":"20160219","nextworkday":"20160222","updatetime":"2018-08-02 17:26:05.42"}
...
- 解释元数据
java -jar orc-tools-1.6.3-uber.jar meta orc文件名
样例输出:
[root@host-xx packages]# java -jar orc-tools-1.6.3-uber.jar meta 000000_0
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Processing data file 000000_0 [length: 24442]
Structure for 000000_0
File Version: 0.12 with HIVE_4243
Rows: 1224
Compression: ZLIB
Compression size: 262144
Calendar: Julian/Gregorian
Type: struct<sysday:char(8),workday:char(8),isworkday:char(1),lastday:char(8),nextday:char(8),lastworkday:char(8),nextworkday:char(8),updatetime:timestamp>
Stripe Statistics:
Stripe 1:
Column 0: count: 1224 hasNull: false
Column 1: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 2: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 3: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 2448
Column 4: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 5: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 6: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 7: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 8: count: 1224 hasNull: false min: 2018-08-02 17:26:00.799 max: 2023-10-30 09:38:56.51
File Statistics:
Column 0: count: 1224 hasNull: false
Column 1: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 2: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 3: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 2448
Column 4: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 5: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 6: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 7: count: 1224 hasNull: false minChildren: 9223372036854775807 maxChildren: 0 totalChildren: 19584
Column 8: count: 1224 hasNull: false min: 2018-08-02 17:26:00.799 max: 2023-10-30 09:38:56.51
Stripes:
Stripe: offset: 3 data: 23605 rows: 1224 tail: 126 index: 348
Stream: column 0 section ROW_INDEX start: 3 length 12
Stream: column 1 section ROW_INDEX start: 15 length 45
Stream: column 2 section ROW_INDEX start: 60 length 45
Stream: column 3 section ROW_INDEX start: 105 length 30
Stream: column 4 section ROW_INDEX start: 135 length 45
Stream: column 5 section ROW_INDEX start: 180 length 45
Stream: column 6 section ROW_INDEX start: 225 length 45
Stream: column 7 section ROW_INDEX start: 270 length 45
Stream: column 8 section ROW_INDEX start: 315 length 36
Stream: column 1 section DATA start: 351 length 3454
Stream: column 1 section LENGTH start: 3805 length 21
Stream: column 2 section DATA start: 3826 length 3398
Stream: column 2 section LENGTH start: 7224 length 21
Stream: column 3 section DATA start: 7245 length 241
Stream: column 3 section LENGTH start: 7486 length 6
Stream: column 3 section DICTIONARY_DATA start: 7492 length 5
Stream: column 4 section DATA start: 7497 length 3391
Stream: column 4 section LENGTH start: 10888 length 21
Stream: column 5 section DATA start: 10909 length 3394
Stream: column 5 section LENGTH start: 14303 length 21
Stream: column 6 section DATA start: 14324 length 3369
Stream: column 6 section LENGTH start: 17693 length 21
Stream: column 7 section DATA start: 17714 length 3362
Stream: column 7 section LENGTH start: 21076 length 21
Stream: column 8 section DATA start: 21097 length 1144
Stream: column 8 section SECONDARY start: 22241 length 1715
Encoding column 0: DIRECT
Encoding column 1: DIRECT_V2
Encoding column 2: DIRECT_V2
Encoding column 3: DICTIONARY_V2[2]
Encoding column 4: DIRECT_V2
Encoding column 5: DIRECT_V2
Encoding column 6: DIRECT_V2
Encoding column 7: DIRECT_V2
Encoding column 8: DIRECT_V2
File length: 24442 bytes
Padding length: 0 bytes
Padding ratio: 0%
________________________________________________________________________________________________________________________
当上述两条命令输出均正常无误时,可判断 ORC 文件正常被解析。笔者也碰到 ORC 文件无法被解析的情况,具体原因是因为从 Hive 导出数据时使用 hdfs getmerge 命令导出,此时生成的 ORC 文件无法被 Lightning 正常导入到 TiDB。
ORC文件重命名
使用 TiDB Lightning导入 ORC 文件与导入其他类型文件一样,需要保证 ORC 文件满足命令规则。关于文件命令规则,具体可以参考文档 TiDB Lightning 数据源
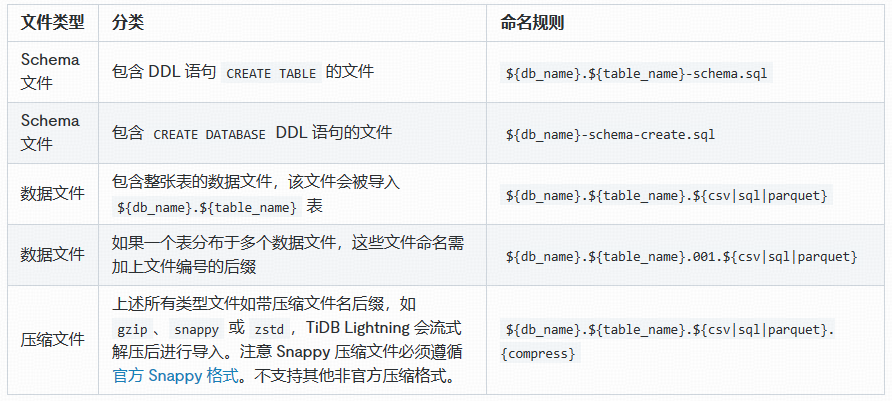
如上述表格所示,假设我们所要导入的 ORC 表名为 pdm.t06_date_info,那么我们需要将 ORC 文件重命名为 pdm.t06_date_info.orc。如果是有多个 ORC 文件,则需要命名为 pdm.t06_date_info.000.orc、pdm.t06_date_info.001.orc 等等。
编辑 Lightning.toml 配置文件
当文件名称符合导入命名规则后,将文件放置于固定的目录下,之后需要做的是准备 lightning.toml 导入配置文件。对比 CSV 格式文件的导入,ORC 文件的导入配置相对更简单,因为 ORC 文件的 delimiter、sperator 等配置通常都是固定的,不需要额外配置。以下是一个 ORC 文件的 lightning.toml 配置示例:
[lightning]
# 日志
level = "info"
file = "tidb-lightning.log"
[tikv-importer]
# 选择使用的导入模式
backend = "local"
# 设置排序的键值对的临时存放地址,目标路径需要是一个空目录
sorted-kv-dir = "/data1/ssd/sorted-kv-dir"
[mydumper]
# 源数据目录。
data-source-dir = "/data1/orc/"
[tidb]
# 目标集群的信息
host = "xx.xx.x.xx"
port = 4000
user = "xxx"
password = "xxx"
# 表架构信息在从 TiDB 的“状态端口”获取。
status-port = 10080
# 集群 pd 的地址
pd-addr = "xx.xx.x.xx:12399"
执行数据导入
执行导入的命令,与其他格式的文件导入没有不同。只不过,如果 TiDB 的版本与 Lightning 的版本不同,则可能会提示版本不匹配的错误,针对此问题,我们可以在命令中增加 -check-requirements=false 以跳过版本检查。
[root@host-xx packages]# /data1/packages/tidb-ee-toolkit-v7.5.1-0-linux-arm64/tidb-lightning -config lightning_orc.toml -check-requirements=false
Verbose debug logs will be written to tidb-lightning.log
tidb lightning exit successfully
从数据库中检查,数据已经正常导入。
后续
对于相同的数据量,ORC 文件由于是压缩的,大约是 TXT 文件的 1/3。因此在数据导入性能上,同样数据的导入性能可能也会有所差异,后续将使用同样大数据量的 ORC 和 TXT 文件进行 Lightning 导入测试,以便了解两者的导入性能差别。