大模型训练技术:使用QLM提升Qwen2-7B 128k训练效率3.4倍
原创
一、引言
自Transformer架构问世以来,大模型领域的进展如火如荼,短短几年内,模型参数规模已攀升至天文数字,轻松跨过万亿门槛。面对如此庞然大物,传统的单机单GPU训练方式显然力不从心。因此,单机多GPU、多机多GPU的分布式训练方案应运而生,成为驾驭超大规模模型的必要手段。然而,这一转变并非坦途,各种挑战接踵而至,比如:高昂的显存需求、漫长的训练周期以及对模型吞吐量的苛求。
为了攻克这些难关,一系列旨在提升效率的并行计算策略、显存优化技巧被引入分布式训练流程中,共同编织出一张覆盖广阔的技术网。智能工程部结合集群算力调度,在充分考量任务特性和硬件环境的基础上,融合并行优化技术,精心调整参数配置,以期实现训练效率与资源利用率的双重飞跃。
本文将简单介绍这些技术在分布式训练中的作用,并结合实际案例,展示如何利用这些技术提升大模型训练和微调的效率。
二、相关技术原理
2.1 并行技术
随着大模型训练性能的要求,各种并行技术应用于分布式训练,主要有:
1、数据并行(Data Parallelism , DP):将训练数据分成多个批次,每个批次分配到不同的设备进行训练。每个设备都有一份完整的模型,并在本地计算损失和梯度。然后,通过同步所有设备的梯度来更新模型参数。
2、流水线并行(Pipeline Parallelism , PP):将模型按层分割成多个阶段,每个阶段由不同的设备负责。各设备在处理一个微批次时,可以并行处理其他微批次,从而提高设备利用率,减少等待时间。
3、张量并行(Tensor Parallelism , TP):将模型中的张量切分成更小的块,并分配到不同的计算节点。每个节点只计算张量的一部分,节点间需要进行通信以合并结果。
4、序列并行(Sequence Parallelism , SP):主要用于长序列数据的训练,将长序列切分成多个子序列,同时在不同设备上处理这些子序列。
5、上下文并行(Context Parallelism , CP):可以看成是增强版的SP,是对所有的输入和所有的输出激活在序列维度上进行切分,分别在不同的设备上进行计算,可以有效提升长上下文依赖任务的训练效率。
下面将详细介绍各种并行技术的原理及特点。
2.1.1 数据并行

图2.1 数据并行示意图
数据并行在每个worker上复制一份模型,并将数据集在多个worker之间分割;每个worker接收不同批次的数据,并执行前向传播,反向时worker定期汇总它们的梯度,以确保所有worker看到一个一致的权重版本。通过这种方式可以有效提高模型的训练速度。
2.1.2 模型并行
根据拆分方式的不同,模型并行分为流水线并行和张量并行。
2.1.2.1 流水线并行
流水线并行是模型的层间切分[1],把模型的不同层划分为不同的stage,放置在不同的worker上,如图2.2所示,前面几层放在一个worker上,后面几层放在另一个worker上。每部分计算完成后,将数据传递到下个stage,直到整个模型计算完成。
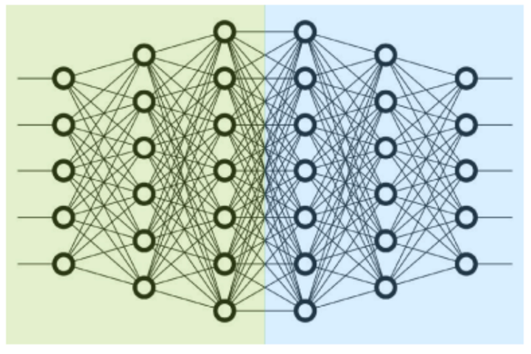 图2.2 层间切分示意图
图2.2 层间切分示意图
但是这种划分方式在训练时会产生大量的时间气泡,如图2.3所示,由于前一个worker未完成训练时后一个worker一直在等待,这极大的浪费了GPU资源。

图2.3 朴素流水线示意图
针对这种F-then-B(Forward then Backward)方案,Megatron-LM使用了一种1F1B(One Forward pass followed by One Backward pass)的策略[2],如图2.4所示,将一个批次的训练数据划分出多个微批,每个微批的数据训练完后立刻传递给下个worker,当前worker立刻开始下个微批的训练,通过这种方式,将气泡时间缩短,提高GPU利用率,若再使用交错调度,可进一步减少气泡
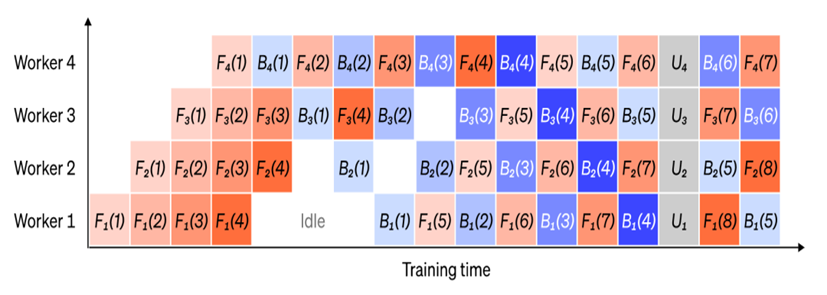
图2.4 1F1B流水线示意图
2.1.2.2 张量并行
张量并行是模型的层内切分,如图2.5所示,其主要是针对矩阵运算进行提速。通过合理的方式将输入矩阵 和参数矩阵 进行分块计算,依据切分矩阵的方式可以分为行并行和列并行。
 图2.5 层内切分示意图
图2.5 层内切分示意图
1、行并行
如图2.6所示,若将A按行切分为A1和A2 ,则 需按列切分为X1和 X2,即:
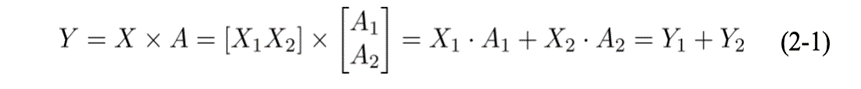
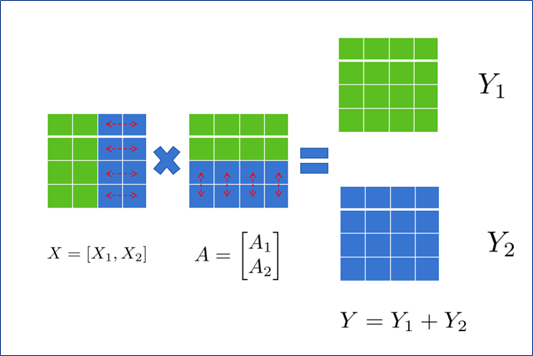
图2.6 矩阵按行切分运算示意图
通过此方式将矩阵分块,分别放置在两张卡上计算。计算完成后,通过All-Reduce获取其他卡上的计算结果,得到最终的Y。
从前反向的角度来看行并行的过程, f算子前向时会将X切分为X1 和 X2 ,分别放在不同的GPU上,在反向时对回传的梯度通过All-Gather进行拼接;f算子前向过程会通过All-Reduce对结果进行累加,在反向时会分别求梯度。
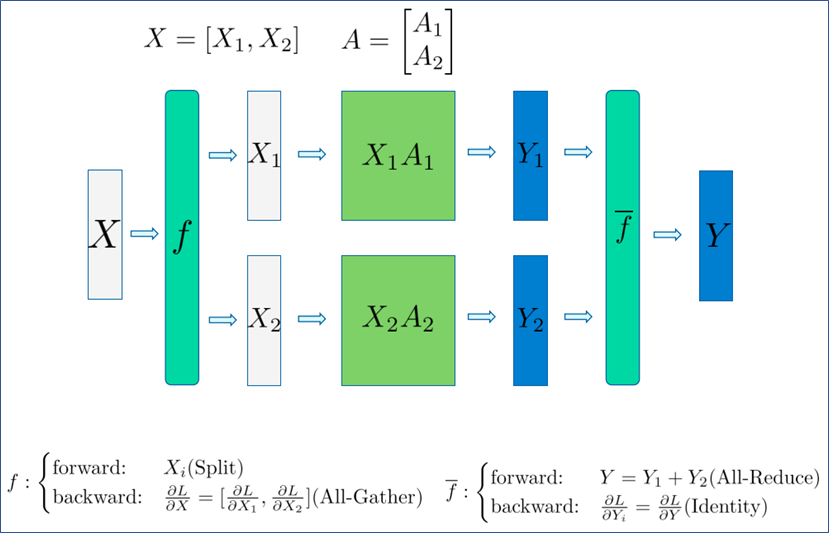
图2.7 行并行前反向流程示意图
2、列并行
如图2.8所示, 若将A 按列切分为A1 和A2, X则无需切分,即:
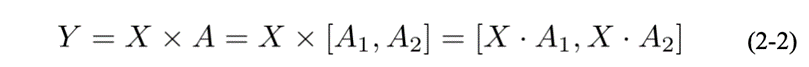
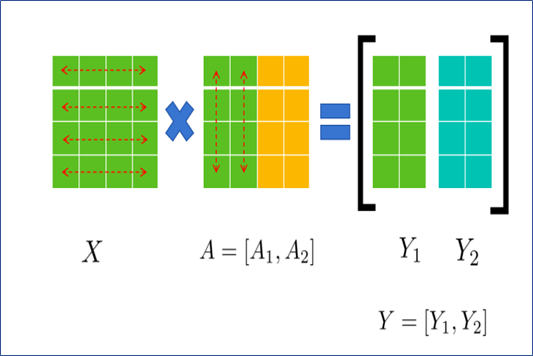
图2.8 矩阵按列切分运算示意图
从前反向的角度来看列并行的过程, f算子前向时会将X分配到两张卡上,在反向时会对回传的梯度通过All-Reduce进行累加;f算子前向过程会通过All-Gather对结果进行拼接,在反向时会将梯度矩阵切分为两部分,然后回传。
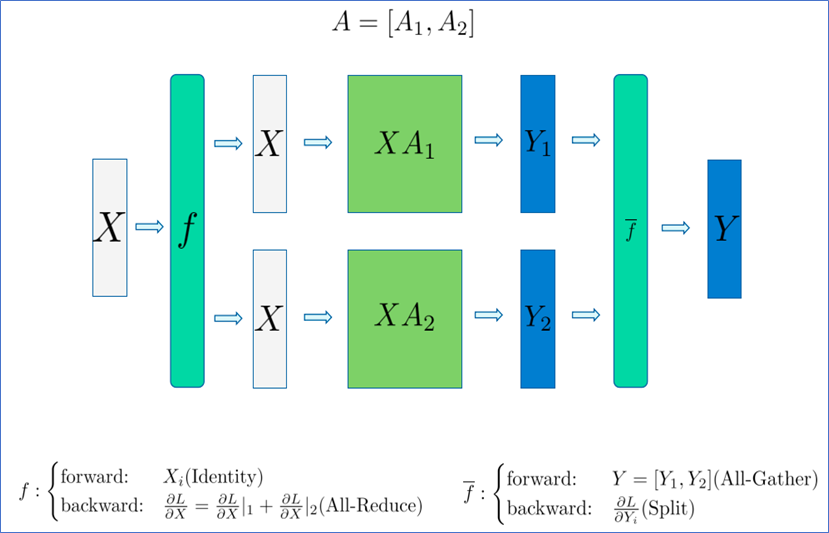
图2.9 列并行前反向流程示意图
3、Transformer中的张量并行
Transformer结构是由一个Attention模块和MLP模块组成。如图2.10所示,Attention模块由SelfAttention层加上Dropout组成;MLP模块有两个GEMM,第一个GEMM把维度从H变为4H,第二个GEMM把维度从4H变回H,中间采用了GeLU激活函数;并且每层的连接上也使用了残差连接。
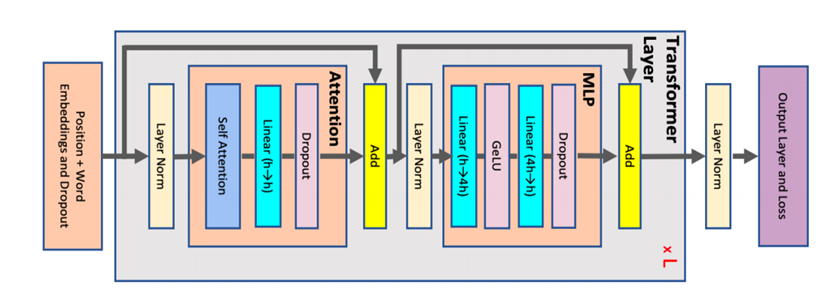
图2.10 Transformer结构示意图
针对Attention模块,可以利用多头注意操作中固有的并行性,对自注意块进行分割。查询(Query , Q)、键(Key , K)和值(Value , V)矩阵以列并行的方式进行优化。同时输出线性层可以直接操作注意力层的输出。
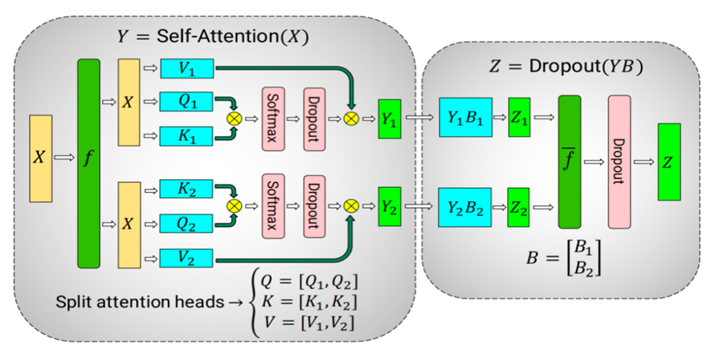
图2.11 Self-Attention
针对MLP模块,MLP模块中的第一个GEMM,对应的操作可以表示为Y=GeLU(X A) 。若将A按行切分的话,则
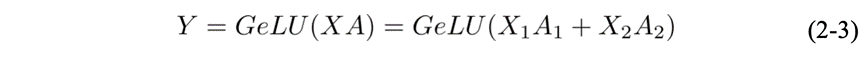
但由于GeLU是一个非线性函数,故
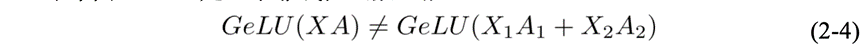
所以要采用行并行的话就必须在GeLU操作前加一个All-Reduce同步点,让不同的GPU之间交换信息。另一种并行方式是列并行,若采取列并行的话,则GeLU函数可以独立应用于每个GEMM的输出,对应
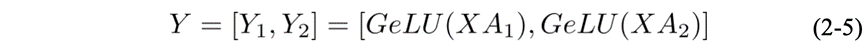
这种方式不需要同步点,因此,以列并行的方式划分第一个GEMM,并沿着它的行分割第二个GEMM,可直接将GeLU的输出作为下一个的输入,不需要任何通信,最终整体的并行方式如图2.12所示:
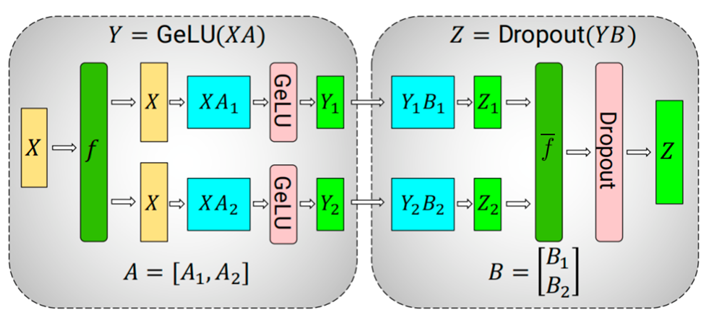
图2.12 MLP
2.1.3 序列并行
序列并行采用了对序列维度进行均匀划分的策略,以此减少模型显存占用。Megatron-LM在张量并行的基础上,对 Transformer 层中的 LayerNorm 和 Dropout 操作的输入按照序列长度维度进行分割[3] ,从而使得每个设备只需处理部分序列的 Dropout 和 LayerNorm 操作。
当然,进行额外的分割会导致通信模式的改变。在Transformer层中,TP的通信模式包括前向中的两个All-Reduce以及反向中的两个All-Reduce。然而,由于SP对序列维度进行了划分,传统的All-Reduce已不再适用。为了汇集各个设备上SP所产生的结果,适应SP和TP之间的数据传递需求,需引入All-Gather;而为了将TP生成的结果传递到序列并行层,需引入Reduce-Scatter,因此,如图2.13所示,引入 和 两算子, 表示前向时的All-Gather以及反向时的Reduce-Scatter, 表示前向时的Reduce-Scatter以及反向时的All-Gather。由于一个All-Reduce就相当于一个Reduce-Scatter和一个All-Gather,故在开启TP时再开启SP并没有增加额外的通信。反而在反向的实现上,把 Reduce-Scatter和权重梯度的计算做了重叠,进一步减少了通信所占用的时间。
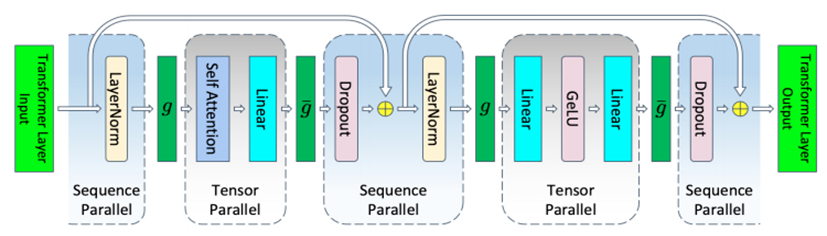
图2.13 开启TP和SP的Transformer层
2.1.4 上下文并行
上下文并行也是一种在序列维度上的并行化方案[4],针对长文本处理任务优化较好。与SP不同的是,SP只针对LayerNorm和Dropout输出的激活值在序列维度上进行切分,而CP则是对所有的input输入和所有的输出激活值在序列维度上进行切分,CP可以看成是增强版的SP。
为了减少激活显存占用,每个GPU在前向传播中仅存储一个序列块的KV,并在反向传播中再次收集KV。KV通信发生在一个GPU与其他TP组的对应GPU之间。在底层,这些All-Gather和Reduce-Scatter操作被转换为环形拓扑中的点对点通信。此外,通过使用多查询注意力或分组查询注意力来交换KV,也可以减少通信。
以图2.14的TP2-CP2的Transformer网络为例,在Attention前的是CP的通信算子,其他都是TP的通信算子。AG表示All-Gather, RS表示Reduce-Scatter, AG/RS表示前向All-Gather反向Reduce-Scatter, RS/AG表示前向Reduce-Scatter反向All-Gather。
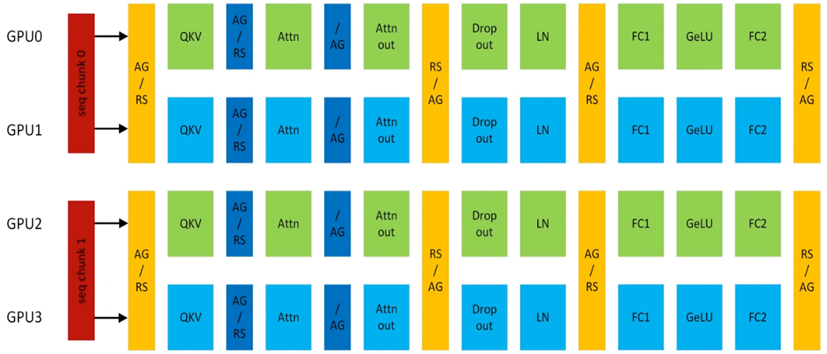
图2.14 开启TP和CP的Transformer层
2.2 显存优化
2.2.1 训练过程中的显存分析
大模型训练过程中,GPU的瓶颈往往不是其计算能力,而是显存的容量限制。占用显存的部分主要由模型权重、梯度、优化器、激活值等几部分组成。
1、模型权重
模型训练过程中,一般有fp32、fp16、bf16、int8等几种模型保存格式,fp32即用32位保存一个模型参数,int8即8位,fp16和bf16用16位保存。假设模型参数量为Ψ,训练过程中以bf16的精度保存模型,则其权重本身的显存占用约为2Ψ(Bytes)(在不加特殊说明的情况下,后面显存的单位也为Bytes)。
2、梯度
梯度数据类型通常与模型数据类型匹配。混合精度训练中,梯度类型一般为fp16。对 fp32训练,梯度占用显存大小为4Ψ,对 fp16/混精训练,梯度显存占用为2Ψ。
3、优化器
目前大模型训练中,使用较多的为Adam优化器,训练时需要动量和二阶动量,若优化器采用fp32形式保存参数,其所占显存为12Ψ。
4、激活值
在大模型训练中,Embedding层和最后的LayerNorm以及输出层占用的显存与Transformer块产生的显存相比可以忽略不计。
假设激活值的数据类型为fp16,输入长度为s,batch size为b,hidden的维度为h,attention head数量为a, 模型层数为L,则:
每一层 Transformer块的产生的激活值显存占用为:
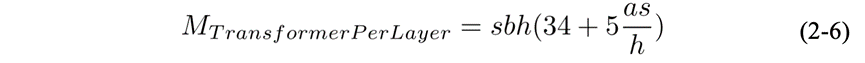
如图2.15所示,开启TP后,Transformer层中的部分模块的显存可以被分摊到不同的设备之间。不能被分摊的主要是两个LayerNorm块和两个Dropout块产生的显存,共计 。
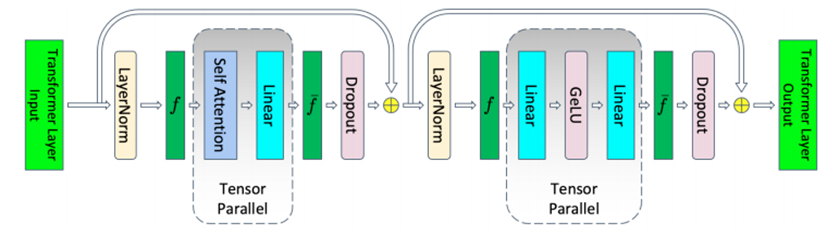
图2.15 开启TP的Transformer层
假设张量并行度为t,则每层 Transformer 的显存占用为:
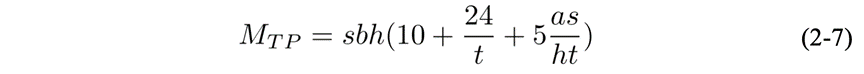
若再开启SP,Transformer 层中的 LayerNorm 和 Dropout 块也会被切分,对张量在序列维度进行切分,切分数量等于张量并行的大小。则每层激活值的显存占用为:
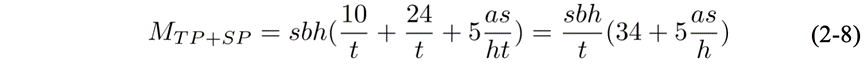 若采取流水线并行,由于第一阶段需要存储p个微批的激活值,所以不论并行大小p是多少,存储第一阶段的激活值所需的显存为:
若采取流水线并行,由于第一阶段需要存储p个微批的激活值,所以不论并行大小p是多少,存储第一阶段的激活值所需的显存为:
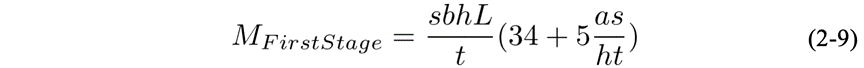
若再使用交错调度的话,总激活显存会按照(1+(p-1)/pm) 进行缩放,其中m是交错流水线的规模。
2.2.2 显存优化技术
显存优化技术主要是通过减少数据冗余,以算代存和压缩数据表示等方法来降低上述部分的显存占用,下面介绍两种常用的节省显存的方法。
1、重计算
激活重计算技术,其仅存储每层的输入激活值并在需要时重新计算其他激活值。
如在TP的基础上选择重计算,则显存占用为
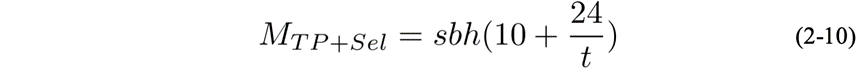
若再开启SP,则显存为
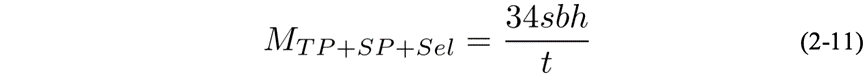
若全量重计算的话,则显存为
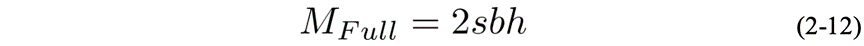
虽然全量重计算可以极大幅度的减少激活值的显存占用,但全量重计算会带来30%-40%左右的计算性能损失,在训练过程中需结合实际的情况来决定使用哪种重计算方式。
2、ZeRO
ZeRO[5],全称为Zero Redundancy Optimizer, 是由DeepSpeed项目中提出的一种创新方法,旨在解决数据并行训练中常见的显存冗余问题。在传统的数据并行训练中,模型的参数、梯度以及优化器状态会在每个GPU上完整复制,造成了显存冗余。
ZeRO技术通过在不同GPU之间分配和共享这些数据,减少每个GPU的显存需求。具体而言:ZeRO提出了三种策略,分别对应着 将优化器参数分开存储、 将优化器和梯度分开存储以及 三部分参数都分开存储三种情况。具体效果可见图2.16:
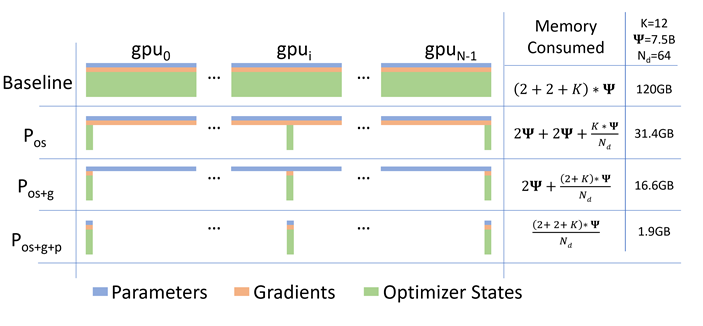
图2.16 ZeRO的三个级别
假设模型的参数Ψ=7.5B,GPU数Nd=64,优化器状态的显存乘数因子为K,对于Adam来说是K=12。对于Baseline(DP)来说,每个GPU都要保存全部的参数、梯度和优化器状态,假设使用fp16保存模型,总显存是(2+2+K)Ψ,即120GB。对于 来说,把KΨ的显存划分到Nd个GPU上,因此每个GPU上的显存为2Ψ+2Ψ+KΨ/Nd,即31.4GB。对于 来说,把KΨ+2Ψ的优化器状态和梯度划分到Nd个GPU上,每个GPU为2Ψ+(2+k)𝜓Ψ/Nd,即16.6GB。最后 把所有的都划分,因此每个GPU为(2+2+K)Ψ/Nd,即1.9GB。
与更高级别的ZeRO相比, 保留了模型参数的完全复制,避免了在计算过程中频繁的数据交换,保持了较高的计算效率,并且相比于 和 , 仅涉及优化器状态的并行化,而不涉及到模型权重和梯度的分割,实现比较简单,这使得它在很多情况下成为一种实用的选择。
三、QLM加速实战经验
QLM,全称Qihoo Language Model,是智能工程部在当前主流的大模型加速框架Megatron-LM的基础上二次开发的一体式框架,支持Huggingface与Megatron的多种模型格式转换、预训练、评测、微调、分析等能力,与TAI平台结合,可有效支持Qwen、zhinao等千卡训练,长文本微调等多种任务。
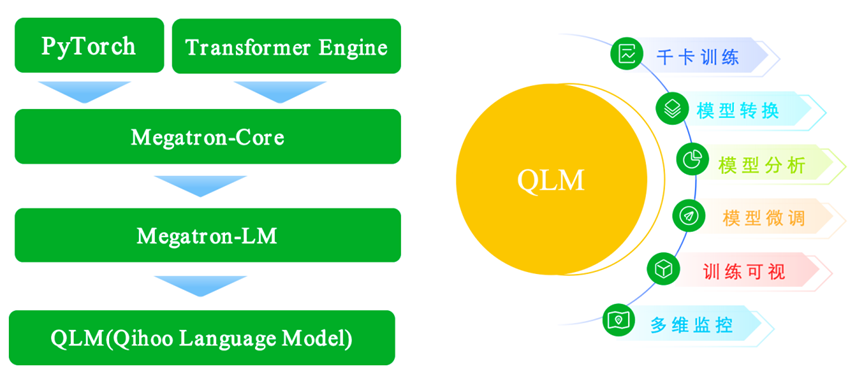
图3.1 QLM框架及功能示意图
下面展示如何通过QLM框架支持业务部门的128k长文本微调提速实践,通过利用上面各种优化提速技术,支持长文本微调速率由120s/sample至35.5s/sample,提速3.4倍。
base版本是在4台H800机器上训练的,由于资源有限,调优在4台A100上进行,H800和A100的性能如下图所示:
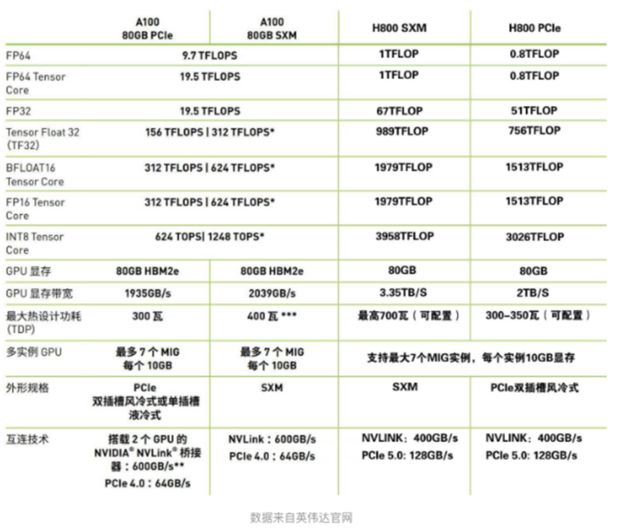
图3.2 不同GPU性能参数对比
并行提速调优过程中,首先可以尝试开启DP,将输入数据分片,提高数据处理速率。base版本是以DP1-TP4-PP1-SP-CP8的配置下达到的,base版本没有开启DP,由于总GPU数需要等于DPTPPP*CP,相应的需要减小CP数,在开启DP的同时,通过–overlap-grad-reduce --overlap-param-gather 两个参数在DP通信时做overlap,可以提高12%的性能。若要开启MP,则优先考虑TP,因为TP是在机器节点内进行通信,可以通过NVLINK进行加速,相比于PP的通信效率要高,此外,受限于模型特性,TP的最大值被固定在4,故无需调整。
由于任务上下文较长,故开启SP和CP是一个较优的选择,然而,CP的数值并非越高越佳,其最佳值需经由细致测试和综合考量确定。最终调优结果如表3.1所示:
表3.1 不同优化参数下的结果
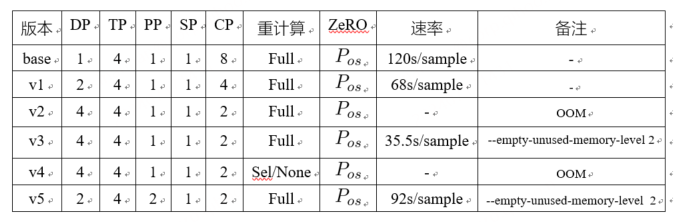
v2版本在优化过程中碰到了OOM,促使我们在v3版本中采取了激进的显存碎片清理策略,力求在每次计算周期结束后,释放那些不再需要的显存空间。尽管这一举措对训练速度产生了一定影响,但相较于v1版本的速率和v2版本的OOM问题,v3版本最终以35.5s/sample的速率实现了稳定运行,成功平衡了性能与资源利用之间的关系。
值得注意的是,v3及其之前版本均采用了全量重计算方法,这种方法会带来约30%的性能损耗。鉴于此,v4版本尝试下调了重计算的级别,以期提升效率,但不幸的是,这一调整触再次触发了OOM异常。此时还没有开启PP,v5开启了PP策略,虽然在速率上超越了base版本,但与V3版本的巅峰表现仍存在显著差距,故如图3.2所示,本次调优达到的最优效率为35.5s/sample,与base版本相比,提速3.4倍,且模型推理结果达到预期效果。
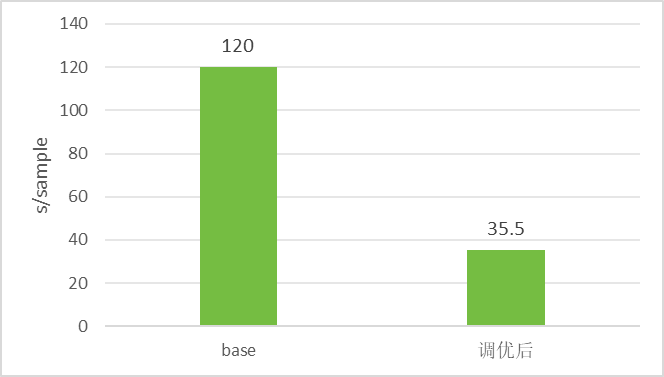
图3.2 调优前后速率对比示意图
四、总结
本文阐述了大模型分布式训练过程中并行优化技术的基本原理,分析了模型训练过程中的显存占用情况,与如何更好的节省显存,并结合实际应用场景,展示了QLM如何利用这些技术提升长文本任务训练效率的具体实践。
随着大模型的迅猛演进,未来的训练场景将不可避免地遭遇“三重壁垒”——内存墙、通信墙、计算墙,这三大瓶颈将构成严峻挑战。面对此情此景,如何精简显存占用,降低跨节点通信成本,以及提升计算效能与效率,已成为QLM团队矢志不渝的追求目标。我们正全力以赴,探索创新解决方案,旨在构建更加高效、可持续的大模型生态。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















![[ComfyUI]Flux:超美3D微观山水禅意,经典中文元素AI重现,佛陀楼阁山水画卷](https://img-blog.csdnimg.cn/direct/4a2d3a791f754642af3f0383c95ee9c7.png#pic_center)