定制是关键!
生成式人工智能对企业最有影响力的应用之一是创建自然语言界面,这些界面经过定制,可以使用特定领域和用例数据来提供更好、更准确的响应。这意味着回答有关特定领域的问题,例如银行、法律和医疗领域。
我们经常谈论实现这一目标的两种方法:
- 检索增强生成 (RAG):将这些文档存储在向量数据库中,并在查询时根据它们与问题的语义相似性检索文档,然后将它们用作 LLM 的上下文。
- 监督微调 (SFT):根据代表特定领域知识的一组提示和响应来训练现有的基础模型。
虽然大多数尝试使用 RAG 的组织都希望利用其内部知识库来扩展 LLM 的知识,但许多组织如果不进行重大优化就无法实现预期结果。同样,整理足够大且高质量的数据集以进行微调也是一项挑战。这两种方法都有局限性:微调将模型限制在其训练数据中,使其容易受到近似和幻觉的影响,而 RAG 为模型奠定了基础,但仅根据文档与查询的语义接近度来检索文档——这可能不相关,并且可能导致推理不充分的答案。
参考链接:
微软 Azure OpenAI 试用申请

RAFT 来救援!

我们可以结合使用 RAG或微调,而不是只选择其中一种!将 RAG 视为一场开卷考试:模型查找相关文档来生成答案。微调就像一场闭卷考试:模型依赖于预先训练的知识。就像在考试中一样,最好的结果来自于学习和随手记笔记。
检索感知微调 (RAFT) 是一种强大的技术,可用于为特定领域的开放式设置(例如域内 RAG)准备微调数据。它改变了语言模型的格局,结合了 RAG 和微调的最佳部分。RAFT 通过提高模型理解和使用特定领域知识的能力,帮助模型针对特定领域进行量身定制。它是 RAG 和特定领域的 SFT 之间的最佳结合点。
它是如何工作的?
RAFT 分为三个步骤:
- 准备数据集来教模型如何回答有关您的领域的问题。
- 使用准备好的数据集对模型进行微调
- 评估新的、定制的、领域适应模型的质量
RAFT 的关键在于训练数据生成,其中每个数据点都包含一个问题 (Q)、一组文档 (Dk) 和一个思路链式答案 (A)。文档分为包含答案的 Oracle 文档 (Do) 和不包含答案的干扰文档 (Di)。微调教会模型区分这些文档,从而生成一个自定义模型,该模型的表现优于仅使用 RAG 或微调的原始模型。我们使用 GPT-4o 生成训练数据并微调 GPT-4o mini,从而根据您的用例量身定制经济高效、速度更快的模型。这种称为蒸馏的技术使用 GPT-4o 作为教师模型,使用 4o-mini 作为学生模型。
在本博客的下一部分中,我们将开始实践。如果您想自己跟进,或查看参考代码,请查看https://aka.ms/aoai-raft-workshop。我们将为银行用例创建一个领域适配模型,该模型能够回答有关银行在线工具和账户的问题。
笔记本 1- 生成 RAFT 训练数据
首先收集特定领域的文档;在我们的示例中,这些是银行文档的 PDF。为了生成我们的训练数据,我们将 PDFS 转换为 markdown 文本格式。该文档为 PDF 格式,包含许多表格和图表,我们将使用 GPT-4o 将页面内容转换为 markdown。我们使用 Azure OpenAI GPT 4o 将所有这些信息提取到 Markdown 文件中,以用于下游处理。然后,我们使用 GPT-4o(我们的教师模型)生成合成的“问题-文档-答案”三元组,包括“黄金文档”(高度相关)和“干扰项”(误导)的示例。这将确保模型学会区分相关信息和不相关信息。RAFT利用思维链 (CoT) 过程,通过集成 CoT RAFT 过程提高了模型提取信息和执行逻辑推理的能力。这种方法有助于防止过度拟合并增强训练鲁棒性,使其对于需要详细和结构化思维的任务特别有效
然后,我们将这些数据格式化以进行微调,将其分为训练集、验证集和测试集。验证集用于训练,测试集用于最后测量性能。
笔记本2-RAFT微调
现在是时候教我们的学生了!准备好训练和验证数据后,下一步是将这些数据上传到 Azure OpenAI 并创建微调作业。这非常简单:在 AI Studio 中,选择您的模型、上传您的训练和验证数据以及设置您的训练参数只需点击几下即可。我们将选择 4o-mini 作为我们的学生模型进行训练。 在实验室中,我们将向您展示如何使用 SDK 上传和触发微调作业。UI 使其成为一种简单的实验方式,而 SDK 方法是生产化和启用 llmops 策略以在生产中部署的首选方式。
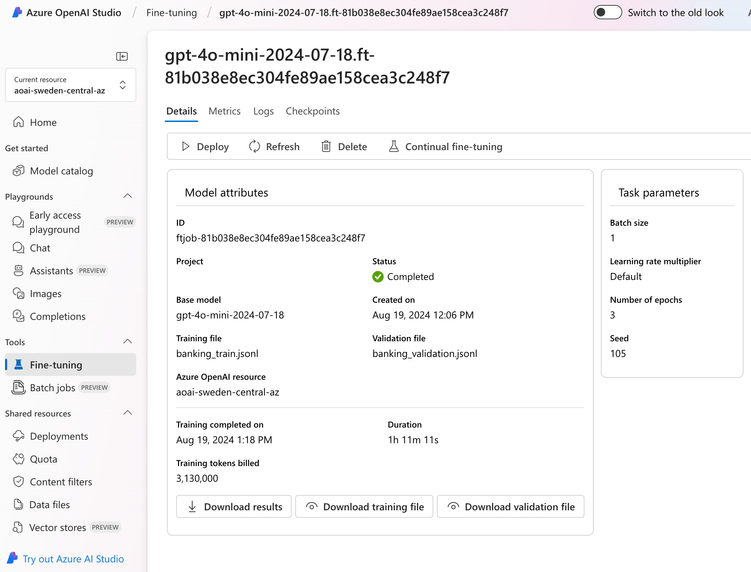
一旦微调作业开始运行,我们就可以监控其进度,并在完成后在 Azure OpenAI Studio 中分析微调后的模型。最后,我们使用微调后的模型创建一个新的部署,准备用于我们的专业领域任务。
笔记本 3 - 我们的 RAFT 模型真的比基础模型更好吗?让我们检查一下!
您可以首先查看 AI Studio 返回的内置指标,显示损失和准确度。我们希望看到准确度提高,而损失下降:
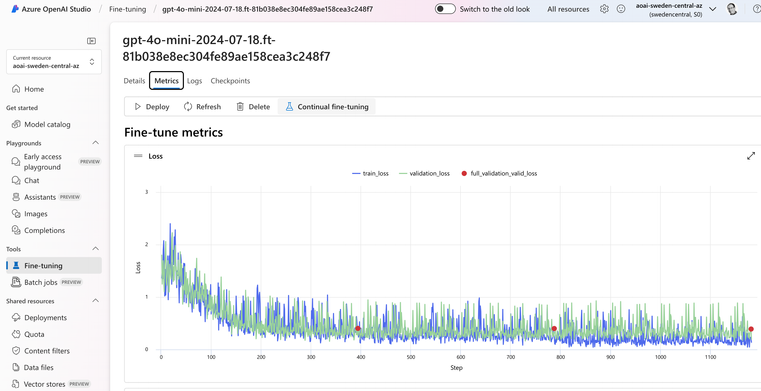
但是,我们可以做更多的事情来衡量模型的质量。还记得我们一开始的测试数据集吗?这就是我们准备它的原因!
虽然有很多评估选项,包括 AI Studio 评估,但在我们的示例中,我们使用开源库 RAGAS,它使用答案相关性、忠实度、答案相似性和答案正确性等指标来评估 RAG 管道。这些指标要么依靠 LLM 作为评判者,要么依靠嵌入模型来评估生成答案的质量和准确性。
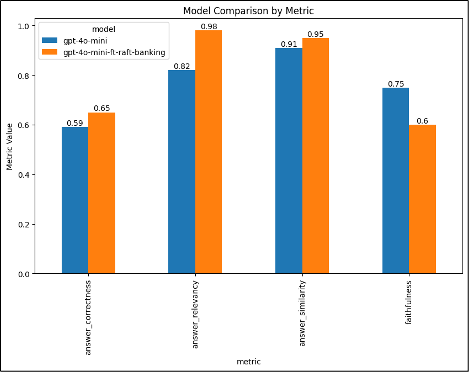
gpt4o-mini 与 gpt4o-mini-raft 对比
我们可以通过调整训练参数和/或生成额外的训练数据来进一步改善模型指标。