
文章链接:https://arxiv.org/pdf/2409.08260
Github链接:https://github.com/Nnn-s/CATdiffusion




总结速览
解决的问题:
-
单一U-Net在所有去噪步骤中对齐文本提示和视觉对象不足以生成期望的对象。
-
扩散模型的复杂采样空间中无法保证对对象生成的可控性。
提出的方案:
-
语义预修复:在多模态特征空间中推理目标对象的语义特征。
-
高保真度的对象生成:在扩散的潜在空间中基于已修复的语义特征生成目标对象。
应用的技术:
-
采用级联的Transformer语义修复器与目标修复扩散模型,提出了新型的Cascaded Transformer-Diffusion(CAT-Diffusion)框架。
-
语义修复器通过上下文和文本提示条件,预测目标对象的语义特征。语义修复器的输出作为视觉提示,经过参考Adapter层来指导高保真对象生成。
达到的效果:
-
在OpenImages-V6和MSCOCO数据集上的广泛评估表明,CAT-Diffusion在文本引导的目标修复任务中优于现有的最新方法。
方法
首先,在文本引导的物体修复中,需要在由输入图像的二值mask指示的指定区域内生成由文本提示(通常是对象标签)描述的新对象。这个任务要求与图像和文本提示分别具有视觉一致性和语义相关性。本节将深入探讨级联Transformer-Diffusion(CAT-Diffusion),在简要回顾扩散模型后,随后介绍训练细节。
级联Transformer-扩散模型
设 、 和 分别为输入图像、描述新目标的文本提示和指示需要修复区域的二值mask。大多数现有的文本引导物体修复扩散模型仅优化文本提示 和期望目标 在潜在空间中的对齐,这导致了次优结果。为了进一步改进,需要解决两个主要问题:
-
依赖单独的U-Net在所有去噪时间步中实现视觉-语义对齐是不够的;
-
在复杂的采样空间中稳定生成高保真度对象是具有挑战性的,而没有额外的语义信息。
为了解决这些挑战,研究者们提出将传统的单阶段流程分解为两个级联阶段:首先进行语义预修复,然后进行对象生成,从而形成CAT-Diffusion。技术上,CAT-Diffusion通过一种新颖的语义修复器在辅助的多模态特征空间(例如CLIP)中进行对象预修复。语义修复器通过知识蒸馏进行训练,以预测目标对象的语义特征,条件是未遮罩的视觉上下文和文本提示。这样,得出的输出自然对齐文本提示和视觉对象,除了U-Net之外,无论去噪时间步如何。语义修复器的输出通过参考Adapter层进一步集成到目标修复扩散模型中,以实现可控的目标修复。CAT-Diffusion的整体框架如下图2所示。
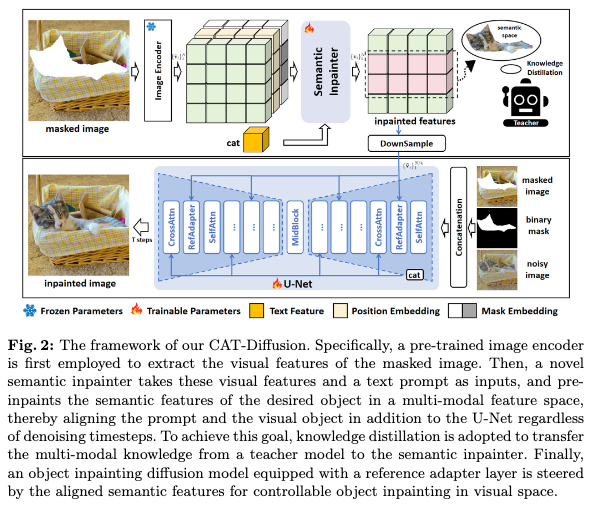
语义修复器
为了缓解在整个去噪过程中仅依靠单独的U-Net对齐文本提示和视觉对象的不足,提出通过在U-Net之外,利用经过良好预训练的辅助多模态特征空间对目标对象的语义特征进行预修复,以增强视觉-语义对应关系。其原理在于,预训练的多模态特征空间是通过大规模的跨模态数据进行学习的,用于实现视觉-语义对齐,无论去噪时间步如何。在本工作中,设计了一种有效的知识蒸馏目标,将这种多模态知识从教师模型(CLIP)转移到CAT-Diffusion中的语义修复器。
基于Transformer的语义修复器(SemInpainter)参数化为 ,与CAT-Diffusion中的目标修复扩散模型级联,如上图2的上部所示。首先,通过CLIP的图像编码器(ImageEnc)提取被遮罩图像 的视觉特征 ,其中 是局部图像块的特征向量。给定被遮罩图像的损坏特征 和文本提示 的文本特征,SemInpainter 旨在预测语义特征 ,以忠实重建CLIP空间中的目标对象。这样,视觉-语义对齐在扩散模型的整个去噪过程中自然得到实现。整个过程可以表示为
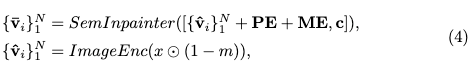
其中 表示拼接操作, 是可学习的位置嵌入, 是可学习的mask嵌入,指示视觉特征 是否在图像 中被遮罩。SemInpainter 实现为24层的Transformer结构(类似于CLIP的图像编码器)。最后,通过将 和 与二值mask 混合,得到修复后的特征 ,这些特征将随后被整合到目标修复扩散模型中:
![]()
其中 是一个无参数的下采样层,用于降低特征分辨率以提高计算效率。
为了强制预测的对象特征与文本提示 对齐,提出将多模态知识从教师模型(在本文中采用CLIP作为教师模型)转移到SemInpainter。技术上,SemInpainter 的训练任务是遮罩特征预测,以恢复CLIP空间中被遮罩对象的真实语义特征,条件是未遮罩的视觉上下文和文本提示 。
参考Adapter层
由于控制扩散模型以实现高保真度的文本到图像生成仍然具有挑战性,受到 [55, 59] 的启发,语义特征 被用作额外的条件,称为视觉提示,以引导扩散模型在潜在空间中进行可控的修复。具体来说,在基础目标修复扩散模型中引入了一个新的参考Adapter层(RefAdapter),其形式为Transformer风格的多头交叉注意力层。所提出的RefAdapter 在U-Net的原始自注意力(SelfAttn)和交叉注意力层(CrossAttn)之间交替插入,如图2的下部所示。设 为U-Net的中间隐藏状态,其中 随不同层的分辨率变化。 是扩散模型中文本编码器提取的提示 的文本特征。首先定义不同类型注意力层的共享模块原型为:
![]()
因此,升级版U-Net中的一个完整块,包括SelfAttn、RefAdapter和CrossAttn,操作如下:
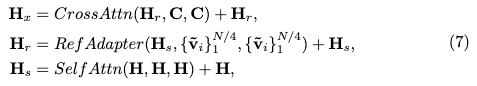
其中 将作为下一块的输入。
目标修复扩散模型
通过将目标修复流程分解为两个级联过程,CAT-Diffusion能够生成与文本提示语义对齐的高保真度对象。此外,通过利用额外的语义指导(即修复后的视觉特征 ),进一步增强了填补对象与周围图像上下文之间的视觉一致性。
一般来说,参数化为 的U-Net的修复扩散模型以噪声潜在编码 、指示待修复区域的mask 和被遮罩的潜在编码 作为输入,估计从 中需要去除的噪声,从而得到去噪后的 。数学上,整体过程可以表示为:
![]()
训练
扩散损失
对于配备参考adapter层的目标修复扩散模型的训练,采用 [35] 中的通用实践,目标函数为:
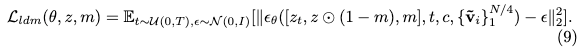
知识蒸馏损失
此外,为了强制语义修复器预修复与提示 语义对齐的对象特征,通过知识蒸馏任务中的真实视觉特征 对语义修复器进行监督。优化目标可以表示为:

其中 是配对图像 和文本提示 的训练数据集, 表示前面提出的SemInpainter的可训练参数。
实验
验证级联Transformer-扩散方法(CAT-Diffusion)在文本指导的目标修复任务中的优点,并与最先进的基于扩散的方法进行了比较。大量实验验证了CAT-Diffusion在修复高保真度对象方面的有效性。
实施细节
在OpenImages-V6的训练集中的本地mask与对应对象标签对上训练CAT-Diffusion。CAT-Diffusion通过Adam优化,学习率为0.00001,使用8个A100 GPU进行约40K次迭代。批量大小设置为128,输入图像分辨率设置为512 × 512。
比较方法和评估指标
比较方法
将CAT-Diffusion与几种最先进的基于扩散的方法进行了比较,包括Blended Diffusion、Blended Latent Diffusion、GLIDE、SmartBrush、Stable Diffusion 和 Stable Diffusion Inpainting。具体来说,Blended Diffusion、Blended Latent Diffusion 和 Stable Diffusion 仅利用预训练的基础文本到图像模型,通过在每个去噪步骤中混合生成的对象和背景进行文本指导的目标修复。其他方法则使用文本提示、二值mask和被遮罩图像作为输入来训练修复扩散模型。由于相同的评估设置,所有方法的结果均取自 [45],但 [1] 的结果除外。请注意,已将Blended Latent Diffusion中的文本到图像Stable Diffusion 2.1替换为1.5,以确保公平比较。
评估指标
所有上述方法都在OpenImages-V6和 MSCOCO的测试集上进行评估,分别涉及13,400和9,311张测试图像。采用三种广泛使用的指标:Frechet Inception Distance (FID)、Local FID 和 CLIP score。值得一提的是,FID 和 Local FID 分别测量修复对象在全局图像和局部补丁中的真实性和视觉一致性,而 CLIP score 估计修复对象与文本提示之间的语义相关性。此外,还涉及用户研究以评估视觉一致性和文本-对象对齐。由于GLIDE仅支持256 × 256分辨率的图像,将所有结果调整为相似大小以确保公平比较。此外,评估中考虑了分割mask和边界框mask。
性能比较
OpenImages-V6上的定量结果
下表1总结了所有方法在OpenImages-V6测试集上的结果。总体而言,所有指标的结果一致地展示了CAT-Diffusion在分割mask或边界框mask下的有效性。具体来说,基于混合的方法(即Blended Latent Diffusion 和 Stable Diffusion)在CLIP分数上表现相当,但FID 和 Local FID 分数远低于CAT-Diffusion。推测这是因为这些方法仅关注修复图像与对象标签之间的视觉-语义对齐,并仅在潜在空间中混合生成的对象和背景。因此,周围未遮罩区域的语义上下文被忽视,导致视觉一致性差。SmartBrush通过将被遮罩图像纳入U-Net以进行上下文学习,并进一步使用形状mask指导扩散模型,展现了更好的性能。然而,SmartBrush的FID和Local FID分数仍低于CAT-Diffusion。结果验证了通过参考Adapter层用语义修复器预修复的对象特征来引导扩散模型的影响。
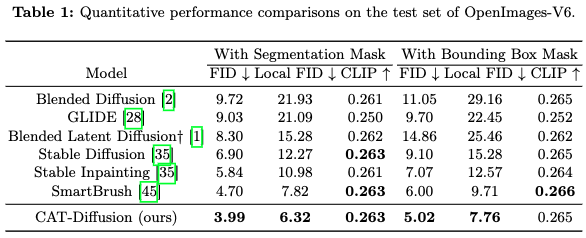
MSCOCO上的定量结果
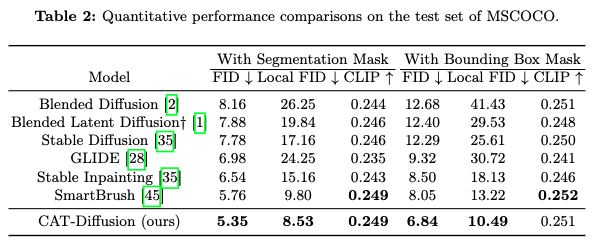
下表2列出了所有方法在MSCOCO测试集上的结果。值得注意的是,SmartBrush 和CAT-Diffusion 都没有在MSCOCO上进行训练。与OpenImages-V6上的趋势类似,CAT-Diffusion 在大多数指标上优于其他方法。具体来说,CAT-Diffusion 在Local FID(使用边界框mask)上相对于强基线 Stable Diffusion Inpainting 和 SmartBrush 分别提高了42.1% 和 20.7%。结果再次验证了在CAT-Diffusion中将单次修复流程分解为两个级联过程(首先进行语义预修复,然后生成对象)的优点。
定性比较
通过案例研究对不同方法进行定性测试。下图3展示了几个示例。如前四个结果所示,CAT-Diffusion生成的图像与输入文本提示的语义对齐程度优于其他方法。此外,在图像中,生成对象与周围环境的视觉一致性更好,修复结果中的对象形状也更准确。结果证明了通过提出的语义修复器预修复对象语义特征的优越性。例如,与其他方法生成的图像相比,第一排的CAT-Diffusion生成的男人在结构上更完整。这得益于通过参考Adapter层用预修复的目标对象语义特征引导扩散模型。尽管没有提供形状mask,CAT-Diffusion仍能根据文本提示和边界框mask生成高保真度的对象(中间两排)。此外,还对具有更具描述性文本提示的目标修复进行了评估,不同方法生成的结果显示在底部两排。类似地,CAT-Diffusion生成了视觉上更令人愉悦的图像。

用户研究
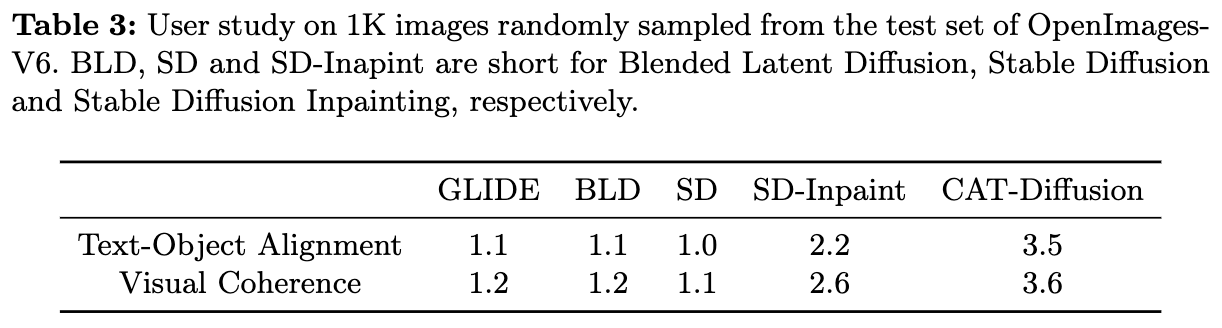
研究者们进行了一项用户研究,以检查修复图像是否符合人类偏好。在实验中,从OpenImages-V6测试集中随机抽取了1K张图像进行评估。SmartBrush 尚未发布,因此被排除在外。邀请了10名具有不同教育背景的评估员(5名男性和5名女性):艺术设计(4名)、心理学(2名)、计算机科学(2名)和商业(2名)。向所有评估员展示修复图像和相关提示,并要求他们从两个方面给出评分(0∼5):
-
与周围环境的视觉一致性;
-
与文本提示的对齐程度和对象形状的准确性。
下表3总结了不同方法的平均结果。结果表明,在文本-对象对齐和视觉一致性方面,CAT-Diffusion在所有基线方法中遥遥领先。
分析与讨论
CAT-Diffusion的消融研究
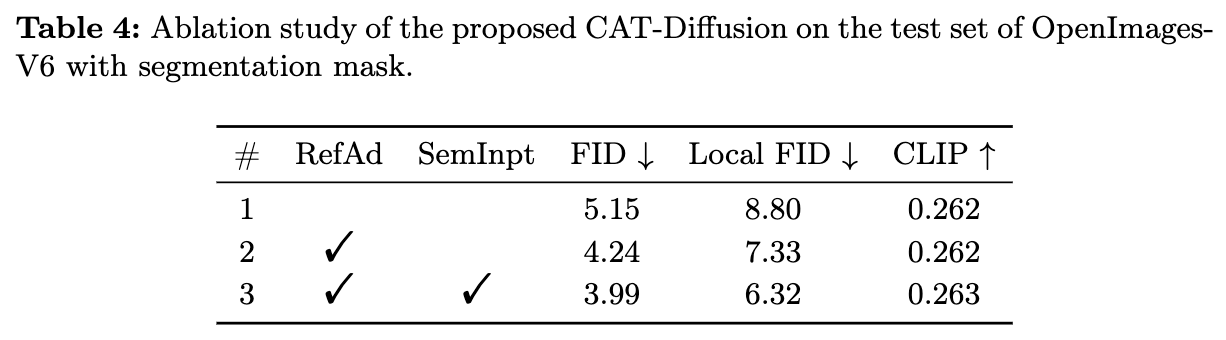
研究了CAT-Diffusion中各个组件对整体性能的影响。考虑了每个阶段的一个或多个组件,表4总结了使用分割mask的OpenImages-V6测试集上的结果。请注意,第1行的基线是使用[21]中的对象-文本对进行微调的Stable Inpainting模型。通过结合仅使用mask图像 的CLIP特征训练的参考Adapter层,第2行的变体在FID和Local FID分数上分别相较于第1行的基线模型提高了0.91和1.47。这并不令人意外,因为未mask区域的CLIP特征通过参考Adapter层为基础扩散模型提供了更丰富的上下文语义,从而改善了视觉一致性并保留了背景。语义修复器的输出进一步提升了模型,通过引入所需对象的语义,获得了第3行在所有指标上的最佳结果。
语义修复器预测的特征
随后分析了提出的语义修复器在提高所需对象语义特征方面的程度。值得注意的是,由于CLIP中的自注意机制,mask区域的CLIP特征本身就包含了来自未mask区域的上下文语义,从而在通过语义修复器之前与真实标签具有非平凡的相似性。特别地,计算了语义修复器输入/输出与对应真实标签之间的余弦相似度,在10K张图像上进行分析。下图4(a)展示了这两个分布。平均余弦相似度从0.47提高到0.65,显示了提出的语义修复器的有效性。尽管语义修复器的输出并不是100%准确,但这些语义特征为CAT-Diffusion生成高保真度对象贡献了更丰富的上下文。
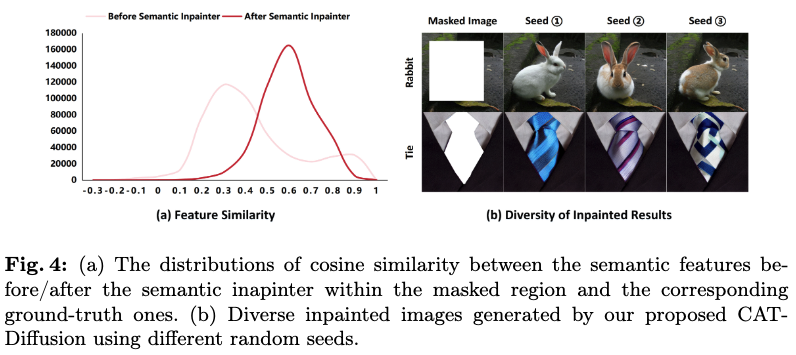
修复结果的多样性
为了测试CAT-Diffusion在相同语义特征下生成修复结果的多样性,对不同随机种子下的结果进行了研究。上图4(b)展示了两个示例。可以观察到,CAT-Diffusion能够生成具有准确形状的多样化对象,这由参考Adapter层控制。
推理复杂度
在推理阶段,只需要对提出的语义修复器进行一次前向传递,并且修复的特征可以在每个去噪步骤中重复使用,从而带来较小的计算开销。CAT-Diffusion每张图像的平均时间为1.84秒,相较于SD-Inpaint的1.60秒稍长。
结论
本文提出了一种新颖的级联Transformer-扩散(CAT-Diffusion)模型,以增强扩散模型在文本引导目标修复中的视觉-语义对齐和可控性。具体而言,CAT-Diffusion将传统的单阶段管道分解为两个级联过程:首先进行语义预修复,然后进行对象生成。通过在多模态特征空间中预修复所需对象的语义特征,然后通过这些特征引导扩散模型进行对象生成,CAT-Diffusion能够生成与提示语义一致且与背景视觉一致的高保真度对象。
从技术上讲,基于Transformer的语义修复器在给定未mask的上下文和提示的情况下预测所需对象的语义特征。然后,来自语义修复器的修复特征通过参考Adapter层进一步输入到目标修复扩散模型中,以实现受控生成。在OpenImages-V6和MSCOCO上的广泛实验验证了CAT-Diffusion的有效性。
广泛影响
最近生成模型(如扩散模型)的进展开启了创造性媒体生成的新领域。然而,这些创新也可能被滥用于生成欺骗性内容。本文的方法可能被利用来在图像中修复有害内容,用于传播虚假信息,对此类行为坚决反对。
参考文献
[1]Improving Text-guided Object Inpainting with Semantic Pre-inpainting
更多精彩内容,请关注公众号:AI生成未来




















