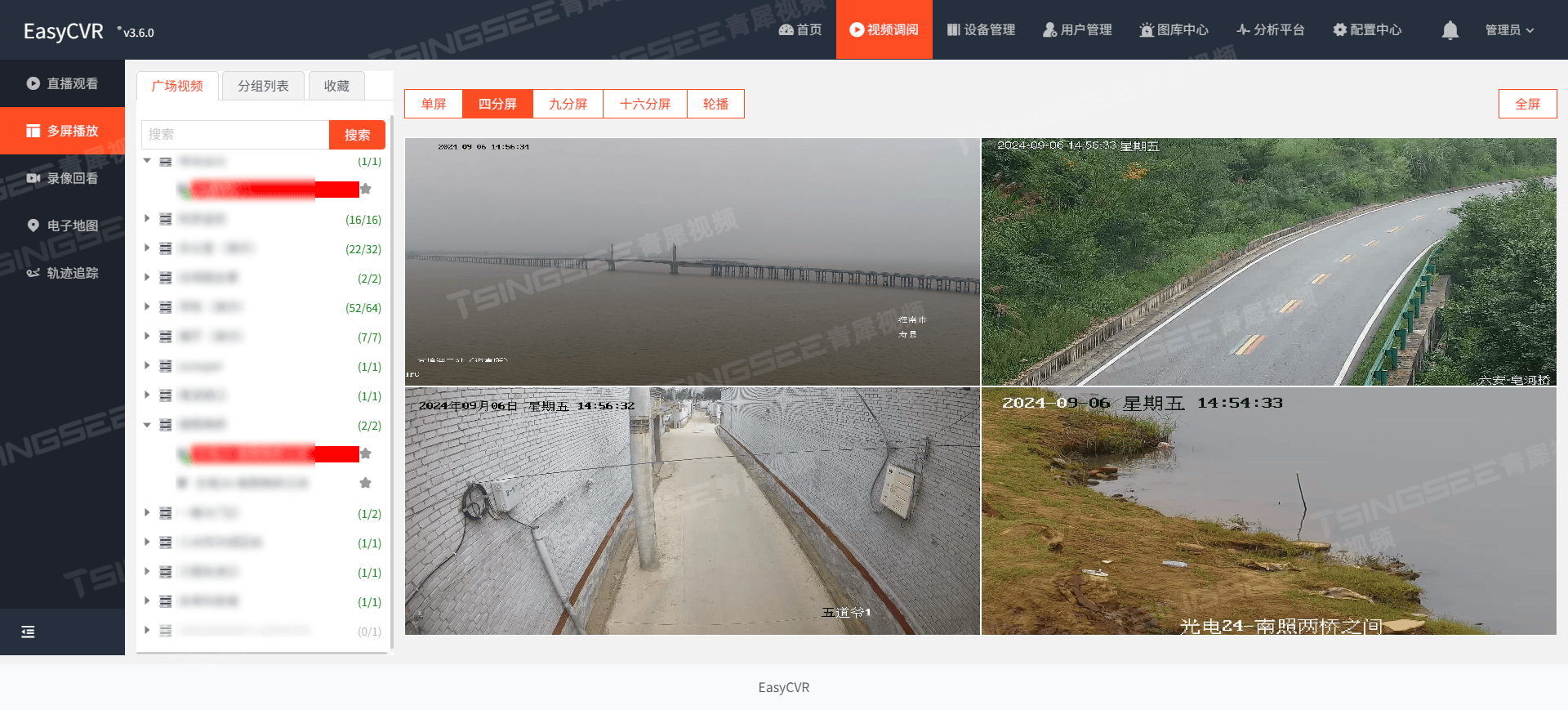
1 功能说明
RDB (Redis Database Backup) 是 Redis 的一种持久化方式,它通过将某一时刻的内存快照(snapshot)以二进制格式保存到磁盘上。这种持久化方式提供了高性能和紧凑的数据存储,但相对于 AOF (Append Only File) 来说,可能会丢失最后一次快照之后的数据。
RDB 特点
- 性能:RDB 在生成快照时只需要 fork 一个子进程来处理,父进程可以继续处理客户端请求,因此对性能影响较小。
- 数据恢复:RDB 文件是紧凑的二进制文件,加载速度快,适合用于大规模数据恢复。
- 灾难恢复:RDB 文件可以在不同机器之间传输,适合备份和灾难恢复。
- 数据丢失:如果在两次快照之间发生故障,那么这期间的所有写操作将会丢失。
- 配置灵活:可以通过配置
save指令来设置触发 RDB 快照的条件,例如每隔多少秒或多少次写操作后生成一次快照。
触发条件:
- 配置文件中的
save指令,例如save 900 1表示 900 秒内至少有 1 次写操作时触发快照。 - 手动调用
SAVE或BGSAVE命令。 - 主从复制时,从节点会自动触发 BGSAVE 生成 RDB 文件。
2 配置
- save 阻塞创建
- bgsave 异步创建
配置文件
# 配置 RDB 快照
save 900 1
save 300 10
save 60 10000
# 设置 RDB 文件名
dbfilename dump.rdb
# 设置 RDB 文件存放目录
dir /var/redis/data/
在这个配置中,Redis 会在以下条件下生成 RDB 快照:
- 900 秒内至少有 1 次写操作。
- 300 秒内至少有 10 次写操作。
- 60 秒内至少有 10000 次写操作。
与 AOF 配合使用
# RDB 配置
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir /var/redis/data/
# AOF 配置
appendonly yes
appendfilename "appendonly.aof"
dir /var/redis/data/
appendfsync everysec
# 使用 RDB 前言来优化 AOF 重写
aof-use-rdb-preamble yes
3 文件格式

操作符列表
redis 操作符是一类特殊标记符。
通常用来揭示紧跟其后或之前的一段字节流的存储的内容类型。
redis 支持的操作符列表(第7版):
| Byte | Name | Description |
|---|---|---|
| 0xFF | EOF | rdb 文件结束符 |
| 0xFE | SELECTDB | redis 数据库编号 |
| 0xFD | EXPIRETIME | redis 过期时间),使用秒表示。 |
| 0xFC | EXPIRETIMEMS | redis 过期时间,使用毫秒表示。 |
| 0xFB | RESIZEDB | redis dbsize,描述 key 数目和设置了过期时间 key 数目 |
| 0xFA | AUX | redis 元属性,可以存储任意的的 key-value 对 |
key-value 对
数据库编号之后,紧跟着就是该数据库中存放的全部数据。
数据以 key-value 链的形式,一个接着一个存放。
每一个 key-value 由 4 部分组成:
1. key 过期时间
如果有设置过期时间,则会存放具体过期时间的 timestamp。否则这部分不存在。采用小端字节序编码。
以 0xFD 开头,代表过期时间为秒,之后的 4 byte 表示该key 的过期时间。
以 0xFC 开头,代表过期时间为毫秒,之后的 8 byte 表示该key 的过期时间。
2. value 存储类型
该部分使用 1 byte 表示。具体的存储类型如下:
# 0 = "String Encoding"
# 1 = "List Encoding"
# 2 = "Set Encoding"
# 3 = "Sorted Set Encoding"
# 4 = "Hash Encoding"
# 9 = "Zipmap Encoding"
# 10 = "Ziplist Encoding"
# 11 = "Intset Encoding"
# 12 = "Sorted Set in Ziplist Encoding"
# 13 = "Hashmap in Ziplist Encoding"
3.key
使用字符串编码方法编码 key。
4.value
依据 value 存储类型的不同,使用对应的值编码方法编码 value。
如当 value 存储为 0 时,value 使用字符串编码方法编码。
当 value 为 10 时,value 使用ziplist 编码方法编码。
尾部区域编码
该区域最为简单。固定使用 9 byte。
第一 byte 为 0xFF ,之后固定跟着 8 byte 用于 crc64 校验。
该校验码采用crc-64-jones算法生成,用于校验 rdb 文件的合法性。
可以在 redis 配置文件设置 rdbchecksum no 关闭校验。之后 dump rdb 文件时将以
00 00 00 00 00 00 00 00 结尾。加载 rdb 文件时也会跳过验证 checksum。
编码算法细节
至此 rdb 文件各位置的编码方法概要已经介绍完毕。接下来展开解释具体的编码算法。
首先介绍两个 rdb 文件中基础编码算法:整数编码和字符串编码,之后进一步解析稍复杂的值编码算法。
整数编码
该部分为了尽量缩短字节数,采用可变字节编码方法。rdb 文件中频繁使用该算法。
主要用于在二进制文件中存储下一个对象的长度,如在编码一个 key 时,使用该方法在 key 的前几个 byte 存储该 key 占用字节数。
具体算法:
- 从高位开始,读取第一个 byte 的前 2 bit。
- 如果高位以 00 开始:当前 byte 剩余 6 bit 表示一个整数。
- 如果高位以 01 开始:当前 byte 剩余 6 bit,加上接下来的 8 bit 表示一个整数。
- 如果高位以 10 开始:忽略当前 byte 剩余的 6 bit,接下来的 4 byte 表示一个整数。
- 如果高位以 11 开始:特殊编码格式,剩余 6 bit 用于表示该格式。
该算法在整数较小时可以缩短编码,如 0-63 只需 1 byte 表示,64-16383 只需 2 byte。
字符串编码
rdb 文件的字符串是二进制安全的。不需要像 c 语言的字符串那样,以 ‘\0’ 为结束符。
rdb 文件的字符串主要有三种编码方法:简单的长度前缀编码字符,使用字符串编码整型以及压缩字符串。
均是以使用整数编码编码表示字符串长度,之后存储具体字符串编码。
当整数编码为:
-
最高 2 bit 为 00、01、10 时:
简单字符串方法。
长度编码后是字符串具体的编码。如字符 ‘a’ 使用 ‘0x61’ 表示。 -
最高 2 bit 为 11 ,剩余 6 bit 为数 0、1、2 时:
字符串整型编码方法。
- 为 0 时:之后 8 bit 用于存储该整型。
- 为 1 时:之后 16 bit 用于存储该整型。
- 为 2 时:之后 32 bit 用于存储该整型。
-
最高 2 bit 为 11 ,剩余 6 bit 为数 3 时:
压缩字符串编码方法。
该类型的解码具体方法:- 使用整数编码方法读取压缩后字符串长度,如表示为 clen。
- 使用整数编码方法读取未压缩字符串长度,如表示为 len。
- 读取 clen 个字节。
- 最后使用 lzf 算法这 clen 个字节,解析后还原字符串。
hash 编码
当某个 key 存储的 hash 数据的大小超过 hash-max-ziplist-entries 或者 hash-max-ziplist-values 的值时。使用 hash table 编码值为 hash 类型的数据。
编码过程:
- 使用整数编码方法 hash key 数,如表示 size。
- 使用字符串编码方法读取 2*size 个字符串。该字符串由 size个key-value 对组成。
例如:“f1 v1 f2 2” 用来表示 hash 表,{“f1”->“v1”,“f2”->“2”}。最后章节会详细介绍表示该 hash 数据的实际的二进制串。
Hashmap in Ziplist 编码
当某个 key 存储的 hash 数据大小都小于 hash-max-ziplist-entries 或者 hash-max-ziplist-values 的值时。hash 表示为连续的 entry 链,并使用 ziplist 编码算法表示 hash 数据。
例如:hash 数据 {“f1”->“v1”,“f2”->“2”} ,使用ziplist 编码方法编码字符串列表 [“f1”,“v1”,“f”,“22”]。
ziplist 编码
ziplist 编码在 redis 各类型的数据,hash、list 等中普遍使用。
ziplist 运行过程可以理解为是将一个字符串 list 序列化,同时为了方便从两端快速检索,增加了额外的 offset 等信息。
ziplist 整体结构:
<zlhead><zlbytes><zltail><zllen><entry>...<entry><zlend>
-
zlhead
使用字符串编码解码,存储当前 key 所属 value 的 bytes 数目以及是否启用了 lzf 等信息。如 ziplist 以
1B开头,对应 2 进制为0b00011011,后 6 bit 表示为 十进制27,表示当前 ziplist 共有 27 bytes。从 开始读取直到 。 -
zlbytes
4 byte 无符号整数,采用小端字节序编码。表示当前 ziplist 总占用字节数。
-
zltail
4 byte 无符号整数,采用小端字节序编码。代表到达最后一个 entry 需要跳过的字节数。
-
zllen
2 byte 无符号整数,采用小端字节序编码。ziplist entry 数目。当用于存储 hash 数据时,entry 数为 key 数 + value数。
-
entrys
存储 entry 列表。每个 entry 按如下方法存储。
entry 结构:
<length-prev-entry><special-flag><raw-bytes-of-entry>-
可变长编码,存储前一个 entry 的占用的字节数。使用[整数编码](# 整数编码)编码。
-
同样是可变长编码,存储当前 entry 的类型以及长度。
这里是理解 ziplist 的关键。
用高位的前若干 bit 分别表示两种类型以及 9 种情况:
字节码 类型 涵义 00ppppppString 00紧接的 6 bit 表示字符串长度,代表不超过 64 byte 的字符串`01pppppp qqqqqqqq` String `10______ <4 byte>` String 1100____Integer 当前 byte 紧接的 2 bytes 表示字符串长度,代表一个 16 bit 有符号整型 1101____Integer 当前 byte 紧接的 4 bytes 表示字符串长度,代表一个 32 bit 有符号整型 1110____Integer 当前 byte 紧接的 8 bytes 表示字符串长度,代表一个 64 bit 有符号整型 11110000Integer 当前 byte 紧接的 3 bytes 表示字符串长度,代表一个 24 bit 有符号整型 11111110Integer 当前 byte 紧接的 1 bytes 表示字符串长度,代表一个 8 bit 有符号整型 1111[0001-1101]Integer 特殊编码。 0001-1101对应十进制值为 1-13 。实际由于11110000已经被占用,该编码仍需要饱含0。所以需在00紧接的 4 bit 转换为数值后减掉1。所以该编码可以用来表示0-12的数值。 -
存储实际数据。依据 指定的类型和长度。采用[整数编码](# 整数编码)或[字符串编码](# 整数编码)。
-
-
zlend
固定以
0xFF结尾。
4 核心代码
rdbSave
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(char *filename, rdbSaveInfo *rsi) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp = NULL;
rio rdb;
int error = 0;
/*
创建一个临时文件名 temp-<pid>.rdb,其中 <pid> 是当前进程的 PID。
打开临时文件进行写操作。如果打开失败,记录错误日志并返回 C_ERR。
*/
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
/*
初始化 RIO 结构体
使用 rioInitWithFile 初始化 RIO(Redis I/O)结构体,使其与文件关联。
调用 startSaving 函数开始保存过程,并传递标志 RDBFLAGS_NONE 表示没有特殊标志。
*/
rioInitWithFile(&rdb,fp);
startSaving(RDBFLAGS_NONE);
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
/*
调用 rdbSaveRio 函数将数据写入 RIO 结构体。如果保存过程中出现错误,设置 errno 并跳转到 werr 标签。
*/
if (rdbSaveRio(&rdb,&error,RDBFLAGS_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
/*
刷新文件缓冲区,确保所有数据都被写入文件。
对文件描述符执行 fsync,确保数据被持久化到磁盘。
关闭文件。如果任何一步失败,跳转到 werr 标签。
*/
if (fflush(fp)) goto werr;
if (fsync(fileno(fp))) goto werr;
if (fclose(fp)) { fp = NULL; goto werr; }
fp = NULL;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
//将临时文件重命名为最终的目标文件名。如果重命名失败,记录错误日志,删除临时文件,并返回 C_ERR。
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
stopSaving(1);
return C_OK;
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
if (fp) fclose(fp);
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
/*
rdb:指向 rio 结构体的指针,用于写入数据。
error:指向整数的指针,用于存储错误代码。
rdbflags:标志位,包含一些额外的信息(如是否为 AOF 重写前言)。
rsi:指向 rdbSaveInfo 结构体的指针,包含一些额外的信息(如复制偏移量等)。
*/
int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
uint64_t cksum;
size_t processed = 0;
int j;
long key_count = 0;
long long info_updated_time = 0;
char *pname = (rdbflags & RDBFLAGS_AOF_PREAMBLE) ? "AOF rewrite" : "RDB";
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
if (rdbSaveInfoAuxFields(rdb,rdbflags,rsi) == -1) goto werr;
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
/* Write the SELECT DB opcode */
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(rdb,j) == -1) goto werr;
/* Write the RESIZE DB opcode. */
uint64_t db_size, expires_size;
db_size = dictSize(db->dict);
expires_size = dictSize(db->expires);
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
/* Iterate this DB writing every entry */
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
/* When this RDB is produced as part of an AOF rewrite, move
* accumulated diff from parent to child while rewriting in
* order to have a smaller final write. */
if (rdbflags & RDBFLAGS_AOF_PREAMBLE &&
rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
{
processed = rdb->processed_bytes;
aofReadDiffFromParent();
}
/* Update child info every 1 second (approximately).
* in order to avoid calling mstime() on each iteration, we will
* check the diff every 1024 keys */
if ((key_count++ & 1023) == 0) {
long long now = mstime();
if (now - info_updated_time >= 1000) {
sendChildInfo(CHILD_INFO_TYPE_CURRENT_INFO, key_count, pname);
info_updated_time = now;
}
}
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
/* If we are storing the replication information on disk, persist
* the script cache as well: on successful PSYNC after a restart, we need
* to be able to process any EVALSHA inside the replication backlog the
* master will send us. */
if (rsi && dictSize(server.lua_scripts)) {
di = dictGetIterator(server.lua_scripts);
while((de = dictNext(di)) != NULL) {
robj *body = dictGetVal(de);
if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)
goto werr;
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
/* EOF opcode */
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the
* loading code skips the check in this case. */
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return C_ERR;
}