在本文中,我们将详细了解 JVM 如何存储对象及其在内存中的表示形式。此外,我们将深入探讨性能影响以及如何利用它们来获得优势。
*此外,我们将了解如何使用-XX:+UseCompressedOops以及它如何影响应用程序的性能。此外,我们将了解UseCompressedOops*和堆大小之间的联系。
1. 对象的大小
JVM使用以下结构在内存中表示Java对象:

图 1:Java 对象布局
让我们更详细地回顾这些部分,以了解它们的用途和存储的数据。
1.1. 标记词
此部分存储对象的运行时数据。JVM 可能会在此处放置有关锁、幸存者计数、垃圾收集标记甚至哈希码的信息。 此部分的大小完全取决于 JVM 的体系结构。32 位体系结构将使用四个字节表示一个标记字,64 位体系结构将使用八个字节表示一个标记字。虽然我们无法直接更改其大小,但体系结构可能会影响应用程序的性能。
1.2. 类指针
klass [sic] 指针是指向对象类的指针。 它引用类元数据,这对很多事情都有帮助:方法调用、计算字段偏移量、内存分配、垃圾收集等。 指针本身可以接收 4 个字节或 8 个字节的信息。本节最令人兴奋的部分是我们可以使用 JVM 参数来更改它,我们将在本文后面讨论。
1.3. 数组长度
数组长度仅针对数组设置。 在任何系统上它占用四个字节。 但是,这并不意味着我们可以使用无符号整数进行索引,因为我们可以将其放入数组长度部分。每个 JVM 都可能施加其限制,尝试分配一个巨大的数组可能会导致OutOfMemoryError并显示以下消息: 请求的数组大小超出 VM 限制 。
1.4. 内部填充
内部填充是可选的,用于对齐对象头的大小。其大小取决于 JVM 架构。32 位架构使用四字节对齐;64 位架构默认使用八字节对齐。 我们可以改变此行为,但此讨论超出了本文的范围。
1.5. 实例字段
实例字段包含对象字段的值。此部分的大小完全取决于字段类型及其组成。JVM 可能会执行优化并重新排列字段的顺序。这称为字段打包。此过程旨在减少因填充而浪费的内存。
1.6. 外部填充
最后的填充确保下一个对象的正确对齐。有时,对象会对齐到正确的字节数;有时,我们需要额外的填充。我们可以利用这一知识,在不增加内存占用的情况下向类添加更多字段。
2. 物体的大小
让我们计算不同 JVM 架构上空对象和空数组的大小。我们将考虑对象的默认 8 字节对齐,但我们可以更改它。一般公式如下所示:
空对象的大小 = Mark Word + Klass Pointer + Padding
因此,一般来说,我们会得到以下结果:
| 32 位 JVM | 64 位 JVM | |
|---|---|---|
| 32 位指针 | 8 | 16 |
| 64 位指针 | -* | 16 |
对于数组,我们有一个类似的公式,其中仅包含数组的长度:
空对象的大小 = 标记字 + 类指针 + 数组的长度 + 填充
我们可以对空数组的大小进行类似的计算:
| 32 位 JVM | 64 位 JVM | |
|---|---|---|
| 32 位指针 | 16 | 16 |
| 64 位指针 | -* | 24 |
- 我们不能在 32 位 JVM 上使用 64 位指针。
3. 对象指针
JVM 将对象存储在堆中;要使用这些对象,我们应该能够通过它们的地址引用它们。如果我们有 4 GB 的内存,我们需要 8 字节地址,并希望单独寻址每个字节。
这是否意味着我们不能对较大的堆使用八字节地址? JVM 有一个优化,它限制对象的起始并默认将其对齐到八个字节。
通过对齐,地址的最后三位将始终为零。 因此,我们可以在存储地址时省略它们,这在技术上使我们能够将地址从 32 位压缩到 29 位。 较小的地址大小意味着我们可以将可寻址内存增加八倍(!):从 4 GB 增加到 32 GB:
指针压缩
| 对象起始字节数 | 32 位地址(二进制) | 29 位压缩地址 |
|---|---|---|
| 0 | 00000000000000000000000000000 000 | 00000000000000000000000000000 |
| 8 | 00000000000000000000000000001 000 | 0000000000000000000000000000001 |
| 16 | 00000000000000000000000000010 000 | 000000000000000000000000000010 |
| 24 | 00000000000000000000000000011 000 | 0000000000000000000000000000011 |
| 三十二 | 00000000000000000000000000100 000 | 000000000000000000000000000100 |
| 40 | 00000000000000000000000000101 000 | 0000000000000000000000000000101 |
| 四十八 | 00000000000000000000000000110 000 | 0000000000000000000000000000110 |
| 56 | 00000000000000000000000000111 000 | 0000000000000000000000000000111 |
| 64 | 00000000000000000000000001000 000 | 000000000000000000000000001000 |
| 72 | 00000000000000000000000001001 000 | 000000000000000000000000001001 |
当我们需要压缩后的完整地址时,我们可以向左移动一位并解压缩。但是,没有什么东西是免费的,我们将在这个操作上花费 CPU 周期:
**00000000000000000000000000101 << 3 = 00000000000000000000000000101 **000
如果我们使用的堆大于 32 GB,则 JVM 默认为地址分配 64 位。因此,我们的对象的大小将会增加。同时,由于对齐规则,64 位 JMV 上的空对象的大小不会改变。
这些知识有时可能很有用,因为我们可以在不显著增加内存消耗的情况下存储更多信息。但是,不建议依赖利用填充空间的性能优势。
4. 性能影响
我们将使用具有一百万个元素的整数 链表 :
@NotNull
private static LinkedList<Integer> createLinkedList() {
return new LinkedList<>(ThreadLocalRandom.current()
.ints(ONE_MILLION)
.boxed()
.collect(Collectors.toList()));
}
此外,我们将有一个简单的逻辑来从这个列表中过滤和计算奇数和偶数:
private static void filterList(List<Integer> integers, Blackhole blackhole) {
int even = 0;
int odd = 0;
for (final Integer integer : integers) {
if (integer % 2 == 0) {
even++;
} else {
odd++;
}
}
blackhole.consume(even);
blackhole.consume(odd);
}
4.1. 解压缩和 CPU 周期
让我们运行以下基准测试:
@Benchmark
public void filteringList(NumberFilteringState state, Blackhole blackhole) {
filterList(state.integers, blackhole);
}
此代码几乎不产生任何垃圾,因此让我们使用不同的堆大小来运行它。我们将针对 2 GB、4 GB 和 8 GB 堆运行几个测试。从技术上讲,它不会影响性能。此外,我们将使用-XX:+AlwaysPreTouch*来避免堆大小调整问题:*
** filterList() 基准的性能分析**
| 堆大小 | 压缩指针 (ops/s) | 未压缩指针 (ops/s) |
|---|---|---|
| 2 GB | 193.990 | 241.983 |
| 4GB | 194.502 | 242.473 |
| 8 GB | 194.555 | 242.344 |
压缩指针有利于减小对象大小,但同时需要额外的 CPU 周期来解压缩。由于我们的基准测试所做的唯一一件事就是取消引用LinkedList 中的节点 ,因此使用压缩指针时开销较大。
因此,此类应用程序的性能可能会受到严重影响。在我们的基准测试中,差异非常显著:≈194 ops/s 对 ≈242 ops/s。
问题是,当堆大小超过 4 GB 时,JVM 会自动打开它们,这是 Java 6 的默认行为。**有时,我们可以通过添加更多内存来使应用程序变慢。 **
这就是为什么我们需要更加关注堆大小管理。我们应该平衡应用程序以分配“恰到好处”的内存量。不会产生太多垃圾的应用程序在较小的堆大小上可以表现得更好。
对于较大的堆,我们不使用压缩,这样就跳过了压缩步骤。同时,由于标头占用了 8 个字节,因此内存占用也更高。
4.2. 内存占用
让我们检查另一个具有更高对象创建率的基准:
** creatingList() 基准的性能分析**
| 堆大小 | 压缩指针 (ops/s) | 未压缩指针 (ops/s) |
|---|---|---|
| 2 GB | 26.860 | 26.379 |
| 4GB | 28.199 | 26.784 |
| 8 GB | 28.236 | 27.002 |
这里,我们得到了相反的结果。使用压缩指针的基准测试性能更高。原因是对象占用的空间更少。
4.3. 总体表现
让我们结合这两个基准来获得更合理的结果,因为应用程序通常会创建并迭代对象:
@Benchmark
public void creatingAndFilteringList(NumberFilteringState state, Blackhole blackhole) {
List<Integer> linkedList = createLinkedList();
filterList(linkedList, blackhole);
blackhole.consume(linkedList);
}
该基准测试将结合我们从较小的标头中获得的内存消耗优势和解压缩所浪费的周期:
** creatingAndFilteringList() 基准的性能分析**
| 堆大小 | 压缩指针 (ops/s) | 未压缩指针 (ops/s) |
|---|---|---|
| 2 GB | 25.191 | 24.949 |
| 4GB | 25.082 | 23.610 |
| 8 GB | 25.174 | 22.874 |
在此设置中,压缩指针和非压缩指针的行为类似。但总体而言,压缩指针具有更好的性能。对于任何应用程序,结果可能都不相同。性能影响完全取决于访问模式、对象创建率和其他因素。
5.垃圾收集
让我们检查一下垃圾收集器在之前的基准测试中的行为。我们将考虑在 8 GB 堆上运行的示例的结果。为了分析行为,我们将使用来自GCeasy的报告。
5.1. 创建率低
首先,让我们检查一下过滤基准。这个基准没有产生任何垃圾,报告也相当无聊。该应用程序在所有测试的堆大小上的行为都类似。
唯一的区别是峰值堆使用量。它主要基于初始List的大小。**因此,使用未压缩指针的版本会消耗更多内存。 **
检查报告和视觉效果没有多大意义。基准测试不会产生任何垃圾,我们使用*-Xmx、-Xms和-XX:+AlwaysPreTouch*预初始化了堆,因此垃圾收集日志中唯一的一行是以下内容:
[0.005秒][info][gc]使用G1
5.2. 高创建率
在creatingList基准测试中,我们发现创建率存在显著差异。使用压缩指针时,我们将得到以下结果:
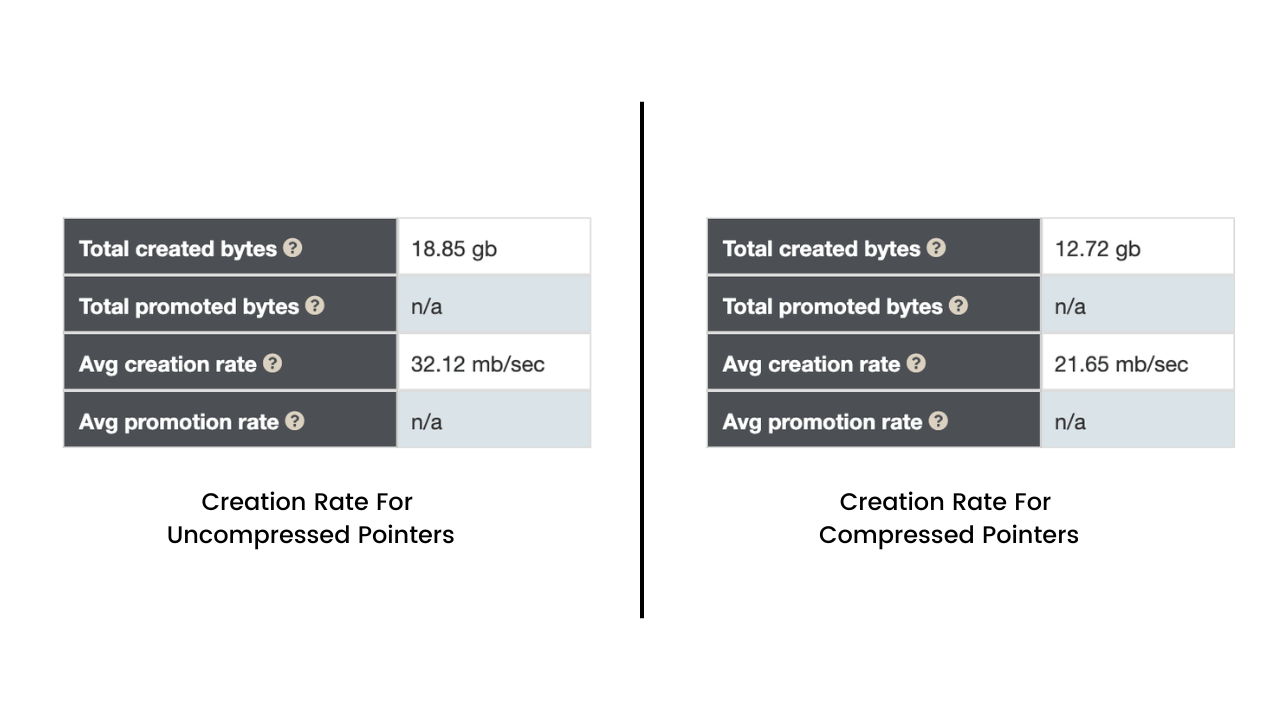
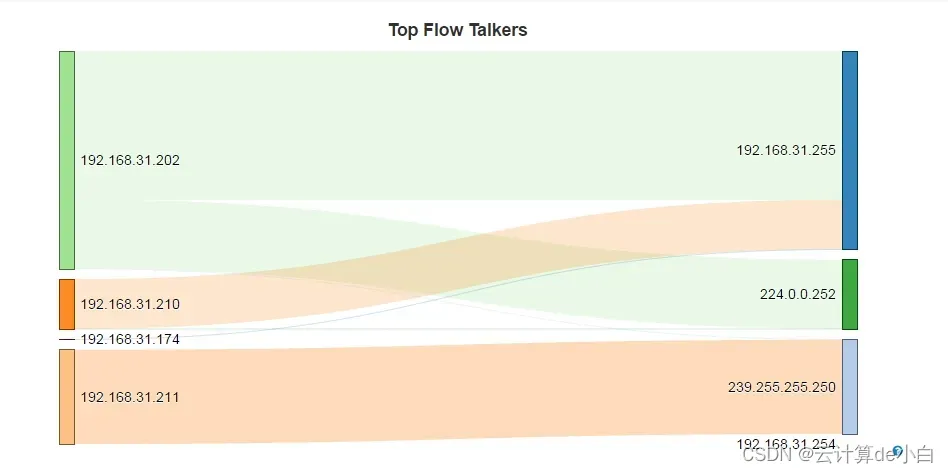
图 2:未压缩指针与压缩指针的创建率
我们拥有更大的对象,并且创建率更高。我们可以通过检查垃圾收集活动来解释这一点。在未压缩指针的情况下,我们将拥有更多的垃圾收集周期:
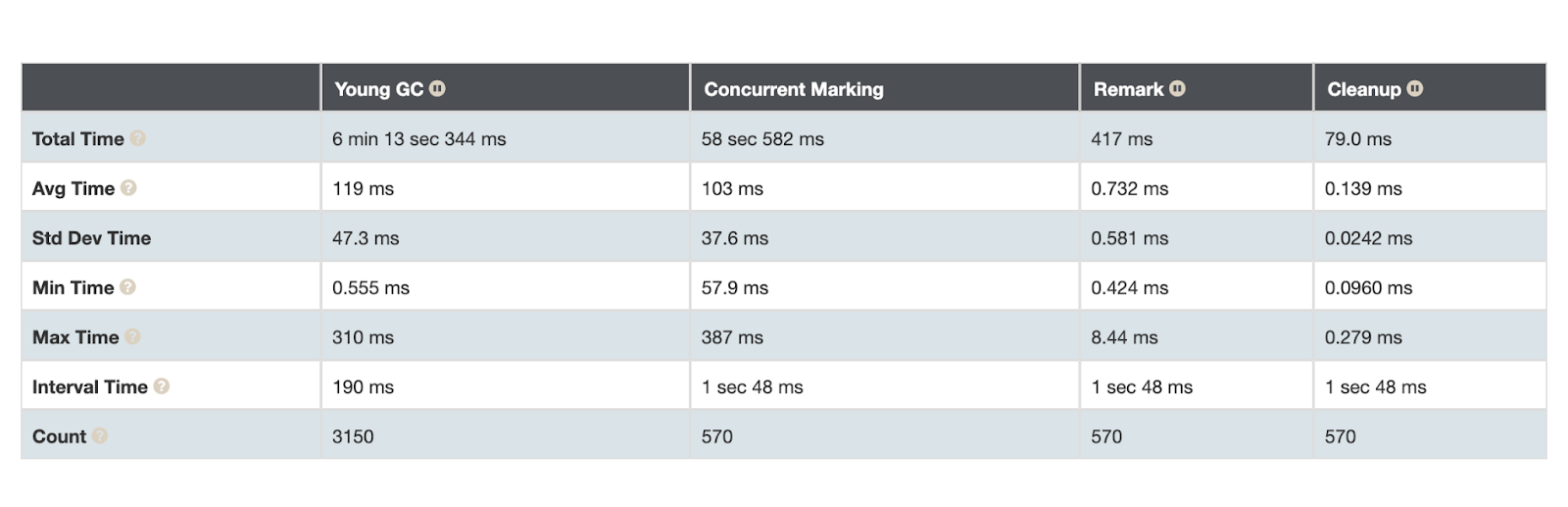
图 3:未压缩指针的垃圾收集活动
虽然压缩指针需要更少的循环:

图 4:压缩指针的垃圾收集活动
更少的循环是合理的,因为我们需要更小的对象来填充堆。因此,使用压缩指针,我们的性能会略有提高,垃圾收集周期也会更快:
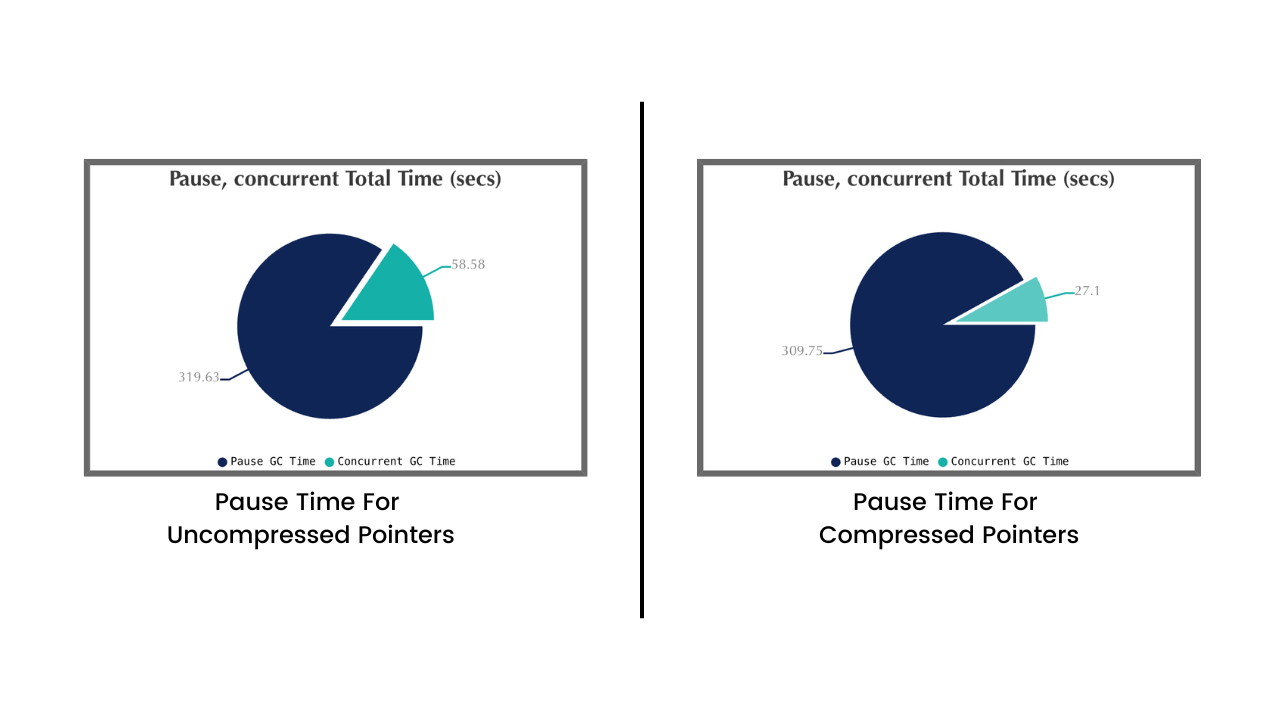
图 5:未压缩指针与压缩指针的暂停时间
结论
使用压缩对象指针可以帮助提高应用程序的性能,但同时,它可能会使其运行速度变慢,有时甚至不会影响它。一切都取决于应用程序和我们的目标。
要确定 -XX:UseCompressedOops 的实际效果 , 我们应该分析应用程序并查看它在不同情况下的行为。了解 JVM 的内部结构可以提供更多见解,并防止使用不会产生任何影响的 JVM 标志。同时,始终可以使用yCrash检查假设并确保理论优化为我们带来真正的好处。
原文链接
![[大语言模型-论文精读] 阿里巴巴-通过多阶段对比学习实现通用文本嵌入](https://i-blog.csdnimg.cn/direct/d47da0aeb15b4941b42c4d7efdd92fb7.png)