号主:老杨丨11年资深网络工程师,更多网工提升干货,请关注公众号:网络工程师俱乐部
上午好,我的网工朋友。
9月27日早上,A股市场迎来了一波前所未有的火爆行情,成交量激增,市场情绪高涨。
然而,这场交易热潮却让上海证券交易所(上交所)的交易系统“崩”了!
这大新闻咱网工圈都热议纷纷。
是的,你没听错,上交所的系统在当天上午出现了短暂的宕机,导致很多投资者无法正常买卖股票,甚至撤单都成了难题。
这一事件不仅让股民们感叹“行情太火,服务器都扛不住了”,也引发了IT圈内的广泛讨论。
今年见过的宕机事件还真不少啊。虽然现在已经恢复正常,但对于 IT 从业者来讲,出现了这样的事故简直是天都要塌了!
今天我们就来浅聊一下,这次上交所系统宕机的原因、可能的防范措施,以及这对IT从业者和未来技术发展的影响。
今日文章阅读福利:《云计算学习大纲(2024)》
私信我,发送暗号“111”,即可获取云计算从0到1的学习路径,方便萌新更快入手学习。
01 事件回顾股市火爆!交易所崩了?
9月27日早间,中国人民银行公告,自9月27日起,下调金融机构存款准备金率0.5个百分点(不含已执行5%存款准备金率的金融机构);公开市场7天期逆回购操作利率由此前的1.70%调整为1.50%,下调0.2个百分点。
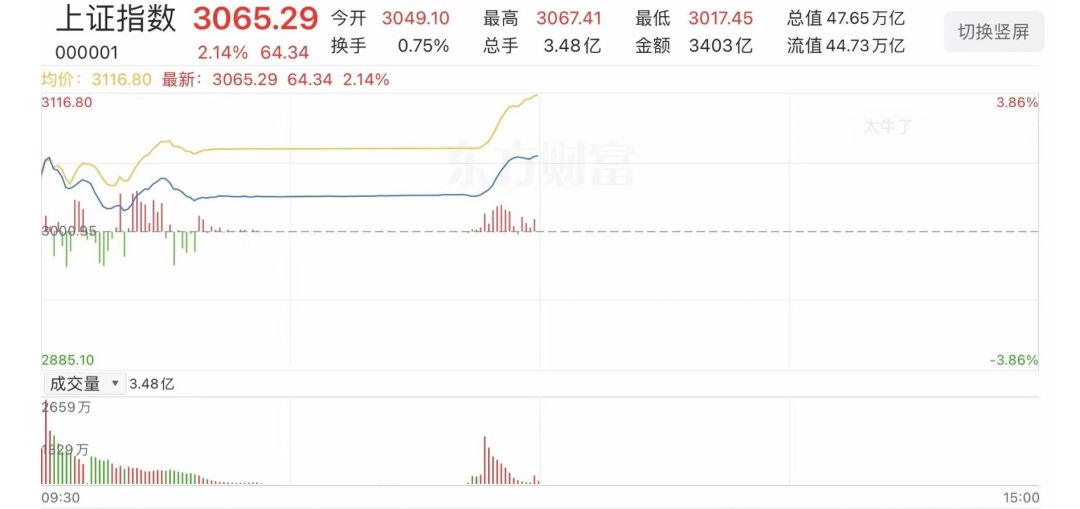
久违的行情,气吞山河,荡气回肠!
很多人股民情绪被调动起来,感觉和过年一样!
就在大家纷纷涌入市场准备大展身手的时候,上交所的交易系统却突然“罢工”了。
早上开盘不久,很多股民发现自己的订单提交不上去,撤单也撤不了,整个交易过程变得异常缓慢,甚至完全卡住了。
上交所服务器,被大家给买崩了?!
大家都在吐槽:“这行情太火爆了,连交易所的服务器都扛不住了!”、“买个股票比抢演唱会门票还难!”更有投资者调侃说:“这是要让咱们冷静冷静吗?”。
02 为啥崩了?这次宕机是哪里出问题了?
这次上交所服务器宕机,到底是哪里出了问题?
关于事故原因,外界也是猜测不断,有群友发了个聊天记录出来,说是此次事故是上交所的网关出了问题。
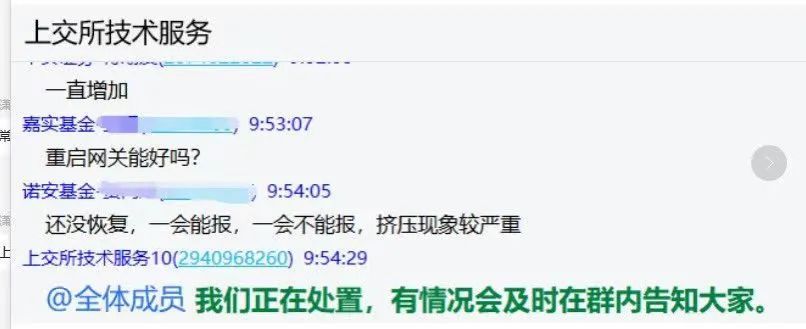
其实说来说去,无非就是那几个可能的技术原因。
首先,接着刚刚说的,网关问题可能是主要的“罪魁祸首”。
据InfoQ的文章所言,上交所采用的是全新自主研发的基于流式接口的交易网关(TDGW),虽然设计上有高性能、低时延等优点,但在实际运行中可能还存在一些未被发现的问题。
一旦遇到大规模并发请求,网关可能无法及时处理,导致系统响应缓慢甚至崩溃。
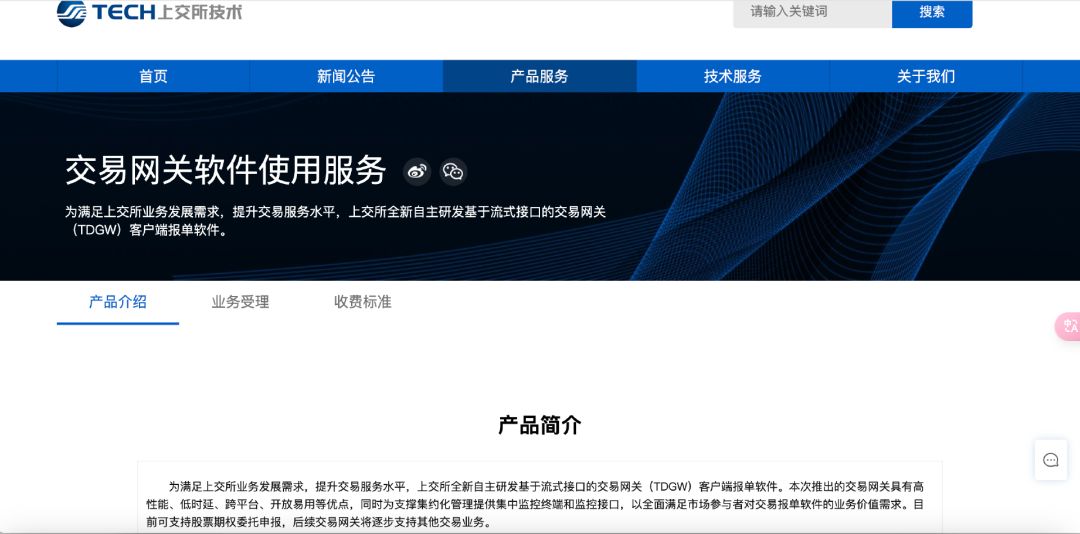
其次,服务器扩容不足也可能是一个重要因素。
市场交易量激增时,现有的服务器容量可能不足以应对这种突发的高流量。这就像是高峰期的高速公路,如果车道不够宽,再多的车辆也只会造成拥堵。
在这种情况下,云计算的优势就显得尤为重要。通过云服务提供商,可以根据实际需要动态调整计算、存储和网络资源,从而有效应对高峰时段的需求。
最后,软件或硬件升级不完善也可能导致了此次宕机。
新推出的交易网关(TDGW)虽然在理论上有很多优势,但任何新技术在实际应用中都可能存在未知的风险。
如果在上线前没有进行充分的压力测试和性能优化,或者在部署过程中出现了某些配置错误,都可能导致系统在高负载下出现问题。
网络工程在这方面的角色也很关键,例如,通过软件定义网络(SDN)技术,可以更灵活地控制和管理网络行为,提高系统的灵活性和响应速度。
简单来说,这次宕机就像是一个大型商场在节假日突然迎来大量顾客,如果入口太小、收银台不够多,再加上新的管理系统还没完全调试好,整个商场就会陷入混乱。
对于金融市场的交易系统来说,道理也是一样的。
我们需要更强大的基础设施、更灵活的资源调度以及更完善的升级测试,才能确保在市场火爆时也能顺畅运行。
03 防范措施建议
为了避免类似事件再次发生,我们需要从多个方面入手,采取有效的防范措施和改进方案。
以下是一些具体的建议:
1、加强系统测试:
压力测试:定期进行大规模的压力测试,模拟极端交易量的情况,确保系统在高负载下仍能稳定运行。
性能优化:对系统进行全面的性能优化,找出并解决潜在的瓶颈问题。
2、提高冗余性和弹性:
多地点数据中心:建立多地点的数据中心,确保在某个节点出现问题时,可以迅速切换到其他节点,保证服务连续性。
云计算资源:利用云计算平台的弹性伸缩能力,根据实际需求动态调整计算、存储和网络资源,应对突发的高流量。
3、持续监控与预警:
实时监控:部署先进的监控工具,实时监控系统的运行状态,包括CPU使用率、内存占用、网络带宽等关键指标。
智能预警:设置合理的阈值触发警报,一旦发现异常情况,立即通知运维团队进行处理,避免小问题演变成大故障。
4、定期维护与更新:
软硬件检查:定期对服务器、网络设备等进行检查和维护,确保硬件设备处于良好状态。
安全补丁:及时更新操作系统和应用程序的安全补丁,防止已知漏洞被恶意利用。
5、完善应急预案:
备份与恢复:制定详细的备份和恢复计划,确保在系统出现故障时能够快速恢复数据和服务。
演练与培训:定期进行应急演练,提高团队的响应速度和处理能力。同时,对运维人员进行培训,提升他们的技术水平和应急处置能力。
总结来说, 一个稳定的交易系统需要综合考虑硬件、软件、应急机制等多个方面,并不断进行优化和完善。
通过一些措施,我们可以降低系统宕机的风险,确保市场的稳定运行。
无论是对于上交所还是其他机构来说,构建一个高效、可靠且灵活的技术基础设施都是至关重要的。
04 浅谈一波未来方向
这次上交所系统宕机事件还挺典型的,也让我们看到了未来技术发展的方向。
我想从我的角度延伸一下这事儿,扯得有点远,浅谈一波网工可能的未来方向之一,希望能给大家一些实用的建议。
01 浅谈一下云计算
首先,咱们得谈谈云计算。
现在云计算已经不是什么新鲜事了,但真正用好它的人还不多。
通过云原生技术,比如容器化和微服务,我们可以让系统更加灵活和可扩展。举个例子,如果你的系统突然遇到大量用户涌入,传统的服务器可能一下子就崩了,但有了云计算,你可以快速增加资源,应对这种突发情况。
小贴士:多云策略也很重要。
不要把所有的鸡蛋放在一个篮子里,多用几个云服务商,这样即使某个云出现问题,你还有其他的选择。这不仅能提高系统的容错能力,还能让你在谈判中更有话语权。
02 自动化与智能化
自动化运维是未来的趋势。
像Ansible、Puppet这些工具,可以帮你实现自动化部署、监控和维护。
以前需要手动干的事情,现在几行脚本就能搞定,大大提高了效率,减少了人为错误。
智能监控也是个大趋势。
利用人工智能和机器学习,你可以提前发现潜在的问题,并自动触发应急响应机制。比如,系统突然出现异常流量,智能监控系统能立即识别并采取措施,防止问题扩大。
小贴士:多学学Python或者Shell脚本,这些技能会让你在自动化运维方面如虎添翼。同时,了解一些AI和机器学习的基础知识,也能让你在智能监控方面更得心应手。
新时代的网工,绝对离不开AI。
03 灾备与高可用性
灾备和高可用性是保证系统稳定运行的关键。建立多地数据中心,确保在某个节点出现问题时,可以迅速切换到其他节点。定期进行数据备份,并制定详细的恢复计划,确保在系统出现故障时,能够快速恢复数据和服务。
小贴士:别等到出了问题才想起灾备,平时就要做好准备。
定期演练灾备方案,确保团队成员都清楚各自的职责。这样一旦真的出现问题,大家才能有条不紊地应对。
04 标准化与合规
最后谈谈标准化和合规。遵循行业标准和规范,比如ISO/IEC 27001信息安全管理体系认证,确保系统的安全性和合规性。内部流程也很重要,包括代码审查、变更管理、应急预案等,这些都是保障系统稳定性的基础。
小贴士:拿一些权威认证,比如HCIE云计算,不仅能提升你的技术水平,还能让你在职场上更有竞争力。这些认证不仅是对你能力的认可,也是你在项目中实施最佳实践的保障。
关于这块,我也算是有些经验,如果你想聊聊云计算,或者关于未来的职场方向,欢迎畅聊。
最后说一下,随着经济发展,未来各种工程项目、科技创新项目以及消费升级相关项目可能会有更大市场。
特别是在云计算、大数据分析等领域,需求量将会大幅增加。
建议网工们多多观察行业趋势,同时提升自己在云计算和网络工程方面的技能,让自己在未来的市场竞争中占据优势。
原创:老杨丨11年资深网络工程师,更多网工提升干货,请关注公众号:网络工程师俱乐部