Llama 3.2-Vision是Meta开发的一系列多模态大型语言模型(LLMs),包含11B和90B两种规模的预训练和指令调整模型。

这些模型专门优化用于视觉识别、图像推理、字幕生成和回答有关图像的一般问题。Llama 3.2-Vision模型在常见行业基准测试中的表现优于许多现有的开源和封闭多模态模型。支持8种语言的文本任务,并且可以进行额外的语言微调。该模型使用独立的视觉适配器来支持图像识别任务,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)进行优化,以符合人类对有用性和安全性的偏好。

本文将带大家在矩池云快速使用 Llama-3.2-11B-Vision 进行推理。
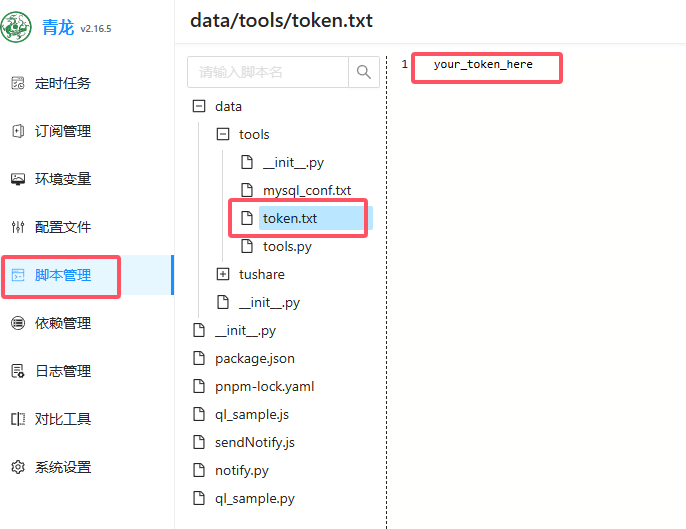
上传模型和数据
如果租用的亚太区机器可以直接访问huggingface,在线下载模型和数据,无需操作以下步骤。
Llama-3.2-11B-Vision-Instruct 的模型放在Huggingface,租用国内服务器直接运行下载可能很慢,所以我们需要提前本地下载好,然后上传到矩池云网盘再租用机器使用。
注意 Llama-3.2 模型需要在 Huggingface 登录后申请才能下载,请先访问以下链接前往申请通过后再租用机器操作。
https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct
本地下载好后,把相关文件上传到矩池云网盘即可,之后再根据项目需求进行调用。
租用机器
本次复现先使用的是亚太1区 NVIDIA RTX 4090 配置环境,镜像使用的是 Pytorch 2.4.0,选择好机器和镜像后,点击租用即可。
使用亚太1区的可以无感连 Github 和 HuggingFace,克隆 Github 代码或者下载Huggingface 模型很快。

租用成功后我们可以在租用页面看到机器的 SSH、Jupyterlab 等链接,矩池云官网有详细的教程介绍了如何使用这些链接连接服务器。

运行代码
接着上一步,我们直接打开 jupyterlab,新建一个 Notebook 。

安装环境
如果直接运行官方给的代码会出现一个包缺失错误,不要慌。
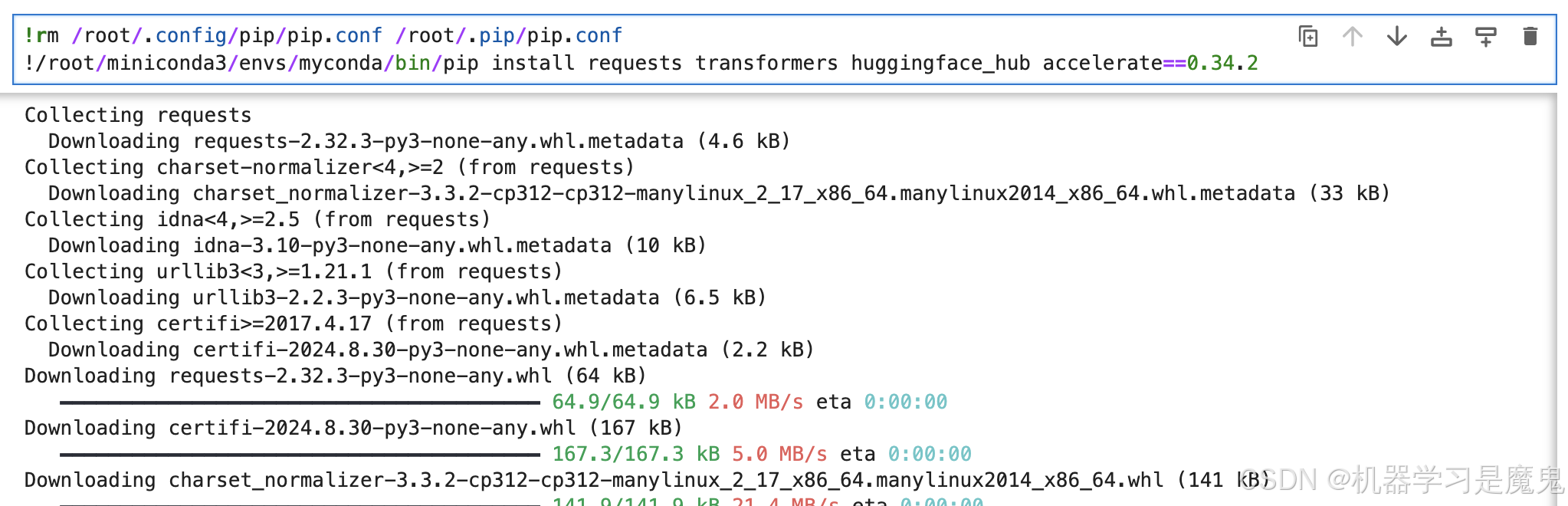
 在notebook cell中运行以下指令安装需要的python包。
在notebook cell中运行以下指令安装需要的python包。
# 这句rm指令是清除镜像里默认配置的国内pip镜像源,
# 如果你租用的不是亚太1区的机器,不用运行这句
!rm /root/.config/pip/pip.conf /root/.pip/pip.conf
!/root/miniconda3/envs/myconda/bin/pip install requests transformers huggingface_hub accelerate==0.34.2
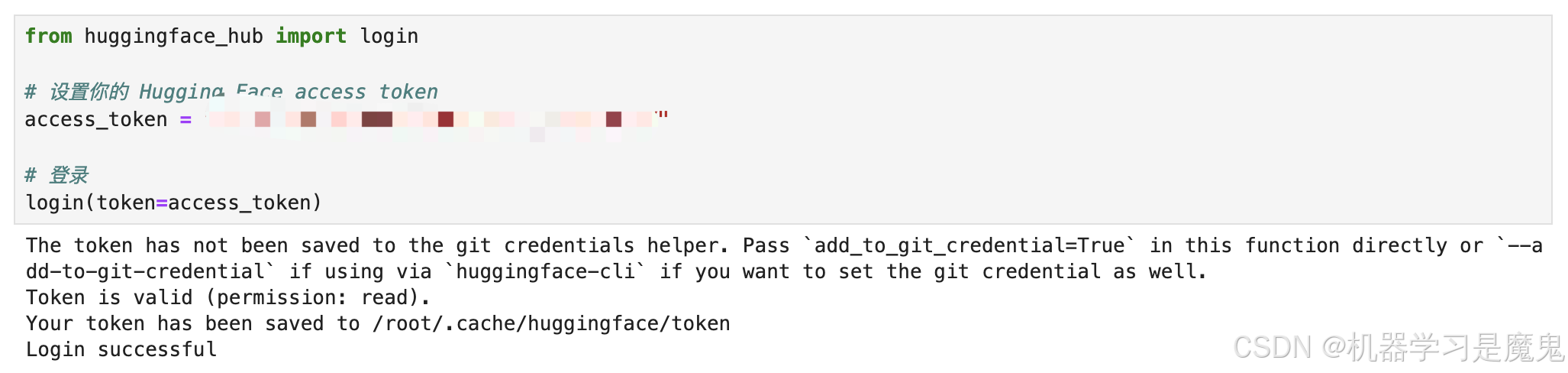
登录 Huggingface
如果你已经本地下载上传好了 Llama-3.2 模型,则无需执行以下步骤。如果和我一样租用亚太1区机器,想直接在机器里下载模型,则需要执行以下步骤。
Huggingface access_token 获取方法:访问以下页面,登录Huggingface 后点击 Create new token即可。
https://huggingface.co/settings/tokens

再运行以下代码登录 Huggingface 。
from huggingface_hub import login
# 设置你的 Hugging Face access token
access_token = "hf_UxxxxxxxxxxxxxxxxAX"
# 登录
login(token=access_token)
登录后,再运行官方提供的推理代码即可开始下载模型,推理啦。如果租用亚太1区机器,模型总共21G,下载大概12分钟。
如果你是本地上传的模型,请将"meta-llama/Llama-3.2-11B-Vision-Instruct"改成你模型文件所在路径。
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))
官方案例运行结果:

换一张本地图片测试看看,我从矩池云官网截了一张图,然后问问 Llama 3.2 里面有什么信息。
 结果:还不错,识别到了图中的4090等关键信息。
结果:还不错,识别到了图中的4090等关键信息。

尝试将max_new_tokens从30变成300后,识别回复的内容更全面、更准确了,相应推理时间也变长了。

推理运行速度很快,显存占用22GB左右,可以在 3090、4090、A40、A6000等显卡运行推理。

保存环境
租用页面点击更多->保存到个人环境即可,输入环境名称,再点击保存环境按钮。
注意:保存环境存放在你的矩池云网盘,默认有5g免费空间,像我现在保存环境20g,就得先去扩容,再保存,不然会保存失败。

保存成功后下次即可快速从保存环境启动啦,无需花时间等环境配置及模型下载了。
如果你复现有什么问题,或者有什么AI项目复现需求,欢迎评论交流,知无不言。