如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
模型简介
模型背景
Swin Transfromer在2021年首次发表于论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》,目前已用于图像分割、分类等计算机视觉领域的各项任务中。该模型借鉴了Vision Transformer模型的思想,将二维图像加工成transformer可处理的一维数据,试图将transformer这一自然语言处理领域的利器,迁移至计算机视觉领域,以获得较优的模型性能。
目前,transformer应用到CV领域,需要克服一些难题:
- 随着图像的分辨率增加,展平后的序列长度呈平方级别增加,是模型不可接受的,将严重影响transformer中自注意力的计算效率;
- 不同于NLP模型的传统输入特征,同一物体的图像因拍摄角度等原因,尺度和内容特征方差较大。
Swin Transformer创新地引入了滑动窗口机制,在窗口内进行自注意力计算,使计算复杂度随图片分辨率平方级别增长降低为线性增长,并使模型可以学习到跨窗口的图像信息;参考了传统的CNN结构,进行类似的级联式局部特征提取工作,在每一层次进行下采样以扩大感受野,并可提取到多尺度的图像信息。
模型基本结构
Swin Transfromer的基本结构如图1(d)所示,由4个层级式模块组成,每一模块内包含一个Swin Transformer Block。原始输入图像尺寸为H×W×3(3为RGB通道数),经过Patch Partition层分为大小为4×4的patch,尺寸转换为(H/4)×(W/4)×48,其功能等价于卷积核大小为4×4,步长为4,卷积核个数为48的二维卷积操作。
随后,每个Stage内部由Patch Merging模块(Stage1为Linear Embedding)、Swin Transformer模块组成。以Stage1、Stage2为例:
-
Linear Embedding
线性嵌入模块(Linear Embedding)将图像的通道数调整为嵌入长度C,调整后的图像尺寸为(H/4)×(W/4)×C。
-
Swin Transformer
Linear Embedding模块的输出序列长度往往较大,无法直接输入transformer。在本模型中,将输入张量划分为m×m大小的窗口,其中m为每个窗口内的patch数量,原文模型中默认为7。自注意力计算将在每个窗口内展开。为提取窗口间的信息,对窗口进行滑动,并再次计算自注意力。有关Swin Transformer模块的自注意力计算等实现细节见下文。
-
Patch Merging
下采样模块(Patch Merging)的作用是降低图片分辨率,扩大感受野,捕获多尺寸的图片信息,同时降低计算量,如图1(a)所示。类比于下采样在CNN模型中的实现,Swin Transformer模块的输出经过一次下采样,由(H/4)×(W/4)×C转换为(H/8)×(W/8)×2C,将临近的2个小patch合并成一个大patch,相当于进行了步长为2的二维卷积操作,后经过线性层(或1×1卷积层)调整通道数至2C,功能等价于Patch Partition模块与Linear Embedding模块的先后组合。此后再经过多个Swin Transformer模块、Patch Merging模块,进行多尺度特征的提取。
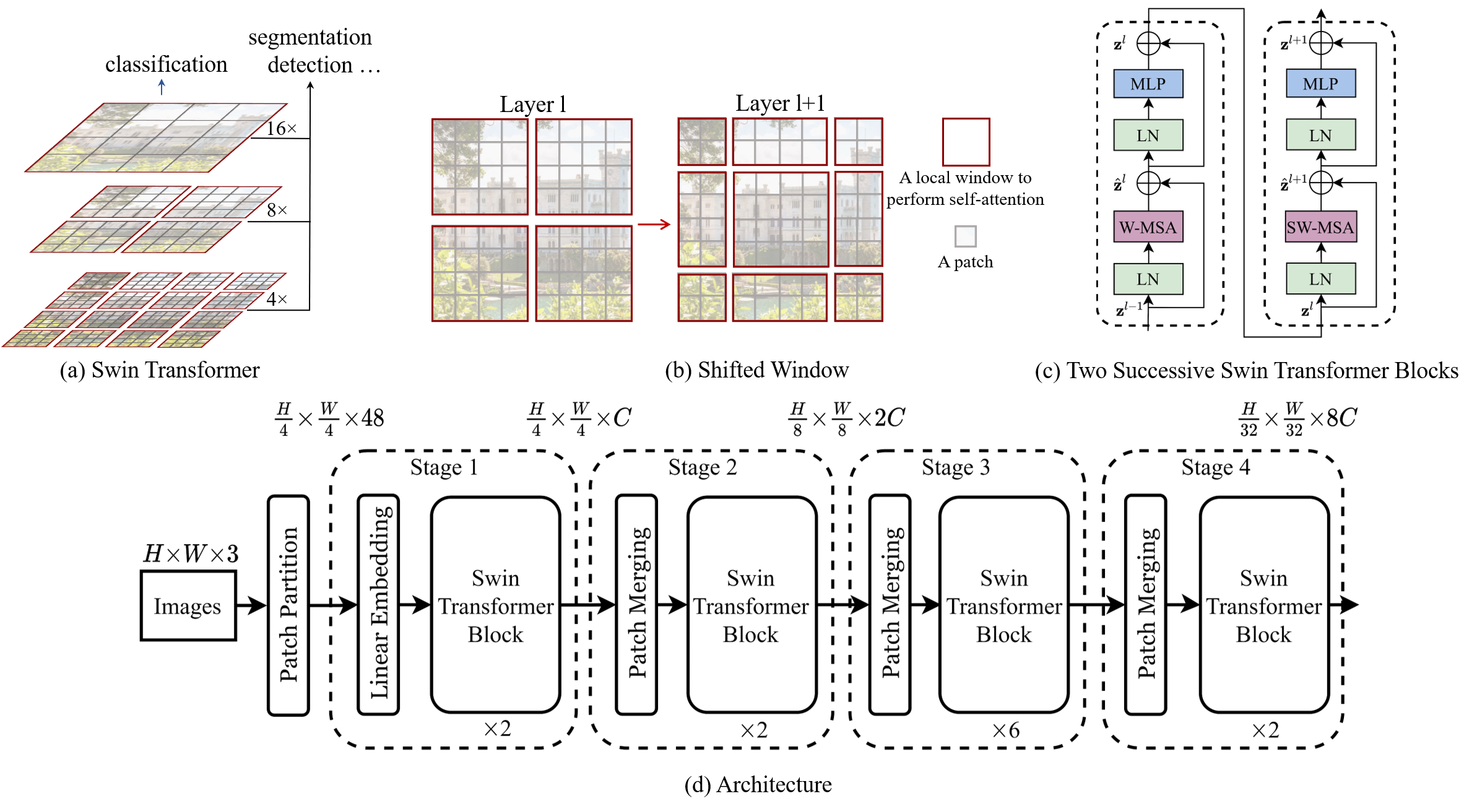
图1 Swin Transformer模型结构图
Swin Transformer模块原理
Swin Transformer模块的细节实现如图1(c)所示,核心部分为多头自注意力的计算。如上所述,基于全尺寸图像的自注意力在面对密集计算型任务时具有较高的计算复杂度,因此本模型采用基于窗口的自注意力计算(W-MSA),输入张量先被分割成窗口,在窗口内的patch之间计算多头自注意力。相比于传统的自注意力计算,此处在计算q、k时额外增加了相对位置编码,以提供窗口内的位置信息。
Swin Transformer的亮点在于采用滑动窗口机制,提取窗口之间的信息,达到全局自注意力的效果。以4个4×4大小的窗口为例,在计算滑动窗口多头自注意力(SW-MSA)时,将窗口向右下移动2个patch,得到9个新窗口,其中上、下、左、右4个新窗口包含原窗口划分中2个窗口的图像信息,中间的新窗口包含原窗口划分中4个窗口的图像信息,从而实现窗口之间的通信。但随之而来的是窗口数量的成倍增加和不同的窗口大小,反而增大了计算难度。
为降低计算量,本模型对新窗口进行循环移位处理,组成新的窗口布局,将4×4大小的窗口数降低为4个,如图1(b)所示。此时除左上角的窗口外,其它3个窗口包含的部分patch原本并不属于同一区域,不应计算之间的自注意力,因此本模型创新性地提出了masked MSA机制,原理在自注意力计算结果上加上mask矩阵,目的是只取相同原窗口内的patch间的q、k计算结果,而不同原窗口内的patch间q、k计算结果添加原码后得到一个较大的负数,在随后的softmax层计算中,掩码部分输出将会是0,达到忽略其值的目的。
模型特点
- 基于滑动窗口的自注意力计算,交替使用W-MSA、SW-MSA,解决transformer应用于计算机视觉领域所产生的计算复杂度高的问题;
- 借鉴CNN架构,对图像进行降采样,捕获多尺寸层次的全局特征。
仓库说明
仓库结构为:
└─ swin_transformer
├─ src
├─ configs // SwinTransformer的配置文件
├─ args.py
└─ swin_tiny_patch4_window7_224.yaml
└─ data
├─ augment // 数据增强函数文件
├─ auto_augment.py
├─ mixup.py
└─ random_erasing.py
└─ imagenet // miniImageNet数据集
├─ train
├─ val
└─ test
├─ swin_transformer.ipynb // 端到端可执行的Notebook文件
└─ README.md
MindSpore相关依赖引入
In [1]:
import numpy as np import mindspore.common.initializer as weight_init import mindspore.ops.operations as P from mindspore import Parameter from mindspore import Tensor from mindspore import dtype as mstype from mindspore import nn from mindspore import numpy from mindspore import ops import os import mindspore.common.dtype as mstype import mindspore.dataset as ds import mindspore.dataset.transforms as C import mindspore.dataset.vision as vision from mindspore.dataset.vision.utils import Inter import collections.abc from itertools import repeat import os import mindspore from mindspore import Model from mindspore import context from mindspore.common import set_seed from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Callback from mindspore.nn.loss.loss import LossBase from mindspore.common import RowTensor from mindspore.ops import composite as Cps from mindspore.ops import functional as F from mindspore.ops import operations as P from mindspore.communication.management import init, get_rank from mindspore.context import ParallelMode from mindspore.train.serialization import load_checkpoint, load_param_into_net from mindspore.nn.optim import AdamWeightDecay from mindspore.nn.optim.momentum import Momentum
SwinTransformer模型定义
如下所示,代码中SwinTransformer类的定义与继承结构和原文中的模型原理结构具有对应关系:
SwinTransformer
├─ PatchEmbed
└─ BasicLayer
├─ PatchMerging
└─ SwinTransformerBlock
├─ WindowAttention
├─ RelativeBias
├─ DropPath1D
├─ Mlp
├─ Roll
├─ WindowPartitionConstruct
└─ WindowReverseConstruct
In [2]:
from src.configs.args import args
def _ntuple(n):
def parse(x):
if isinstance(x, collections.abc.Iterable):
return x
return tuple(repeat(x, n))
return parse
class Identity(nn.Cell):
"""Identity"""
def construct(self, x):
return x
class DropPath(nn.Cell):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob, ndim):
super(DropPath, self).__init__()
self.drop = nn.Dropout(keep_prob=1 - drop_prob)
shape = (1,) + (1,) * (ndim + 1)
self.ndim = ndim
self.mask = Tensor(np.ones(shape), dtype=mstype.float32)
def construct(self, x):
if not self.training:
return x
mask = ops.Tile()(self.mask, (x.shape[0],) + (1,) * (self.ndim + 1))
out = self.drop(mask)
out = out * x
return out
class DropPath1D(DropPath):
def __init__(self, drop_prob):
super(DropPath1D, self).__init__(drop_prob=drop_prob, ndim=1)
to_2tuple = _ntuple(2)
act_layers = {
"GELU": nn.GELU,
"gelu": nn.GELU,
}
=> Reading YAML config from ./src/configs/swin_tiny_patch4_window7_224.yaml Namespace(arch='swin_tiny_patch4_window7_224', accumulation_step=1, amp_level='O1', ape=False, batch_size=128, beta=[0.9, 0.999], clip_global_norm_value=5.0, crop=True, data_url='./src/data/imagenet', device_id=1, device_num=1, device_target='GPU', epochs=100, eps=1e-08, file_format='MINDIR', in_channel=3, is_dynamic_loss_scale=True, keep_checkpoint_max=20, optimizer='adamw', set='ImageNet', graph_mode=0, mix_up=0.8, mlp_ratio=4.0, num_parallel_workers=16, start_epoch=0, warmup_length=20, warmup_lr=7e-08, weight_decay=0.05, loss_scale=1024, lr=0.0005, lr_scheduler='cosine_lr', lr_adjust=30, lr_gamma=0.97, momentum=0.9, num_classes=100, patch_size=4, patch_norm=True, swin_config='./src/configs/swin_tiny_patch4_window7_224.yaml', seed=0, save_every=5, label_smoothing=0.1, image_size=224, train_url='./', cutmix=1.0, auto_augment='rand-m9-mstd0.5-inc1', interpolation='bicubic', re_prob=0.25, re_mode='pixel', re_count=1, mixup_prob=1.0, switch_prob=0.5, mixup_mode='batch', base_lr=0.0005, min_lr=6e-06, nonlinearity='GELU', keep_bn_fp32=True, drop_path_rate=0.2, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], window_size=7)
In [3]:
class Mlp(nn.Cell):
"""MLP Cell"""
def __init__(self, in_features, hidden_features=None,
out_features=None,
act_layer=act_layers[args.nonlinearity],
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Dense(in_channels=in_features, out_channels=hidden_features, has_bias=True)
self.act = act_layer()
self.fc2 = nn.Dense(in_channels=hidden_features, out_channels=out_features, has_bias=True)
self.drop = nn.Dropout(keep_prob=1.0 - drop)
def construct(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
In [4]:
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = np.reshape(x, (B, H // window_size, window_size, W // window_size, window_size, C))
windows = x.transpose(0, 1, 3, 2, 4, 5).reshape(-1, window_size, window_size, C)
return windows
In [5]:
class WindowPartitionConstruct(nn.Cell):
"""WindowPartitionConstruct Cell"""
def __init__(self, window_size):
super(WindowPartitionConstruct, self).__init__()
self.window_size = window_size
def construct(self, x):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = P.Reshape()(x, (B, H // self.window_size, self.window_size, W // self.window_size, self.window_size, C))
x = P.Transpose()(x, (0, 1, 3, 2, 4, 5))
x = P.Reshape()(x, (B * H * W // (self.window_size ** 2), self.window_size, self.window_size, C))
return x
In [6]:
class WindowReverseConstruct(nn.Cell):
"""WindowReverseConstruct Cell"""
def construct(self, windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = windows.shape[0] // (H * W // window_size // window_size)
x = ops.Reshape()(windows, (B, H // window_size, W // window_size, window_size, window_size, -1))
x = ops.Transpose()(x, (0, 1, 3, 2, 4, 5))
x = ops.Reshape()(x, (B, H, W, -1))
return x
In [7]:
class RelativeBias(nn.Cell):
"""RelativeBias Cell"""
def __init__(self, window_size, num_heads):
super(RelativeBias, self).__init__()
self.window_size = window_size
# define a parameter table of relative position bias
coords_h = np.arange(self.window_size[0]).reshape(self.window_size[0], 1).repeat(self.window_size[0],
1).reshape(1, -1)
coords_w = np.arange(self.window_size[1]).reshape(1, self.window_size[1]).repeat(self.window_size[1],
0).reshape(1, -1)
coords_flatten = np.concatenate([coords_h, coords_w], axis=0) # 2, Wh, Ww
relative_coords = coords_flatten[:, :, np.newaxis] - coords_flatten[:, np.newaxis, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.transpose(1, 2, 0) # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
self.relative_position_index = Tensor(relative_coords.sum(-1).reshape(-1)) # Wh*Ww, Wh*Ww
self.relative_position_bias_table = Parameter(
Tensor(np.random.randn((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads),
dtype=mstype.float32)) # 2*Wh-1 * 2*Ww-1, nH
self.one_hot = nn.OneHot(axis=-1, depth=(2 * window_size[0] - 1) * (2 * window_size[1] - 1),
dtype=mstype.float32)
self.index = Parameter(self.one_hot(self.relative_position_index), requires_grad=False)
def construct(self, axis=0):
out = ops.MatMul()(self.index, self.relative_position_bias_table)
out = P.Reshape()(out, (self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1], -1))
out = P.Transpose()(out, (2, 0, 1))
out = ops.ExpandDims()(out, 0)
return out
In [8]:
class WindowAttention(nn.Cell):
r""" Window based multi-head self attention (W-MSA) Cell with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qZk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
if isinstance(dim, tuple) and len(dim) == 1:
dim = dim[0]
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = Tensor(qk_scale or head_dim ** -0.5, mstype.float32)
self.relative_bias = RelativeBias(self.window_size, num_heads)
# get pair-wise relative position index for each token inside the window
self.q = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.k = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.v = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.attn_drop = nn.Dropout(keep_prob=1.0 - attn_drop)
self.proj = nn.Dense(in_channels=dim, out_channels=dim, has_bias=True)
self.proj_drop = nn.Dropout(keep_prob=1.0 - proj_drop)
self.softmax = nn.Softmax(axis=-1)
def construct(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
q = ops.Reshape()(self.q(x), (B_, N, self.num_heads, C // self.num_heads)) * self.scale
q = ops.Transpose()(q, (0, 2, 1, 3))
k = ops.Reshape()(self.k(x), (B_, N, self.num_heads, C // self.num_heads))
k = ops.Transpose()(k, (0, 2, 3, 1))
v = ops.Reshape()(self.v(x), (B_, N, self.num_heads, C // self.num_heads))
v = ops.Transpose()(v, (0, 2, 1, 3))
attn = ops.BatchMatMul()(q, k)
attn = attn + self.relative_bias()
if mask is not None:
nW = mask.shape[1]
attn = P.Reshape()(attn, (B_ // nW, nW, self.num_heads, N, N,)) + mask
attn = P.Reshape()(attn, (-1, self.num_heads, N, N,))
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = ops.Reshape()(ops.Transpose()(ops.BatchMatMul()(attn, v), (0, 2, 1, 3)), (B_, N, C))
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
In [9]:
class Roll(nn.Cell):
"""Roll Cell"""
def __init__(self, shift_size, shift_axis=(1, 2)):
super(Roll, self).__init__()
self.shift_size = to_2tuple(shift_size)
self.shift_axis = shift_axis
def construct(self, x):
x = numpy.roll(x, self.shift_size, self.shift_axis)
return x
In [10]:
class SwinTransformerBlock(nn.Cell):
""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Cell, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Cell, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=act_layers[args.nonlinearity], norm_layer=nn.LayerNorm):
super(SwinTransformerBlock, self).__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
if isinstance(dim, int):
dim = (dim,)
self.norm1 = norm_layer(dim, epsilon=1e-5)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath1D(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim, epsilon=1e-5)
mlp_hidden_dim = int((dim[0] if isinstance(dim, tuple) else dim) * mlp_ratio)
self.mlp = Mlp(in_features=dim[0] if isinstance(dim, tuple) else dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = np.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# img_mask: [1, 56, 56, 1] window_size: 7
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.reshape(-1, self.window_size * self.window_size)
attn_mask = mask_windows[:, np.newaxis] - mask_windows[:, :, np.newaxis]
# [64, 49, 49] ==> [1, 64, 1, 49, 49]
attn_mask = np.expand_dims(attn_mask, axis=1)
attn_mask = np.expand_dims(attn_mask, axis=0)
attn_mask = Tensor(np.where(attn_mask == 0, 0., -100.), dtype=mstype.float32)
self.attn_mask = Parameter(attn_mask, requires_grad=False)
self.roll_pos = Roll(self.shift_size)
self.roll_neg = Roll(-self.shift_size)
else:
self.attn_mask = None
self.window_partition = WindowPartitionConstruct(self.window_size)
self.window_reverse = WindowReverseConstruct()
def construct(self, x):
"""construct function"""
H, W = self.input_resolution
B, _, C = x.shape
shortcut = x
x = self.norm1(x)
x = P.Reshape()(x, (B, H, W, C,))
# cyclic shift
if self.shift_size > 0:
shifted_x = self.roll_neg(x)
# shifted_x = numpy.roll(x, (-self.shift_size, -self.shift_size), (1, 2))
else:
shifted_x = x
# partition windows
x_windows = self.window_partition(shifted_x) # nW*B, window_size, window_size, C
x_windows = ops.Reshape()(x_windows,
(-1, self.window_size * self.window_size, C,)) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = P.Reshape()(attn_windows, (-1, self.window_size, self.window_size, C,))
shifted_x = self.window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = self.roll_pos(shifted_x)
# x = numpy.roll(shifted_x, (self.shift_size, self.shift_size), (1, 2)) # TODO:Don't stupid
else:
x = shifted_x
x = P.Reshape()(x, (B, H * W, C,))
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
In [11]:
class PatchMerging(nn.Cell):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim[0] if isinstance(dim, tuple) and len(dim) == 1 else dim
# Default False
self.reduction = nn.Dense(in_channels=4 * dim, out_channels=2 * dim, has_bias=False)
self.norm = norm_layer([dim * 4,])
self.H, self.W = self.input_resolution
self.H_2, self.W_2 = self.H // 2, self.W // 2
self.H2W2 = int(self.H * self.W // 4)
self.dim_mul_4 = int(dim * 4)
self.H2W2 = int(self.H * self.W // 4)
def construct(self, x):
"""
x: B, H*W, C
"""
B = x.shape[0]
x = P.Reshape()(x, (B, self.H_2, 2, self.W_2, 2, self.dim))
x = P.Transpose()(x, (0, 1, 3, 4, 2, 5))
x = P.Reshape()(x, (B, self.H2W2, self.dim_mul_4))
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
In [12]:
class BasicLayer(nn.Cell):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Cell, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Cell | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
# build blocks
self.blocks = nn.CellList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2, # TODO: 这里window_size//2的时候特别慢
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def construct(self, x):
"""construct"""
for blk in self.blocks:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
In [13]:
class PatchEmbed(nn.Cell):
""" Image to Patch Embedding
Args:
image_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Cell, optional): Normalization layer. Default: None
"""
def __init__(self, image_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
image_size = to_2tuple(image_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [image_size[0] // patch_size[0], image_size[1] // patch_size[1]]
self.image_size = image_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_channels=in_chans, out_channels=embed_dim, kernel_size=patch_size, stride=patch_size,
pad_mode='pad', has_bias=True, weight_init="TruncatedNormal")
if norm_layer is not None:
if isinstance(embed_dim, int):
embed_dim = (embed_dim,)
self.norm = norm_layer(embed_dim, epsilon=1e-5)
else:
self.norm = None
def construct(self, x):
"""docstring"""
B = x.shape[0]
# FIXME look at relaxing size constraints
x = ops.Reshape()(self.proj(x), (B, self.embed_dim, -1)) # B Ph*Pw C
x = ops.Transpose()(x, (0, 2, 1))
if self.norm is not None:
x = self.norm(x)
return x
In [14]:
class SwinTransformer(nn.Cell):
""" Swin Transformer
A Pynp impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
image_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 100
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Cell): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(self, image_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=None, num_heads=None, window_size=7,
mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
image_size=image_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = Parameter(Tensor(np.zeros(1, num_patches, embed_dim), dtype=mstype.float32))
self.pos_drop = nn.Dropout(keep_prob=1.0 - drop_rate)
# stochastic depth
dpr = [x for x in np.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.CellList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None)
self.layers.append(layer)
self.norm = norm_layer([self.num_features,], epsilon=1e-5)
self.avgpool = P.ReduceMean(keep_dims=False)
self.head = nn.Dense(in_channels=self.num_features,
out_channels=num_classes, has_bias=True) if num_classes > 0 else Identity()
self.init_weights()
def init_weights(self):
"""init_weights"""
for _, cell in self.cells_and_names():
if isinstance(cell, nn.Dense):
cell.weight.set_data(weight_init.initializer(weight_init.TruncatedNormal(sigma=0.02),
cell.weight.shape,
cell.weight.dtype))
if isinstance(cell, nn.Dense) and cell.bias is not None:
cell.bias.set_data(weight_init.initializer(weight_init.Zero(),
cell.bias.shape,
cell.bias.dtype))
elif isinstance(cell, nn.LayerNorm):
cell.gamma.set_data(weight_init.initializer(weight_init.One(),
cell.gamma.shape,
cell.gamma.dtype))
cell.beta.set_data(weight_init.initializer(weight_init.Zero(),
cell.beta.shape,
cell.beta.dtype))
def no_weight_decay(self):
return {'absolute_pos_embed'}
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(ops.Transpose()(x, (0, 2, 1)), 2) # B C 1
return x
def construct(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
miniImageNet数据集引入
所使用的数据集:miniImageNet
- 数据集大小:共100类,60000张图像,每类600张图像
- 数据格式:JPGE格式,84*84彩色图像
- 对数据集结构的处理要求:类别分布均衡,训练集 : 验证集 : 测试集 = 7 : 1 : 2
miniImageNet数据集的原始结构如下:
└─ dataset
├─ images
├─ n0153282900000005.jpg
├─ n0153282900000006.jpg
├─ ...
├─ train.csv
├─ val.csv
└─ test.csv
匹配图像与CSV文件后,数据集结构变为:
└─ dataset
├─ train
├─ 第1类
└─ 600张图像
├─ ...
└─ 第64类
└─ 600张图像
├─ val
├─ 第65类
└─ 600张图像
├─ ...
└─ 第80类
└─ 600张图像
└─ test
├─ 第81类
└─ 600张图像
├─ ...
└─ 第100类
└─ 600张图像
仍需进一步将数据集结构处理为:
└─ dataset
├─ train
├─ 第1类
└─ 420张图像
├─ ...
└─ 第100类
└─ 420张图像
├─ val
├─ 第1类
└─ 60张图像
├─ ...
└─ 第100类
└─ 60张图像
└─ test
├─ 第1类
└─ 120张图像
├─ ...
└─ 第100类
└─ 120张图像
处理后的数据集的下载方式:
- 链接:百度网盘 请输入提取码 提取码:xqnu
请将数据集保存至路径“mindspore_swin_transformer/src/data”下,并逐层解压文件。
In [15]:
""" Data operations, will be used in train.py and eval.py """ from src.data.augment.auto_augment import _pil_interp, rand_augment_transform from src.data.augment.mixup import Mixup from src.data.augment.random_erasing import RandomErasing
In [16]:
def _get_rank_info():
"""
get rank size and rank id
"""
rank_size = int(os.environ.get("RANK_SIZE", 1))
if rank_size > 1:
from mindspore.communication.management import get_rank, get_group_size
rank_size = get_group_size()
rank_id = get_rank()
else:
rank_size = rank_id = None
return rank_size, rank_id
In [17]:
def create_dataset_imagenet(dataset_dir, args, repeat_num=1, training=True):
"""
create a train or val or test mini-imagenet dataset for SwinTransformer
Args:
dataset_dir(string): the path of dataset.
do_train(bool): whether dataset is used for train or eval.
repeat_num(int): the repeat times of dataset. Default: 1
Returns:
dataset
"""
device_num, rank_id = _get_rank_info()
shuffle = bool(training)
if device_num == 1 or not training:
data_set = ds.ImageFolderDataset(dataset_dir, num_parallel_workers=args.num_parallel_workers,
shuffle=shuffle)
else:
data_set = ds.ImageFolderDataset(dataset_dir, num_parallel_workers=args.num_parallel_workers, shuffle=shuffle,
num_shards=device_num, shard_id=rank_id)
image_size = args.image_size
# define map operations
# BICUBIC: 3
# data augment
if training:
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
aa_params = dict(
translate_const=int(image_size * 0.45),
img_mean=tuple([min(255, round(255 * x)) for x in mean]),
)
interpolation = args.interpolation
auto_augment = args.auto_augment
assert auto_augment.startswith('rand')
aa_params['interpolation'] = _pil_interp(interpolation)
transform_img = [
vision.RandomCropDecodeResize(image_size, scale=(0.08, 1.0), ratio=(3 / 4, 4 / 3),
interpolation=Inter.BICUBIC),
vision.RandomHorizontalFlip(prob=0.5),
vision.ToPIL()
]
transform_img += [rand_augment_transform(auto_augment, aa_params)]
transform_img += [
vision.ToTensor(),
vision.Normalize(mean=mean, std=std, is_hwc=False),
RandomErasing(args.re_prob, mode=args.re_mode, max_count=args.re_count)
]
else:
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
# test transform complete
if args.crop:
transform_img = [
vision.Decode(),
vision.Resize(int(256 / 224 * image_size), interpolation=Inter.BICUBIC),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std, is_hwc=True),
vision.HWC2CHW()
]
else:
transform_img = [
vision.Decode(),
vision.Resize(int(image_size), interpolation=Inter.BICUBIC),
vision.Normalize(mean=mean, std=std, is_hwc=True),
vision.HWC2CHW()
]
transform_label = C.TypeCast(mstype.int32)
data_set = data_set.map(input_columns="image", num_parallel_workers=args.num_parallel_workers,
operations=transform_img)
data_set = data_set.map(input_columns="label", num_parallel_workers=args.num_parallel_workers,
operations=transform_label)
if (args.mix_up > 0. or args.cutmix > 0.) and not training:
# if use mixup and not training(False), one hot val data label
one_hot = C.OneHot(num_classes=args.num_classes)
data_set = data_set.map(input_columns="label", num_parallel_workers=args.num_parallel_workers,
operations=one_hot)
# apply batch operations
data_set = data_set.batch(args.batch_size, drop_remainder=True,
num_parallel_workers=args.num_parallel_workers)
if (args.mix_up > 0. or args.cutmix > 0.) and training:
mixup_fn = Mixup(
mixup_alpha=args.mix_up, cutmix_alpha=args.cutmix, cutmix_minmax=None,
prob=args.mixup_prob, switch_prob=args.switch_prob, mode=args.mixup_mode,
label_smoothing=args.label_smoothing, num_classes=args.num_classes)
data_set = data_set.map(operations=mixup_fn, input_columns=["image", "label"],
num_parallel_workers=args.num_parallel_workers)
# apply dataset repeat operation
data_set = data_set.repeat(repeat_num)
ds.config.set_prefetch_size(4)
return data_set
In [18]:
class ImageNet:
"""ImageNet Define"""
def __init__(self, args, training=True):
train_dir = os.path.join(args.data_url, "train")
val_ir = os.path.join(args.data_url, "val")
test_ir = os.path.join(args.data_url, "test")
if training:
self.train_dataset = create_dataset_imagenet(train_dir, training=True, args=args)
self.val_dataset = create_dataset_imagenet(val_ir, training=False, args=args)
self.test_dataset = create_dataset_imagenet(test_ir, training=False, args=args)
训练与评估
本案例利用MindSpore框架,基于Callback基于自定义了回调类 EvaluateCallBack,为了满足在模型训练时,能够在每一次epoch结束后计算3个评价指标:Loss、Top1-Acc、Top5-Acc,并根据评价指标的变化保存当前最优的模型的特定需求。
具体的实现流程首先是在EvaluateCallBack类中,通过__init__方法初始化相关参数,并重新实现epoch_end方法,在该方法中通过MindSpore的字典类型变量RunContext.original_args()获取模型训练时记录的相关属性,如cur_epoch_num,即当前epoch数,以及train_network,即训练的网络模型,在epoch_end方法中还计算了3个评价指标:Loss、Top1-Acc、Top5-Acc,并比较当前epoch的Top1-Acc值与记录的最优Top1-Acc值,利用先前获取到的train_network将表现最优的模型保存在特定路径下。综上实现了在模型训练时,每个epoch结束后计算eval_metrics类中定义的各个评价指标,并根据Top1-Acc指标保存最优模型。
在模型训练时,首先是设置模型训练的epoch次数为100,再通过自定义的create_dataset方法创建了训练集和验证集,设置batch_size大小为128,图像尺寸统一调整为224x224;损失函数使用SoftmaxCrossEntropyWithLogits计算预测值与真实值之间的交叉熵,优化器使用adamw,并设置学习率为0.005。回调函数方面使用了LossMonitor和TimeMonitor来监控训练过程中每个epoch结束后,损失值Loss的变化情况以及每个epoch、每个step的运行时间,还实例化了自定义的回调类EvaluateCallBack,实现计算每个epoch结束后,计算评价指标Loss、Top1-Acc和Top5-Acc,并保存当前最优模型。在100个epcoh结束后,模型在验证集和测试集上的评估指标为:
- 验证集:Top1-Acc:55.15%,Top5-Acc:81.00%
- 测试集:Top1-Acc:55.26% ,Top5-Acc:81.59%
本案例构建的网络模型具有较好的性能,能够实现对测试集进行较为准确的预测。
设置精度水平
In [19]:
def do_keep_fp32(network, cell_types):
"""Cast cell to fp32 if cell in cell_types"""
for _, cell in network.cells_and_names():
if isinstance(cell, cell_types):
cell.to_float(mstype.float32)
def cast_amp(net):
"""cast network amp_level"""
if args.amp_level == "O1":
print(f"=> using amp_level {args.amp_level}\n"
f"=> change {args.arch} to fp16")
net.to_float(mstype.float16)
cell_types = (nn.GELU, nn.Softmax, nn.Conv2d, nn.Conv1d, nn.BatchNorm2d, nn.LayerNorm)
print(f"=> cast {cell_types} to fp32 back")
do_keep_fp32(net, cell_types)
elif args.amp_level == "O2":
print(f"=> using amp_level {args.amp_level}\n"
f"=> change {args.arch} to fp16")
net.to_float(mstype.float16)
cell_types = (nn.BatchNorm2d, nn.LayerNorm)
print(f"=> cast {cell_types} to fp32 back")
do_keep_fp32(net, cell_types)
elif args.amp_level == "O3":
print(f"=> using amp_level {args.amp_level}\n"
f"=> change {args.arch} to fp16")
net.to_float(mstype.float16)
else:
print(f"=> using amp_level {args.amp_level}")
args.loss_scale = 1.
args.is_dynamic_loss_scale = 0
print(f"=> When amp_level is O0, using fixed loss_scale with {args.loss_scale}")
定义Loss函数
In [20]:
class SoftTargetCrossEntropy(LossBase):
"""SoftTargetCrossEntropy for MixUp Augment"""
def __init__(self):
super(SoftTargetCrossEntropy, self).__init__()
self.mean_ops = P.ReduceMean(keep_dims=False)
self.sum_ops = P.ReduceSum(keep_dims=False)
self.log_softmax = P.LogSoftmax()
def construct(self, logit, label):
logit = P.Cast()(logit, mstype.float32)
label = P.Cast()(label, mstype.float32)
loss = self.sum_ops(-label * self.log_softmax(logit), -1)
return self.mean_ops(loss)
class CrossEntropySmooth(LossBase):
"""CrossEntropy"""
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth, self).__init__()
self.onehot = P.OneHot()
self.sparse = sparse
self.on_value = Tensor(1.0 - smooth_factor, mstype.float32)
self.off_value = Tensor(1.0 * smooth_factor / (num_classes - 1), mstype.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
self.cast = ops.Cast()
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, F.shape(logit)[1], self.on_value, self.off_value)
loss2 = self.ce(logit, label)
return loss2
def get_criterion(args):
"""Get loss function from args.label_smooth and args.mix_up"""
assert args.label_smoothing >= 0. and args.label_smoothing <= 1.
if args.mix_up > 0. or args.cutmix > 0.:
print(25 * "=" + "Using MixBatch" + 25 * "=")
# smoothing is handled with mixup label transform
criterion = SoftTargetCrossEntropy()
elif args.label_smoothing > 0.:
print(25 * "=" + "Using label smoothing" + 25 * "=")
criterion = CrossEntropySmooth(sparse=True, reduction="mean",
smooth_factor=args.label_smoothing,
num_classes=args.num_classes)
else:
print(25 * "=" + "Using Simple CE" + 25 * "=")
criterion = CrossEntropySmooth(sparse=True, reduction="mean", num_classes=args.num_classes)
return criterion
class NetWithLoss(nn.Cell):
"""
NetWithLoss: Only support Network with Classfication
"""
def __init__(self, model, criterion):
super(NetWithLoss, self).__init__()
self.model = model
self.criterion = criterion
def construct(self, data, label):
predict = self.model(data)
loss = self.criterion(predict, label)
return loss
定义单步训练
In [21]:
_grad_scale = Cps.MultitypeFuncGraph("grad_scale")
reciprocal = P.Reciprocal()
@_grad_scale.register("Tensor", "Tensor")
def tensor_grad_scale(scale, grad):
return grad * F.cast(reciprocal(scale), F.dtype(grad))
@_grad_scale.register("Tensor", "RowTensor")
def tensor_grad_scale_row_tensor(scale, grad):
return RowTensor(grad.indices,
grad.values * F.cast(reciprocal(scale), F.dtype(grad.values)),
grad.dense_shape)
class TrainClipGrad(nn.TrainOneStepWithLossScaleCell):
"""
Encapsulation class of SSD network training.
Append an optimizer to the training network after that the construct
function can be called to create the backward graph.
Args:
network (Cell): The training network. Note that loss function should have been added.
optimizer (Optimizer): Optimizer for updating the weights.
sens (Number): The adjust parameter. Default: 1.0.
use_global_nrom(bool): Whether apply global norm before optimizer. Default: False
"""
def __init__(self, network, optimizer,
scale_sense=1.0, use_global_norm=True,
clip_global_norm_value=1.0):
super(TrainClipGrad, self).__init__(network, optimizer, scale_sense)
self.use_global_norm = use_global_norm
self.clip_global_norm_value = clip_global_norm_value
self.print = P.Print()
def construct(self, *inputs):
"""construct"""
weights = self.weights
loss = self.network(*inputs)
scaling_sens = self.scale_sense
status, scaling_sens = self.start_overflow_check(loss, scaling_sens)
scaling_sens_filled = Cps.ones_like(loss) * F.cast(scaling_sens, F.dtype(loss))
grads = self.grad(self.network, weights)(*inputs, scaling_sens_filled)
grads = self.hyper_map(F.partial(_grad_scale, scaling_sens), grads)
# apply grad reducer on grads
grads = self.grad_reducer(grads)
# get the overflow buffer
cond = self.get_overflow_status(status, grads)
overflow = self.process_loss_scale(cond)
# if there is no overflow, do optimize
if not overflow:
if self.use_global_norm:
grads = Cps.clip_by_global_norm(grads, clip_norm=self.clip_global_norm_value)
loss = F.depend(loss, self.optimizer(grads))
else:
self.print("=============Over Flow, skipping=============")
return loss
def get_train_one_step(args, net_with_loss, optimizer):
"""get_train_one_step cell"""
if args.is_dynamic_loss_scale:
print(f"=> Using DynamicLossScaleUpdateCell")
scale_sense = nn.wrap.loss_scale.DynamicLossScaleUpdateCell(loss_scale_value=2 ** 24, scale_factor=2,
scale_window=2000)
else:
print(f"=> Using FixedLossScaleUpdateCell, loss_scale_value:{args.loss_scale}")
scale_sense = nn.wrap.FixedLossScaleUpdateCell(loss_scale_value=args.loss_scale)
net_with_loss = TrainClipGrad(net_with_loss, optimizer, scale_sense=scale_sense,
clip_global_norm_value=args.clip_global_norm_value,
use_global_norm=True)
return net_with_loss
定义学习率、优化器和模型的获取函数
In [22]:
__all__ = ["multistep_lr", "cosine_lr", "constant_lr", "get_policy", "exp_lr"]
def get_policy(name):
"""get lr policy from name"""
if name is None:
return constant_lr
out_dict = {
"constant_lr": constant_lr,
"cosine_lr": cosine_lr,
"multistep_lr": multistep_lr,
"exp_lr": exp_lr,
}
return out_dict[name]
def constant_lr(args, batch_num):
"""Get constant lr"""
learning_rate = []
def _lr_adjuster(epoch):
if epoch < args.warmup_length:
lr = _warmup_lr(args.warmup_lr, args.base_lr, args.warmup_length, epoch)
else:
lr = args.base_lr
return lr
for epoch in range(args.epochs):
for batch in range(batch_num):
learning_rate.append(_lr_adjuster(epoch + batch / batch_num))
learning_rate = np.clip(learning_rate, args.min_lr, max(learning_rate))
return learning_rate
def exp_lr(args, batch_num):
"""Get exp lr """
learning_rate = []
def _lr_adjuster(epoch):
if epoch < args.warmup_length:
lr = _warmup_lr(args.warmup_lr, args.base_lr, args.warmup_length, epoch)
else:
lr = args.base_lr * args.lr_gamma ** epoch
return lr
for epoch in range(args.epochs):
for batch in range(batch_num):
learning_rate.append(_lr_adjuster(epoch + batch / batch_num))
learning_rate = np.clip(learning_rate, args.min_lr, max(learning_rate))
return learning_rate
def cosine_lr(args, batch_num):
"""Get cosine lr"""
learning_rate = []
def _lr_adjuster(epoch):
if epoch < args.warmup_length:
lr = _warmup_lr(args.warmup_lr, args.base_lr, args.warmup_length, epoch)
else:
e = epoch - args.warmup_length
es = args.epochs - args.warmup_length
lr = 0.5 * (1 + np.cos(np.pi * e / es)) * args.base_lr
return lr
for epoch in range(args.epochs):
for batch in range(batch_num):
learning_rate.append(_lr_adjuster(epoch + batch / batch_num))
learning_rate = np.clip(learning_rate, args.min_lr, max(learning_rate))
return learning_rate
def multistep_lr(args, batch_num):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
learning_rate = []
def _lr_adjuster(epoch):
lr = args.base_lr * (args.lr_gamma ** (epoch / args.lr_adjust))
return lr
for epoch in range(args.epochs):
for batch in range(batch_num):
learning_rate.append(_lr_adjuster(epoch + batch / batch_num))
learning_rate = np.clip(learning_rate, args.min_lr, max(learning_rate))
return learning_rate
def _warmup_lr(warmup_lr, base_lr, warmup_length, epoch):
"""Linear warmup"""
return epoch / warmup_length * (base_lr - warmup_lr) + warmup_lr
def get_learning_rate(args, batch_num):
"""Get learning rate"""
return get_policy(args.lr_scheduler)(args, batch_num)
In [23]:
def get_optimizer(args, model, batch_num):
"""Get optimizer for training"""
print(f"=> When using train_wrapper, using optimizer {args.optimizer}")
args.start_epoch = int(args.start_epoch)
optim_type = args.optimizer.lower()
params = get_param_groups(model)
learning_rate = get_learning_rate(args, batch_num)
step = int(args.start_epoch * batch_num)
accumulation_step = int(args.accumulation_step)
learning_rate = learning_rate[step::accumulation_step]
train_step = len(learning_rate)
print(f"=> Get LR from epoch: {args.start_epoch}\n"
f"=> Start step: {step}\n"
f"=> Total step: {train_step}\n"
f"=> Accumulation step:{accumulation_step}")
learning_rate = learning_rate * args.batch_size * int(os.getenv("DEVICE_NUM", args.device_num)) / 512.
if accumulation_step > 1:
learning_rate = learning_rate * accumulation_step
if optim_type == "momentum":
optim = Momentum(
params=params,
learning_rate=learning_rate,
momentum=args.momentum,
weight_decay=args.weight_decay
)
elif optim_type == "adamw":
optim = AdamWeightDecay(
params=params,
learning_rate=learning_rate,
beta1=args.beta[0],
beta2=args.beta[1],
eps=args.eps,
weight_decay=args.weight_decay
)
else:
raise ValueError(f"optimizer {optim_type} is not supported")
return optim
def get_param_groups(network):
""" get param groups """
decay_params = []
no_decay_params = []
for x in network.trainable_params():
parameter_name = x.name
if parameter_name.endswith(".weight"):
# Dense or Conv's weight using weight decay
decay_params.append(x)
else:
# all bias not using weight decay
# bn weight bias not using weight decay, be carefully for now x not include LN
no_decay_params.append(x)
return [{'params': no_decay_params, 'weight_decay': 0.0}, {'params': decay_params}]
In [24]:
def get_swintransformer(args):
"""get swintransformer according to args"""
# override args
image_size = args.image_size
patch_size = args.patch_size
in_chans = args.in_channel
embed_dim = args.embed_dim
depths = args.depths
num_heads = args.num_heads
window_size = args.window_size
drop_path_rate = args.drop_path_rate
mlp_ratio = args.mlp_ratio
qkv_bias = True
qk_scale = None
ape = args.ape
patch_norm = args.patch_norm
print(25 * "=" + "MODEL CONFIG" + 25 * "=")
print(f"==> IMAGE_SIZE: {image_size}")
print(f"==> PATCH_SIZE: {patch_size}")
print(f"==> NUM_CLASSES: {args.num_classes}")
print(f"==> EMBED_DIM: {embed_dim}")
print(f"==> NUM_HEADS: {num_heads}")
print(f"==> DEPTHS: {depths}")
print(f"==> WINDOW_SIZE: {window_size}")
print(f"==> MLP_RATIO: {mlp_ratio}")
print(f"==> QKV_BIAS: {qkv_bias}")
print(f"==> QK_SCALE: {qk_scale}")
print(f"==> DROP_PATH_RATE: {drop_path_rate}")
print(f"==> APE: {ape}")
print(f"==> PATCH_NORM: {patch_norm}")
print(25 * "=" + "FINISHED" + 25 * "=")
model = SwinTransformer(image_size=image_size,
patch_size=patch_size,
in_chans=in_chans,
num_classes=args.num_classes,
embed_dim=embed_dim,
depths=depths,
num_heads=num_heads,
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop_rate=0.,
drop_path_rate=drop_path_rate,
ape=ape,
patch_norm=patch_norm)
# print(model)
return model
定义EvaluateCallBack,保存在验证集上指标最优的模型
In [25]:
class EvaluateCallBack(Callback):
"""EvaluateCallBack"""
def __init__(self, model, eval_dataset):
super(EvaluateCallBack, self).__init__()
self.model = model
self.eval_dataset = eval_dataset
self.best_acc = 0.
def epoch_end(self, run_context):
"""
Test when epoch end, save best model with best.ckpt.
"""
cb_params = run_context.original_args()
cur_epoch_num = cb_params.cur_epoch_num
result = self.model.eval(self.eval_dataset)
if result["Acc"] > self.best_acc:
self.best_acc = result["Acc"]
mindspore.save_checkpoint(cb_params.train_network, 'ckpt/best.ckpt')
print("epoch: %s acc: %s top5-acc: %s, best acc is %s" %
(cb_params.cur_epoch_num, result["Acc"], result["Top5-Acc"], self.best_acc), flush=True)
载入数据、设置环境、初始化模型、训练
In [26]:
def get_dataset(args, training=True):
""""Get model according to args.set"""
print(f"=> Getting {args.set} dataset")
dataset = ImageNet(args, training)
return dataset
def set_device(args):
"""Set device and ParallelMode(if device_num > 1)"""
rank = 0
# set context and device
device_target = args.device_target
device_num = int(os.environ.get("DEVICE_NUM", 1))
if device_target == "Ascend":
if device_num > 1:
context.set_context(device_id=int(os.environ["DEVICE_ID"]))
init(backend_name='hccl')
context.reset_auto_parallel_context()
context.set_auto_parallel_context(device_num=device_num, parallel_mode=ParallelMode.DATA_PARALLEL,
gradients_mean=True)
# context.set_auto_parallel_context(pipeline_stages=2, full_batch=True)
rank = get_rank()
else:
context.set_context(device_id=args.device_id)
elif device_target == "GPU":
if device_num > 1:
init(backend_name='nccl')
context.reset_auto_parallel_context()
context.set_auto_parallel_context(device_num=device_num, parallel_mode=ParallelMode.DATA_PARALLEL,
gradients_mean=True)
rank = get_rank()
else:
context.set_context(device_id=args.device_id)
else:
raise ValueError("Unsupported platform.")
return rank
In [27]:
assert args.crop, f"{args.arch} is only for evaluation"
set_seed(args.seed)
mode = {
0: context.GRAPH_MODE,
1: context.PYNATIVE_MODE
}
context.set_context(mode=mode[args.graph_mode], device_target=args.device_target)
context.set_context(enable_graph_kernel=True)
if args.device_target == "Ascend":
context.set_context(enable_auto_mixed_precision=True)
rank = set_device(args)
# get model and cast amp_level
net = get_swintransformer(args)
cast_amp(net)
criterion = get_criterion(args)
net_with_loss = NetWithLoss(net, criterion)
data = get_dataset(args)
batch_num = data.train_dataset.get_dataset_size()
optimizer = get_optimizer(args, net, batch_num)
net_with_loss = get_train_one_step(args, net_with_loss, optimizer)
eval_network = nn.WithEvalCell(net, criterion, args.amp_level in ["O2", "O3", "auto"])
eval_indexes = [0, 1, 2]
eval_metrics = {'Loss': nn.Loss(),
'Acc': nn.Accuracy(),
'Top5-Acc': nn.Top5CategoricalAccuracy()}
model = Model(net_with_loss, metrics=eval_metrics,
eval_network=eval_network,
eval_indexes=eval_indexes)
# checkpoint and callback settings
# keep_checkpoint_max (int) - 最多保存多少个checkpoint文件。默认值:1。
config_ck = CheckpointConfig(save_checkpoint_steps=data.train_dataset.get_dataset_size(),
keep_checkpoint_max=args.save_every)
ckpt_save_dir = "./ckpt"
time_cb = TimeMonitor(data_size=data.train_dataset.get_dataset_size())
# prefix (str) - checkpoint文件的前缀名称。默认值:’CKP’。
# directory (str) - 保存checkpoint文件的文件夹路径。默认情况下,文件保存在当前目录下。默认值:None。
# config (CheckpointConfig) - checkpoint策略配置。默认值:None。
ckpoint_cb = ModelCheckpoint(prefix=args.arch, directory=ckpt_save_dir, config=config_ck)
loss_cb = LossMonitor()
eval_cb = EvaluateCallBack(model=model, eval_dataset=data.val_dataset)
print("begin train")
model.train(int(args.epochs - args.start_epoch), data.train_dataset,
callbacks=[time_cb, ckpoint_cb, loss_cb, eval_cb],
dataset_sink_mode=True)
print("train success")
=========================MODEL CONFIG========================= ==> IMAGE_SIZE: 224 ==> PATCH_SIZE: 4 ==> NUM_CLASSES: 100 ==> EMBED_DIM: 96 ==> NUM_HEADS: [3, 6, 12, 24] ==> DEPTHS: [2, 2, 6, 2] ==> WINDOW_SIZE: 7 ==> MLP_RATIO: 4.0 ==> QKV_BIAS: True ==> QK_SCALE: None ==> DROP_PATH_RATE: 0.2 ==> APE: False ==> PATCH_NORM: True =========================FINISHED=========================
[WARNING] ME(2932479:139625079657088,MainProcess):2022-10-22-17:23:09.484.580 [mindspore/train/model.py:1075] For EvaluateCallBack callback, {'epoch_end'} methods may not be supported in later version, Use methods prefixed with 'on_train' or 'on_eval' instead when using customized callbacks.
=> using amp_level O1 => change swin_tiny_patch4_window7_224 to fp16 => cast (<class 'mindspore.nn.layer.activation.GELU'>, <class 'mindspore.nn.layer.activation.Softmax'>, <class 'mindspore.nn.layer.conv.Conv2d'>, <class 'mindspore.nn.layer.conv.Conv1d'>, <class 'mindspore.nn.layer.normalization.BatchNorm2d'>, <class 'mindspore.nn.layer.normalization.LayerNorm'>) to fp32 back =========================Using MixBatch========================= => Getting ImageNet dataset => When using train_wrapper, using optimizer adamw => Get LR from epoch: 0 => Start step: 0 => Total step: 32800 => Accumulation step:1 => Using DynamicLossScaleUpdateCell begin train =============Over Flow, skipping============= =============Over Flow, skipping============= =============Over Flow, skipping============= =============Over Flow, skipping============= =============Over Flow, skipping============= epoch: 1 step: 328, loss is 4.606683254241943 Train epoch time: 98225.719 ms, per step time: 299.469 ms epoch: 1 acc: 0.04364809782608696 top5-acc: 0.1559103260869565, best acc is 0.04364809782608696 epoch: 2 step: 328, loss is 4.516416072845459 Train epoch time: 77570.307 ms, per step time: 236.495 ms epoch: 2 acc: 0.05672554347826087 top5-acc: 0.1875, best acc is 0.05672554347826087 epoch: 3 step: 328, loss is 4.447005748748779 Train epoch time: 77713.935 ms, per step time: 236.933 ms epoch: 3 acc: 0.06725543478260869 top5-acc: 0.2027853260869565, best acc is 0.06725543478260869 epoch: 4 step: 328, loss is 4.451318740844727 Train epoch time: 77429.944 ms, per step time: 236.067 ms epoch: 4 acc: 0.07540760869565218 top5-acc: 0.2301290760869565, best acc is 0.07540760869565218 epoch: 5 step: 328, loss is 4.380975246429443 Train epoch time: 77789.145 ms, per step time: 237.162 ms epoch: 5 acc: 0.08967391304347826 top5-acc: 0.2686820652173913, best acc is 0.08967391304347826 epoch: 6 step: 328, loss is 4.443111896514893 Train epoch time: 78030.254 ms, per step time: 237.897 ms epoch: 6 acc: 0.11090353260869565 top5-acc: 0.3021399456521739, best acc is 0.11090353260869565 =============Over Flow, skipping============= epoch: 7 step: 328, loss is 4.38911247253418 Train epoch time: 77914.136 ms, per step time: 237.543 ms epoch: 7 acc: 0.13671875 top5-acc: 0.33474864130434784, best acc is 0.13671875 epoch: 8 step: 328, loss is 4.416530609130859 Train epoch time: 78155.158 ms, per step time: 238.278 ms epoch: 8 acc: 0.12516983695652173 top5-acc: 0.335258152173913, best acc is 0.13671875 epoch: 9 step: 328, loss is 4.346778392791748 Train epoch time: 77911.331 ms, per step time: 237.535 ms epoch: 9 acc: 0.14673913043478262 top5-acc: 0.36905570652173914, best acc is 0.14673913043478262 epoch: 10 step: 328, loss is 4.5370354652404785 Train epoch time: 77869.734 ms, per step time: 237.408 ms epoch: 10 acc: 0.16559103260869565 top5-acc: 0.41389266304347827, best acc is 0.16559103260869565 epoch: 11 step: 328, loss is 4.40866756439209 Train epoch time: 77792.362 ms, per step time: 237.172 ms epoch: 11 acc: 0.16932744565217392 top5-acc: 0.42595108695652173, best acc is 0.16932744565217392 epoch: 12 step: 328, loss is 4.258575439453125 Train epoch time: 78045.822 ms, per step time: 237.945 ms epoch: 12 acc: 0.1883491847826087 top5-acc: 0.4429347826086957, best acc is 0.1883491847826087 =============Over Flow, skipping============= epoch: 13 step: 328, loss is 4.406404972076416 Train epoch time: 78015.169 ms, per step time: 237.851 ms epoch: 13 acc: 0.19208559782608695 top5-acc: 0.45023777173913043, best acc is 0.19208559782608695 epoch: 14 step: 328, loss is 4.288840293884277 Train epoch time: 77976.810 ms, per step time: 237.734 ms epoch: 14 acc: 0.20074728260869565 top5-acc: 0.47452445652173914, best acc is 0.20074728260869565 epoch: 15 step: 328, loss is 4.286988735198975 Train epoch time: 77837.343 ms, per step time: 237.309 ms epoch: 15 acc: 0.20838994565217392 top5-acc: 0.491508152173913, best acc is 0.20838994565217392 epoch: 16 step: 328, loss is 4.023094654083252 Train epoch time: 78042.042 ms, per step time: 237.933 ms epoch: 16 acc: 0.21993885869565216 top5-acc: 0.5079823369565217, best acc is 0.21993885869565216 epoch: 17 step: 328, loss is 4.169596195220947 Train epoch time: 77697.700 ms, per step time: 236.883 ms epoch: 17 acc: 0.22554347826086957 top5-acc: 0.5061141304347826, best acc is 0.22554347826086957 epoch: 18 step: 328, loss is 4.3070878982543945 Train epoch time: 78022.776 ms, per step time: 237.874 ms epoch: 18 acc: 0.23539402173913043 top5-acc: 0.5283627717391305, best acc is 0.23539402173913043 =============Over Flow, skipping============= epoch: 19 step: 328, loss is 4.109980583190918 Train epoch time: 78016.262 ms, per step time: 237.854 ms epoch: 19 acc: 0.25577445652173914 top5-acc: 0.5222486413043478, best acc is 0.25577445652173914 epoch: 20 step: 328, loss is 4.031306743621826 Train epoch time: 77715.961 ms, per step time: 236.939 ms epoch: 20 acc: 0.25900135869565216 top5-acc: 0.5385529891304348, best acc is 0.25900135869565216 epoch: 21 step: 328, loss is 4.215546607971191 Train epoch time: 77684.027 ms, per step time: 236.842 ms epoch: 21 acc: 0.25968070652173914 top5-acc: 0.5531589673913043, best acc is 0.25968070652173914 epoch: 22 step: 328, loss is 4.093695640563965 Train epoch time: 78090.945 ms, per step time: 238.082 ms epoch: 22 acc: 0.2600203804347826 top5-acc: 0.5543478260869565, best acc is 0.2600203804347826 epoch: 23 step: 328, loss is 4.0735273361206055 Train epoch time: 77968.515 ms, per step time: 237.709 ms epoch: 23 acc: 0.2787024456521739 top5-acc: 0.5686141304347826, best acc is 0.2787024456521739 epoch: 24 step: 328, loss is 4.377508163452148 Train epoch time: 77772.071 ms, per step time: 237.110 ms epoch: 24 acc: 0.2798913043478261 top5-acc: 0.5782948369565217, best acc is 0.2798913043478261 =============Over Flow, skipping============= epoch: 25 step: 328, loss is 3.937976360321045 Train epoch time: 77997.789 ms, per step time: 237.798 ms epoch: 25 acc: 0.2916100543478261 top5-acc: 0.5825407608695652, best acc is 0.2916100543478261 =============Over Flow, skipping============= epoch: 26 step: 328, loss is 4.130610942840576 Train epoch time: 77919.894 ms, per step time: 237.561 ms epoch: 26 acc: 0.29483695652173914 top5-acc: 0.5840692934782609, best acc is 0.29483695652173914 epoch: 27 step: 328, loss is 3.963009834289551 Train epoch time: 78296.125 ms, per step time: 238.708 ms epoch: 27 acc: 0.30570652173913043 top5-acc: 0.6103940217391305, best acc is 0.30570652173913043 epoch: 28 step: 328, loss is 3.94366717338562 Train epoch time: 78107.002 ms, per step time: 238.131 ms epoch: 28 acc: 0.31266983695652173 top5-acc: 0.6154891304347826, best acc is 0.31266983695652173 epoch: 29 step: 328, loss is 3.7120132446289062 Train epoch time: 77957.414 ms, per step time: 237.675 ms epoch: 29 acc: 0.32319972826086957 top5-acc: 0.627547554347826, best acc is 0.32319972826086957 epoch: 30 step: 328, loss is 4.277674198150635 Train epoch time: 78170.149 ms, per step time: 238.324 ms epoch: 30 acc: 0.311820652173913 top5-acc: 0.6129415760869565, best acc is 0.32319972826086957 epoch: 31 step: 328, loss is 4.324661731719971 Train epoch time: 78529.550 ms, per step time: 239.419 ms epoch: 31 acc: 0.3255774456521739 top5-acc: 0.6299252717391305, best acc is 0.3255774456521739 =============Over Flow, skipping============= epoch: 32 step: 328, loss is 4.174750804901123 Train epoch time: 77924.515 ms, per step time: 237.575 ms epoch: 32 acc: 0.33695652173913043 top5-acc: 0.6441915760869565, best acc is 0.33695652173913043 epoch: 33 step: 328, loss is 3.8301479816436768 Train epoch time: 77852.323 ms, per step time: 237.355 ms epoch: 33 acc: 0.3422214673913043 top5-acc: 0.641983695652174, best acc is 0.3422214673913043 epoch: 34 step: 328, loss is 4.2253923416137695 Train epoch time: 78160.324 ms, per step time: 238.294 ms epoch: 34 acc: 0.32778532608695654 top5-acc: 0.6323029891304348, best acc is 0.3422214673913043 epoch: 35 step: 328, loss is 4.316101551055908 Train epoch time: 77949.068 ms, per step time: 237.650 ms epoch: 35 acc: 0.358695652173913 top5-acc: 0.6569293478260869, best acc is 0.358695652173913 epoch: 36 step: 328, loss is 4.160644054412842 Train epoch time: 78140.680 ms, per step time: 238.234 ms epoch: 36 acc: 0.32999320652173914 top5-acc: 0.6413043478260869, best acc is 0.358695652173913 epoch: 37 step: 328, loss is 3.802969217300415 Train epoch time: 78095.721 ms, per step time: 238.097 ms epoch: 37 acc: 0.36379076086956524 top5-acc: 0.6569293478260869, best acc is 0.36379076086956524 epoch: 38 step: 328, loss is 4.089756011962891 Train epoch time: 78088.570 ms, per step time: 238.075 ms epoch: 38 acc: 0.37313179347826086 top5-acc: 0.6798573369565217, best acc is 0.37313179347826086 =============Over Flow, skipping============= epoch: 39 step: 328, loss is 3.53753662109375 Train epoch time: 77897.645 ms, per step time: 237.493 ms epoch: 39 acc: 0.3828125 top5-acc: 0.6759510869565217, best acc is 0.3828125 epoch: 40 step: 328, loss is 3.609902858734131 Train epoch time: 78314.654 ms, per step time: 238.764 ms epoch: 40 acc: 0.3804347826086957 top5-acc: 0.6703464673913043, best acc is 0.3828125 epoch: 41 step: 328, loss is 4.303561210632324 Train epoch time: 78110.555 ms, per step time: 238.142 ms epoch: 41 acc: 0.39809782608695654 top5-acc: 0.6931046195652174, best acc is 0.39809782608695654 epoch: 42 step: 328, loss is 3.4438838958740234 Train epoch time: 77831.506 ms, per step time: 237.291 ms epoch: 42 acc: 0.3931725543478261 top5-acc: 0.6961616847826086, best acc is 0.39809782608695654 epoch: 43 step: 328, loss is 3.5862011909484863 Train epoch time: 78138.125 ms, per step time: 238.226 ms epoch: 43 acc: 0.3967391304347826 top5-acc: 0.6983695652173914, best acc is 0.39809782608695654 epoch: 44 step: 328, loss is 4.128260612487793 Train epoch time: 77968.969 ms, per step time: 237.710 ms epoch: 44 acc: 0.39249320652173914 top5-acc: 0.6944633152173914, best acc is 0.39809782608695654 =============Over Flow, skipping============= epoch: 45 step: 328, loss is 4.155826091766357 Train epoch time: 77874.741 ms, per step time: 237.423 ms epoch: 45 acc: 0.40591032608695654 top5-acc: 0.7055027173913043, best acc is 0.40591032608695654 epoch: 46 step: 328, loss is 3.9320266246795654 Train epoch time: 78020.188 ms, per step time: 237.866 ms epoch: 46 acc: 0.4154211956521739 top5-acc: 0.7155230978260869, best acc is 0.4154211956521739 epoch: 47 step: 328, loss is 4.123641014099121 Train epoch time: 78344.166 ms, per step time: 238.854 ms epoch: 47 acc: 0.4155910326086957 top5-acc: 0.7116168478260869, best acc is 0.4155910326086957 epoch: 48 step: 328, loss is 4.011114120483398 Train epoch time: 78071.050 ms, per step time: 238.021 ms epoch: 48 acc: 0.4232336956521739 top5-acc: 0.7280910326086957, best acc is 0.4232336956521739 epoch: 49 step: 328, loss is 4.114437580108643 Train epoch time: 78166.502 ms, per step time: 238.313 ms epoch: 49 acc: 0.4327445652173913 top5-acc: 0.7359035326086957, best acc is 0.4327445652173913 epoch: 50 step: 328, loss is 4.075896739959717 Train epoch time: 77756.753 ms, per step time: 237.063 ms epoch: 50 acc: 0.4201766304347826 top5-acc: 0.7141644021739131, best acc is 0.4327445652173913 =============Over Flow, skipping============= epoch: 51 step: 328, loss is 4.036683082580566 Train epoch time: 77974.045 ms, per step time: 237.726 ms epoch: 51 acc: 0.43783967391304346 top5-acc: 0.7260529891304348, best acc is 0.43783967391304346 epoch: 52 step: 328, loss is 4.108072280883789 Train epoch time: 78001.574 ms, per step time: 237.810 ms epoch: 52 acc: 0.4320652173913043 top5-acc: 0.7331861413043478, best acc is 0.43783967391304346 epoch: 53 step: 328, loss is 3.69376802444458 Train epoch time: 77847.631 ms, per step time: 237.340 ms epoch: 53 acc: 0.4505774456521739 top5-acc: 0.7437160326086957, best acc is 0.4505774456521739 epoch: 54 step: 328, loss is 4.165959358215332 Train epoch time: 77814.628 ms, per step time: 237.240 ms epoch: 54 acc: 0.44089673913043476 top5-acc: 0.7328464673913043, best acc is 0.4505774456521739 epoch: 55 step: 328, loss is 4.163305282592773 Train epoch time: 78025.681 ms, per step time: 237.883 ms epoch: 55 acc: 0.45499320652173914 top5-acc: 0.7367527173913043, best acc is 0.45499320652173914 epoch: 56 step: 328, loss is 4.002499580383301 Train epoch time: 78114.233 ms, per step time: 238.153 ms epoch: 56 acc: 0.45822010869565216 top5-acc: 0.7454144021739131, best acc is 0.45822010869565216 =============Over Flow, skipping============= epoch: 57 step: 328, loss is 3.964570999145508 Train epoch time: 77909.596 ms, per step time: 237.529 ms epoch: 57 acc: 0.47673233695652173 top5-acc: 0.7567934782608695, best acc is 0.47673233695652173 epoch: 58 step: 328, loss is 3.8768999576568604 Train epoch time: 77917.612 ms, per step time: 237.554 ms epoch: 58 acc: 0.47843070652173914 top5-acc: 0.7554347826086957, best acc is 0.47843070652173914 epoch: 59 step: 328, loss is 3.3266918659210205 Train epoch time: 77987.581 ms, per step time: 237.767 ms epoch: 59 acc: 0.4782608695652174 top5-acc: 0.7637567934782609, best acc is 0.47843070652173914 epoch: 60 step: 328, loss is 3.9986932277679443 Train epoch time: 78162.117 ms, per step time: 238.299 ms epoch: 60 acc: 0.4748641304347826 top5-acc: 0.7651154891304348, best acc is 0.47843070652173914 epoch: 61 step: 328, loss is 3.554734230041504 Train epoch time: 79327.994 ms, per step time: 241.854 ms epoch: 61 acc: 0.47690217391304346 top5-acc: 0.7627377717391305, best acc is 0.47843070652173914 epoch: 62 step: 328, loss is 4.098214149475098 Train epoch time: 79343.368 ms, per step time: 241.901 ms epoch: 62 acc: 0.48012907608695654 top5-acc: 0.765625, best acc is 0.48012907608695654 =============Over Flow, skipping============= epoch: 63 step: 328, loss is 3.7967209815979004 Train epoch time: 78342.405 ms, per step time: 238.849 ms epoch: 63 acc: 0.48556385869565216 top5-acc: 0.7676630434782609, best acc is 0.48556385869565216 epoch: 64 step: 328, loss is 3.398728609085083 Train epoch time: 78146.445 ms, per step time: 238.251 ms epoch: 64 acc: 0.4835258152173913 top5-acc: 0.7725883152173914, best acc is 0.48556385869565216 epoch: 65 step: 328, loss is 3.307548999786377 Train epoch time: 77922.219 ms, per step time: 237.568 ms epoch: 65 acc: 0.4984714673913043 top5-acc: 0.778702445652174, best acc is 0.4984714673913043 epoch: 66 step: 328, loss is 4.043028354644775 Train epoch time: 78039.694 ms, per step time: 237.926 ms epoch: 66 acc: 0.5010190217391305 top5-acc: 0.7793817934782609, best acc is 0.5010190217391305 epoch: 67 step: 328, loss is 3.7040460109710693 Train epoch time: 77856.072 ms, per step time: 237.366 ms epoch: 67 acc: 0.49966032608695654 top5-acc: 0.7797214673913043, best acc is 0.5010190217391305 epoch: 68 step: 328, loss is 3.765737771987915 Train epoch time: 78541.913 ms, per step time: 239.457 ms epoch: 68 acc: 0.5047554347826086 top5-acc: 0.783797554347826, best acc is 0.5047554347826086 epoch: 69 step: 328, loss is 3.8921711444854736 Train epoch time: 78037.338 ms, per step time: 237.919 ms epoch: 69 acc: 0.5137567934782609 top5-acc: 0.7843070652173914, best acc is 0.5137567934782609 epoch: 70 step: 328, loss is 3.996326446533203 Train epoch time: 77872.417 ms, per step time: 237.416 ms epoch: 70 acc: 0.5125679347826086 top5-acc: 0.7875339673913043, best acc is 0.5137567934782609 epoch: 71 step: 328, loss is 4.144741535186768 Train epoch time: 77957.219 ms, per step time: 237.674 ms epoch: 71 acc: 0.5137567934782609 top5-acc: 0.790421195652174, best acc is 0.5137567934782609 epoch: 72 step: 328, loss is 3.6382193565368652 Train epoch time: 78040.411 ms, per step time: 237.928 ms epoch: 72 acc: 0.5127377717391305 top5-acc: 0.7860054347826086, best acc is 0.5137567934782609 epoch: 73 step: 328, loss is 3.5755395889282227 Train epoch time: 78034.322 ms, per step time: 237.910 ms epoch: 73 acc: 0.5159646739130435 top5-acc: 0.7878736413043478, best acc is 0.5159646739130435 epoch: 74 step: 328, loss is 3.6679434776306152 Train epoch time: 77881.833 ms, per step time: 237.445 ms epoch: 74 acc: 0.5193614130434783 top5-acc: 0.7931385869565217, best acc is 0.5193614130434783 =============Over Flow, skipping============= epoch: 75 step: 328, loss is 3.8212318420410156 Train epoch time: 78212.435 ms, per step time: 238.453 ms epoch: 75 acc: 0.5236073369565217 top5-acc: 0.7936480978260869, best acc is 0.5236073369565217 epoch: 76 step: 328, loss is 3.811330556869507 Train epoch time: 77924.677 ms, per step time: 237.575 ms epoch: 76 acc: 0.5263247282608695 top5-acc: 0.7961956521739131, best acc is 0.5263247282608695 epoch: 77 step: 328, loss is 3.0529000759124756 Train epoch time: 77880.984 ms, per step time: 237.442 ms epoch: 77 acc: 0.5264945652173914 top5-acc: 0.7990828804347826, best acc is 0.5264945652173914 epoch: 78 step: 328, loss is 3.051379680633545 Train epoch time: 77631.681 ms, per step time: 236.682 ms epoch: 78 acc: 0.5320991847826086 top5-acc: 0.8023097826086957, best acc is 0.5320991847826086 epoch: 79 step: 328, loss is 4.120721340179443 Train epoch time: 77824.862 ms, per step time: 237.271 ms epoch: 79 acc: 0.53125 top5-acc: 0.7989130434782609, best acc is 0.5320991847826086 epoch: 80 step: 328, loss is 3.954958915710449 Train epoch time: 77628.485 ms, per step time: 236.672 ms epoch: 80 acc: 0.5353260869565217 top5-acc: 0.8002717391304348, best acc is 0.5353260869565217 =============Over Flow, skipping============= epoch: 81 step: 328, loss is 3.724217176437378 Train epoch time: 78065.812 ms, per step time: 238.006 ms epoch: 81 acc: 0.5363451086956522 top5-acc: 0.8019701086956522, best acc is 0.5363451086956522 epoch: 82 step: 328, loss is 3.155369997024536 Train epoch time: 77924.482 ms, per step time: 237.575 ms epoch: 82 acc: 0.537703804347826 top5-acc: 0.8067255434782609, best acc is 0.537703804347826 epoch: 83 step: 328, loss is 3.3825459480285645 Train epoch time: 77953.530 ms, per step time: 237.663 ms epoch: 83 acc: 0.5354959239130435 top5-acc: 0.803328804347826, best acc is 0.537703804347826 =============Over Flow, skipping============= epoch: 84 step: 328, loss is 3.9255869388580322 Train epoch time: 77817.596 ms, per step time: 237.249 ms epoch: 84 acc: 0.5433084239130435 top5-acc: 0.8092730978260869, best acc is 0.5433084239130435 epoch: 85 step: 328, loss is 3.62528133392334 Train epoch time: 78312.543 ms, per step time: 238.758 ms epoch: 85 acc: 0.5436480978260869 top5-acc: 0.8045176630434783, best acc is 0.5436480978260869 epoch: 86 step: 328, loss is 3.8779077529907227 Train epoch time: 79035.696 ms, per step time: 240.962 ms epoch: 86 acc: 0.5456861413043478 top5-acc: 0.80859375, best acc is 0.5456861413043478 epoch: 87 step: 328, loss is 4.07357931137085 Train epoch time: 77741.437 ms, per step time: 237.017 ms epoch: 87 acc: 0.544327445652174 top5-acc: 0.8034986413043478, best acc is 0.5456861413043478 epoch: 88 step: 328, loss is 3.640528917312622 Train epoch time: 77927.202 ms, per step time: 237.583 ms epoch: 88 acc: 0.5438179347826086 top5-acc: 0.8074048913043478, best acc is 0.5456861413043478 epoch: 89 step: 328, loss is 3.3842782974243164 Train epoch time: 78080.250 ms, per step time: 238.050 ms epoch: 89 acc: 0.5448369565217391 top5-acc: 0.8108016304347826, best acc is 0.5456861413043478 epoch: 90 step: 328, loss is 3.9701128005981445 Train epoch time: 78034.974 ms, per step time: 237.912 ms epoch: 90 acc: 0.5473845108695652 top5-acc: 0.8106317934782609, best acc is 0.5473845108695652 epoch: 91 step: 328, loss is 3.93862247467041 Train epoch time: 77777.080 ms, per step time: 237.125 ms epoch: 91 acc: 0.5487432065217391 top5-acc: 0.8091032608695652, best acc is 0.5487432065217391 epoch: 92 step: 328, loss is 3.3578507900238037 Train epoch time: 77840.785 ms, per step time: 237.319 ms epoch: 92 acc: 0.5499320652173914 top5-acc: 0.8087635869565217, best acc is 0.5499320652173914 epoch: 93 step: 328, loss is 3.402940034866333 Train epoch time: 77841.572 ms, per step time: 237.322 ms epoch: 93 acc: 0.5516304347826086 top5-acc: 0.8077445652173914, best acc is 0.5516304347826086 epoch: 94 step: 328, loss is 3.50596022605896 Train epoch time: 78055.788 ms, per step time: 237.975 ms epoch: 94 acc: 0.5514605978260869 top5-acc: 0.8106317934782609, best acc is 0.5516304347826086 epoch: 95 step: 328, loss is 3.9884400367736816 Train epoch time: 77863.441 ms, per step time: 237.389 ms epoch: 95 acc: 0.5516304347826086 top5-acc: 0.8092730978260869, best acc is 0.5516304347826086 =============Over Flow, skipping============= epoch: 96 step: 328, loss is 3.4499902725219727 Train epoch time: 77863.299 ms, per step time: 237.388 ms epoch: 96 acc: 0.5526494565217391 top5-acc: 0.8079144021739131, best acc is 0.5526494565217391 epoch: 97 step: 328, loss is 3.518087387084961 Train epoch time: 77672.538 ms, per step time: 236.807 ms epoch: 97 acc: 0.5526494565217391 top5-acc: 0.8102921195652174, best acc is 0.5526494565217391 epoch: 98 step: 328, loss is 2.900960922241211 Train epoch time: 77649.499 ms, per step time: 236.736 ms epoch: 98 acc: 0.5512907608695652 top5-acc: 0.8084239130434783, best acc is 0.5526494565217391 epoch: 99 step: 328, loss is 3.933858633041382 Train epoch time: 77925.955 ms, per step time: 237.579 ms epoch: 99 acc: 0.5531589673913043 top5-acc: 0.8104619565217391, best acc is 0.5531589673913043 epoch: 100 step: 328, loss is 2.9689321517944336 Train epoch time: 77380.916 ms, per step time: 235.917 ms epoch: 100 acc: 0.5514605978260869 top5-acc: 0.809952445652174, best acc is 0.5531589673913043 train success
测试
In [28]:
def test(net, model):
# load the saved model for evaluation
param_dict = load_checkpoint("ckpt/best.ckpt")
# load parameter to the network
load_param_into_net(net, param_dict)
# load testing dataset
data = get_dataset(args, training=False)
print(f"=> begin eval")
results = model.eval(data.test_dataset)
print(f"=> eval results:{results}")
print(f"=> eval success")
In [29]:
test(net, model)
=> Getting ImageNet dataset
=> begin eval
=> eval results:{'Loss': 1.8583465449271663, 'Acc': 0.5525873655913979, 'Top5-Acc': 0.8158602150537635}
=> eval success
总结
miniImageNet上的SwinTransformer
| 属性 | 情况 |
|---|---|
| 模型 | SwinTransformer |
| 模型版本 | swin_tiny_patch4_window7_224 |
| 资源 | Gefore RTX 3090 * 1 |
| MindSpore版本 | 1.8.1 |
| 验证集 | miniImageNet Val,共6,000张图像 |
| 验证集分类准确率 | Top1-Acc: 55.32%, Top5-Acc: 81.05% |
| 测试集 | miniImageNet Test,共12,000张图像 |
| 测试集分类准确率 | Top1-Acc: 55.26%, Top5-Acc: 81.59% |





![[python] 基于PyOD库实现数据异常检测](https://img-blog.csdnimg.cn/img_convert/2e116bc552b6c90a35c030c0f7be4f8f.png)