点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
作者简介
管海粟,华中科技大学本科生在读。
主要研究方向为图像生成、图像分割、多模态大模型。获得国家奖学金、校三好学生奖学金、华中科技大学本科特优生等荣誉。发表ACL 2024 Best Paper一篇,一篇scientific Data,申请4项发明专利。获得多项学科竞赛一等奖。
概述
甲骨文(OBS)起源于大约3000年前的中国商朝,是中国语言史的基石,其出现时间早于许多现有的书写体系。尽管已发现数以万计的甲骨文铭文,但大量甲骨文尚未被破译,这使得这种古老的语言笼罩着一层神秘的面纱。近年来人工智能技术快速兴起,可能为甲骨文的解读开辟新天地。传统的自然语言处理方法依赖于大量文本语料库,而古代历史语言往往缺乏这种优势。现有的人工智能在甲骨文领域的研究主要聚焦于对已破译甲骨文的识别和检测上面,但是对于未破译甲骨文的研究却依旧存在挑战。因此,本报告介绍了我们推出的甲骨文破译模型OBSD(Oracle Bone Script Decipher)。项目利用扩散模型,模拟汉字演变的过程,将甲骨文文字图像转化为现代汉字图像,通过产生未破译甲骨文的现代汉字来反推其含义,从而辅助破译甲骨文。此外,OBSD还提出局部结构采样(Localized Structural Sampling)和零样本细化(Zero-shot Refinement)两个方法提高图像生成质量。OBSD在与其他图像到图像转换模型的对比中取得了更好的性能,并在未破译的甲骨文文字上面进行了大量的定性实验,有望为甲骨文的破译提供字形或者图像上的线索。
论文地址:https://arxiv.org/pdf/2406.00684
代码链接:https://github.com/guanhaisu/OBSD
Research Background
Background Information
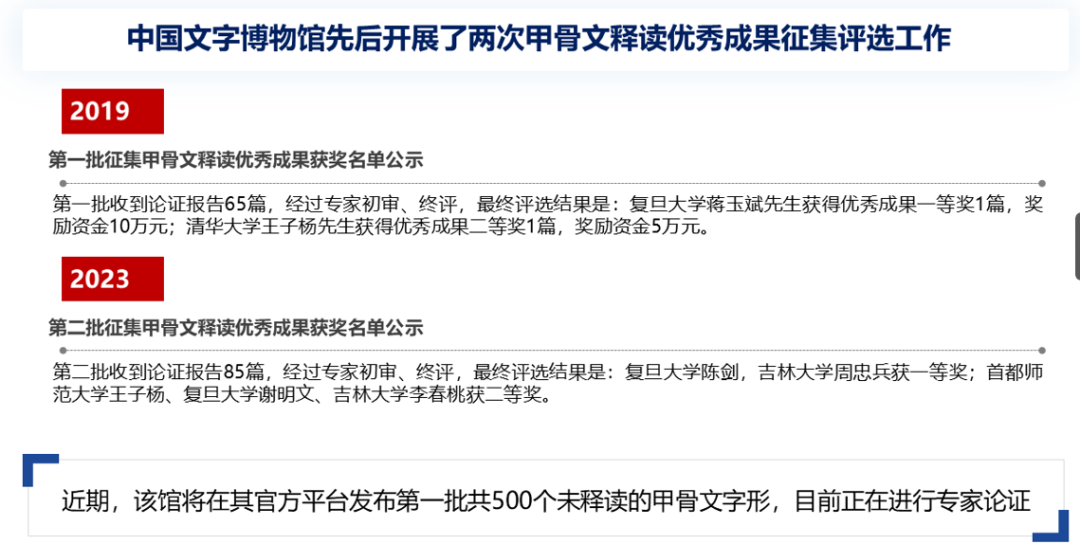
中国文字博物馆对甲骨文释读成果进行了两次公示。首次公示于2019年,复旦大学的蒋玉斌先生获得一等奖,清华大学的王子杨先生获得二等奖。2023年的第二次公示中,一等奖增加至两名,二等奖增至三名,且收到的论证报告数量从65篇上升至85篇,反映出国内学者对甲骨文破译工作兴趣的增长。
甲骨文,作为中国古代的一种文字,主要用于记录和占卜,其历史可以追溯到大约3000年前的商朝时期。这种文字被刻在动物的骨骼上,是中国古代文明的重要遗产。近年来,在美国山脉的岩壁上发现的类似甲骨文的刻痕,进一步证实了甲骨文在全球范围内的历史影响。
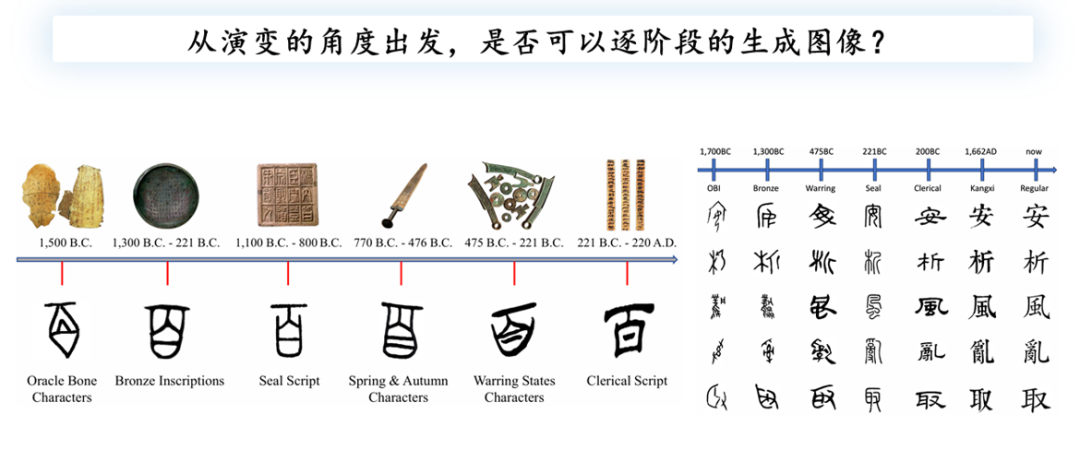
从3300年前至今,甲骨文经历了五个至六个发展阶段。它起源于公元前1500年左右的商朝,随后发展到青铜器上的铭文,再经过篆文、春秋战国、隶书等时期的文字变化,最终演变成现代汉字。这一漫长的演变过程见证了甲骨文的丰富历史和在中国文字发展中的重要作用。

甲骨文之所以重要,是因为它将中国的历史推前了约一千年,为中华民族的悠久历史提供了实证,这对那些质疑中国历史的西方国家具有重要的意义。甲骨文不仅记录在动物骨骼上,也通过现代数字化技术得到了保存和研究,如河南安阳出土的甲骨文的扫描图像,以及专家对拓片的手工处理,都使得这些古老文字得以更好地传承和研究。

甲骨文破译是指将这些古老文字与现代汉字相匹配的过程。尽管某些甲骨文字与现代字形有明显相似之处,但很多字形的演变并不直观,这使得破译工作颇具挑战性。
目前,已知的甲骨文字约有4500个,其中大约三分之一已被破译。破译工作不仅涉及字形的直接对比,还需要结合语义、历史背景、考古发现和文字学知识。例如,蒋玉斌先生在破译“蠢”字时,就考虑了文字的发音。因此,甲骨文破译是一个跨学科的复杂任务,人工智能在这一领域的应用也日益广泛。

甲骨文破译对计算机从业人员来说存在三大难点。首先,甲骨文缺乏标准化编码系统,这与现代汉语和英语的标准化文本和文献形成对比,使得计算机处理变得复杂。其次,缺少综合语料库,甲骨文的完整故事或事件记录极为罕见,难以形成可供分析的语料库。最后,甲骨文存在多对一的情况,即不同的甲骨文可能对应同一个现代汉字,这种多样性增加了破译的难度。

甲骨文主要保存为单字图像,涵盖甲骨文、金文和战国文字等,通常以图片形式存档。由于缺少统一编码和语料库,人工智能在甲骨文研究中的应用主要限于文字检测与识别,尤其是在已知字符上。面对未知或未破译的甲骨文,仍面临挑战。目前,AI在甲骨文破译方面的应用还处于早期阶段。

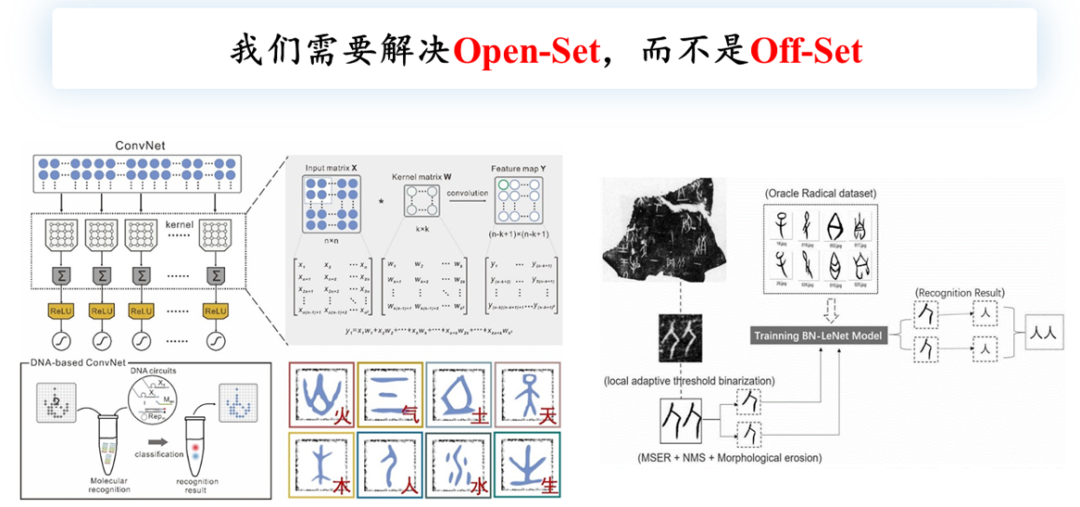
要破译甲骨文,本质上是一个开放集问题,需要推广到尚未破译的类别上。这两张图展示了目前在人工智能领域的相关工作,可以看到这些研究主要是利用深度神经网络进行视觉处理,检测并识别已知类别,但是对于未知的甲骨文破译却无能为力。
Solutions
Solutions
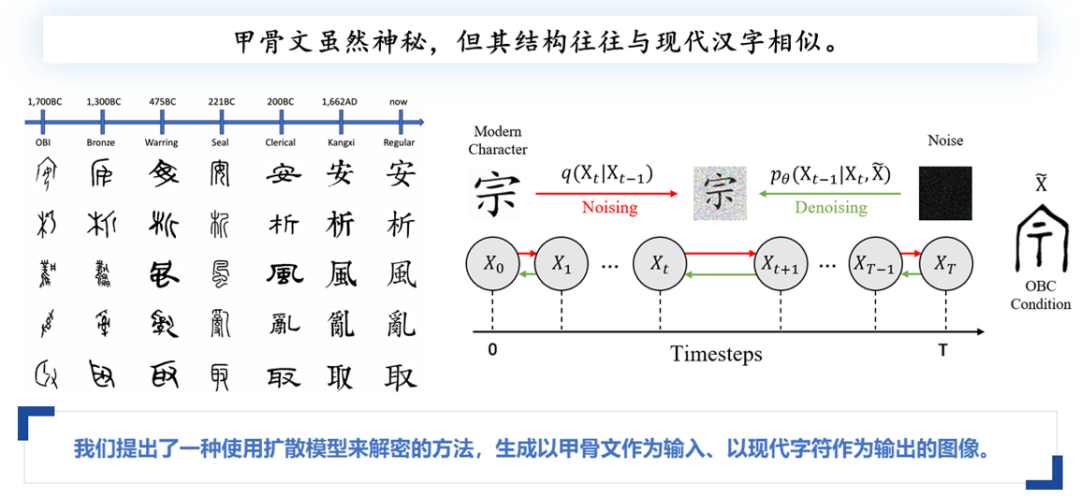
尽管甲骨文难以破译,但它与现代汉字在结构上有许多相似之处。例如,“安”字的上下结构和“析”字的左右结构在甲骨文中已有体现,“取”字的部首对应也较为明确。尽管部分文字在演变过程中发生了较大变化,我们仍能从已破译的甲骨文中找到与现代汉字密切相关的字。
我们设想通过图像生成技术来解决甲骨文的破译问题。图像生成不仅能生成已破译的字,还能生成未破译的字。具体操作是输入一张甲骨文图像作为条件,利用扩散模型生成与之匹配的现代汉字图像。通过识别生成的现代汉字,我们可以反向推测甲骨文的含义。
这一过程与破译甲骨文的逻辑相似,本质上是将甲骨文映射到现代汉字。因此,我们提出了一种基于扩散模型的破译方法:以甲骨文为输入,生成对应的现代汉字作为输出。
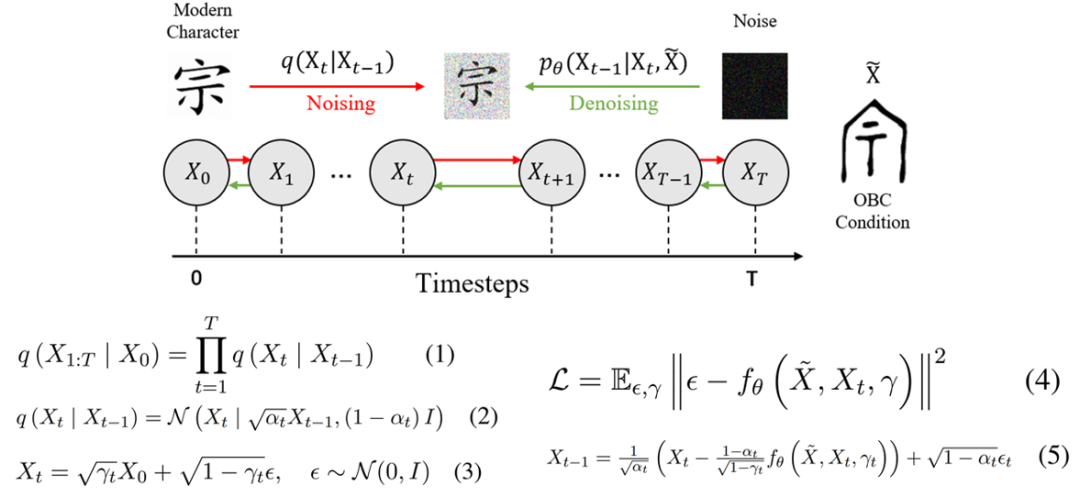
接下来,通过识别生成的现代汉字,可以实现甲骨文的破译效果。为此,本文将简要介绍扩散模型的工作机制,主要通过加噪和去噪过程来实现。
在加噪过程中,现代汉字的图像被视为目标域,对其进行加噪处理。定义X0为现代汉字图像,X1为X0加噪后的图像。加噪过程遵循公式(3)。其中,ϵ代表噪声,加噪过程是一个马尔可夫过程,表示t+1的状态仅依赖于Xt。当t值足够大时,目标域图像会逐步加噪,最终变为均值为0、方差为1的高斯噪声。
在去噪过程中,训练模型参数θ,通过概率分布公式拟合q,并预测p(噪声ϵ)。模型的任务是让扩散模型θ学习加噪图像中的噪声。掌握噪声后,通过逆向推理,从高斯源域中随机抽样,并通过模型预测噪声。利用概率公式从Xt反推出Xt-1,逐步去噪,最终还原出X0,即现代汉字图像。
在甲骨文破译任务中,去噪时不仅输入Xt,还需要额外输入甲骨文图像,以引导模型更精确地预测噪声,确保去噪过程更加准确。扩散模型已有多种变体,如DDPM(SDE)、DDIM(ODE)以及Fflow Mmatching等,它们的核心都基于类似的于加噪与去噪过程。
总之,扩散模型通过噪声的逐步添加与去除,最终生成目标图像。本研究利用这一机制,生成与甲骨文相对应的现代汉字,进而实现破译目的。
Method
基于此,本文提出了名为OBSD的模型。OBSD方法由两个连续的扩散模型组成,这两个模型在参数上完全独立。第一个扩散模型以甲骨文图像作为输入,生成现代汉字的图像。第二个扩散模型接收第一个模型的输出,并对其进行细化,以修正图像中的结构变化和潜在错误。这些错误可能会影响后续的识别或判断。
通过这种双重扩散模型的设计,OBSD能够从一张甲骨文图片生成高质量的现代汉字图像,从而简化了识别过程,提升了破译的准确性。
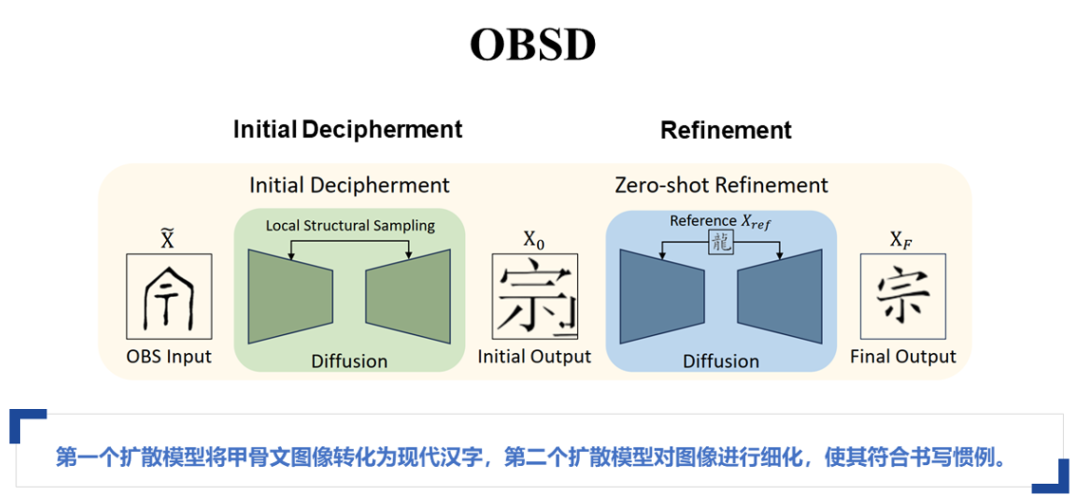
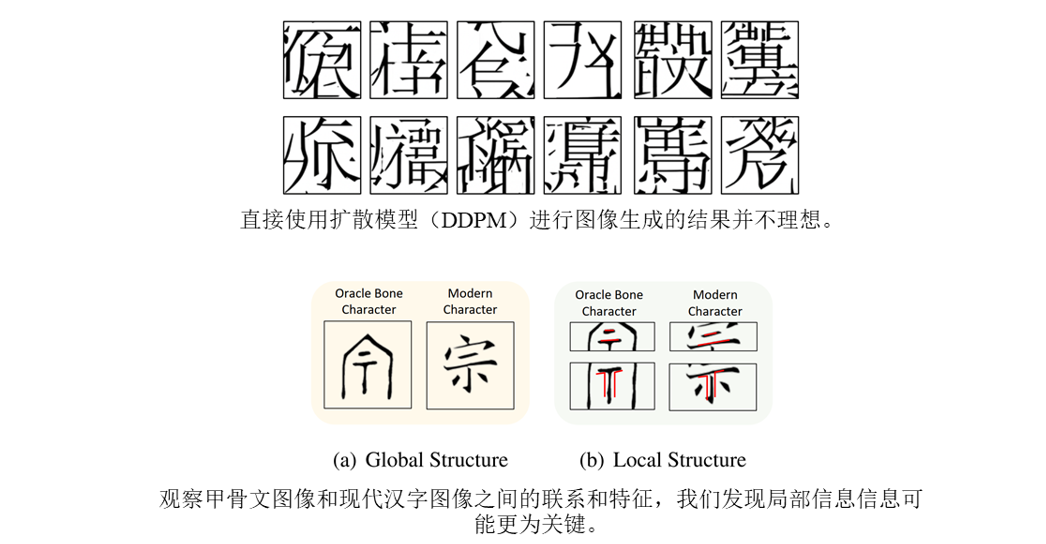
首先,本文探讨了第一个扩散模型的挑战。若直接采用DDPM或DDIM模型进行图像生成,结果往往不理想。实验中,使用DDPM或DDIM生成的字符显示出杂乱无章的特征,缺乏现代汉字的结构特性。这表明,直接通过扩散模型从甲骨文图像生成现代汉字图像存在显著困难,尤其是全局特征的转换难以实现。
相比之下,条件扩散模型(如ControlNet)在输入明确轮廓时表现出色。这些模型可以清晰地识别出输入与输出之间的强对应关系。然而,甲骨文与现代汉字的对应关系并不固定。例如,“宝盖头”在甲骨文中不仅仅局限于上方,其下方也可能包含不同的内容。正因如此,扩散模型难以轻松学到这种复杂的风格迁移或图像转换任务。
本文进一步注意到,甲骨文与现代汉字之间不一定需要全局对应,局部特征同样值得关注。例如,在右下角标记的字中,许多局部特征相似且有强对应关系。这表明,局部特征可能在破译过程中比全局特征更为关键。尽管这种观点在视觉领域可能显得反直觉,但最新研究表明,通过分块处理局部特征,往往能比直接全局处理获得更好的结果。
因此,本文提出在甲骨文破译任务中应更多关注局部特征,以解决全局特征难以转换的问题。
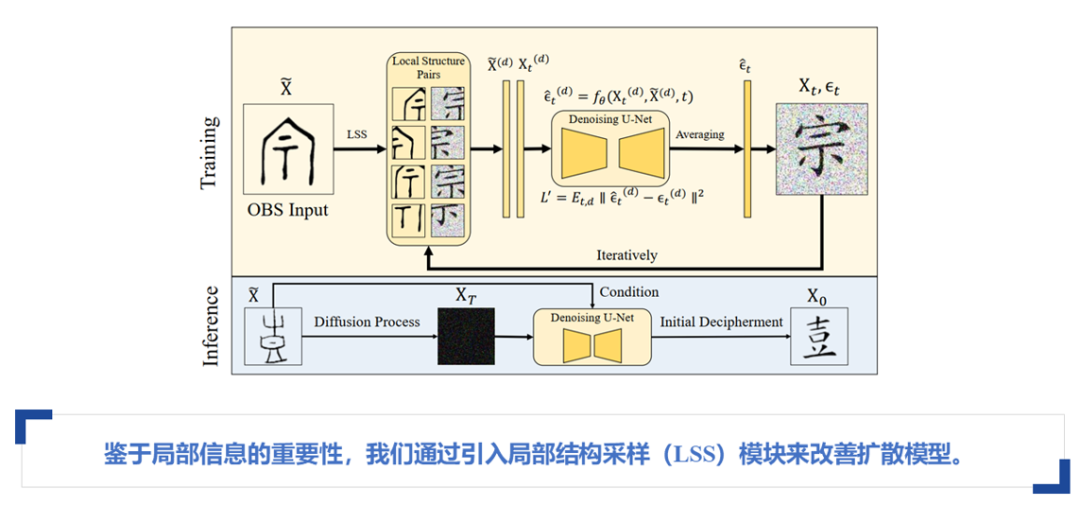
基于此,本文提出了第一个改进方案,即引入局部结构采样模块(LSS)。LSS的核心思想是,既然局部特征较全局特征更易学习,模型可以仅学习局部特征之间的转换,降低训练难度。
具体做法是对现代汉字和甲骨文图像进行随机采样。例如,对于112x112的图像,仅采样其中的64x64小patch,并将它们对应起来。模型只需学习这些局部patch之间的转换,如右上角到右上角、中心到中心、右下角到右下角等。这样,模型的生成任务变得更加简单,避免了复杂的全局转换。
公式中的d表示随机采样的patch索引,扩散模型最终预测的是这些索引之间的转换,而非全局生成。损失函数则根据局部生成与局部GT(ground truth)之间的关系来计算,采用二阶范数进行梯度回传。
在生成过程中,使用滑动窗口平均的方式平滑图像,确保生成图像的一致性和连续性。然而,由于训练时patch之间没有信息交互,生成的图像可能会出现局部区域之间缺乏联系的问题,导致图像不够完整和连贯。
在去噪过程中,本文引入了滑动平均操作,借鉴了Multi Diffusion的思想。具体而言,训练是在patch上进行的。为了将这些patch聚合成一个全局图像,采用了滑动平均方法。patch大小为64x64,通过滑动窗口将整个图像划分为16x16的网格,滑动时允许像素重叠。例如,64x64图像中,四个方向上有四个patch可能重叠,形成16x16网格。这种重叠方式确保多个patch之间能进行信息交互,推理时能提取到训练中未包含的细节。
本文还引入了两个关键参数:Ω和M。Ω用于表示噪声的累积,M为技术计数参数。首先,利用Crop操作将整张图片按滑动窗口方式分割成小块,并通过训练好的扩散模型预测每个块的噪声,累积到Ω_t中。同时,每个滑动窗口的蒙版信息累加到M上,确保每个包含某个patch的像素被记录。在每一步去噪过程中,对重叠部分的噪声进行加权平均,从而在patch之间建立信息交互。
这种滑动平均操作从t等于1000逐步减小到1,每一步都进行滑动窗口和加权平均操作,使得全局信息在去噪过程中不断整合,从而确保生成图像的质量和一致性。

引入LSS后,整体图像生成质量显著提升,从最初完全不像字的图像逐渐转变为可以识别的字形。然而,仍然存在一些问题:尽管global ground truth非常清晰且无噪声,生成的图像中却出现了许多结构畸变和图像伪影。例如,“诀”字的上部多出了一横,而右边的“瓜”字也存在类似的问题。
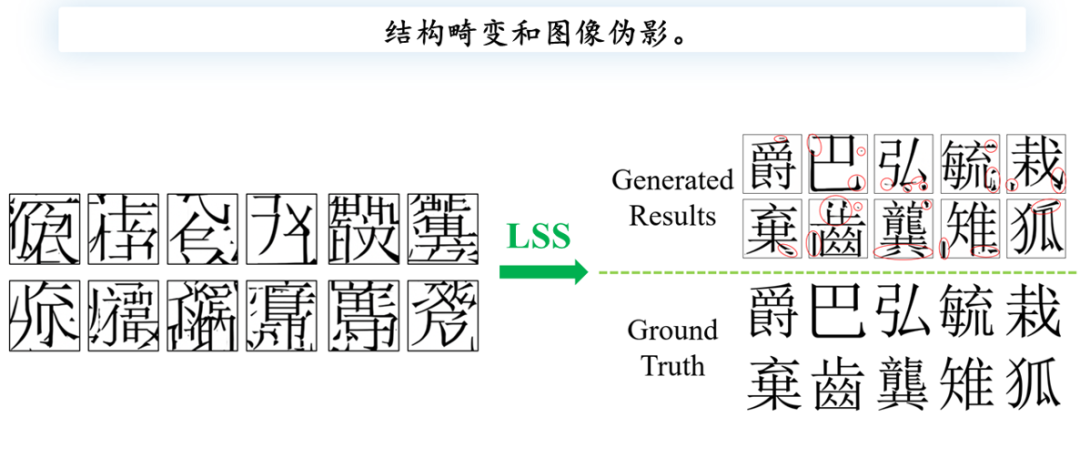
作者推测,问题可能源于训练集或样本的多样性。正如前面提到的多对一问题,同一个现代汉字“巴”可能对应多个不同的甲骨文书写形式,这些字体形式在书写方式上存在差异,导致在第一阶段扩散模型生成的图像中出现结构畸变和伪影,从而影响后续OCR系统的准确识别。
为了应对这一问题,作者考虑通过改进训练方式来提高模型表现。现代汉字有多种书写方式,如楷书、行书、草书等,此外还有多种艺术字体。因此,本文提出在第二阶段引入一个专门学习现代汉字组成规律和逻辑结构的扩散模型,以对第一阶段生成的结果进行矫正。
具体而言,第二个扩散模型将在“1对1”的任务上学习现代汉字的书写规律,确保生成的汉字符合逻辑。例如,当某个部分未被正确生成时,意味着第一阶段模型未能充分理解现代汉字的书写规律。因此,第二阶段模型可以通过训练,利用现代汉字不同书写风格(如楷书、黑体)的数据集来学习。
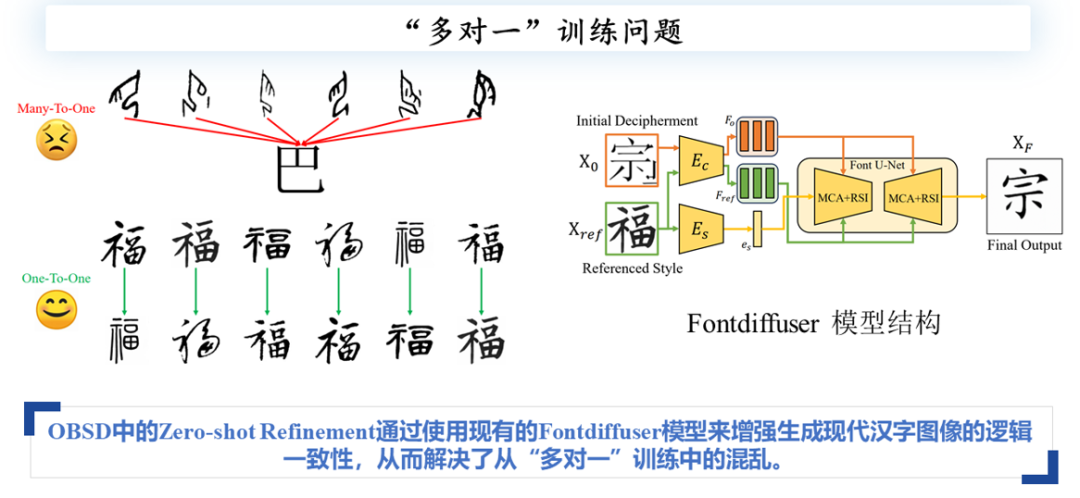
为此,本文使用现有的Fontdiffuser模型,并在数据集上进行风格迁移训练。通过提供源内容和参考风格,生成的汉字将符合指定的风格,如楷书或黑体。在完成现代汉字的训练后,本文将训练好的Fontdiffuser模型应用于甲骨文破译任务。第一阶段生成的甲骨文图像输入到第二阶段模型中,并指定所需风格,最终生成较为准确的现代汉字,从而解决多对一训练中的混乱问题。
Experiment
数据集
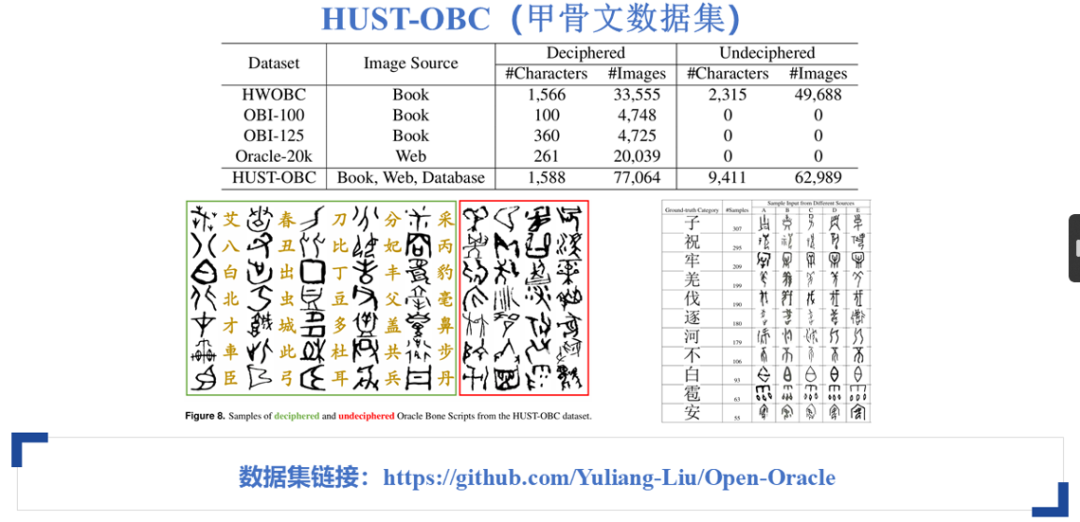
本文使用了两个数据集:HUST-OBC数据集和EVOBC数据集。其中,HUST-OBC数据集是专门为甲骨文研究构建的。在构建过程中,数据来源于书籍、网站以及现有的多个数据集。例如,数据集包含从权威甲骨文数据集中进行的人工切片和类别提取,还通过爬取“殷契文渊”和“国学大师”等权威网站的数据,最终形成了目前最大的开源甲骨文数据集。
相比现有的HWOBC、OBI-100、OBI-125和Oracle-20k数据集,HUST-OBC数据集在数据量和类别数量上具有明显优势,包含约1600个类别和77000张图像。此外,数据收集过程中还发现了大量未破译的甲骨文样本,约有60000张图像,类别数量达到9000。这些类别不仅包括未破译的完整字符,还包含未破译的偏旁部首和结构。

数据集的构建结果如下:该数据集中包含已破译和未破译的甲骨文及其对应的现代汉字。右侧展示了一些样本,如“子”字。尽管现代汉字为“子”,但甲骨文存在多种书写方式。其他汉字也具有类似的情况,即同一个现代汉字对应多种不同的甲骨文书写形式。
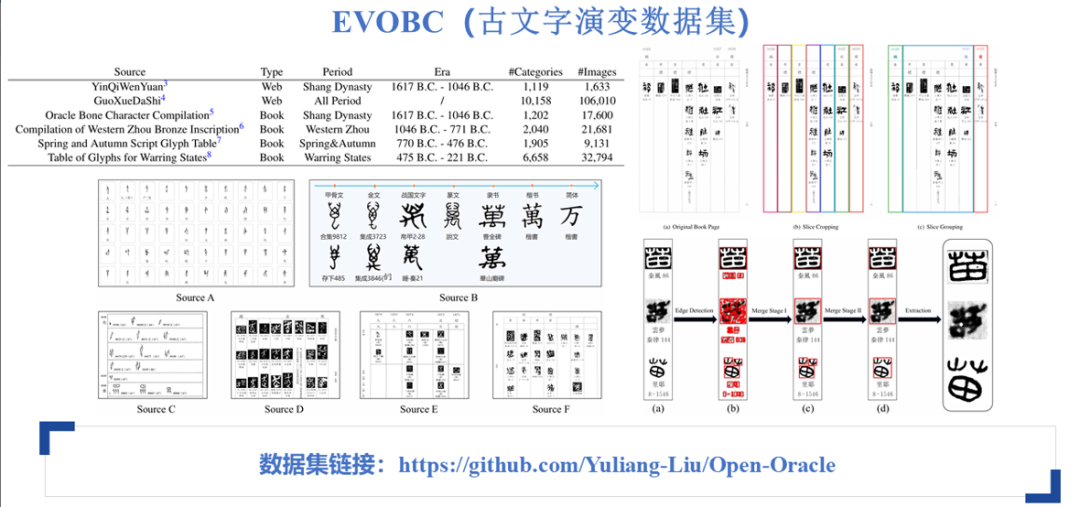
除了HUST-OBC数据集之外,本文还使用了EVOBC数据集。EVOBC是专门为研究古文字演变构建的数据集,涵盖了从甲骨文、金文,到春秋战国时期的文字,再到篆书、隶书、楷书,直至现代简体字的演变过程。该数据集从相关网站、书籍以及现有的数据集中提取了不同阶段的文字,并通过特定的方法进行处理和构建,最终形成了目前最大的古文字演变数据集。在研究过程中,主要利用了甲骨文阶段的数据。
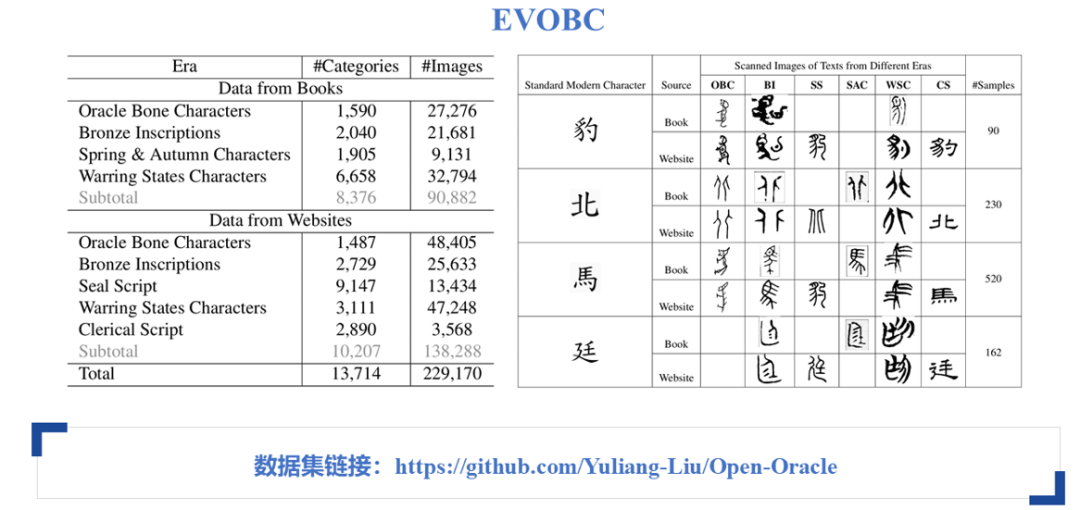
数据统计显示,从商代的甲骨文到现代汉字的演变过程中,各个阶段的统计情况非常清晰。整个数据集包含13000个类别,图像数量十分庞大。本文主要使用了甲骨文的数据,数据量已足够支持实验分析。通过整合HUST-OBC和EVOBC两个数据集中的所有甲骨文数据,最终得到了约6万到7万条数据用于实验。
定量结果
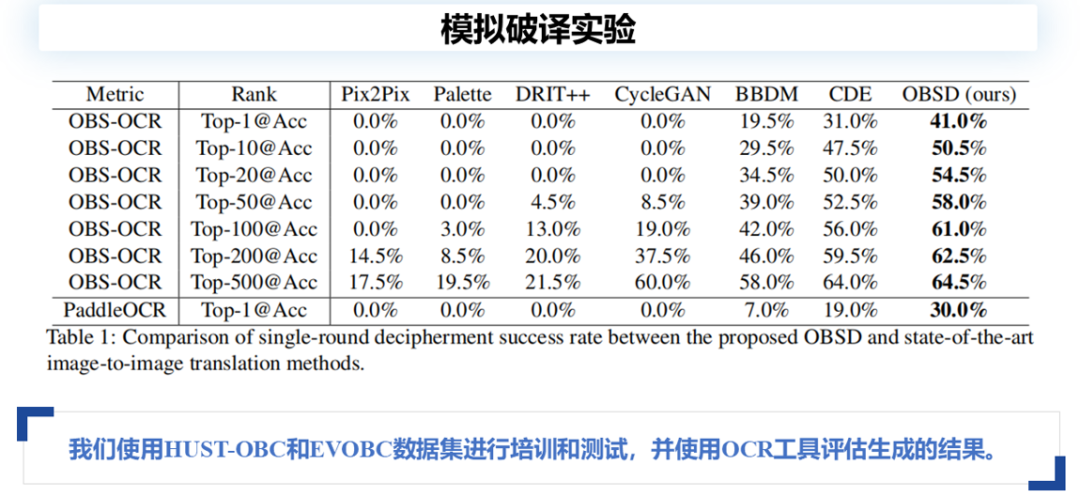
模拟破译实验
本文选取了经典的图像风格转换模型,如Pix2Pix和CycleGAN,以及近期在CVPR、ECCV、ICCV等会议上提出的图像风格迁移模型,如BBDM和CDE,进行对比实验。在训练过程中,模拟了破译任务,将1600个类别中的200类作为未见类别,其余1400类用于模型训练,测试则在未见过的200类上进行。
在甲骨文任务中,评估生成模型的效果不能仅依赖于SSIM和FID等图像质量指标,因为这些指标在破译任务中的实际意义有限。即便模型生成的图像质量较高,但如果生成的字是错误的,结果依然无效。因此,本文引入了OCR工具来辅助评估生成结果。
为了评估生成结果,本文使用了两种文字识别引擎:一是自训练的OCR工具,专用于单字分类,在88900多个常用现代汉字上达到了99.89%的准确度;二是百度的PaddleOCR,其具备检测、识别和全景功能,但本文仅使用其单字识别功能。
对比实验结果显示,提出的OBSD模型在表现能力上优于其他模型,且随着候选类别数从Top-1增加到Top-500,破译准确率逐步提升。
多轮破译
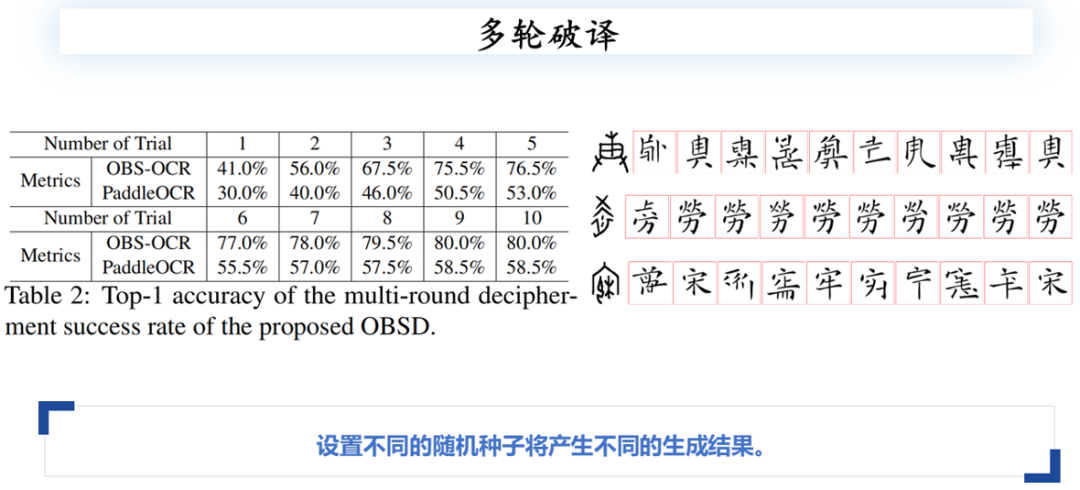
本文还进行了其他实验,例如多轮破译实验。
从另一个角度来看,扩散模型是否只能生成一个固定的甲骨文或现代汉字?这种破译方式是否过于单一?事实上,扩散模型是一个随机过程。在经典的DDPM公式中,假设图像的采样过程每一步都是符合一个高斯分布的,因此生成的图像具备一定随机性。
在实验中,本文采用了DDIM或DDPM的原始参数进行多轮破译。通过设置不同的随机种子,去噪采样过程会生成不同的结果,从而产生不同的现代汉字。实验结果显示,不同的随机种子生成的结果差异显著。例如,在某些示例中,某些随机种子生成的字形更偏向于“宋”字,而另一些则更接近“牢”字。这表明随机种子对生成结果有重要影响。

本文设计了一个实验,使用了10个不同的随机种子生成了10个不同的图像。只要这些图像中有一个字被正确识别,便认为这10次破译中至少有一次是有效的。实验结果显示,随着随机种子数量的增加和破译轮数的提升,OCR模型的识别准确率逐步上升,从最初的41%提升至第9个随机种子时达到80%的峰值。同时,PaddleOCR的性能也在随机种子达到8或9个时达到顶点。

测试结果表明,只需设置9或10个随机种子,模型就能够达到最高的破译准确率。此外,本文还进行了消融实验,进一步验证了该方法的有效性。
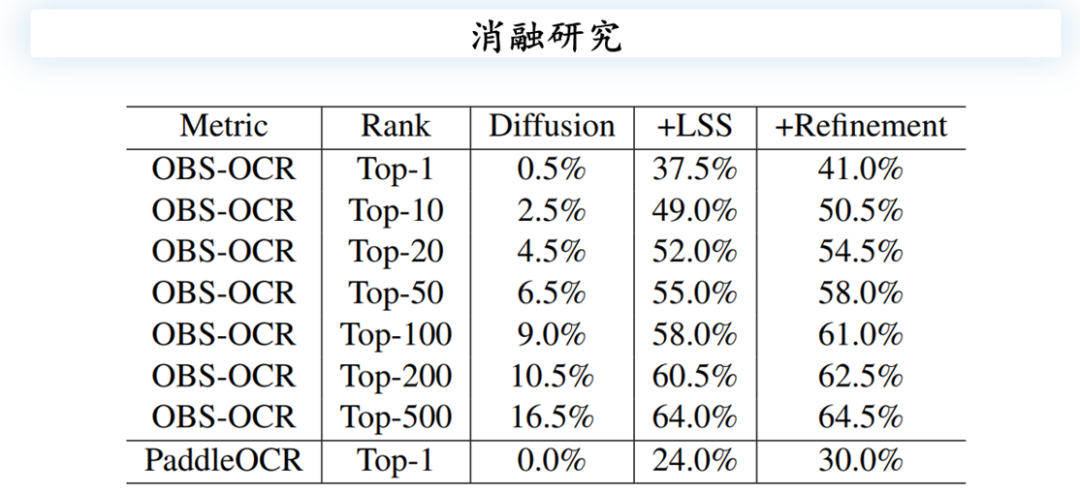
消融研究
在实验与研究中,本文引入了多个模块进行测试。例如,最初直接使用扩散模型的原始DDPM或DDIM进行处理,结果并不理想。随后加入了局部结构采样(LSS)模块,准确率显著提升。接着,本文进一步引入了第二个Refinement模块,对生成的现代汉字图片进行矫正,进一步提升了整体性能,特别是在百度PaddleOCR上的表现尤为显著,验证了该模块在提升破译准确性方面的重要作用。
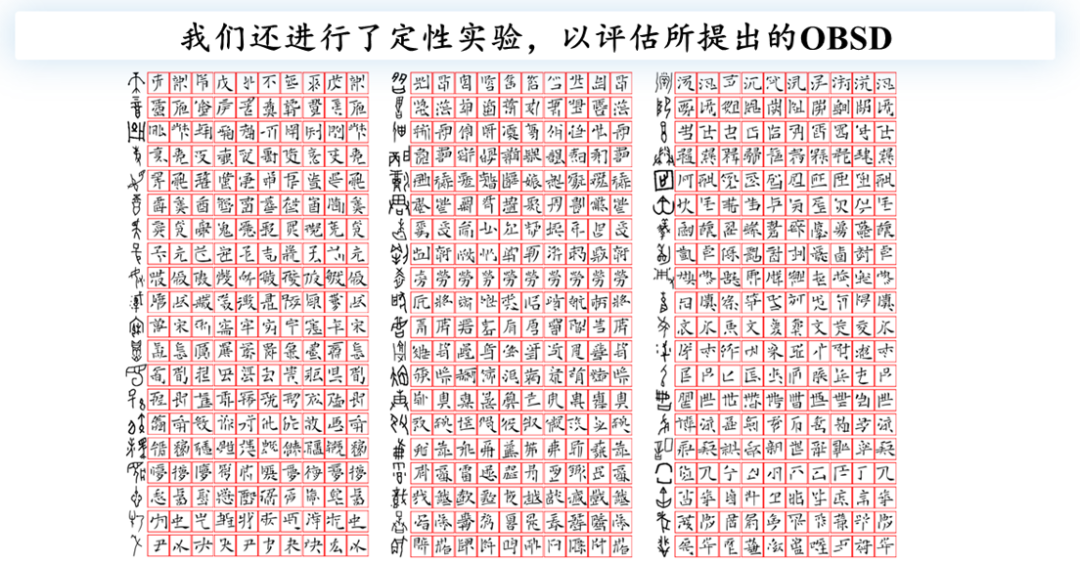
以下是消融实验的可视化结果:第一行展示了输入的甲骨文图像,第二行是对应的现代汉字Ground Truth。第三行展示了利用扩散模型直接生成的结果,初步生成的图像并不像标准的汉字。引入局部采样细化后,模型的表现显著提升,生成的图像开始呈现出汉字的特征。进一步进行图像矫正后,最终的生成结果显示了明显的改进,例如右下角的字形更为清晰,一些难以辨认的图像畸变得到了有效改善。

定性结果
最后,本文还进行了一些定性实验和结果分析,包括使用传统的GNN模型和最新的扩散模型来观察其可视化结果。经过引入LSS模型及后续优化处理,最终的生成结果显著改善,表现相当令人满意。
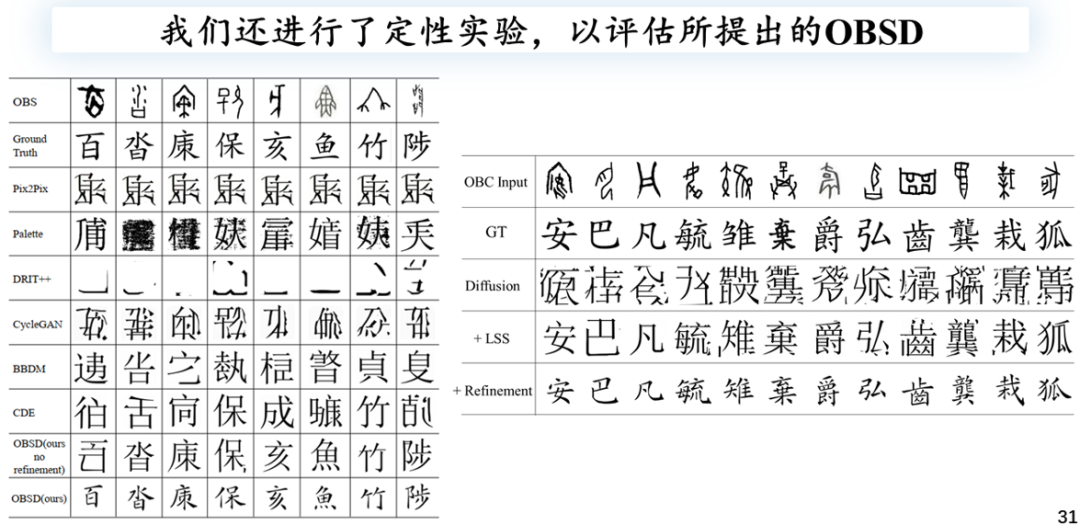
在实际情况下对未破译字符进行的实验显示,尽管在已破译的文字上取得了显著进展,例如在top-1识别率上达到了41%,但对于未破译字符,大多数仍无法识别。这表明,已破译的1600类字符之间可能存在较强的紧密联系,即它们在结构上具有相似性,而未破译字符可能包含尚未了解的结构或组合方式。然而,实验中仍发现少量样本可能提供了有关模型结构或偏旁部首的组成方式,这为未来甲骨文的破译提供了潜在的结构线索。
Future Work
在未来的工作展望中,可以考虑将甲骨文到现代汉字的演变过程中的多个阶段纳入研究,例如金文、篆书和春秋战国时期的文字。这种方法可能有助于改进模型的表现。如果能够将这些中间阶段的文字作为模型的输入或输出,将可能增强对文字演变的理解和处理能力。此外,观察演变过程中的细微变化,如从青铜器铭文到战国铭文的变化,并捕捉这些关键信息,可能为未来的甲骨文破译提供更有价值的线索和支持。
Summary
本工作介绍了一种使用条件扩散模型来破译甲骨文的新方法——OBSD。本文提出了局部结构采样(LSS)和零样本细化矫正技术,以解决从甲骨文向现代汉字转化的难题。此外,OBSD方法还具有潜力用于破译其他古代文字,如玛雅文字和其他象形文字。未来的工作将包括与古文字学专家合作,进一步验证和完善OBSD,以增强人工智能在破译古代语言方面的应用。
本篇文章由陈研整理

往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!














![[spring]SpringBoot拦截器 统一数据返回格式 统一异常处理](https://i-blog.csdnimg.cn/direct/72379fe76ec0406f8cb70c671c16808d.png)


