当AI遇上“乔丹打篮球”,真相竟然藏在动画里?
想象一下,你向一位AI大模型轻声询问:“迈克尔・乔丹从事的体育运动是……”几乎在瞬间,它就自信满满地回答:“篮球!”
这一刻,你是否曾好奇,这看似无所不知的AI,是如何在它那浩瀚的“大脑”里存储并检索这些琐碎却精准的事实的?
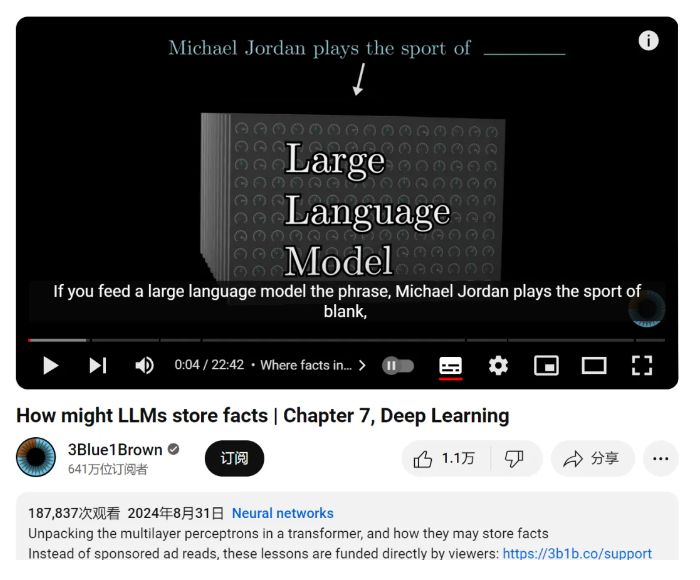
最近,科技界的热门话题再次被点燃,3Blue1Brown的《深度学习》课程第7课以一场生动的动画盛宴,为我们揭开了LLM(大型语言模型)存储事实的神秘面纱。
这次,我们不仅要看懂AI的“记忆宫殿”,还要一起探索“乔丹打篮球”背后的秘密。
LLM的记忆迷宫:事实与向量的奇幻之旅
在AI的世界里,没有真正的书本和笔记本,但它却拥有一种不可思议的能力——将海量的知识编码成高维向量,存储于它那由亿万个参数构成的复杂网络中。

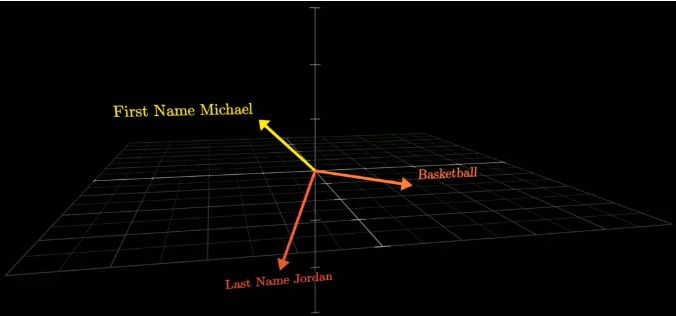
想象一下,当我们输入“迈克尔・乔丹”时,AI其实是在它的“记忆迷宫”里寻找与这个名字相关联的所有线索。
这些线索,就像是迷宫中的指路牌,指引着AI走向正确的答案——“篮球”。
3Blue1Brown的动画,就像一位耐心的导游,引领我们穿梭于这个由Transformer和MLP(多层感知器)构建的迷宫中。
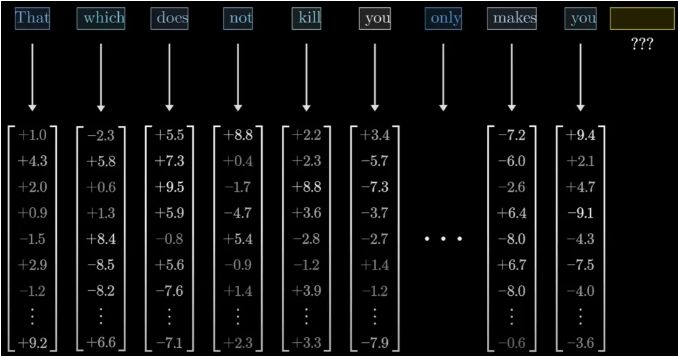
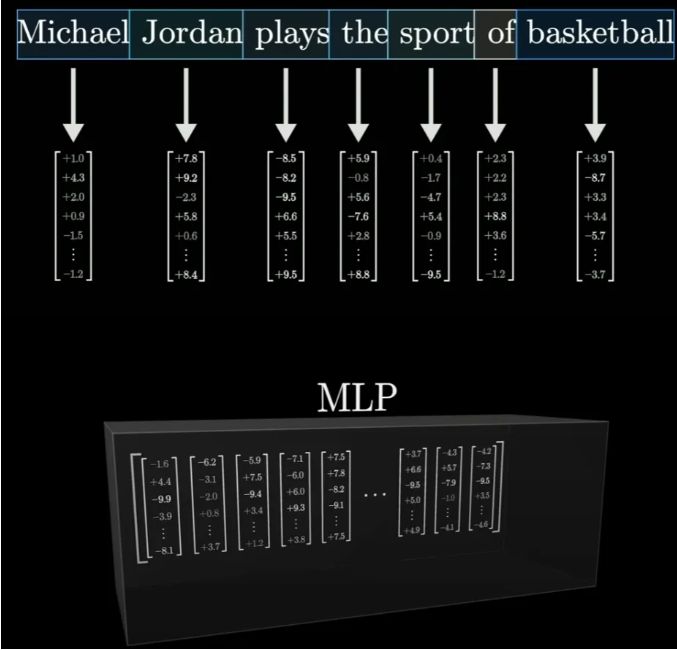
特别是MLP,它就像是一个个精密的“知识过滤器”,通过一系列复杂的运算,将输入的文本向量转化为包含丰富信息的输出向量。

在这个过程中,“乔丹打篮球”这一事实,被巧妙地嵌入到了网络的某个角落,等待着被唤醒。
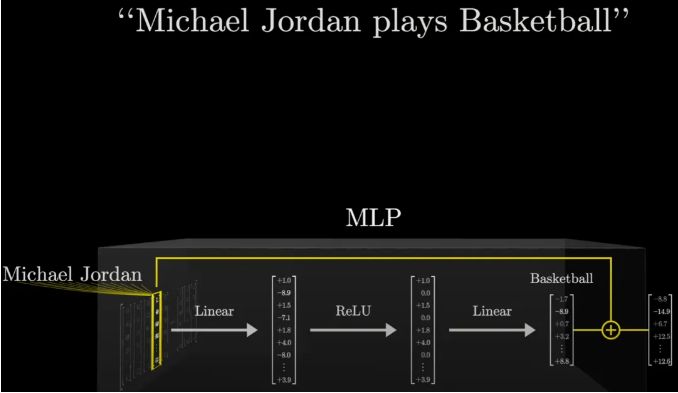
MLP的内部探秘:从“姓名”到“运动”的神奇转变
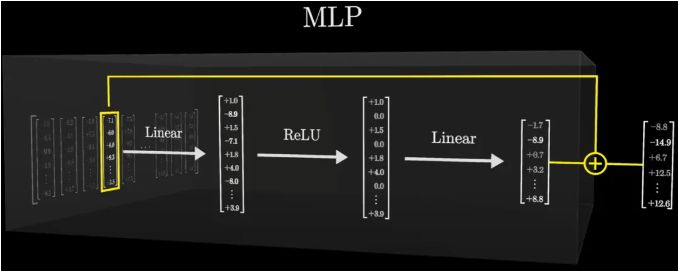
走进MLP的内部,我们仿佛进入了一个由数字和矩阵编织的奇幻世界。在这里,每一个向量都承载着特定的信息,

它们通过线性投射、ReLU激活等步骤,不断地变换着形态,最终汇聚成指向正确答案的“光束”。
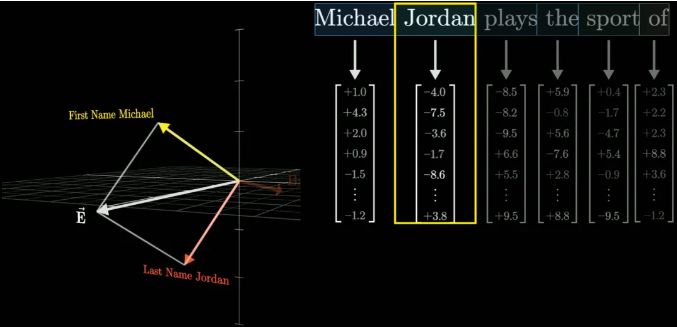
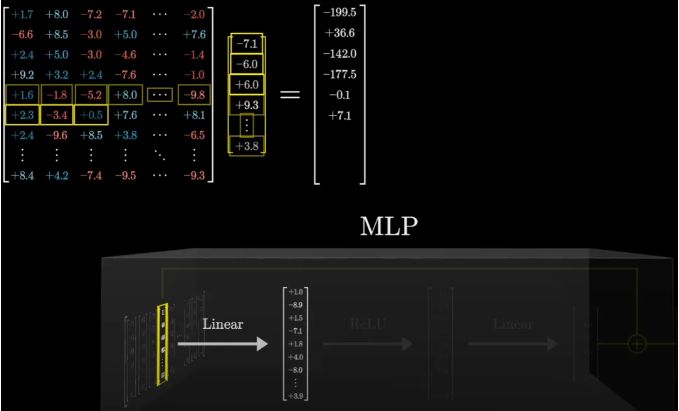
以“乔丹打篮球”为例,当输入“Michael Jordan”时,MLP会先对这个文本向量进行一系列的线性变换,就像是给它穿上了一层又一层的“知识外衣”。
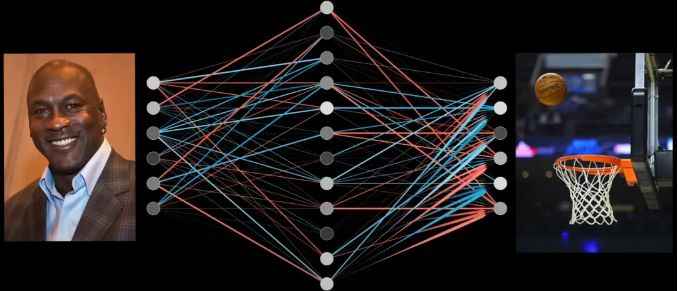
这些外衣上,布满了与“Michael”、“Jordan”以及可能与之相关的各种概念相连接的线索。接着,通过ReLU函数的筛选,
那些与“全名”不匹配的线索被剔除,只剩下最纯净、最相关的信息。最后,在另一个线性变换的作用下,这些信息被整合成指向“Basketball”的明确指示。
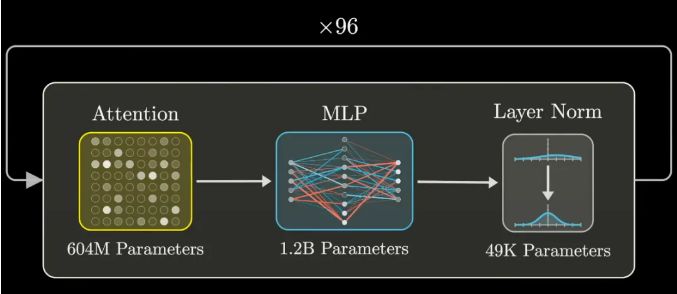
GPT-3的参数盛宴:1750亿个数字的狂欢
提到GPT-3,不得不提的就是它那惊人的1750亿个参数。这些参数,就像是构成AI“记忆宫殿”的砖石,
.
每一块都承载着特定的信息或功能。那么,这些参数究竟是如何分布和工作的呢?
原来,在GPT-3的架构中,MLP占据了参数总量的三分之二以上。每个MLP都包含多个线性变换步骤,每个步骤都需要大量的参数来支持。
以嵌入空间为例,其大小决定了矩阵的维度,进而决定了参数的数量。而GPT-3中,嵌入空间的大小达到了惊人的12288维,这仅仅是开始。
随着向量的不断传递和变换,参数的数量呈指数级增长,最终汇聚成了那个令人咋舌的1750亿。
从“乔丹打篮球”到AI的未来
通过3Blue1Brown的这场动画盛宴,我们不仅揭开了LLM存储事实的神秘面纱,还深入到了MLP的内部,见证了从“姓名”到“运动”的神奇转变。
更重要的是,我们意识到了AI背后那庞大而复杂的参数网络,正是这些看似冰冷的数字,构建了我们与AI之间沟通的桥梁。
然而,AI的旅程才刚刚开始。随着技术的不断进步,我们有理由相信,未来的AI将更加智能、更加人性化。
它们将不仅仅能够回答“乔丹打篮球”这样的简单问题,更能在医疗、教育、科研等领域发挥巨大的作用,成为我们生活中不可或缺的一部分。
而这一切的起点,就藏在那一个个生动有趣的动画和复杂的参数之中。让我们共同期待AI带来的无限可能吧!